贡献者Github ID:luckyLJY 文章整理:曾辉
Apache SeaTunnel 作为一款强大的数据同步和转换工具,凭借其部署易用性、容错机制、数据源支持、性能优势、功能丰富性以及活跃的社区支持,成为了数据工程师们不可或缺的利器。
因其具有的以下优良特性:
在数据源方面,支持多种传统数据库、以及现有流行的多数大数据存储;
数据同步方面,支持批流的数据同步方式,完美兼容离线同步、实时同步、全量同步、增量同步等实际应用场景;
其社区在技术更新上非常迅速,确保了中电信翼康能够及时获取技术支持与更新迭代。将其选型作为了数据集成主要技术。

SeaTunnel 不仅能够满足各种规模和类型的数据处理需求,为用户提供高效、稳定和灵活的数据处理解决方案。随着数据环境的不断演变和发展,SeaTunnel 将继续在数据同步和转换领域发挥领导作用,推动数据驱动的业务发展。
对于我们公司基于SeaTunnel的应用实践也可以参考这篇文章:https://mp.weixin.qq.com/s/SitGSc9iZYlH-nLpGR0AJw
在了解了 Apache SeaTunnel 的背景后,接下来我将分享如何快速参与其代码开发,完善功能。以自己首次贡献代码的经历为例,简述具体步骤。
代码环境搭建
- 首先,在 SeaTunnel 的官方 GitHub 仓库地址:https://github.com/apache/seatunnel 进行 fork 操作,将代码仓库复制到自己的 GitHub 账户中。
-
在本地使用 IDE(如 IntelliJ IDEA)克隆 fork 后的代码,并配置 Java 以及 Maven 仓库。
-
编译拉取的代码,并确保代码格式化:

- 编译构建项目:
- 对编译打包完成的 SeaTunnel 代码进行测试:
- 解压后的代码目录:

- 启动服务端:
- 提交测试案例:
- 测试成功的环境如下:
这一步非常重要,它确保你拥有一个正确的开发环境,以便后续代码开发的顺利进行。
学习与实践 SeaTunnel 的工作流程
- 官方提供的 SeaTunnel 工作流图:
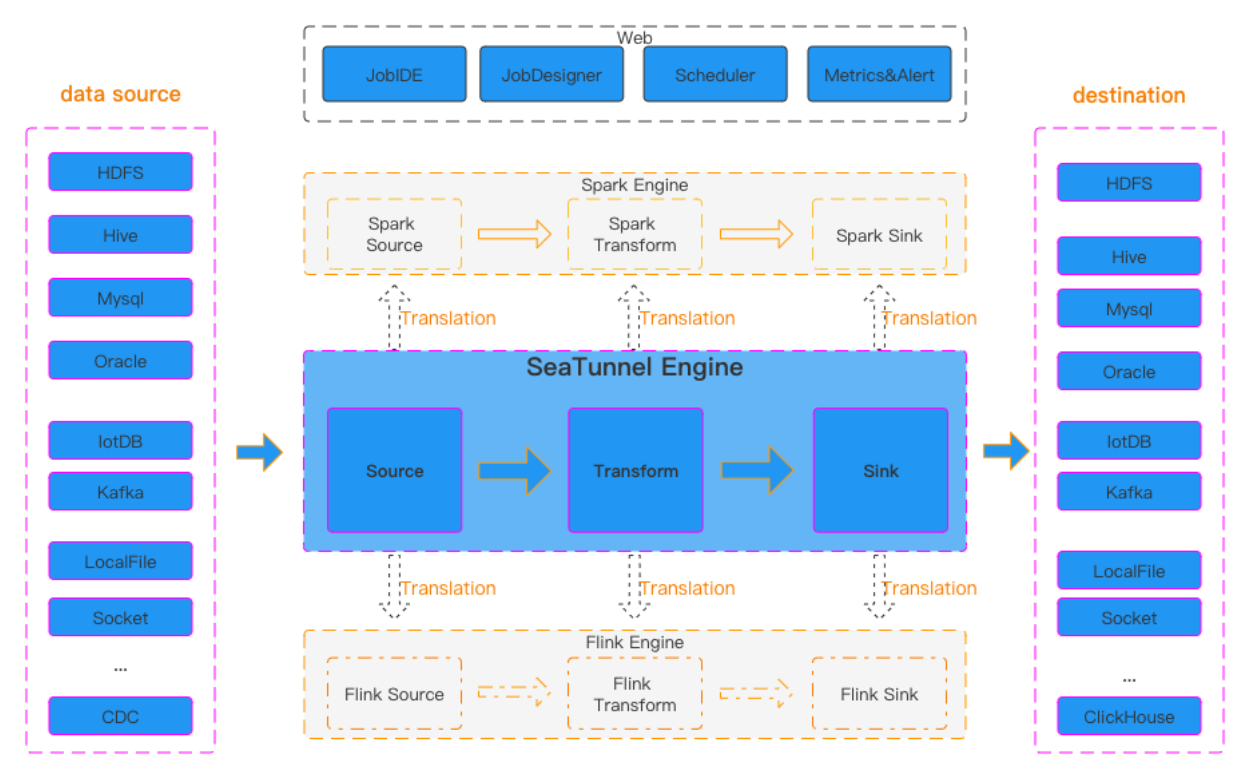
通过该图我们可以看出,SeaTunnel 的工作流程包括:source(数据源)、transform(数据转换)、sink(数据目标),以及执行引擎。source 是数据的输入源,sink 是数据的输出目标,而 transform 则是将输入数据转换为目标数据的插件。SeaTunnel 支持多种执行引擎,包括其自带的 Zeta 引擎,以及 Flink 和 Spark。
-
以 MySQL 到 MySQL 数据同步为例,以下是一个实际案例的
conf配置文件:confenv { parallelism = 1 job.mode = "BATCH" } source { jdbc { url = "jdbc:mysql://localhost:3306/test_his" driver = "com.mysql.cj.jdbc.Driver" user = "root" password = "123456" query = "select * from ods_jc_hzjbxxb;" properties { useSSL=false rewriteBatchedStatements=true } } } transform { } sink { jdbc { url = "jdbc:mysql://localhost:3306/api-server" driver = "com.mysql.cj.jdbc.Driver" user = "root" password = "123456" query = """insert into ods_jc_hzjbxxb (...) values (...);""" properties { useSSL=false rewriteBatchedStatements=true } } }
该配置实现了 MySQL 到 MySQL 的简单数据同步。请根据官方文档中的 connector-v2 示例,创建 JDBC 插件,并在 plugins/jdbc/lib 目录下放置 MySQL 连接器。然后重启 SeaTunnel 服务,将配置文件放在 config 目录下,并使用以下命令提交作业:
./bin/seatunnel.cmd --config ./config/mysql_jdbc.conf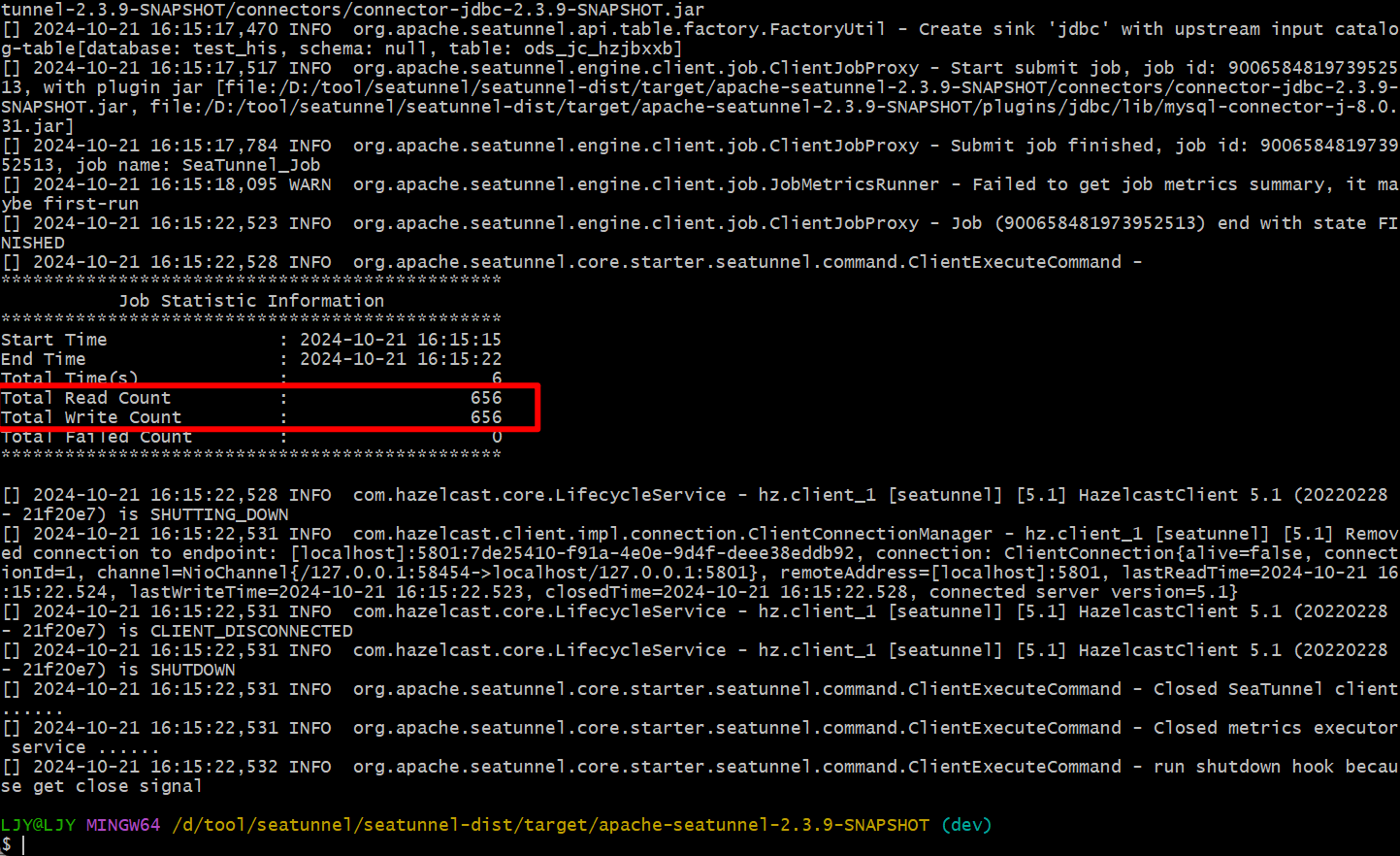
通过日志可以验证数据同步是否成功,并在目标数据库中检查同步结果。
代码阅读
通过学习 SeaTunnel 的工作流程,主要调试 SeaTunnel 自带的Zeta引擎的执行过程,通过官方文档的阅读了解到 SeaTunnel 的作业运行模式有Local和集群模式,项目实际应用更多为集群模式,因此把调试集群的执行过程作为主要学习对象。
- 服务端执行顺序的代码调试:
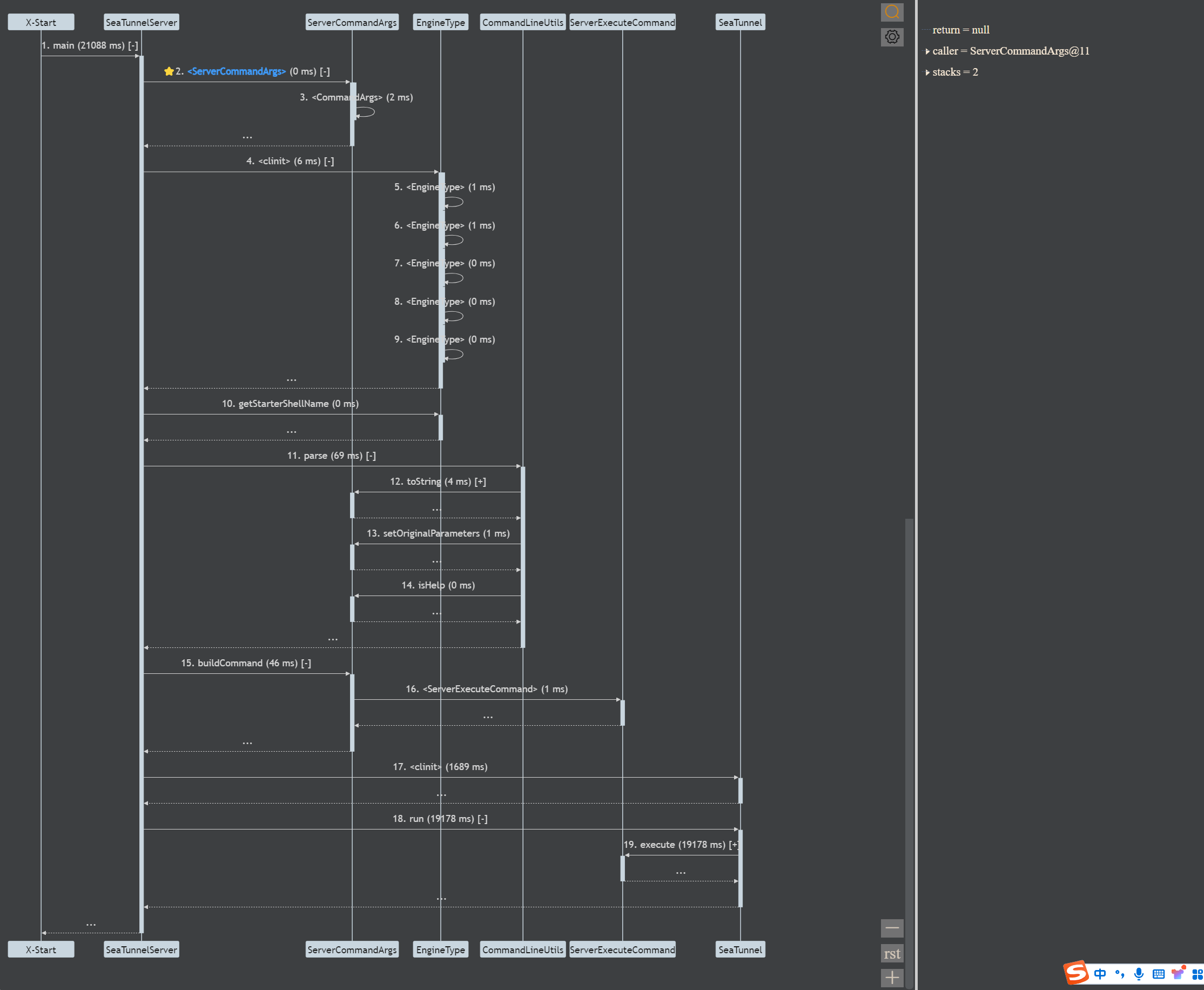
通过 server.execute() 方法查看服务端的执行流程:
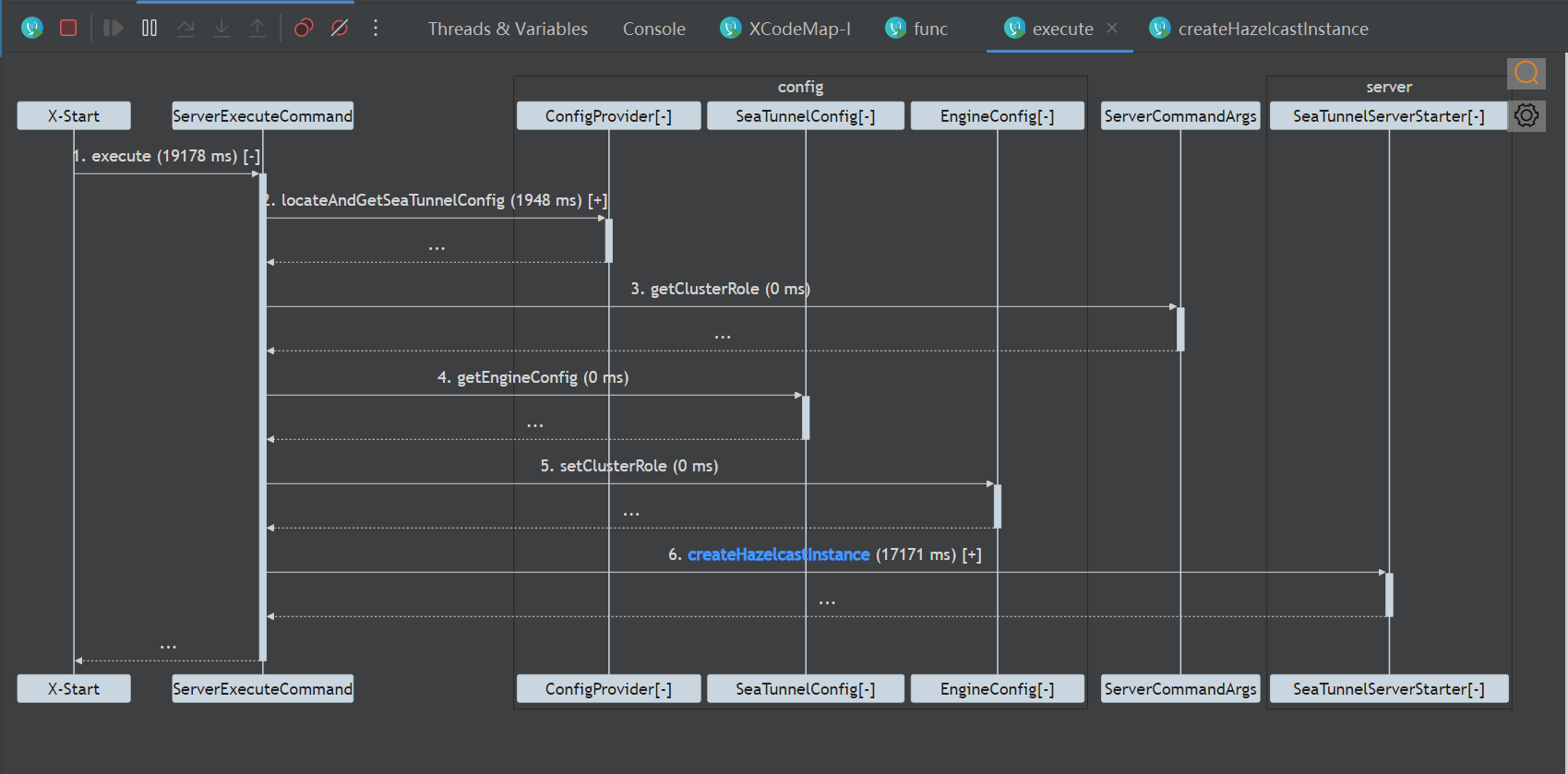
通过代码调试的手段了解客户端启动的执行顺序
- 通过命令行提交完会调用org.apache.seatunnel.core.starter.seatunnel.command.ClientExecuteCommand#execute方法
- 调用org.apache.seatunnel.engine.client.job.ClientJobProxy#submitJob方法
- 调用服务端的org.apache.seatunnel.engine.server.CoordinatorService#submitJob
尝试开发
-
需求背景
我们在公司开发
OpenGauss CDC时,发现当前的JDBC Sink插件不直接支持 OpenGauss 数据库,而是通过PostgreSQL JDBC Sink来写入。实际使用中遇到了兼容性问题,因此我决定开发一个通过 OpenGauss 自带 JDBC 驱动进行连接的功能。
-
代码实现
通过阅读 JDBC 连接器的代码,我发现只需要在
seatunnel-connectors-v2/connector-jdbc模块下实现 OpenGauss 的 Catalog 和 Dialect。org.apache.seatunnel.connectors.seatunnel.jdbc.catalog包下创建 OpenGauss 的CatalogFactory,因其兼容 PostgreSQL,可继承 Postgres 的实现。- 在
org.apache.seatunnel.connectors.seatunnel.jdbc.internal.dialect包下实现 OpenGauss 的方言工厂,覆写acceptsURL方法以支持 OpenGauss 的连接。
-
e2e 测试代码编写
编写 e2e 测试需要继承
AbstractJdbcIT类,并实现相关的测试案例,如initContainer初始化容器,以及getJdbcCase配置容器信息。
最终,我通过 Git 提交代码至自己的仓库,并向 SeaTunnel 开源项目发起 Pull Request,随后关注流水线运行情况以及代码 review 的反馈,直到社区 PMC 合并代码。
不知道如何提PR的同学可以参考这篇文章:https://mp.weixin.qq.com/s/wOVxNjg-tSQeenUY5Sd7kQ
个人心得
通过这次亲身参与 Apache SeaTunnel 代码贡献与学习的经历,我深入了解了 SeaTunnel 的源码与架构设计。
这不仅拓宽了我的技术视野,也让我更加深刻地理解了其分布式数据处理架构。从用户到开发者和贡献者的身份转变,使我能够更精确地将 SeaTunnel 的功能与特性应用到具体的业务场景中。
特别是在处理 source 和 sink 的众多配置参数时,我体会到从用户到开发者的角色转换所带来的优势。不再只是关注基本功能,而是深入理解这些配置背后的技术原理,使我能够灵活应对复杂的业务需求。
此次参与经历对我的技术成长有着重要影响,也激励我继续在开源社区中探索和贡献。
总结
通过参与 SeaTunnel 开源项目的部署、调试、阅读源码和尝试开发,我对开源项目的开发流程和规范有了更深的了解。同时,非常感谢 dailai 和 zhangdonghao 两位大佬的知识分享与帮助!
如果你有参与开源社区的想法可以联系社区小助手:seatunnel1
本文由 白鲸开源科技 提供发布支持!