来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: ClearCLIP: Decomposing CLIP Representations for Dense Vision-Language Inference

创新点
- 发现两个关键因素在将
CLIP适配密集视觉-语言推理中起着至关重要的作用:残差连接影响的减少以及通过自注意力机制的空间信息重组。 - 提出
ClearCLIP,在CLIP的最后一层中进行了三项简单的修改:去除残差连接、最后一个注意力层中采用自注意力机制以及舍弃前馈网络(FFN)。这些修改旨在增强注意力输出,从而为开放词汇语义分割任务生成更清晰的表示。
内容概述
尽管大规模预训练的视觉-语言模型(VLMs),特别是CLIP在各种开放词汇任务中取得了成功,但它们在语义分割中的应用仍然面临挑战,常常产生噪声分割图,存在误分割区域。
论文仔细重新审视了CLIP的架构,并确定残差连接是降低分割质量的主要噪声源。通过对不同预训练模型中残差连接与注意力输出的统计特性进行比较分析,发现CLIP的图像-文本对比训练范式强调全局特征,而牺牲了局部可区分性,从而导致噪声分割结果。
为此,论文提出了ClearCLIP,这是一种新颖的方法,旨在分解CLIP的表示,以增强开放词汇语义分割。对最终层进行了三项简单的修改:去除残差连接、最后一个自注意力层中采用自注意力机制以及丢弃前馈网络。ClearCLIP可以一致地产生更清晰、更准确的分割图,并在多个基准测试中超过现有方法。
ClearCLIP
基于ViT的CLIP模型由一系列残差注意力块组成。
舍弃残差连接
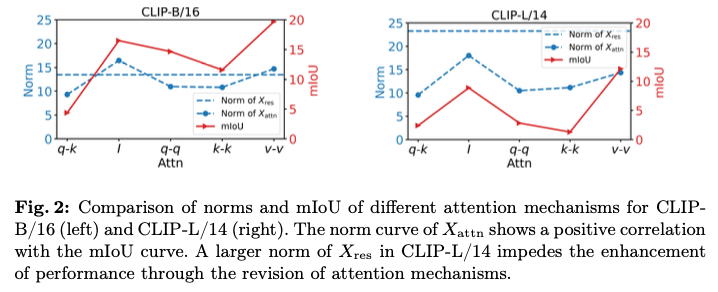
通过比较COCOStuff数据集中CLIP-B/16和CLIP-L/14模型最后一个模块的残差连接 \(X_{{res}}\) 与不同注意力输出 \(X_{{attn}}\) 的范数来开始分析,可以很容易地观察到这两个子图的共性和差异:
- 共性在于
mIoU曲线和 \(X_{attn}\) 的范数曲线表现出一定程度的正相关。 - 差异包括:
1)CLIP-B/16中 \(X_{res}\) 的范数远小于CLIP-L/14的范数;2)CLIP-B/16中的注意力修改在q-k基线之上表现出一致的改善,而CLIP-L/14中的情况则没有。
因此,当 \(X_{res}\) 的影响(或范数)最小化时,注意力修改才是有效的。换句话说, \(X_{res}\) 显著削弱了CLIP在密集推断任务上的表现。
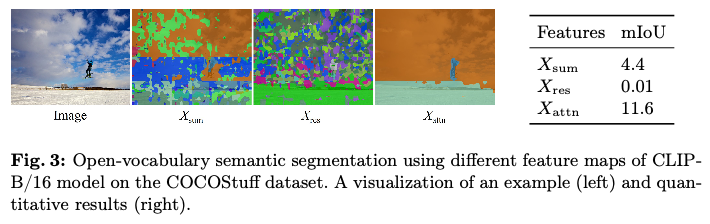
为了验证这一假设,基于CLIP-B/16使用 \(X_{{sum}}\) 、 \(X_{{res}}\) 和 \(X_{{attn}}\) 进行开放词汇语义分割实验。COCOStuff数据集上的实验结果如图3所示,发现 \(X_{res}\) 的mIoU接近于零,这表明残差连接可能对图像分割没有帮助。相反,仅使用 \(X_{{attn}}\) 的mIoU显著高于 \(X_{{sum}}\) 。图3中的可视化结果表明,CLIP的噪声分割图可以分解为一个模糊的 \(X_{{res}}\) 图和一个更清晰的 \(X_{{attn}}\) 图。根据这些实验结果,可以初步得出结论:分割图中的噪声主要来源于残差连接。
为了进一步证明 \(X_{res}\) 如何影响CLIP的性能,引入了一个缩放因子 \(\alpha\) ,使得 \(X_{{sum}} = X_{{res}} + \alpha X_{{attn}}\) ,该因子控制 \(X_{attn}\) 相对于 \(X_{res}\) 的相对影响。实验表明表明更大的 \(\alpha\) 显著提升了性能,这清楚地说明了 \(X_{{res}}\) 对性能的不利影响。
最后,论文建议直接舍弃残差连接以在密集的视觉-语言推理任务中实现最佳性能。
舍弃前馈网络(FFN)
Transformer架构中的前馈网络(FFN)在建模数据中的关系和模式方面起着至关重要的作用,但最近的研究显示,FFN在推理过程中对图像表示的影响微乎其微。最后一个注意力模块中的FFN特征与最终分类特征的余弦角度明显更大,因此建议在密集预测任务中舍弃FFN。
在应用于基础CLIP模型时,论文发现移除FFN对开放词汇语义分割任务的影响较小。但当与去除残差连接相结合时,舍弃FFN会导致结果的改善,特别是在模型规模较大的情况下。这种改进的原理在于,去除残差连接显著改变了FFN的输入,从而影响其输出。因此,去除FFN的输出可能会减轻其对性能的负面影响。
自注意力机制
基于上述分析,使用最后一个自注意力层的注意力输出用于视觉-语言推理。
\\\begin{equation} X\^{{visual}} = X_{{attn}} = {Proj}({Attn}_{(\\cdot) (\\cdot)} \\cdot v), \\label{eq:solution} \\end{equation} \\
受到之前工作的启发,可以在注意力机制 \({Attn}{(\cdot) (\cdot)}\) 中使用不同的查询-键组合。实际上, \({Attn}{qq}\) 在大多数情况下始终能够实现更好的性能,因此选择默认使用它。
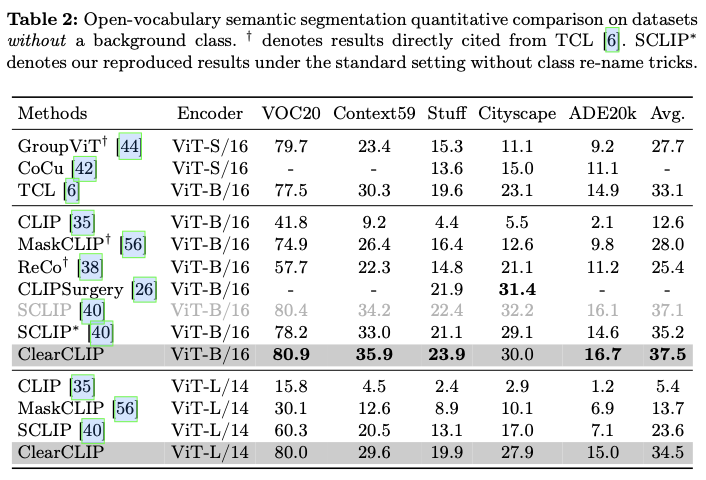
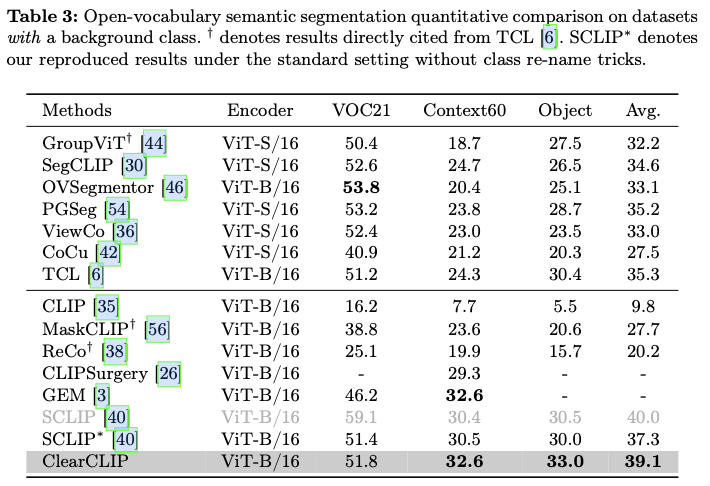
主要实验

如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
