Ceph集群的检查可以简化为 MON 状态检查、OSD 状态检查和 PG 状态检查。上一章节我们重点介绍了 MON 的状态和维护方法。本章节将重点介绍 OSD 状态和块存储常用命令。
- Tips:如果是故障排查,请在确保 MON 状态正常的情况下进行 OSD 和 PG 状态检查。
- Tips:下面的简单理解只是为了方便理解,并不能完全代表实际名称的含义。
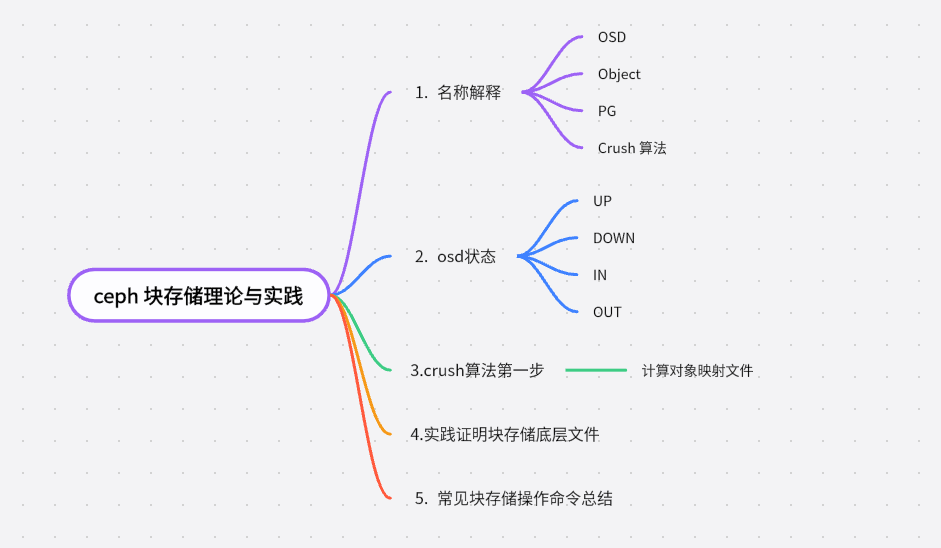
1 名称解释
OSD: 全称 Object Storage Device,也就是负责响应客户端请求并返回具体数据的进程。一个 Ceph 集群一般都有很多个 OSD。可以简单理解为一块物理磁盘或分区。
Object:Ceph 最底层的存储单元是 Object 对象,每个 Object 包含元数据和原始数据。(简单理解:如果你上传了 1G 文件 file1,它将在客户端侧分割为默认 4M 大小的数据,每一个 4M 大小的数据就是一个 Object).
PG:全称 Placement Group,一般翻译为归置组,是一个逻辑的概念,一个 PG 包含多个 OSD 集合。引入 PG 这一层是为了让数据不直接指定后端 OSD,而是不直接绑定后端设备。
ceph的数据冗余有两种模式 副本 (replicas)和 EC (纠删码),如果是副本模式,此时假定是3副本,则一个pg 对应osd集合是三个osd ,类似于pg 1.0 ->(osd1,osd2,osd3),此时pg1.0对应的副本分布存在于osd1和osd2和osd3上。
CRUSH: CRUSH 是 Ceph 使用的数据分布算法,算法分两步,第一步采用一致性hash来计算出pg,第二步则是计算出具体osd。
2 OSD状态
OSD 的守护进程只有运行和关闭两种状态,而 OSD 状态是指其在 Ceph 集群中的状态。分两个维度:
-
是否在集群中(in or out)(简单理解:osd 异常原因离线(down)300s内 ,则ceph会保留在集群内,超过300s ceph会自动将osd踢出集群,踢出去后状态为out。)
-
是否运行(up or down). (简单理解:ceph-osd 的守护进程是否运行,运行up ,否则down)
这两个维度是相互独立的因此有4种状态
| in | up | 正常状态,OSD启动并在服务中,支持正常读写。 |
|---|---|---|
| in | down | OSD停止但仍在服务中。如果300s内没有恢复,状态会变为out down,然后Ceph会开始迁移PG。 |
| out | up | OSD启动但不在集群中,Ceph正在清空这个OSD上的PG,PG会被迁移到其他OSD。 |
| out | down | OSD停止且不在集群中,需修复错误并进行恢复,或者故障维护 |
问题1: 如何查看osd状态?
ceph osd stat
3 osds: 3 up (since 2h), 3 in (since 7w); epoch: e73上面输出显示总共有3个osd, 3个osd处于 up,3个osd 处于in 状态。如果某osd down之后,怎么确定该osd处于哪个节点?
问题2: 查看osd对应的节点?
ceph osd tree
如图所示mon01 节点上有3个osd 编号分别是osd0 osd1 osd2 
- Tips: 此时查看osd对应节点依赖crush map,crush 之后章节会做详细介绍。
3 Crush算法第一步
之前文章我们提过分布式存储最大的特点就是要去中心化。如何做到去中心化了,ceph采用的方式就是一个字 算 ,那他是如何计算的了?网上有一大堆专业的文章给你来说明其是怎么计算的,这里我只想讲其算法的本质内容,力争让任何一个新手都能看懂的算法。
crush 算法的第一步将对象映射到对应的pg ,crush 算法的第二部就是将pg 映射到对应osd集合。
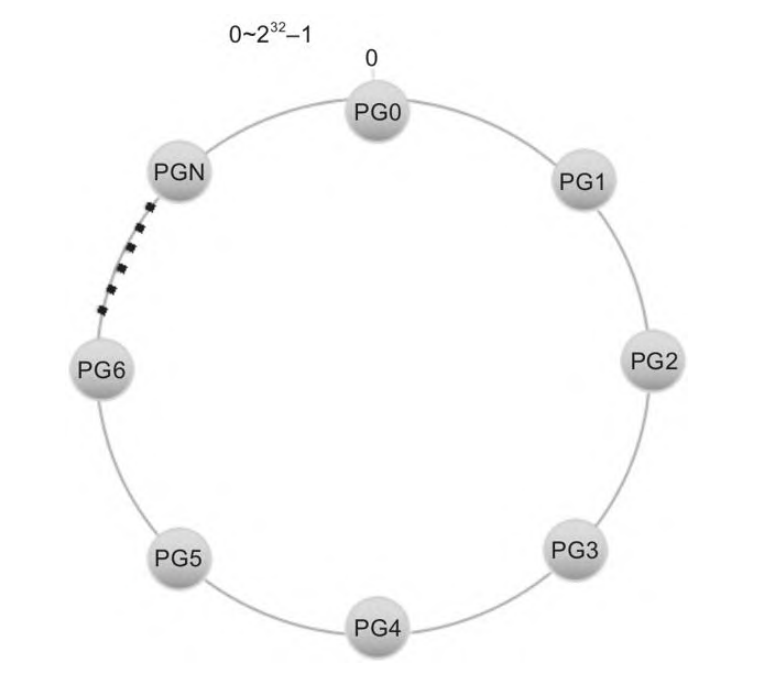
首先会构造一个长度为0~2^32-1的整数空间,然后首尾相连,形成一个封闭的环,然后pg均匀分布在这个环里。
假设有一个对象名称为 my_large_object,其大小为 10MB。由于对象大于 4MB,Ceph 会将其切分成多个小对象。对于 10MB 的对象,分割方式如下:
- 切分
- 第一个对象:my_large_object.000(前 4MB)
- 第二个对象:my_large_object.001(接下来的 4MB)
- 第三个对象:my_large_object.002(最后的 2MB)
- 哈希运算:
对于每个切分后的对象,Ceph 使用一致性哈希算法进行哈希运算。
假设:
- my_large_object.000 的哈希值为 1234567890
- my_large_object.001 的哈希值为 0987654321
- my_large_object.002 的哈希值为 1122334455
-
获取 PG 数量 :
假设该集群中有 128 个 PG(Placement Groups)。
-
取模运算:
- 对于第一个对象:1234567890 % 128 = 18,映射到 pg.18
- 对于第二个对象:0987654321 % 128 = 33,映射到 pg.33
- 对于第三个对象:1122334455 % 128 = 23,映射到 pg.23
映射到 PG:最终,Ceph 将每个小对象存储到对应的 PG 上:
my_large_object.000 存储到 pg.18
my_large_object.001 存储到 pg.33
my_large_object.002 存储到 pg.23
在实际的环境中pg是需要放在存储池 (pool )中,存储池可以形象理解为一个目录而pg则是里面文件,其实无论是pg,还是pool都是逻辑概念,ceph实际上没有该实体。
问题3: 为什么需要单独设置pg这一逻辑概念?
Ceph's data placement introduces a layer of indirection to ensure
that data doesn't bind directly to specific OSDs.For this reason,
tracking system faults requires finding the placement group
(PG) and the underlying OSDs at the root of the problem
#官方原文按官方的文档的说法,就是为了使对象不直接指定后端的osd ,而找到pg问题的根源也变成了找到pg对应的osd。这样有什么好处了,因为osd 也就是磁盘会经常故障而需要替换,而pg做为逻辑概念可以保持相对固定。这样无论后端osd 怎么变化 pg位置是相对固定,pg 取模的值也相对固定。
tips: 这也同时告知我们集群的pg数需要提前规划,规划完成后尽量不要调整pg数量,一旦pg数据调整会造成大量数据的迁移和变更。
在实际的ceph集群中 pg是一个16进制数,刚才我们也说明了pg是存在存储池(pool)中,而存储池也是有一个编号{pool-num}的,默认是从1开始的非负正整数
#查看ceph 集群存储池的详情
ceph osd pool ls detail 
如图所示第二列就是存储池的编号。而pg_num 则是存储池中pg的个数 。 {pool-num}.{pg-id} 就是pg的完整表示方式。
#查看pg 对应后端osd映射关系
# 例子:ceph pg map pg_id
# 此时是查看 pg1.0对应的 osd 集合。也说明该pg的pool-num 为1 对应上图中就是 volumes池。
ceph pg map 1.0
osdmap e3960 pg 1.0 (1.0) -> up [8,10,26] acting [8,10,26]4 实践证明
# 1 生成一个 8M 文件 f1
[root@mon01 ~]# dd if=/dev/zero of=f1 bs=1M count=8
8+0 records in
8+0 records out
8388608 bytes (8.4 MB) copied, 0.0638015 s, 131 MB/s
#2 将文件上传到 volumes 存储池中
rbd import f1 -p volumes
rbd: --pool is deprecated for import, use --dest-pool
Importing image: 100% complete...done.
#3 rbd info 文件名称 -p 存储池名称
rbd info f1 -p volumes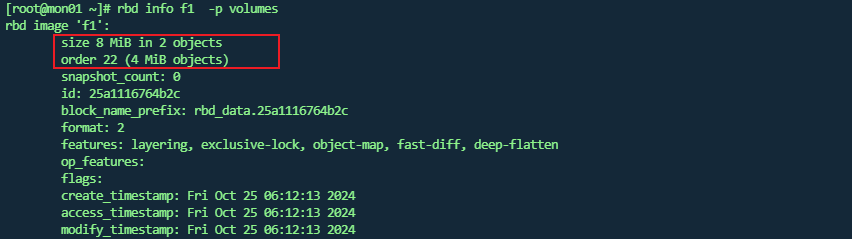
这里只是说有2个对象 ,对象大小为4MiB,并没有直观展示存储文件,事实上使用 rados 命令查看时没有看到类似00这样的文件。

这里主要是因为ceph 块存储是精简置备 , 这里对该名称不做详细介绍,其实你只需要知道,精简置备的原则就是,随着文件的内容的扩容,该文件也是会不断变化的。
下面我们继续证明上述理论。
-
先删除原先的文件
rbd rm f1 -p volumes
-
重新生成一个16M的文件f2
dd if=/dev/zero of=f2 bs=1M count=16
-
上传到volumes 存储池
rbd import f2 -p volumes
-
查看存储池中的对象文件

-
rbd 查看块文件详情
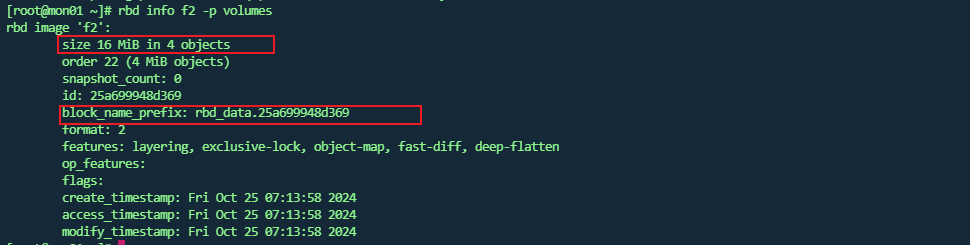
此时
block_name_prefix: rbd_data.25a699948d369说明其文件存储前缀信息。通过上面图可以发现此时是没有 rbd_data.25a699948d369 这个文件的。 -
将块文件映射进Linux 内核中
rbd map f2 -p volumes
/dev/rbd0
此时会发现系统多了一个类似磁盘的设备/dev/rbd0此时就是f2文件的映射。
-
创建系统
mkfs.xfs /dev/rbd0
-
挂载文件,并写入新文件写满16MB 文件
mount /dev/rbd0 /mnt
[root@mon01 ~]# cd /mnt/
[ dd if=/dev/zero of=file bs=1M count=16
dd: error writing 'file': No space left on device
13+0 records in
12+0 records out
12582912 bytes (13 MB) copied, 2.17574 s, 5.8 MB/s
此时报错没有空间了,此时不要紧因为16M的文件,底层有一部分占用,实际可用是少于16M的


此时正好是4个文件。也就是证明之前我们所说的所有理论。也许小伙伴会问,你这么折腾的意义是什么?
个人观点:学习任何理论知识,要学以致用,实践是检验真理的唯一标准。 另一方面通过上述的操作也能让小伙伴们了解了如何使用ceph块存储,将ceph存储池文件映射进内核就是一个块设备,是不是十分简单。
last 命令总结
#1 查看osd 状态
ceph osd stat
#2 查看osd 对应的主机
ceph osd tree
#3 查看存储池
ceph osd pool ls
#4 查看存储池详情
ceph osd pool ls detail
#5 查看pg对应的osd
ceph pg map {pg_id}
#6 上传文件到对应存储池
rbd import {filename} -p {poolname}
#7 查看存储中文件的详情
rbd info {filename} -p {poolname}
#8 将存储池中文件映射进内核
rbd map {filename} -p {poolname}
#9 取消内核映射
rbd unmap {filename} -p {poolname}
#10 查看ceph对象中底层文件
rados ls -p {poolname}下一张我们将重点介绍pg的状态,并结合实际例子来说明各种pg的状态详细含义,敬请期待。