ceph分布式存储
Ceph 分布式存储 集群配置
管理集群配置
集群引导选项
Ceph 集群引导依赖特定选项提供启动关键信息,核心逻辑与本地配置文件中的关键选项如下:
-
集群引导核心逻辑:
监控器(MON)启动时,会读取
monmap(监控器映射文件)和ceph.conf(配置文件),通过这两个文件确定与其他 MON 的通信方式,进而与其他 MON 建立仲裁(确保集群一致性的决策机制),完成集群启动基础准备。 -
关键引导选项:
- mon_ip :列出集群中所有监控器的 IP 地址,是启动集群的必备选项,且无法存储在配置数据库中,必须在初始配置中明确。
- 若不想依赖本地配置文件,可通过 DNS 服务记录提供 mon_host 列表(即监控器主机名列表),让集群通过 DNS 解析获取监控器地址。
-
本地 ceph.conf 中的其他常用选项:
- mon_host_override:用于指定集群监控器的初始列表,可覆盖其他方式获取的监控器地址。
- mon_dns_serv_name:指定 DNS SRV 记录的名称,集群通过查询该 DNS 记录识别监控器。
- mon_data/osd_data/mds_data/mgr_data:分别定义监控器、OSD、MDS、管理器守护进程的本地数据存储目录,用于存放各自的运行数据。
- keyring/keyfile/key:存储与监控器进行身份验证的凭据(如密钥环文件路径、密钥文件或直接配置密钥),确保通信安全。
在运行时覆盖配置设置
Ceph支持在守护进程运行时,临时更改大部分配置选项。
ceph tell 命令
ceph tell $type.$id config 命令可临时覆盖配置选项,并要求所配置的MON和守护进程都在运行。
ceph tell $type.$id config show,获取守护进程的所有运行时设置。ceph tell $type.$id config get,获取守护进程的特定运行时设置。ceph tell $type.$id config set,设置守护进程的特定运行时设置。当守护进程重启时,这些临时设置将恢复为原始值。
bash
[root@ceph1 ~]# ceph tell mon.ceph1.yuxb.cloud config get mon_allow_pool_delete
{
"mon_allow_pool_delete": "true"
}
[root@ceph1 ~]# ceph tell mon.ceph1.yuxb.cloud config set mon_allow_pool_delete false
{
"success": "mon_allow_pool_delete = 'false' "
}
[root@ceph1 ~]#
# 临时更改的值已生效
[root@ceph1 ~]# ceph tell mon.ceph1.yuxb.cloud config get mon_allow_pool_delete
{
"mon_allow_pool_delete": "false"
}
# 集群数据库中值仍然为true
[root@ceph1 ~]# ceph config get mon.ceph1.yuxb.cloud mon_allow_pool_delete
true
# 重启守护进程,生效的值恢复为数据库中设置的值
[root@ceph1 ~]# ceph orch daemon restart mon.ceph1.yuxb.cloud
Scheduled to restart mon.ceph1.yuxb.cloud on host 'ceph1.yuxb.cloud'
[root@ceph1 ~]# ceph tell mon.ceph1.yuxb.cloud config get mon_allow_pool_delete
{
"mon_allow_pool_delete": "true"
}
# 使用此命令更改的设置在守护进程重启后会恢复为原始设置。
# `ceph tell $type.$id config` 命令接受通配符,以获取或设置同一类型的所有守护进程的值。
[root@ceph1 ~]# ceph tell mon.* config get mon_allow_pool_delete
mon.ceph1.yuxb.cloud: {
"mon_allow_pool_delete": "true"
}
mon.ceph2: {
"mon_allow_pool_delete": "false"
}
mon.ceph3: {
"mon_allow_pool_delete": "false"
}ceph daemon 命令
Ceph支持在集群特定节点上使用 ceph daemon $type.$id config 命令临时覆盖配置选项。该命令不需要连接 MON ,但要求对应的守护进程要运行,所以即使 MON 未运行,该命令仍可发挥作用,有助于故障排除。
ceph daemon $type.$id config show ,获得特定守护进程运行时所有设置。
bash
# 在ceph1上只能查看和设置ceph1上运行的相关进程设置
[root@ceph1 ~]# cephadm shell
Inferring fsid b40700ee-9c26-11f0-8c1f-000c29463e75
Using recent ceph image quay.io/ceph/ceph@sha256:f15b41add2c01a65229b0db515d2dd57925636ea39678ccc682a49e2e9713d98
[ceph: root@ceph1 /]# ceph daemon mon.ceph1.yuxb.cloud config show配置集群监控器 Monitor
配置 Ceph 监控器
Ceph 监控器(Monitor,简称 MON)是集群的 "中枢神经",其核心职能是存储并维护集群映射(Cluster Map) ------ 这份映射包含客户端定位 MON 节点、OSD(对象存储守护进程)节点所需的关键信息,是集群正常运转的基础。
MON 与客户端的核心交互逻辑
Ceph 客户端无法直接与 OSD 进行数据读写,必须先完成以下步骤:
- 客户端主动连接任意一个 MON 节点;
- 从 MON 中检索最新的集群映射;
- 基于集群映射定位目标 OSD,之后才能执行数据的读 / 写操作。
由此可见,MON 的配置正确性直接决定了客户端能否正常接入集群、数据能否有效流转,是 Ceph 集群部署与维护的核心环节。
MON 的共识机制与角色划分
为确保集群映射的一致性和可靠性,MON 集群采用 Paxos 算法变体(具体为 Paxos 的优化实现)来实现分布式共识,通过选举 "领导者" 确保多节点间的决策统一。
根据集群映射的同步状态,每个 MON 会被分配以下三种角色之一:
- Leader(领导者) :集群中第一个获取并持有最新版本集群映射的 MON,负责协调集群映射的更新与同步,是 MON 集群的核心决策节点。
- Provider(提供者):同样持有最新版本的集群映射,但未被选举为 Leader,主要职能是为 "落后" 的 MON 提供映射同步服务。
- Requester(请求者):未持有最新版本的集群映射,需主动向 Provider 发起同步请求,完成映射更新后才能重新加入集群的 "仲裁体系"(Quorum)。
MON 的映射同步与高可用规则
映射同步机制
MON 集群的映射同步遵循 "主动检查 + 被动同步" 原则:
- 实时触发同步:当有新的 MON 节点加入集群时,会立即触发同步流程,新节点以 Requester 身份向 Provider 同步最新映射;
- 定期检查同步:所有已加入集群的 MON 会定期(由集群配置参数控制)检查相邻 MON 的映射版本,若发现自身版本落后,会自动向持有新版本的 Provider 发起同步,确保集群内所有 MON 映射一致。
仲裁(Quorum)与高可用配置
Ceph MON 集群的可用性依赖 "仲裁机制"------ 只有当集群中超过半数的 MON 处于正常运行状态时,才能建立有效的仲裁(Quorum),确保集群映射的更新与决策合法。
- 仲裁计算示例:若部署 5 个 MON 节点,需至少 3 个节点正常运行(5/2 + 1 = 3)才能建立仲裁;若部署 3 个 MON 节点,则需至少 2 个节点正常运行。
- 生产环境核心建议 :为保障高可用性,生产级 Ceph 集群必须至少部署 3 个 MON 节点(避免单节点故障导致集群失活)。同时,Ceph 支持在集群运行过程中动态添加 / 删除 MON 节点,便于根据业务规模调整集群架构。
查看监控器仲裁
ceph status 命令,检查 MON 仲裁状态。
bash
[root@ceph1 ~]# ceph status | grep mon
mon: 3 daemons, quorum ceph1.yuxb.cloud,ceph2,ceph3 (age 38m)ceph mon stat` 命令,检查 MON 仲裁状态。
bash
[root@ceph1 ~]# ceph mon stat
e3: 3 mons at {ceph1.yuxb.cloud=[v2:192.168.108.11:3300/0,v1:192.168.108.11:6789/0],ceph2=[v2:192.168.108.12:3300/0,v1:192.168.108.12:6789/0],ceph3=[v2:192.168.108.13:3300/0,v1:192.168.108.13:6789/0]} removed_ranks: {}, election epoch 26, leader 0 ceph1.yuxb.cloud, quorum 0,1,2 ceph1.yuxb.cloud,ceph2,ceph3ceph quorum_status -f json-pretty 命令,友好的 json 格式输出 MON 仲裁状态。
bash
[root@ceph1 ~]# ceph quorum_status -f json-pretty
{
"election_epoch": 26,
"quorum": [
0,
1,
2
],
"quorum_names": [
"ceph1.yuxb.cloud",
"ceph2",
"ceph3"
],
"quorum_leader_name": "ceph1.yuxb.cloud",
"quorum_age": 2323,
......控制面板中查看 MON 的状态:单击Cluster > Monitor。
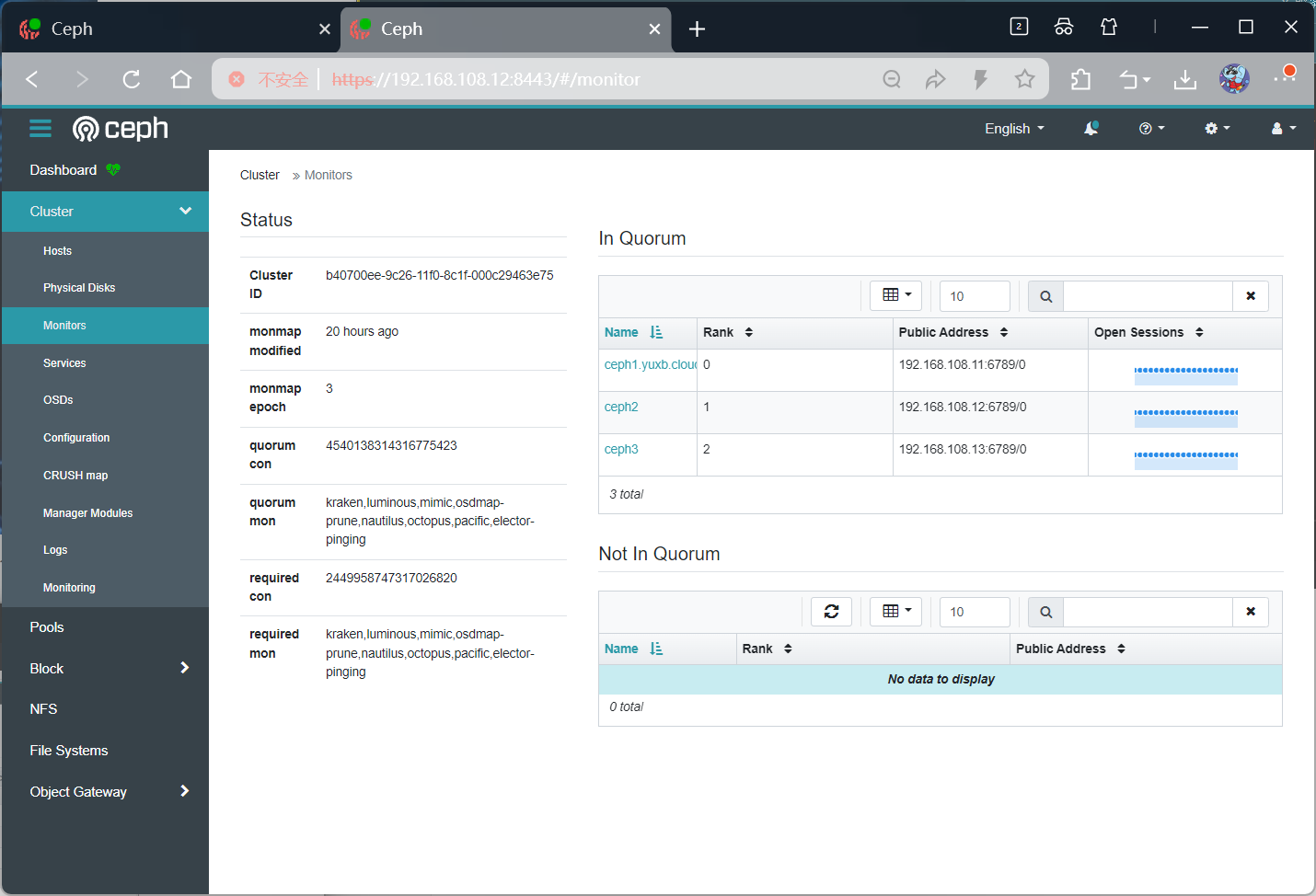
分析监控器映射
Ceph 集群映射包含:
- MON 映射
- OSD 映射
- PG 映射
- MDS 映射
- CRUSH 映射
MON 映射包含:
- 集群 fsid(文件系统 ID),fsid 是一种自动生成的唯一标识符 (UUID),用于标识 Ceph 集群。
- 各个 MON 节点通信的名称、IP 地址和网络端口。
- 映射版本信息,如 epoch 和最近一次更改时间。MON 节点通过同步更改并就当前版本达成一致来维护映射。
bash
[root@ceph1 ~]# ceph mon dump
epoch 3
fsid b40700ee-9c26-11f0-8c1f-000c29463e75 #集群fsid
last_changed 2025-09-28T06:25:27.879600+0000
created 2025-09-28T04:50:58.062319+0000
min_mon_release 16 (pacific)
election_strategy: 1
0: [v2:192.168.108.11:3300/0,v1:192.168.108.11:6789/0] mon.ceph1.yuxb.cloud
1: [v2:192.168.108.12:3300/0,v1:192.168.108.12:6789/0] mon.ceph2
2: [v2:192.168.108.13:3300/0,v1:192.168.108.13:6789/0] mon.ceph3
dumped monmap epoch 3管理集中配置数据库
MON 节点存储和维护集中配置数据库。数据库文件位于 MON 节点,默认位置是:
/var/lib/ceph/$fsid/mon.$host/store.db。
数据库文件会不断增大,改进措施:
运行 ceph tell mon.$id compact 命令,整合数据库,以提高性能。
bash
[root@ceph1 ~]# ceph tell mon.ceph1.yuxb.cloud compact
compacted rocksdb in 0 seconds将 mon_compact_on_start 配置选项为 TRUE ,以便在每次守护进程启动时压缩数据库。
bash
[root@ceph1 ~]# ceph config set mon mon_compact_on_start true设置以下数据库文件大小相关定义,以触发运行状况变化:
- mon_data_size_warn ,当配置数据库文件的大小超过此值时,集群运行状况更改为HEALTH_WARN 。默认值是15 (GB)。
- mon_data_avail_warn ,当包含配置数据库文件的文件系统剩余容量小于或等于此百分比时,将集群运行状况更改为 HEALTH_WARN 。默认值是30 (%)。
- mon_data_avail_crit ,当包含配置数据库的文件系统剩余容量小于或等于此百分比 时,将集群运行状况更改为 HEALTH_ERR 。默认值是5 (%)。
集群验证
Ceph 默认使用 Cephx 协议进行加密身份验证,同时使用共享密钥进行身份验证。默认情况下,Ceph 会启用 Cephx。如有必要,可以禁用 Cephx,但不建议这样做,因为这样会减弱集群的安全性。
使用 ceph config set 命令启用或禁用 Cephx 协议。
bash
[root@ceph1 ~]# ceph config get mon auth_service_required
cephx
[root@ceph1 ~]# ceph config get mon auth_cluster_required
cephx
[root@ceph1 ~]# ceph config get mon auth_client_required
cephx, none参数说明:
- auth_service_required ,客户端与Ceph services之间通信认证。可用值
cephx和none。 - auth_cluster_required ,Ceph集群守护进程之间通信认证,例如
ceph-mon,ceph-osd,ceph-mds,ceph-mgr。可用值cephx和none。 - auth_client_required ,客户端与Ceph集群之间通信认证。可用值
cephx和none。
cephadm 工具创建 client.admin 用户,让用户能够运行管理命令并创建其他 Ceph 客户端用户帐户,用户密钥环存储在 /etc/ceph 目录中。
bash
[root@ceph1 ~]# ls /etc/ceph
ceph.client.admin.keyring ceph.conf ceph.pub rbdmap守护进程数据目录包含 Cephx 密钥环文件。对于 MON,密钥环文件是:
/var/lib/ceph/fsid/mon.fsid/mon.fsid/mon.host/keyring。
bash
[root@ceph1 ~]# ls /var/lib/ceph/b40700ee-9c26-11f0-8c1f-000c29463e75/mon.ceph1.yuxb.cloud/keyring
/var/lib/ceph/b40700ee-9c26-11f0-8c1f-000c29463e75/mon.ceph1.yuxb.cloud/keyring**密钥环文件以纯文本形式存储机密密钥。**务必使用合适的 Linux 文件权限来保护它们的安全。
使用ceph auth命令创建、查看和管理集群
使用 ceph-authtool 命令创建密钥环文件。
示例:为 MON 节点创建一个密钥环文件。
bash
[root@ceph1 ~]# ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *'
creating /tmp/ceph.mon.keyring
# --create-keyring /tmp/ceph.mon.keyring
创建一个新的密钥环文件(Keyring),路径为 /tmp/ceph.mon.keyring。
# --gen-key -n mon.
生成一个新密钥(--gen-key)。
-n mon. 指定密钥关联的实体名称(Entity Name),这里是 mon.(表示 Monitor 守护进程)。
注意:实体名称通常以守护进程类型开头(如 mon.、osd.),后接节点标识符(如 mon.a)。
# --cap mon 'allow *'
为该密钥分配权限(Capabilities):
mon 表示权限作用于 Monitor 服务。
'allow *' 授予 所有 Monitor 操作的完全权限(如访问集群状态、修改配置等)。
# cephadm工具还会在/etc/ceph目录中创建client.admin用户,让您能够运行管理命令并创建其他Ceph客户端用户帐户。Ceph 分布式存储 池管理
Ceph 数据组织结构
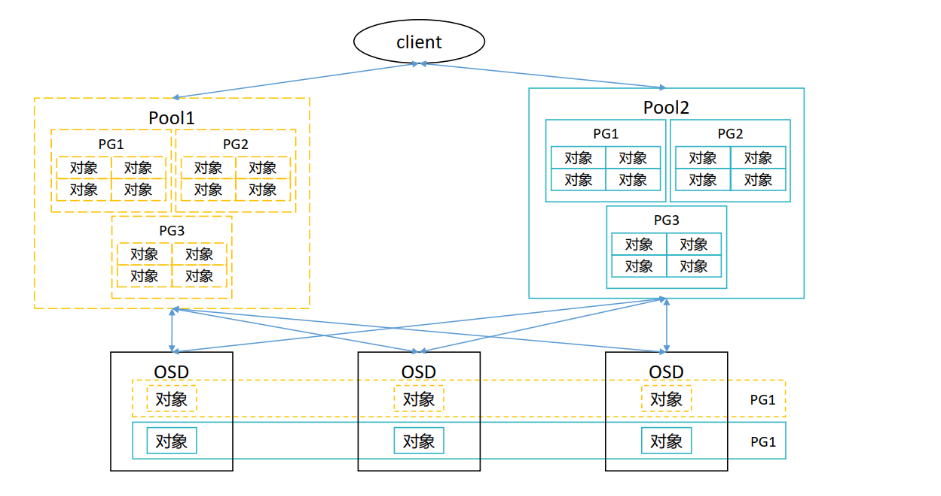
POOL
池是 Ceph 存储集群的逻辑分区,用于在通用名称标签下存储对象。 Ceph 为每个池分配特定数量放置组 (PG),用于对对象进行分组以进行存储。
每个池具有以下可调整属性:
- 池 ID
- 池名称
- PG 数量
- CRUSH 规则,用于确定此池的 PG 映射
- 保护类型(复本或擦除编码)
- 与保护类型相关的参数
- 影响集群行为的各种标志
Place Group
PG(Placement Group,归置组)是 Ceph 中连接 Pool(存储池)与 OSD 的核心中间层,本质是 Pool 的子集、对象的集合,且一个 PG 仅归属一个 Pool。
其核心作用是通过哈希映射实现数据分配:Ceph 会将同一 PG 内的所有对象计算出相同哈希值,再将该 PG 整体映射到一组 OSD 上,以此实现对象在集群中的分布式存储。
PG 数量直接影响 Ceph 集群性能,需平衡设置:
- 数量过多:数据移动时单个 PG 数据量少,但 Ceph 会消耗大量 CPU、内存用于 PG 管理计算,影响客户端正常使用;
- 数量过少:单个 PG 存储数据量大,移动 PG 时会占用大量网络带宽,同样影响客户端使用。
关于 PG 数量设置,有明确的计算规则和原则:
-
旧版本计算公式
(结果需舍入到最接近的 2 的 N 次幂):
- 集群 PG 总数 = (OSD 数 × 100) / 最大副本数;
- 单个 Pool 的 PG 总数 = (OSD 数 × 100) / 最大副本数 / 池数;
-
通用设置原则:
- OSD 数 < 5 时,PG 数量设为 128;
- 5 ≤ OSD 数 < 10 时,PG 数量设为 512;
- 10 ≤ OSD 数 < 50 时,PG 数量设为 4096;
- OSD 数 > 50 时,建议用官方工具计算,链接:https://old.ceph.com/pgcalc/。
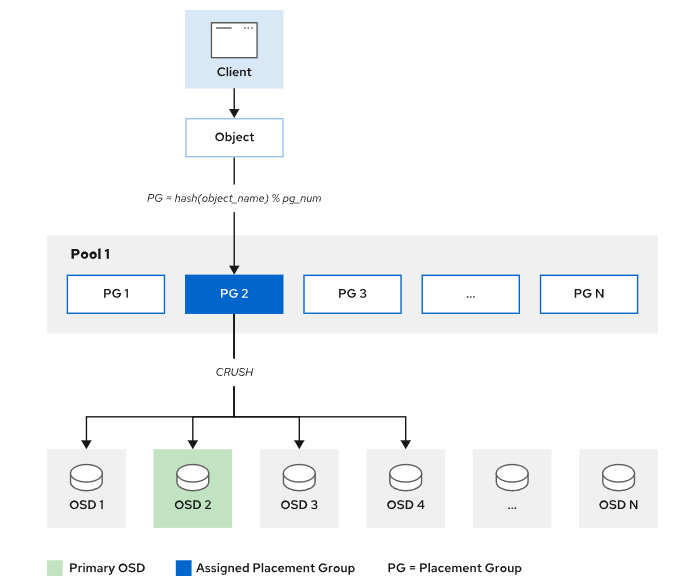
映射对象到OSD
Ceph 客户端读写数据时,无需关心对象具体存储位置,只需提供 "资源池名称" 和 "对象 ID"(完整对象含对象 ID、二进制数据、对象元数据),核心流程分四步:
- 获取集群映射:客户端先向监控器(MON)请求最新集群映射副本,该映射包含集群中所有 MON、OSD、MDS 的信息(如节点状态、位置),但不包含具体对象的存储位置。
- 计算 PG ID :根据 "对象 ID" 和 "资源池的 PG 数量" 计算归属的 PG ID,公式为
PG ID = hash(Object ID)%(PG number)。其中,资源池的 PG 数量需通过池名称从集群配置中获取,哈希运算确保同一对象始终映射到固定 PG。 - 用 CRUSH 算法确定 OSD 组:客户端通过 CRUSH 算法,根据 PG ID 计算出该 PG 对应的 OSD 集合(Acting Set),且 Acting Set 属于集群的 "在线 OSD 集合(Up Set)"。Up Set 中第一个 OSD 是该 PG 的主 OSD,其余为辅助 OSD(用于存储副本)。
- 直接与主 OSD 通信:客户端无需经过 MON 中转,直接与计算出的主 OSD 建立连接,完成数据的读写操作。
客户端访问ceph流程
- 客户端向MON集群发起连接请求。
- 客户端和MON建立连接后,它将索引最新版本的cluster map,从而获取到MON、 OSD和MDS的信息,但不包括对象的存储位置。
- client根据CRUSH算法计算出对象对应的PG和OSD。
- client根据上步中计算得出主OSD的位置,然后和其进行通信,完成对象的读写。
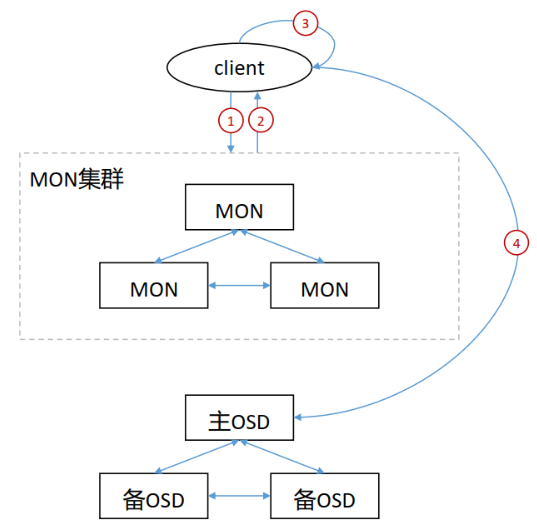
在 ceph 中,客户端自行计算对象存储位置的速度要比通过和ceph组件交互来查询对象存储位置快很多,因此,在数据读写时,都是客户端根据CRUSH完成对象的位置计算。
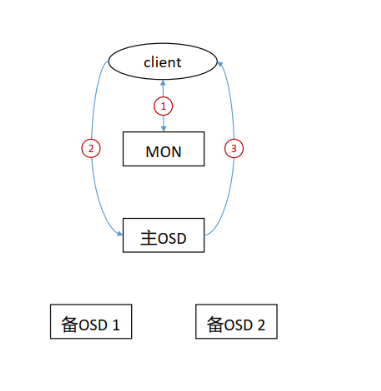
Ceph 数据读取流程
- 客户端通过MON获取到cluster map。
- client通过cluster map获取到主OSD节点信息,并向其发送读取请求。
- 主OSD将client请求的数据返回给client。
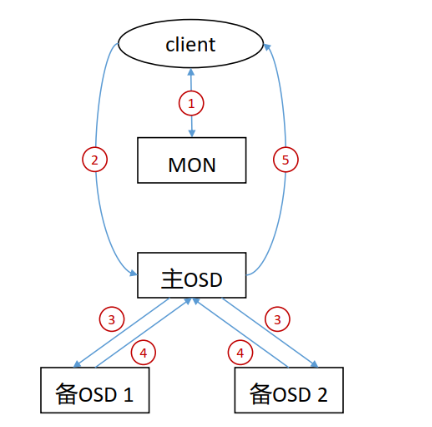
Ceph 数据写入流程
- 客户端通过 MON 获取到 cluster map。
- 客户端通过cluster map获取到主OSD节点信息,并向其发送写入请求。
- 主OSD收到写入请求后,将数据写入,并向两个备OSD发起数据写入指令。
- 两个备OSD将数据写入后返回确认到主OSD。
- 主OSD收到所有备OSD写入完成后的确认后,向客户端返回写入完成的确认。
Ceph 写入优化:平衡强一致性与延迟
Ceph 为保障数据强一致性,原本需等数据全写入磁盘再响应,会导致高延迟。因此设计了 "两次确认" 写入机制,既保一致性又降延迟:
-
第一次确认(缓存写入完成)
所有 OSD 节点将数据写入内存缓存后,立即向客户端确认。客户端收到后,认为写入完成,可继续后续操作,大幅降低感知延迟。
-
第二次确认(磁盘持久化完成)
OSD 后台将缓存数据刷入物理磁盘,所有节点完成后,再向客户端二次确认。客户端此时确认数据彻底落地,可按需删除本地临时数据。
底层仍通过 "副本同步"(主从 OSD 同步写入)和 "故障恢复"(节点故障时从副本补写),确保强一致性不打折。
数据保护
Ceph 存储支持:复本池 和纠删码池。
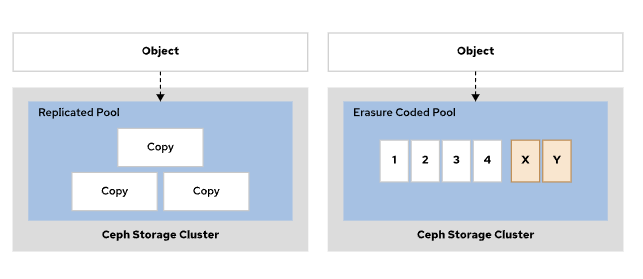
Ceph 存储池(Pool)核心类型与选择指南
Ceph 存储池(Pool)是数据存储的逻辑容器,核心分为复本池 和纠删代码池两类,二者在存储开销、性能、适用场景上差异显著,且创建后不可修改类型,需根据业务需求提前选型。
核心池类型对比
| 特性 | 复本池(Replicated Pool) | 纠删代码池(Erasure Code Pool) |
|---|---|---|
| 核心原理 | 将数据对象复制为多个副本,分散存储到不同 OSD 节点 | 用纠删码算法拆分数据 + 生成校验块,节省存储 |
| 存储开销 | 高(如 3 副本需 3 倍原始存储空间) | 低(如 4+2 配置仅需 1.5 倍原始存储空间) |
| 性能表现 | 读写速度快(无额外计算,直接操作副本) | 读写有额外 CPU 消耗(需计算 / 校验奇偶块),延迟较高 |
| 网络带宽需求 | 高(同步副本需传输完整数据) | 低(传输拆分后的数据块 + 校验块) |
| 核心优势 | 低延迟、高可用性,适合高频访问 | 存储效率高,节省硬件成本 |
选型核心建议
- 选复本池的场景
- 数据需频繁读写(如数据库、虚拟机磁盘);
- 对读取延迟敏感(如业务系统实时数据);
- 优先保障可用性和性能,对存储成本不敏感。
- 选纠删代码池的场景
- 数据访问频率低(如备份数据、归档文件);
- 对延迟要求不高,但需大幅节省存储成本;
- CPU 资源相对充足(可承担校验计算开销)。
关键注意事项
- 类型不可修改:池创建后无法从复本池转为纠删代码池(反之亦然),需提前规划业务需求;
- 副本 / 纠删配置:复本池需指定副本数(如 3 副本),纠删代码池需指定 "数据块数 + 校验块数"(如 4+2,代表 4 个数据块 + 2 个校验块,允许 2 个块丢失)。
创建池
创建复本池
Ceph 为每个对象创建多个复本来保护复本池中的数据。Ceph 使用CRUSH 故障域来确定存储数据的操作集的主要 OSD。然后,主要 OSD 会查找池的当前复本数量,并计算要写入对象的次要 OSD。在主要 OSD 收到写入确认并完成数据写入后,主要 OSD 会向 Ceph 客户端确认写入操作已成功。如果一个或多个 OSD 出现故障,这一过程可保护对象中的数据。
bash
# 创建复本池语法
ceph osd pool create pool-name pg-num pgp-num replicated crush-rule-name
# pool_name,指定新池的名称。
# pg_num,指定池的放置组 (PG) 总数。
# pgp_num,指定池的有效放置组数量。将它设置为与 pg_num 相等。该值可省略。
# replicated,指定池的类型为复本池;如果命令中未包含此参数,这是默认值。
# crush-rule-name,指定池的 CRUSH 规则集的名称。示例:
bash
[root@ceph1 ~]# ceph osd pool create pool_web 32 32 replicated
pool 'pool_web' created
[root@ceph1 ~]# ceph osd pool ls
device_health_metrics
pool_web创建纠删代码池
纠删代码池通过 "数据分块 + 编码冗余" 机制保护对象数据,核心是将数据拆分为多个区块并生成编码块,存储在不同 OSD 中,既实现故障时的数据重构,又大幅提升存储效率,具体逻辑如下:
核心工作原理
- 数据与编码块拆分 :存储对象时,先将数据分割为
k个等大的数据区块,再通过算法计算生成m个编码区块(编码块大小与数据块一致); - 分布式存储 :
k个数据块 +m个编码块,共k+m个区块,分别存储到集群中不同的 OSD 节点; - 故障重构 :当最多
m个 OSD 节点故障(数据块或编码块丢失)时,可通过剩余的k个数据块(或部分数据块 + 编码块)反向计算,重构完整对象数据。
与复本池的存储效率对比
复本池需存储 n 份完整对象副本(如 3 副本需 3 倍原始空间),而纠删代码池仅需存储 k+m 个区块,存储开销远低于复本模式:
- 示例 1:3 副本复本池 → 存储开销为原始数据的 3 倍;
- 示例 2:
k=4、m=2的纠删代码池 → 仅需存储 6 个区块(4 数据 + 2 编码),开销为原始数据的6/4=1.5倍。
支持的 k+m 配置与容量计算
- 常用 k+m 组合及存储比率 (比率 = 原始数据大小 / 实际存储大小):
- 4+2 → 比率 1:1.5(即实际存储为原始数据的 1.5 倍);
- 8+3 → 比率 1:1.375;
- 8+4 → 比率 1:1.5。
- 有效容量计算方法 :
- 核心公式:有效容量 =
[k/(k+m)] × 集群总原始容量; - 示例:64 个 OSD(每个 4TB,总原始容量 256TB),配置
k=8、m=4→ 有效容量 =[8/(8+4)] × 256 ≈ 170.67TB,存储比率为256/170.67≈1.5。
- 核心公式:有效容量 =
bash
# 创建纠删代码池语法
ceph osd pool create pool-name pg-num pgp-num erasure erasure-code-profile crush-rule-name
# pool-name,指定新池的名称。
# pg-num,指定池的放置组 (PG) 总数。
# pgp-num,指定池的有效放置组数量。通常而言,这应当与PG总数相等。
# erasure,指定池的类型是纠删代码池。
# erasure-code-profile,指定池使用的纠删代码配置文件的名称。默认情况下,Ceph使用default配置文件。
# crush-rule-name是要用于这个池的 CRUSH 规则集的名称。如果不设置,Ceph 将使用纠删代码池配置文件中定义的规则集。
# 纠删代码池无法使用对象映射功能。对象映射是对象的一个索引,用于跟踪 rbd 对象的块会被分配到哪里,可用于提高大小调整、导出、扁平化和其他操作的性能。示例:
bash
[root@ceph1 ~]# ceph osd pool create pool_era 32 32 erasure
pool 'pool_era' created
[root@ceph1 ~]# ceph osd pool ls
device_health_metrics
pool_web
pool_era
# 查看默认纠删代码配置
[root@ceph1 ~]# ceph osd erasure-code-profile ls
default
[root@ceph1 ~]# ceph osd erasure-code-profile get default
k=2
m=2
plugin=jerasure
technique=reed_sol_van管理纠删代码配置文件
纠删代码配置文件可配置纠删代码池用于存储对象的数据区块和编码区块的数量,以及要使用的纠删代码插件和算法。
bash
# 创建纠删代码配置文件语法
ceph osd erasure-code-profile set profile-name arguments
- k,在不同 OSD 之间拆分的数据区块数量。默认值为 2。
- m,数据变得不可用之前可以出现故障的 OSD 数量。默认值为 1。
- directory,此可选参数是插件库的位置。默认值为 /usr/lib64/ceph/erasure-code。
- plugin,此可选参数定义要使用的纠删代码算法。
- crush-failure-domain,此可选参数定义 CRUSH 故障域,它控制区块放置。默认设置为 host,这样可确保对象的区块放置到不同主机的 OSD 上。如果设置为 osd,则对象的区块可以放置到同一主机的 OSD 上。如果主机出现故障,则该主机上的所有 OSD 都会出现故障。故障域可用于确保将区块放置到不同数据中心机架或其他定制的主机上的 OSD 上。
- crush-device-class,此可选参数选择仅将这一类别设备支持的 OSD 用于池。典型的类别可能包括 hdd、ssd 或nvme。
- crush-root,此可选参数设置 CRUSH 规则集的根节点。
- key=value,插件可以具有对该插件唯一的键值参数。
- technique,每个插件提供一组不同的技术来实施不同的算法。示例:
bash
[root@ceph1 ~]# ceph osd erasure-code-profile set ceph k=4 m=2
# 列出现有的就删代码配置文件
[root@ceph1 ~]# ceph osd erasure-code-profile ls
ceph
default
# 查看现有配置文件的详细信息
[root@ceph1 ~]# ceph osd erasure-code-profile get ceph
crush-device-class=
crush-failure-domain=host
crush-root=default
jerasure-per-chunk-alignment=false
k=4
m=2
plugin=jerasure
technique=reed_sol_van
w=8
# 删除现有的配置文件
[root@ceph1 ~]# ceph osd erasure-code-profile rm ceph
[root@ceph1 ~]# ceph osd erasure-code-profile ls
default
# 现有纠删代码配置文件是无法修改或更改,只能创建新的配置文件查看池状态
bash
# 列出池清单
[root@ceph1 ~]# ceph osd pool ls
device_health_metrics
pool_web
pool_era
或
[root@ceph1 ~]# ceph osd lspools
1 device_health_metrics
2 pool_web
3 pool_era
# 列出池清单和池的详细配置
[root@ceph1 ~]# ceph osd pool ls detail
pool 1 'device_health_metrics' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 43 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr_devicehealth
pool 2 'pool_web' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 46 flags hashpspool stripe_width 0
pool 3 'pool_era' erasure profile default size 4 min_size 3 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 52 flags hashpspool stripe_width 8192
# 列出池状态信息,池被哪些客户端使用
[root@ceph1 ~]# ceph osd pool stats
pool device_health_metrics id 1
nothing is going on
pool pool_web id 2
nothing is going on
pool pool_era id 3
nothing is going on
# 查看池容量使用信息
[root@ceph1 ~]# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 180 GiB 177 GiB 2.6 GiB 2.6 GiB 1.42
TOTAL 180 GiB 177 GiB 2.6 GiB 2.6 GiB 1.42
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 0 B 3 0 B 0 56 GiB
pool_web 2 32 0 B 0 0 B 0 56 GiB
pool_era 3 32 0 B 0 0 B 0 84 GiB管理 池
管理 池 应用类型
使用 ceph osd pool application 命令,管理池 Ceph 应用类型。应用类型有cephfs(用于 Ceph 文件系统) 、rbd(Ceph 块设备)和 rgw(RADOS 网关)。
bash
[root@ceph1 ~]# ceph osd pool application
disable enable get rm set
# 启用池的类型为rbd
[root@ceph1 ~]# ceph osd pool application enable pool_web rbd
enabled application 'rbd' on pool 'pool_web'
[root@ceph1 ~]#
[root@ceph1 ~]# ceph osd pool ls detail | grep pool_web
pool 2 'pool_web' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 58 flags hashpspool stripe_width 0 application rbd
# 使用set子命令,设置池的应用类型详细配置
[root@ceph1 ~]# ceph osd pool application set pool_web rbd app1 apache
set application 'rbd' key 'app1' to 'apache' on pool 'pool_web'
# 使用get子命令,查看池的应用类型详细配置
[root@ceph1 ~]# ceph osd pool application get pool_web
{
"rbd": {
"app1": "apache"
}
}
# 使用rm子命令,删除池的应用类型详细配置
[root@ceph1 ~]# ceph osd pool application rm pool_web rbd app1
removed application 'rbd' key 'app1' on pool 'pool_web'
[root@ceph1 ~]# ceph osd pool application get pool_web
{
"rbd": {}
}
# 禁用池的类型
[root@ceph1 ~]# ceph osd pool application disable pool_web rbd --yes-i-really-mean-it
disable application 'rbd' on pool 'pool_web'
[root@ceph1 ~]# ceph osd pool ls detail | grep pool_web
pool 2 'pool_web' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 61 flags hashpspool stripe_width 0管理 池 配额
使用 ceph osd pool get-quota 命令,获取池配额信息:池中能够存储的最大字节数或最大对象数量。
bash
[root@ceph1 ~]# ceph osd pool get-quota pool_web
quotas for pool 'pool_web':
max objects: N/A
max bytes : N/A
[root@ceph1 ~]#使用 ceph osd pool set-quota 命令,可以设置池配额来限制池中能够存储的最大字节数或最大对象数量。
bash
[root@ceph1 ~]# ceph osd pool set-quota pool_web max_objects 100000
set-quota max_objects = 100000 for pool pool_web
[root@ceph1 ~]# ceph osd pool set-quota pool_web max_bytes 10G
set-quota max_bytes = 10737418240 for pool pool_web
[root@ceph1 ~]# ceph osd pool get-quota pool_web
quotas for pool 'pool_web':
max objects: 100k objects (current num objects: 0 objects)
max bytes : 10 GiB (current num bytes: 0 bytes)当池使用量达到池配额时,操作将被阻止。用户可通过将该值设置为 0 来删除配额。
bash
[root@ceph1 ~]# ceph osd pool set-quota pool_web max_objects 0
set-quota max_objects = 0 for pool pool_web
[root@ceph1 ~]# ceph osd pool set-quota pool_web max_bytes 0
set-quota max_bytes = 0 for pool pool_web
[root@ceph1 ~]#
[root@ceph1 ~]#
[root@ceph1 ~]# ceph osd pool get-quota pool_web
quotas for pool 'pool_web':
max objects: N/A
max bytes : N/A管理 池 配置
查看池配置
bash
# 查看池所有配置
[root@ceph1 ~]# ceph osd pool get pool_web all
size: 3
min_size: 2
pg_num: 32
pgp_num: 32
crush_rule: replicated_rule
hashpspool: true
nodelete: false
nopgchange: false
nosizechange: false
write_fadvise_dontneed: false
noscrub: false
nodeep-scrub: false
use_gmt_hitset: 1
fast_read: 0
pg_autoscale_mode: on
bulk: false
# 查看池特定配置
[root@ceph1 ~]# ceph osd pool get pool_web nodelete
nodelete: false
或
[root@ceph1 ~]# ceph osd pool get pool_web all | grep nodelete
nodelete: false设置池配置
bash
# 设置池不可删除
[root@ceph1 ~]# ceph osd pool set pool_web nodelete true
set pool 2 nodelete to true
[root@ceph1 ~]# ceph osd pool get pool_web nodelete
nodelete: true
# 将 nodelete 重新设置为 FALSE,即可允许删除池
[root@ceph1 ~]# ceph osd pool set pool_web nodelete false
set pool 2 nodelete to false
[root@ceph1 ~]# ceph osd pool get pool_web nodelete
nodelete: false管理 池 复本数
bash
# 更改池的复本数量。
[root@ceph1 ~]# ceph osd pool set pool_web size 2
set pool 2 size to 2
[root@ceph1 ~]# ceph osd pool get pool_web all
size: 2
min_size: 1
pg_num: 32
pgp_num: 32
crush_rule: replicated_rule
hashpspool: true
nodelete: false
nopgchange: false
nosizechange: false
write_fadvise_dontneed: false
noscrub: false
nodeep-scrub: false
use_gmt_hitset: 1
fast_read: 0
pg_autoscale_mode: on
bulk: false
# 池的默认复本数量
[root@ceph1 ~]# ceph config get mon osd_pool_default_size
3
# 创建新池的默认复本数量
[root@ceph1 ~]# ceph config set mon osd_pool_default_size 2
[root@ceph1 ~]# ceph config get mon osd_pool_default_size
2
# 定义池的最小复本数量
[root@ceph1 ~]# ceph config get mon osd_pool_default_min_size
0
# #参数值为0是特殊设置,意味着集群将自动使用存储池的size值作为最小副本数,举例说明:如果某存储池size=3,那么min_size会自动设为2(即size/2+1取整)
[root@ceph1 ~]# ceph config set mon osd_pool_default_min_size 1
[root@ceph1 ~]# ceph config get mon osd_pool_default_min_size
1管理 池 PG 数
bash
# 更改池 PG 数量
[root@ceph1 ~]# ceph osd pool set pool_web pg_num 64
set pool 2 pg_num to 64
[root@ceph1 ~]# ceph osd pool get pool_web all
size: 2
min_size: 1
pg_num: 64
pgp_num: 64
crush_rule: replicated_rule
hashpspool: true
nodelete: false
nopgchange: false
nosizechange: false
write_fadvise_dontneed: false
noscrub: false
nodeep-scrub: false
use_gmt_hitset: 1
fast_read: 0
pg_autoscale_mode: on
bulk: false
# Ceph 存储默认在池上配置放置组自动扩展。自动扩展允许集群计算放置组的数量,并且自动选择适当的 pg_num 值集群中的每个池都有一个 pg_autoscale_mode 选项,其值可以是 on、off 或 warn。
- on:启用自动调整池的 PG 数。
- off:禁用池的 PG 自动扩展。
- warn:在 PG 数需要调整时引发运行状况警报并将集群运行状况更改为 HEALTH_WARN。
集群配置放置组自动扩展,需要在 Ceph MGR 节点上启用 pg_autoscaler 模块,并将池的自动扩展模式设置为 on:
bash
[root@ceph1 ~]# ceph mgr module enable pg_autoscaler
module 'pg_autoscaler' is already enabled (always-on)
[root@ceph1 ~]# ceph osd pool set pool_web pg_autoscale_mode off
set pool 2 pg_autoscale_mode to off
[root@ceph1 ~]# ceph osd pool autoscale-status
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE BULK
device_health_metrics 0 3.0 179.9G 0.0000 1.0 1 on False
pool_web 0 2.0 179.9G 0.0000 1.0 64 off False
pool_era 0 2.0 179.9G 0.0000 1.0 32 on False
[root@ceph1 ~]# ceph osd pool set pool_web pg_autoscale_mode on
set pool 2 pg_autoscale_mode to on
[root@ceph1 ~]# ceph osd pool autoscale-status
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE BULK
device_health_metrics 0 3.0 179.9G 0.0000 1.0 1 on False
pool_web 0 2.0 179.9G 0.0000 1.0 64 on False
pool_era 0 2.0 179.9G 0.0000 1.0 32 on False管理 池 中对象
bash
[root@ceph1 ~]# rados -h
usage: rados [options] [commands]
POOL COMMANDS
lspools list pools
cppool <pool-name> <dest-pool> copy content of a pool
purge <pool-name> --yes-i-really-really-mean-it
remove all objects from pool <pool-name> without removing it
df show per-pool and total usage
ls list objects in pool
POOL SNAP COMMANDS
lssnap list snaps
mksnap <snap-name> create snap <snap-name>
rmsnap <snap-name> remove snap <snap-name>
OBJECT COMMANDS
get <obj-name> <outfile> fetch object
put <obj-name> <infile> [--offset offset]
......上传对象到池中
bash
#将host1文件上传到webapp池取名为hosts
[root@ceph1 ~]# echo yuxb1 > hosts1
[root@ceph1 ~]# rados -p pool_web put hosts hosts1
[root@ceph1 ~]# rados -p pool_web ls
hosts查看池中对象状态
bash
[root@ceph1 ~]# rados -p pool_web stat hosts
pool_web/hosts mtime 2025-09-29T14:34:46.000000+0800, size 6检索对象到本地
bash
[root@ceph1 ~]# rados -p pool_web get hosts newhosts
[root@ceph1 ~]# cat newhosts
yuxb1追加池中对象
bash
[root@ceph1 ~]# echo yuxb2 >> hosts2
[root@ceph1 ~]# rados append -p pool_web hosts hosts2
[root@ceph1 ~]# rados get hosts newhosts -p pool_web
[root@ceph1 ~]# cat newhosts
yuxb1
yuxb2删除池中对象
bash
[root@ceph1 ~]# rados put passwd /etc/passwd -p pool_web
[root@ceph1 ~]# rados ls -p pool_web
passwd
hosts
[root@ceph1 ~]# rados rm passwd -p pool_web
[root@ceph1 ~]# rados ls -p pool_web
hosts管理 池 快照
bash
# 创建池快照
# 给池pool_web创建快照snap1
[root@ceph1 ~]# ceph osd pool mksnap pool_web snap1
created pool pool_web snap snap1
[root@ceph1 ~]# ceph osd pool ls detail
pool 1 'device_health_metrics' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 43 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr_devicehealth
pool 2 'pool_web' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 autoscale_mode on last_change 77 lfor 0/0/71 flags hashpspool,pool_snaps stripe_width 0
snap 1 'snap1' 2025-09-29T06:38:46.960187+0000
pool 3 'pool_era' erasure profile default size 4 min_size 3 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 52 flags hashpspool stripe_width 8192
# 查看
[root@ceph1 ~]# rados -p pool_web lssnap
1 snap1 2025.09.29 14:38:46
1 snaps
# 删除池快照
[root@ceph1 ~]# ceph osd pool rmsnap pool_web snap1
removed pool pool_web snap snap1
[root@ceph1 ~]# ceph osd pool ls detail
pool 1 'device_health_metrics' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 43 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr_devicehealth
pool 2 'pool_web' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 autoscale_mode on last_change 78 lfor 0/0/71 flags hashpspool,pool_snaps stripe_width 0
pool 3 'pool_era' erasure profile default size 4 min_size 3 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 52 flags hashpspool stripe_width 8192管理 池 快照中对象
对池某个快照中对象操作需要使用-s选项指定快照名称。
bash
# 给池pool_web拍摄快照snap1
[root@ceph1 ~]# ceph osd pool mksnap pool_web snap1
created pool pool_web snap snap1
[root@ceph1 ~]# rados -p pool_web listsnaps hosts
hosts:
cloneid snaps size overlap
head - 12
# 拍摄快照后,上传新的内容到hosts中
[root@ceph1 ~]# echo yuxb3 > hosts3
[root@ceph1 ~]# rados -p pool_web put hosts hosts3
[root@ceph1 ~]# rados -p pool_web get hosts newhosts
[root@ceph1 ~]# cat newhosts
yuxb3
# 查看快照中对象
[root@ceph1 ~]# rados ls -p pool_web -s snap1
selected snap 3 'snap1'
hosts
# 获取快照中对象
[root@ceph1 ~]# rados -p pool_web -s snap1 get hosts hosts-from-snap1
selected snap 3 'snap1'
[root@ceph1 ~]# cat hosts-from-snap1
yuxb1
yuxb2
# 恢复对象内容为指定快照时内容
[root@ceph1 ~]# rados -p pool_web rollback hosts snap1
rolled back pool pool_web to snapshot snap1
[root@ceph1 ~]# rados -p pool_web get hosts newhosts
[root@ceph1 ~]# cat newhosts
yuxb1
yuxb2快照是只读文件系统,无法上传和删除快照中对象。
bash
[root@ceph1 ~]# rados put -p pool_web -s snap1 passwd /etc/passwd
selected snap 3 'snap1'
error putting pool_web/passwd: (30) Read-only file system
[root@ceph1 ~]# rados ls -p pool_web -s snap1
selected snap 3 'snap1'
hosts
[root@ceph1 ~]# rados rm -p pool_web -s snap1 hosts
selected snap 3 'snap1'
error removing pool_web>hosts: (30) Read-only file system管理 池 命名空间
Ceph可以将整个池提供给特定应用。随着应用增加,池的数量也增加。
使用命名空间,可以对池中对象进行逻辑分组,还可以限制用户只能存储或检索池中特定命名空间内的对象。借助命名空间,可以让多个应用使用同一个池,而且不必将整个池专用于各个应用,从而确保池的数量不会太多。
若要在命名空间内存储对象,客户端应用必须提供池和命名空间的名称。默认情况下,每个池包含一个具有空名称的命名空间,称为默认命名空间。
bash
[root@ceph1 ~]# rados put -p pool_web -N myns1 hostname1 /etc/hostname
[root@ceph1 ~]# rados ls -p pool_web
hosts
[root@ceph1 ~]# rados ls -p pool_web -N myns1
hostname1
# 上传的hsotname1在namespace myns1中
[root@ceph1 ~]# rados put -p pool_web -N myns2 hostname2 /etc/hostname
[root@ceph1 ~]# rados ls -p pool_web -N myns2
hostname2
# 查看全部
[root@ceph1 ~]# rados ls -p pool_web --all
myns1 hostname1
hosts
myns2 hostname2
[root@ceph1 ~]# rados ls -p pool_web --all --format=json-pretty
[
{
"namespace": "myns1",
"name": "hostname1"
},
{
"namespace": "",
"name": "hosts"
},
{
"namespace": "myns2",
"name": "hostname2"
}
]重命名池
**重命名池不会影响池中存储的数据。**如果用户重命名池,则会影响池级别的用户权限,则必须使用新的池名称来更新该用户的能力。
bash
[root@ceph1 ~]# ceph osd pool rename pool_web pool_apache
pool 'pool_web' renamed to 'pool_apache'
[root@ceph1 ~]# ceph osd lspools
1 device_health_metrics
2 pool_apache
3 pool_era
[root@ceph1 ~]#删除池
bash
# 这种方式删不掉,可能是误删除
[root@ceph1 ~]# ceph osd pool rm pool_apache
Error EPERM: WARNING: this will *PERMANENTLY DESTROY* all data stored in pool pool_apache. If you are *ABSOLUTELY CERTAIN* that is what you want, pass the pool name *twice*, followed by --yes-i-really-really-mean-it.
# 确认两次名字也不行
[root@ceph1 ~]# ceph osd pool rm pool_apache pool_apache --yes-i-really-really-mean-it
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool必须将集群级别 mon_allow_pool_delete 设置为 TRUE 才能删除池。
bash
[root@ceph1 ~]# ceph config set mon mon_allow_pool_delete true
[root@ceph1 ~]# ceph config get mon mon_allow_pool_delete
true
[root@ceph1 ~]# ceph osd pool rm pool_apache pool_apache --yes-i-really-really-mean-it
pool 'pool_apache' removed删除池会删除池中的所有数据,而且不可逆转。
可以通过设置池 nodelete 属性为 yes,防止池被误删除
bash
# ceph osd pool set pool_apache nodelete trueCeph 分布式存储 认证和授权管理
Ceph 集群身份验证
cephx 协议
Ceph 存储使用 cephx 协议管理集群认证。
Ceph 中用户帐户用途:
- Ceph 守护进程之间的内部通信。
- 客户通通过 librados 库访问集群。
- 集群管理。
账户名称
Ceph 帐户按使用主体分三类,规则清晰:
- 守护进程帐户:名与守护进程一致(如 osd.1、mgr.ceph1),安装时自动创建;
- 客户端应用帐户:带 client. 前缀(如 client.openstack 用于 OpenStack 集成,client.rgw.hostname 用于对象网关);
- 超级用户帐户:默认 client.admin,权限最高,ceph 命令默认用它,换帐户需用 --name/--id 指定。
可以设置 CEPH_ARGS 环境变量来定义用户名称或用户 ID 等参数。
示例:
bash
# export CEPH_ARGS="--id yuxb"**应用的最终用户不在 Ceph 集群中拥有帐户。**最终用户访问应用,然后由应用代表他们访问 Ceph。从 Ceph 角度来看,应用就是客户端。应用可能会通过其他机制提供自己的用户身份验证。
密钥环文件
在 Ceph 创建用户帐户时,会为每个用户自动生成对应的密钥环文件,该文件是用户身份验证的核心载体 ------ 客户端系统或应用服务器必须通过此文件验证身份,才能访问 Ceph 集群,因此需将密钥环文件复制到需要进行身份验证的目标系统上。
Ceph 查找密钥环文件的路径由 /etc/ceph/ceph.conf 配置文件中的 keyring 参数定义,默认路径规则为 /etc/ceph/$cluster.$name.keyring。例如,针对 client.openstack 这个用户帐户,其对应的密钥环文件默认路径就是 /etc/ceph/ceph.client.openstack.keyring。
需要特别注意,密钥环文件以纯文本形式存储机密密钥,存在泄露风险。因此必须通过 Linux 文件权限严格保护:仅授权需要使用该密钥的 Linux 用户访问,避免无关用户读取;同时,仅在需要用该用户身份验证的系统上部署对应的密钥环文件,不额外扩散至其他非必要设备。
指定用户身份
ceph、rados 和 rbd 等命令行工具,通过 --id 和 --keyring 选项指定要使用的用户帐户和密钥环文件。未指定时,命令会以 client.admin 用户进行身份验证。
示例:
bash
# ceph 命令会以 client.operator3 进行身份验证并列出可用池Cephx 协议通信原理
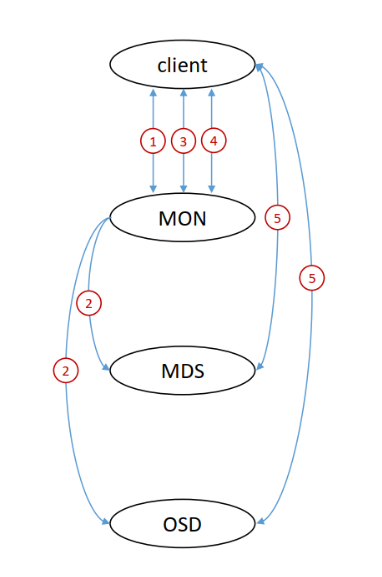
Cephx 协议是 Ceph 集群的核心身份验证与通信加密机制,基于共享机密密钥实现客户端与集群间的安全交互,核心逻辑可分为 "通信过程简化版" 与 "完整认证流程" 两部分,具体如下:
简要通信过程(核心三步)
- 客户端发起请求:客户端向监控器(MON)请求会话密钥,并同步传递自身与集群预存的 "共享秘钥",用于初步身份校验;
- 监控器加密返回会话密钥:MON 验证共享秘钥有效性后,生成会话密钥,用该共享秘钥对会话密钥加密,再将加密后的会话密钥返回给客户端;
- 客户端获取会话密钥并请求票据:客户端用自身保存的共享秘钥解密数据,得到会话密钥,随后向 MON 请求 "集群守护进程(MDS/OSD)身份验证票据",为后续与守护进程交互做准备。
完整认证流程(五步法)
- 会话密钥请求:客户端(client)主动向 MON 发送请求,申请用于后续通信的会话秘钥;
- MON 生成并同步会话密钥:MON 生成随机会话秘钥,同时将该会话秘钥同步给集群内的 MDS(元数据服务器)和 OSD(对象存储守护进程),确保三者持有相同的会话秘钥;
- 会话密钥加密传递:MON 调用客户端与集群预存的 "共享密钥",对会话密钥进行加密后返回给客户端;客户端收到后,用自身保存的共享秘钥解密,最终获取会话密钥(后续 client 与集群所有组件的通信,均通过该会话密钥加密 / 解密);
- 票据申请与生成:客户端用会话密钥加密通信内容,向 MON 请求 "身份验证票据(ticket)";MON 用会话密钥解密客户端请求,验证合法性后创建 ticket,再用会话密钥加密 ticket 并返回;客户端解密后获取 ticket;
- 客户端与守护进程交互:客户端携带 ticket 与 MDS、OSD 进行数据读写 / 元数据操作;由于 MDS、OSD 已从 MON 同步获取会话密钥,可通过验证 ticket 的合法性(用会话密钥校验),确认客户端身份,最终允许交互。
整个流程中,共享密钥仅用于 "初始会话密钥加密",后续通信均依赖 "临时会话密钥",且 MON 会提前将会话密钥同步给 MDS/OSD,既避免共享密钥频繁传输导致泄露风险,又确保集群各组件能统一验证客户端身份,保障通信安全。
管理用户账户
查看用户账户
bash
# 列出现有用户帐户
[root@ceph1 ~]# ceph auth list
osd.0
key: AQCj1dhoLcCKEBAAF/x6bP8K+RLSa7tpa+ETkw==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQCj1dhoLjOZEhAA5+0Fsz5zBvs13Hv2ilOh7w==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.2
key: AQCj1dhoRamoGhAA7zw0LS+FwN+EP9wIysJolA==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.3
key: AQCn1dho8PUcOBAAN/8je4TgJJJ7lwplSxJVoQ==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.4
key: AQCo1dhoX8xZFxAABQcOZDRsiDfn+2RhPnKy7Q==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.5
key: AQCo1dhoZGfkIBAAb5cLiGRN1pZeBebwBEWrxQ==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.6
key: AQCr1dhoIIEUOxAAmogRJzooDKNHVghWBeJZHQ==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.7
key: AQCs1dho2W7gHRAApdV1ZRvvBXNMnIye/rlPRQ==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.8
key: AQCs1dhouu2EIBAAZJXp4jPjcrsV5ejbrhcNtQ==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
client.admin
key: AQCxvtho9kx2BxAASOSGdmjTHnSikfja51jB1w==
caps: [mds] allow *
caps: [mgr] allow *
caps: [mon] allow *
caps: [osd] allow *
client.bootstrap-mds
key: AQC0vtho2+eeDRAALCbx+qChpszFKDutvG0vgA==
caps: [mon] allow profile bootstrap-mds
client.bootstrap-mgr
key: AQC0vthol/eeDRAA2CidFBQXmnunqZUuCod+bA==
caps: [mon] allow profile bootstrap-mgr
client.bootstrap-osd
key: AQC0vthoKwWfDRAA2MadMNmk8okVAwv5pZRwfQ==
caps: [mon] allow profile bootstrap-osd
client.bootstrap-rbd
key: AQC0vthoJBOfDRAAiZWeTEn7gZXacaE+BDswgg==
caps: [mon] allow profile bootstrap-rbd
client.bootstrap-rbd-mirror
key: AQC0vthofCCfDRAAdFtugz5bpdyUSsZ2sQ6dxw==
caps: [mon] allow profile bootstrap-rbd-mirror
client.bootstrap-rgw
key: AQC0vthoJS6fDRAAAsF8hFcNENLM5Ep63K4Mkg==
caps: [mon] allow profile bootstrap-rgw
client.crash.ceph1.yuxb.cloud
key: AQD2vthotNtXIRAAyQsEY3/L6bfneLBuFy4pFA==
caps: [mgr] profile crash
caps: [mon] profile crash
client.crash.ceph2.yuxb.cloud
key: AQC+1NhoVRrPJBAAuQtrErSPW2EBUifHh1Uk6g==
caps: [mgr] profile crash
caps: [mon] profile crash
client.crash.ceph3.yuxb.cloud
key: AQDR1Nhod++vNRAAO5nEaHrDKPSmq/YwqHhh/w==
caps: [mgr] profile crash
caps: [mon] profile crash
mgr.ceph1.yuxb.cloud.znbwet
key: AQCxvthoIlhQIxAAGvhdoFSIoL7yiQ5WCRkeug==
caps: [mds] allow *
caps: [mon] profile mgr
caps: [osd] allow *
mgr.ceph2.azsvel
key: AQDA1NhoMiOFMxAA4QaKIdl322FRSiZHNqPA1g==
caps: [mds] allow *
caps: [mon] profile mgr
caps: [osd] allow *
mgr.ceph3.zfnffb
key: AQBs1dhomZ7kJRAAnbmZjfOa/qoR2vTs9G3Epg==
caps: [mds] allow *
caps: [mon] profile mgr
caps: [osd] allow *
installed auth entries:
[root@ceph1 ~]#
# 获取特定帐户的详细信息
[root@ceph1 ~]# ceph auth get osd.0
[osd.0]
key = AQCj1dhoLcCKEBAAF/x6bP8K+RLSa7tpa+ETkw==
caps mgr = "allow profile osd"
caps mon = "allow profile osd"
caps osd = "allow *"
exported keyring for osd.0
# 获取特定帐户的key内容
[root@ceph1 ~]# ceph auth get-key osd.0
AQCj1dhoLcCKEBAAF/x6bP8K+RLSa7tpa+ETkw==
[root@ceph1 ~]# ceph auth print-key osd.0
AQCj1dhoLcCKEBAAF/x6bP8K+RLSa7tpa+ETkw==
[root@ceph1 ~]# ceph auth print_key osd.0
AQCj1dhoLcCKEBAAF/x6bP8K+RLSa7tpa+ETkw==
[root@ceph1 ~]#创建用户账户
bash
# 创建用户帐户
[root@ceph1 ~]# ceph auth add client.app1
added key for client.app1
[root@ceph1 ~]# ceph auth get-or-create client.app2
[client.app2]
key = AQCcO9pouND4KxAATOj2KiEC9Ip1v3RuO8ENjw==
[root@ceph1 ~]# ceph auth get-or-create-key client.app3
AQChO9podkufGhAAr9GMG2tlgOMj18WDZzcKog==
# 赋予用户账户权限
[root@ceph1 ~]# ceph auth add client.app4 mon 'allow r'
added key for client.app4删除用户账户
bash
[root@ceph1 ~]# ceph auth del client.app3
updated
[root@ceph1 ~]# ceph auth rm client.app2
updated
[root@ceph1 ~]# ceph auth ls | grep client.app
installed auth entries:
client.app1
client.app4导出和导入用户账户
bash
# 导出特定帐户的详细信息
[root@ceph1 ~]# ceph auth export osd.0 -o ceph.osd.0.keyring.1
export auth(key=AQCj1dhoLcCKEBAAF/x6bP8K+RLSa7tpa+ETkw==)
[root@ceph1 ~]# cat ceph.osd.0.keyring.1
[osd.0]
key = AQCj1dhoLcCKEBAAF/x6bP8K+RLSa7tpa+ETkw==
caps mgr = "allow profile osd"
caps mon = "allow profile osd"
caps osd = "allow *"
[root@ceph1 ~]# ceph auth get osd.0 -o ceph.osd.0.keyring.2
exported keyring for osd.0
[root@ceph1 ~]# cat ceph.osd.0.keyring.2
[osd.0]
key = AQCj1dhoLcCKEBAAF/x6bP8K+RLSa7tpa+ETkw==
caps mgr = "allow profile osd"
caps mon = "allow profile osd"
caps osd = "allow *"
# 导入特定帐户的详细信息
# 先导出client.app4然后删除client.app4
[root@ceph1 ~]# ceph auth export client.app4 -o ceph.client.app4.keyring
export auth(key=AQCzO9poS2xxMxAAm/mJ5vPSQ1Lioe3+9EHutA==)
[root@ceph1 ~]# ceph auth rm client.app4
updated
[root@ceph1 ~]# ceph auth get client.app4
Error ENOENT: failed to find client.app4 in keyring
# 将刚才删除的client.app4导入观察现象
[root@ceph1 ~]# ceph auth import -i ceph.client.app4.keyring
imported keyring
[root@ceph1 ~]# ceph auth get client.app4
[client.app4]
key = AQCzO9poS2xxMxAAm/mJ5vPSQ1Lioe3+9EHutA==
caps mon = "allow r"
exported keyring for client.app4配置用户账户功能
用户账户功能
Cephx 中的权限称为 "功能",用于控制对池数据、命名空间或守护进程的访问,按守护进程类型(mon、osd、mgr、mds)授予,核心功能及作用如下:
- allow:作为权限前缀,用于定义后续权限范围。
- r:读取权限。用户至少需在监控器(mon)上有此权限,以获取 CRUSH 映射。
- w:写入权限。客户端需此权限在 OSD 上存储 / 修改对象;管理器(mgr)有此权限可启用 / 禁用模块。
- x :执行权限。允许调用对象类方法(如读写操作)、对监控器进行身份验证,支持
rados lock get等扩展操作。 - class-read/class-write:x 的子集,分别允许调用类的读写方法,常用于 RBD 池。
- *****:完全访问权限,包含读写执行及管理命令权限。
可通过 ceph auth caps 命令为已创建的用户账户分配功能。
示例:
bash
[root@ceph1 ~]# ceph auth add client.yuxb
added key for client.yuxb
[root@ceph1 ~]# ceph auth caps client.yuxb mon 'allow r' osd 'allow rw'
updated caps for client.yuxb
# 创建用户账户时,直接赋予权限。
[root@ceph1 ~]# ceph auth add client.yuxb mon 'allow r' osd 'allow rw'
[root@ceph1 ~]# ceph auth get client.yuxb
[client.yuxb]
key = AQAEP9pozo/5KhAAXleSQloDfIqq4fcgTh6ISw==
caps mon = "allow r"
caps osd = "allow rw"
exported keyring for client.yuxb用户账户功能配置文件
创建用户帐户时,可使用cephx 预定义的功能配置文件:
- 简化用户访问权限配置。
- 实现守护进程之间的内部通信。
- Ceph 会在内部定义这些文件,用户无法自行创建配置文件。
cephx 预定义的部分功能配置文件如下:
-
osd,授予用户作为 OSD 连接其他 OSD 或监控器的权限, 以便 OSD 能够 处理复制心跳流量和状态报告。
bash[root@ceph1 ~]# ceph auth get osd.1 [osd.1] key = AQCj1dhoLjOZEhAA5+0Fsz5zBvs13Hv2ilOh7w== caps mgr = "allow profile osd" caps mon = "allow profile osd" caps osd = "allow *" exported keyring for osd.1 -
bootstrap-osd,授予用户引导 OSD 的权限,以便他们在引导 OSD 时具有添加密钥的权限。
bash[root@ceph1 ~]# ceph auth get client.bootstrap-osd [client.bootstrap-osd] key = AQC0vthoKwWfDRAA2MadMNmk8okVAwv5pZRwfQ== caps mon = "allow profile bootstrap-osd" exported keyring for client.bootstrap-osd -
rbd,授予用户读写访问 Ceph 块设备的权限。
-
rbd-read-only,授予用户只读访问 Ceph 块设备的权限。
示例:
bash
[root@ceph1 ~]# ceph auth add client.forrbd mon 'profile rbd' osd 'profile rbd'
added key for client.forrbd
[root@ceph1 ~]# ceph auth get client.forrbd
[client.forrbd]
key = AQC0Qdpo4Aj/OhAAD00vs1rlXbYkJRF6uh/PGQ==
caps mon = "profile rbd"
caps osd = "profile rbd"
exported keyring for client.forrbd限制访问范围
Ceph 中可通过多种方式限制用户访问范围,精准控制权限边界:
- 按池限制 :仅允许访问指定池,不指定则默认所有池。示例:创建
client.formyapp1,赋予监控器读权限,及myapp池的读写权限。
bash
[root@ceph1 ~]# ceph auth get-or-create client.formyapp1 mon 'allow r' osd 'allow rw pool=myapp'
[client.formyapp1]
key = AQAWQtpoOkiDBxAAjbxeyI6i5OZwzJfwgmLBnQ==
[root@ceph1 ~]#- 按命名空间限制 :仅允许访问特定命名空间对象。示例:
client.formyapp2只能访问photos命名空间。
bash
[root@ceph1 ~]# ceph auth get-or-create client.formyapp2 mon 'allow r' osd 'allow rw namespace=photos'
[client.formyapp2]
key = AQAgQtpoXKNuARAAwWEiKxRFRqlsGYhbeiuBZg==- 池 + 命名空间组合限制 :同时限定池和命名空间。示例:
client.formyapp3仅能访问myapp池的photos命名空间。
bash
[root@ceph1 ~]# ceph auth get-or-create client.formyapp3 mon 'allow r' osd 'allow rw pool=myapp namespace=photos'
[client.formyapp3]
key = AQA0QtpoG1ZzMBAAkw/pfB0/hE15EkzbDu7YjA==- 按对象名称前缀限制 :仅允许访问特定前缀的对象。示例:
client.formyapp4可访问前缀为pref的对象。
bash
[root@ceph1 ~]# ceph auth get-or-create client.formyapp4 mon 'allow r' osd 'allow rw object_prefix pref'
[client.formyapp4]
key = AQBJQtposcbVKRAAUwWnXtrjZFlVdoUQ6GDuPg==- 按文件路径限制(CephFS) :限定 Ceph 文件系统特定目录。示例:
client.webdesigner仅能访问/webcontent目录,拥有读写权限。
bash
# ceph fs authorize cephfs client.webdesigner /webcontent rw - 按监控器命令限制 :仅允许执行特定监控器命令。示例:
client.operator1可执行auth get-or-create和auth list命令。
bash
[root@ceph1 ~]# ceph auth get-or-create client.operator1 mon 'allow r, allow command "auth get-or-create", allow command "auth list"'
[client.operator1]
key = AQD/Q9pogZN3OBAAMkvq1Q9eAD4BkzdxNKq4Ng==实践示例:
1、创建可执行 ceph auth list 的用户
生成 client.gaoqiaodong 并赋予对应权限,导出密钥环文件后,使用该用户执行 ceph auth list 可成功查看授权信息。
bash
[root@ceph1 ~]# ceph auth get-or-create client.yuxb mon 'allow r,allow command "auth list"'
[client.yuxb]
key = AQD1RNpoNXqFNRAAWESpSEERikUqZkRN9bMDxA==
[root@ceph1 ~]# ceph auth get client.yuxb -o /etc/ceph/ceph.client.yuxb.keyring
exported keyring for client.yuxb
[root@ceph1 ~]# ceph auth ls --id yuxb
Error EACCES: access denied
[root@ceph1 ~]# ceph auth list --id yuxb
osd.0
key: AQCj1dhoLcCKEBAAF/x6bP8K+RLSa7tpa+ETkw==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQCj1dhoLjOZEhAA5+0Fsz5zBvs13Hv2ilOh7w==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.2
......2、通过客户端管理 Ceph
在客户端安装 ceph-common,从 Ceph 节点拷贝 ceph.client.admin.keyring 和 ceph.conf 到客户端,即可用 ceph -s 等命令管理集群。
bash
# client
[root@client ~]# mkdir /etc/ceph
[root@client ~]# dnf install -y ceph-common
# ceph1
# 将/etc/ceph/ceph.client.admin.keyring拷贝到client
# 将/etc/ceph.conf拷贝到cleint
[root@ceph1 ~]# scp /etc/ceph/ceph.client.admin.keyring root@client:/etc/ceph/
The authenticity of host 'client (192.168.108.10)' can't be established.
ECDSA key fingerprint is SHA256:FPYe2LYas2LxQYQs/Uy7j6s8oD02rVjtJYf/BS/95Go.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added 'client,192.168.108.10' (ECDSA) to the list of known hosts.
root@client's password:
ceph.client.admin.keyring 100% 151 136.5KB/s 00:00
[root@ceph1 ~]# scp /etc/ceph/ceph.conf root@client:/etc/ceph/
root@client's password:
ceph.conf 100% 283 298.8KB/s 00:00
# client
[root@client ~]# ceph -s
cluster:
id: b40700ee-9c26-11f0-8c1f-000c29463e75
health: HEALTH_WARN
Degraded data redundancy: 32 pgs undersized
services:
mon: 3 daemons, quorum ceph1.yuxb.cloud,ceph2,ceph3 (age 7h)
mgr: ceph2.azsvel(active, since 7h), standbys: ceph1.yuxb.cloud.znbwet, ceph3.zfnffb
osd: 9 osds: 9 up (since 7h), 9 in (since 26h)
data:
pools: 2 pools, 33 pgs
objects: 3 objects, 0 B
usage: 2.6 GiB used, 177 GiB / 180 GiB avail
pgs: 32 active+undersized
1 active+cleanosd
caps: osd allow *
osd.2
...
2、通过客户端管理 Ceph
在客户端安装 `ceph-common`,从 Ceph 节点拷贝 `ceph.client.admin.keyring` 和 `ceph.conf` 到客户端,即可用 `ceph -s` 等命令管理集群。
```bash
# client
[root@client ~]# mkdir /etc/ceph
[root@client ~]# dnf install -y ceph-common
# ceph1
# 将/etc/ceph/ceph.client.admin.keyring拷贝到client
# 将/etc/ceph.conf拷贝到cleint
[root@ceph1 ~]# scp /etc/ceph/ceph.client.admin.keyring root@client:/etc/ceph/
The authenticity of host 'client (192.168.108.10)' can't be established.
ECDSA key fingerprint is SHA256:FPYe2LYas2LxQYQs/Uy7j6s8oD02rVjtJYf/BS/95Go.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added 'client,192.168.108.10' (ECDSA) to the list of known hosts.
root@client's password:
ceph.client.admin.keyring 100% 151 136.5KB/s 00:00
[root@ceph1 ~]# scp /etc/ceph/ceph.conf root@client:/etc/ceph/
root@client's password:
ceph.conf 100% 283 298.8KB/s 00:00
# client
[root@client ~]# ceph -s
cluster:
id: b40700ee-9c26-11f0-8c1f-000c29463e75
health: HEALTH_WARN
Degraded data redundancy: 32 pgs undersized
services:
mon: 3 daemons, quorum ceph1.yuxb.cloud,ceph2,ceph3 (age 7h)
mgr: ceph2.azsvel(active, since 7h), standbys: ceph1.yuxb.cloud.znbwet, ceph3.zfnffb
osd: 9 osds: 9 up (since 7h), 9 in (since 26h)
data:
pools: 2 pools, 33 pgs
objects: 3 objects, 0 B
usage: 2.6 GiB used, 177 GiB / 180 GiB avail
pgs: 32 active+undersized
1 active+clean