环境准备
- IDEA 必须
- git 必须
- maven 必须
- jdk 1.8+ 必须
- scala 2.12.7
源码下载
如果能访问github,下载github的源码(flink的代码托管网站)
git clone https://github.com/apache/flink.git如果不能访问github,可以通过码云下载(国内的代码托管平台)
git clone https://gitee.com/apache/flink.gitflink tag出来的分支是release出来的版本,本次使用flink 1.19.1的tag,查看所有tag
git tag check out出来1.19.1的tag
#从tagrelease-1.19.1 创建新的本地分支release-1.19.1_my
git checkout release-1.19.1 -b release-1.19.1_myIDEA打开Flink项目
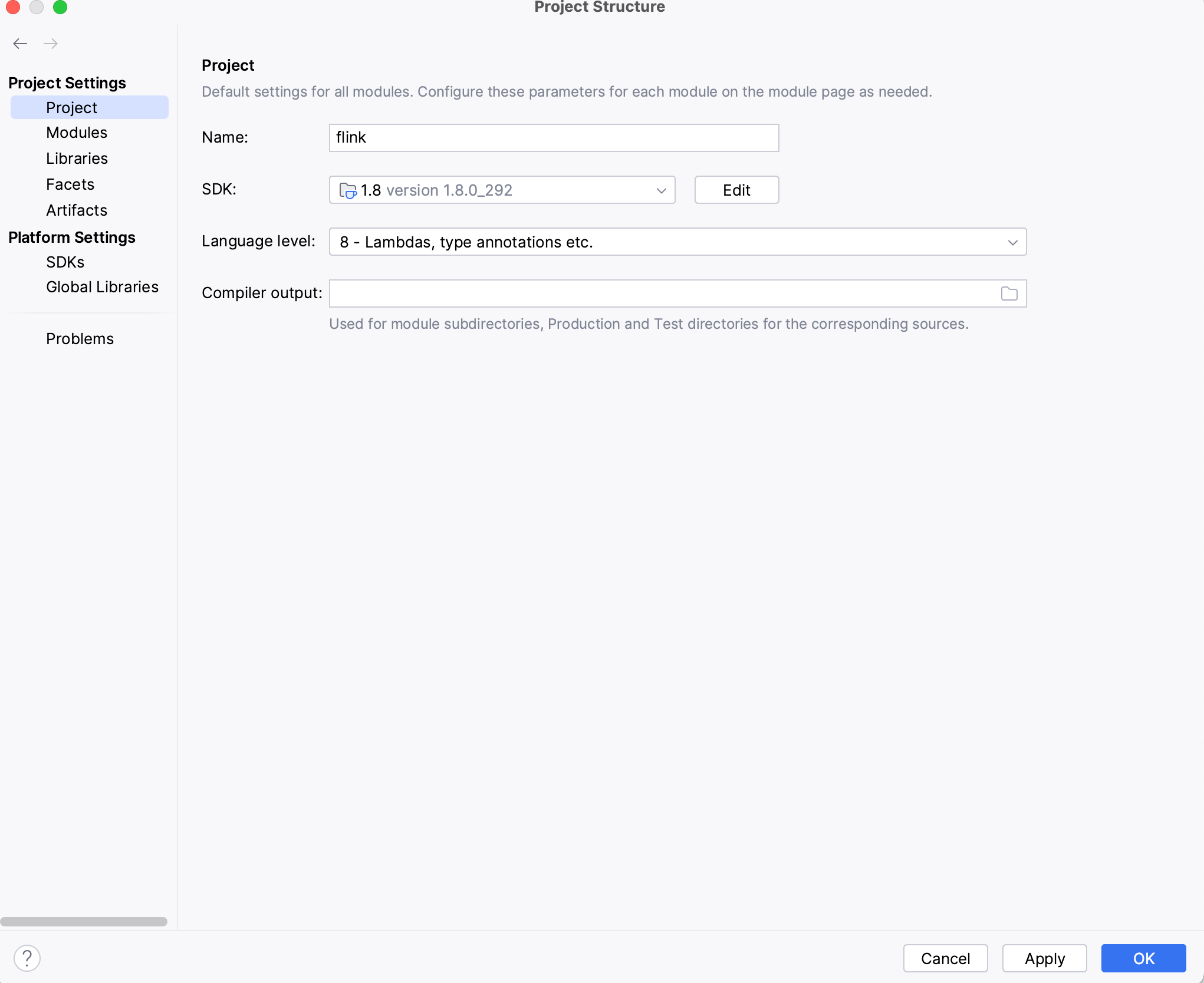
设置JDK版本
点击File---> Project Structure--->Project设置Jdk版本(如下图),jdk版本设置1.8或者1.8之后的版本
设置scala版本
点击File---> Project Structure--->Platfrom Settings ---> Global Libraries--->ScalaSdk 设置scala版本(如下图)
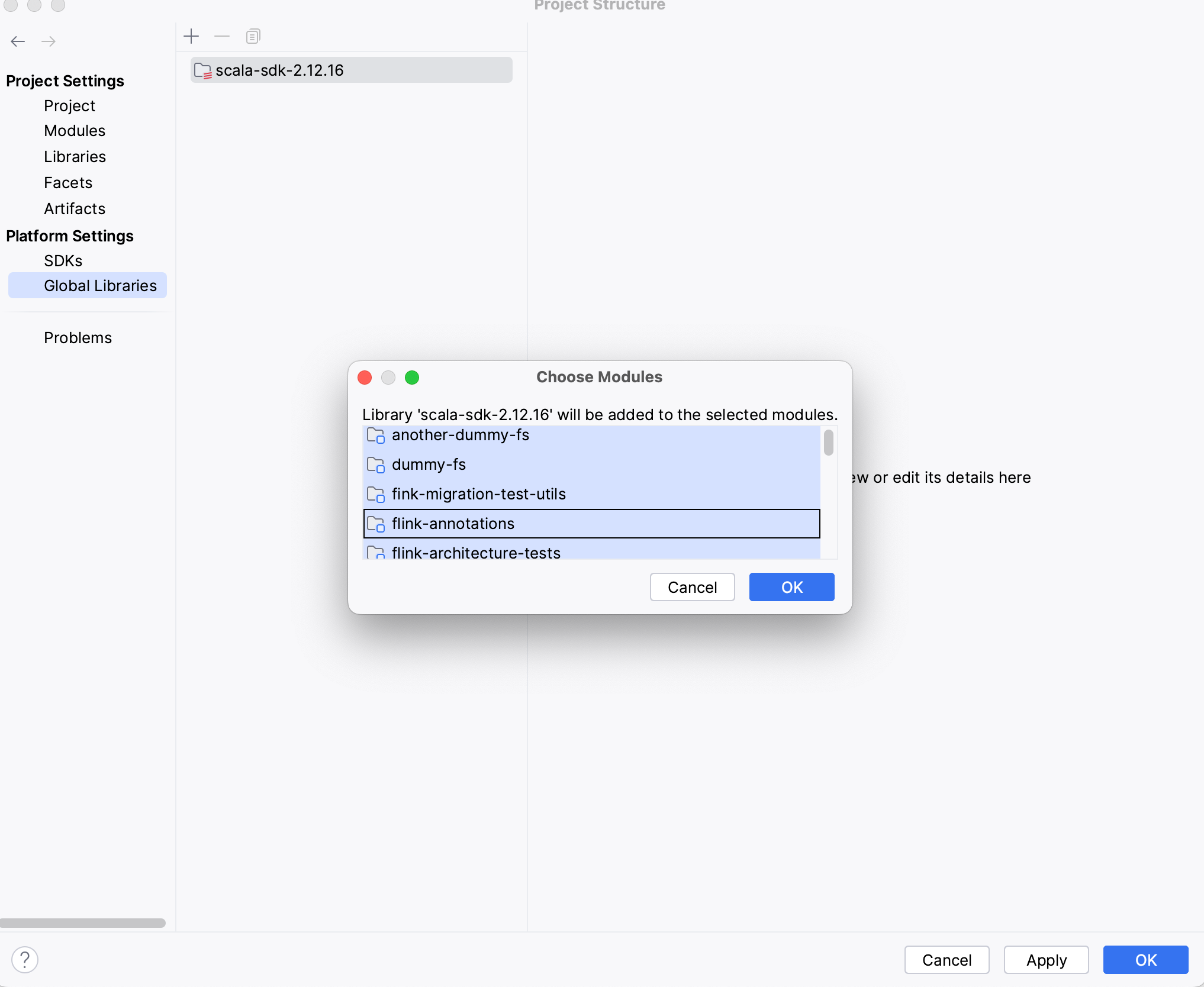
添加scala sdk,然后选中所有的模块
源码编译
1.跳过测试
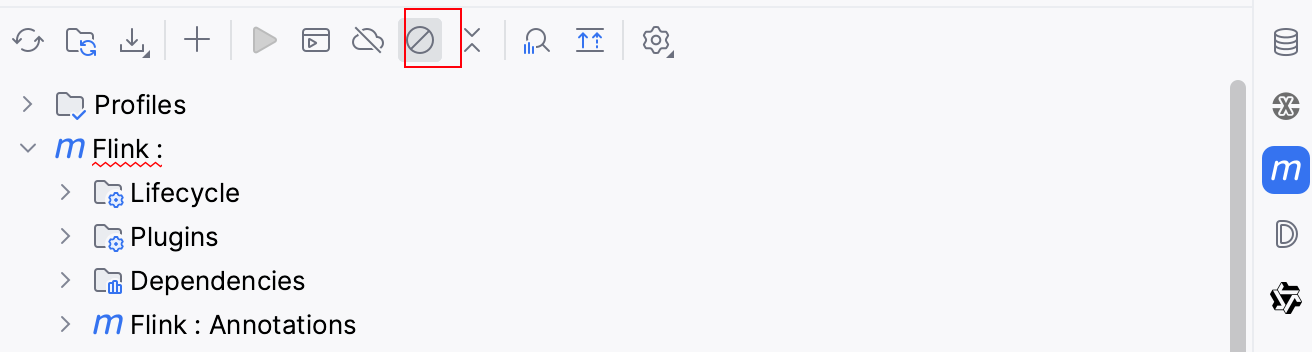
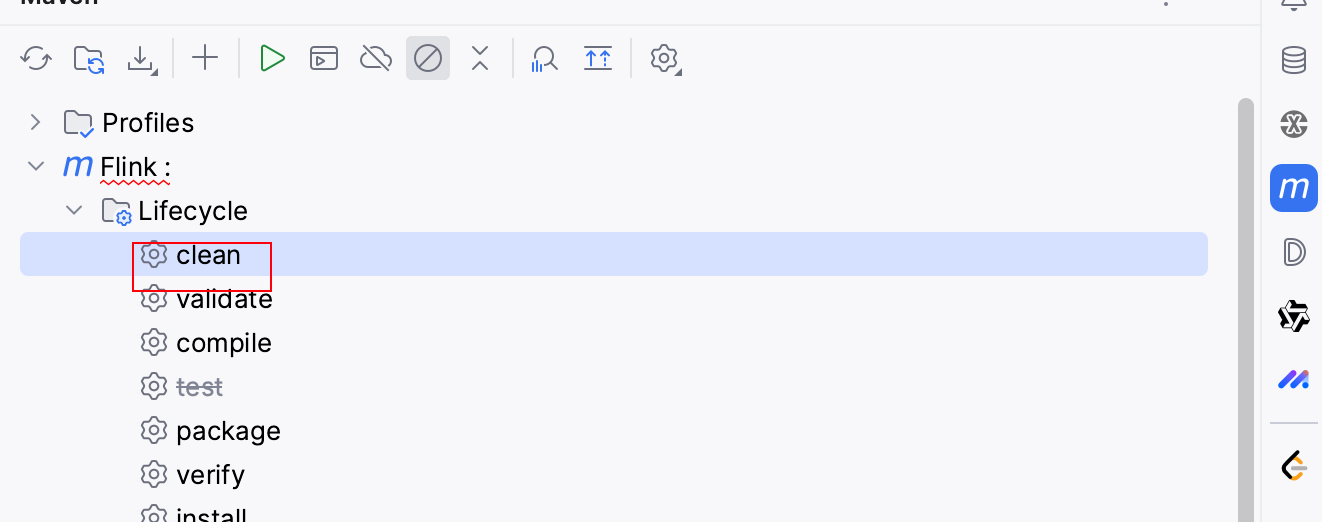
2.clean
3.install
然后就等待install结束,最后每个模块都是success,则install成功,就会出现flink的bin包,包含flink的lib和conf等
如果install失败,可以直接去flink官网下载对应的二进制包(Apache Download Mirrors)
编译或者下载flink二进制包解压后的目录如下
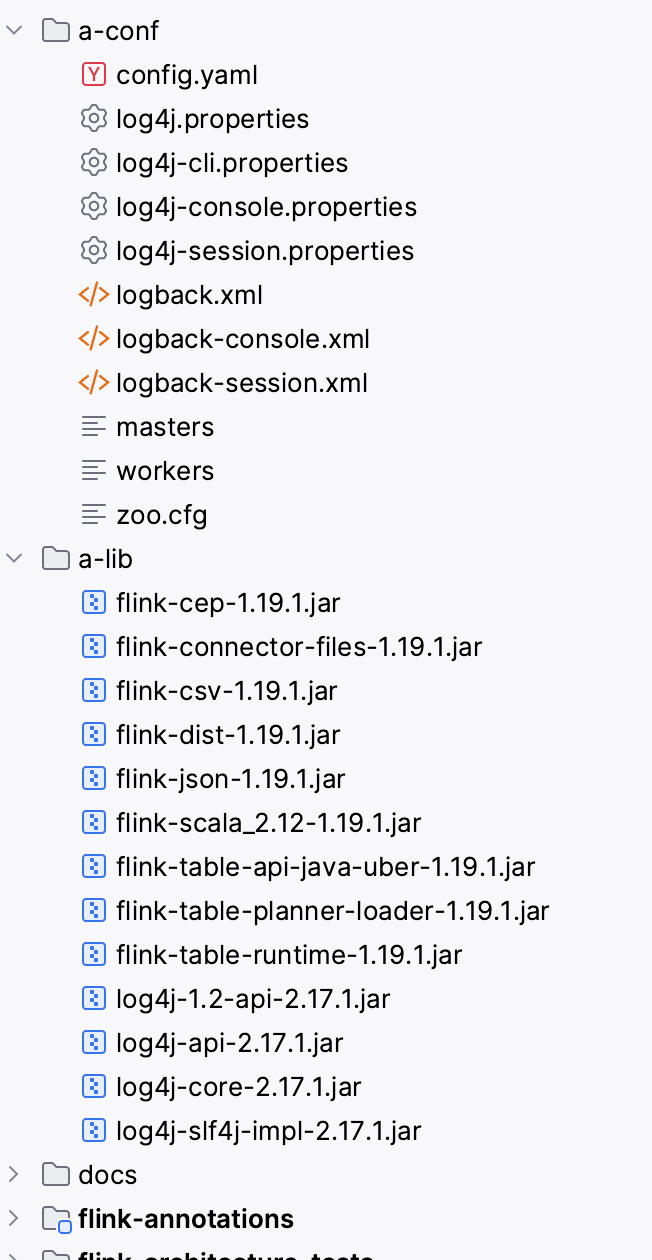
在本地创建a-lib和a-conf两个目录,便于后续使用
- a-lib:将flink二进制包目录下的lib的包复制到该目录下
- a-conf:将flink二进制包目录下的conf下文件复制到该目录下
本地运行
修改配置
修改a-conf下的config.yaml
################################################################################
env.java.opts.all: --add-exports=java.base/sun.net.util=ALL-UNNAMED --add-exports=java.rmi/sun.rmi.registry=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.api=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.file=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.parser=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.tree=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.util=ALL-UNNAMED --add-exports=java.security.jgss/sun.security.krb5=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.net=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/java.lang.reflect=ALL-UNNAMED --add-opens=java.base/java.text=ALL-UNNAMED --add-opens=java.base/java.time=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.base/java.util.concurrent=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.atomic=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.locks=ALL-UNNAMED
jobmanager.resource-id: q1
jobmanager.rpc.address: localhost
# The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6123
jobmanager.bind-host: localhost
jobmanager.memory.process.size: 1600m
taskmanager.bind-host: localhost
taskmanager.resource-id: q2
#唯一标识 window下必须配置
taskmanager.cpu.cores: 1
#任务的堆内存
taskmanager.memory.task.heap.size: 512m
#托管内存
taskmanager.memory.managed.size: 512m
#网络内存(Network Memory)
taskmanager.memory.network.min: 128m
taskmanager.memory.network.max: 128m
#任务堆外内存
taskmanager.memory.task.off-heap.size: 0m
#框架内存
taskmanager.memory.framework.heap.size: 256m
#框架堆外内存
taskmanager.memory.framework.off-heap.size: 128m
#JVM Metaspace
taskmanager.memory.jvm-metaspace.size: 128m
#JVM 开销
taskmanager.memory.jvm-overhead.min: 128m
taskmanager.memory.jvm-overhead.max: 128m
#心跳参数
heartbeat.timeout: 50000
heartbeat.interval: 10000
taskmanager.host: localhost
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 1
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
jobmanager.execution.failover-strategy: region
rest.address: localhost
rest.bind-address: localhost启动JobManager
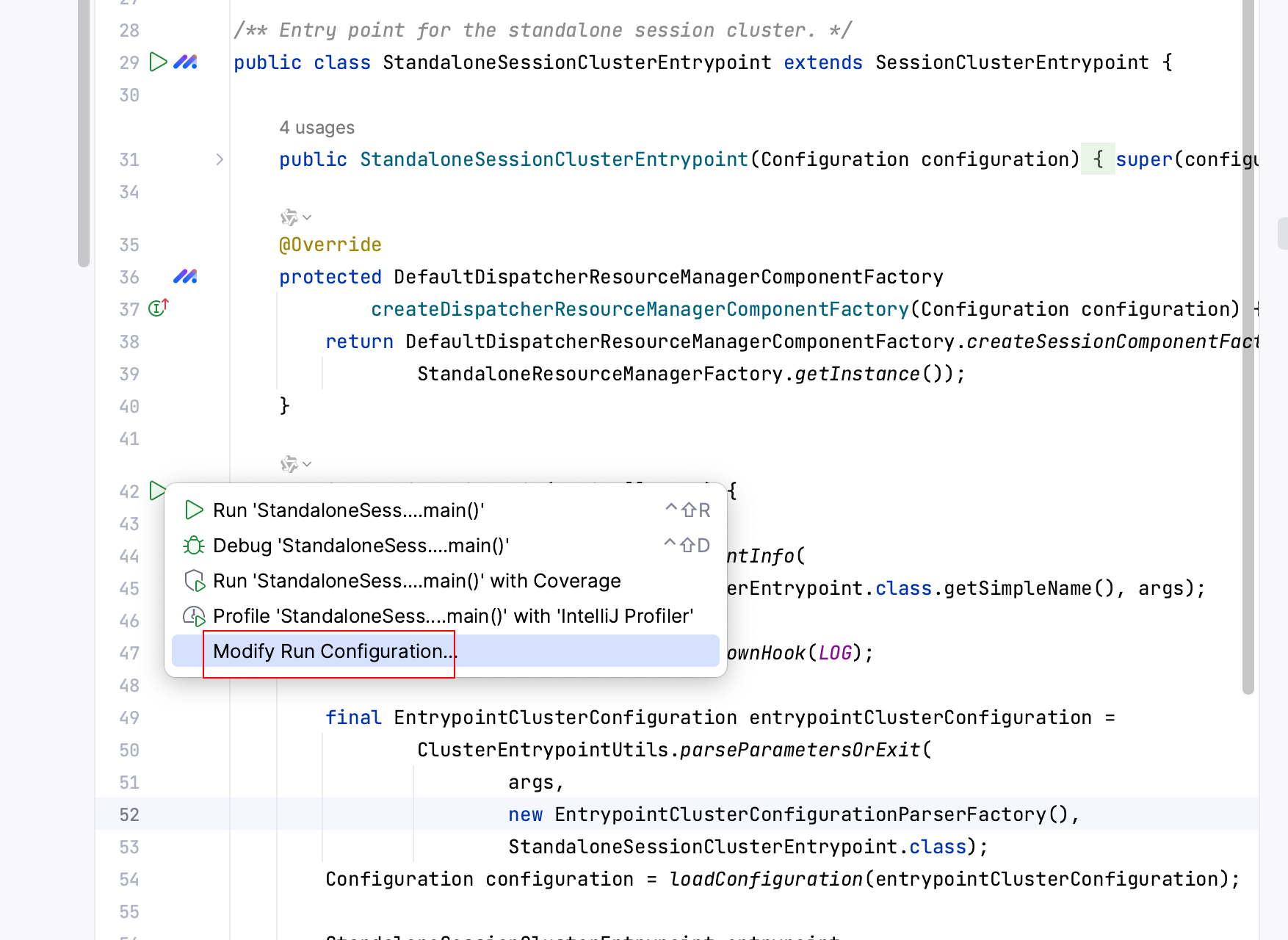
1.搜索 StandaloneSessionClusterEntrypoint类
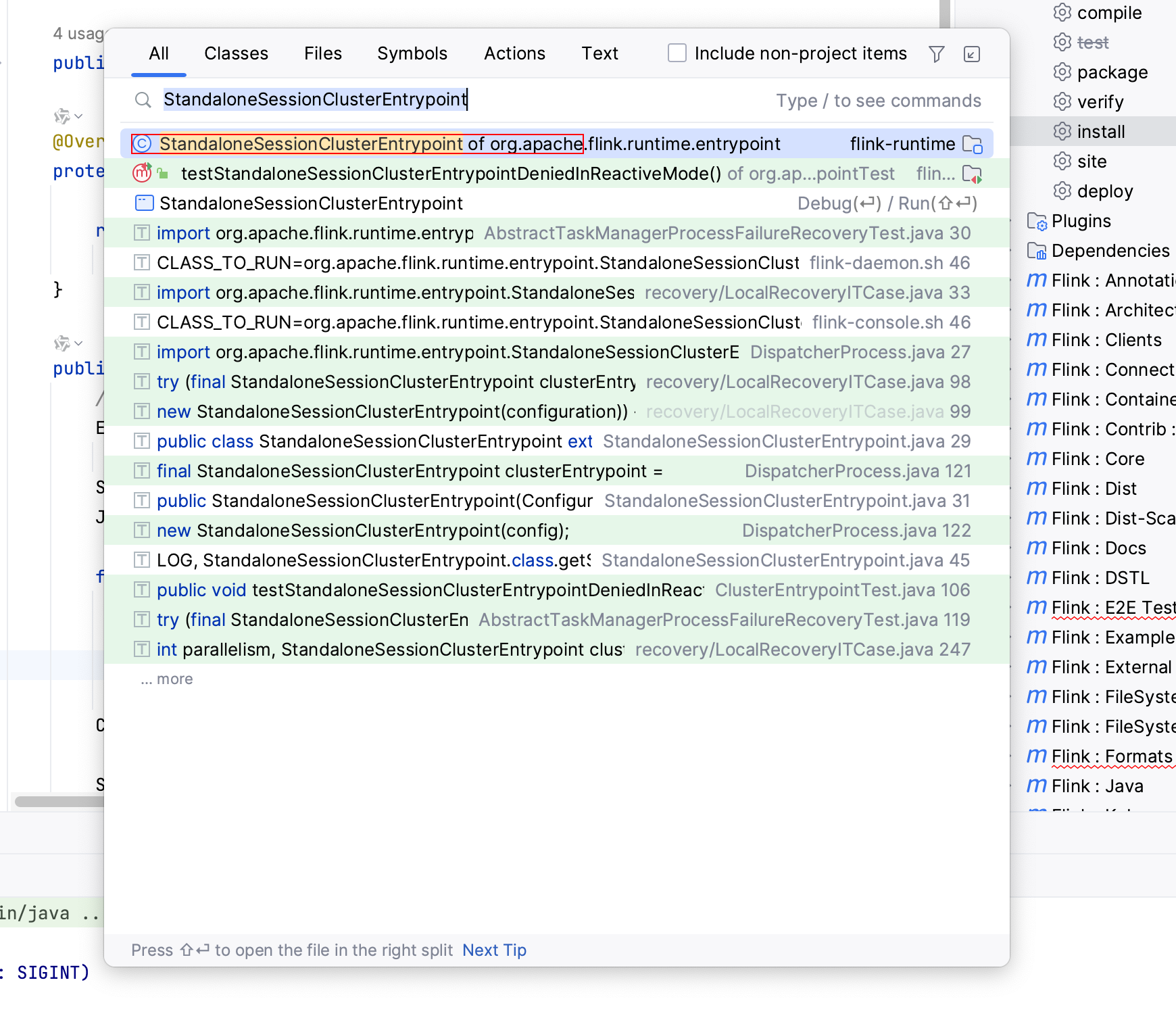
2.设置参数 右键选择Modify Run Configuration
3.配置启动参数
-c a-conf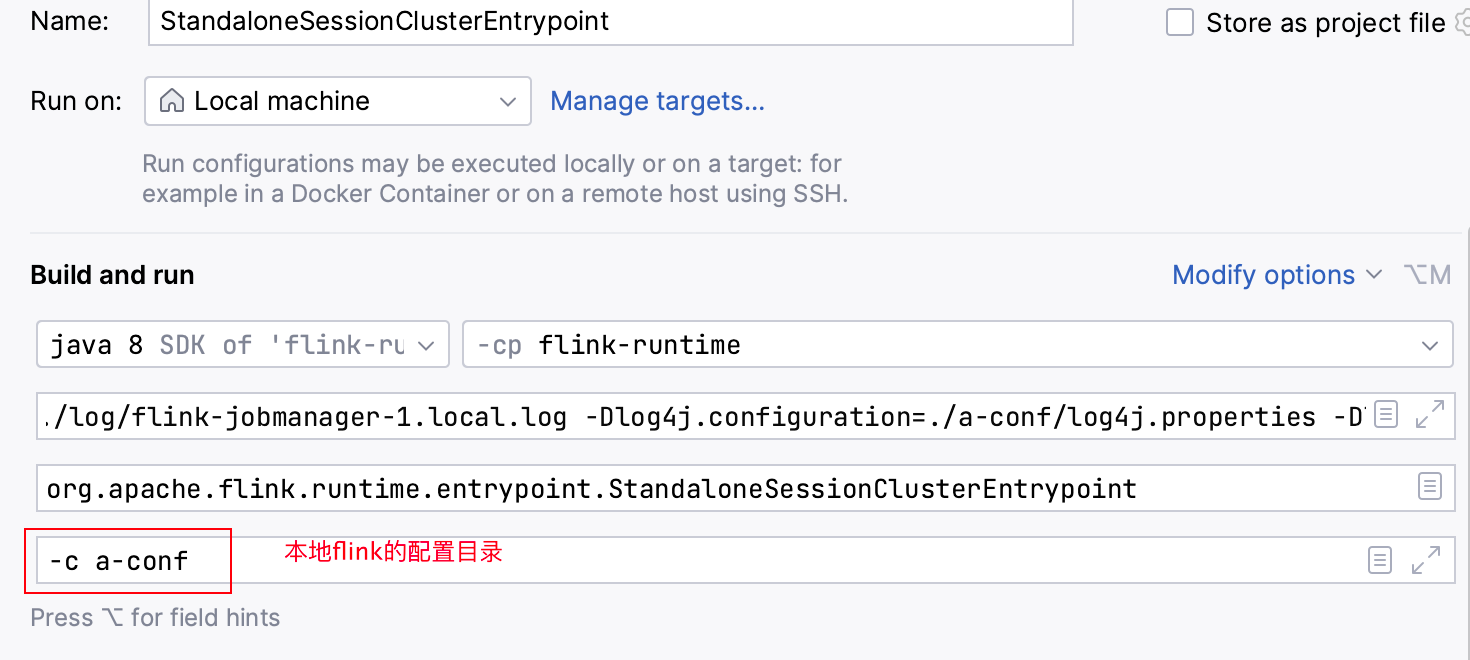
4.添加jvm参数
-Dlog.file=./log/flink-jobmanager-1.local.log
-Dlog4j.configuration=./a-conf/log4j.properties
-Dlog4j.configurationFile=./a-conf/log4j.properties
-Dlogback.configurationFile=./a-conf/logback.xml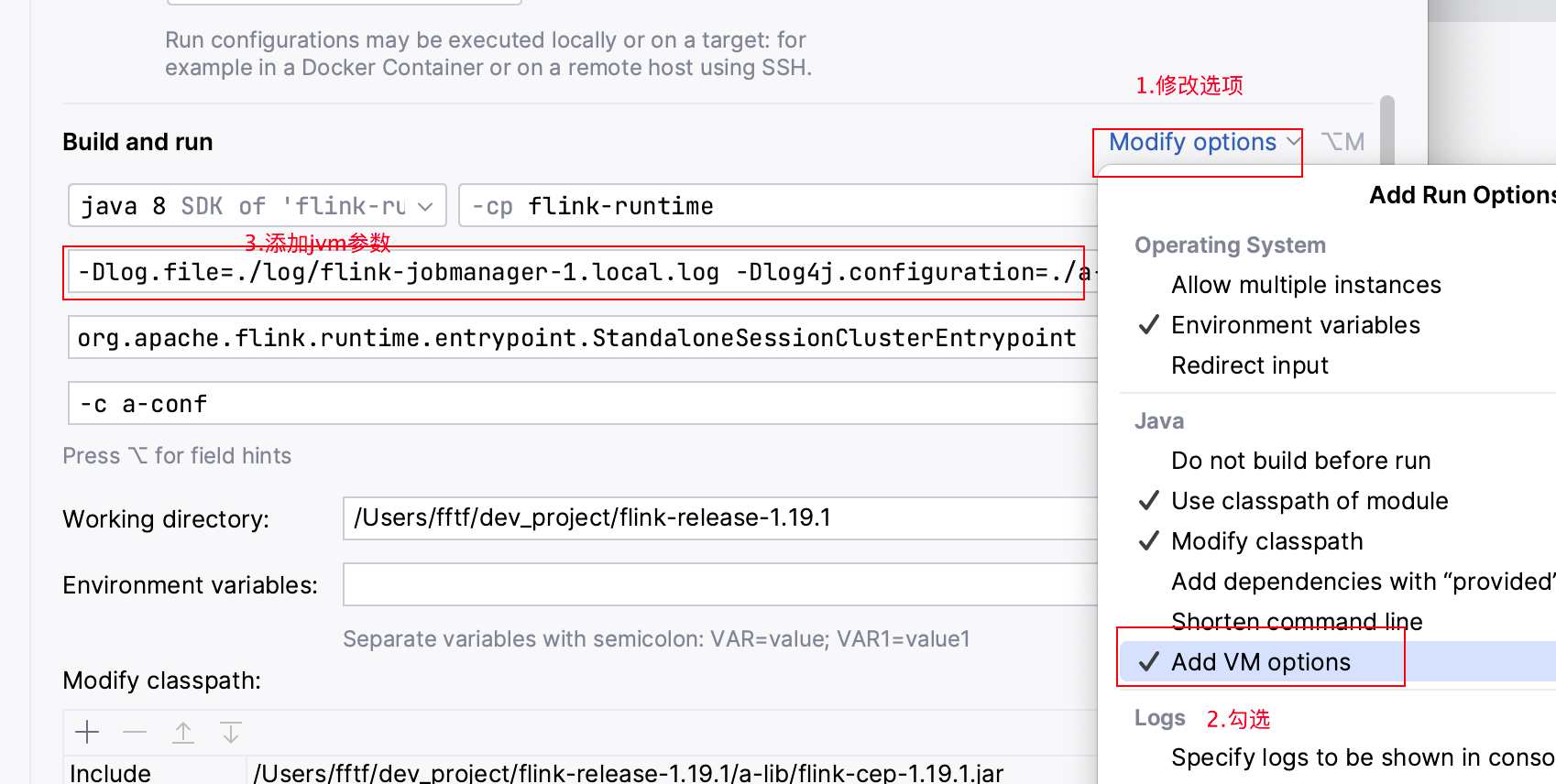
5.添加需要用到lib
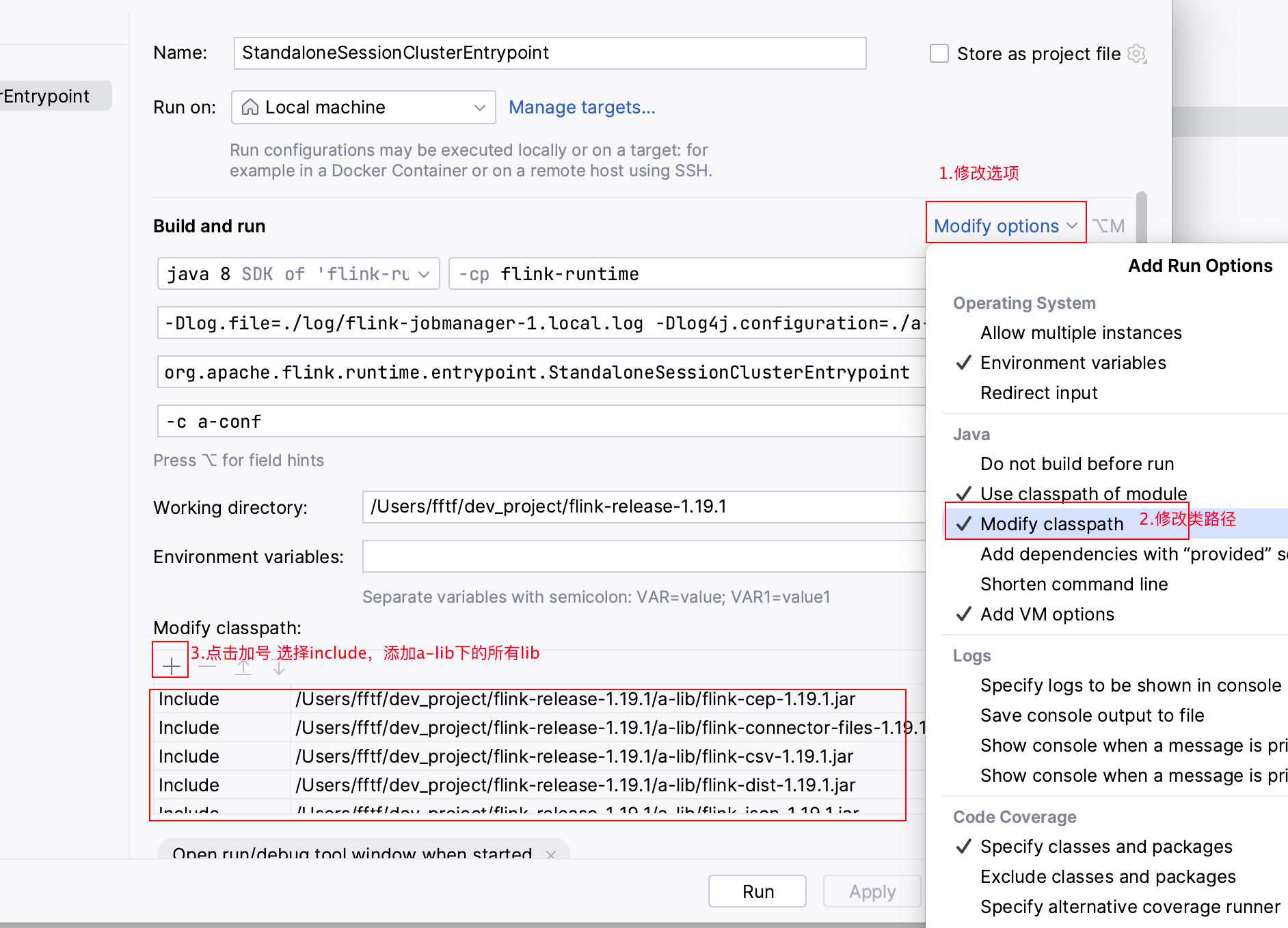
6.启动JobManager

7.验证
http://localhost:8081/#/job-manager/metrics
启动TaskManager
1.搜索TaskManagerRunner
2.找到TaskManagerRunner main方法,右键Modify Run Configuration
3.配置启动参数,和JobManager配置一样
4.添加jvm参数
-Dlog.file=./log/flink-taskmanager-1.local.log
-Dlog4j.configuration=./a-conf/log4j.properties
-Dlog4j.configurationFile=./a-conf/log4j.properties
-Dlogback.configurationFile=./a-conf/logback.xml5.添加需要用到lib,操作步骤和JobManager一致
6.启动TaskManagr
7.验证
