继承

什么是继承?
继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许我们在保持原有类特性的基础上进行扩展,增加方法(成员函数)和属性(成员变量),这样产生新的类,称为子类,或派生类。
继承呈现了面向对象程序设计的层次结构,体现了由简单到复杂的认知过程。以前我们接触的是函数层次的复用,而++继承是类设计层次的复用++。
下面我们看到没有继承之前我们设计了两个类Student和Teacher,Student和Teacher都有姓名/地址/ 电话/年龄等成员变量,都有identity身份认证的成员函数,设计到两个类里面就是冗余 的。当然他们也有++一些不同的++成员变量和函数,比如老师独有成员变量是职称,学生的独有成员变量是学号;学生的独有成员函数是学习,老师的独有成员函数是授课。
c++
class Student
{
public:
// 进⼊校园/图书馆/实验室刷⼆维码等⾝份认证
void identity()
{
// ...
}
// 学习
void study()
{
// ...
}
protected:
string _name = "peter"; // 姓名
string _address; // 地址
string _tel; // 电话
int _age = 18; // 年龄
int _stuid; // 学号
};
class Teacher
{
public:
// 进⼊校园/图书馆/实验室刷⼆维码等⾝份认证
void identity()
{
// ...
}
// 授课
void teaching()
{
//...
}
protected:
string _name = "张三"; // 姓名
int _age = 18; // 年龄
string _address; // 地址
string _tel; // 电话
string _title; // 职称
};
int main()
{
return 0;
}
我们可以将公共的成员都放到Person类中,Student和teacher都继承Person,就可以复用这些成员,就不需要重复定义了,省去了很多麻烦。
c++
class Person
{
public:
// 进⼊校园/图书馆/实验室刷⼆维码等⾝份认证
void identity()
{
cout << "void identity()" <<_name<< endl;
}
protected:
string _name = "张三"; // 姓名
string _address; // 地址
string _tel; // 电话
int _age = 18; // 年龄
};
class Student : public Person
{
public:
// 学习
void study()
{
// ...
}
protected:
int _stuid; // 学号
};
class Teacher : public Person
{
public:
// 授课
void teaching()
{
//...
}
protected:
string title; // 职称
};
int main()
{
Student s;
Teacher t;
s.identity();
t.identity();
return 0;
}继承的定义
格式
下面我们看到Person是基类,也称作⽗类。Student是派生类,也称作子类。(因为翻译的原因,所以既叫基类/派⽣类,也叫⽗类/子类)

我们来讲讲这个继承方式,它类似于我们以前学的访问限定符。
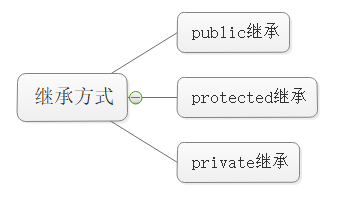
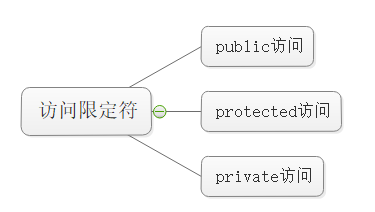
父类中不同访问限定符下的成员在不同的继承方式后会变成什么成员?

-
基类private成员在派⽣类中无论以什么方式继承都是不可见的。这里的不可见是指基类的私有成员还是++被继承到了++ 派生类对象中,但是语法上限制派生类对象不管在类里面还是类外面都不能去访问它。
-
基类private成员在派生类中是不能被访问,如果基类成员++不想在类外直接被访问,但需要在派生类中能访问,就定义为protected。++ ++可以看出保护成员限定符是因继承才出现的。++
-
实际上面的表格我们进行⼀下总结会发现,基类的私有成员在派生类都是不可见。基类的其他成员派生类的访问方式==Min(成员在基类的访问限定符,继承方式),public >protected> private。通俗地说,就是取小的那个权限。
-
使用关键字class时默认的继承方式是private,使用struct时默认的继承方式是public,不过最好显式的写出继承方式。
-
++在实际运用中一般使用都是public继承++,⼏乎很少使⽤protetced/private继承,也并不提倡使用 protetced/private继承,因为protetced/private继承下来的成员都只能在派生类的类里面使⽤,实际中扩展维护性不强。
以上是普通类的继承,现在我们来看看类模板的继承。
继承类模版
比如我们要实现一个栈,此前我们的方式是通过一个模版参数可以去换底层的适配器,vector,list,deque。
而另一种方式实现栈就是继承,用栈去继承vector。(我们原本的方式叫做组合)
c++
namespace momo
{
template<class T>
class stack : public std::vector<T>
{
public:
void push(const T& x)
{
push_back(x);
//......
};
}
int main()
{
momo::stack<int> st;
st.push(1);
st.push(2);
st.push(3);
return 0;
}但是这样我们会编译报错:
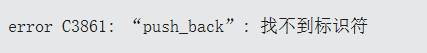
普通的类的继承不存在这样的问题,在上面我们的s.identity(); ,子类对象调用父类中的函数,并没有报错。
或者我们也一样在子类的成员函数中去调用父类函数:
c++
class Person
{
public:
void identity()
{
cout << "void identity()" << _name << endl;
}
protected:
string _name = "张三";
string _address;
string _tel;
int _age = 18;
};
class Teacher : public Person
{
public:
void teaching()
{
identity();//不会有问题
}
protected:
string title;
};但是我们类模板的栈想要去复用vector的成员函数时,却调不动,或者说找不到。这是由于按需实例化。
momo::stack<int> st;实例化了stack,把 template<class T>的T实例化为了int,所以 class stack : public std::vector<T>相当于把vector实例化了,但是根据按需实例化,我们此时++不会把vector中所有的成员都实例化。++
更具体地说,momo::stack<int> st;只会实例化栈的构造函数,同时也实例化了vector的构造函数,但不会实例化其他。
所以我们需要进行指定:vector::push_back(x);
所以总之,父类是类模板时,需要指定一下类域。
我们可以把vector改成list,此时我们的栈就是list实例化出来的。
按需实例化
我们可以做一个简单的回忆。
假如我们现在有一个类A,如果构造函数有问题,比如这里我们调用一个并不存在的函数func(),马上就能检查出来:
c++
template<class T>
class A
{
public:
A()
{
func();
}
};
int main()
{
A<int> aa;
return 0;
}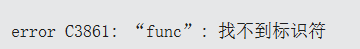
而如果我们现在不是在构造函数中调用这个不存在的func:
c++
template<class T>
class A
{
public:
A()
{
//func();
}
void push(const T& x)
{
func();
}
};
int main()
{
A<int> aa;
return 0;
}在VS2022下,也会报错,而在更老的编译器比如2013下,则不会被检查出来。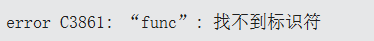

这说明了不依赖模版参数的,都会进行检查。
那么我们来看依赖模版参数的,会不会被检查出来呢?
c++
//改成这样,依赖模版参数
void push(const T& x)
{
x.func();
}
并没有被检查出来。所以,新版VS不依赖模版参数的,都会进行检查。而旧版的如2013,不依赖模版的也不进行检查。
讲了这么多,重点是,父类是类模板时,子类的函数复用父类中的函数时需要指定一下类域。
c++
void push(const T& x)
{
vector<int>::push_back(x);
};宏
这时我们可以使用宏,来更快地替换我们要的容器类型。我们以前是通过模版参数来替换成vector 、list还是deque的栈,现在我们可以通过宏的方式来实现这一点:
c++
#define CONTAINER std::vector
namespace momo
{
template<class T>
class Stack :public CONTAINER<T>
{
public:
void push(const T& x)
{
CONTAINER<T>::push_back(x);
}
void pop()
{
CONTAINER<T>::pop_back();
}
const T& top()
{
CONTAINER<T>::back();
}
bool empty()
{
return CONTAINER<T>::empty();
}
};
}本质,宏就是一种替换,有时候可以巧妙使用。
基类和派生类间的转换
(父类和子类对象赋值兼容转换)
• ++public继承的++ 派生类对象可以赋值给****基类的指针/基类的引⽤**。这里有个形象的说法叫切片或者切割。寓意把派生类中基类那部分切出来,基类指针或引用指向的是派生类中切出来的基类那部分。
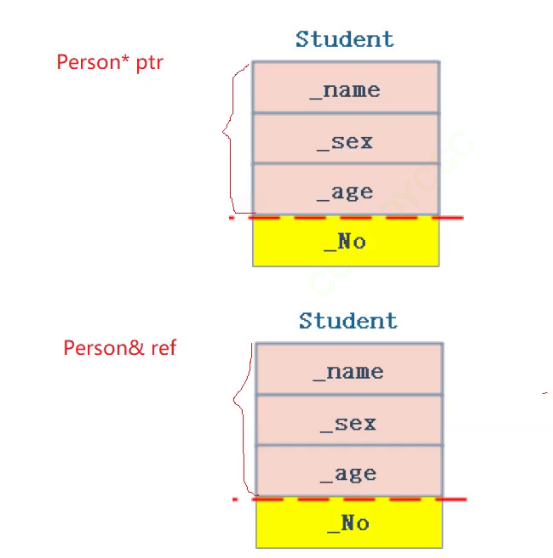
• 基类对象不能赋值给派生类对象。
• ++基类的指针或者引用 可以通过强制类型转换赋值给派生类的指针或者引用。++但是必须是基类的指针是指向派生类对象时才是安全的。这里基类如果是多态类型,可以使⽤RTTI(Run-TimeType Information)的dynamic_cast来进行识别后进行安全转换。(ps:这个日后再说)
c++
class Person
{
protected :
string _name; // 姓名
string _sex; // 性别
int _age; // 年龄
};
class Student : public Person
{
public :
int _No ; // 学号
};
int main()
{
Student sobj ;
// 1.派⽣类对象可以赋值给基类的指针/引⽤ (并没有产生类型转换)
Person* pp = &sobj;
Person& rp = sobj;//如果产生了类型转换,生成父类类型的临时对象,临时对象具有常性,应该加const引用才能编译通过。所以反过来说明并没有产生类型转换。
//可以说rp引用了子类中切割的一部分,是一种特殊处理。
//派⽣类对象可以赋值给基类的对象是通过调用后面会讲解的基类的拷贝构造完成的
Person pobj = sobj;
//2.基类对象不能赋值给派⽣类对象,这里会编译报错
sobj = pobj;
return 0;
}继承中的作用域
隐藏规则
- 在继承体系中基类和派生类都有独⽴的作用域。
- 派生类和基类中有同名成员,派生类成员将屏蔽基类对同名成员的直接访问,这种情况叫隐藏。 (在派生类成员函数中,可以使用基类::基类成员显式访问)
- 需要注意的是如果是成员函数的隐藏,只需要函数名相同就构成隐藏。
- 注意在实际中在继承体系里面最好不要定义同名的成员。
这一部分会出一些很坑的选择题。
派生类的默认成员函数
4个常见默认成员函数
6个默认成员函数,默认的意思就是指我们不写,编译器会变我们自动生成⼀个,那么在派生类中,这几个成员函数是如何生成的呢?
- 派生类的构造函数必须调用基类的构造函数初始化基类的那⼀部分成员。如果基类没有默认的构造函数,则必须在派生类构造函数的++初始化列表阶段显式调++用。
- 派生类的拷贝构造函数必须调⽤基类的拷⻉构造完成基类的拷⻉初始化。
- 派⽣类的operator=必须要调⽤基类的operator=完成基类的复制。需要注意的是派⽣类的 operator**=隐藏**了基类的operator=,所以显⽰调⽤基类的operator=,需要++指定基类作⽤域++
- 派生类的析构函数会在被调⽤完成后⾃动调⽤基类的析构函数清理基类成员。因为这样才能保证派⽣类对象先清理派⽣类成员再清理基类成员的顺序。
- 派⽣类对象初始化先调⽤基类构造再调派⽣类构造。
- 派⽣类对象析构清理先调⽤派⽣类析构再调基类的析构。
- 因为多态中⼀些场景析构函数需要构成重写,重写的条件之⼀是函数名相同(这个我们多态章节会讲 解)。那么编译器会对析构函数名进⾏特殊处理,处理成destructor(),所以基类析构函数不加 virtual的情况下,派⽣类析构函数和基类析构函数构成隐藏关系。
具体解释:
第一点:
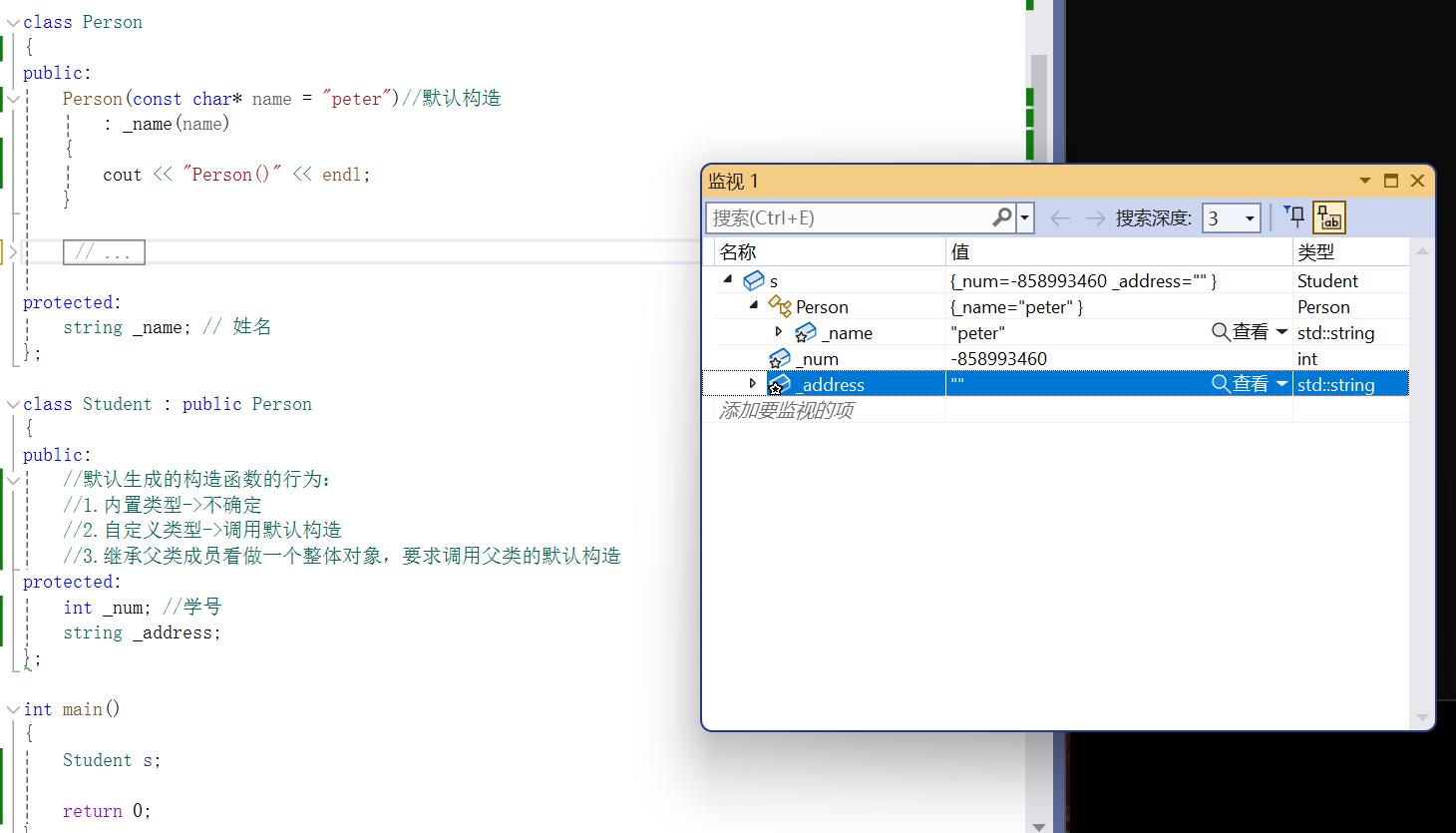
我们可以看到,派生类默认生成的构造函数确实符合上面说的规则。
假设现在我们不提供默认构造:
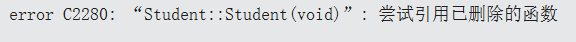
可以看到,就无法自己生成派生类的默认构造函数。
那么我们可以自己写一个Student类的构造函数,把父类的部分也初始化了吗?
c++
class Person
{
public:
Person(const char* name)//无默认构造
: _name(name)
{
cout << "Person()" << endl;
}
protected:
string _name;
};
class Student : public Person
{
public:
//自己写的构造
Student(const char* name,int num,const char* address)
:_name(name)
,_num(num)
,_address(address)
{}
protected:
int _num;
string _address;
};
int main()
{
Student s("Lily", 1, "valley");
return 0;
}这样的话会报错,所以我们可以看出,父类没有默认构造,在子类的构造函数的参数列表直接去初始化父类部分是不可行的。
因为一开始就说了:派生类的构造函数必须调用基类的构造函数初始化基类的那⼀部分成员。必须在派生类构造函数的++初始化列表阶段显式调++用。
所以我们必须这样写:
c++
Student(const char* name,int num,const char* address)
:Person(name)//当作一个整体,就像调用一个匿名对象一样
,_num(num)
,_address(address)
{}**第二点:**派生类的拷贝构造函数必须调⽤基类的拷⻉构造完成基类的拷⻉初始化。
也和第一点一样,子类的成员分为三个部分:内置类型、自定义类型、父类继承而来的部分。(同样分为三个部分来看的还有赋值重载、析构函数。)
对于内置类型,自动生成的拷贝构造会完成++值拷贝++;对于自定义类型,自动生成的拷贝构造会去调用它的拷贝构造;对于父类继承而来的部分,自动生成的拷贝构造会去调用父类的拷贝构造。------所以可以看出,对于我们的Student类,不用自己写拷贝构造,自动生成的就够用了:
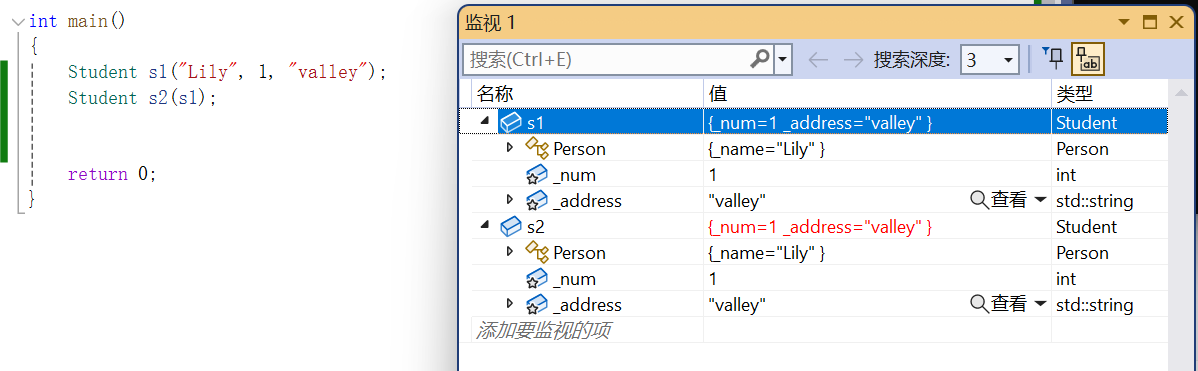
所以我们可以看出,可以把父类的部分看做一个自定义类型成员。因为对于构造、拷贝构造、析构、赋值重载,父类的部分就和自定义类型成员一样,都是调用对应的构造或析构等。
所以子类一般只要我们自己写构造,但是如果有资源需要清理,就涉及深浅拷贝,要自己写。
c++
//假如有深拷贝,所以要显式写拷贝构造函数:
Student(const Student& s)
:_num(s._num)
,_address(s._address)
,Person(s)//在上面的基类和派生类的转换中我们说过的:
//public继承的派生类对象可以赋值给基类的指针/基类的引⽤
{
//深拷贝
}初始化列表初始化的顺序与在初始化列表中写的顺序无关,而是和声明的顺序(也就是内存中存储的顺序)有关。
所以上面的拷贝构造的初始化列表,先进行的是父类部分,然后才是_ num然后_ address。
派生类的拷贝构造函数必须调⽤基类的拷⻉构造完成基类的拷⻉初始化。因为是必须,所以我们不写,Person(s),是不行的。就算基类中有默认构造,也不行(会调用父类默认构造,但是不能完成我们要的行为)。
**第三点:**赋值重载和拷贝构造类似,一般也不用我们自己写,如果有需要深拷贝的资源,就需要我们自己实现。
c++
Student& operator=(const Student& s)
{
if (this != &s)
{
//operator=(s);子类和父类构成了隐藏,直接调用调不到父类的,会栈溢出。
Person::operator=(s);//指定调用
_num = s._num;
_address = s._address;
}
return *this;
}**第四点:**也是类似的。这个情况不需要我们写。如果有需要释放的资源,才需要自己实现。
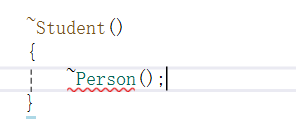
析构是可以显式调用的,但是为什么这里调不动呢?
子类的析构和父类的析构构成隐藏关系。
这在第七点中有解释。
和上面构成隐藏的处理方式一样,我们通过指定作用域来解决。
c++
int main()
{
Student s1("Lily", 1, "valley");
Student s2(s1);
Student s3("Rose",2,"wall");
s1 = s3;
return 0;
}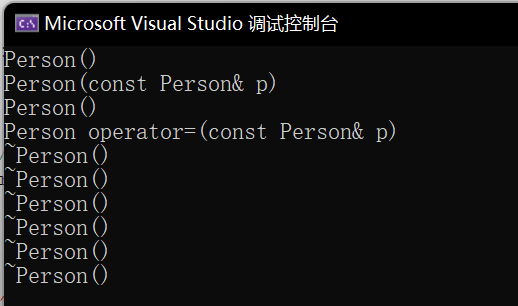
为什么会调用这么多次析构函数呢?
这是因为:
c++
~Student()
{
Person::~Person();
}我们并不需要去手动调用析构,因为子类析构之后,会自动调用父类的析构。就像自定义类型的析构,我们没写也会自动调。
这是一个规定 ,为了保证析构的顺序是先析构子类,再析构父类。++后定义的要先析构。++
本文到此结束,下次再见。