NumPy Ndarray 对象
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。
ndarray 对象是用于存放同类型元素的多维数组。
ndarray 中的每个元素在内存中都有相同存储大小的区域。
ndarray 内部由以下内容组成:
-
一个指向数据(内存或内存映射文件中的一块数据)的指针。
-
数据类型或 dtype,描述在数组中的固定大小值的格子。
-
一个表示数组形状(shape)的元组,表示各维度大小的元组。
-
一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数。
ndarray 的内部结构:
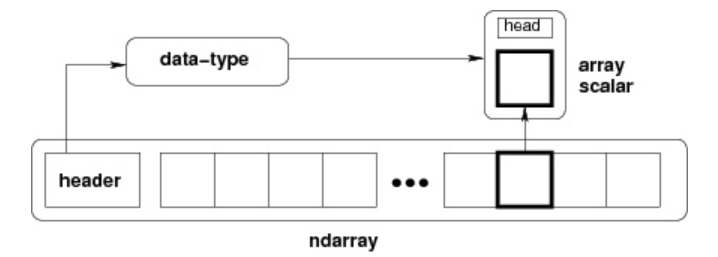
跨度可以是负数,这样会使数组在内存中后向移动,切片中 obj::-1 或 obj:,::-1 就是如此。
创建一个 ndarray 只需调用 NumPy 的 array 函数即可:
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)参数说明:
| 名称 | 描述 |
|---|---|
| object | 数组或嵌套的数列 |
| dtype | 数组元素的数据类型,可选 |
| copy | 对象是否需要复制,可选 |
| order | 创建数组的样式,C为行方向,F为列方向,A为任意方向(默认) |
| subok | 默认返回一个与基类类型一致的数组 |
| ndmin | 指定生成数组的最小维度 |
实例
接下来可以通过以下实例帮助我们更好的理解。
数据类型可以用作将python数转换为数组标量的函数(请参阅数组标量部分以获得解释),将python数字序列转换为该类型的数组,或作为许多numpy函数或方法接受的dtype关键字的参数。一些例子:
python
import numpy as np
x = np.float32(1)
print(x)
y = np.int_([1,2,4])
print(y)
z = np.arange(3, dtype=np.uint8)
print(z) 数组类型也可以通过字符代码引用,主要是为了保持与较旧的包(如Numeric)的向后兼容性。有些文档可能仍然引用这些,例如:
数组类型也可以通过字符代码引用,主要是为了保持与较旧的包(如Numeric)的向后兼容性。有些文档可能仍然引用这些,例如:
python
x=np.array([1, 2, 3], dtype='f')
print(x)我们建议使用dtype对象。
要转换数组的类型,请使用 .astype() 方法(首选)或类型本身作为函数。例如:
python
z1=z.astype(float)
print(z1)
print(np.int8(z1))0. 1. 2.
0 1 2
注意,在上面,我们使用 Python 的 float对象作为dtype。NumPy的人都知道int是指np.int_,bool意味着np.bool_,这float是np.float_和complex是np.complex_。其他数据类型没有Python等价物。
要确定数组的类型,请查看dtype属性:
python
print(z1.dtype)dtype对象还包含有关类型的信息,例如其位宽和字节顺序。数据类型也可以间接用于查询类型的属性,例如它是否为整数:
python
d=np.dtype("int32")
print(d)
print(np.issubdtype(d,np.int32))
print(np.issubdtype(d,np.float_))int32
True
False
数组标量
NumPy通常将数组元素作为数组标量返回(带有关联dtype的标量)。数组标量与Python标量不同,但在大多数情况下它们可以互换使用(主要的例外是早于v2.x的Python版本,其中整数数组标量不能作为列表和元组的索引)。有一些例外,例如当代码需要标量的非常特定的属性或者它特定地检查值是否是Python标量时。通常,存在的问题很容易被显式转换数组标量到Python标量,采用相应的Python类型的功能(例如,固定的int,float,complex,str,unicode)。
使用数组标量的主要优点是它们保留了数组类型(Python可能没有匹配的标量类型,例如int16)。因此,使用数组标量可确保数组和标量之间的相同行为,无论值是否在数组内。NumPy标量也有许多与数组相同的方法。
溢出错误
当值需要比数据类型中的可用内存更多的内存时,NumPy数值类型的固定大小可能会导致溢出错误。例如,numpy.power对于64位整数正确计算 100 * 10 * 8,但对于32位整数给出1874919424(不正确)。
python
np.power(100, 8, dtype=np.int64)
10000000000000000
print(np.power(100, 8, dtype=np.int32))
1874919424NumPy和Python整数类型的行为在整数溢出方面存在显着差异,并且可能会使用户期望NumPy整数的行为类似于Python int。与 NumPy 不同,Python 的大小int 是灵活的。这意味着Python整数可以扩展以容纳任何整数并且不会溢出。
NumPy分别提供numpy.iinfoopen in new window并numpy.finfoopen in new window验证NumPy整数和浮点值的最小值或最大值:
python
print(np.iinfo(np.int64)) # Bounds of the default integer on this system.
Machine parameters for int64 --------------------------------------------------------------- min = -9223372036854775808 max = 9223372036854775807 ---------------------------------------------------------------
如果64位整数仍然太小,则结果可能会转换为浮点数。浮点数提供了更大但不精确的可能值范围。
python
print(np.power(100, 100, dtype=np.int64)) # Incorrect even with 64-bit int
print(np.power(100, 100, dtype=np.float64))0
1e+200
扩展精度
Python 的浮点数通常是64位浮点数,几乎等同于 np.float64 。在某些不寻常的情况下,使用更精确的浮点数可能会很有用。这在numpy中是否可行取决于硬件和开发环境:具体地说,x86机器提供80位精度的硬件浮点,虽然大多数C编译器提供这一点作为它们的 long double 类型,MSVC(Windows构建的标准)使 long double 等同于 double (64位)。NumPy使编译器的 long double 作为 np.longdouble 可用(而 np.clongdouble 用于复数)。您可以使用 np.finfo(np.longdouble) 找出 numpy提供了什么。
NumPy不提供比C的 long double 更高精度的dtype;特别是128位IEEE四精度数据类型(FORTRAN的 REAL*16 )不可用。
为了有效地进行内存的校准,np.longdouble通常以零位进行填充,即96或者128位, 哪个更有效率取决于硬件和开发环境;通常在32位系统上它们被填充到96位,而在64位系统上它们通常被填充到128位。np.longdouble被填充到系统默认值;为需要特定填充的用户提供了np.float96和np.float128。尽管它们的名称是这样叫的, 但是np.float96和np.float128只提供与np.longdouble一样的精度, 即大多数x86机器上的80位和标准Windows版本中的64位。
请注意,即使np.longdouble提供比python float更多的精度,也很容易失去额外的精度,因为python通常强制值通过float传递值。例如,%格式操作符要求将其参数转换为标准python类型,因此即使请求了许多小数位,也不可能保留扩展精度。使用值1 + np.finfo(np.longdouble).eps测试你的代码非常有用。
下面实例展示结构化数据类型的使用,类型字段和对应的实际类型将被创建。
实例 4
首先创建结构化数据类型
python
import numpy as np
dt = np.dtype([('age',np.int8)])
print(dt)输出结果为:
[('age', 'i1')]
python
import numpy as np
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt)
print(a)(10,) (20,) (30,)


python
print(a['age'])10 20 30
python
import numpy as np
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
a = np.array([('abc', 21, 50),('xyz', 18, 75)], dtype = student)
print(a)(b'abc', 21, 50.) (b'xyz', 18, 75.)
