项目引入Mybatis-plus
第一步: 引入starter依赖
java
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
</dependency>第二步: 使用@MapperScan扫描mapper文件夹
java
@SpringBootApplication
@MapperScan("com.shier.shierusercenterbackend.mapper")
public class ShierUserCenterBackendApplication {
public static void main(String[] args) {
SpringApplication.run(ShierUserCenterBackendApplication.class, args);
}
}第三步: 在application.yml文件里加上相应配置
java
mybatis-plus:
configuration:
map-underscore-to-camel-case: false # 驼峰转换
# log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 日志
global-config:
db-config:
logic-delete-field: delFlag # 全局逻辑删除的实体字段名
logic-delete-value: 1 # 逻辑已删除值(默认为 1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)**map-underscore-to-camel-case: false**:
默认情况下,MyBatis-Plus 会将数据库中的下划线命名方式映射为驼峰命名方式(例如:user_name 转 为 userName)。通过将这个配置项设置为 false,禁用了这个默认的下划线转驼峰的功能。
**log-impl: org.apache.ibatis.logging.stdout.StdOutImpl**:
这是 MyBatis-Plus 的日志输出实现配置。在注释状态下,将使用 MyBatis 默认的日志输出实现,即输出到控制台。
**global-config**: 这个部分是 MyBatis-Plus 的全局配置项。**db-config**: 数据库配置部分。**logic-delete-field: isDelete**: 配置逻辑删除的实体字段名,即表示数据是否被删除的字段。在这里,配置为isDelete,表明使用isDelete字段进行逻辑删除的标记。**logic-delete-value: 1**: 配置逻辑已删除的值。在这里,配置为1,表示逻辑删除状态。**logic-not-delete-value: 0**: 配置逻辑未删除的值。在这里,配置为0,表示逻辑未删除状态。
第四步: 加上Config文件
java
@Configuration
@EnableTransactionManagement
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
PaginationInnerInterceptor pii = new PaginationInnerInterceptor();
pii.setDbType(DbType.MYSQL);
pii.setMaxLimit(500L);
interceptor.addInnerInterceptor(pii);
return interceptor;
}
@Bean
public ConfigurationCustomizer configurationCustomizer() {
return configuration -> configuration.setUseDeprecatedExecutor(false);
}
}常用注解:
@TableName
用于指定数据库表名, 通常在实体类Entity上使用
例如: @TableName("user")
@TableId
用于指定表中的主键字段, 通常在实体类的主键属性上使用
例如: @TableId(value = "id", type = IdType.AUTO)
其中 value 表示主键字段名, type 表示主键生成策略
@TableField
用于指定表中的非主键字段, 可以用于实体类的属性上, 以映射属性和数据库字段
例如: @TableField(value = "user_name", exist = true)
value 表示数据库中的字段名,
exist 表示该字段是否存在, 默认为true, 设置为false表示在数据库中不存在该字段
@TableLogic
用于指定逻辑删除字段, 逻辑删除是指在数据库中标记,某个记录已删除, 而不是真正删除
例如: @TableLogic(value = "0", delval = "1")
value 表示未删除状态的默认值
delval 表示删除状态的值
@Version
用于指定乐观锁字段, 乐观锁是一种并发控制策略, 用于解决多线程同时修改同一条记录的问题
例如: @Version private Integer version
@EnumValue
用于指定枚举类型字段的映射
例如: @EnumValue private Integer status
@InterceptorIgnore
用于忽略MP拦截器的处理
例如: @InterceptorIgnore(tenantLine = "true")
表示忽略拦截器
@FieldFill 相关文章
解析Java中的MyBatis Plus注解 @FieldFill:优雅处理字段填充-阿里云开发者社区
条件构造器:
Mybatis-plus 的 Wrapper 是一个条件构造器, 用于简化复杂的SQL查询条件的构建
它提供了一系列易于使用的API, 让你能够以链式编程的方式编写查询条件
举个荔枝~
QueryWrapper
java
@Test
public void testWrapper(){
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.like("username", "o")
.eq("status", 1);
userMapper.selectList(wrapper).forEach(System.out::println);
}
看到左上角这玩意绿了说明单元测试通过了~
接下来我们用更进阶的方法进行查询, 也就是Lambda~
LambdaQueryWrapper
java
@Test
public void testWrapper2(){
PageParam pageParam = new PageParam();
pageParam.setPageNum(1);
pageParam.setPageSize(10);
LambdaQueryWrapper<User> query = Wrappers.lambdaQuery();
query.like(User::getUsername, "o")
.eq(User::getStatus, 1)
.orderByDesc(User::getBalance)
.last("limit " + pageParam.getPageNum() + ", " + pageParam.getPageSize());
List<User> users = userMapper.selectList(query);
users.forEach(System.out::println);
}这里的代码有个小小的优化点
就是用户的状态status可以单独做一个枚举类去存放
因为状态是比较固定的值 不是0就是1 , 直接写死并不美观, 所以可以封装
LambdaQueryWrapper更好用, 因为它构建sql语句的时候, 需要用到数据库字段名,
上面一种方法很明显是直接在代码里写死字段名了, 一旦数据库的某些字段更改就寄了
所以我们采取第二种方法, 使用LambdaQueryWrapper<User> query = Wrappers.lambdaQuery()
这样就巧妙地避开了数据库某些字段的变更而导致代码失效~
静态工具Db:
这个可是重头戏了~
查询用户状态为 1 的所有用户信息
java
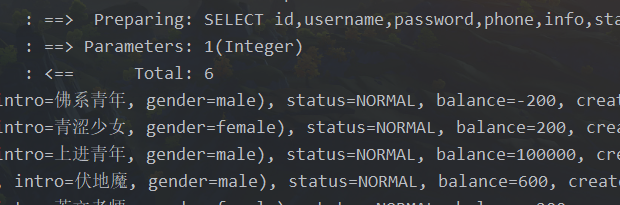
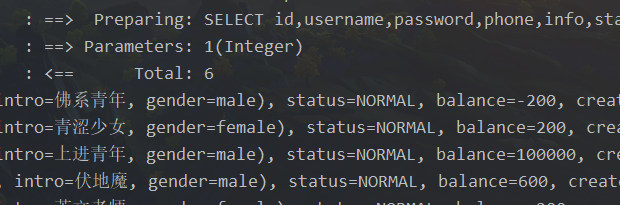
@Test
public void testQuery(){
List<User> users = Db.lambdaQuery(User.class).eq(User::getStatus, 1).list();
users.forEach(System.out::println);
}
查询多个用户的地址
java
// 2.2根据用户ids查询地址
List<Address> addresses = Db.lambdaQuery(Address.class)
.in(Address::getUserId, userIds)
.list();查询用户Ids相关的用户信息, 根据Id分组, 存入Map
userMap = users.stream().collect(Collectors.groupingBy(User::getId));
这行代码用Id进行了数据分组, 便于存入hashMap中
java
@Test
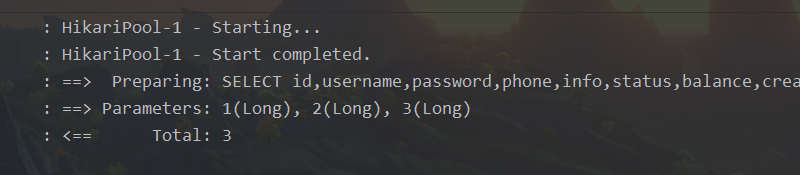
void testQueryByIds(){
List<User> users = Db.lambdaQuery(User.class)
.in(User::getId, 1L, 2L, 3L)
.list();
Map<Long, List<User>> userMap = new HashMap<>(0);
if(CollUtil.isNotEmpty(users)){
userMap = users.stream().collect(Collectors.groupingBy(User::getId));
}
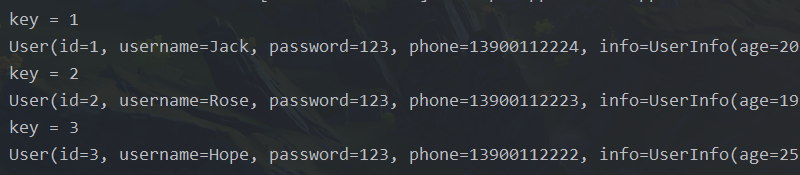
userMap.forEach((k, v) -> {
System.out.println("key = " + k);
v.forEach(System.out::println);
});
}