
上一篇:《设计卷积神经网络CNN为什么不是编程?》
**序言:**我们已经踏入了设计人工智能(AI)模型的大门,有一个重要概念请大家务必记住:人工智能模型 = 架构 + 特征。任何一个AI模型都是先设计出架构,再通过数据训练获得特征。整合了特征的架构才算是一个完整的人工智能模型,如果没有特征的支撑,架构本身还不能称为人工智能模型。
在本节中,我们将探索一个比 Fashion MNIST 分类器更复杂的场景。我们将扩展我们对卷积和卷积神经网络的理解,尝试对图片内容进行分类,其中特征的位置并不总是在同一个地方。所以我们为此创建了马或人数据集。(我们全部的编码都是经过验证过的,大家可以用来自己验证。)
马或人数据集
本节的数据集包含了一千多张 300 × 300 像素的图片,大约各有一半是马和人,以不同的姿势呈现。你可以在图 3-7 中看到一些示例。

图 3-7:马和人正如你所看到的,主体具有不同的方向和姿势,图像的构图也各不相同。比如说这两匹马------它们的头部方向不同,一张是远景,展示了整个动物,而另一张是近景,仅展示了头部和部分身体。同样地,人类的光照不同,肤色各异,姿势也不同。男性双手叉腰,而女性则伸展双手。这些图像中还包含了背景,比如树木和海滩,因此分类器需要识别出图像中哪些部分是决定马和人特征的重要特征,而不被背景干扰。
尽管之前预测 Y = 2X -- 1 或分类小型单色衣物图像的例子可能可以通过传统编码实现,但很明显,这个问题要复杂得多,进入了机器学习成为解决问题关键的领域。
一个有趣的旁注是,这些图像都是计算机生成的。理论上,CGI 马的图像中识别出的特征应适用于真实图像。在本章稍后,你将看到这种方法的效果如何。
Keras 的 ImageDataGenerator
你一直使用的 Fashion MNIST 数据集自带标签。每个图像文件都有一个包含标签详情的文件。然而,许多基于图像的数据集并没有这一点,"马或人"数据集也不例外。没有标签的情况下,图像被分成各自类型的子目录。在 TensorFlow 的 Keras 中,有一个名为 ImageDataGenerator 的工具可以利用这种结构来自动为图像分配标签。
要使用 ImageDataGenerator,只需确保你的目录结构中包含一组命名的子目录,每个子目录就是一个标签。例如,"马或人"数据集提供为一组 ZIP 文件,一个包含训练数据(1000 多张图像),另一个包含验证数据(256 张图像)。当你下载并将它们解压到本地用于训练和验证的目录中时,确保它们按图 3-8 所示的文件结构存放。
以下是获取训练数据并将其提取到相应命名子目录的代码,如图所示:
import urllib.request
import zipfile
url = "https://storage.googleapis.com/laurencemoroney-blog.appspot.com/
horse-or-human.zip"
file_name = "horse-or-human.zip"
training_dir = 'horse-or-human/training/'
urllib.request.urlretrieve(url, file_name)
zip_ref = zipfile.ZipFile(file_name, 'r')
zip_ref.extractall(training_dir)
zip_ref.close()
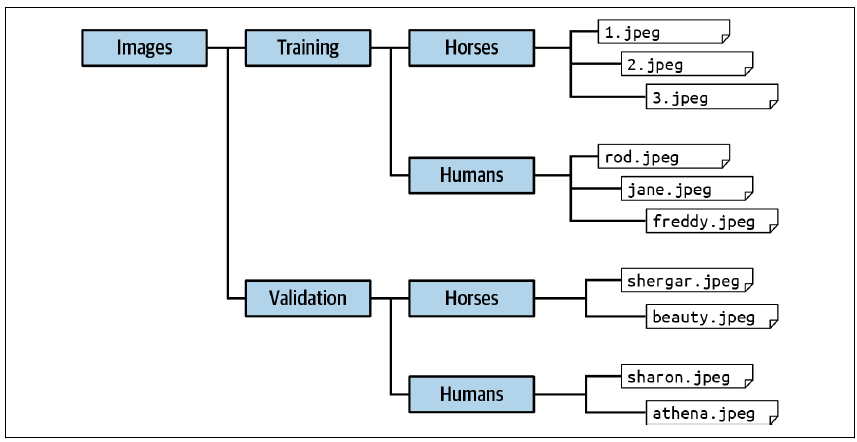
图 3-8:确保图像位于命名的子目录中以下是获取训练数据并将其提取到如图所示的相应命名子目录中的代码:
import urllib.request
import zipfile
url = "https://storage.googleapis.com/laurencemoroney-blog.appspot.com/
horse-or-human.zip"
file_name = "horse-or-human.zip"
training_dir = 'horse-or-human/training/'
urllib.request.urlretrieve(url, file_name)
zip_ref = zipfile.ZipFile(file_name, 'r')
zip_ref.extractall(training_dir)
zip_ref.close()
这只是简单地下载训练数据的 ZIP 文件,并将其解压到 horse-or-human/training 目录中(我们稍后会处理验证数据的下载)。这是包含图像类型子目录的父目录。
要使用 ImageDataGenerator,我们现在只需使用以下代码:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
All images will be rescaled by 1./255
train_datagen = ImageDataGenerator(rescale=1/255)
train_generator = train_datagen.flow_from_directory(
training_dir,
target_size=(300, 300),
class_mode='binary'
)
我们首先创建一个名为 train_datagen 的 ImageDataGenerator 实例。然后,我们指定它将从一个目录中流出图像用于训练过程。目录是之前指定的 training_dir。此外,我们还设置了一些数据的超参数,比如目标大小------在这个例子中,图像大小为 300 × 300,并且类别模式为二进制。如果只有两类图像(就像这个例子),模式通常是二进制;如果有两类以上,模式则为分类。
马或人的卷积神经网络架构
在设计用于分类这些图像的架构时,你需要考虑几个与 Fashion MNIST 数据集的主要差异。首先,这些图像要大得多------300 × 300 像素------因此可能需要更多的层次。其次,这些图像是全彩色的,而不是灰度的,因此每张图像将拥有三个通道而非一个。第三,只有两种图像类型,因此我们有一个二分类器,只需一个输出神经元即可实现,其中对于一个类别接近 0,另一个类别接近 1。在探索这个架构时,请牢记这些考虑事项:
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu' ,
input_shape=(300, 300, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
这里有一些需要注意的点。首先,这是第一个卷积层。我们定义了 16 个 3 × 3 的过滤器,但图像的输入形状为 (300, 300, 3)。记住,这是因为我们的输入图像是 300 × 300 的彩色图像,所以有三个通道,而不是之前用于单色 Fashion MNIST 数据集的一个通道。
在另一端,你会注意到输出层中只有一个神经元。这是因为我们使用的是二分类器,如果用 sigmoid 函数激活,这个单一神经元就能实现二分类。sigmoid 函数的作用是将一组值驱动到 0,另一组驱动到 1,这对于二分类来说非常合适。
接下来,注意我们如何堆叠了好几个卷积层。这样做是因为我们的图像源相当大,我们希望随着时间推移,得到许多较小的图像,每张图像都突出了特征。如果我们查看 model.summary 的结果,就能看到这种效果:
=================================================================
conv2d (Conv2D) (None, 298, 298, 16) 448
max_pooling2d (MaxPooling2D) (None, 149, 149, 16) 0
conv2d_1 (Conv2D) (None, 147, 147, 32) 4640
max_pooling2d_1 (MaxPooling2 (None, 73, 73, 32) 0
conv2d_2 (Conv2D) (None, 71, 71, 64) 18496
max_pooling2d_2 (MaxPooling2 (None, 35, 35, 64) 0
conv2d_3 (Conv2D) (None, 33, 33, 64) 36928
max_pooling2d_3 (MaxPooling2 (None, 16, 16, 64) 0
conv2d_4 (Conv2D) (None, 14, 14, 64) 36928
max_pooling2d_4 (MaxPooling2 (None, 7, 7, 64) 0
flatten (Flatten) (None, 3136) 0
dense (Dense) (None, 512) 1606144
dense_1 (Dense) (None, 1) 513
=================================================================
Total params: 1,704,097
Trainable params: 1,704,097
Non-trainable params: 0
注意,当数据通过所有卷积层和池化层后,最终变成了 7 × 7 的元素。理论上,这些将是相对简单的激活特征图,只包含 49 个像素。这些特征图可以传递给全连接的神经网络,以将它们匹配到相应的标签。
当然,这也使得我们比之前的网络拥有更多的参数,因此训练速度会更慢。使用这种架构,我们将学习 170 万个参数。
为了训练网络,我们需要用一个损失函数和一个优化器来编译它。在这种情况下,因为只有两类,我们可以使用二元交叉熵损失函数 binary cross entropy,顾名思义,这是专为这种场景设计的损失函数。我们还可以尝试一个新的优化器,均方根传播(RMSprop),它带有一个学习率(lr)参数,可以用来调整学习速率。代码如下:
model.compile(loss='binary_crossentropy',
optimizer=RMSprop(lr=0.001),
metrics='accuracy')
我们通过使用 fit_generator 并传入我们之前创建的 train_generator 来进行训练:
history = model.fit_generator(
train_generator,
epochs=15
)
这个示例可以在 Colab 中运行,但如果你想在自己的机器上运行,请确保使用 pip install pillow 安装 Pillow 库。
请注意,在 TensorFlow 的 Keras 中,你可以使用 model.fit 将训练数据和训练标签进行拟合。在使用生成器时,旧版本要求使用 model.fit_generator。在 TensorFlow 的较新版本中,你可以使用任一方法。
仅仅经过 15 轮训练,这种架构在训练集上就达到了非常令人印象深刻的 95% 以上的准确率。当然,这仅适用于训练数据,并不能代表网络在未曾见过的数据上的表现。
接下来我们将看看如何使用生成器添加验证集并测量其性能,以更好地指示该模型在实际中的表现。
向马或人数据集中添加验证
要添加验证,你需要一个独立于训练集的验证数据集。有时你会得到一个主数据集,需要自己进行拆分,但在马或人数据集中,有一个独立的验证集可以下载。
你可能会想,为什么我们这里谈的是验证数据集而不是测试数据集,它们是一样的吗?
对于之前章节中的简单模型,通常将数据集分成两个部分就够了,一个用于训练,另一个用于测试。但对于我们正在构建的这种更复杂的模型,你会希望创建单独的验证集和测试集。它们之间有什么区别呢?训练数据用于教网络如何将数据和标签对应起来。验证数据在训练过程中用于查看网络在之前未见过的数据上的表现------即,它并不是用来拟合数据和标签的,而是用来检查拟合的效果如何。测试数据则是在训练完成后用于查看网络在完全未见过的数据上的表现。有些数据集提供三向分割,在其他情况下,你可能需要将测试集拆分为验证和测试两个部分。这里,你将下载一些额外的图像来测试模型。
你可以使用与训练图像类似的代码来下载验证集并将其解压到另一个目录中:
validation_url = "https://storage.googleapis.com/laurencemoroney-blog.appspot.com/validation-horse-or-human.zip"
validation_file_name = "validation-horse-or-human.zip"
validation_dir = 'horse-or-human/validation/'
urllib.request.urlretrieve(validation_url, validation_file_name)
zip_ref = zipfile.ZipFile(validation_file_name, 'r')
zip_ref.extractall(validation_dir)
zip_ref.close()
一旦有了验证数据,就可以设置另一个 ImageDataGenerator 来管理这些图像:
validation_datagen = ImageDataGenerator(rescale=1/255)
validation_generator = train_datagen.flow_from_directory(
validation_dir,
target_size=(300, 300),
class_mode='binary'
)
要让 TensorFlow 为你执行验证,只需更新 model.fit_generator 方法,指定希望使用验证数据在每个训练周期(epoch)测试模型。你可以使用 validation_data 参数,并传入刚构建的验证生成器:
history = model.fit_generator(
train_generator,
epochs=15,
validation_data=validation_generator
)
经过 15 个训练周期后,你会发现模型在训练集上的准确率超过 99%,但在验证集上只有大约 88%。这表明模型出现了过拟合,就像我们在上一章中看到的那样。
尽管如此,考虑到模型训练所用的图像数量少且图像多样化,性能并不算差。你开始遇到由于数据不足而带来的瓶颈,但有一些技术可以用来提升模型的性能。我们会在本章稍后探讨这些技术,不过在此之前,让我们来看看如何使用这个模型。
测试马或人图像
能够构建一个模型当然很好,但你肯定也想试一试它的实际效果。刚开始我的 AI 之旅时,一个让我感到非常沮丧的问题是,我能找到大量展示如何构建模型的代码和模型表现的图表,但却很少能找到帮助我自己测试模型的代码。我会尽量避免在本书中出现这样的情况!
测试模型可能在 Colab 中最为方便。我已经在 GitHub 上提供了一个马或人笔记本,可以直接在 Colab 中打开。
一旦你训练好模型,你会看到一个名为"运行模型"的部分。在运行它之前,先在线上找几张马或人的图片并下载到你的电脑上。Pixabay.com 是一个不错的版权免费图像网站。建议先将测试图像准备好,因为在你搜索时节点可能会超时。
图 3-9 显示了我从 Pixabay 下载的几张用于测试模型的马和人图像。

图 3-9:测试图像上传图像后,如图 3-10 所示,模型正确地将第一张图像分类为人,将第三张图像分类为马,但尽管中间那张图像显然是人,却被错误地分类为马!
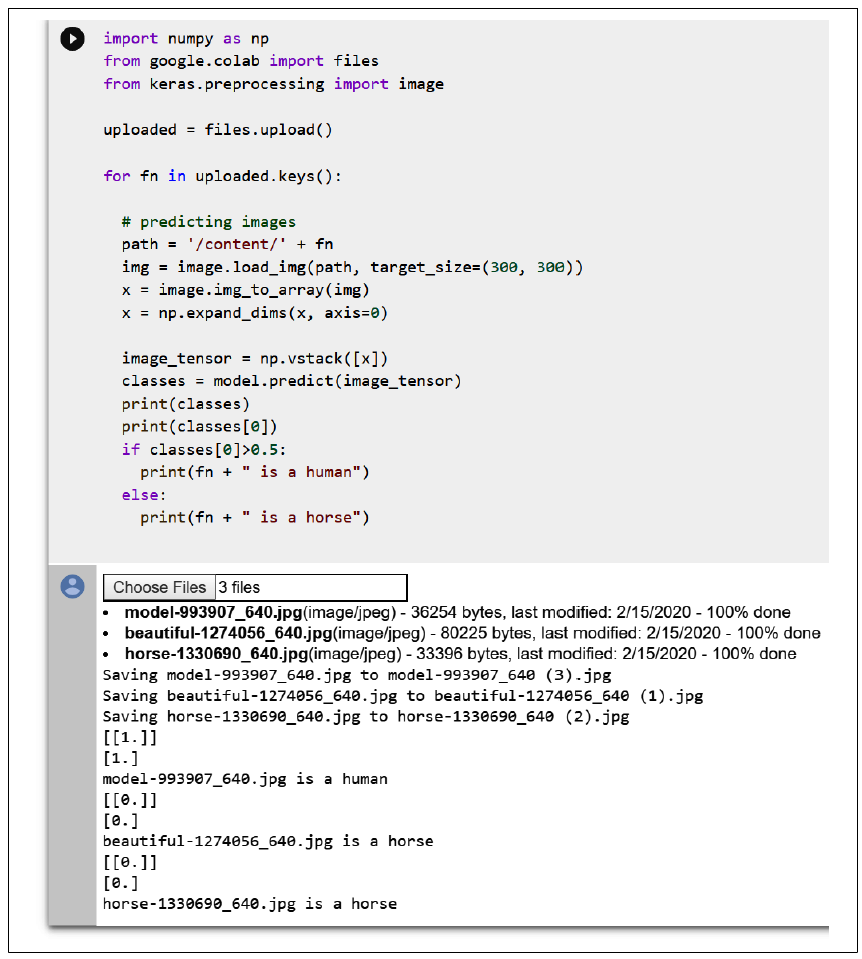
图 3-10:执行模型你也可以同时上传多张图片,让模型对它们进行预测。你可能会注意到模型倾向于过拟合马的分类。如果人类没有完全呈现姿势------即,看不到他们的全身------模型可能会偏向于将其归为马。这就是这种情况下发生的事。第一个人类模型完全呈现了姿势,图像的姿势类似于数据集中许多姿势,因此模型能正确分类她。而第二个人面对着相机,但图像中只有她的上半身。训练数据中没有类似的图像,所以模型无法正确识别她。
现在我们来看一下代码,了解它的作用。也许最重要的部分是这一段:
img = image.load_img(path, target_size=(300, 300))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
这里,我们从 Colab 保存的路径中加载图像。请注意,我们指定了目标大小为 300 × 300。上传的图像可以是任意形状,但如果要输入到模型中,它们必须是 300 × 300,因为模型是按这个尺寸训练的。所以,第一行代码加载图像并将其调整为 300 × 300。
接下来的代码将图像转换为二维数组。然而,模型期望的是三维数组,这在模型架构中的 input_shape 指定了。幸运的是,Numpy 提供了一个 expand_dims 方法,可以轻松地为数组添加一个新维度。
现在我们将图像放入三维数组中,只需确保它是垂直堆叠的,这样它的形状与训练数据一致:
image_tensor = np.vstack(x)
图像格式正确后,就可以进行分类了:
classes = model.predict(image_tensor)
模型返回一个包含分类结果的数组。因为在这个例子中只有一个分类,它实际上是一个包含数组的数组。你可以在图 3-10 中看到,对于第一个(人类)模型,它看起来像 \[1.]。
接下来只需检查数组第一个元素的值。如果大于 0.5,我们认为它是人类:
if classes0 > 0.5:
print(fn + " is a human")
else:
print(fn + " is a horse")
这里有几个关键点需要考虑。首先,尽管网络是用合成的计算机生成图像训练的,它在识别真实照片中的马或人方面表现得相当好。这是一个潜在的好处,意味着你不一定需要数千张照片来训练模型,可以通过 CGI 以相对低成本完成训练。
但这个数据集也展示了你将面临的一个基本问题。你的训练集无法代表模型在真实环境中可能遇到的每种情况,因此模型总会对训练集有一定程度的过度专门化。这里就有一个清晰的例子:图 3-9 中间的人类被错误分类了。训练集中没有包含这个姿势的人类,因此模型没有"学到"人类可以是这个样子的。因此,它很可能将该形象视为马,在这种情况下,它确实如此。
解决方案是什么?最明显的办法是增加更多训练数据,包含该特定姿势的人类以及其他未代表的姿势。然而,这并不总是可行的。幸运的是,TensorFlow 提供了一个巧妙的技巧来虚拟扩展数据集------这叫做图像增强(image augmentation),我们接下来将探索它。