来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Open-World Dynamic Prompt and Continual Visual Representation Learning

创新点
- 在开放世界中建立了一种新的持续视觉表征学习的实用设置。
- 提出了一种简单而强大的方法,动态提示与表征学习器(
DPaRL,Dynamic Prompt and Representation Learner),该方法在有效更新区分性表征主干网络的同时动态生成提示。这一增强提高了在测试时对未见开放世界类别的泛化能力。 - 在所提议的实用设置中,
DPaRL表现超越了最先进的持续学习方法,无论是无回放方法还是基于回放的方法。
内容概述
开放世界本质上是动态的,特点是不断演变的概念和分布。在这种动态开放世界环境中,持续学习(CL)带来了一个重大挑战,即如何有效地泛化到未见的测试时类。为了解决这一挑战,论文提出了一种新的、针对开放世界视觉表示学习的实际CL设置。在这一设置中,后续数据流系统性地引入与先前训练阶段中所见类不相交的新类,同时与未见的测试类保持区别。
为此,论文提出了动态提示和表示学习器(DPaRL),这是一种简单但有效的基于提示的持续学习(PCL)方法。DPaRL学习生成用于推理的动态提示,而不是依赖于之前PCL方法中的静态提示池。此外,DPaRL在每个训练阶段共同学习动态提示生成和区分性表示,而以前的PCL方法仅在整个过程中细化提示学习。
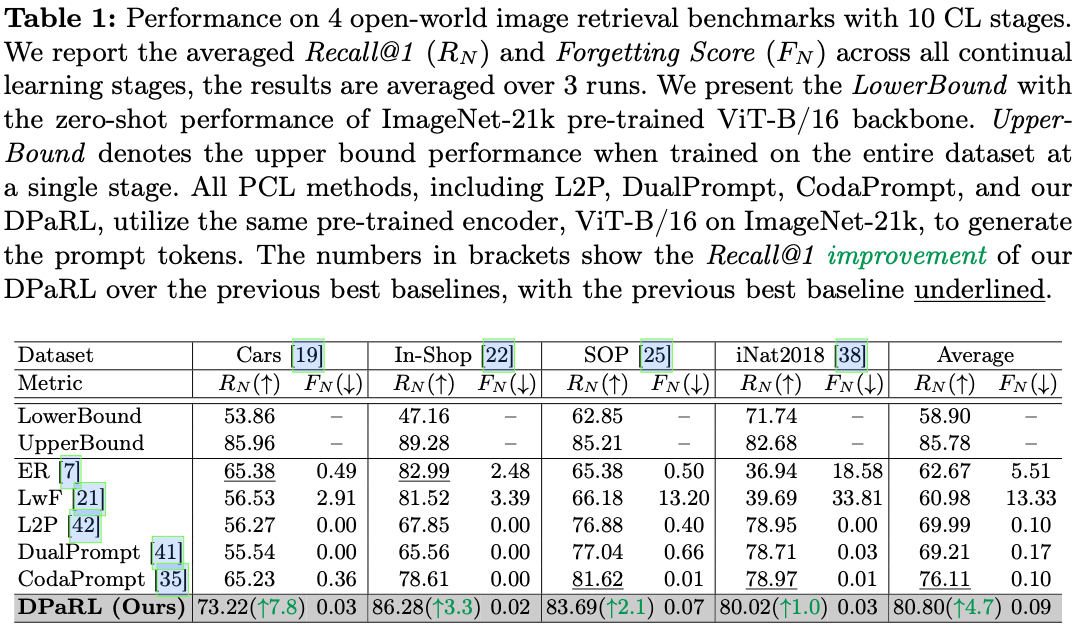
实验结果表明,方法的优越性,在公认的开放世界图像检索基准上,DPaRL在Recall@1性能上平均提高了4.7%,超越了最新的先进方法。
Dynamic Prompt and Representation Learner (DPaRL)
封闭世界与开发世界设置
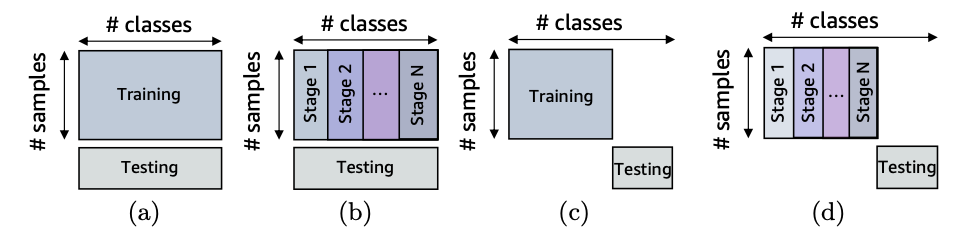
视觉表示学习的两个基本设置是封闭世界和开放世界范式。在封闭世界设置中(如图 (a/b) 所示),持续训练和测试数据的类别是完全相同的。而开放世界设置(如图 (c/d) 所示)中,持续训练和测试类别完全不同,因此需要模型学习能对未见过的概念进行概括的表示。
基于提示的持续学习
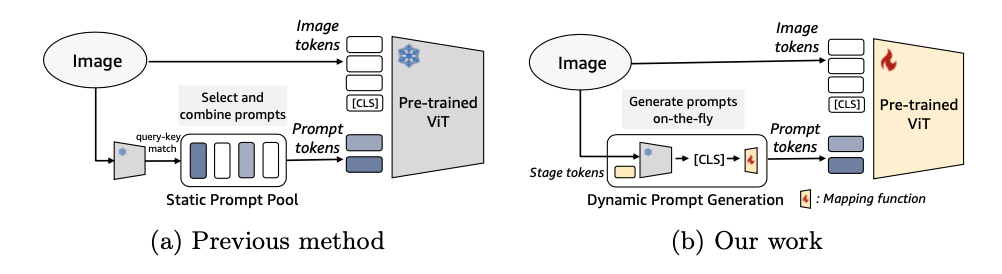
基于提示的持续学习(PCL)方法使用预训练的视觉变换器(ViT)作为封闭世界图像分类的区分性主干,如图 (a) 所示。这些方法创建了一个包含多个提示token的提示池,在训练期间仅更新该池中的可学习参数。在推理时,学习到的提示池是静态的,PCL方法从该池中选择tokens,输入到多个ViT主干层进行预测。
论文的方法也采用了这种PCL范式,但在训练和测试类别不相交的开放世界设置中,现有的静态PCL提示池设计存在局限性,即测试类别内部和外部的距离分布之间的分离有限。
为此,论文引入一个动态提示生成(DPG)网络替代静态提示池,通过联合动态提示和表示学习范式,增强了区分性表示主干模型的能力,更有效地对开放世界概念进行概括。
动态提示生成(DPG)网络
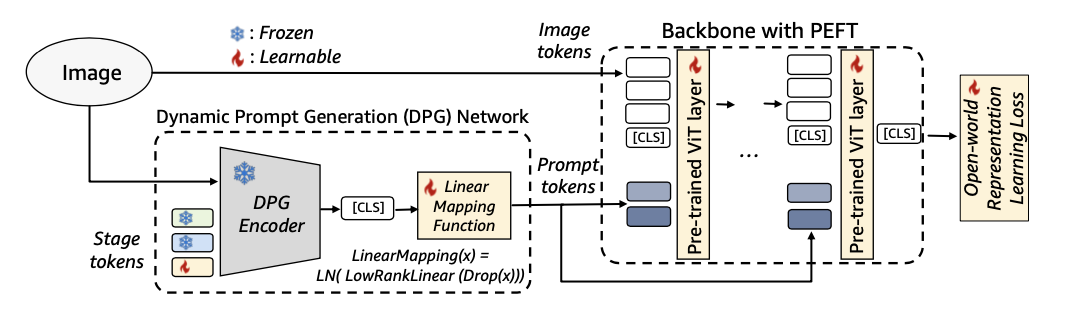
动态阶段token
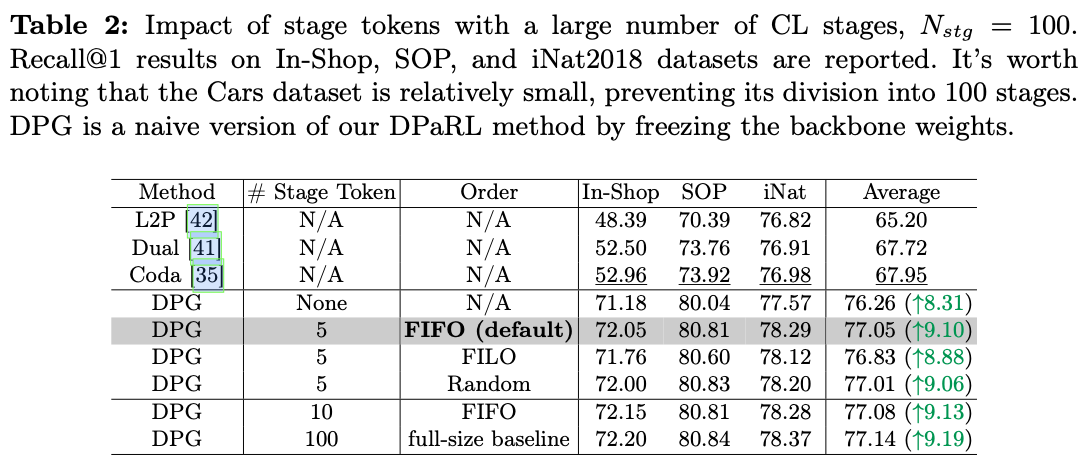
为了保留动态提示生成(DPG)过程中每个持续学习阶段的信息,引入了阶段token \(S\) 。在训练阶段 \(t\) ,训练一个阶段token \(S_{t}\),同时以先进先出(FIFO)队列的方式冻结之前的阶段token \(S_{t - (q - 1)} \sim S_{t-1}\) ,其中 \(q\) 是最大队列大小,设置为5。这确保了来自之前阶段的知识保持不变,同时阶段token的总数受到队列大小的限制,而不会随着阶段数的增加而线性扩展。随后,在DPG网络中,通过自注意力模块进行阶段间token与实例图像token之间信息的融合。
映射函数
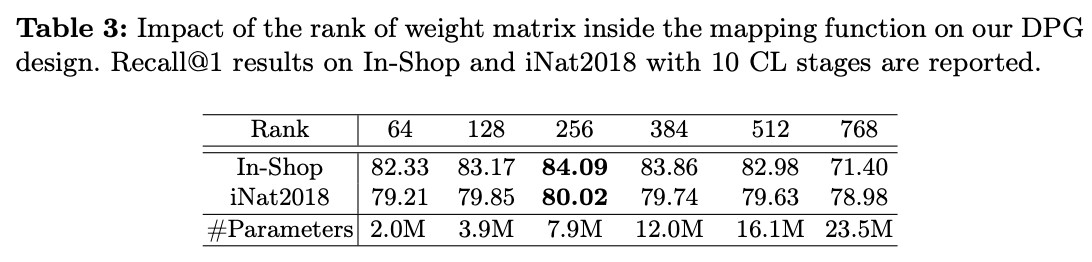
DPG生成一个 `CLS`token,以动态获取任务特定的高级信息。然而,它的大小与主干模型所需的提示tokens不同。为了解决这个问题,需要引入一个映射函数来连接 `CLS`token与提示tokens。一种直接的方法是使用单个线性层进行维度转换。然而,这种方法会引入过多的额外参数,导致过度参数化,也可能导致高度压缩的 `CLS`token信息出现过拟合。
为了解决这个问题,受到LoRA的启发,对权重参数施加约束 \(W=AB^T \in \mathbb{R}^{C_{in} \times C_{out}}\) ,其中 \(A \in \mathbb{R}^{C_{in} \times R}\) , \(B \in \mathbb{R}^{C_{out} \times R}\) ,确保最大秩为 \(R< \min(C_{in}, C_{out})\) 。此外,对该低秩线性映射函数应用了Dropout和LayerNorm,这进一步有助于避免过拟合并稳定训练。
在这个专用映射函数和预训练神经网络的帮助下,提示 \(P\) 是从输入图像 \(I\) 和阶段tokens \(S_{t, q} := S_{t - (q - 1)} \sim S_{t}\) 动态获得的:
\\\begin{equation} P = Mapping(DPG\\mbox{-}Network(\[S_{t, q}; \\hspace{1mm} I)). \label{eq:propmt_generation} \end{equation} \]
将 \(P\) 重新调整为大小为 \(N_p \times C \times L\) ,其中 \(N_p\) 是提示的数量, \(C\) 是通道维度, \(L\) 表示提示应用于主干模型的层数。遵循之前的PCL方法中的提示技术,生成的提示将插入到ViT主干中的前 \(L\) 层。第 \(l\) 层的提示 \(P_l \in \mathbb{R}^{N \times C}\) 被划分为 \(\{P_{l,k}, P_{l,v}\}\in \mathbb{R}^{\frac{N}{2} \times C}\) ,作为前缀添加到注意力机制中键和值的输入token嵌入中。
最终,多头自注意力可表示为:
\\\begin{equation} h_i = Attention(X_lW_q\^i, \\hspace{1mm} \[P_{k};XW_k^i, \hspace{1mm} P_{v};XW_v^i). \end{equation} \]
联合动态提示与表示学习
与之前冻结主干模型的PCL方法不同,DPaRL以联合学习动态提示生成和带有鉴别性表示学习的主干模型。这种方法旨在最大化整个管道的能力,以整合旧阶段概念和新概念,从而封装多样的语义,帮助在开放世界中对未见类别和未知领域转移的泛化。
利用参数高效的微调技术,DPaRL成功地最大化了准确性性能,同时最小化了灾难性遗忘。需要注意的是,用于提示生成的DPG编码器权重(管道的左侧)是冻结的,而可学习的参数包括阶段tokens、映射函数和表示损失函数中的权重,以及鉴别性表示主干权重。
主要实验
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
