2024-08-15,由斯坦福大学发布的Continuous Perception Benchmark(CPB),一个推动视频模型模仿人类连续感知能力的新基准。
数据集地址:Continuous Perception Benchmark|视频理解数据集|物体识别
一、背景:
视频理解的重要性 在计算机视觉领域,视频理解一直是一个基础而富有挑战的任务,它对于从监控到自动驾驶等多个领域都至关重要。
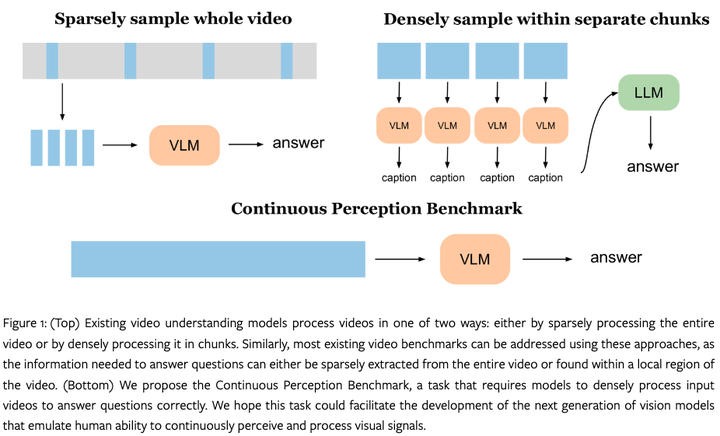
现有技术的局限 现有的视频模型通常要么从视频中稀疏地采样关键帧,要么将视频分割成多个块,然后在每个块内密集采样。这种方法无法像人类那样连续地处理视频信号。
目前遇到的困难和挑战:
-
稀疏采样或分块处理:现有模型无法有效利用视频中的全部信息,导致无法全面理解视频内容。
-
缺乏全局时间信息:仅分析关键帧或独立处理视频片段,可能会丢失全局时间信息。
-
无法学习复杂概念:处理少量帧可能导致模型学习到的只是表面的或错误的信号,而不是像人类那样学习到组合性、直观物理学和物体永久性等关键概念。
数据集地址:Continuous Perception Benchmark|视频理解数据集|物体识别
二、让我们一起了解CPB
CPB的核心创新点在于提出了一个新的视频问题回答任务,要求模型必须连续分析整个视频流以获得最佳性能。
-
连续感知:CPB要求模型必须连续分析整个视频流,而不是仅关注几帧或小片段。
-
密集处理:模型需要密集地处理输入视频,以模拟人类感知视觉信号的方式。
-
新的评估方法:通过Mean Absolute Error (MAE), Root-Mean-Square-Error (RMSE), Off-By-One accuracy (OBO), Off-By-Zero (OBZ)等指标来评估模型性能。
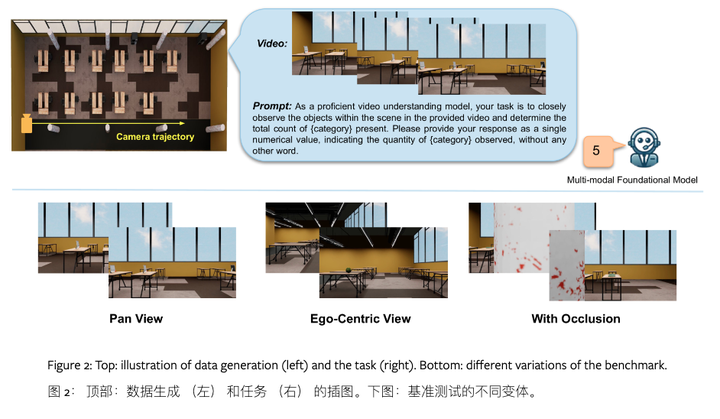
数据集 :
使用OmniGibson模拟器生成数据集,创建了包含家具和随机放置在桌子上的对象的3D场景。
每个样本包括视频、物体数量和位置信息,以及详细的标注信息。设计了包括视频问题回答在内的多个核心任务。
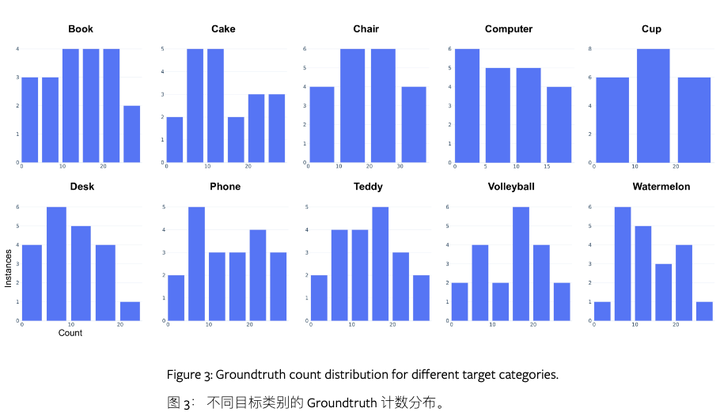
三、让我们展望CPB应用
比如,我是一个热爱生活,热爱烹饪的美食视频博主。
我的频道专注于教人做菜,我每周都会拍摄几个新的烹饪视频,但视频编辑过程总是很耗时。这时候,CPB就能帮上大忙了。
视频拍摄
我准备好了所有食材,开始录制新的视频------比如说,教大家做经典的意大利面。我把相机放在三脚架上,开始烹饪。我一边操作,一边讲解每个步骤的要点。
智能剪辑
-
自动标记和检索:视频拍摄完成后,我可以用CPB来分析整个视频。CPB能够识别出视频中的关键步骤,比如切菜、煮面、搅拌等。它甚至能识别出你讲解的每个要点,自动为这些片段打上标签。
-
自动剪辑:我告诉CPB,你想要一个3分钟的精简版视频,只包含最关键的步骤。CPB会分析整个视频,自动选取最能代表每个步骤的片段,然后把这些片段剪辑在一起,生成一个连贯的视频。
-
高光时刻:我还可以要求CPB找出那些特别精彩的瞬间,比如观众可能会"哇"出来的那些------比如你巧妙地把面条扔到空中,然后准确无误地接住。CPB会识别出这些瞬间,并把它们放在视频的高光时刻。
互动元素
-
观众视角:我还可以利用CPB来分析观众的反馈。比如,我可以让CPB分析观众在哪个片段停留的时间最长,哪个片段的点赞和评论最多。这样,我就知道哪些内容最受欢迎,哪些可能需要改进。
-
个性化推荐:如果我的频道有很多类似的视频,CPB可以帮助我分析哪些视频最符合当前观看这个视频的观众的口味,然后在视频末尾推荐给他们。
后期制作
-
智能字幕:CPB还可以帮助我自动生成字幕。它能够识别视频中的对话,然后转换成文字,生成字幕文件。这样,我的视频就能更容易被不同语言的观众理解。
-
内容分析:在视频发布后,CPB可以帮助我分析观众的观看习惯,比如他们通常在哪个点暂停或退出。这样,我就知道视频的哪些部分可能需要改进,哪些部分做得不错。
通过CPB的帮助,我的视频编辑工作变得轻松多了。我不再需要一帧一帧地去剪片子,也不用担心错过那些精彩的瞬间。我可以把更多的时间花在创作上,而不是后期制作上。而且啊,我的视频内容也因为更加精准和吸引人,而获得了更多的观看和点赞。这就是CPB的魔力!