前言:
大家好,在上一篇文章里面,我们已经把webrtc的apm降噪工程代码已经移植到rk3568上,今天就开始从最简单的音频降噪NS工程代码来学习音频降噪的原理。
噪声的分类:
在讲解代码实践之前,首先我们需要了解噪声的分类;虽然我们都知道噪声是啥,但是在不同场景的噪声,处理的手段会有差异。
噪声分两大类:
-
1、稳态噪声(Stationary Noise)
-
2、非稳态噪声(Non-stationary Noise)
稳态噪声:
稳态噪声就是"长期存在、变化缓慢的噪声",它的能量谱(频谱)随时间变化很小。常见例子,比如说:
| 噪声类型 | 是否稳态 | 解释 |
|---|---|---|
| 空调噪声 | 稳态 | "呼呼"持续不变 |
| 风扇噪声 | 稳态 | 基本恒定频率 |
| 电脑电流声 | 稳态 | 高频持续"滋滋" |
| 车内发动机怠速 | 稳态 | 频谱变化缓慢 |
| 服务器机房噪声 | 稳态 | 持续背景噪声 |
这些噪声通常:
频谱平滑
能量分布稳定
变化极小
非稳态噪声
指短时突发、变化快、频谱不稳定的噪声,它的能量和频谱随时间剧烈变化。 比如说:
| 噪声类型 | 是否非稳态 | 原因 |
|---|---|---|
| 键盘敲击声 | 非稳态 | 高瞬态能量 |
| 门关上的"砰" | 非稳态 | 爆发式冲击 |
| 撞击、敲桌子 | 非稳态 | 极短时冲击波 |
| 塑料袋、纸张摩擦 | 非稳态 | 随机频率变化 |
| 讲话中的爆破音(P/K) | 瞬态 | 高频瞬态声 |
| 儿童尖叫声 | 变化快 | 非周期不稳定 |
特点:
瞬态(transient)
不可预测
持续时间极短(几毫秒)
能量突发式增大
对于这种非稳态噪声处理,是比较难处理的,在后续的文章里面,我们再详细介绍这块。
常见降噪处理算法和处理流程介绍
噪声处理,一句话来说,就是把语音信号里面的噪声去除掉,留下纯净的语音信号即可。
常见的语音降噪算法有,我这里介绍的是单通道的处理算法,而且是大概概括一下,本篇文章暂时不做详细的介绍:
-
1、谱减法
-
2、维纳滤波法
-
3、基于最大似然(ML)、最大后验(MAP)、最小均方估计(MMSE)的统计模型法
-
4、贝叶斯估计法
-
5、基于特征值和奇异值分解的子空间法
-
6、音频机器学习模型,代表算法:
goRNNoise(实用、轻量级) DTLN(高质量) DeepFilterNet SEGAN DeepConv-TasNet Demucs
RNNoise(基于RNN,实时降噪)开源地址:
go
https://github.com/xiph/rnnoise?utm_source=chatgpt.com
DTLN(基于双信号转换 LSTM 网络),开源地址:
go
https://github.com/breizhn/DTLN?utm_source=chatgpt.com
DeepFilterNet(深度多帧过滤器,实时优化),开源地址:
go
https://github.com/Rikorose/DeepFilterNet?utm_source=chatgpt.com
webrtc降噪处理流程:
在讲解webrtc中的降噪代码之前,我们要先了解一下webrtc中降噪的总体流程:
-
1、帧分割(10 ms)
-
2、Hann 窗函数
-
3、FFT(分为几个 sub-band)
-
4、噪声能量估计(Min-statistics 或 MCRA)
-
5、计算 SNR(信噪比)
-
6、计算 Wiener 增益:gain = SNR / (SNR + 1)
-
7、应用增益: 低 SNR(吵噪)→ 小增益 高 SNR(有人声)→ 保留语音
-
8、iFFT
-
9、重建时域信号
go
10ms PCM → FFT → 噪声估计 → Wiener 增益 → 降噪频谱 → iFFT → 重建 PCM帧分割(10ms)Frame Splitting:
为什么要分帧?这个肯定是第一眼看到你很疑惑;原因如下:
音频信号是连续的(流),但降噪算法(尤其频域算法)必须一次处理一小段。
为什么 10ms?
因为:语音信号 10ms 内基本视为"平稳"(stationary)
-
FFT 需要固定窗口长度
-
10ms 延迟几乎听不出来(实时处理用)
-
分帧就是把"长波形"切成一页页的小段来处理。
WebRTC 规定,这个是原文,:

go
// APM processes audio in chunks of about 10 ms. See GetFrameSize() for
// details.
static constexpr int kChunkSizeMs = 10;
// Returns floor(sample_rate_hz/100): the number of samples per channel used
// as input and output to the audio processing module in calls to
// ProcessStream, ProcessReverseStream, AnalyzeReverseStream, and
// GetLinearAecOutput.
//
// This is exactly 10 ms for sample rates divisible by 100. For example:
// - 48000 Hz (480 samples per channel),
// - 44100 Hz (441 samples per channel),
// - 16000 Hz (160 samples per channel).
//
// Sample rates not divisible by 100 are received/produced in frames of
// approximately 10 ms. For example:
// - 22050 Hz (220 samples per channel, or ~9.98 ms per frame),
// - 11025 Hz (110 samples per channel, or ~9.98 ms per frame).
// These nondivisible sample rates yield lower audio quality compared to
// multiples of 100. Internal resampling to 10 ms frames causes a simulated
// clock drift effect which impacts the performance of (for example) echo
// cancellation.
static int GetFrameSize(int sample_rate_hz) { return sample_rate_hz / 100; }APM(Audio Processing Module,音频处理模块)以约 10 毫秒为一个音频块来进行处理。具体细节请参阅 GetFrameSize() 函数。kChunkSizeMs = 10:每个处理块的固定时长为 10 毫秒。GetFrameSize() 的作用: 返回 floor(sample_rate_hz / 100) 的结果。 这个值表示:在调用以下 APM 函数时,每个声道要输入 / 输出的采样点数量:
go
ProcessStream()
ProcessReverseStream()
AnalyzeReverseStream()
GetLinearAecOutput()如果采样率能够被 100 整除,那么计算出来的值就与 10ms 的音频长度完全一致。比如:
48000 Hz → 每声道 480 个采样点(等于 10ms)
44100 Hz → 每声道 441 个采样点(等于 10ms)
16000 Hz → 每声道 160 个采样点(等于 10ms)
如果采样率不能被 100 整除,那么得到的帧长度只是"接近" 10ms,而不是严格 10ms。比如:
22050 Hz → 每声道 220 个采样点(≈ 9.98ms)
11025 Hz → 每声道 110 个采样点(≈ 9.98ms)
这些不能整除 100 的采样率,相比那些整百采样率,会导致更低的音频处理质量。 因为 APM 内部必须将其重采样为严格 10ms 的帧长度,这会产生一种类似"时钟漂移(clock drift)"的效应,并且会影响某些算法的性能(例如回声消除 Echo Cancellation)。
GetFrameSize() 的具体实现非常简单: 只返回 sample_rate_hz / 100,也即采样率除以 100。这个结果就是 10 毫秒音频所包含的采样点数量。
go
static int GetFrameSize(int sample_rate_hz) {
return sample_rate_hz / 100;
}其他环节我们详细来看源代码来解读,这里暂时介绍第一个。
webrtc降噪代码工程:
下面是一个最简单的降噪代码工程:
go
// Build AudioProcessing
rtc::scoped_refptr<webrtc::AudioProcessing> apm = webrtc::AudioProcessingBuilder().Create();
webrtc::AudioProcessing::Config cfg = apm->GetConfig();
cfg.high_pass_filter.enabled = opt.hpf;
cfg.noise_suppression.enabled = true;
// Map NS level
if (opt.ns == "low") cfg.noise_suppression.level = webrtc::AudioProcessing::Config::NoiseSuppression::kLow;
elseif (opt.ns == "moderate") cfg.noise_suppression.level = webrtc::AudioProcessing::Config::NoiseSuppression::kModerate;
else cfg.noise_suppression.level = webrtc::AudioProcessing::Config::NoiseSuppression::kHigh;
// AGC2 (recommended over AGC1 for most apps)
cfg.gain_controller2.enabled = opt.agc2;
cfg.gain_controller2.adaptive_digital.enabled = opt.agc2;
// VAD
//cfg.voice_detection.enabled = opt.vad;
// AEC (disabled in this file-only demo; left here for reference)
cfg.echo_canceller.enabled = false;
// 瞬态抑制
cfg.transient_suppression.enabled = true;
// 语音检测
//cfg.voice_detection.enabled = true;
apm->ApplyConfig(cfg);
// 1) 创建并配置 VAD
VadInst* vad = nullptr;
WebRtcVad_Create();
WebRtcVad_Init(vad);
// 模式:0~3,越大越"激进/敏感"
WebRtcVad_set_mode(vad, 2);
const int sample_rate = (int)in.sample_rate;
const size_t channels = in.channels;
const size_t frame_samples = static_cast<size_t>(sample_rate / 100); // 10 ms
const size_t total_samples = in.samples.size();
webrtc::StreamConfig input_cfg(sample_rate, channels);
webrtc::StreamConfig output_cfg(sample_rate, channels);
std::vector<int16_t> out;
out.reserve(total_samples);
size_t frames_with_voice = 0, total_frames = 0;
for (size_t pos = 0; pos < total_samples; pos += frame_samples * channels) {
size_t remaining = total_samples - pos;
size_t this_frame = std::min(frame_samples * channels, remaining);
std::vector<int16_t> frame(frame_samples * channels, 0);
std::memcpy(frame.data(), in.samples.data() + pos, this_frame * sizeof(int16_t));
// In-place process
int err = apm->ProcessStream(frame.data(), input_cfg, output_cfg, frame.data());
if (err != 0) throw std::runtime_error("AudioProcessing::ProcessStream failed");
if (opt.vad) {
auto stats = apm->GetStatistics();
// voice_detected is optional in stats
if (stats.voice_detected && *stats.voice_detected) frames_with_voice++;
total_frames++;
}
out.insert(out.end(), frame.begin(), frame.end());
}官方也有给一个demo学习,但是他不是降噪的工程,我上面是代码基于这个改造得到的:
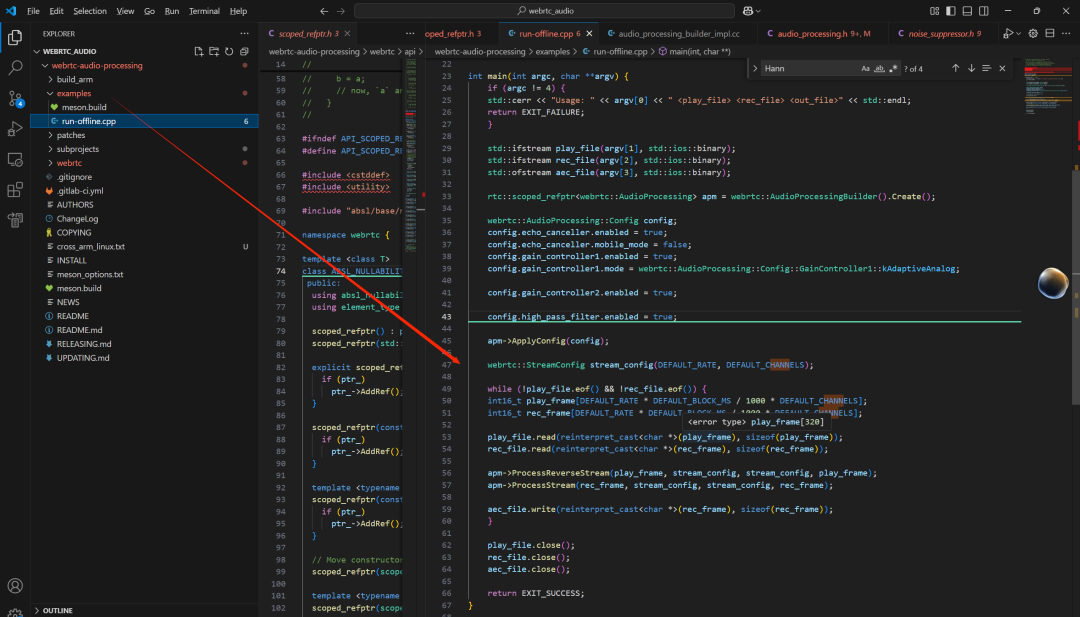
在讲解代码之前,我们先简单来看AudioProcessing降噪结构定义:
go
// Enables background noise suppression.
struct NoiseSuppression {
bool enabled = false;
enum Level { kLow, kModerate, kHigh, kVeryHigh };
Level level = kModerate;
bool analyze_linear_aec_output_when_available = false;
} noise_suppression;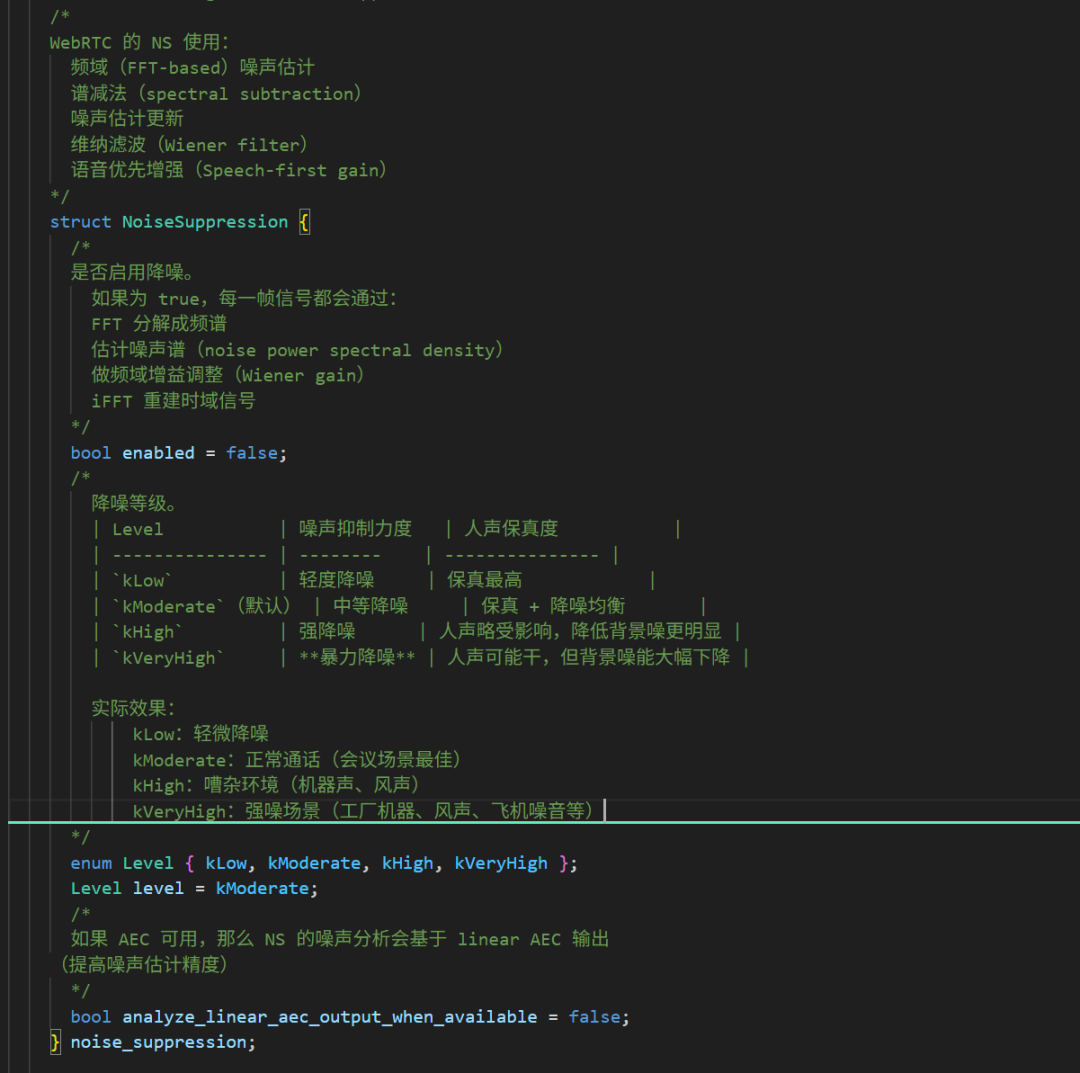
有了这个基础之后,我们开始介绍一下上面的代码,整个代码处理流程:
go
原始 PCM
↓
分帧(10ms)
↓
APM 加工(包含:高通 + 降噪 + AGC2 + 瞬态抑制)
↓
WebRTC Spectral Noise Suppression(维纳滤波降噪)
↓
可选:VAD 检测是否有人声
↓
输出降噪后的 PCM- 1、AudioProcessing(APM)是 WebRTC 音频处理的总控模块
go
rtc::scoped_refptr<webrtc::AudioProcessing> apm =
webrtc::AudioProcessingBuilder().Create();AudioProcessing内部包括模块有:
| 模块 | 功能 |
|---|---|
| HPF | 高通,去低频噪声(风噪、低频嗡声) |
| NS | 噪声抑制(频域维纳滤波) |
| AEC | 回声消除(你这里关闭了) |
| AGC1/AGC2 | 自动增益控制(响度一致) |
| VAD | 语音检测 |
| TS | 瞬态噪声抑制(键盘敲击声) |
目前代码开通的模块:
高通滤波
降噪(NS)
AGC2
瞬态抑制(击键/碰撞噪声处理)
- 2、开启高通滤波器
go
cfg.high_pass_filter.enabled = opt.hpf;//这里赋值为ture高通滤波器的定义:
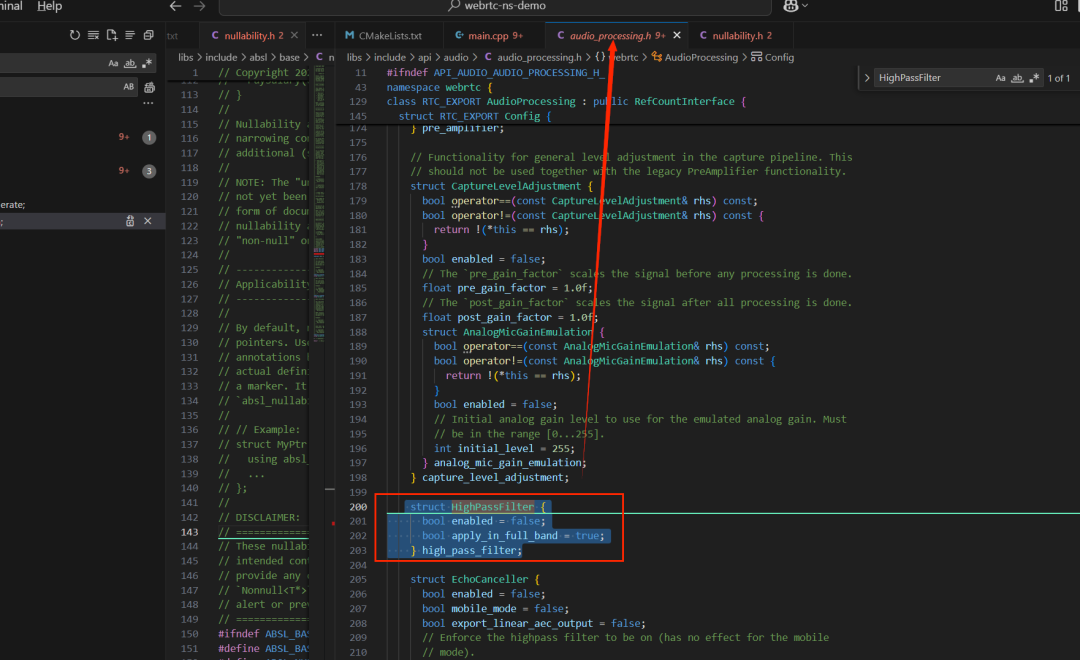
go
/*
高通滤波器在 APM 中是非常重要的基础模块,主要用来:
去除低频轰鸣声(风声、空调声、道路噪声)
去掉麦克风/电源带来的 50/60Hz 嗡声
降低 DC offset(直流偏置)
提升 Voice Activity Detection (VAD) 的准确性;WebRTC 的高通滤波器通常是 90 Hz(左右)截止频率。
Input PCM
↓
[HighPassFilter] ← 你这段配置控制的就是这一步
↓
Echo Cancellation (AEC)
↓
Noise Suppression (NS)
↓
Automatic Gain Control (AGC)
↓
Output PCM
*/
struct HighPassFilter {
bool enabled = false;//是否启用高通滤波器
/*
决定高通滤波器作用在哪个频带。如果为 true(默认):高通滤波器对整段信号进行处理(full-band);也就是说:
所有频率范围的输入信号都经过 HPF → 再进入 APM 其它模块。
如果为 false:高通滤波只应用在音频的"底层带宽"(即低带),通常是 窄带(8kHz) 或 16kHz 的部分段
apply_in_full_band 的含义是:
true:在整个 full-band 上应用 HPF(即对原始全频率信号做一次高通,然后再做分带)
false:只对某一个子带(通常是低频/主带)应用 HPF,其他高频带不单独再滤
*/
bool apply_in_full_band = true;
} high_pass_filter;- 3、开启降噪(Noise Suppression)
go
cfg.noise_suppression.enabled = true;- 4、设置降噪强度(low / moderate / high)
go
if (opt.ns == "low") cfg.noise_suppression.level = kLow;
else if (opt.ns == "moderate") cfg.noise_suppression.level = kModerate;
else cfg.noise_suppression.level = kHigh;| level | 降噪力度 | 声音效果 |
|---|---|---|
| low | 最轻 | 保真度最高 |
| moderate | 中等(默认) | 会议最佳 |
| high | 强降噪 | 有人声变"干"风险 |
| very high | 暴力降噪 | 强噪环境用 |
- 5、开启 AGC2(自动增益控制 2)
go
cfg.gain_controller2.enabled = opt.agc2;
cfg.gain_controller2.adaptive_digital.enabled = opt.agc2;AGC2 特点:
完全数字化
不需要硬件支持
自动让音量保持稳定
适合嵌入式系统、录音文件处理
作用:
防止声音忽大忽小
增强较小的语音
提高降噪后音质
AGC2 与 NS 配合可以达到 专业会议级降噪音质。
- 6、开启瞬态噪声抑制(键盘/撞击噪声)
go
cfg.transient_suppression.enabled = true;TS 模块专门处理:
键盘敲击
物件掉落
咔哒声
爆音
鼠标点按
它能去除这种 "瞬间,高能量" 的噪声。
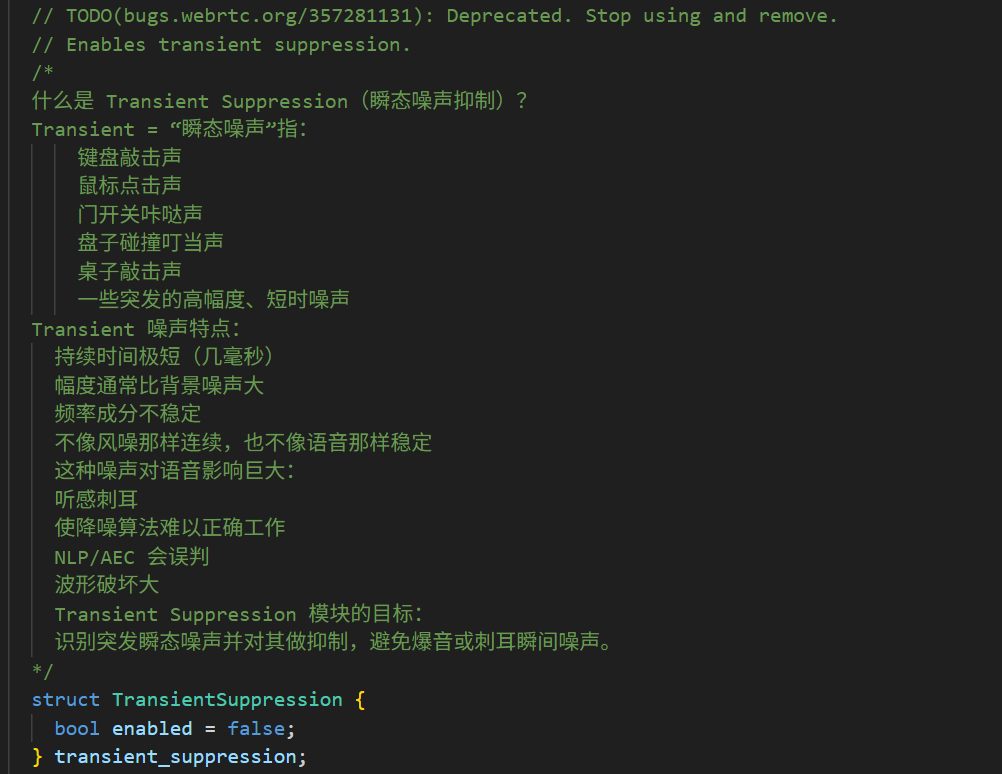
不过这个未来可能是被抛弃,官方后期不会维护这个模块,估计对于处理非稳态噪声,处理效果不是很好,暂时没有测试,后面有测试再和大家说。
- 7、ApplyConfig --- 把设置应用到 APM 内部
go
apm->ApplyConfig(cfg);执行这个之后:
HPF、NS、AGC2、TS 都被开启
APM 内部会创建对应模块
初始化 FFT、噪声估计器、滤波器等
这是开始降噪前必要的一步。
- 8、准备分帧(WebRTC 统一使用 10ms)
go
const size_t frame_samples = sample_rate / 100; // 10ms- 9、10ms 循环:核心处理过程
go
for (pos=0; pos < total_samples; pos += frame_samples * channels)
{
...
apm->ProcessStream(frame.data(), input_cfg, output_cfg, frame.data());
...
}ProcessStream 内部执行哪些降噪算法?
go
Raw PCM
↓
High Pass Filter(高通)
↓
Noise Suppression(频域降噪)
↓
Transient Suppression(瞬态噪声抑制)
↓
AGC2(自适应增益 + 限幅器)
↓
Output PCM-10、可选:统计 VAD(语音检测)
go
auto stats = apm->GetStatistics();
if (stats.voice_detected && *stats.voice_detected) frames_with_voice++;WebRTC 内部会用:
能量判断
频谱判断
多带语音概率
来判断是否为语音帧。
可用于:
静音检测
录音分析
语音触发
自动剪辑无声片段
总结:
上面每一个流程会比较复杂,暂时我们没有看到里面具体是怎么实现,所以后期我们后面深入去追webrtc APM的源码来学习,下期内容,我们来放到板端进行测试一下效果是怎样的!