
序言:过拟合是人工智能训练中的一个常见问题,类似于一位"读死书"的学生,他只能机械地背诵书本内容,缺乏灵活性,一旦题目稍有变化便无法理解。为了解决这一问题,科学家们从人脑的学习方式中获得启发,设计出"随机失活"方法。在学习过程中,随机关闭部分神经元,避免神经元之间过度依赖,从而提升模型的灵活性与应变能力。
随机失活
在本章前面,我们讨论了过拟合现象,即网络可能会对某一类输入数据变得过于专注,而在其他数据上表现较差。为了解决这个问题,可以使用一种叫做随机失活的正则化技术。
当神经网络在训练时,每个神经元都会对后续层的神经元产生影响。随着时间推移,尤其是在较大的网络中,某些神经元可能会变得过于专注,这种影响会继续向下传播,最终导致整个网络变得过度专注,出现过拟合问题。
此外,相邻的神经元可能会拥有非常相似的权重和偏差值,如果不加以监控,整个模型会变得过于依赖那些神经元激活的特征,导致模型整体变得过于专注。
举个例子,看看图3-21中的神经网络,它包含2个、6个、6个和2个神经元的层结构。中间层的神经元可能会最终拥有非常相似的权重和偏差值。
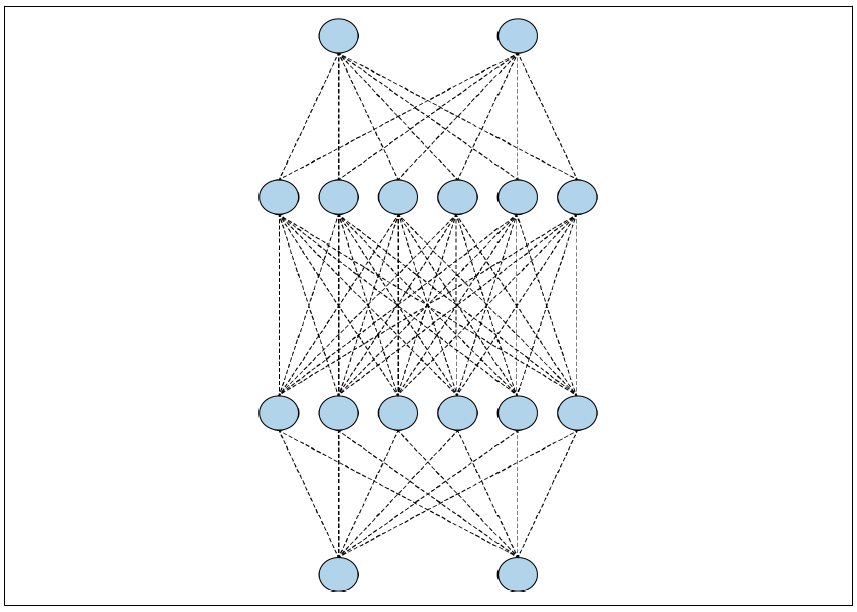
图3-21. 一个简单的神经网络在训练时,如果随机去除一些神经元并忽略它们,这些神经元对下一层神经元的影响会被暂时阻断(见图3-22)。
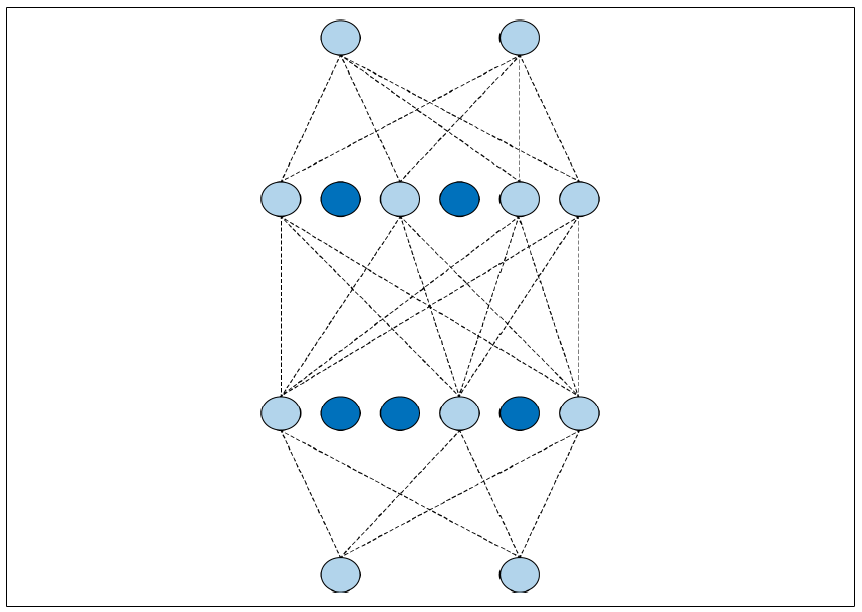
图3-22:一个带有随机失活的神经网络这样做可以减少神经元过于专注的风险。网络虽然依然学习相同数量的参数,但在泛化能力上会更好------也就是说,它对不同输入的适应能力会更强。
随机失活的概念由Nitish Srivastava等人在2014年的论文《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》中提出。
要在TensorFlow中实现随机失活,可以直接使用一个简单的Keras层,如下所示:
tf.keras.layers.Dropout(0.2),
这样可以在指定层中随机失活指定比例的神经元(这里是20%)。需要注意的是,找到适合你网络的失活比例可能需要一些实验。
举个简单的例子来说明这一点,比如第二章中的Fashion MNIST分类器。我将改变网络定义,增加很多层,如下所示:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(64, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
将其训练20个周期后,训练集的准确率约为94%,验证集的准确率约为88.5%。这是潜在过拟合的一个迹象。
在每个全连接层之后引入随机失活,如下所示:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(64, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
当在相同的数据上以相同的时间训练该网络时,训练集的准确率下降到约89.5%。验证集的准确率保持基本不变,为88.3%。这些值彼此更接近;因此,引入随机失活不仅证明了过拟合正在发生,而且使用随机失活可以通过确保网络不会对训练数据过度专注来帮助消除这种模糊性。
在设计神经网络时要记住,训练集上的高准确率并不总是好事。这可能是过拟合的一个信号。引入随机失活可以帮助你消除这个问题,从而在没有这种虚假安全感的情况下优化网络的其他方面。
总结:随机失活在模型训练中至关重要,否则我们训练出的模型就像'死记硬背'的学生,只会对付特定的数据,无法应对真实应用场景中的变化。通过随机失活,我们让模型在学习过程中更加灵活,从而提高它在不同数据上的适应能力,避免成为'傻子模型'。
下一篇我们将讲解如何在TensorFlow Datasets中使用公共数据集进行训练"。它指的是利用TensorFlow Datasets库(一个提供多种预处理数据集的库)来访问和加载公共训练数据集,以便在模型训练中使用。