项目目标
需要使用的技术栈:

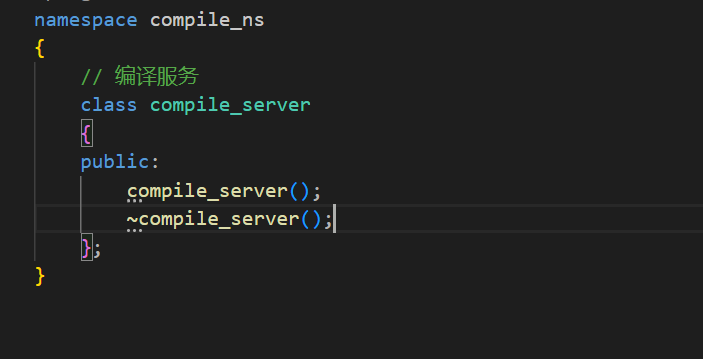
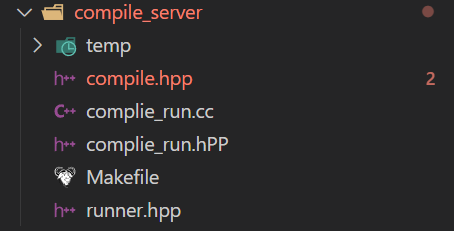
这个项目共分成三个模块第一个模块为公共的模块,用于解决字符串处理,文件操作,网络连接等等的问题。
第二个模块是一个编译运行的模块,这个模块的主要功能就是将用户的代码收集上来之后要在服务器上形成临时文件,进行编译最后运行,最后的还有一个Judge模块采用的是MSVC的模式来调用后端的编译模块,以及访问文件和数据库把题目列表和编辑界面展示给用户,让用户能进行正常的操作。

最后运行会形成两个服务器,两个服务器之间使用网络套接字进行通信,这样就能将遍历服务部署在服务器后端的多态机器上oj_server只有一台,这样就能让oj_server自动的负载均衡的选择后端的编译服务,能够以集群处理的方式对外输出oj服务。这个项目的可扩展性很强。
项目所需技术栈

部分前端内容只做了解和简单使用。
开发环境:

这里先创建好项目的目录,然后连接到VScode上。
然后建立三个模块目录(common公共方法都放在这个模块中,oj_server(判题是否正确的服务),compile_server(编译代码运行的模块))。
然后增加一个ReadMe.md,为项目做简单说明。

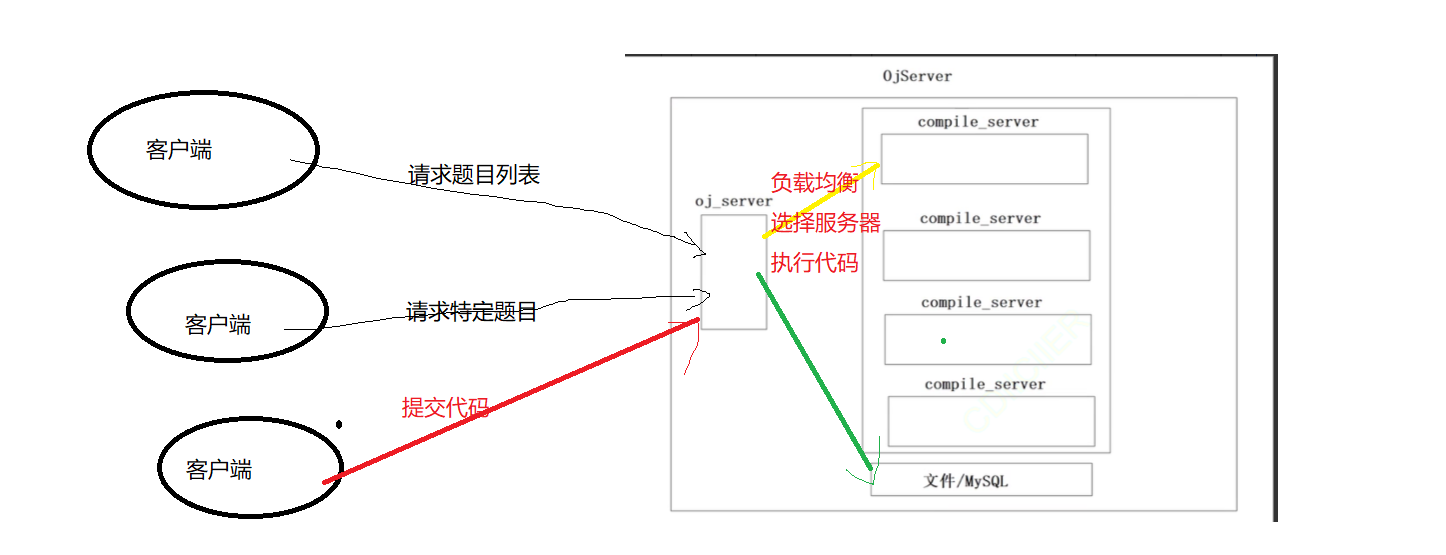
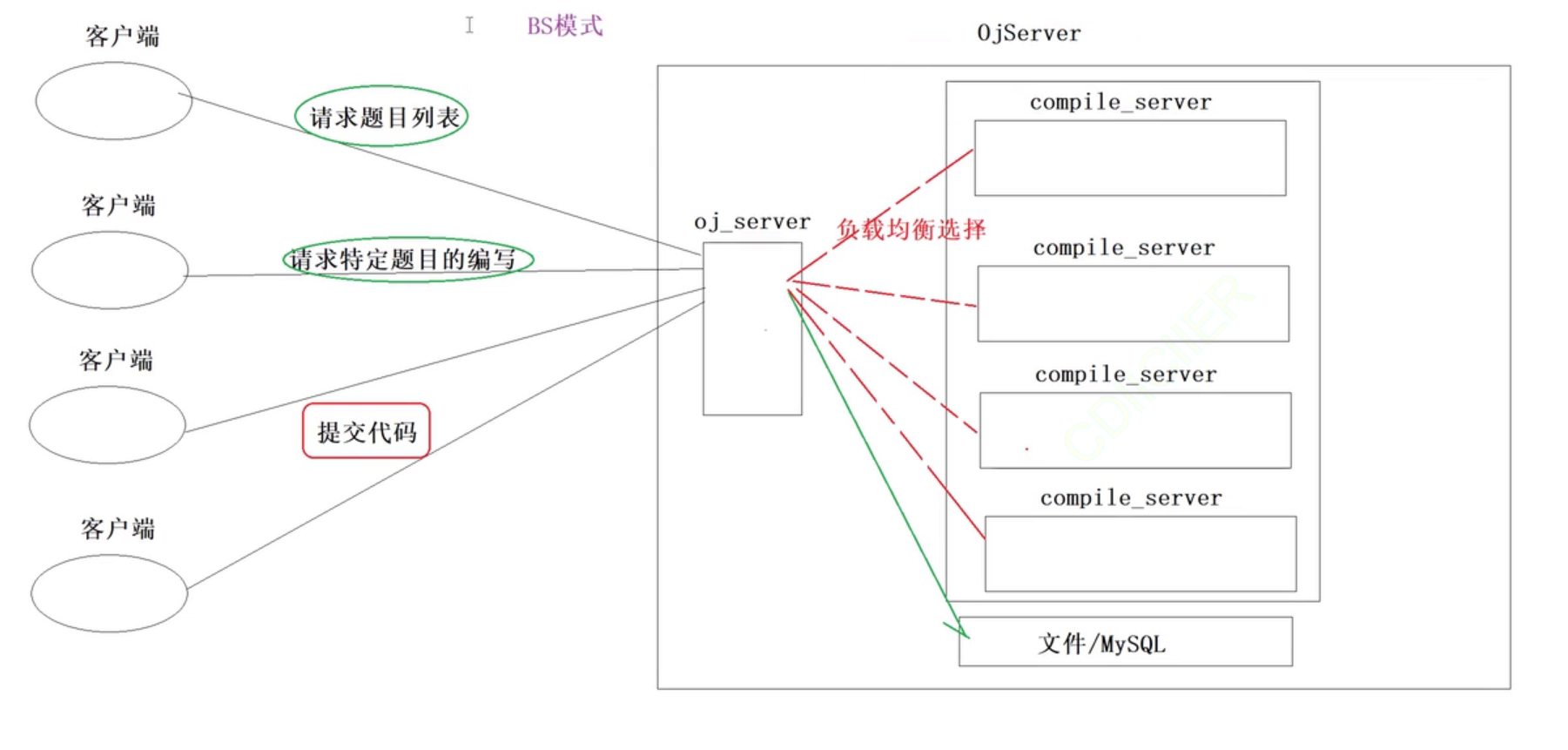
以上就是这个项目的宏观结构。下面使用图像表示一下:
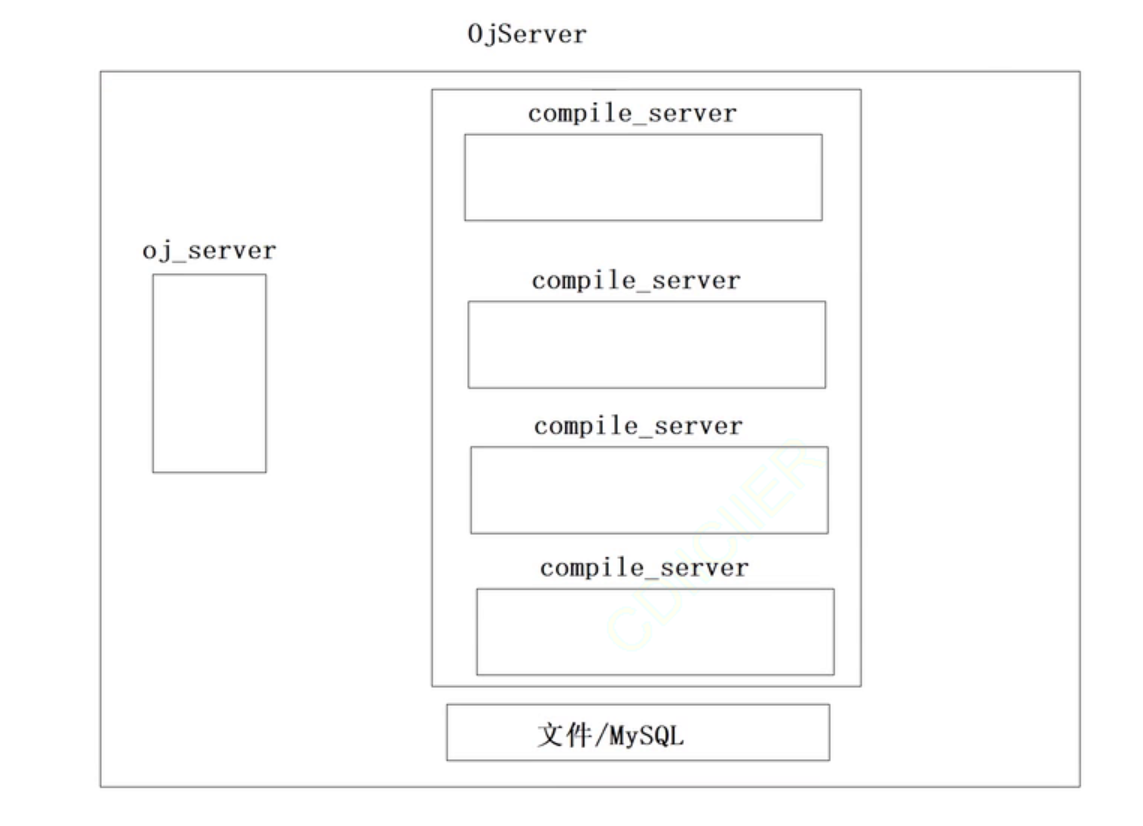
以上整体是一个oj服务,其中有两个重要模块一个是oj_server(提供题目,给与客户端编写代码的功能,可以不止存在一个),然后是编译和运行代码的模块,然后还有文件/数据库里面保存的就是题目。
然后如果客户端只是为了获取题目列表或者请求特定的题目的话,此时的oj_server不需要调用编译和运行的模块而是去到文件中获取题目列表或者特定的题目,然后返回给客户端。
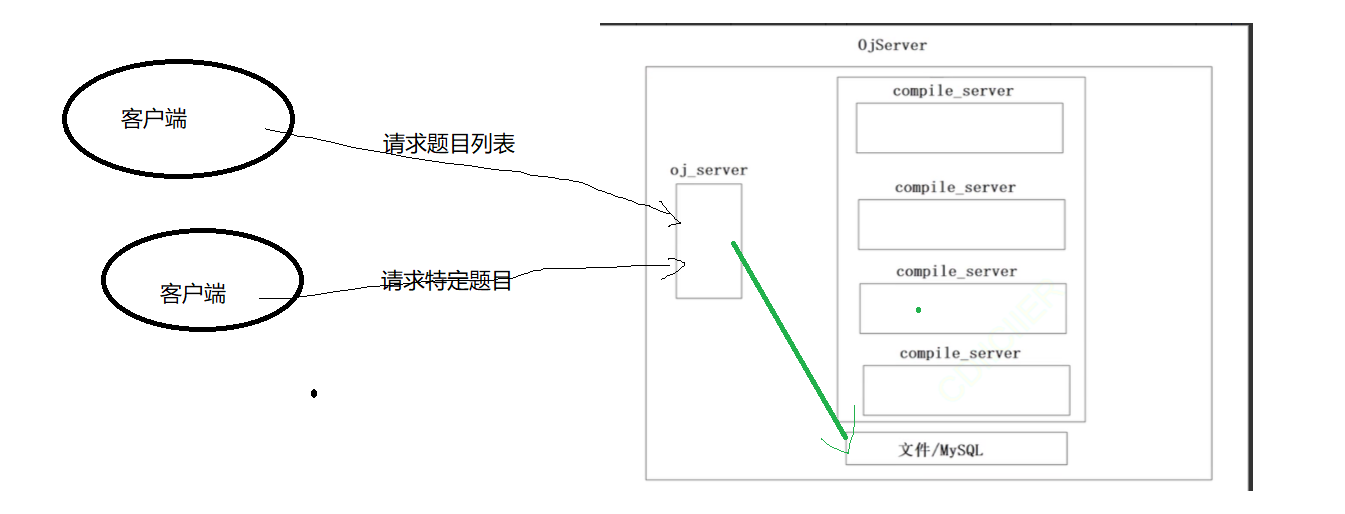
如果客户端时提交代码:就需要负载均衡的选择服务器执行代码,然后将结果和题目的正确结果做判断判断客户端题目是否编写成功,如果失败就返回失败的原因。成功则返回成功结果
这种模式就是BS模式:
下面先编写compile_server模块(因为这个模块的功能较为独立,只需要编译运行代码,以及接收请求就够了),编写完成之后再去编写oj_server模块。最后再去设计前端的内容。
这张图就是项目编写宏观结构的图形化:
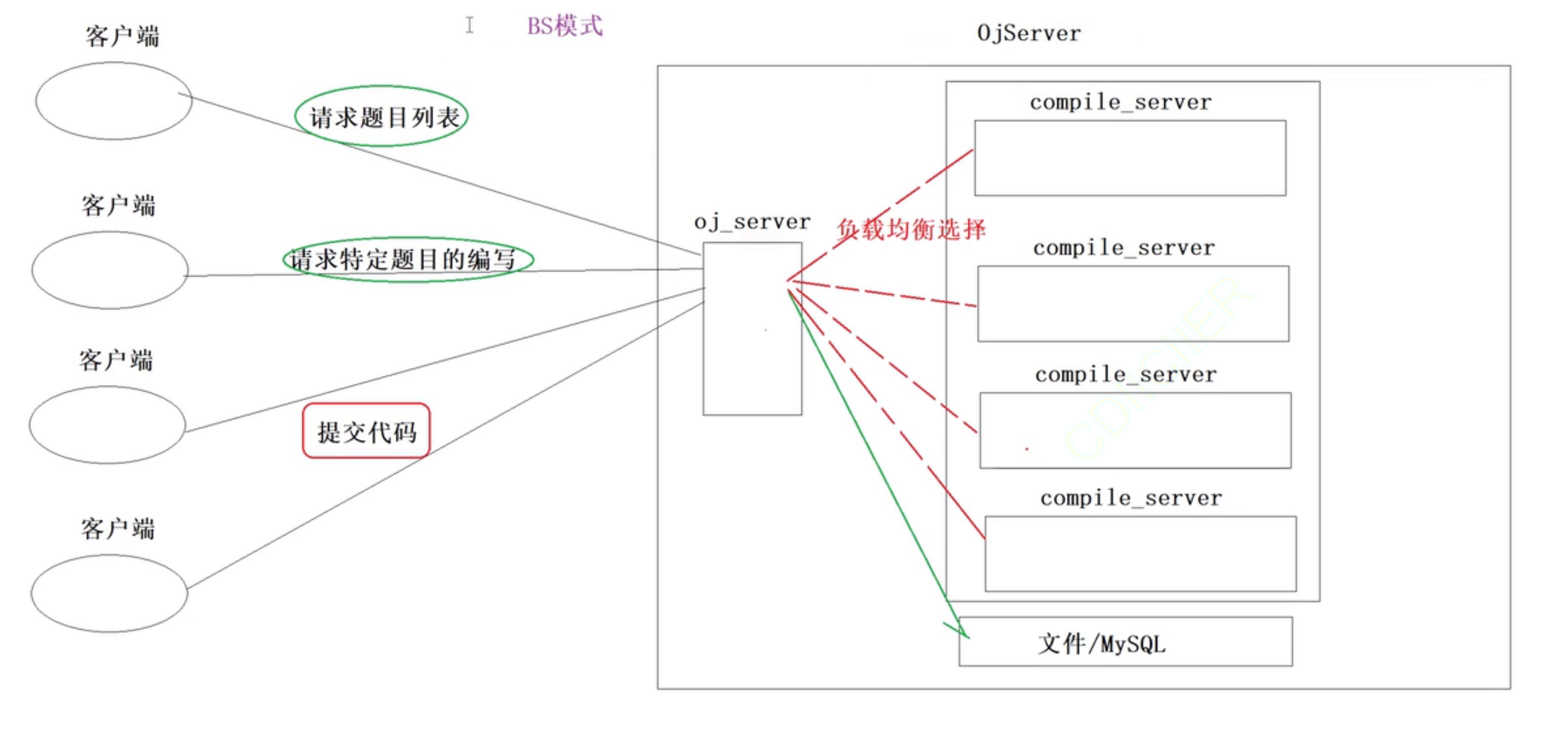
下面是编写思路:

对于这个项目只实现了:

compile_server服务设计
这个模块提供的服务如下:

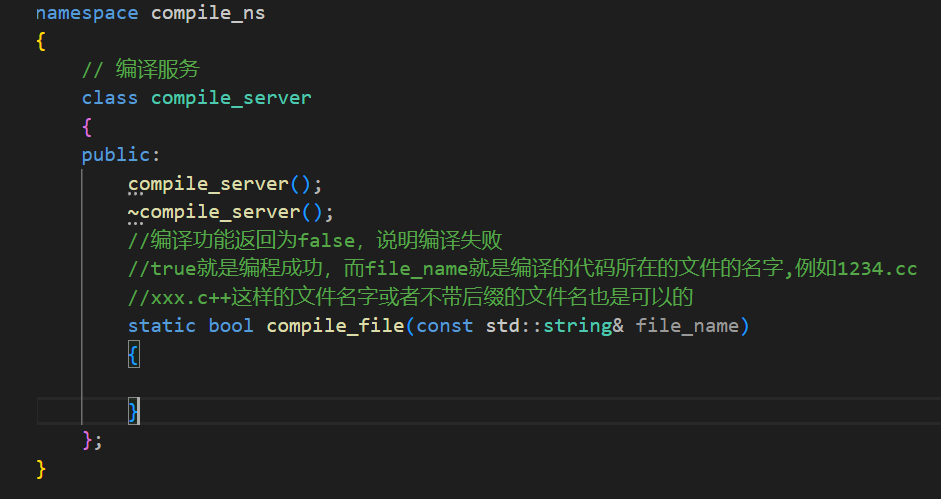
下面就是编译模块需要的源代码文件建立出来。
首先需要编译的服务所以需要一个编译服务的hpp文件。然后再写一个runner.hpp(提供运行代码的服务).有了两个服务之后需要对外提供使用接口,也就是整合上面两个功能的hpp文件,需要一个complie_run文件。虽然现在这个服务的基本功能已经具有了,但是不要忘了这个服务是需要作为一个网络服务而进行的,所以这里还需要一个源文件compile_server.cc用于接收网络请求,并且调用上面的三个源代码,来完成编译和运行代码的功能。
最后还需要一个Makefile文件
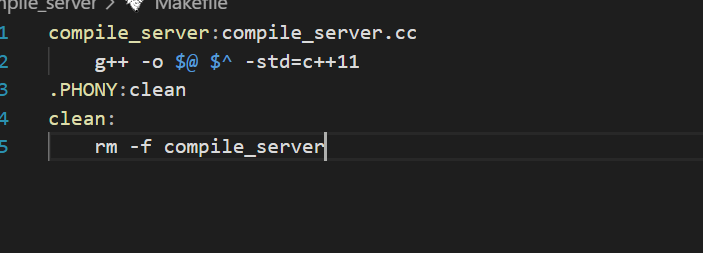
编写这个服务一定会使用很多的库,之后要使用了再加即可。
这三个hpp功能首先完成编译的功能,这里我们有两个网络服务第一个网络服务也就是现在正在编写的服务用于接收网络请求,然后根据网络请求形成代码文件,编译运行,然后将运行结果以响应的方式返回去,另外一个网络服务(oj_server)的作用就是接收客户端发送的请求,根据客户端的请求,决策是否需要调用编译服务,调用编译服务就接收编译结果然后返回给用户,不需要调用编译服务就根据用户的请求,返回题目列表,或者特定的题目。
compile.hpp
需要注意这个文件只负责代码的编译。为了更好的完成这个功能所以会起一个命名空间,然后根据面向对象的原则写一个编译的类。下图中的命名空间名字不太好,后面我改成了ns_compilefunc
然后就是编译功能了,在写这个功能之前要知道一个点,那就是这个服务被调用的时候oj_server一定会将用户的代码以网络请求的方式发送给这个编译服务。经过主函数的处理之后,到这里我们可以认为这个服务已经得到了用户的代码。然后我们知道要编译代码就需要有临时文件,这里我不打算将创建临时文件的功能放在这里,所以这里假设已经存在一个临时文件了。临时文件和代码都已经有了下面就是进行编译了。而编译的结果就两个:要么编译成功,要么编译失败(告警也是归类于失败的)。当编译失败的时候回想stderr中打印失败的原因。对于这个编译模块来说,只关心编译是否成功,出错的原因是什么这个功能是不关心的。所以为了最后能够知道错误的原因,需要形成一个临时的文件,用于保存编译出错的结果的。
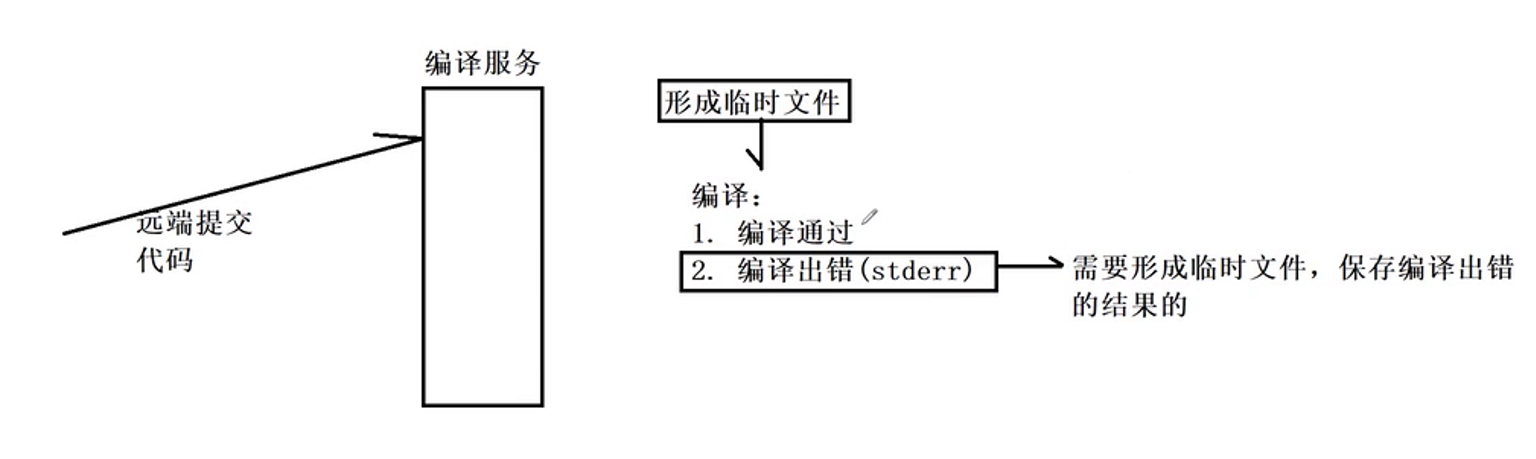
既然要编译那么是提供编译服务的这个进程取执行编译的功能吗?很显然不是如果是这个编译服务的进程去执行编译的功能,从系统编程的角度来说就是要进行程序替换,那么这个编译服务就无法接收远端提交的代码了,所以这里需要fork子进程去完成编译工作:
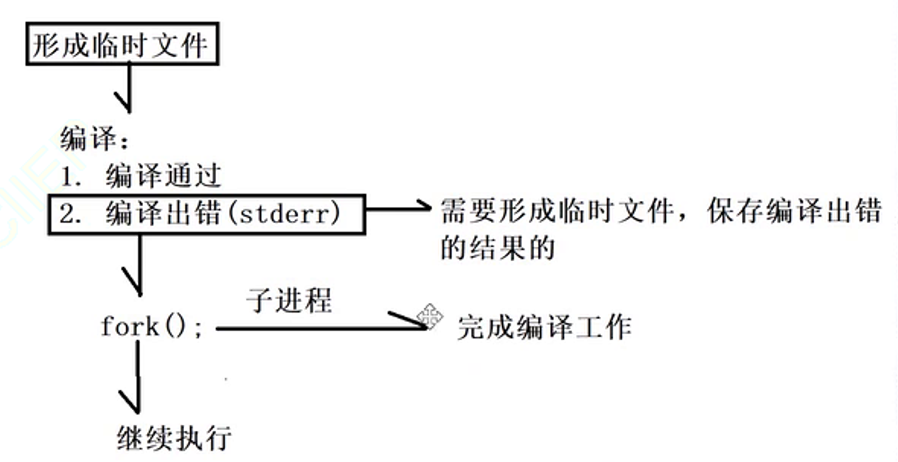
子进程如果编译错误就会往stderr中打印错误的原因,此时又想要将结果保存到临时文件中,所以需要进行文件fd的重定向。
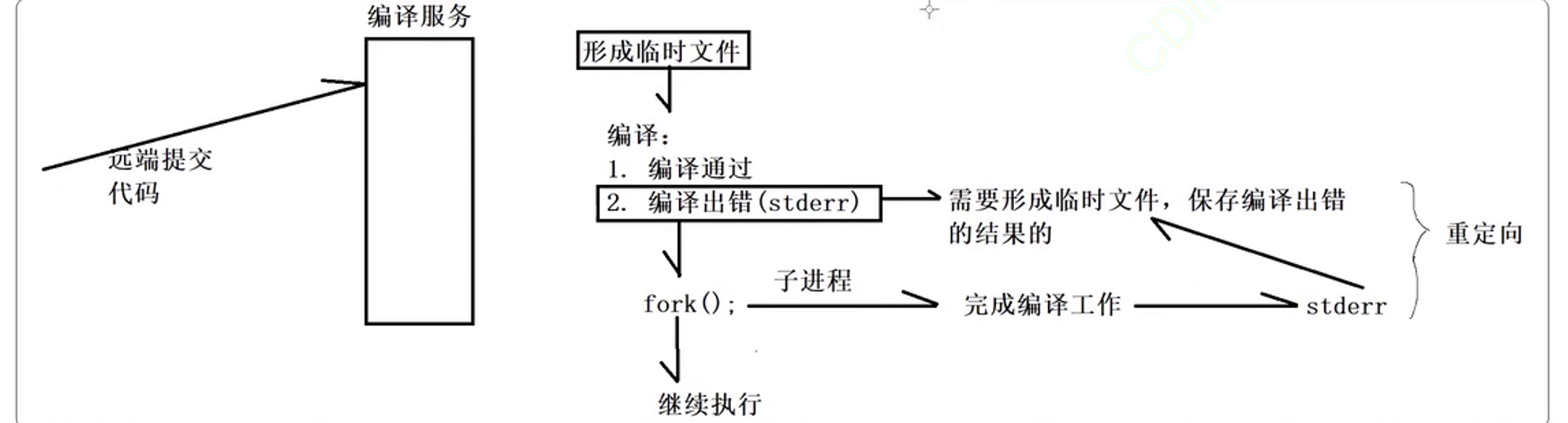
下面就是来完成基本的代码的编写了。
只是一个编译的功能自然是不需要成员函数的,然后就是要为外部提供编译的方法了,这里有两种做法,第一种:以对象的方式呈现给外部,当然也可以只提供功能。
这里只提供功能。
子进程要进行编译自然是要调用g++去进行编译了,而调用g++的方法自然是使用程序替换了,但是程序替换的函数有下面这些,要使用哪一个呢?这里我只想通过g++就直接去调用g++编译器,而不需要带上什么冗余的其它的路径。
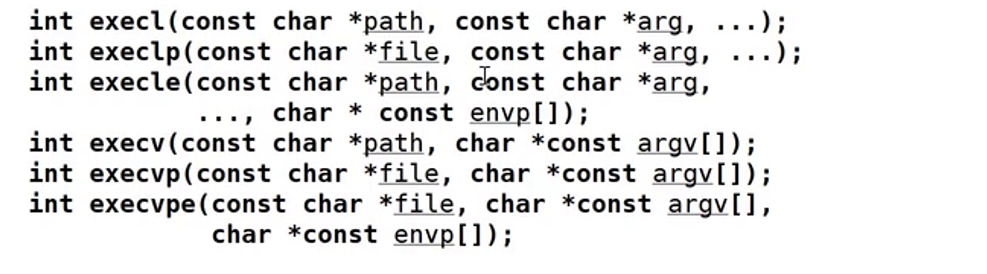
而带path的程序替换是需要带上路径的,所以这里选择的是最后带p的程序替换函数那么是execlp还是execvp呢?这里选择使用execlp。
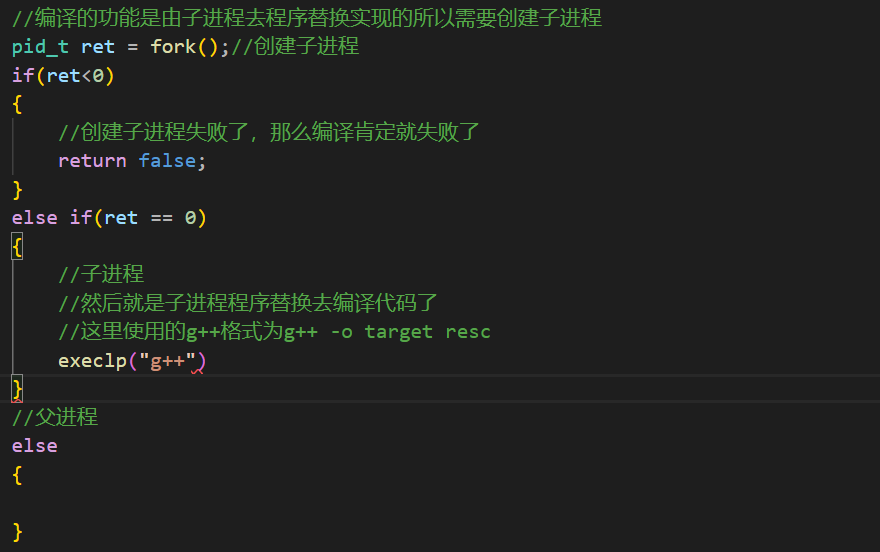
现在根据g++的使用格式我们需要知道源代码文件所在的路径,已经生成的可执行程序放在那里的文件,这就意味着这里会产生临时文件。同时因为远端传过来的是一个文件(默认文件都是不带后缀),也需要一个地方储存,所以这里需要在创建一个文件夹用于储存这些临时文件。
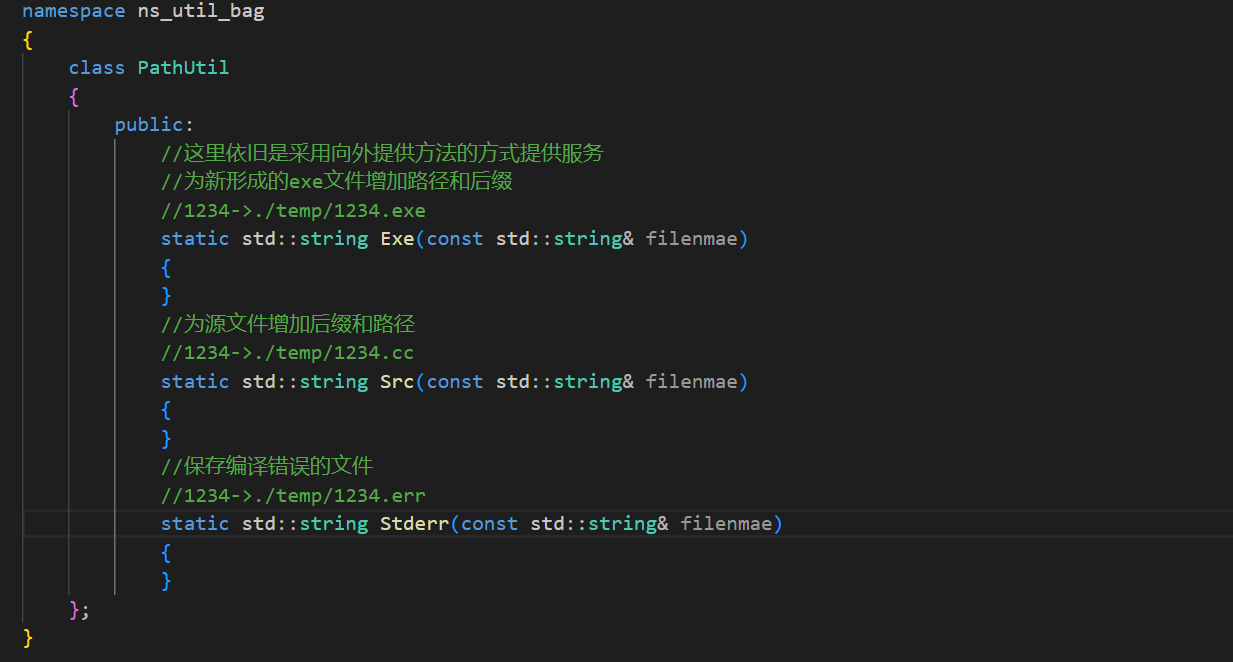
假设这里的file_name = 1234,那么这里需要做的就是如下:

现在编译成功要形成的文件名字已经有了,错误时要写入错误信息的文件也有了,源代码文件1234经过变化之后需要变成1234.cc。
重新排序之后也就是这样,首先1234这个文件是在./temp中的,所以子进程首先要给这个文件加上.cc后缀,然后根据file_name形成剩下的.stderr文件和可执行程序的文件。这些文件都需要增加路径和后缀。
在这个过程中就出现了第一个需要写到comm模块中的方法,因为外部在传递file_name的时候可能不会增加后缀和路径,需要我添加后缀和路径,而这个功能不止编译服务需要,运行模块可能也需要这个服务,编译和运行服务的整合服务可能也需要这个功能,所以这里需要将这个功能写到comm中去。

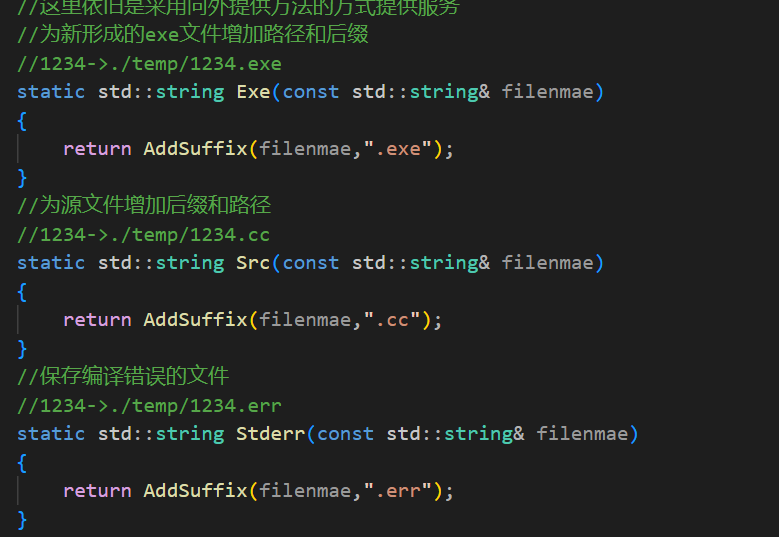
至于方法的具体实现之后再来写。这样路径拼接功能就完成了。
现在再回到g++函数处就可以继续了。首先就是在这个compile.hpp中引入路径拼接这个功能增加头文件和是释放命名空间(using namespace)。
然后就来完成g++的程序替换了:

然后来完成路径拼接这个工具类的函数。因为对于每一个文件而言要填到的路径都说是一样的,所以这里将路径作为了一个const string的全局变量,然后因为三个函数具有相同的逻辑所以这里再写一个辅助函数。

然后三个工具函数就可以通过调用这个辅助函数完成减少重复代码的编写:
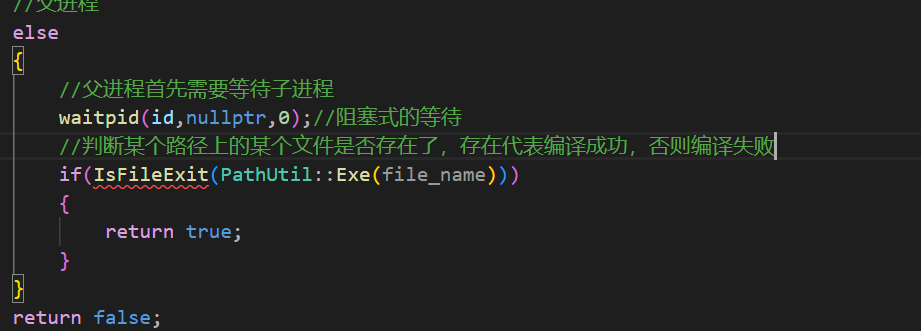
现在准备工作就基本完成了。
现在对于编译功能来说,已经能够完成编译了,但是编译的结果怎么样,是否出错,也是需要告诉父进程的,所以父进程需要等待子进程。在等待完成之后,需要判断编译是否成功,这里不使用子进程的退出码来判断,如何判断呢?如果可执行程序成功创建了,那么自然编译成功了,没有创建出来编译自然错误了。所以这里通过判断某个文件是否存在来判断编译是否成功。通过这个原理就能够知道了子进程程序替换的退出码是不重要的,而子进程程序替换是可能失败的,所以最后写一个exit让子进程在替换成功/失败后都不再往后走了。 然后父进程通过判断某个文件是否存在来判断编译是否成功
因为这个判断某个文件是否存在的功能其它的模块可能也需要所以我依旧是将这个功能写到comm中。
下面就是判断某个文件是否存在的代码要如何写了。
对于某个文件是否存在可以使用打开这个文件的方式来判断,如果打开失败那么这个文件自然不存在,但是这种方法过于暴力了。这里使用一个接口:

这个接口的第一个参数是某个路径上的某个文件,第二个参数是一个输出型参数。struct stat结构:
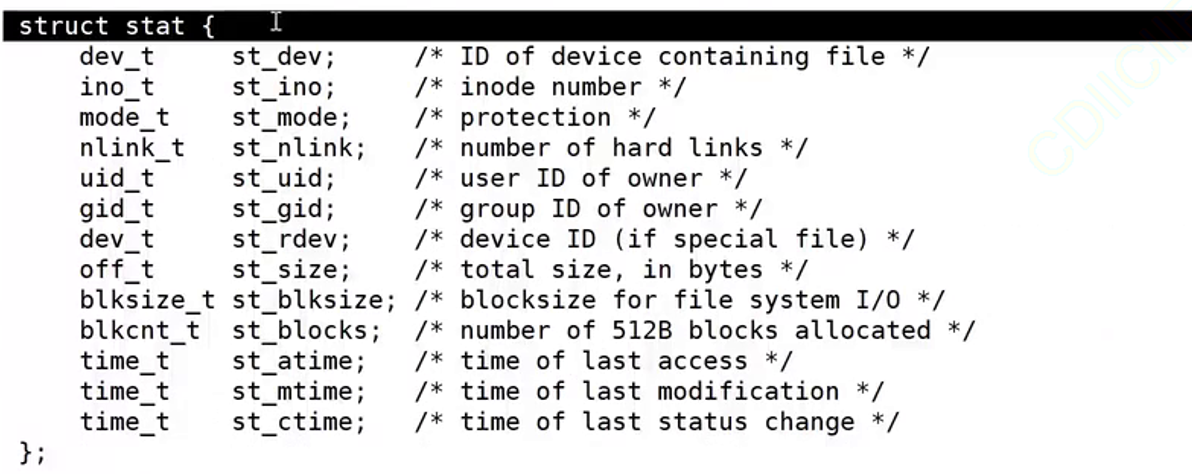
这个接口的作用就是获取某个文件的某个属性,获取到的属性就放在这个输出型参数中。文件的acm时间文件的inode文件的大小等等都在这个结构体中有。这个函数的返回值是获取文件属性成功了返回0,失败-1被返回,错误码被设置。文件存在才能获取成功否则就是文件不存在。
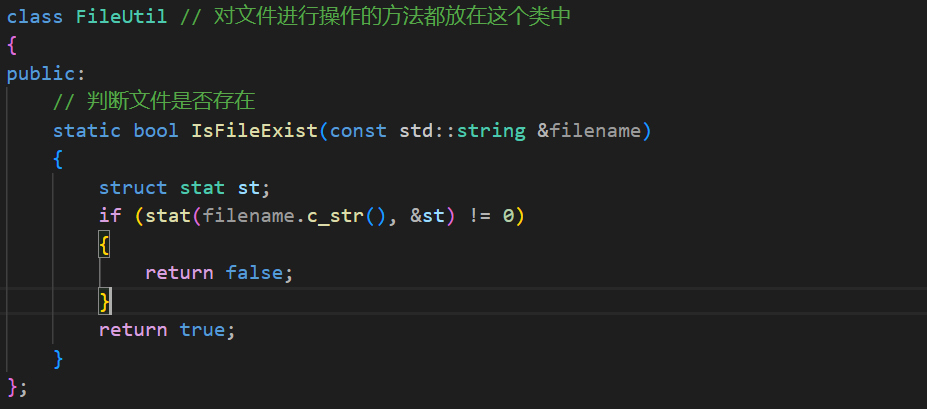
然后在compile中调用这个函数。

到这里编译的主体逻辑就已经完成了。但是如果编译出错了,g++会打印出错的信息。现在需要这个信息,而g++打印的信息是往stderr中打印的,所以子进程在进程g++程序替换之前,需要进行将stderr进行重定向。同时打印错误文件将错误信息写到这个错误文件中。

下面开发一个日志系统,再开发完成之后加入到这个服务当中。
日志系统的开发
因为日志肯定不止一个模块需要使用,所以这里我将日志写到comm中。
对于一个日志来说首先就是日志的等级了。

然后就是日志函数了,这里我打算做一个开放式的日志函数。
在使用日志的时候像下面这样去使用
LOG()<<"错误信息" ,所以Log这个函数最后的返回值一定是一个std::cout。

下面来编写日志的功能,首先就是让日志信息增加等级,错误文件的名字,和错误的行号:
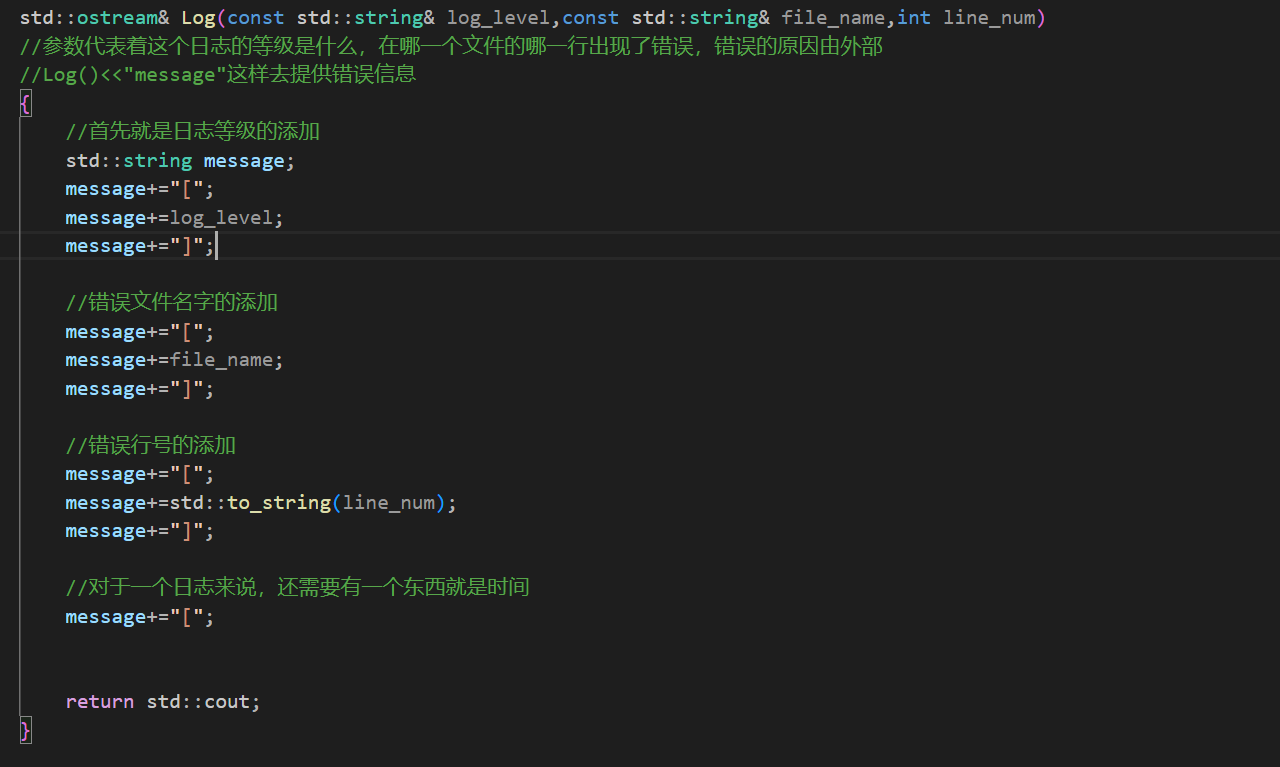
但是对于日志来说还需要一个时间,获取时间这个功能我打算将其作为一个公共的组件,所以这里再去util中写一个获取时间的工具。

至于这个函数的时间之后再去做:
下面就是将这个函数放到log中。

最后使用std::cout的原因在注释中写明了。这样就能开放式的拼接错误信息,这就是一个开放式的日志函数。
但是在使用日志函数的每次都要Log()然后传递一大堆的参数去调用,能否直接LOG(<日志等级>)去使用呢?当然可行。

最后是FILE 和 LINE 是 C/C++ 预定义的宏,它们分别用于获取当前源文件名和当前源文件的行号。
FILE:它会在预处理时被替换为包含当前源文件名的字符串字面量。在编译时,它表示正在编译的源文件的名称,通常是绝对路径或相对路径。LINE:它会在预处理时被替换为当前源文件的行号。在编译时,它表示代码中LINE出现的地方所在的行号。
这两个宏通常用于调试和日志记录,以便在输出中包含有关源文件和代码位置的信息,有助于快速定位和修复问题。
下面就是GetCurrentTime函数的实现了。
获取时间有很多的做法,比如c语言就提过了time函数去获取时间
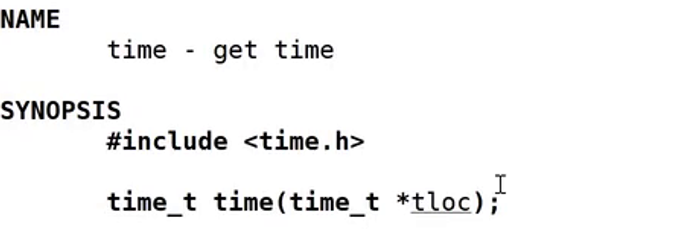
time_t就是一个长整数时间戳,这里我打算使用下面的函数:
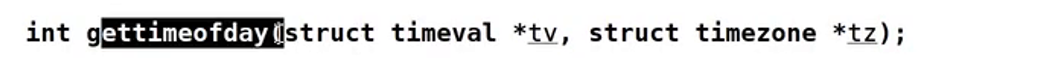
第一个参数是一个输出型参数会输出当前的时间,而第二个输出型参数输出的是一个时区这里不关心,结构体中的成员:

这意味着需要我传入这个结构。其中这两个成员中的第一个就是秒数(代表从1970年到现在累计的秒数为多少),第二个参数为微秒,这个参数不使用暂不做处理。
对于gettimeofday这个函数的返回值成功返回0,失败返回-1,但是这里一般不关心。
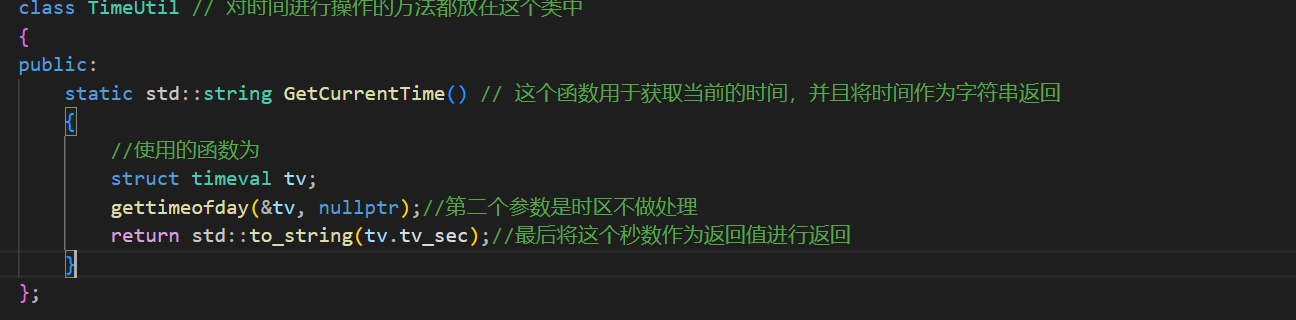
现在日志函数已经完成了,就可以将日志函数添加到编译功能中了
将日志添加到compile中
首先如果子进程创建失败,自然当前用户的请求无法在继续了,但是不会影响整体服务的运行:

然后就是没有成功打开储存错误信息的文件(创建错误信息的文件失败了)。此时就意味着编译可能成功(用户的请求能够完成),也可能失败。所以这里的等级为warning。
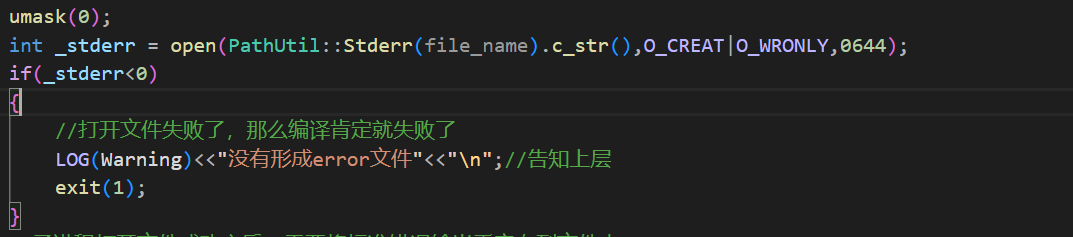
这里的umask是为了让0644创建的错误文件的权限是正确的。让创建的错误信息文件不会受到平台的约束。
然后就是如果g++编译器的路径或者g++本身没有安装导致程序替换出现错误,也需要打印错误信息。因为程序替换成功是不会有日志打印的。

然后走到最后但是没有形成可执行程序,也需要打印日志。

最后如果形成了可执行程序,那么就带上一个Info信息。因为是开放式的日志还可以带上源文件的名字。

日志功能也就加入到编译功能中了。到这里为止,编译功能就完成了。
测试编译功能
因为当前已经存在了编译的功能只要给这个编译的功能调教文件名字即可。
将这个测试代码放到compile_run.cc中
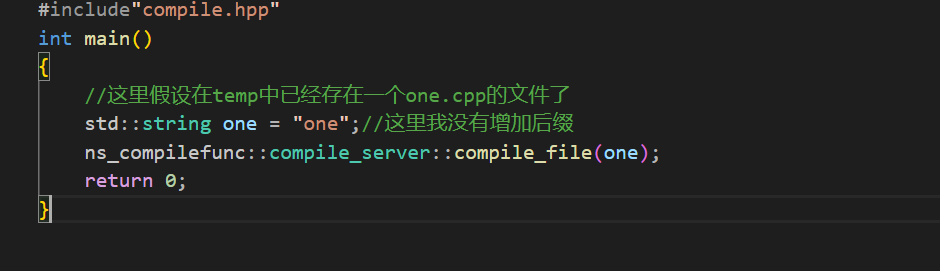
然后下面是one.cpp的内容:
下面就是编译测试运行了:


one.exe文件确实也存在了,运行一下这个exe文件

运行也是可行的。
那么如果one.cc文件如果存在问题,会怎么样呢?
再次运行编译功能:

再去看一下one.err中是否存在失败的原因:
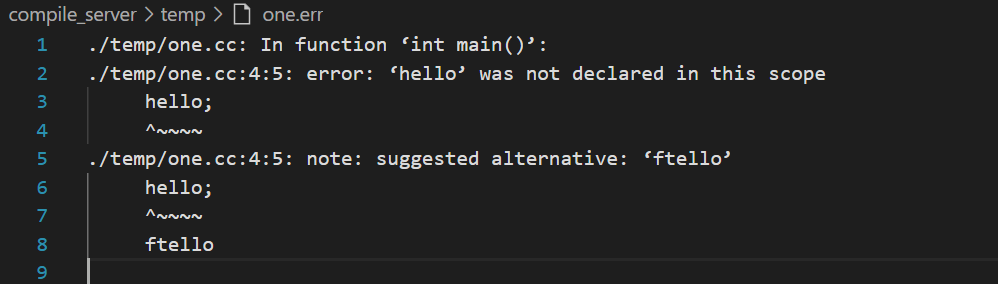
确实存在了。
同时创建的错误文件的权限也是正确的:

到这里编译功能就测试完成了。也就说明基本的编译功能就没有问题了。而整个编译服务不仅需要完成编译还需要运行功能。
到这里为止完成的主要功能就是一个在特定目录下提供特定后缀的c++文件能够完成编译,以及一个开放式的日志功能也有了。
到这里为止编译功能的代码和宏观图像就完成了。
宏观图:
代码就是上面的代码。
runner(运行)功能的编写
大概的思路为:你要运行就要告诉我你要运行的可执行程序的名称,对于runner而言也不需要可执行程序的后缀,你只需要给我文件名我也可以通过公共模块中的拼接功能自动的拼接可运行程序的名称,然后内部运行这个程序即可,运行程序也需要内部创建子进程,然后让子进程程序替换去执行目标程序。而运行的结果也有三种:运行完结果对,运行完结果不对,以及异常,这三种结果如何处理呢?
这些问题待会处理,首先要明确一点,对于运行功能来说,也只需要告诉runner你要运行的文件名就可以了,不需要说明后缀,后缀可以通过comm中的字符串拼接功能区完成。
下面就是在ns_runner这个命名空间中,runner这个类提供的服务函数了。

这个函数的返回值不是bool。

简单原因上图,更深的原因之后说明。
然后就是对于三种运行结果的思考了:

然后对于这个运行服务来说需要知道可执行程序文件的名字(不需要后缀)。除此之外当一个可执行程序运行的时候会默认打开三个文件流:标准输入,标准输出,标准错误。
如果想要给一个正在运行的程序输入参数,那么就需要使用cin/scanf输入参数,但是在oj当中大部分情况下标准输入是不进行考虑的,因为当程序提交完成之后,提交给上层,上层去运行这个程序,输入程序一般不做,但是在力扣的某些题目中是能够让用户去输入一些参数,然后将运行结果返回给用户的。也就是用户的自测试功能此时就需要处理标准输入,我的这个在线oj项目没有这个功能所以对于标准输入时不处理。也就是用户无法指定测试用例,全部由上层的服务来指定测试用例。
标准输出:代表着程序运行完成,输出结果是什么
标准错误:代表程序运行时的错误信息。

在这个项目中,我打算设计三个和当前运行程序名相同的文件,将三个流的信息都放到这些同名文件中,之后如果想要查看这个三个流中的数据,直接扫描这三个文件即可。
到这里就能知道对于Run函数来说,不关心代码跑完的结果是否正确,重点关注代码能否跑完。然后将三个文件流的信息都写到对应的临时文件中。
那么在编译功能处产生的错误文件就不能时StdErr了而应该是CompilerError。
所以修改编译服务中错误文件名称的代码:

这里我也修改了一个StdErr函数:

然后在comm中增加这个函数,同时编译服务产生的错误文件的后缀也不应该是err了,

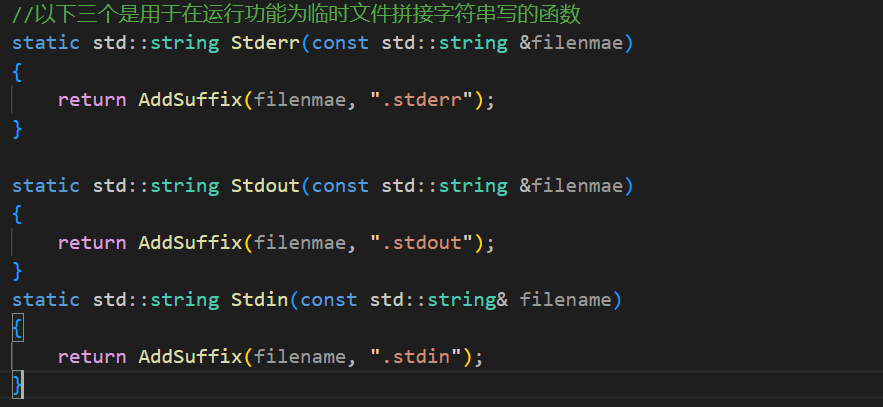
而之前也说过了在Run中需要使用到三个临时文件用于储存标准输入,标准输出,标准错误流中的数据。对于临时文件名字的拼接也是需要的,所以需要在工具类中再增加三个函数用于拼接这三个文件名(标准错误已经有了)
然后就可以正式的来写Run函数了。
而需要运行的程序的名字使用之前写的Exe即可。
然后就是拼接出三个需要的临时文件名字了:

第一个是可执行程序的名字
对于Run函数来说,只考虑在运行的过程中是否出现异常即可。而对于其它的信息直接写到三个临时文件中即可,为了写文件所以需要先打开这三个文件。再打开文件的时候也是在创建这三个文件。

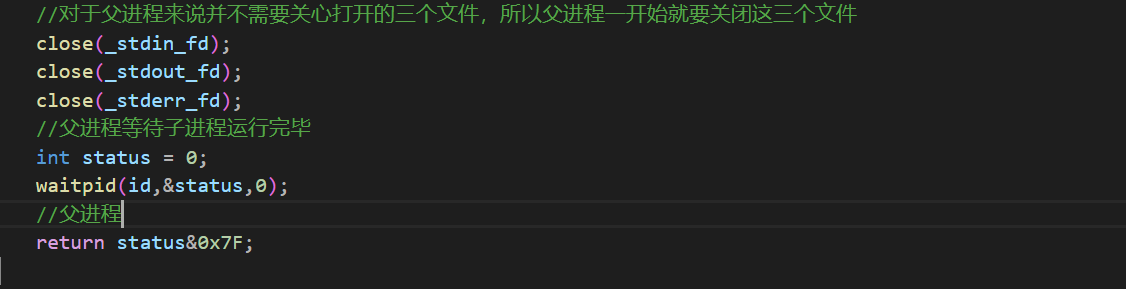
然后对于父进程来说,并不需要关心这个三个文件所以父进程一开始就直接关闭这三个文件fd

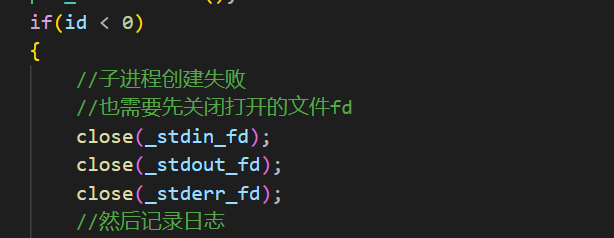
同时如果创建子进程失败了,但是此时已经打开了三个文件也需要将这三个文件关闭:
然后是子进程当程序替换之后需要将程序执行的结果写到这三个文件中(或者从某个文件读取信息)。所以需要进行重定向:

然后就是进行程序替换了:

到这里不要忘了这个运行服务的虽然不需要关心运行结果是否正确,但是需要关心运行是否出现异常,那么如何才能知道子进程的运行没有出现异常呢?首先如果出现异常那么子进程一定是被信号杀掉的,而waitpid这个参数的第二个接口的作用为:

所以当子进程是被信号杀死的,假设子进程被2号信号杀死:

直接让这个status&0x7f只保留最后的7位,这样就能判断这个程序的运行是否出现异常了。
如果这个子进程运行的程序出现异常了这里的返回值就是杀死子进程的信号编号(一定大于0【信号为1到31】)。
到这里就可以说明为什么Run函数设置返回值时使用的是int了

这样就能完成调用功能了,并且将运行结果写到对应的文件中。
测试运行功能
依旧是将运行功能在main函数中进行调用:

此时的temp中除了源代码之外没有任何的文件:
然后就是运行测试了。

因为这里我没有加日志所以并没有打印运行成功。
但是在temp文件夹下:
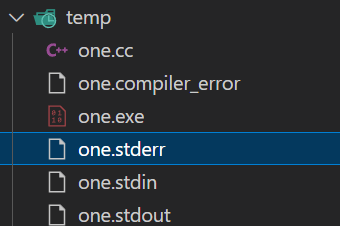
出现了这些文件同时在stdooout中出现了测试程序的输出。
到这里runner服务也就能够正常的运行了。下面就是添加日志。
首先就是如果打开文件失败了,就需要输出日志,但是等级呢?这种内部错误一般是不暴露给用户的,只有用户的错误才应该让用户知道,即便用户使用你的服务没有反应,也不应该将内部的错误信息返回给用户。而这里就内部打印一个err等级的日志。因为打开文件失败了,那么也没必要继续往后走了。

然后是如果创建子进程失败了:
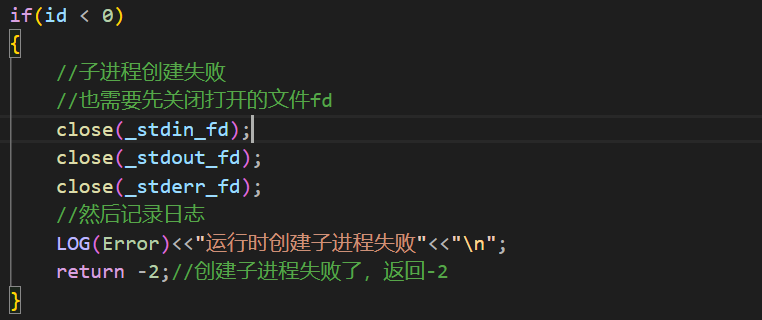
然后在最后,代表子进程至少运行成功了,所以可以打印一个Info信息。至于子进程是否异常可以再将最后的&结果也一起在日志中打印一下即可。

这样就将日志也加入到了runner服务中了。
再次测试运行一下:看日志是否起到作用:
这里提一下现在每一次测试都会让temp中充满了临时文件,之后是可以使用代码去清理这些临时文件的。

这里如果我在测试程序中写一个cerr让这个程序手动往标准错误中写信息,测试一下:
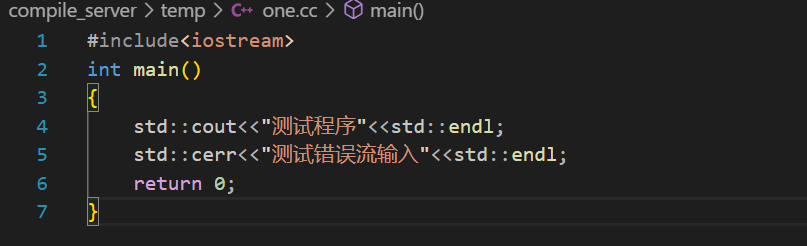
再次运行:
在这个标准错误的文件中就存在打印了。
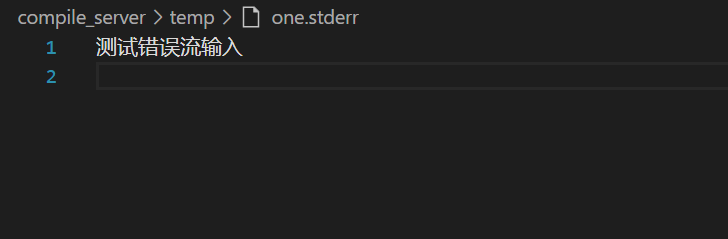
如果one代码是一个错误的代码,失败的信息就会写到新的编译错误的文件中了。
那么接下来就可以组合编译和运行的程序提供给外部了吗?当然不行,有没有可能用户传递上来一个错误代码呢?(死循环等等)并且如果用户的代码崩溃了,那么运行服务不仅要将信号给上层,上层也要知道崩溃的原因是什么。所以还需要给运行服务添加更多的功能(比如时间和空间的约束,以及通过返回的信号告知上层错误原因是什么)。
认识资源约束接口
上面已经说明过了运行模块还不够完善,首先如果用户提交的代码是一个死循环的代码,那么运行模块是会崩溃的。并且在力扣上的题目都是有时间和空间复杂度的要求的。在这个项目中没有那么强力的限制,这里做约束主要是为了防止恶意用户。如何做呢?这里需要介绍一个新的Linux接口:
setrlimit接口是用来设置一个进程的资源使用情况
这个接口能够限制进程使用的虚拟地址空间(单位为字节),以及设置这个进程所占用的cpu时间还有其它的资源也能限制。这里只需要认识两个选项即可:
设置占用的虚拟地址空间。
设置占用的cpu时间。
上面是第一个参数的选择。
然后第二个参数是一个结构体,这个结构体是os为我们提供的一个系统接口。
要求我设置两个值:


那么软限制值和硬限制值得区别是什么呢?
因为我的进程都是非特权的进程,所以硬限制直接设置为无限制即可,通过软限制来约束对资源的使用即可。
这里先通过一个代码认识和使用一下这个接口:
这里我写一个测试代码,这个测试代码是一个死循环的代码:
当我没有给这个进程做相关的限制的时候这个进程就会一直占用cpu资源。
假设这里我就想让这个进程累计跑一秒之后就要退出。 就需要使用上面的接口了。
因为我打算让硬限制是无限制的所以需要使用下面的这个选项来填充硬限制:
然后软限制只要不超过这个硬限制即可。
然后来写代码限制一下:

然后测试运行一下:看是否过了1秒这个进程就会自动关闭:
运行截图:

过了一秒之后,果然这个进程被关闭了。
这就是为什么再写力扣上的某些题目的时候,即使能够通过测试用例,力扣也知道超时了,因为内部是设置了这样的cpu时间的(每一道题目都设置了特定的时间长度)。
但是我的这个项目并不需要这样精细化的设置,统一设置为10秒。
然后来限制一下内存的使用
这里我使用一个死循环让其不断申请空间,但是这个测试用例在申请到一定的空间之后就会被os识别到让之后的new失败(因为其它进程的行为不能影响os,影响os的行为会被强制停止)。
这里还需要注意一点在使用上面的接口去约束空间的时候,并不会像约束cpu时间一样那样的严格,因为对于os来说要查看一个进程的cpu运行时间很好查看,而查看进程占用的空间是不太好查看的。所以会导致限制内存的使用接口的严格程度没有限制cpu时间那样的严格。但是能够看到有约束的
这里先写一个测试代码:
然后使用内存限制一下:
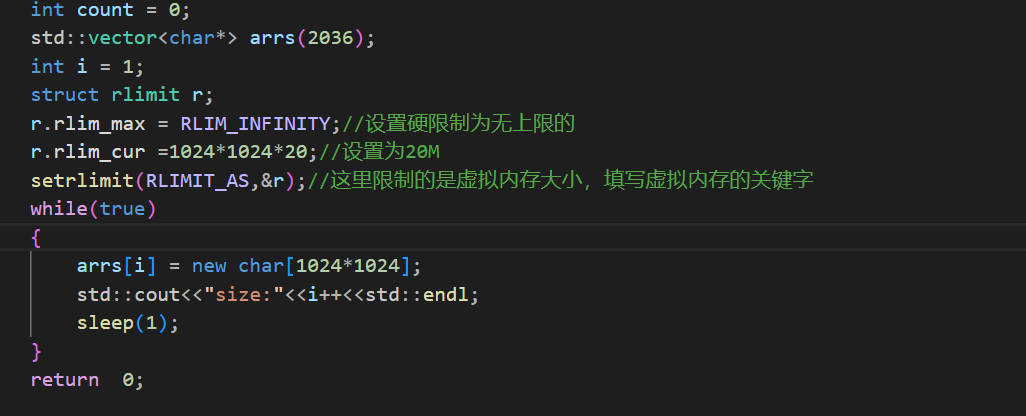
在没有添加空间约束的时候,最大的count能够达到2036。在添加之后count会是20吗?
可以看到在size为7之后就直接申请失败了。
为什么呢?这里限制的是虚拟地址空间,不要忘了这个程序本身在加载的时候也是需要使用虚拟地址空间的。并且stl容器也是需要虚拟地址空间的。由此就导致了size没有达到20。
如果我还想让我的题目在oj的时候想要限制栈大小。都是可以的,这些精细化设置都是可以的,但是这样就很麻烦了,因为不同题目的时间和空间复杂度都是和测试用例强相关的。
那么cpu是如何终止这个进程的呢?当一个进程越界之后,os会发送信号给越界的进程。那么收到的是几号信号呢?
没有关系,我直接捕捉重写所有信号的方法即可(当然部分特殊信号(例如9号是不可捕捉的))。知道这个进程是收到哪一个信号终止的了。
首先测试内存然后是时间
内存:
时间:

6号信号:

24号信号:
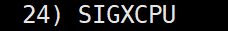
通过这个就能知道了,当进程申请的资源超过约束和进程出现异常的处理方式是类似的。回到runner功能中,就可以在子进程程序替换代码之前进行资源的约束,来让子进程在一个资源可控的上下文中运行。如果资源申请异常了,出现信号,上层就可以通过6号和24信号来决定这个进程出现错误的原因了。
为runner增加约束代码
在增加约束之前,需要制动runner模块只是用来运行程序的,具体约束的时间和空间值,runner是 不知道的。具体约束的时间和空间值,是由出题的人,需要指名的,所以为让让runner能够更加灵活的供给上层去使用的话,可以在Run函数(runner服务中实现功能的函数)增加两个函数参数,作为cpu_limit(cpu时间限制)和mem_limit(内存限制)。所以上层在调用Run的时候需要传入两个约束。然后在单独写一个函数用于让子进程去设置时间和空间的限制。这个函数可以放到comm中,但是因为时间和空间的限制只有在runner中才会考虑所以这里我就没有放到comm中


然后就是实现这个函数了。

如果之后还想要更加精细化的限制,直接在这之后写即可。
到这里runner才算真正的写完了。
而还有一个问题,就是runner的返回值的处理了,通过返回值去知道某一个程序运行错误的原因。
为了解决这个问题就需要去编写complie_run.hpp和complie_run.cc了。
complie_run编译和运行功能
这个模块的主要功能就是适配用户的请求,还有一个功能和临时文件有关,因为临时文件中的代码都是从客户端来的。而这里还有一些工作需要在这个服务中去完成。
首先什么是适配用户的请求呢?
适配用户请求,也就是定制通信协议字段
还有一个功能为正确调用compile 和Run方法。
最后还有一个重要的功能未来使用这个服务的用户很多,那么编译服务也是可能被多个用户请求的,但是temp区域只有一个,所以为了区分不同的用户:
需要形成唯一文件名。不然的话用户之间会互相的影响的。
了解了这个服务需要处理的问题。
然后需要明确一下这里的软件层次:complie_run.cc只需要包含complie_run.hpp即可。complie_run.cc也只需要使用complie_run.hpp中的方法。complie_run.hpp就需要完成上面说的这些问题。
画图表示:
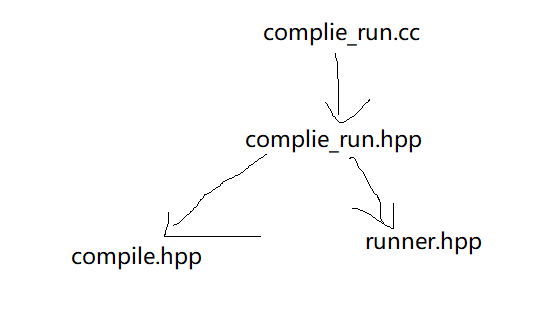
通过这个图就能够知道了complie_run.cc是需要通过http接收外部的网络请求的,既然要接收外部的网络请求,就需要进行序列化和反序列化,这里就需要使用json了,json是一种成熟的序列化和反序列化的方法。 然后在接口的实现上,外部会传进来一个json式的数据,complie_run.cc在处理之后又会返回一个json式的数据。
首先json是一个第三方库,需要安装,安装方法网上是有的,这里就介绍一种centeros的一种安装方法使用下面的指令
sudo yum install jsoncpp-devel不同版本的json在使用上是存在不同的一下是我使用的版本:

安装完成之后在complie_run.hpp中包含下面的头文件:

下面是使用json进行序列化的测试代码:

在上面将kv值一填下面通过writer对象中的方法就会形成对应的json串。直接使用g++编译时会报错的,因为你需要告诉g++使用的json库在哪里。
需要这样去使用:

最后的结果:
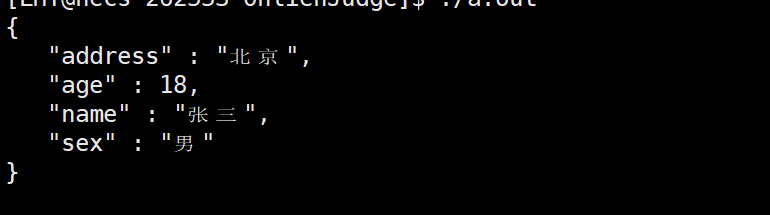
这里能够直接使用-ljsoncpp因为当你安装json的时候在os的默认搜索路径上就已经安装了这个库了,所以能够直接使用-ljsoncpp这样去连接这个库。

json就能够将结构化的数据转化为一个字符串方便进行网络发送。如果不想使用上面的那样形成的字符串还可以使用:

这样的方式去形成序列化字符串。

当用户发送数据的时候,会存在很多数据例如,要运行的程序的数据,要发送给这个程序的标准输入的数据,以及一些其它的数据等等。这些数据就是在一个结构体中的结构化数据。将这些结构化的数据转化为一个字符串这个过程就是序列化,而反序列化自然就是将字符串转化为结构化的数据了。
由此就需要进行规定了,这里就规定用户给complie_run这个模块的数据格式必须为:

由此就知道了输入的信息的格式是什么
同时这个服务完成之后也需要给上层进行输出,而输出的结构也是有要求的:

然后在complie_run.hpp中的第一个向外提供的函数中需要两个参数,一个就是输入的json字符串,一个就是输出的json字符串。
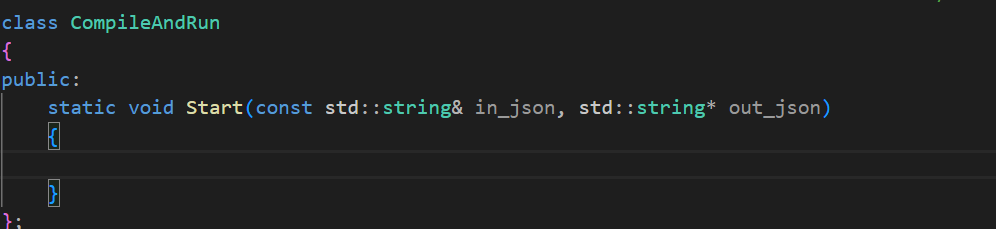
下面就是完成这个函数了。
现在这个start函数能够收到一个json串,首先就要将这个json串中的数据解析出来,放到另外一个json中。要完成这个工作就需要Json中的另外一个类对象去辅助。

这样就能将in_json字符串中的内容,反序列化到in_value中了。这里的parse其实有三个参数最后一个参数是有缺省的一般缺省为true.

但是这个parse这里还有许多细节需要处理,这些细节会造成差错问题,最后再来处理。
in_json中的数据:

在将数据进行反序列化之后就可以提取数据了。

如果获取的code为空,代表没有代码,那么这个服务自然就不能为用户提供了,这里就需要做一些差错处理了。和上面的一样,先记录最后再来完成。
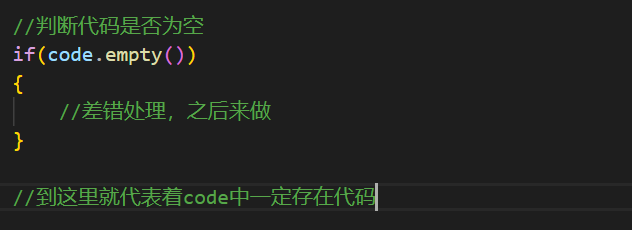
既然code中存在代码了,而下层的编译和运行服务需要这个代码形成一个文件,所以这里需要将这个code写到文件中,但是正如之前所说,可能会有多个用户一起访问这个服务,所以要为每一个用户的代码文件,起一个唯一的代码文件名字。
产生唯一文件名的函数,虽然只有这一个服务需要,但是因为在工具命名中已经声明了存在文件的工具类。所以我就这个函数的实现放到了命名空间中。
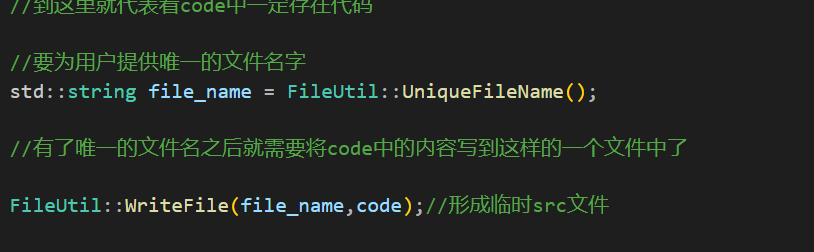
然后就是在comm中实现这两个函数了。
UniqueFileName只负责形成一个唯一性的文件名。至于这个文件的后缀,和目录都是没有的。所以上面的代码直接使用file_name是不可行的,如果使用file_nam e那么就算完成了写的工作,写的文件也会放在当前目录下,而不是放在temp目录下。所以就需要使用之前写的路径工具类中的方法了。
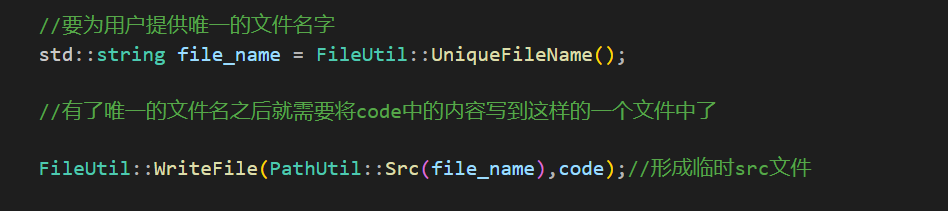
这样才是正确的带路径和后缀的文件名字。有了唯一的临时文件之后就是调用编译和运行服务了。
编译线程可执行程序:

形成可执行程序之后自然就是运行了。


在增加了输入之后,一样反序列化要得到这两个数据。

然后就可以将这两个数据交给Run数据了。这就是将Run的参数暴露给上层,让上层告诉底层这里需要填写的内容。

到这里就完成了吗?当然不是,在上面的步骤中如果某一个步骤出现了错误,差错要如何处理。完成运行之后还要告诉上层这个程序的运行结果,因为服务是基于http的,所以又需要将结果反序列化为一个json字符串。这些步骤都还没有写。到这里只是完成了一个大体的框架而已。
现在引入差错处理:
现在已经可知的是用户输入的json串的形式为:

上面的数据只是举一个例子。
那么输出的json串是什么样子呢?

就是上面的这个样子,其中前面两个字段是必须要填写的。
到现在这里核心思路已经没有问题了,现在先去处理差错处理。
根据输出的json串来进行差错处理,因为即使出现了错误也是要个给上层返回错误的原因的。
首先如果用户传递的code根本没有交给我,那么就不要说编译和运行了。
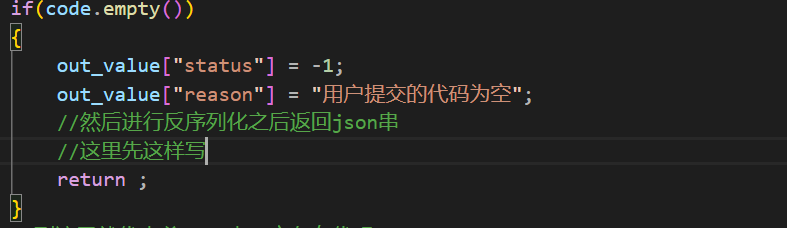
然后下面的逻辑是形成一个唯一的文件名,这里形成唯一的文件名使用的思路为毫秒级别的时间戳+原子性递增的唯一值来形成唯一的文件名字。由此就不需要对形成文件名字的函数做判断了。
下面是根据这个文件名字形成临时文件

而写文件也是的返回值为bool也就是写文件也是存在成功和失败两个情况的。

这里就体现了虽然是服务器内部的错误,但是不能告诉用户,因为怕群众中存在坏人。
形成了临时文件之后就是处理编译了,编译依旧只有成功和失败两个返回。依旧是要在编译失败的时候返回json串,但是编译失败了,需要告诉用户编译错误的原因是什么,这个原因在哪里呢?就在xxx.compiler_error这个文件中,要让用户知道错误的原因就需要读取文件的内容。而读取文件的内容 在comm的file工具类中实现这个方法。

当然可能还需要更多的参数,如果后面需要了再加即可。
有了这个接口之后处理编译错误的json串也就好处理了。

上面的步骤如果都没有问题,那么就会进入最后一个步骤:运行了。
根据运行的返回值:

就需要产生不同的json串了。
一个一个处理这三个情况:
第一种情况自然就是在运行时服务器内部出现了错误:
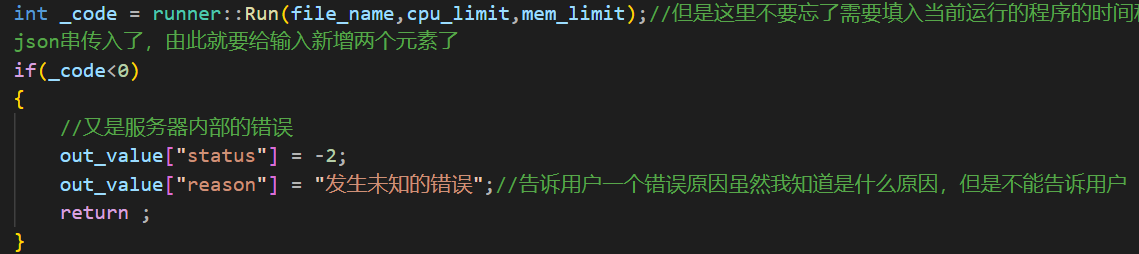
第二种情况程序运行时出现了异常,程序接收到的信号编号的描述就是异常的原因,这里我就在这个类中专门写了一个函数用于将信号的编号翻译为描述

具体的内容之后实现。
这样运行时的异常问题也能处理了:

最后就是_code=0代表编译运行成功了。后面我认为_code这个名字不好改为了run_code
但是现在的代码显得很臃肿,因为每一次的差错处理都要给out_value增加描述然后序列化然后返回。能否将out_value的增加描述放到最后去实现呢?当然是可以的。
需要通过goto来实现。因为需要使用到goto所以将goto跳转代码之间变量的声明放到前面:

然后定义一个变量:

然后如果用户传入的代码为空:
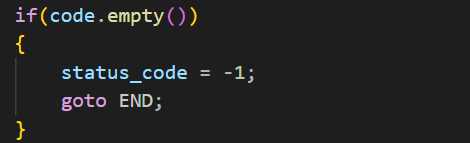
形成临时文件失败了

编译失败了

然后又是运行时的不同情况了。
第一种依旧是运行时的内部错误
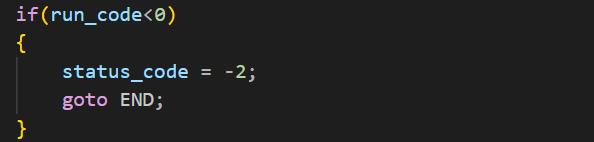
然后就是运行时收到信号了。

最后就是运行成功了
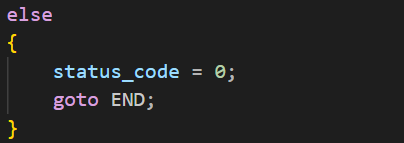
然后就是在END这里统一通过status_code处理不同的情况了,这也是为什么我在前面的错误的时候将返回值设置为了负数,而信号的返回值为正数,运行成功为0。这样就能够通过status_code的值,来确定不同的原因了。其实这里使用if和else判断就可以了,因为如果程序运行成功了最后的run_coe也是0,不需要进行==0的的判断。但是我这里为了逻辑的清晰就这样写了
既然可以通过status_code的值来确定不同的原因修改一下上面的SinalToDes将其变成通过status_code中的值返回不同的描述(负数一定不是信号,正数一定是信号)。

然后就是END:

如果status_code为0说明运行成功了,需要读取这个程序运行的结果,以及如果出现了非信号的错误,也需要储存起来。

最后就是序列化了:
这里为了调式使用了Json::StyledWriter

现在差错处理的宏观结构也有了下面就是实现上面没有写的方法了。
第一个编写的方法是CodeToDes,
这个函数我打算使用switch,case语句来实现。
首先是对负数run_code和0的处理:

然后就是run_code为正数收到信号了
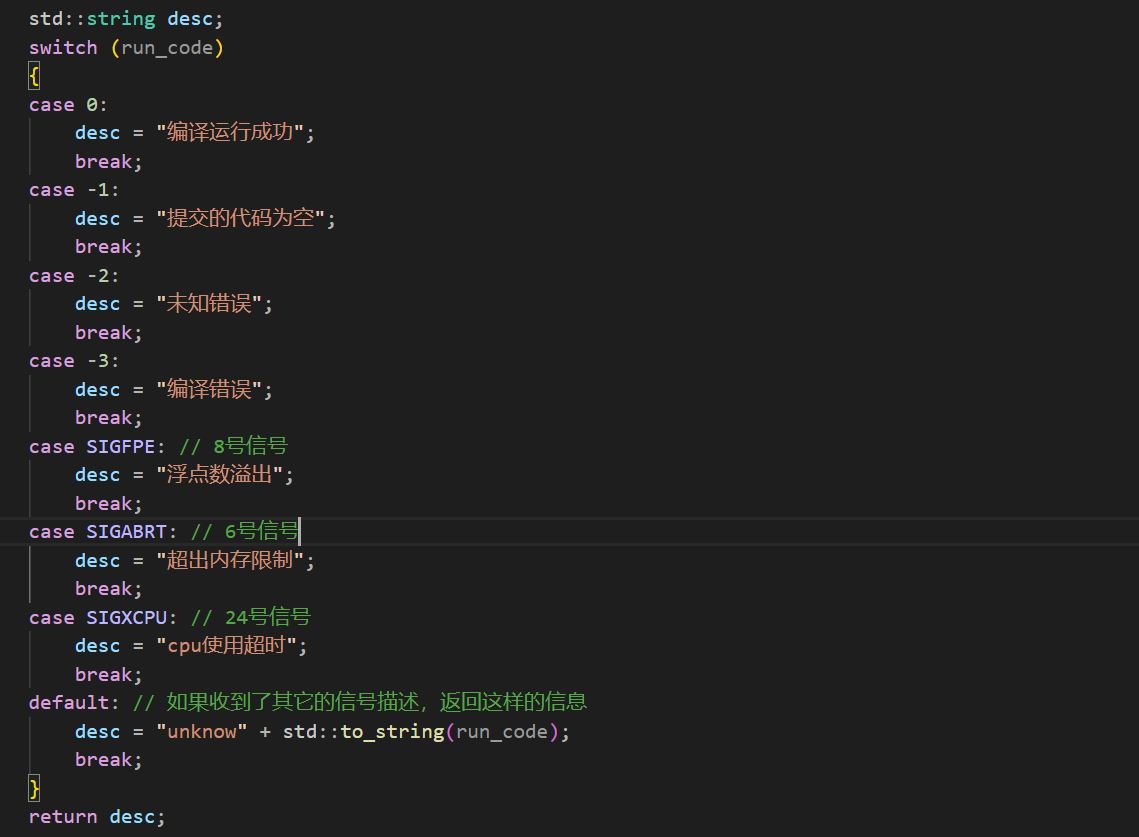
当然这里的信号转换是没有写完的之后如果用户提交的代码引发了其它的信号,直接在这里继续往后加即可。但是当run_code为-3的时候我这里更想要知道的是,编译的g++报错是什么。也就是那个compile_err文件中的信息。所以这里需要使用读取文件的接口,同时需要将文件名字加入到函数参数中。
修改一下函数头:

然后修改一下函数体:
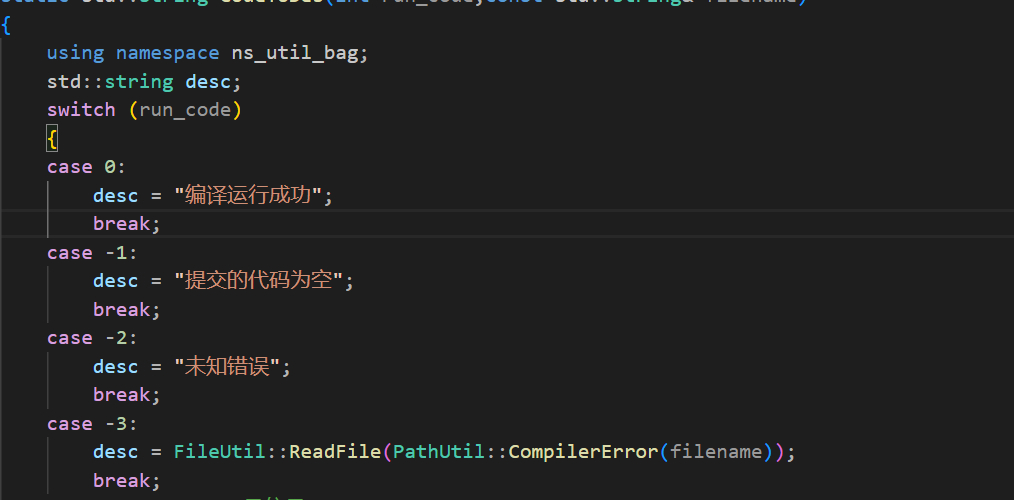
这样这个函数就比较完善了。
下面实现生成唯一文件名字的函数UniqueFileName。
根据之前所说这里的实现要通过毫秒时间戳+一个原子性递增的唯一值来实现。所以需要在时间工具类中写一个函数用于获取毫秒时间戳。因为之前的时间类中只能获得秒时间戳。
毫秒时间戳要如何获取呢?这里就要知道在struct timeval中存在两个值:

一个值是秒(转成毫秒要乘上1000),另外一个 值就是微秒(转成毫秒要除上1000)
这样就能获取毫秒级别的时间戳了。
然后在UniqueFileName中使用这个函数就能得到毫秒级别的时间戳了,现在还需要一个原子性的唯一值,可以使用一个static变量然后加锁来实现也可以通过信号量实现。在C++11标准中,提供了 atomic_uint,atomic_uint 是 C++ 标准库中提供的一种原子数据类型,用于在多线程环境中对无符号整数进行原子操作。它提供了一种线程安全的方式来操作无符号整数,避免了数据竞争和不一致性的问题。
这样就能线程一个唯一的文件名了。
现在已经形成了唯一的文件名,下面就是写入了,写入函数只告诉我写入的字符串内容和文件名字即可。下面就来完成这个函数:
然后就是读文件了,这里我打算修改一下读文件的参数接口,因为读文件的返回值我也想修改为bool类型,然后使用输出型参数的方式将读取的文件内容发送给外部。
通过getline的返回值进行判断不会出现错误吗?while循环需要的不应该是一个bool类型吗?这里就要知道在getline内部重载了强制类型转换。所以即使getline的返回值不是bool类型的经过强制类型转换也能转化为bool类型的。
然后还有一个特点getline是不保存行分隔符的。
但是在某些情况下需要保存这个行分隔符号,某些情况下又不需要保存。例如在某些读取的文件中我使用这个分隔符号可以做了一些格式,这个时候就需要保存这个分隔符号了。所以是否保存这个分隔符号交给上层决定,我增加一个bool参数,让上层决定是否保存。
这样就完成了,现在就需要修改一下使用ReadFile接口的地方了。
而在使用读取文件的接口那里对于返回值我就不做判断了,因为即使读取失败了也就是文件为空而已(后面也会处理),如果在做判断就会让代码显得臃肿。

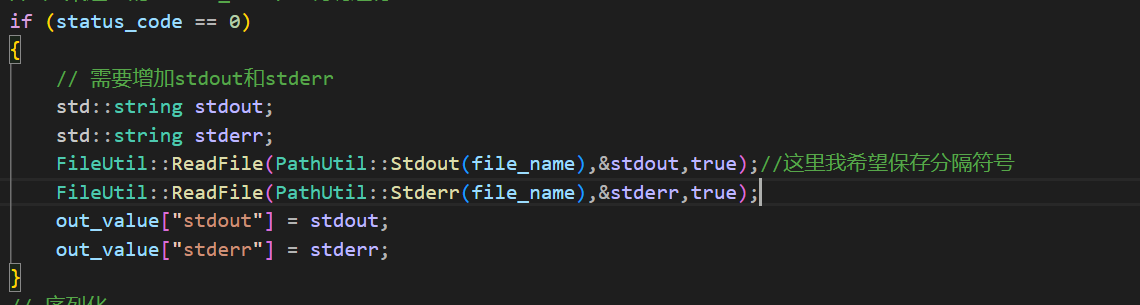
然后编译一下是否存在语法错误。
编译成功下面就是设计测试用例了。
调式compile_run
根据这个函数的参数:

两个json串中的内容为如下:

需要传入的是两个json串,这个json串是client通过http传递过来的但是我这里只是进行测试就不使用http让client来传了.
这里我自己创建一个json字符串即可。
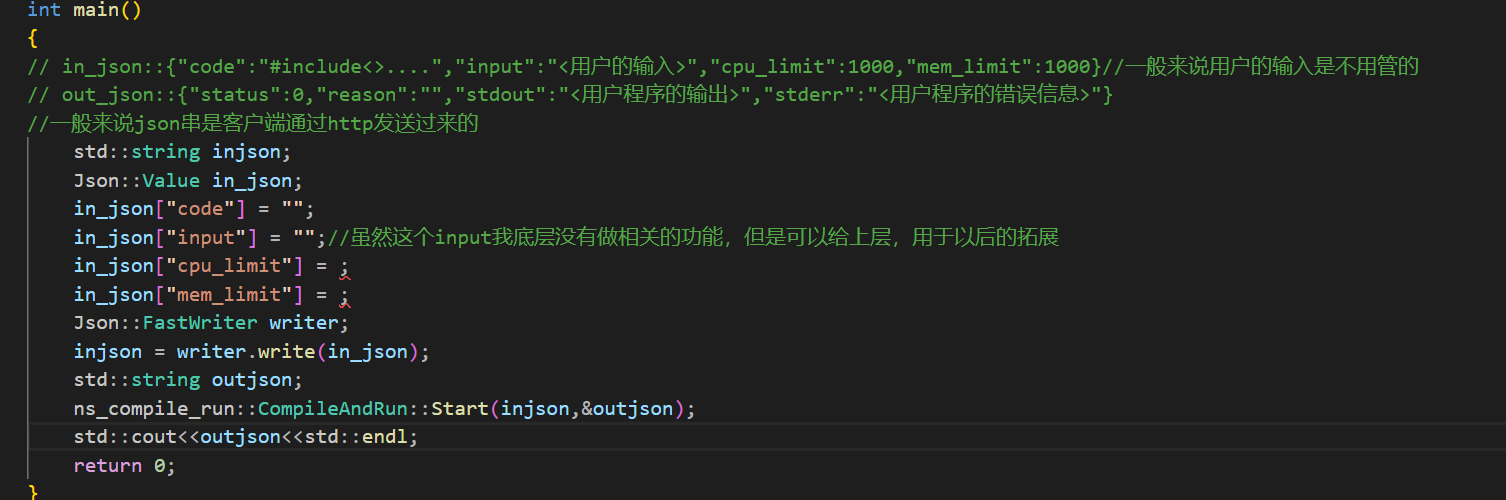
然后就是填充这些值了。
这里使用一个c++11中的字符串字面量R("")在""中的内容即使是一个很长的字符串(包含特殊字符),也不会导致编译器报错,因为R("")中的内容会被编译器直接替换成字符串字面量。不会认为这些字符串中的特殊字符存在任何的意义。
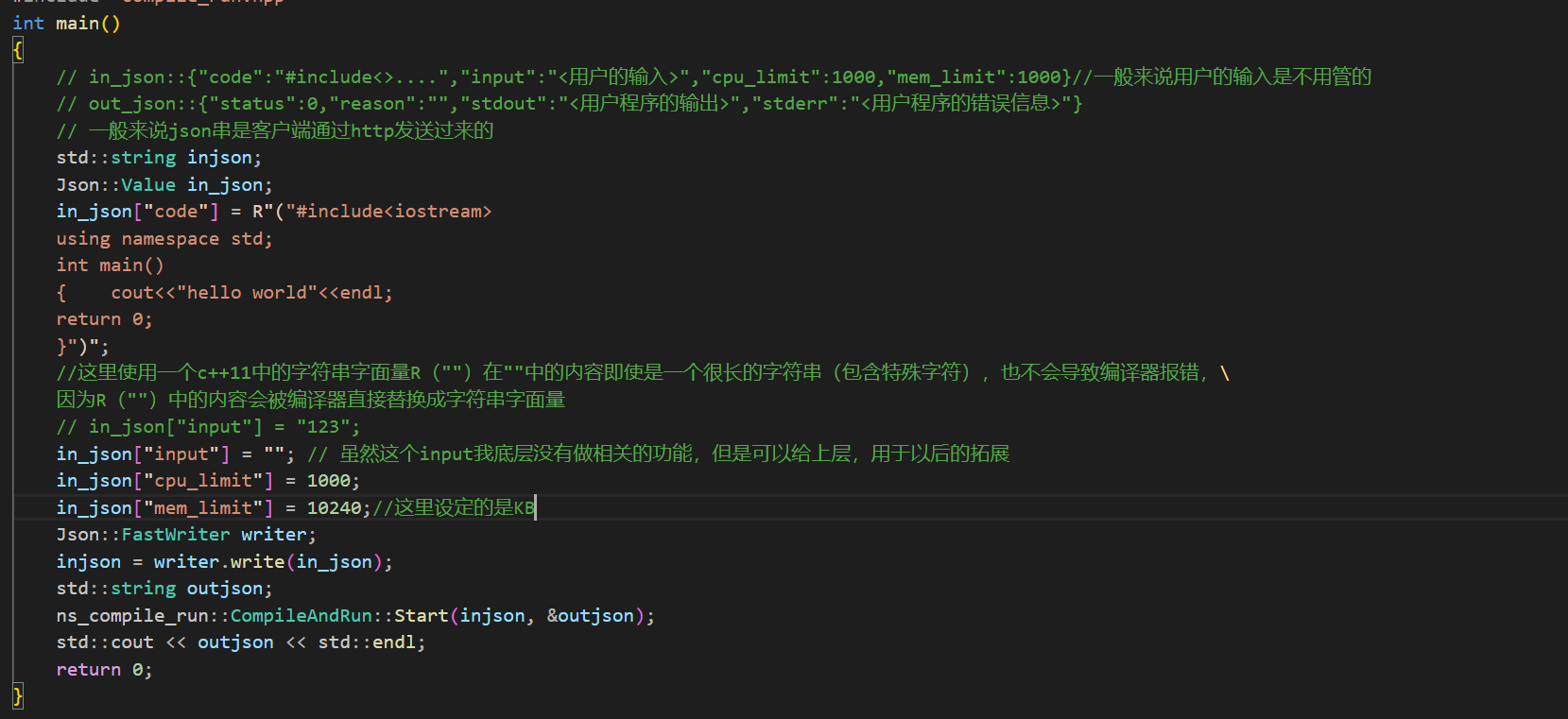
编译运行一下:
运行图片:

同时也产生了临时文件:
临时文件是通过时间戳加上原子静态变量形成的,这里因为我每一次都在重启服务所以都是1。但是唯一的文件名确实是产生了。
可以看到这里报了一个错误,这个错误是因为我设定的可以使用虚拟内存实在是太少了,导致连一些必须使用的库都无法包含完成所以出现了这个错误。这里我增大一下可以使用的空间。再去运行:
如果我在这个代码中使用了死循环呢?
强制停止,如果是空间使用超过呢?

如果出现了除0错误呢?
这些我设定的错误都能正常的处理,到这里编译和运行的整合服务也就调试完毕了。
这个服务就能完成你传入一个json,我就给你返回一个json(经过处理),下面要做的就是要将这个编译运行服务进行打包形成一个网络服务。只有成为了一个网络服务别人才能以网络的形式来访问我的这个服务。这里需要引入网络库,c++还没有官方的网络库。当然我也可以自己写,无非就是通过TCP套接字获取客户端的链接(监听,获取等等),代码要写还是很容易的,但是很麻烦,这里就可以使用c++的一个开源的第三方网络库(cpp-httplib)使用这个将这个服务直接打包为网络服务。以及在完成一个编译运行服务之后再temp中的临时文件,应该将其删除了。
首先解决临时文件清理的问题。因为可能出现编译或者其它什么原因导致的错误,我是不知道具体形成了什么文件的,所以在清理文件的时候,需要先判断这个文件是否存在,如果存在就清理,但是每一个需要清理的文件名我是知道的,所以可以完成删除文件函数。并且这个函数,因为只有编译和运行模块需要使用所以我就放在编译并且允许模块了。
主要使用unlink函数删除这个文件。这个函数需要带路径的文件名字。
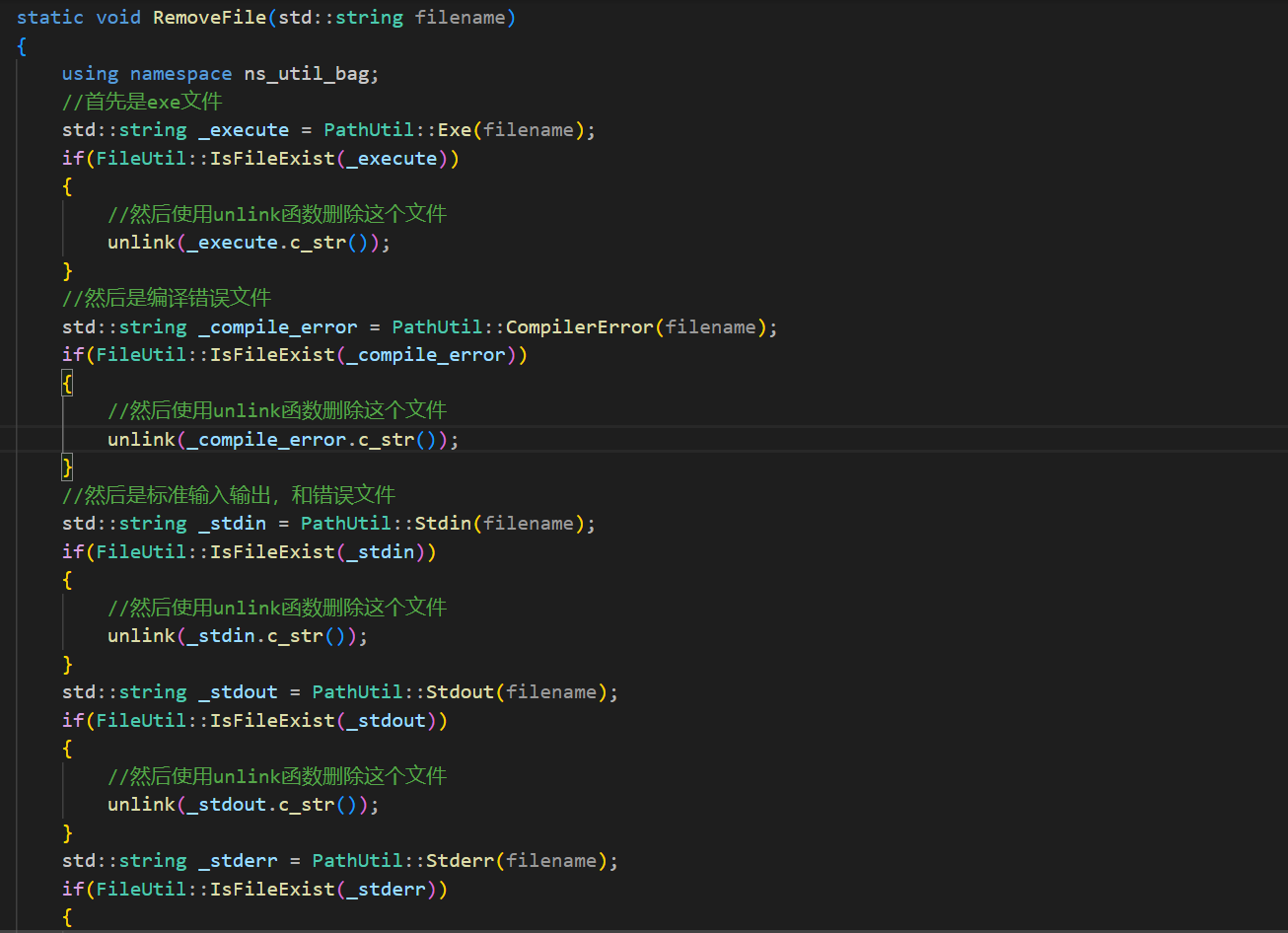
没有截取完,但是思路都是一样的。
判断文件是否存在存在就删除(是否存在这个函数之前已经实现过了)。

最后再编译运行一下:
果然在temp路径下没有临时文件了。
下面就是通过网络库将这个服务打包为网络服务了。
使用http-lib库
这个http-lib是一个开源的网络库。
gitee链接:https://gitee.com/yuanfeng1897/cpp-httplib
这里我使用的版本是:0.7.15版本(在仓库的标签那里选择就可以了)比较稳定的版本。
这里我已经安装到了我的一个文件夹中了

这个文件夹中的内容:
这个项目只需要将httplib.h包含到你要使用的代码中就可以使用了(head-only)。

当然你也可以选择将这个项目拷贝到os的默认搜索路径下
在上面的gitee链接中也有文档说明了,这个是如何使用的。
还有一点:

我这里使用的gcc版本如下:
使用7.x/8.x/9.x的版本都是可行的,但是不推荐使用4.x版本的。这样可能导致程序在编译或者运行时出现错误。
下面这样的就是4.x版本的:


这里也有一个gcc升级的一种方法(还有其它的方法)

经过上面的步骤只是让这个会话暂时升级了,如果你想让你的账号一直使用升级后的gcc,可以

这个文件中新增一行描述

这里我下载了7,8,9三个版本,在这个路径下可以看到:

这样我的账号登录使用gcc版本都是9.x了。
记住不要往下面的文件中写入了:

如果修改了这个文件那么使用scl命令就会出现问题。导致无法登录
并且要修改的是自己的家目录下的.bash_profile文件。
然后重新登录从此之后使用的gcc版本都是9.x版本了。
下面我就将网络库的头文件拷贝到comm文件夹下:
因为comm是一个公共组件,oj服务可以使用,编译运行服务也可以使用。
下面就来使用:
先这样定义后直接使用一下: 这里我便一的时候出现了这个错误:

这是因为再httplib这个库中使用thread。所以需要修改一下Makefile。
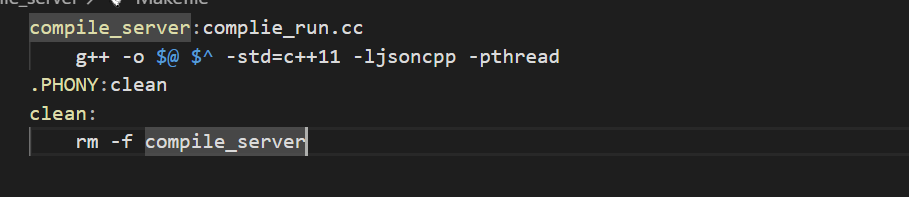
这样就能运行了:

下面继续写代码:

这里编译成功,运行程序,如果你的gcc版本是4.x的就会出现下面的错误:

替换成7.x/8.x/9.x版本就不会出现问题,如果你是再vscode的终端下运行的,需要重新执行:
scl enable devtoolset-9 bash这个指令,因为vscode使用的是自己的账户登录云服务器,不会执行你在另外一个账号执行的脚本指令。
回到上面的步骤,当我使用g++高版本执行启动这个程序之后:

在我的机器上就已经有了一个http

但是我的这个服务什么都没有,所以即便已经启动了,被人请求什么都得不到。所以在启动服务器之前需要提前注册/绑定服务。这样当请求过来的时候才会有服务能够提供。如何注册呢?
这里先使用一个Get方法做一个测试:

这样就相当于在我的服务器中我注册了一个服务,当别人使用/hello作为url的一部分访问的时候就会运行这个服务。响应这个文本。运行测试:


出现了文本,但是打印的方式不对,因为在服务器返回的响应中应该带上,正文所用的编码方式:
在运行的过程中可能会遇到下面这样的偶发问题

这个正在编译的程序被os直接终止了,和代码没有问题,原因是我的云服务器配置比较低,这里我使用vscode连上了这个服务器,并且还在调用高版本g++,比较耗费资源,在编译的时候因为资源耗费过多就被os杀死了(每一个进程在os中都是有资源使用上限的)。上面都是在vscode上运行的,所以直接关闭vscode重新进行连接,在编译一般就能解决在vscode上进行编译出现这个错误的问题了。如果还是存在这个问题,那还是在xshell上连接服务器在进行编译吧。
回到刚才中文错误的事情上,这里需要在响应中写入编码格式

再去运行

中文就能正常的显示了。
现在服务已经能够请求回来了/hello只是一个我测试的服务,后面当用户的请求重新来的时候,就能够得到用户请求的Request json串然后调用刚刚写好的编译运行服务,得到一个json串,在将这个json串返回给用户。这样就完成了一个远程的编译运行的服务。但是还有一个问题上面的代码没有设置web根目录服务。所以这里可以使用下面的代码进行设置:

然后这个set函数可以设置为某一个具体的目录,下的一个默认的网页,这样当用户直接访问我的ip地址的时候就会跳转到默认的首页了。但是这里不需要这么麻烦因为这里我只需要提供一个编译运行服务就够了,不需要默认的网页/默认的服务,这是一个简单的服务就够了,其它的不设置。
到这里这个库就算使用了。如果遇到了其它的需求再去查资料即可。
打包编译运行服务为一个网络服务
现在就使用这个库来进行打包。这里我打算使用的是POST方法。
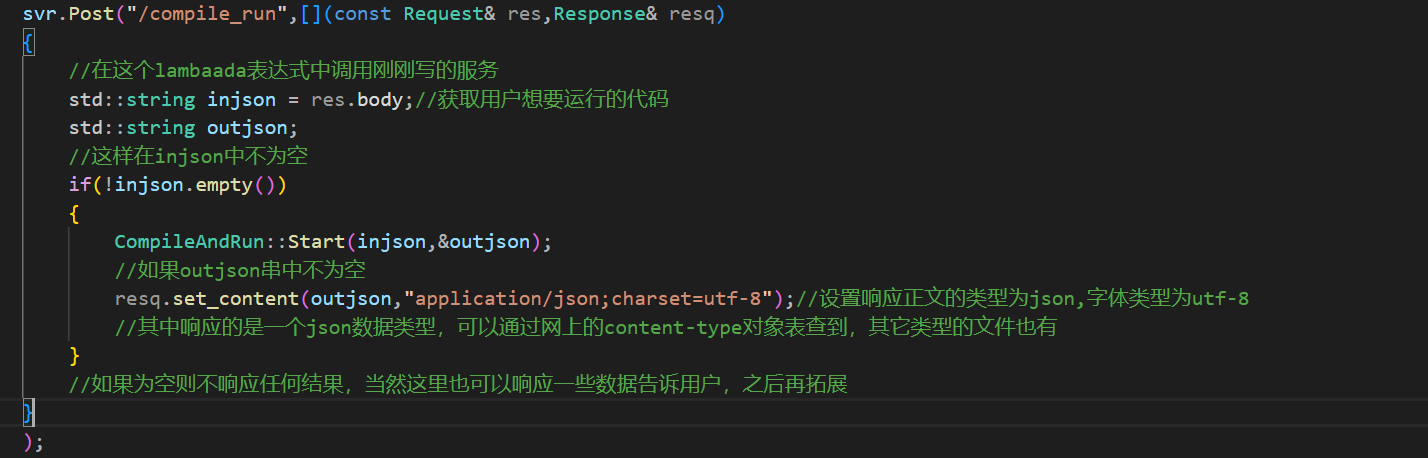
这样就将其打包成为了一个网络服务。编译运行一下是否存在问题:

没有问题,但是现在很难测试这个服务,因为我没有客户端,但是可以通过某些工具构建一个符合要求的post请求及那个其转为json串之后(就是ojserver模块),发送给我的服务器,来进行测试。
这里我通过postman来完成模拟构建工作。下面是postman的官方网站:
https://www.postman.com/downloads/
下载完成之后这样就能填写一个请求的body了:
之后在上面填写上我的ip地址和编译运行服务器所在的url即可。

之后点击发送即可,这里我已经将我的请求运行起来了。
使用postman能够看到返回的json串:

即使出现了错误也能处理:
上面已经完成了一个编译和运行的服务,下面就来完成oj_server服务
oj_server的准备工作
oj_server的本质就是建立一个小型的网站。这里我的这个oj_server打算提供三个主要功能。
第一个就是功能就是获取首页,其实也就是获取一个默认的.html文件,这个首页我也可以做的很漂亮,但是因为我的重点并不在前端所以就使用题目列表当作首页了。
以下就是力扣的题目列表:
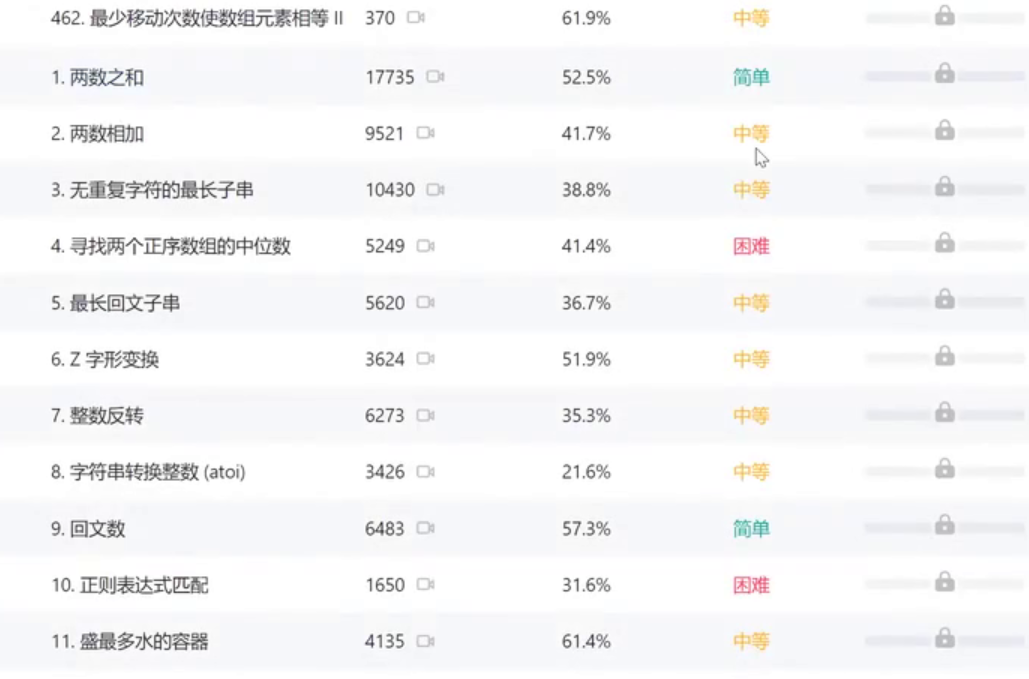
点进一个题目就能得到题目的详细信息。然后就是提交代码,判断正误。
然后的第二个功能就是 编辑区域页面:也就是一个编写代码的区域
第三个功能当提交代码之后,就需要具有判题功能了

对于这个服务的设计模式采用的是MVC设计模式。
那么MVC分别是什么呢?

这个模块主要是和文件/数据库专门做沟通的一个模块。
然后就是V了

最后的c就是control,控制器,这个模块的作用为:你什么时候拿数据,你要拿多少的数据,你要拿的数据要和哪一个网页结合成为一个提供给用户的网页返回给浏览器都由这个control来决定。

control也就是核心业务逻辑。之前一直听说的核心业务逻辑说的也就是这个了。要写核心业务逻辑也就是写这个模块了。当然其它的模块也有写的时候。
这就是MVC架构:

将数据,逻辑和界面进行了分离,使用这个模式便于设计。
下面先创建文件。

这个文件就是要形成的网络服务,上面说的所有的功能都需要这个提供文件提供给用户。
这个文件形成的服务也会在后台调用编译运行服务。
然后还需要有MVC服务的文件:
然后先在.cc文件中写入基本的代码。
然后来完成MakeFile文件
因为网页我不擅长是是,所以实现这个服务我是从底层往上层写的。
路由功能
下面首先来完成网络路由的功能。
因为很显然oj_server的网络功能比起之前写的编译运行的网络服务(只需要有一个网络服务compileandrun就够了),要多很多。这个网站服务需要提供的东西需要更多。因为这个网站会收到很多客户的请求,例如:想要查看题目列表,做题等等不同的请求。所以这个.cc服务首先要做的就是一个用户请求的路由服务。
如何做呢?其实也就是当用户输入不同的网址然后将其路由到不同的服务函数上
首先是启动服务器:
然后就是oj_server需要提供的服务了。

以上三个就是oj_server模块需要提供的服务。
现在来写第一个路由功能:

这样这个oj_server的路由功能就完成了。
但是到这里还没有给用户提供一个默认的首页的网页文件。这个网页的文件我打算写到wwwroot文件夹下。

然后将上面的index路径设置为默认的首页。

下面测试一下:





下一个模块
完成路由功能之后最先要写的模块本来应该是model模块但是没有题库只有存在了题库model模块才能去获取题库中的信息。所以下面就是设计题库了,设计题库自然就需要设计题目了
文件版题目和题库设计
这里在oj_server中新建一个questions的文件夹,用于储存所有题目的信息。
然后从力扣的题目列表中可以看到一个题目拥有的信息为:

然后通过力扣网页上来看,当你在力扣的题目列表中选中了一道题目选中点击之后,才会给你显示某一道题目的详细说明,代码编写区域等等。
所以对于文件版本的题库,需要两批文件构成。
第一批文件:

第二批文件:

这里默认了预设值的代码是在header.cpp中写的,同时用户写的代码也是写到这个文件中的。然后为了判断用户的代码是否能够通过所以还需要一个测试用例代码,这个测试用例在tail.cpp这个文件中。
这两个内容是通过题目的编号,产生关联的。
现在就来写文件架构:

在这个list文件中保存的就是题目列表了。
然后在题目列表中添加第一道题目:

其中的1就是这个题目在题目列表中的编号,然后难度为简单,最后的两个数其中第一个为时间限制,第二个为空间限制。中间的?在后面说明填什么(不过最后我没有填)
到这里就将这道题目不包含题目描述的信息加进来了。
然后我在和questions.list同级的位置上设置一个id为1的文件夹。

这就意味着.list文件是一个顶级的目录,然后这个目录中和1编号有关的信息就在这个1文件夹中。
然后在这个1号文件夹中加入,这个题目的描述文件,然后就是预设代码文件。
然后将题目描述写到desc.txt中:
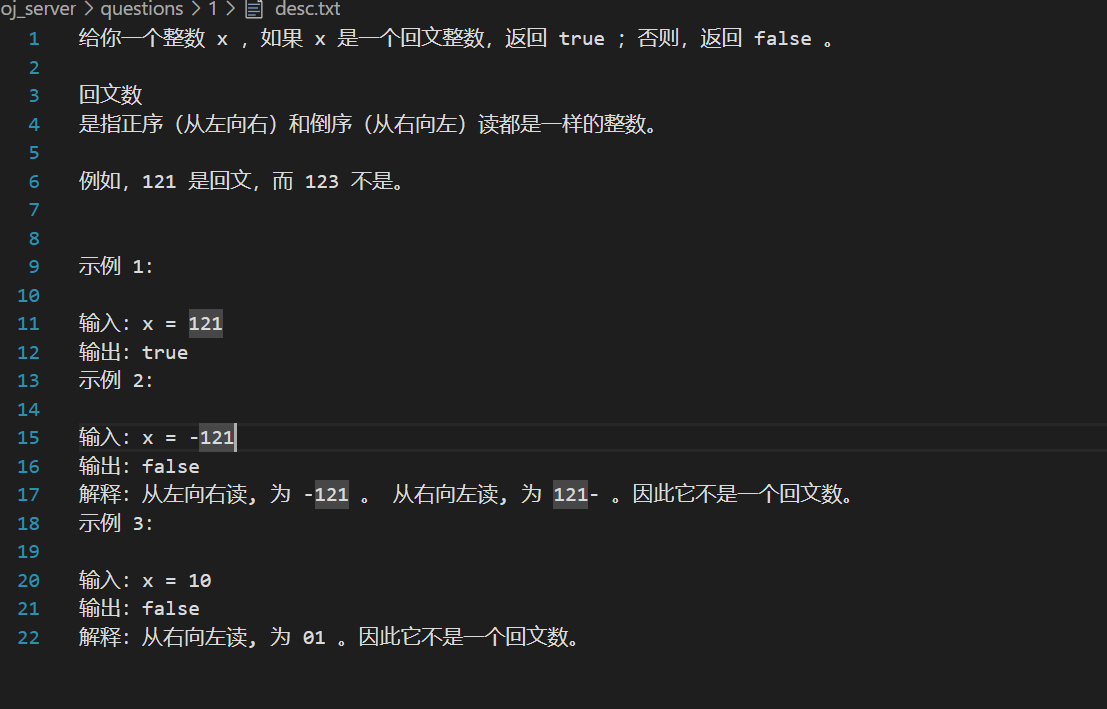
然后就是当用户请求这个题目的时候将这个题目预设的代码进行编写了,也就是题目头部的编写(提交给用户的代码):
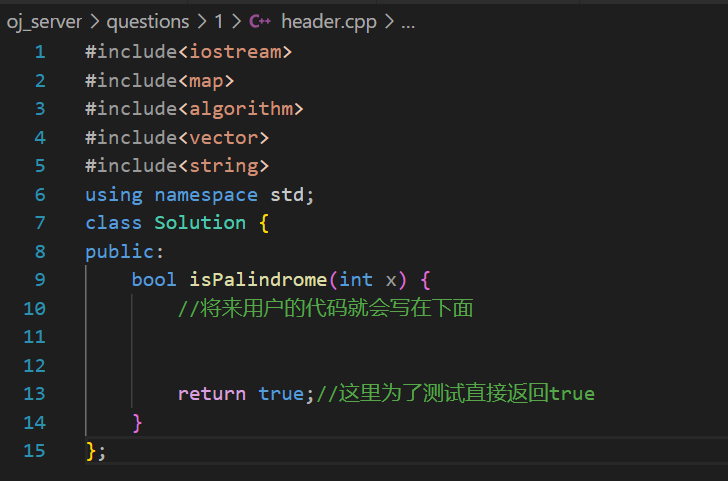
这样在之后完成项目之后上面的代码就会被预设到用户浏览器的在线编辑器中。
但是现在还有一个问题就是oj_server这个模块怎么知道用户提交上来的代码是成功通过测试了?
所以需要写一个代码对用户的代码进行测试用例的输入。
下面的内容也是承接编译模块的重要点: 设计测试用例:
首先创建测试用例的代码:
在tail.cpp中就需要设计测试用例了,如何设计呢?
使用下面的方式:
然后在test1和test2中直接调用header.cpp中写的类的方法,虽然现在这两个文件是分开的,但是在项目真正运行的时候这个两个文件(header.cpp和tail.cpp中的代码文件是会放在一起的)。为了我写测试用例的方便这里我加入了条件编译。当没有定义某一个宏的时候就include"header.cpp",之后可以通过g++编译器的-D选项让g++编译器创建一个我指定的宏就能让inclue"header.cpp"这个包含直接消失了.

然后完成这些函数:
虽然在力扣那样的oj网站中是不会把测试用例暴露出来的,因为怕别人去猜它的值,但是我这里为了便于调试就公开了。当然还可以继续添加测试用例,从这里也能看出来,设计测试用例也是需要非常了解这道算法题目的。
如果用户的代码跑过了上面的三个测试用例在我的这个项目中我就认为你通过了。
这里就需要知道oj_server的运行步骤了: 1当用户提交自己了自己的代码后。
2.oj并不是直接就将用户写的代码(header.cpp)文件直接提交给后端的compile_run服务的。而是将header.cpp文件中的内容拼接上该题号对应的测试用例(tail.cpp)就能够形成一个可以交给compile_run运行的代码文件了。经过compile_run模块运行之后的结果文件会在stdout文件中以json的方式返回给oj_server。然后oj_server把通过测试用例的个数返回给客户端就完成了相当于判题的功能。
通过编写这个功能就能知道了对于一道算法题目最难的点在于测试用例的书写(如何写全测试用例)。
现在再去写一个题目2:

然后就是描述文件中的内容了:
然后依旧是header.cpp
然后就是测试用例(tail.cpp):
之后如果还想要添加题目就按照上面的步骤往后面写就是了。
然后回到题目列表中的?的填写,为了更加方便的找到每一个题目这里的?可以选择将这个题目的描述所在的文件夹的路径加上。但是这样我认为有点没必要,所以我就没有加。直接规定在获取题目列表之后,想要找某一个题目就直接去找这个题目编号同名的文件夹就可以了。
所以最后的题目列表:

到这里文件版本的题库就设计完毕了。下面就是编写model模块了,这个模块的第一个工作就是根据题目list文件,加载所有的题目信息到内存中。不需要担心成本因为算法题目本来就只有几千道,并且因为是纯文本,所以不需要担心内存存不下。
model模块的编写
这个模块的功能为和数据进行交互,对外提供访问数据的接口。
对于model模块依旧是要具有命名空间和类的。类名就叫做Model,model的功能为和数据进行交互而我这里的数据自然就是每一道题目的数据了。因为一道题目的数据有很多,所以这里使用一个结构体去描述题目,然后在保存的时候使用题目的编号和描述某个题目的对象进行映射(使用map进行保存即可)
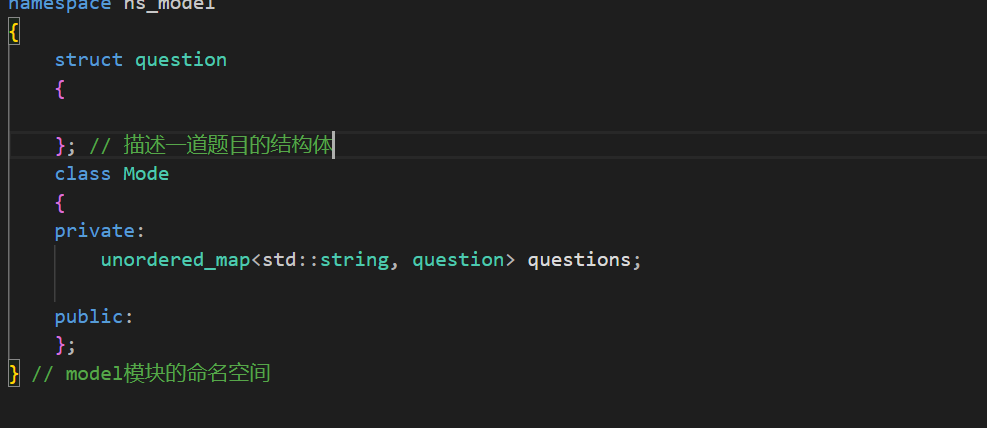
然后先来完成struct 对象的填写,也就是这个题目的信息

然后就是Mode类的填写了。对于这个类来说第一个工作(构造函数)要做的工作应该是将题目加载到内存中。

这个函数的主要目的就是通过question_list所在的路径加载list文件。然后将这个函数放在构造函数中去。
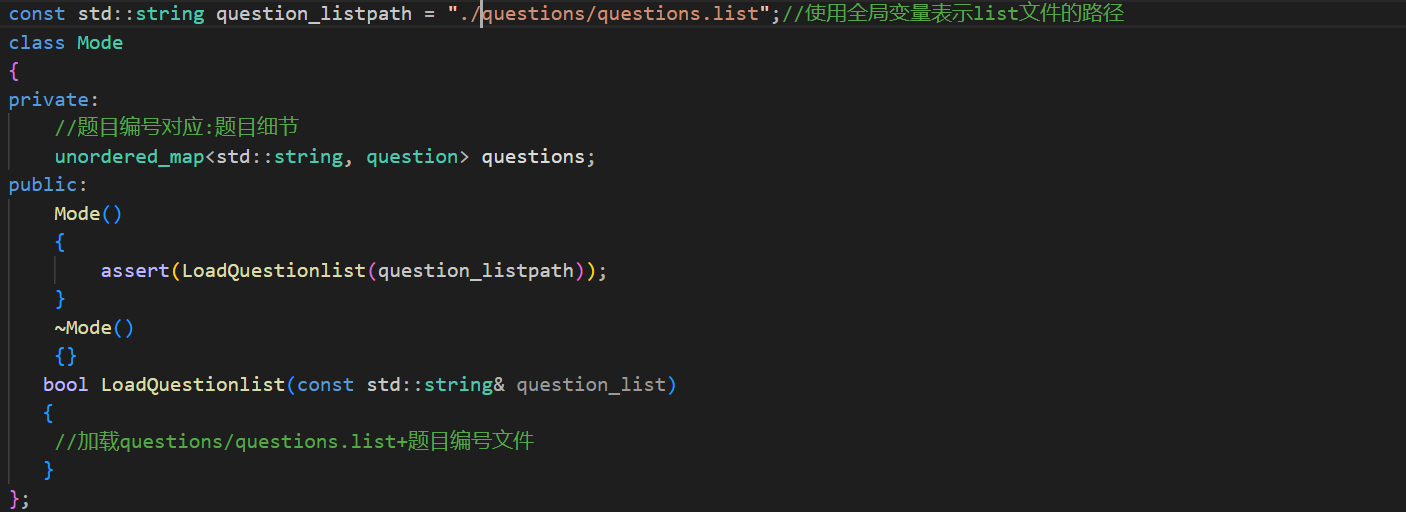
到这里题目列表就有了。然后根据列表信息就能够拿到所有题目的其它信息了。
然后对外提供的功能是什么呢?
第一个就是获取所有的题目,通过vector<question>的输出型参数来给外部。
第二个就是获取一个题目的信息,其实就是通过文件的编号获得一个题目。
其实除此之外还应该有增加题目,删除题目,修改题目的功能,但是这个是文件版本的所以我就不写了。
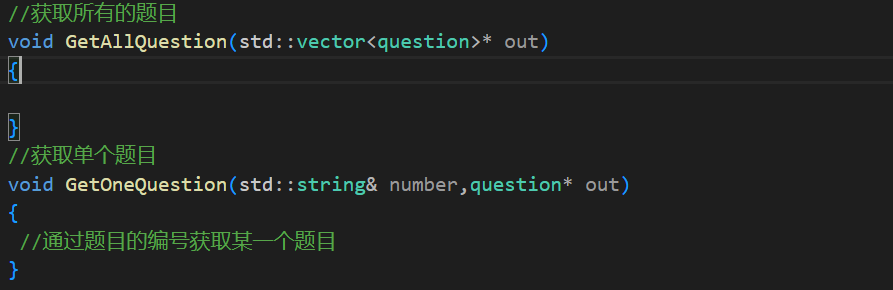
下面就是完成这些函数了。
首先来写获取所有题目列表的函数,虽然后面我能保证获取一个题目和获取所有的题目不会失败,但是为了代码的健壮性还是选择了使用bool作为返回值,而不是void。
第一个就是获取所有题目的函数了:
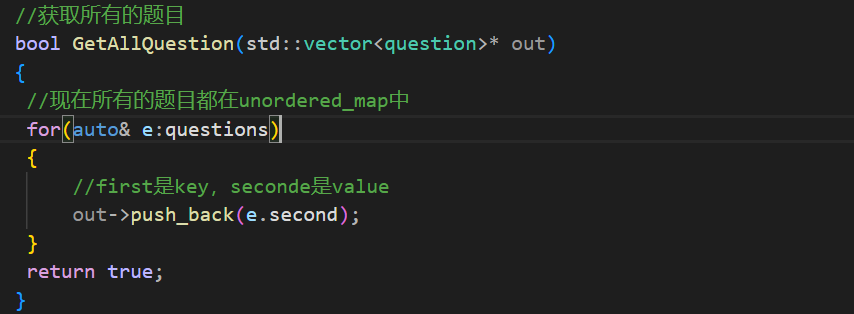
通过编号获取特定的题目:
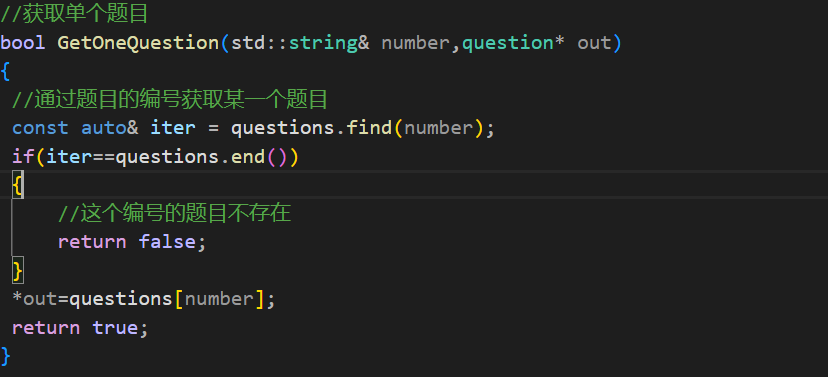
到这里获取所有题目和获取单个题目的函数就完成了,下面就是如何读取配置文件了。也就是load函数了,这个函数需要读取文件中每一个题目的信息,然后将其填写到结构体中,最后插入到容器中。
这个结构体需要的信息都在文件中所以这里的load函数就需要读取文件中的内容了,并且是按行去读取内容。打开文件。
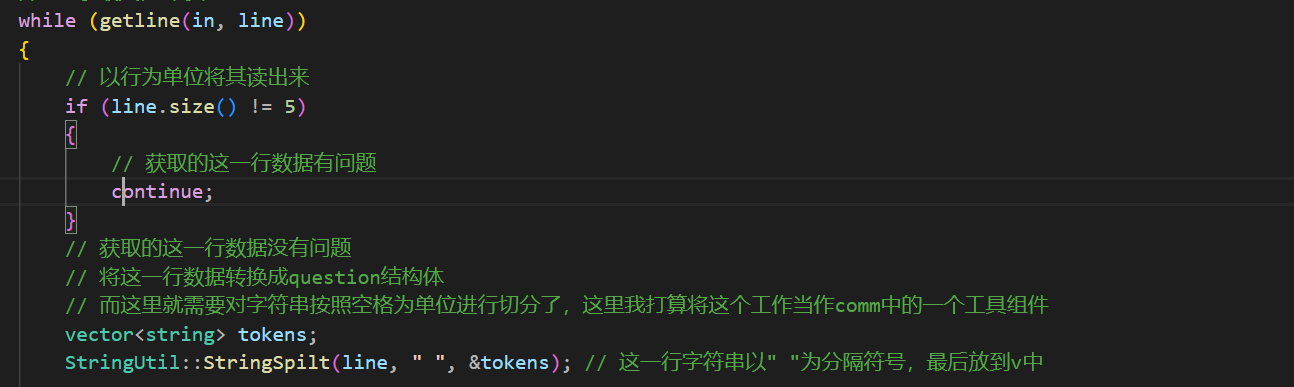
现在已经读到一行数据了,这一行数据中就有一道题目的基本信息,并且是以空格为分隔符号的,而字符串切分的函数不止这一个模块能够使用所以将这一个模块写到comm中.

这个函数的实现之后来做。
然后就是继续完成question的填充工作了。
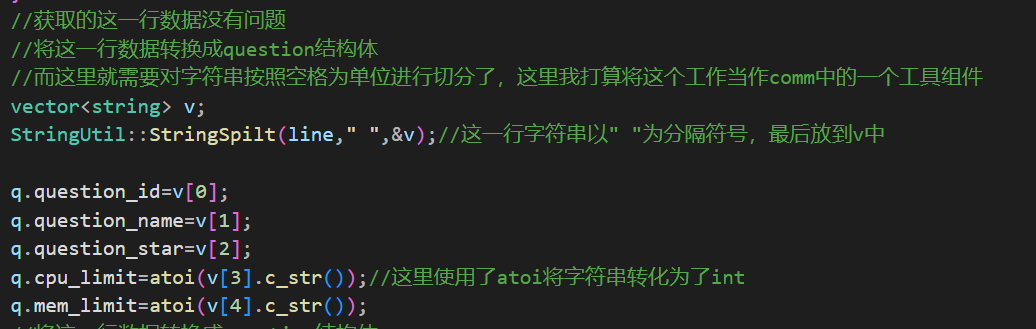
到这里还有三个数据需要填充给question一个是题目的描述,一个是预设的代码信息,一个是测试信息。这是三个信息都在各自的文件中,需要使用之前写的文件工具类中读取文件函数。这里就需要某一个文件具体的文件信息所在的文件路径了:

定制一个这样的全局变量,这个变量+题目编号就是特定的某一个题目的文件夹了。
到这里就完成了。
但是涉及到文件的操作为了之后便于调试最好还是将日志添加上。
首先是在获取所有题目这里,如果用户获取题目失败了,也就是构造函数没有成功:
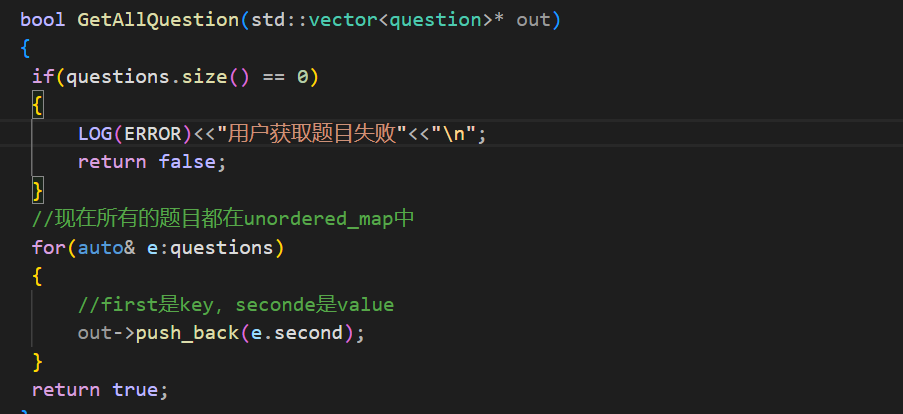
直接打印然后返回false。
获取单个题目也可能会失败
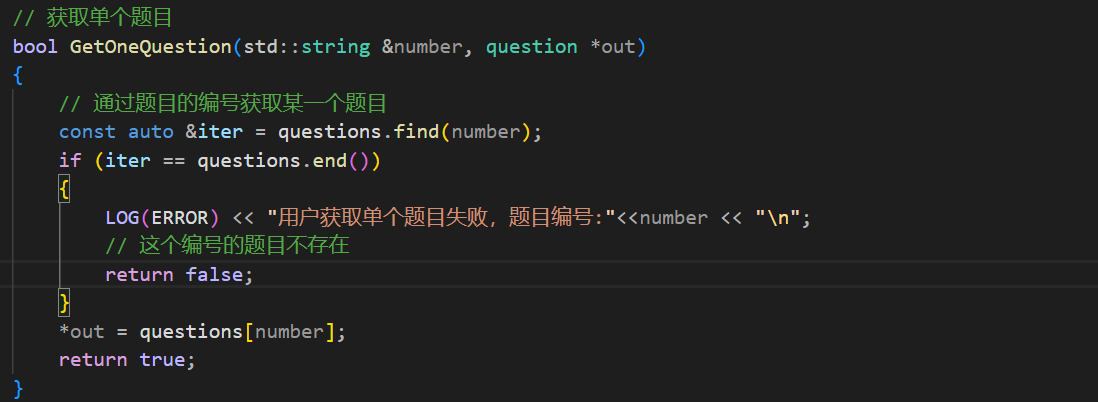
然后如果在load函数中没有将题目加载到map中那么我的这个服务影响到所有正在使用的人,所以这个错误是致命的。
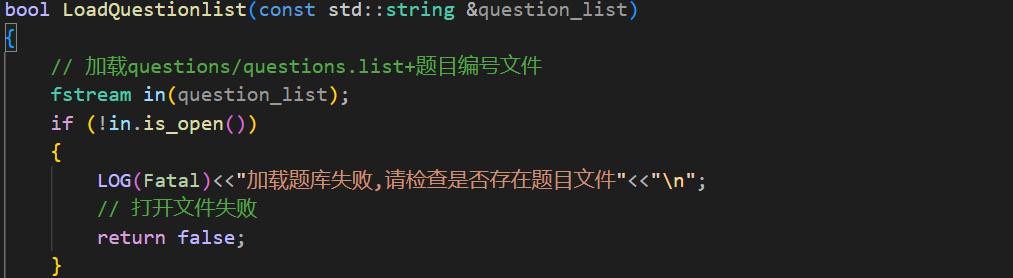
还有可能就是因为题目中的题目不太符合规范导致切分出现了问题:

加载题库成功后,打印一个info信息

最后就是完成字符串切割的函数,当然可以使用string中的函数来完成切分,但是我打算使用boost库中的切分函数,下面就是如何安装boost库:

在centeros上使用上面的指令安装。回到切分的函数上,如果不使用boost库,自己做切分无非就是扫描字符串,找到分隔符然后将这个分隔符号之前的内容拿出来就可以了。但是有了boost库就不需要这样了。首先使用一个代码测试一下这个boost库这个库是c++的准标准库。
测试boost的代码:
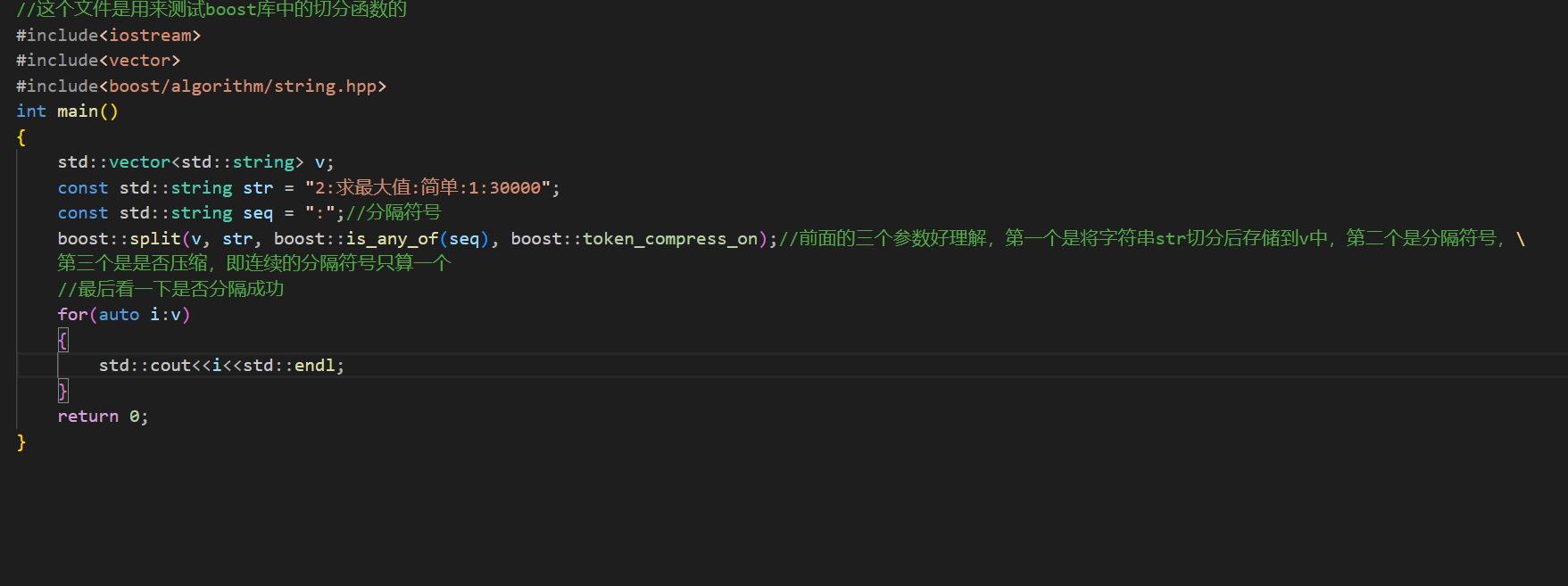
运行测试一下:
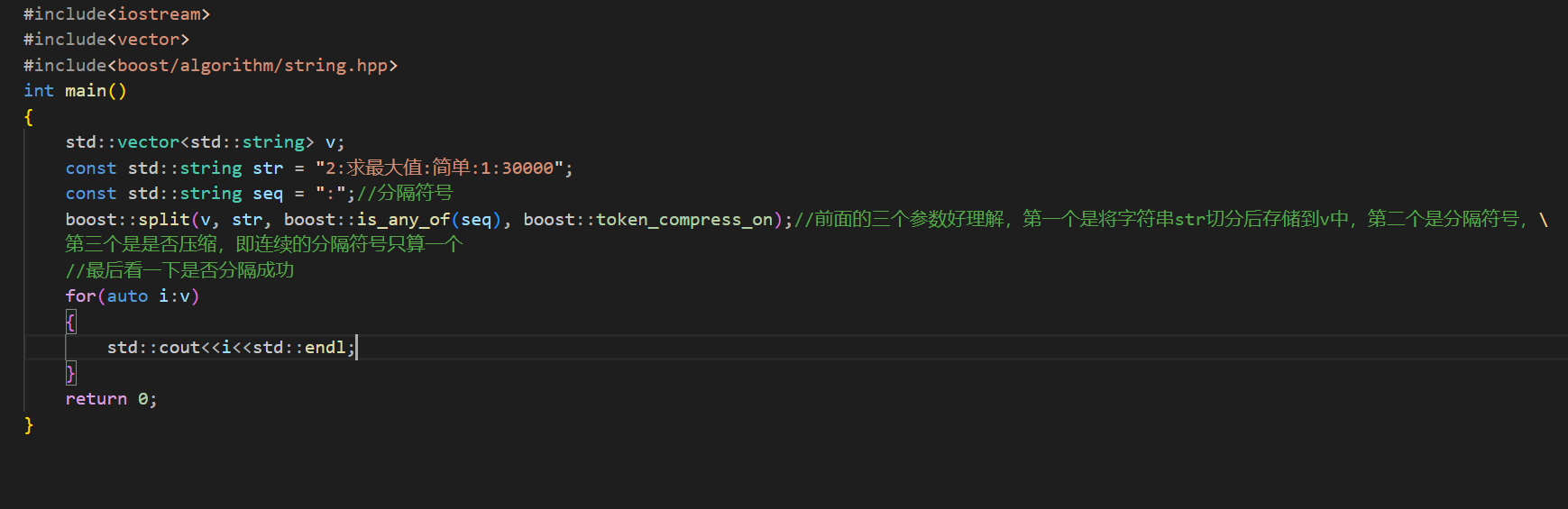
运行测试成功。此时因为我添加了压缩,所以即使你的原始字符串中间使用:::::这样的分隔符号,最后也只会算作一个,如果你是off的话:
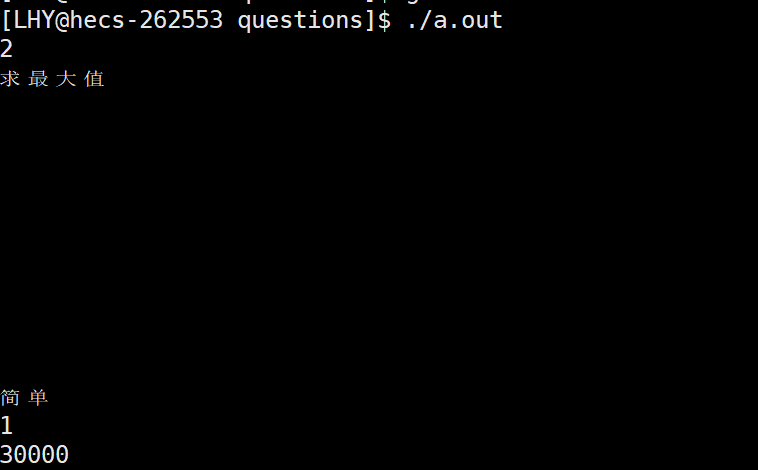
因为在求最大值和难度之间存在很多的分隔符号,这里没有压缩就将这些都保存下来了。
同时这个切分不会影响原始的str。
然后直接将这个使用到之前写的分隔代码中即可:

使用boost库切分就这么简单就完成了,到这里文件版本的model模块就完成了。然后将这个切分增加到mode中:
上面的函数我是写在oj_ model中的。
下面要编写control模块
control模块的编写
现在model已经编写完成了,虽然还没有测试,但是这里先不着急测试,下面先去编写一写control模块,一样这个模块也要有自己的命名空间和类。
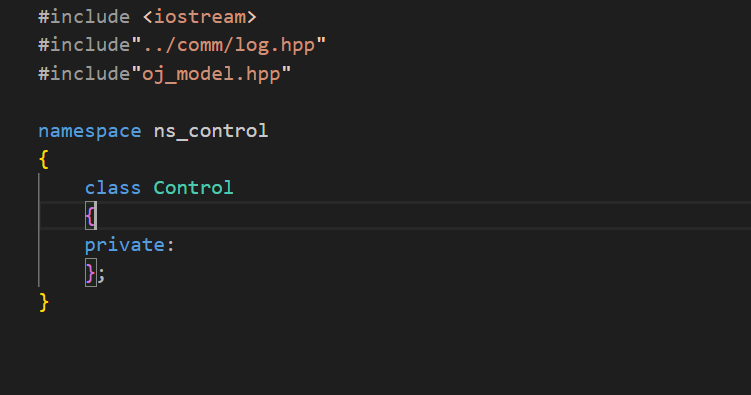
那么在这个控制器中应该有什么呢?control肯定要访问到题目的数据,所以我将model模块直接包含了进来,然后将Model类作为成员对象。
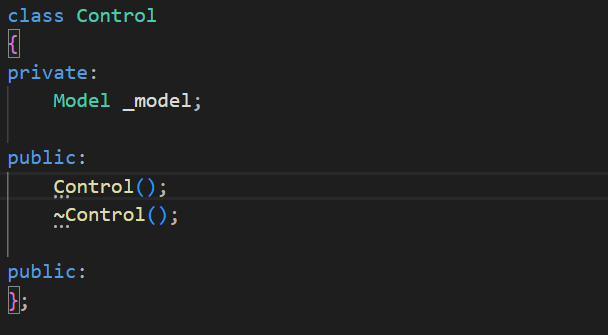
这个control未来是能够被路由功能直接去使用的。所以Control主要负责的就是核心的逻辑。
如何设计函数呢?这里从路由功能开始设计,当oj_server收到一个用户的请求是获取所有的题目,那么我的这个服务最后应该返回一张包含所有题目的html网页。
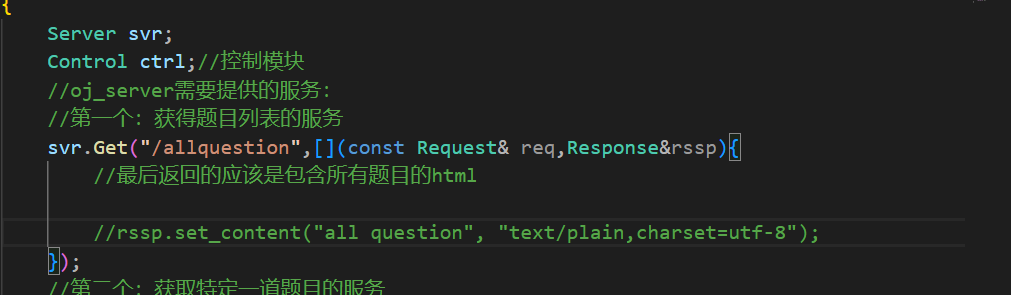
这个工作就交给control来做。因为control模块做的本来就是核心的逻辑。
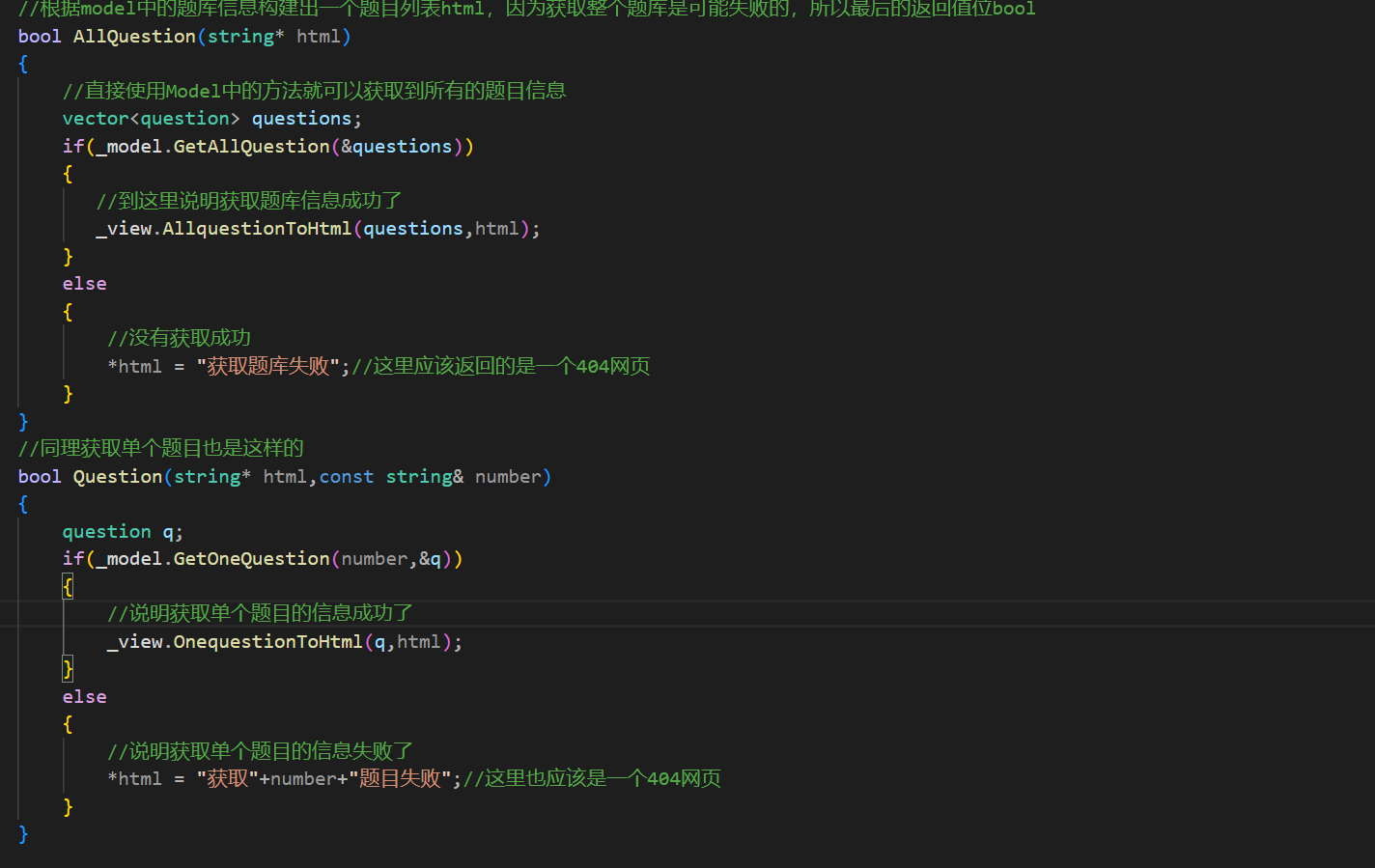
这里就设计一个函数,用于返回获取到题库后的html网页的信息

这个函数因为我还没有写到control中所以存在红线,但是之后会写进去的。这里就使用输出型参数的方式将获取到的网页信息放到html中,最后返回给客户端的浏览器。
同理获取单个题目也是这样的,
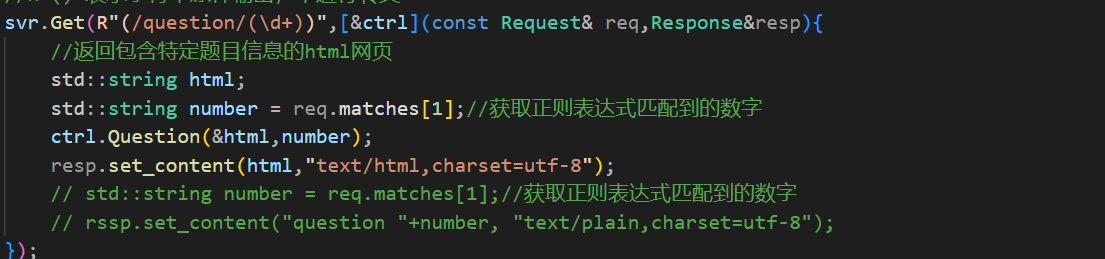
只不过在获取单个题目这里我是知道这个题目的编号的,所以需要将题目编号也传递过去。
至于最后的判题之后再来写。
然后来到control模块中写这两个函数:
这样也只是完成了将题目的信息获取出来了,但是如何将获取的题目信息构造成一个网页,还需要一个模块去完成,这个模块就是view模块。
至于view如何写之后再说,通过这里oj_server主要是获取用户的请求,然后通过control控制器来完成对路由功能的解耦,也就是路由功能的具体实现交给了control模块去实现。
之后的control中还有一个成员就是view模块的成员对象。
这个模块需要使用一个c/c++用于网络渲染的库,这是谷歌开源的渲染程序。
将其下载拷贝到服务器中。然后还需要几个步骤完成安装:

注意以上指令都是在那个第三方库中执行的。
然后就是如何使用这个库了,以上步骤就是将这个库安装到了我系统搜索的默认路径下。
依旧使用之前写的test.cc文件去使用:
然后就能使用这个库了,如何使用呢?可以去看这个项目的手册,这里简单说明一下:
首先需要一个字典例如下面这样的:
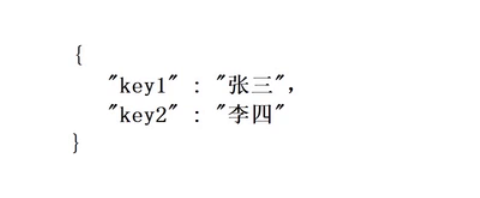
然后在html文件中需要使用下面的方式来表示这个变量会被填充:

这就意味着这里需要的就是,保存数据的数据字典,以及一个待被渲染的网页内容:
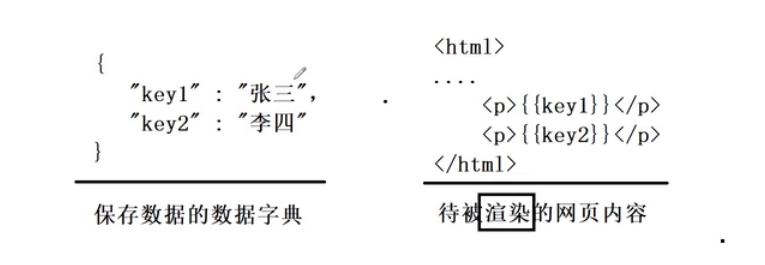
所以所谓的渲染,就是将数据字典中的数据替换到html中,这就是所谓的渲染的功能。
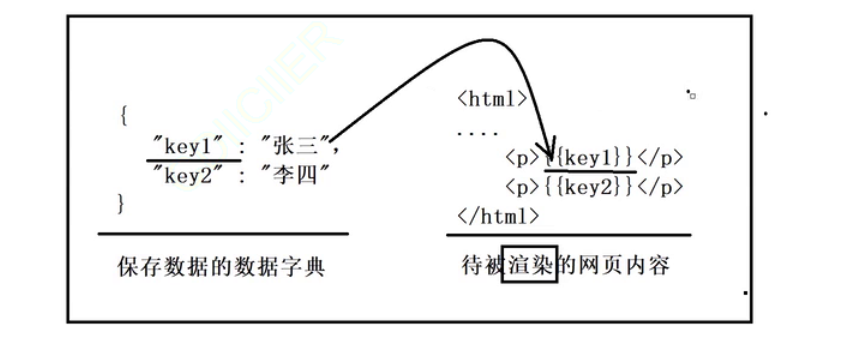
然后来写一下代码:
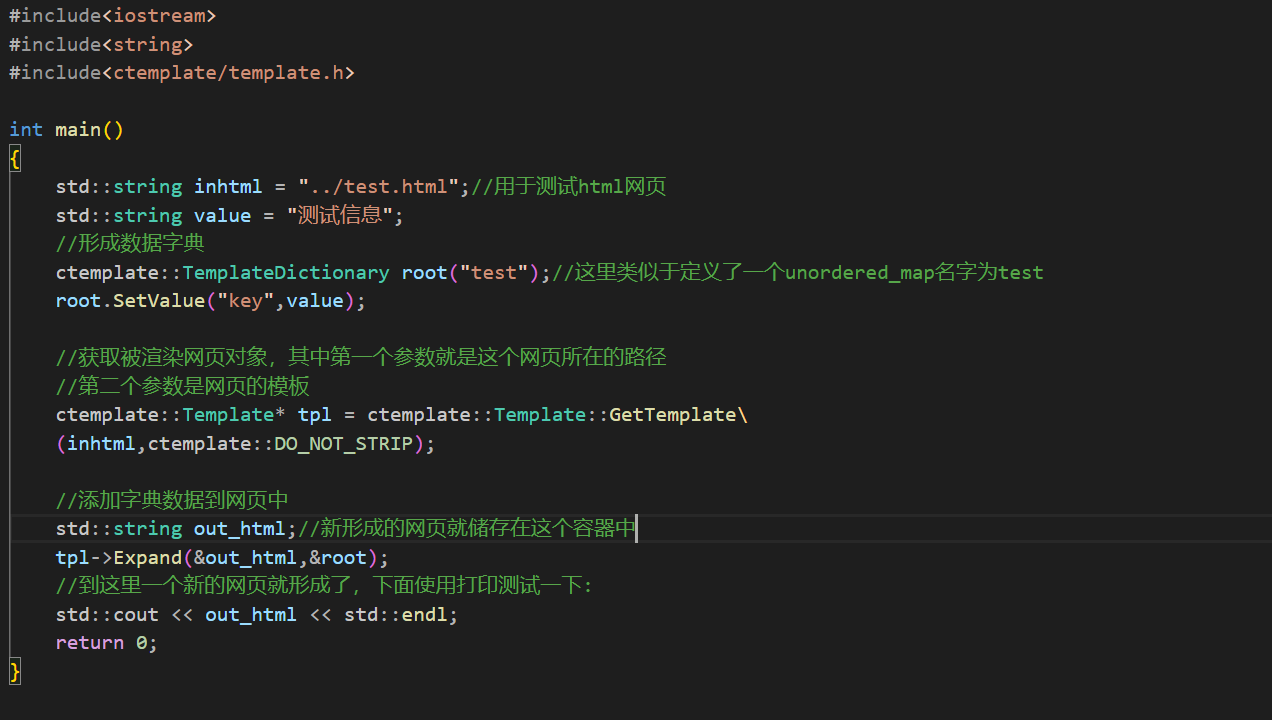
注意这个代码只是用来测试的,到这里基本的使用就完成了。现在在写一个简单的html文件。
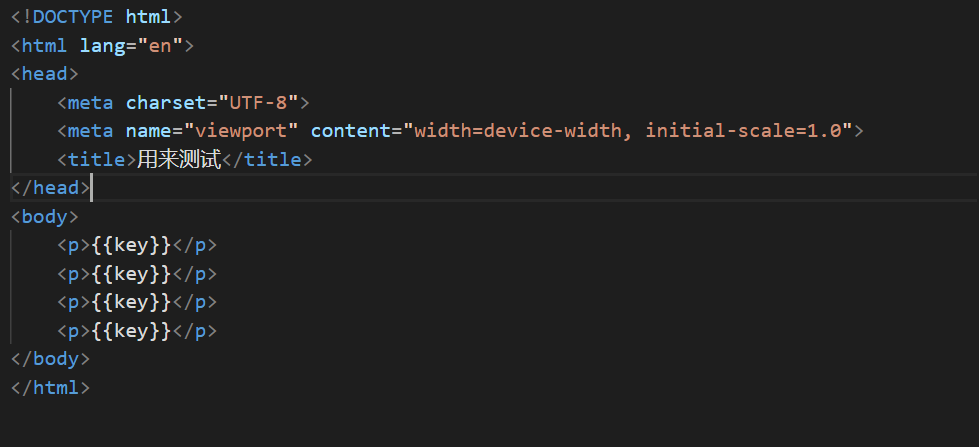
{{}}中的内容就是需要代替的key值,然后编译程序进行测试:

使用ctemplate库了,因为这个库使用了线程,所以还需要加上pthread。
然后运行一下:
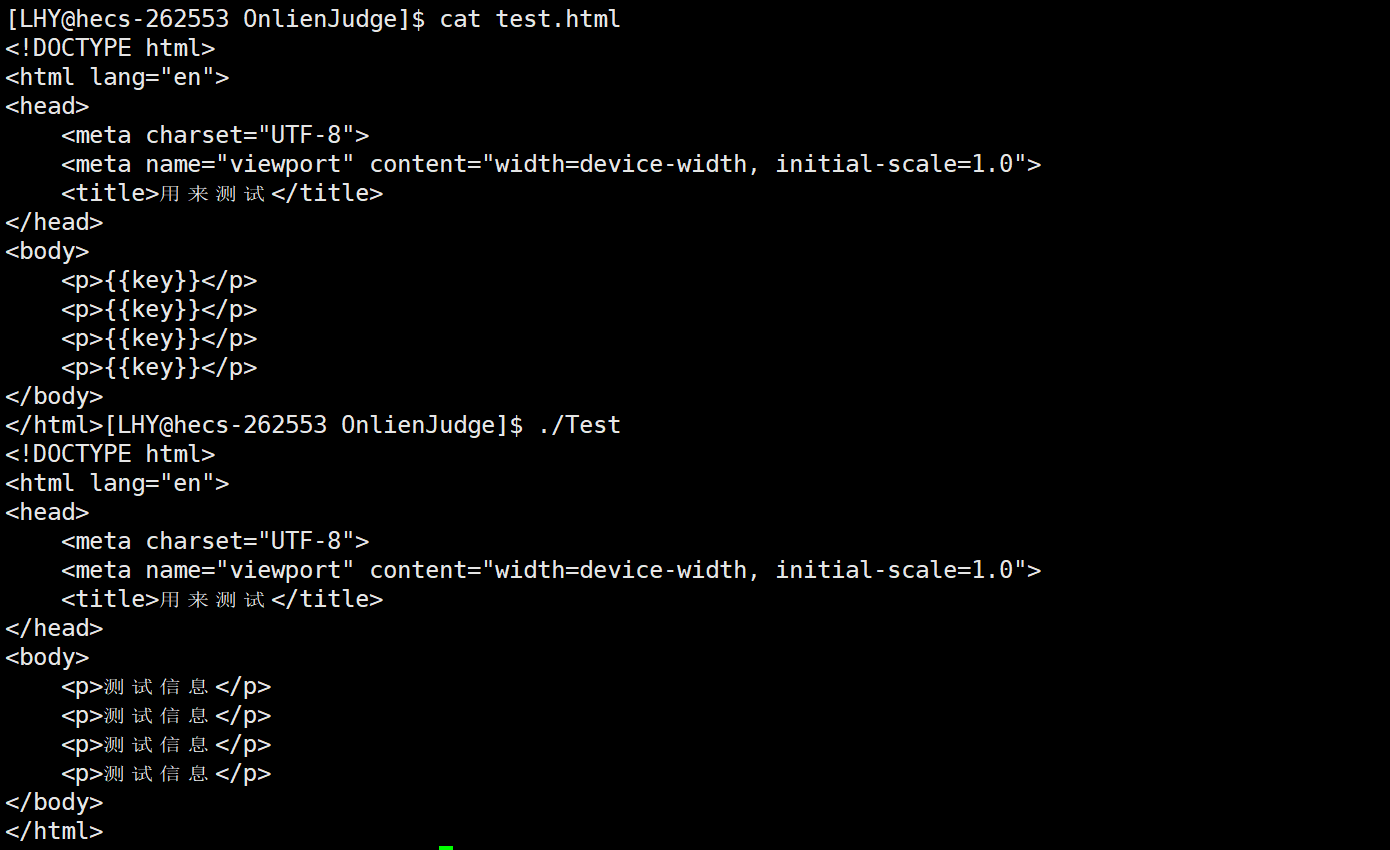
可以看到这个新形成的html信息确实将key替换成为了测试信息。此时就完成了将数据和网页合并形成了一个新的网页,也就完成了渲染工作。
view模块的编写
这里的网页渲染的工作是由view模块完成的,现在要做的就是编写view了。在编写之前需要思考一个这个view我要如何使用。因为control模块中需要我通过一个题库渲染出一整个题目的网页,所以我打算将一整个题库渲染网页的工作写成view的一个函数。以及当用户想要看一道题目的详细信息时也需要通过一个question结构体的信息构建出一个题目的详细信息,这个功能依旧是view的其中一个函数。
这样两个函数接口就设计完成了。一个接口用于接收一个题库,然后将这个题库中的部分题目信息,渲染成一个网页。
另外一个函数用于将特定的题目的详细信息渲染成一个网页。
需要注意的是这里的所有题目的显示我最后想要显示的是一个表格网页。
这样view就设计完成了将这个view添加到control中
到这里这个view就已经设计完成并且在control中使用了。
然后要完成这个view的函数就需要涉及到前后端如何联动了。
因为所有题目的显示我最后想要显示的是一个表格网页,所以我想先认识一下网页的结构。所以需要知道表格在html中是如何写的:
这个信息在w3cschool这个网站上可以学习。
然后将这个添加到我的那个index.html中。
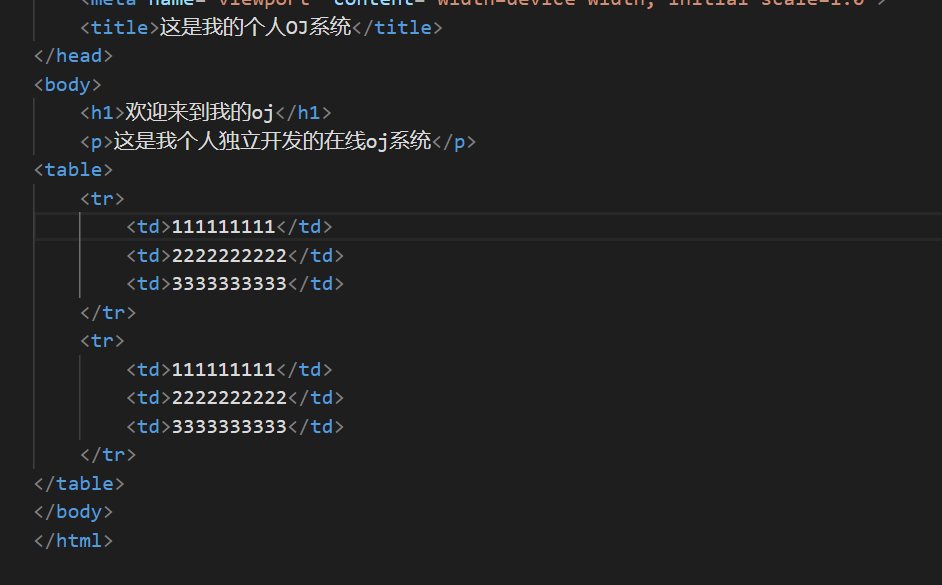
然后启动服务再使用浏览器访问一下我的服务

但是这样没有标题,我还需要一个标题。
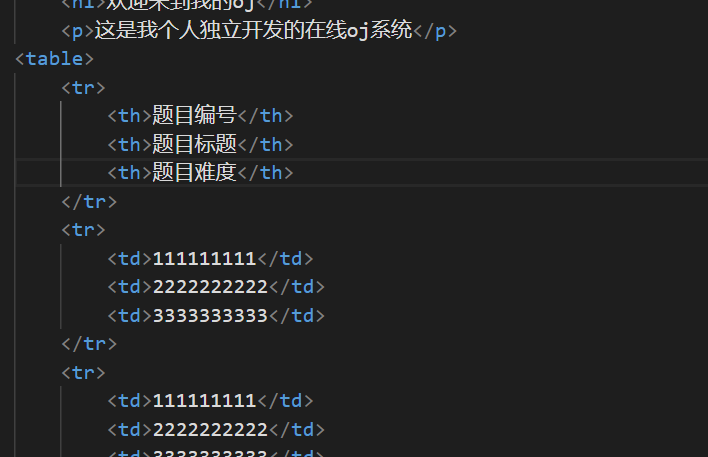

此时一个简单的表格就出现了。虽然目前来看比较难看。但是后面是会进行优化的。只不过网页我最后再去优化。
但是这样很明显是不可行的,如果我的题目很多我还使用这样的代码去显示,对于用户来说使用体验是很差的。之后如果有时间我再来优化这个首页。这里回到view中,view需要渲染两个网页,所以这里新增两个html网页用于给view渲染,一个是题目列表,一个是单个题目的网页。
这两个网页就是给view用于渲染的。
然后就是两个html文件的编写了。
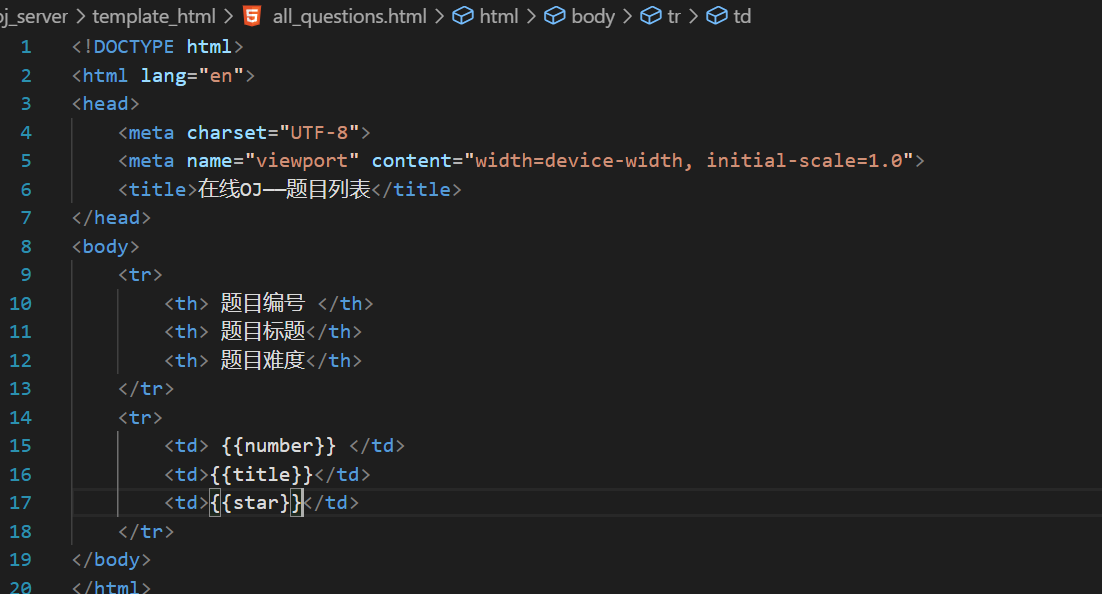
这是题库网页的编写,但是这样渲染出来的题目只有一道很明显是不符合题库的名称的。所以这里就需要循环了。
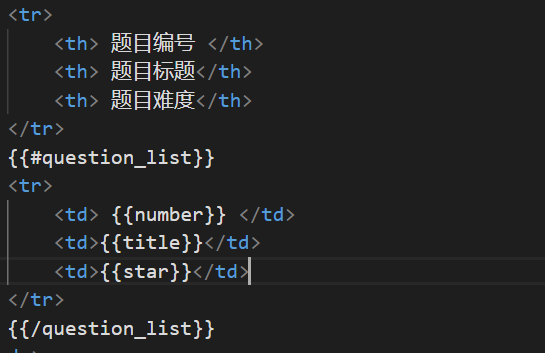
使用这个就意味着在question_list两者中间的部分是可能形成多份的。
这就是现阶段我需要的html需要渲染的内容就是question_list中间的部分。
现在回到view部分首先需要告诉view我这个需要它渲染的网页在哪里,依旧采用的是一个全局变量的方式:
然后就是引入ctemplate库来完成使用数据和网页渲染成新的网页了。

第二步形成数据字典:

如果只是单独的一道题目的话下面就可以使用set往这个数据字典中写信息了,但是这里我想形成的问题网页需要多个题目,所以这里需要使用循环的方式,将多个信息添加到网页中。这里就可以将上面的root当作根网页,然后形成子网页,往子网页中不断添加数据,最后就会形成一个含有多道题目信息的网页。

然后就可以往这个子字典中添加set数据了
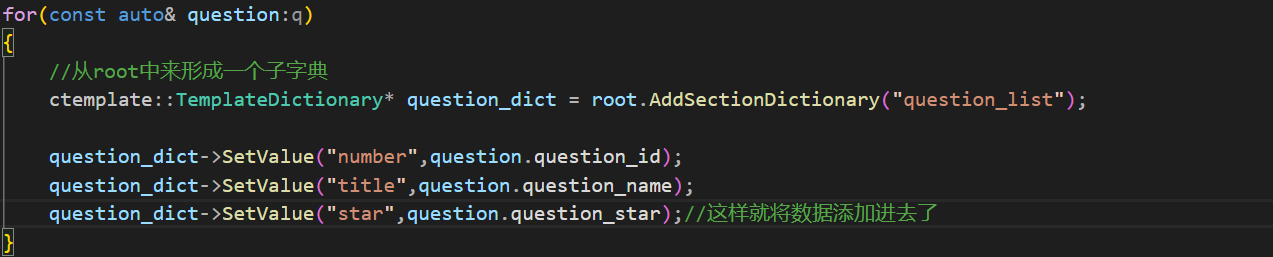
下一步就是获取被渲染的网页了。

此时当在oj_server中请求所有的题目时,就会调用control模块中的加载和渲染题库的功能,control会调用model模块完成对题库的加载,然后调用view模块中的渲染网页的函数(也就是上面的函数)。完成渲染之后,ctrol模块会将这个渲染的网页信息返回给oj_server,oj_server在发送给客户端。那么能否完成呢?这里可以测试运行一下,在测试之前,为了方便跳转我在首页index.html中添加一点东西:
这样是为了便于跳转。
然后运行测试:

可以看到这个题目的页面就正式显示出来了。虽然没有按照正常的排序,但是这个问题不大,只要之后对储存题目的容器进行按照编号排一个序就完成了。
到这里已经完成了对题库的渲染,下面的问题就是如何完成对单个题目的渲染,也就是让用户能够看到一个题目的详细的信息。
依旧是要准备好一个网页用于渲染单个题目。要渲染给单个题目的信息有这个题目标题,这个题目的难度,这个题目的编号,这个题目的信息,以及给用户提供写代码的位置,以及测试用例。
基于这些来写一个html网页

其中的number就是题目的编号,而tittle就是题目的标题。网页的标题已经有了,现在需要的就是给用户一个代码编辑区,以及当前题目的标题和难度和题目的描述
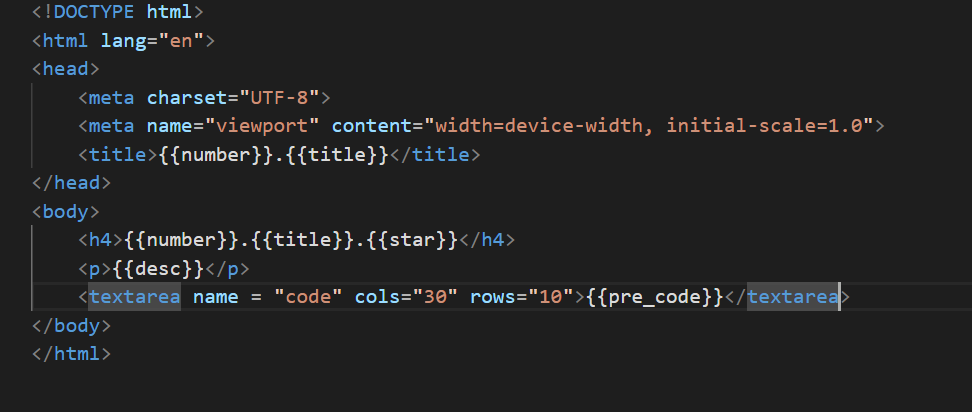
其中的<h4>就是题目的标题,其中desc就是就是这个题目的描述。到这里需要使用到的网页元素就完成了。
下面就是渲染这个网页了。
步骤和之前是一样的:
root.SetValue("pre_code",q.question_header);//预设的代码
但是现在从题库还是无法直接连接到我的单个题目中。
所以这里我需要在题目的网页中新增一个连接
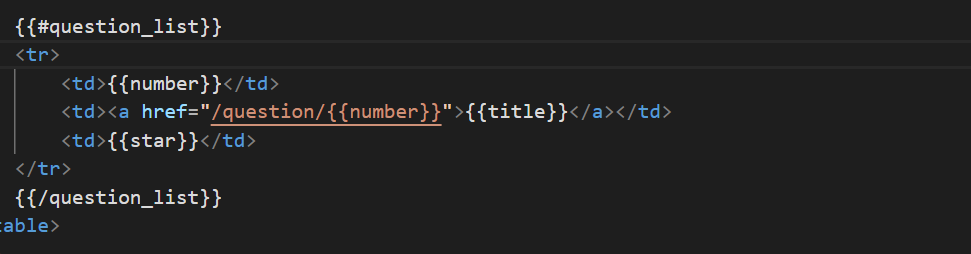
这样就能够通过点击题目去形成对应题目的网页了。
这样是否可行呢?运行测试一下:

之后点击一下就可以到下面的框了,但是这里的这个代码框有点小,我这里手动扩大了。但是这个问题不大,修改一下html即可完成

那么当用户在输入框输入信息之后,下面的功能就是提交了。
到时候点击提交就可以提交用户自己写的代码。虽然这个网页很简单,但是大体的框架就是这样的。
到这里网页请求的基本框架就完成了。下面就是提交功能了。但是要完成提交功能,首先我的oj_server需要先完成判题功能。而判题就涉及到选择后端服务的过程了。此时就有两个路径了。负载均衡逻辑之后再去进行网页的优化。