目录
了解PDF页面信息对于有效处理、编辑和管理PDF文件至关重要。PDF文件通常包含多个页面,每个页面可能有不同的尺寸、方向、旋转角度以及其他属性。在很多应用场景下,获取这些页面信息可以帮助我们更好地控制PDF内容的显示、打印或转换。这篇文章将介绍如何使用Python 获取PDF 文档的各种页面信息,包括:
- 获取PDF页数
- 获取PDF页面尺寸
- 获取PDF页面旋转角度
- 获取PDF页面方向
- 获取PDF页面标签
- 获取PDF页面边框信息
安装所需库
要在Python中获取PDF的各种页面信息,可以使用Spire.PDF for Python库。它是一个专门用于在Python应用程序中创建、读取、操作和转换PDF文档的库。
你可以通过在终端运行以下命令来从PyPI安装Spire.PDF for Python:
python
pip install Spire.PDFPython获取PDF页数
PDF文件中的页数是基本信息之一,了解文档总共有多少页可以帮助我们在操作文件时做出相应的调整。比如在拆分文件、打印特定页码或进行内容提取时,知道文件总页数是至关重要的。
以下是获取PDF页数的具体步骤:
- 使用PdfDocument类打开PDF文件。
- 使用PdfDocument.Pages.Count属性来获取总页数。
实现代码:
python
# 导入所需的模块
from spire.pdf.common import *
from spire.pdf import *
# 打开PDF文档
pdf = PdfDocument("Sample.pdf")
# 获取页面总数
page_count = pdf.Pages.Count
# 输出页面总数
print(f"该PDF有 {page_count} 页。")
pdf.Close()Python获取PDF页面尺寸
PDF的页面尺寸决定了内容如何在页面上呈现,不同的文件可能使用不同的纸张尺寸,如A4、A3等。了解页面尺寸可以帮助我们确保内容适合打印或显示。
以下是获取PDF页面尺寸的具体步骤:
- 使用PdfDocument类打开PDF文件。
- 获取特定页,使用PdfPageBase.Size.Width和PdfPageBase.Size.Height来获取页面宽度和高度。
实现代码:
python
# 导入所需的模块
from spire.pdf.common import *
from spire.pdf import *
# 打开PDF文档
pdf = PdfDocument("Sample.pdf")
# 通过索引获取第一页(索引从0开始)
page = pdf.Pages[0]
# 获取第一页的宽度和高度
width = page.Size.Width
height = page.Size.Height
# 输出第一页的尺寸
print(f"第一页的尺寸为 {width} x {height} 磅。")
pdf.Close()注意,以上获取的值以磅(pt)为单位,你可以使用 Spire.PDF for Python 提供的 PdfUnitConvertor 类在磅与其他单位例如英寸、像素、厘米和毫米之间进行转换。转换代码如下:
python
# 创建 PdfUnitConvertor 对象
converter = PdfUnitConvertor()
# 将磅转换为英寸
inch_value = converter.ConvertUnits(point_value, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch)
# 将磅转换为像素
pixel_value = converter.ConvertUnits(point_value, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel)
# 将磅转换为厘米
centimeter_value = converter.ConvertUnits(point_value, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter)
# 将磅转换为毫米
millimeter_value = converter.ConvertUnits(point_value, PdfGraphicsUnit.Point, PdfGraphicsUnit.Millimeter)Python获取PDF页面旋转角度
有时PDF中的页面可能由于编辑或导出过程中发生旋转,导致页面的内容显示方向不正确。获取页面的旋转角度(如0度、90度、180度或270度)可以帮助我们判断页面是否需要旋转以便正确显示。
以下是获取PDF页面旋转角度的具体步骤:
- 使用PdfDocument类打开PDF文件。
- 获取特定页,使用PdfPageBase.Rotation属性来获取页面的旋转角度。
实现代码:
python
# 导入所需的模块
from spire.pdf.common import *
from spire.pdf import *
# 打开PDF文档
pdf = PdfDocument("Sample.pdf")
# 通过索引获取第一页(索引从0开始)
page = pdf.Pages[0]
# 获取第一页的旋转信息
rotation_info = page.Rotation
# 确定旋转角度
if rotation_info == PdfPageRotateAngle.RotateAngle0:
rotation_angle = "0度(正常)"
elif rotation_info == PdfPageRotateAngle.RotateAngle90:
rotation_angle = "90度(顺时针旋转)"
elif rotation_info == PdfPageRotateAngle.RotateAngle180:
rotation_angle = "180度(倒置)"
elif rotation_info == PdfPageRotateAngle.RotateAngle270:
rotation_angle = "270度(逆时针旋转)"
else:
rotation_angle = "未知旋转角度"
# 输出第一页的旋转角度
print(f"第一页的旋转角度为 {rotation_angle}。")
pdf.Close()Python获取PDF页面方向
PDF页面的方向可以是纵向(Portrait)或横向(Landscape)。不同的页面方向适用于不同的内容展示方式。例如,表格或图表可能更适合横向展示,而文本内容则通常为纵向。判断页面的方向有助于确保页面内容在显示或打印时的布局正确。
以下是获取PDF页面方向的具体步骤:
- 使用PdfDocument类打开PDF文件。
- 获取特定页,根据页面宽高来判断方向。
- 宽度小于高度为纵向。
- 宽度大于高度为横向。
实现代码:
python
# 导入所需的模块
from spire.pdf.common import *
from spire.pdf import *
# 打开PDF文档
pdf = PdfDocument("Sample.pdf")
# 通过索引获取第一页(索引从0开始)
page = pdf.Pages[0]
# 获取第一页的宽度和高度
width = page.Size.Width
height = page.Size.Height
# 检查页面是纵向模式还是横向模式
if width > height:
print("第一页是横向模式。")
else:
print("第一页是纵向模式。")
pdf.Close()Python获取PDF页面标签
页面标签(Page Label)在文档导航时非常有用,通常用于显示自定义页码,帮助用户快速找到指定内容。
实现步骤:
- 使用PdfDocument类打开PDF文件。
- 获取特定页,使用PdfPageBase.Label属性获取页面的自定义标签信息。
实现代码:
python
# 导入所需的模块
from spire.pdf.common import *
from spire.pdf import *
# 打开PDF文档
pdf = PdfDocument("Sample.pdf")
# 通过索引获取第一页(索引从0开始)
page = pdf.Pages[0]
# 获取第一页的标签
label = page.PageLabel
# 输出第一页的标签
print(f"第一页的标签是: {label}")
pdf.Close()Python获取PDF页面边框信息
PDF拥有5种不同的页面边框:
- 媒体框(MediaBox ):定义页面上需要印刷的物理介质的范围。
- 裁剪框(CropBox ):定义页面显示或打印的内容范围,默认值为页面的媒体框。
- 出血框(BleedBox ):PDF 1.3 起开始支持,指在PDF文档中,为了确保印刷品的完整性,在成品尺寸的四周加上一定距离的安全区域。这个安全区域通常为3mm,目的是为了减少裁切时的误差,防止重要内容被裁切掉或留下白边。
- 裁切框(TrimBox ):PDF 1.3 起开始支持,显示印刷和裁切后,裁切文档的最终尺寸,也称为成品框。
- 作品框(ArtBox ):PDF 1.3 起开始支持,定义页面上有意义的内容,包括可能存在的留白。
详情可以参考以下示意图:
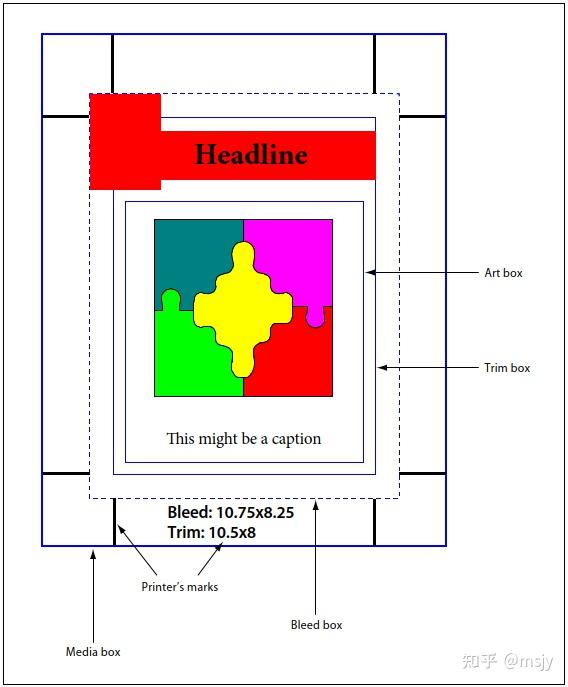
以下是获取PDF页面边框信息的具体步骤:
- 使用PdfDocument类打开PDF文件。
- 获取特定页,使用PdfPageBase.MediaBox、PdfPageBase.CropBox、PdfPageBase.BleedBox、PdfPageBase.TrimBox和PdfPageBase.ArtBox等属性分别获取对应的边框。然后获取它们的相关信息,如尺寸和坐标位置。
实现代码:
python
# 导入所需的模块
from spire.pdf.common import *
from spire.pdf import *
# 打开PDF文档
pdf = PdfDocument("Sample.pdf")
# 通过索引获取第一页(索引从0开始)
page = pdf.Pages[0]
# 获取第一页的媒体框、裁剪框、出血框、裁切框和作品框
media_box = page.MediaBox
crop_box = page.CropBox
bleed_box = page.BleedBox
trim_box = page.TrimBox
art_box = page.ArtBox
# 输出每个框的尺寸和坐标
print(f"媒体框: 宽度 = {media_box.Width}, 高度 = {media_box.Height}, X = {media_box.X}, Y = {media_box.Y}")
print(f"裁剪框: 宽度 = {crop_box.Width}, 高度 = {crop_box.Height}, X = {crop_box.X}, Y = {crop_box.Y}")
print(f"出血框: 宽度 = {bleed_box.Width}, 高度 = {bleed_box.Height}, X = {bleed_box.X}, Y = {bleed_box.Y}")
print(f"裁切框: 宽度 = {trim_box.Width}, 高度 = {trim_box.Height}, X = {trim_box.X}, Y = {trim_box.Y}")
print(f"作品框: 宽度 = {art_box.Width}, 高度 = {art_box.Height}, X = {art_box.X}, Y = {art_box.Y}")
pdf.Close()以上就是如何使用Python获取PDF页数、页面尺寸、旋转角度、页面方向、页面标签和页面边框等信息的全部内容。