
**序言:**当前基于 Transformer 架构的大语言模型人工智能技术,由于投入大、成本高、人才需求苛刻,导致许多企业望而却步。动辄几千万甚至上亿的成本,现实中有几家企业能够承担?真正具有竞争力的技术应当在成本上更低、效率上更高,因此,各大院校和商业公司已不再仅仅关注模型的参数规模,而是在积极探索创新方法,显著降低大语言模型的研发与使用成本,使得大多数企业也能轻松采用。斯坦福大学的这一最新研究成果正是朝着这一目标迈出了一大步------将一个 80 亿参数模型的训练成本降至 20 美元。同时,已有中国企业基于这一研究成果推出了适用于企业的私有 AI 模型及服务器、前端应用的垂直解决方案,为 AI 在企业中的私有化部署铺平了道路。
斯坦福大学的一组研究人员推出了LoLCATs,一种线性化标准Transformer LLMs的新方法,大幅降低了计算需求,同时保留了大部分最先进的(SOTA)性能。而这一切只需要几个小时的GPU计算,总成本不到20美元,最终使模型性能在训练投入上的效率提高至35,500倍。这听起来难以置信,但他们今天展示的三种技巧让这一切成为可能。这项非凡的成就可能很快会成为AI工程团队追求一流表现的基本技能。
那么,他们是如何做到的?
标准LLM的问题: 大型语言模型(LLM)为AI行业带来了巨大的激动与资金,似乎正在走向全球主导的直线路径,作为一种能让文明迈向新时代的优越技术(至少,这是他们想让我们相信的)。令人惊讶的是,这一巨大的赌注迫使大科技公司投资数十亿,集中于一种架构类型------Transformer,然而它们效率极低,所以成本巨高,提高Transformer的效率就必然会降低成本。
Transformer是我们所需的一切。 简单来说,AI不过是一个数据压缩算法,输入数据后学习其中的模式,进而利用这种已掌握的知识做出有用的预测。在现有的实现方法中,没有一种比Transformer更接近所需的效果,原因有二:
-
它们完全可并行化,非常适合用大量数据训练模型。
-
模型的规模越大,效果越好,这引发了人们在如何扩大模型模型和训练预算上的投资和研究狂潮。
然而,以Transformer为基础的模型虽然具有无与伦比的表现力,并不意味着它们是完美的,因为它们的优点带来了自身的问题。
平方复杂度问题。 最大的问题在于它们无法压缩状态或内存。换句话说,如果你希望模型能记住某些信息,那就必须将其以原始状态存储在内存中。人类并不是这样记忆的。人类不会记住所有的事情或经历的事件;人类仅保留被认为重要的部分。
想象你在读一本书。如果你在第11章,主角可能会提到书中之前发生的事情,或许是第1章。如果你留心了,你可能会记得,否则可能需要回头重读那部分。然而,这对内存负担并不是问题,因为如果第2章中没有发生什么特别的事情,你可以随意忘记它。Transformer并不是这样处理信息的。当阅读第11章时,如果需要回忆第1章的内容,它会立即记住,因为它依然能够访问整个11章内容。事实上,如果不是我们在LLM推理中构建的KV缓存(KV Cache),Transformer实际上在阅读每一个新词时都在重读之前的内容。
这是否显得低效?希望是如此,因为确实如此。
但这意味着什么呢?简单来说,这种未压缩的记忆在序列变长时会增长。如果你在第15章,之前的章节会积累,内存需求比读第8章时(只有七个章节)大得多。
更糟的是,由于底层注意力机制的工作方式(为了节省篇幅这里不展开讨论),我们需要为每个章节的每个词存储两种信息(键和值)。这意味着Transformer的计算和内存复杂度是O(n²),也就是说,每当序列长度加倍,计算和内存需求就增加四倍(而三倍则意味着增加九倍)。
通过FlashAttention技术(一部分今天的研究人员开发的),我们帮助降低内存需求至次平方复杂度,通过避免将整个注意力矩阵物化到内存中,也就是说,以上问题部分解决。然而,FlashAttention并未处理计算复杂度,它仍然是平方复杂度(特别是O(n²*d),其中n是序列长度,d是模型维度,即每个向量嵌入的数字量)。原因是因为我们不压缩内存,每个词必须关注每一个先前的词,而在Transformer中主要的操作是成对的乘法运算,因此计算在序列长度方面仍然是平方复杂度。
但现在,一组研究人员找到了将计算复杂度扩展至次平方领域的方法。
如何线性化注意力 正如我们之前提到的,Transformer依赖于一种称为注意力机制的数学操作,它的复杂度在序列长度方面是平方的。简单来说,较长的序列会急剧增加计算需求。然而,其他注意力机制(如线性注意力)则具有线性复杂度,虽然它们在纸面上表现不佳(即线性注意力模型表现较差)。
但如果我们通过训练线性注意力层去模仿它们更高计算密度的对等层,会发生什么呢?
因此,LoLCaTs的目标是创建线性化的LLM,它们在保留其平方复杂度对等体性能的同时具备成本效率。
为此,他们将问题分为三步。
步骤1:替换层 线性化模型的第一步是插入一组线性注意力层,并训练它们模仿标准注意力层的输出。如下所示,通过两层输出之间的均方误差(MSE),我们可以训练新层表现得像原始层。
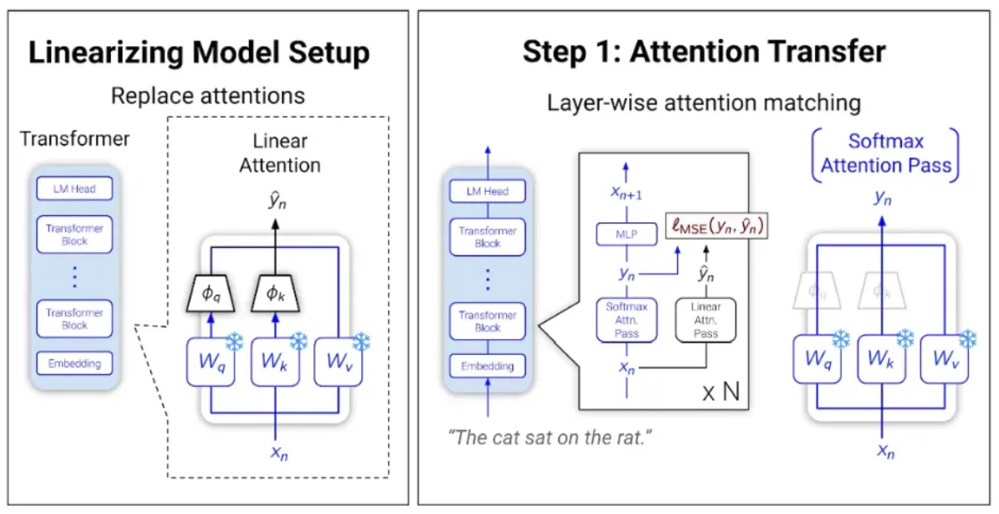
但此时,虽然新层个体上在模仿对等层,已创建的模型表现异常。为了解决这个问题,我们需要重新训练模型执行标准的下一个词预测任务。
步骤2:LoRA微调 当然,重新训练模型以提高效率似乎是一个难以证明合理性的资源使用方式。幸运的是,完全模型微调并非必要,因为有了LoRA适配器。我在这个通讯的多个期刊中提到过它们,但概念是:对任何给定任务,模型本质上是低秩的。简而言之,只有一小部分权重对任何给定预测是重要的。因此,我们可以添加一组小权重,称为适配器,然后将其添加到每层中,同时保持原始模型权重'未触动'。某种程度上,这些适配器会根据它们所训练的数据调整模型的行为。
重要的是,这些适配器比实际模型小得多,因此它们可以快速且低成本地训练。
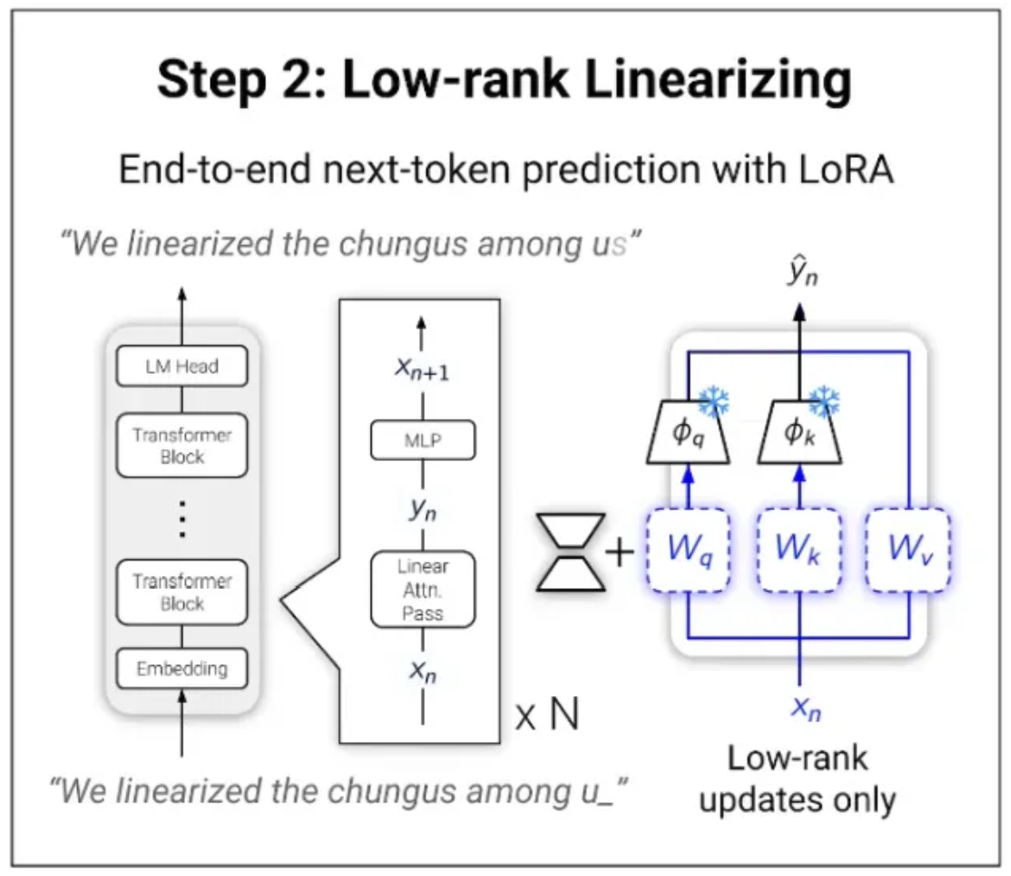
经过LoRA训练后,我们得到一个在下一个词预测上表现与原模型相似的模型,尽管其具有线性注意力层。
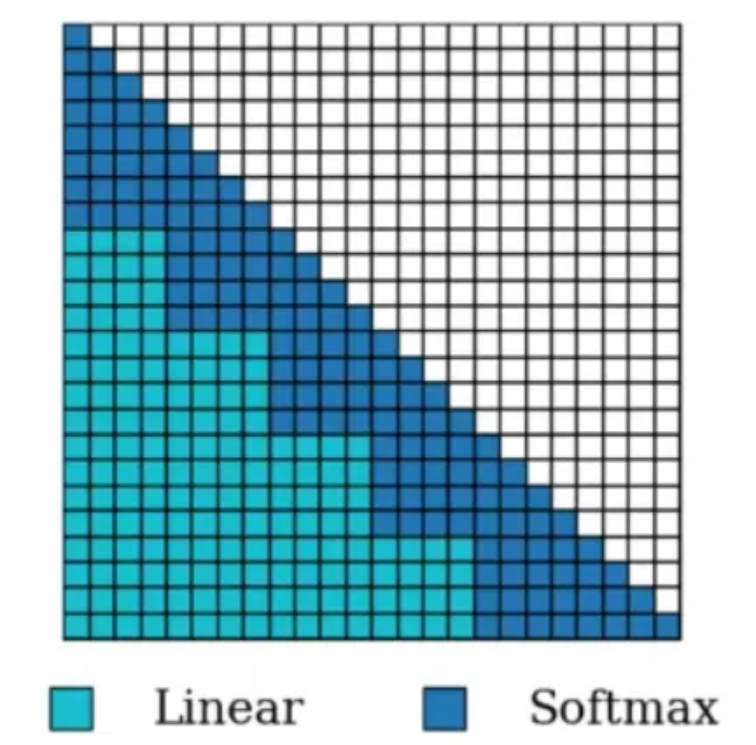
该模型并非完全线性化。实际上,他们将标准注意力(平方)与线性注意力结合起来,因此如果一个序列有D=N+M个词,最后的M个词使用标准注意力计算,而前面的N个(数量更多)则使用线性注意力。
这在标准注意力的表现力和线性注意力的计算效率之间找到了一个良好的平衡。由于语言通常具有邻近性偏向,这意味着最近的词通常比过去的词对预测下一个词更重要,我们使用softmax注意力(标准注意力)处理更近的词,并使用线性注意力处理其余词。
序列中最后的M个词采用传统计算,其他则采用线性形式。
而在此之上,研究人员添加了最后一步。
步骤3:分层优化 在注意力迁移过程中,我们将模型中的所有层一起更新。然而,研究人员观察到,这意味着模型的最后几层具有更大的均方误差(MSE),对于像Llama 3.1 405B这样更深层的模型(比小型版本拥有更多层)尤其如此。因此,他们分批训练层,以确保不会发生这种情况。
那么,最终结果是什么?
最先进...且便宜
LoLCaTs通过在4000万个tokens上优化0.2%的模型参数,大幅提升了线性化大型LLM的效率,关闭了与完全softmax(标准)Transformer性能差距的80%,尽管所用训练tokens量级少了数百倍,比标准微调高达35,500倍的训练效率。
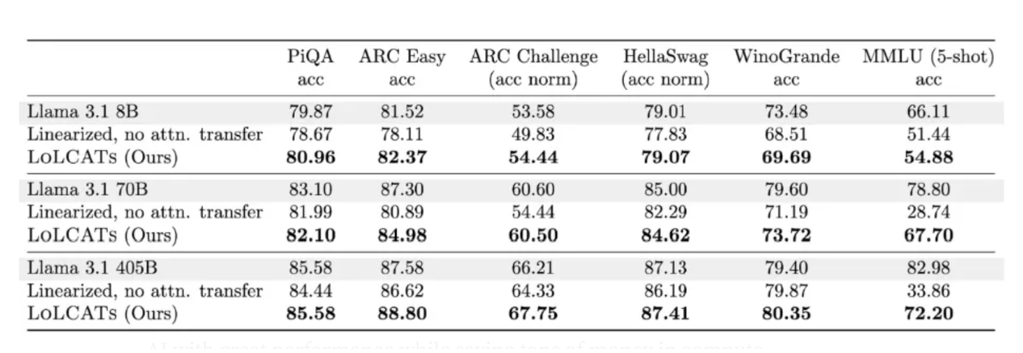
更令人印象深刻的是,在所有三个Llama尺寸上,LoLCaT模型的表现类似于原始模型,但享有线性注意力层带来的显著计算效率,而不是完全的平方注意力。
这些成果仅花费了Llama 3.1 8B单GPU上的几个训练小时(成本低于20美元)。
当然,我们必须承认这种方法仍需一个预训练的平方Transformer来执行这一层蒸馏,但像LoLCaTs这样的基于推理的优化将成为任何希望采用生成式AI的企业的重要组成部分,在获得优异性能的同时节省大量计算成本。
总结: LoLCaTs技术可以让大型语言模型(LLM)的训练成本大大降低。利用这个技术,80 亿参数的模型训练成本只需要不到 20 美元,同时还保持了原本的高性能。和传统的 Transformer 方法相比,LoLCaTs 大幅提升了效率,让模型训练变得又快又省钱。这一突破让更多企业可以低成本获得强大的 AI 能力,为 AI 的普及铺平了道路。