前言
随着越来越多的应用逐渐微服务化后,分布式服务之间的RPC调用使得异常排查的难度骤增,最明显的一个问题,就是整个调用链路的日志不在一台机器上,往往定位问题就要花费大量时间。如何在一个分布式网络中把单次请求的整个调用日志给串起来,变得刻不容缓。
笔者基于 Dubbo 框架的 Filter 扩展点实现了一个分布式日志跟踪工具 dubbo-tracing,源码地址:https://github.com/panchanghe/dubbo-tracing
实现思路
Dubbo 作为国内最热门的 RPC 框架之一,对外提供了丰富的功能扩展点,日志跟踪就需要用到其中org.apache.dubbo.rpc.Filter扩展点。
Filter 扩展点可以在 Consumer 发起 RPC 调用前和 Provider 处理请求前发起拦截,执行我们特定的业务逻辑来对 Dubbo 做增强。另外,Dubbo RPC 调用除了方法入参,还额外提供了 Map 类型的 attachments 来隐式的传递参数。
有了这些前提,要实现分布式日志跟踪就简单了。通过实现 Filter 扩展点拦截 RPC 调用,最早的 Consumer 端生成一个唯一的 TraceId 进行透传,TraceId 在整个调用链路里保持一致,TraceId 会被写到日志上下文 MDC 中,最终和业务日志一起打印到日志文件里,这样通过 TraceId 检索就能获取整个调用链路的所有日志。一个完整的 RPC 调用链路是一个树状结构,最早发起调用的节点是根节点,一直向下延伸,为了把整个链路的日志构造成树状结构展示,我们还需要一个 SpanId,它代表了当前日志在整个调用链路中的层级。有了这些日志数据,再搭配日志检索服务 + 图形化展示,分布式问题的排查就会简单很多。
TraceId和SpanId生成规则
这里借鉴一下阿里的做法。
TraceId一般由接受请求的第一个服务器产生,具有唯一性,且在整个调用链路中保持不变。
TraceId的生成规则是:服务器IP + 时间戳 + 自增序列 + 进程号,比如:
java
c0a861711731309291125100068524前8位c0a86171是生成TraceId的服务器IP,它被编码为十六进制,每2位代表IP地址中的一段,转换成十进制结果就是192.168.97.113,可以根据该号段快速定位到生成TraceId的服务器。
后面的13位1731309291125是生成TraceId的毫秒级时间戳;之后的4位1000是一个自增的序列,从 1000 开始,涨到 9999 后又会回到 1000;最后的部分68524是当前进程的ID,主要是为了防止单机多进程间产生的TraceId发生冲突。
SpanId 代表本次调用在整个调用链路树中的位置。
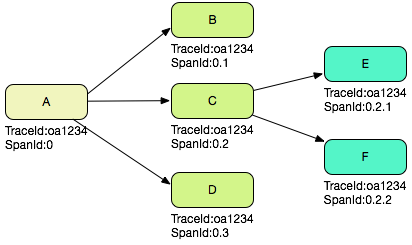
假设一个 Web 系统 A 接收了一次用户请求,那么在这个系统的 MVC 日志中,记录下的 SpanId 是 0,代表是整个调用的根节点,如果 A 系统处理这次请求,需要通过 RPC 依次调用 B、C、D 三个系统,那么在 A 系统的 RPC 客户端日志中,SpanId 分别是 0.1,0.2 和 0.3,在 B、C、D 三个系统的 RPC 服务端日志中,SpanId 也分别是 0.1,0.2 和 0.3;如果 C 系统在处理请求的时候又调用了 E,F 两个系统,那么 C 系统中对应的 RPC 客户端日志是 0.2.1 和 0.2.2,E、F 两个系统对应的 RPC 服务端日志也是 0.2.1 和 0.2.2。
根据上面的描述可以知道,如果把一次调用中所有的 SpanId 收集起来,可以组成一棵完整的链路树。
假设一次分布式调用中产生的 TraceId 是 0a1234(实际不会这么短),那么根据上文 SpanId 的产生过程,如下图所示:
具体实现
1、首先是实现一个根据 机器IP、时间戳、自增序列、进程ID 生成 TraceId 的方案:
java
public class IdUtils {
private static final String PROCESS_ID;
private static final String IP_HEX_CODE;
private static final AtomicInteger COUNTER;
private static final int COUNT_INIT_VALUE = 1000;
private static final int COUNT_MAX_VALUE = 9999;
private static long lastTimestamp = 0L;
static {
PROCESS_ID = ProcessIdUtil.getProcessId();
IP_HEX_CODE = getIpHexCode();
COUNTER = new AtomicInteger(COUNT_INIT_VALUE);
}
/**
* 8位 13位 4位
* 服务器 IP + ID 产生的时间 + 自增序列 + 当前进程号
*
* @return
*/
public static synchronized String newTraceId() {
final long timestamp = System.currentTimeMillis();
long count;
if (timestamp > lastTimestamp) {
COUNTER.set(COUNT_INIT_VALUE);
count = COUNT_INIT_VALUE;
lastTimestamp = timestamp;
} else {
count = COUNTER.incrementAndGet();
if (count == COUNT_MAX_VALUE) {
COUNTER.set(COUNT_INIT_VALUE - 1);
}
}
return IP_HEX_CODE + timestamp + count + PROCESS_ID;
}
private static String getIpHexCode() {
final StringBuilder builder = new StringBuilder();
String host = NetUtils.getLocalHost();
String[] split = host.split("\\.");
for (String s : split) {
String hex = Integer.toHexString(Integer.valueOf(s));
if (hex.length() == 1) {
hex = "0" + hex;
}
builder.append(hex);
}
return builder.toString();
}
}2、为了方便本地透传 TraceId 等信息,必然要用到 ThreadLocal 来记录,所以我们创建一个 TraceContext 类来读写当前线程的 Trace 信息。
java
public class TraceContext {
private static final ThreadLocal<Map<String, Object>> TRACE_THREAD_LOCAL = new ThreadLocal() {
@Override
protected Object initialValue() {
return new HashMap<>();
}
};
public static boolean isStarted() {
return !get().isEmpty();
}
public static void start(String traceId) {
start(traceId, "0");
}
public static void start(String traceId, String spanId) {
get().put(TracingConstant.TRACE_ID, traceId);
get().put(TracingConstant.SPAN_ID, spanId);
get().put(TracingConstant.LOGIC_ID, new AtomicInteger(0));
}
public static String getTraceId() {
return (String) get().get(TracingConstant.TRACE_ID);
}
public static String getSpanId() {
String s = (String) get().get(TracingConstant.SPAN_ID);
return s;
}
public static int nextLogicId() {
return ((AtomicInteger) get().get(TracingConstant.LOGIC_ID)).incrementAndGet();
}
private static Map<String, Object> get() {
return TRACE_THREAD_LOCAL.get();
}
public static void clear() {
TRACE_THREAD_LOCAL.remove();
}
}3、Consumer 端的 Filter 扩展,判断当前线程是否已经生成 TraceId,如果没有则生成新的 TraceId 和 SpanId 写入到 ThreadLocal 同时通过 attachments 透传到 Provider。
java
@Activate(group = {"consumer"})
public class ConsumerTraceFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
if (!TraceContext.isStarted()) {
TraceContext.start(getTraceId());
}
ThreadContext.put(TracingConstant.TRACE_ID, TraceContext.getTraceId());
ThreadContext.put(TracingConstant.SPAN_ID, TraceContext.getSpanId());
invocation.setAttachment(TracingConstant.DUBBO_TRACE_ID, TraceContext.getTraceId());
invocation.setAttachment(TracingConstant.DUBBO_SPAN_ID, TraceContext.getSpanId() + "." + TraceContext.nextLogicId());
return invoker.invoke(invocation);
}
private String getTraceId() {
String traceId = ThreadContext.get(TracingConstant.TRACE_ID);
if (StringUtils.isEmpty(traceId)) {
traceId = IdUtils.newTraceId();
}
return traceId;
}
}4、Provider 端的 Filter 扩展,读取 attachments 透传过来的 TraceId 和 SpanId,如果能读到,就将它们写入本地 ThreadLocal 里,开启 TraceContext,后续如果自己再发起下游的 RPC 调用,则会以它们为基础数据,发给下游节点,整个链路就能串起来了。
java
@Activate(group = {"provider"})
public class ProviderTraceFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
final String traceId = RpcContext.getServerAttachment().getAttachment(TracingConstant.DUBBO_TRACE_ID);
final String spanId = RpcContext.getServerAttachment().getAttachment(TracingConstant.DUBBO_SPAN_ID);
if (StringUtils.isAnyEmpty(traceId, spanId)) {
return invoker.invoke(invocation);
}
TraceContext.start(traceId, spanId);
ThreadContext.put(TracingConstant.TRACE_ID, TraceContext.getTraceId());
ThreadContext.put(TracingConstant.SPAN_ID, TraceContext.getSpanId());
try {
return invoker.invoke(invocation);
} catch (Throwable e) {
throw e;
} finally {
TraceContext.clear();
ThreadContext.remove(TracingConstant.TRACE_ID);
ThreadContext.remove(TracingConstant.SPAN_ID);
}
}
}5、为了让我们自定义的 Filter 能被 Dubbo 加载并执行,还需要在 META-INF/dubbo/org.apache.dubbo.rpc.Filter文件里配置一下:
java
ProviderTraceFilter=top.javap.dubbo.tracing.ProviderTraceFilter
ConsumerTraceFilter=top.javap.dubbo.tracing.ConsumerTraceFilter