
上一篇:《"嵌入"在大语言模型中是解决把句子转换成向量表示的技术》
**序言:**我们常常会说某某人只会"读死书",题目稍微变一点就不会做了。这其实是我们人类学习中很常见的现象。可是你知道吗?人工智能其实更容易"读死书"。不过在人工智能领域,我们有个听起来高大上的说法,叫"过拟合"。说白了,"过拟合"就是人工智能的"读死书"现象。在这个小节我们就来聊聊怎么让人工智能少"读死书"。注意,我说的是"少",因为这个问题没办法完全消除,只能尽量降低。
减少语言模型中的过拟合
过拟合发生在网络对训练数据变得过于专注时,其中一个表现是它在训练集中"噪声"数据中的模式匹配上变得非常出色,而这些噪声在其他地方并不存在。由于这种特定的噪声在验证集中并不存在,网络越擅长匹配这些噪声,验证集上的损失就会越差。这就会导致你在图 6-3 中看到的验证损失不断上升的情况。在本节中,我们将探讨几种通用化模型并减少过拟合的方法。
调整学习率
导致过拟合的最大因素之一可能是优化器的学习率过高。这意味着网络学习得太快了。以下是用于编译模型的代码示例:
model.compile(loss='binary_crossentropy',
optimizer='adam', metrics='accuracy')
这里的优化器简单地声明为 adam,这会调用带有默认参数的 Adam 优化器。然而,这个优化器支持多个参数,包括学习率。可以将代码更改为以下内容:
adam = tf.keras.optimizers.Adam(learning_rate=0.0001,
beta_1=0.9, beta_2=0.999, amsgrad=False)
model.compile(loss='binary_crossentropy',
optimizer=adam, metrics='accuracy')
在这里,默认学习率值(通常为 0.001)被降低了 90%,变为 0.0001。beta_1 和 beta_2 的值保持默认值,amsgrad 也保持默认值。
• beta_1 和 beta_2 必须在 0 和 1 之间,通常两者都接近 1。
• Amsgrad 是 Adam 优化器的一种替代实现,首次在 Sashank Reddi、Satyen Kale 和 Sanjiv Kumar 的论文《On the Convergence of Adam and Beyond》中提出。
这个更低的学习率对网络产生了深远的影响。图 6-4 显示了网络在 100 个训练周期中的准确率。可以看到,在前 10 个周期左右,较低的学习率使得网络看起来像是"没有在学习",但随后它"突破"了,并开始快速学习。
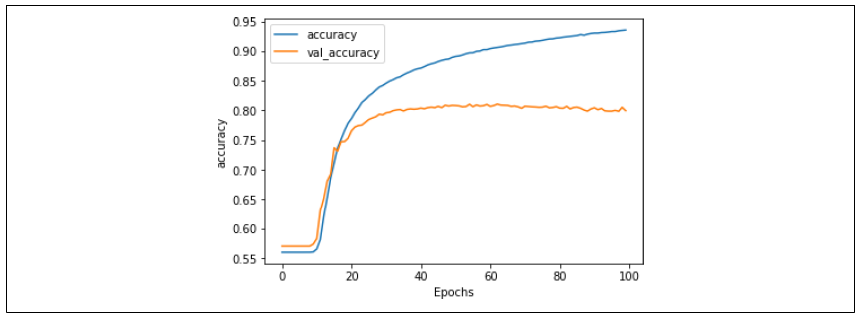
图 6-4:使用较低学习率时的准确率通过观察损失(如图 6-5 所示),我们可以看到,即使在前几个训练周期内准确率没有上升,损失却在下降。所以如果你逐周期观察训练过程,可以有信心相信网络最终会开始学习。
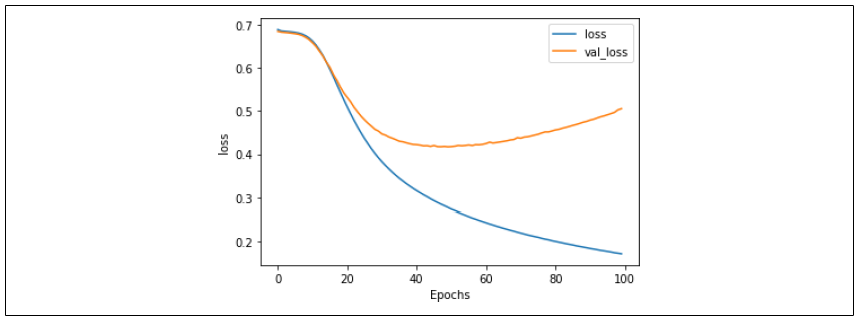
图 6-5:使用较低学习率时的损失虽然损失开始呈现出与图 6-3 中类似的过拟合曲线,但请注意,这种现象发生得更晚,且程度也低得多。在第 30 个训练周期时,损失大约为 0.45,而在图 6-3 中使用较高学习率时,这一数值超过了两倍。尽管网络需要更长时间才能达到较高的准确率,但在损失更小的情况下完成,因此你可以对结果更有信心。
使用这些超参数时,验证集上的损失在大约第 60 个训练周期开始增加,此时训练集的准确率达到约 90%,而验证集的准确率约为 81%,这表明我们的网络是相当有效的。
当然,仅仅调整优化器参数然后宣称成功是比较简单的,但其实还有许多其他方法可以用来改进你的模型,这些方法会在接下来的几节中介绍。在这些部分中,我会恢复使用默认的 Adam 优化器来进行说明。因此,调整学习率的效果不会掩盖其他技术所带来的好处。
**总结:**本节我们介绍了如何通过调整学习速率来缓解语言模型"读死书"的现象。接下来的几节内容将更深入地带大家探索和分析训练数据集的特性,以及模型的架构设计、预设维度等因素是如何影响模型"读死书"问题的。