Transformer架构详解:从注意力机制到完整模型构建
一、注意力机制:Transformer的核心
1.1 为什么需要注意力机制?
在Transformer出现之前,循环神经网络(RNN)及其变体LSTM是处理自然语言序列的主流模型。但RNN存在两个明显缺陷:
- 并行计算受限:RNN按序列顺序处理数据,无法充分利用GPU的并行计算能力
- 长距离依赖捕捉困难:随着序列长度增加,早期信息会逐渐衰减
注意力机制(Attention)的出现解决了这些问题,它允许模型直接关注序列中重要的部分,实现并行计算的同时更好地捕捉长距离依赖关系。
1.2 注意力机制的核心概念
注意力机制基于三个核心向量:
- Query(查询):当前需要关注的目标
- Key(键):用于匹配查询的索引
- Value(值):与键关联的实际内容
可以用查字典的例子理解:当你想查"水果"(Query)时,字典中的"苹果"、"香蕉"(Key)会被匹配,它们对应的值(Value)会被加权组合作为结果。
1.3 注意力计算的数学原理
注意力机制的计算公式如下:
Attention(Q,K,V)=softmax(QKTdk)V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V
计算步骤分解:
- 计算相似度:通过Query与Key的点积计算相关性
- 缩放处理 :除以dk\sqrt{d_k}dk (Key的维度),避免softmax梯度不稳定
- 归一化:使用softmax将相似度转化为注意力权重(和为1)
- 加权求和:用注意力权重对Value进行加权求和,得到最终结果
1.4 注意力机制的PyTorch实现
python
import torch
import math
def attention(query, key, value, dropout=None):
"""注意力计算函数"""
d_k = query.size(-1) # 获取键向量的维度
# 计算Q与K的内积并除以根号dk
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 计算注意力权重
p_attn = scores.softmax(dim=-1)
# 应用dropout(可选)
if dropout is not None:
p_attn = dropout(p_attn)
# 根据权重对value进行加权求和
return torch.matmul(p_attn, value), p_attn1.5 自注意力机制
自注意力(Self-Attention)是注意力机制的特殊形式,其Q、K、V来自同一输入序列:
python
# 自注意力就是将同一输入作为Q、K、V
attention(x, x, x)自注意力能捕捉序列内部每个元素与其他元素的关系,例如在句子"猫追狗,它跑得很快"中,模型能通过自注意力知道"它"指的是"猫"还是"狗"。
1.6 掩码自注意力
在生成任务中,为了防止模型"偷看"未来信息,需要使用掩码自注意力(Masked Self-Attention):
python
# 创建上三角掩码矩阵,遮蔽未来信息
mask = torch.full((1, seq_len, seq_len), float("-inf"))
mask = torch.triu(mask, diagonal=1) # 上三角部分为-inf
# 在注意力计算中应用掩码
scores = scores + mask # 未来位置的分数变为-inf
scores = F.softmax(scores, dim=-1) # -inf经过softmax后变为0掩码确保模型在预测第i个词时,只能看到前i-1个词的信息。
1.7 多头注意力
单一注意力头只能捕捉一种关系,多头注意力(Multi-Head Attention)通过多个并行的注意力头捕捉不同类型的关系:
MultiHead(Q,K,V)=Concat(head1,...,headh)WO \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中每个注意力头计算为:
headi=Attention(QWiQ,KWiK,VWiV) \text{head}_i = \text{Attention}(QW^Q_i, KW^K_i, VW^V_i) headi=Attention(QWiQ,KWiK,VWiV)
多头注意力的实现:
python
class MultiHeadAttention(nn.Module):
def __init__(self, args, is_causal=False):
super().__init__()
assert args.dim % args.n_heads == 0 # 确保维度可被头数整除
self.head_dim = args.dim // args.n_heads
self.n_heads = args.n_heads
# 定义Q、K、V的线性变换矩阵
self.wq = nn.Linear(args.n_embd, self.n_heads * self.head_dim, bias=False)
self.wk = nn.Linear(args.n_embd, self.n_heads * self.head_dim, bias=False)
self.wv = nn.Linear(args.n_embd, self.n_heads * self.head_dim, bias=False)
self.wo = nn.Linear(self.n_heads * self.head_dim, args.dim, bias=False)
self.attn_dropout = nn.Dropout(args.dropout)
self.resid_dropout = nn.Dropout(args.dropout)
self.is_causal = is_causal
# 因果掩码(用于解码器)
if is_causal:
mask = torch.full((1, 1, args.max_seq_len, args.max_seq_len), float("-inf"))
mask = torch.triu(mask, diagonal=1)
self.register_buffer("mask", mask)
def forward(self, q, k, v):
bsz, seqlen, _ = q.shape
# 线性变换并拆分多头
xq, xk, xv = self.wq(q), self.wk(k), self.wv(v)
xq = xq.view(bsz, seqlen, self.n_heads, self.head_dim).transpose(1, 2)
xk = xk.view(bsz, seqlen, self.n_heads, self.head_dim).transpose(1, 2)
xv = xv.view(bsz, seqlen, self.n_heads, self.head_dim).transpose(1, 2)
# 计算注意力分数
scores = torch.matmul(xq, xk.transpose(2, 3)) / math.sqrt(self.head_dim)
# 应用掩码(如果需要)
if self.is_causal:
scores = scores + self.mask[:, :, :seqlen, :seqlen]
# 计算注意力权重并应用dropout
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
scores = self.attn_dropout(scores)
# 加权求和并合并多头
output = torch.matmul(scores, xv)
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
# 最终投影
output = self.wo(output)
output = self.resid_dropout(output)
return output二、Transformer的Encoder-Decoder结构
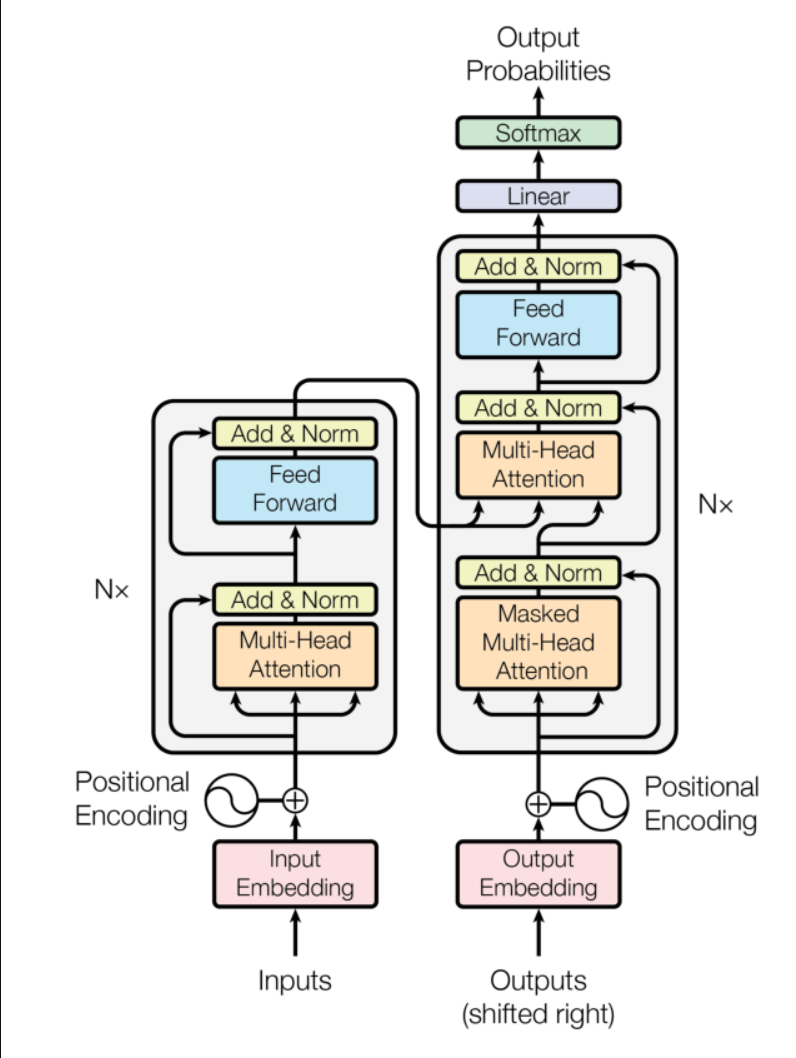
2.1 Seq2Seq任务与Transformer
Transformer是为序列到序列(Seq2Seq)任务设计的模型,输入一个序列,输出另一个可能长度不同的序列。典型应用包括:
- 机器翻译(如中文→英文)
- 文本摘要(长文本→短摘要)
- 问答系统(问题→答案)
Transformer采用Encoder-Decoder架构:
- 编码器(Encoder):将输入序列编码为语义向量
- 解码器(Decoder):将语义向量解码为输出序列
2.2 关键组件
前馈神经网络(FFN)
每个Encoder/Decoder层都包含一个前馈神经网络:
python
class MLP(nn.Module):
"""前馈神经网络"""
def __init__(self, dim: int, hidden_dim: int, dropout: float):
super().__init__()
self.w1 = nn.Linear(dim, hidden_dim, bias=False) # 第一层线性变换
self.w2 = nn.Linear(hidden_dim, dim, bias=False) # 第二层线性变换
self.dropout = nn.Dropout(dropout) # Dropout防止过拟合
def forward(self, x):
# 线性变换→激活函数→线性变换→dropout
return self.dropout(self.w2(F.relu(self.w1(x))))层归一化(Layer Normalization)
层归一化用于稳定训练,将每一层的输入标准化:
python
class LayerNorm(nn.Module):
"""层归一化"""
def __init__(self, features, eps=1e-6):
super().__init__()
self.a_2 = nn.Parameter(torch.ones(features)) # 缩放参数
self.b_2 = nn.Parameter(torch.zeros(features)) # 偏移参数
self.eps = eps # 防止除零
def forward(self, x):
mean = x.mean(-1, keepdim=True) # 计算均值
std = x.std(-1, keepdim=True) # 计算标准差
# 归一化并应用缩放和偏移
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2残差连接(Residual Connection)
残差连接解决深层网络训练困难的问题,将输入直接传到输出:
python
# 残差连接公式:输出 = 输入 + 子层输出
h = x + self.attention.forward(self.attention_norm(x))2.3 编码器(Encoder)
编码器由N个相同的Encoder Layer堆叠而成,每个Layer包含:
- 多头自注意力层(无掩码)
- 前馈神经网络
python
class EncoderLayer(nn.Module):
"""编码器层"""
def __init__(self, args):
super().__init__()
self.attention_norm = LayerNorm(args.n_embd) # 注意力前的归一化
self.attention = MultiHeadAttention(args, is_causal=False) # 多头自注意力
self.fnn_norm = LayerNorm(args.n_embd) # FFN前的归一化
self.feed_forward = MLP(args.dim, args.dim, args.dropout) # 前馈网络
def forward(self, x):
# 自注意力 + 残差连接
norm_x = self.attention_norm(x)
h = x + self.attention.forward(norm_x, norm_x, norm_x)
# FFN + 残差连接
out = h + self.feed_forward.forward(self.fnn_norm(h))
return out
class Encoder(nn.Module):
"""编码器"""
def __init__(self, args):
super().__init__()
# 堆叠N个编码器层
self.layers = nn.ModuleList([EncoderLayer(args) for _ in range(args.n_layer)])
self.norm = LayerNorm(args.n_embd) # 最终归一化
def forward(self, x):
for layer in self.layers:
x = layer(x)
return self.norm(x)2.4 解码器(Decoder)
解码器也由N个相同的Decoder Layer堆叠而成,每个Layer包含:
- 掩码多头自注意力层(防止偷看未来信息)
- 多头注意力层(使用编码器输出作为K和V)
- 前馈神经网络
python
class DecoderLayer(nn.Module):
"""解码器层"""
def __init__(self, args):
super().__init__()
self.attention_norm_1 = LayerNorm(args.n_embd) # 掩码注意力前的归一化
self.mask_attention = MultiHeadAttention(args, is_causal=True) # 掩码自注意力
self.attention_norm_2 = LayerNorm(args.n_embd) # 注意力前的归一化
self.attention = MultiHeadAttention(args, is_causal=False) # 多头注意力
self.ffn_norm = LayerNorm(args.n_embd) # FFN前的归一化
self.feed_forward = MLP(args.dim, args.dim, args.dropout) # 前馈网络
def forward(self, x, enc_out):
# 掩码自注意力 + 残差连接
norm_x = self.attention_norm_1(x)
x = x + self.mask_attention.forward(norm_x, norm_x, norm_x)
# 注意力(结合编码器输出) + 残差连接
norm_x = self.attention_norm_2(x)
h = x + self.attention.forward(norm_x, enc_out, enc_out)
# FFN + 残差连接
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
class Decoder(nn.Module):
"""解码器"""
def __init__(self, args):
super().__init__()
# 堆叠N个解码器层
self.layers = nn.ModuleList([DecoderLayer(args) for _ in range(args.n_layer)])
self.norm = LayerNorm(args.n_embd) # 最终归一化
def forward(self, x, enc_out):
for layer in self.layers:
x = layer(x, enc_out)
return self.norm(x)三、完整Transformer模型构建
3.1 嵌入层(Embedding)
将文本token转换为向量表示:
python
class Embedding(nn.Module):
"""嵌入层"""
def __init__(self, vocab_size, embed_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
def forward(self, x):
# x形状: [batch_size, seq_len]
# 返回: [batch_size, seq_len, embed_dim]
return self.embedding(x)3.2 位置编码(Positional Encoding)
由于Transformer没有循环结构,需要显式加入位置信息:
python
class PositionalEncoding(nn.Module):
"""位置编码"""
def __init__(self, d_model, max_len=5000):
super().__init__()
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(max_len, 1, d_model)
pe[:, 0, 0::2] = torch.sin(position * div_term)
pe[:, 0, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x):
# x形状: [seq_len, batch_size, d_model]
x = x + self.pe[:x.size(0)]
return x3.3 完整Transformer模型
python
class Transformer(nn.Module):
"""完整Transformer模型"""
def __init__(self, args, src_vocab_size, tgt_vocab_size):
super().__init__()
self.encoder_embedding = Embedding(src_vocab_size, args.dim)
self.decoder_embedding = Embedding(tgt_vocab_size, args.dim)
self.positional_encoding = PositionalEncoding(args.dim)
self.encoder = Encoder(args)
self.decoder = Decoder(args)
self.fc = nn.Linear(args.dim, tgt_vocab_size)
def forward(self, src, tgt):
# 编码器部分
enc_embed = self.encoder_embedding(src)
enc_embed = self.positional_encoding(enc_embed)
enc_out = self.encoder(enc_embed)
# 解码器部分
dec_embed = self.decoder_embedding(tgt)
dec_embed = self.positional_encoding(dec_embed)
dec_out = self.decoder(dec_embed, enc_out)
# 输出层
output = self.fc(dec_out)
return output四、总结
Transformer通过注意力机制彻底改变了自然语言处理领域,其核心优势包括:
- 并行计算能力:相比RNN可以更高效地利用GPU
- 长距离依赖捕捉:能直接建模序列中任意位置的依赖关系
- 灵活的架构:可根据任务需求调整(如仅用Encoder的BERT,仅用Decoder的GPT)
理解Transformer的工作原理是掌握现代大语言模型的基础,其注意力机制、Encoder-Decoder结构以及各种组件的设计思想,对理解和应用任何基于Transformer的模型都至关重要。