gin源码阅读(1)URL中的参数是如何解析的?
向gin服务器请求时,URL请求参数有两种形式:(1)在路径中的参数,比如"/user/2/send"中的"2"就是用户编号;(2)查询参数,比如"/user/list?page=1&pageSize=5"中的"page"和"pageSize"就是查询参数。
下面分别对这种URL参数进行解读,看看gin中是如何解析这两种参数的。
一、gin是如何解析URL中路径参数的?
先看一个官方给出的例子:
go
func main() {
router := gin.Default()
// 此 handler 将匹配 /user/john 但不会匹配 /user/ 或者 /user
router.GET("/user/:name", func(c *gin.Context) {
name := c.Param("name")
c.String(http.StatusOK, "Hello %s", name)
})
// 此 handler 将匹配 /user/john/ 和 /user/john/send
// 如果没有其他路由匹配 /user/john,它将重定向到 /user/john/
router.GET("/user/:name/*action", func(c *gin.Context) {
name := c.Param("name") // ref-1
action := c.Param("action")
message := name + " is " + action
c.String(http.StatusOK, message)
})
router.Run(":8080")
}在ref-1处使用了Param(...)函数获取路径中"name"参数的值,我们详细看一下该函数的细节:
go
// Param returns the value of the URL param.
// It is a shortcut for c.Params.ByName(key)
//
// router.GET("/user/:id", func(c *gin.Context) {
// // a GET request to /user/john
// id := c.Param("id") // id == "john"
// // a GET request to /user/john/
// id := c.Param("id") // id == "/john/"
// })
func (c *Context) Param(key string) string {
return c.Params.ByName(key)
}注释中写的很明确,Param(...)函数就是c.Params.ByName(key)的一个简写,我们继续看c.Params.ByName(key)细节:
go
// ByName returns the value of the first Param which key matches the given name.
// If no matching Param is found, an empty string is returned.
func (ps Params) ByName(name string) (va string) {
va, _ = ps.Get(name)
return
}ByName(...)函数就是在从Params中获取键值对数据,我们来看看Params结构体的定义:
go
// Param is a single URL parameter, consisting of a key and a value.
type Param struct {
Key string
Value string
}
// Params is a Param-slice, as returned by the router.
// The slice is ordered, the first URL parameter is also the first slice value.
// It is therefore safe to read values by the index.
type Params []Param现在有一个问题,这个Params是在哪儿赋值的呢?为了回答这个问题,我们先来看看gin是如何处理http请求的。
先看一下router.Run(":8080")函数的调用,如下所示:
go
func (engine *Engine) Run(addr ...string) (err error) {
...... // 省略其他代码
address := resolveAddress(addr)
debugPrint("Listening and serving HTTP on %s\n", address)
err = http.ListenAndServe(address, engine.Handler()) // ref-2
return
}可以看到其实Run方法调用了go自带库中的http.ListenAndServe(...)方法,并且注册了处理器engine.Handler(),这就很明了,http请求就是被注册的handler处理的,我们详细来看一下:
go
func (engine *Engine) Handler() http.Handler {
if !engine.UseH2C {
return engine
}
h2s := &http2.Server{}
return h2c.NewHandler(engine, h2s)
}这里面的h2c不是本次要关注的内容,这儿实际返回的是engine,那么engine就应该实现了下面的接口:
go
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}我们可以就接着看engine中ServeHTTP(...)方法的实现,如下所示:
go
// ServeHTTP conforms to the http.Handler interface.
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
c := engine.pool.Get().(*Context)
c.writermem.reset(w)
c.Request = req
c.reset()
engine.handleHTTPRequest(c) // ref-3
engine.pool.Put(c)
}实际处理请求的就是ref-3处的代码,我们继续往下看,该函数的实现如下所示:
go
func (engine *Engine) handleHTTPRequest(c *Context) {
httpMethod := c.Request.Method
rPath := c.Request.URL.Path
unescape := false
if engine.UseRawPath && len(c.Request.URL.RawPath) > 0 {
rPath = c.Request.URL.RawPath
unescape = engine.UnescapePathValues
}
if engine.RemoveExtraSlash {
rPath = cleanPath(rPath)
}
// Find root of the tree for the given HTTP method
t := engine.trees
for i, tl := 0, len(t); i < tl; i++ { // 先找到匹配树中对应的根节点。
if t[i].method != httpMethod {
continue
}
root := t[i].root
// Find route in tree
value := root.getValue(rPath, c.params, c.skippedNodes, unescape) // ref-4
if value.params != nil {
c.Params = *value.params // ref-5
}
if value.handlers != nil {
c.handlers = value.handlers
c.fullPath = value.fullPath
c.Next()
c.writermem.WriteHeaderNow()
return
}
if httpMethod != http.MethodConnect && rPath != "/" {
if value.tsr && engine.RedirectTrailingSlash {
redirectTrailingSlash(c)
return
}
if engine.RedirectFixedPath && redirectFixedPath(c, root, engine.RedirectFixedPath) {
return
}
}
break
}
...... // 省略其他代码
}gin实际上会将注册的路由组成一个trie树结构,在网上找了一个gin为路由构建的树示意图,如下所示:
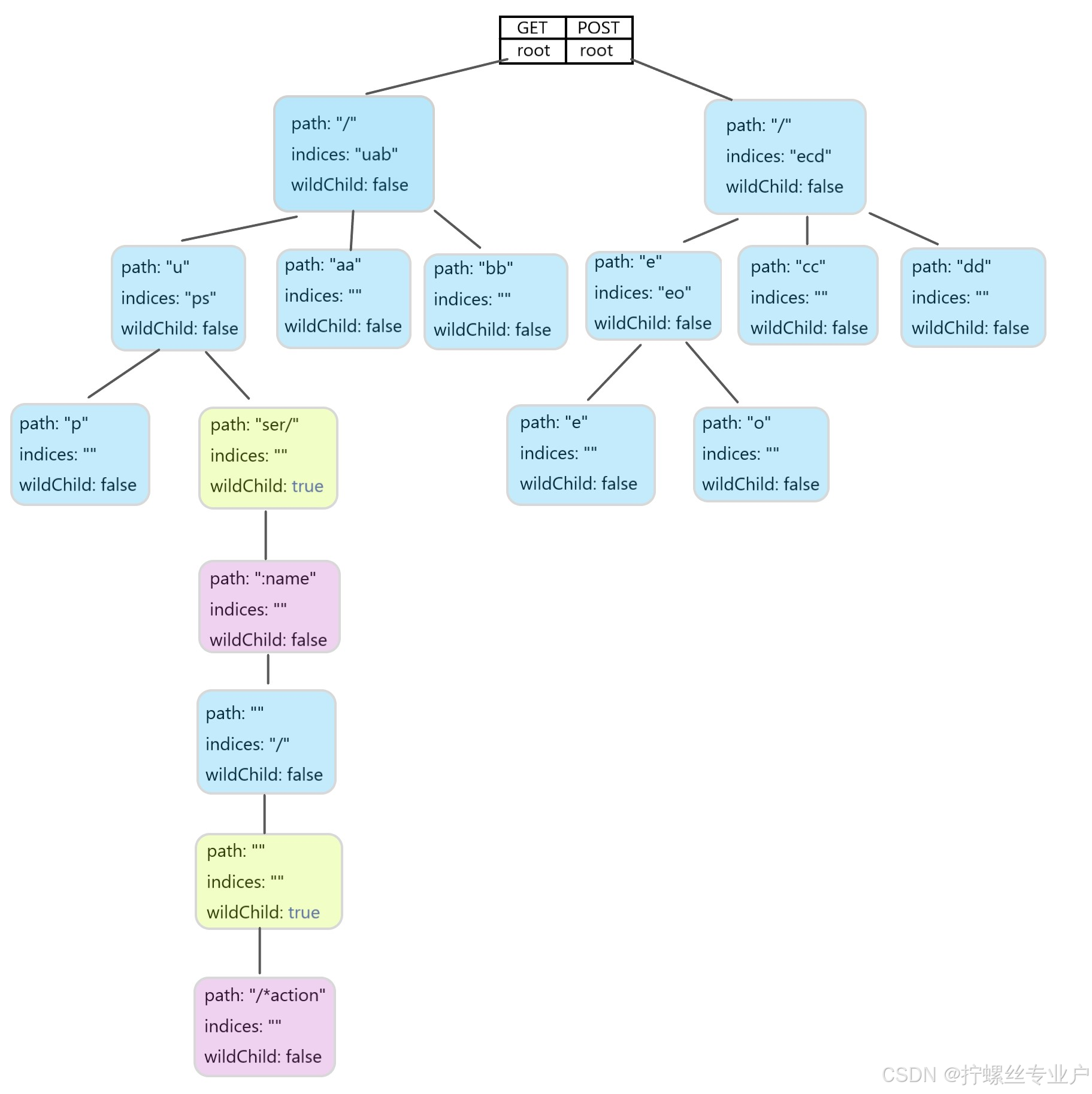
关于字符串搜索树trie可以看轻松搞懂Trie树,这篇文章中有详细的解释。
我们继续回到到代码中,上面的代码会首先找到http请求方法对应的树根(root),然后在root下面的树中找到对应的节点(value),并且在ref-5处将节点的params值赋值给域对象中的Params。我们把关注点集中在ref-4中,接着往下看:
go
// Returns the handle registered with the given path (key). The values of
// wildcards are saved to a map.
// If no handle can be found, a TSR (trailing slash redirect) recommendation is
// made if a handle exists with an extra (without the) trailing slash for the
// given path.
func (n *node) getValue(path string, params *Params, skippedNodes *[]skippedNode, unescape bool) (value nodeValue) {
var globalParamsCount int16
walk: // Outer loop for walking the tree
for {
prefix := n.path
if len(path) > len(prefix) {
if path[:len(prefix)] == prefix {
path = path[len(prefix):]
// Try all the non-wildcard children first by matching the indices
idxc := path[0]
for i, c := range []byte(n.indices) {
if c == idxc {
// strings.HasPrefix(n.children[len(n.children)-1].path, ":") == n.wildChild
if n.wildChild {
...... // 省略其他的代码
}
n = n.children[i]
continue walk
}
}
if !n.wildChild {
...... // 省略其他代码
}
// Handle wildcard child, which is always at the end of the array
n = n.children[len(n.children)-1]
globalParamsCount++
switch n.nType {
case param: // 处理url路径中的占位符参数
// fix truncate the parameter
// tree_test.go line: 204
// Find param end (either '/' or path end)
end := 0
for end < len(path) && path[end] != '/' {
end++
}
// Save param value
if params != nil && cap(*params) > 0 {
if value.params == nil {
value.params = params
}
// Expand slice within preallocated capacity
i := len(*value.params)
*value.params = (*value.params)[:i+1]
val := path[:end]
if unescape {
if v, err := url.QueryUnescape(val); err == nil {
val = v
}
}
// 将路径中的占位符参数的key和value组装到params中
(*value.params)[i] = Param{
Key: n.path[1:],
Value: val,
}
}
// we need to go deeper!
if end < len(path) {
if len(n.children) > 0 {
path = path[end:]
n = n.children[0]
continue walk
}
// ... but we can't
value.tsr = len(path) == end+1
return
}
if value.handlers = n.handlers; value.handlers != nil {
value.fullPath = n.fullPath
return
}
if len(n.children) == 1 {
// No handle found. Check if a handle for this path + a
// trailing slash exists for TSR recommendation
n = n.children[0]
value.tsr = (n.path == "/" && n.handlers != nil) || (n.path == "" && n.indices == "/")
}
return
case catchAll: // 处理URL路径中的通配符参数
...... // 省略其他的代码
default:
panic("invalid node type")
}
}
}
if path == prefix {
// If the current path does not equal '/' and the node does not have a registered handle and the most recently matched node has a child node
// the current node needs to roll back to last valid skippedNode
if n.handlers == nil && path != "/" {
for length := len(*skippedNodes); length > 0; length-- {
skippedNode := (*skippedNodes)[length-1]
*skippedNodes = (*skippedNodes)[:length-1]
if strings.HasSuffix(skippedNode.path, path) {
path = skippedNode.path
n = skippedNode.node
if value.params != nil {
*value.params = (*value.params)[:skippedNode.paramsCount]
}
globalParamsCount = skippedNode.paramsCount
continue walk
}
}
// n = latestNode.children[len(latestNode.children)-1]
}
// We should have reached the node containing the handle.
// Check if this node has a handle registered.
if value.handlers = n.handlers; value.handlers != nil {
value.fullPath = n.fullPath
return
}
// If there is no handle for this route, but this route has a
// wildcard child, there must be a handle for this path with an
// additional trailing slash
if path == "/" && n.wildChild && n.nType != root {
value.tsr = true
return
}
if path == "/" && n.nType == static {
value.tsr = true
return
}
// No handle found. Check if a handle for this path + a
// trailing slash exists for trailing slash recommendation
for i, c := range []byte(n.indices) {
if c == '/' {
n = n.children[i]
value.tsr = (len(n.path) == 1 && n.handlers != nil) ||
(n.nType == catchAll && n.children[0].handlers != nil)
return
}
}
return
}
// Nothing found. We can recommend to redirect to the same URL with an
// extra trailing slash if a leaf exists for that path
value.tsr = path == "/" ||
(len(prefix) == len(path)+1 && prefix[len(path)] == '/' &&
path == prefix[:len(prefix)-1] && n.handlers != nil)
// roll back to last valid skippedNode
if !value.tsr && path != "/" {
for length := len(*skippedNodes); length > 0; length-- {
skippedNode := (*skippedNodes)[length-1]
*skippedNodes = (*skippedNodes)[:length-1]
if strings.HasSuffix(skippedNode.path, path) {
path = skippedNode.path
n = skippedNode.node
if value.params != nil {
*value.params = (*value.params)[:skippedNode.paramsCount]
}
globalParamsCount = skippedNode.paramsCount
continue walk
}
}
}
return
}
}上面的代码大致分为三个步骤,(1)通过匹配路径找到对应的节点;(2)判断节点的类型;(3)如果节点类型是param,也就是路径参数,那么就会对实际http请求的路径进行解析,组装键值对,并且把组装好的键值对赋值给params中。这个就和前面从Param获取参数连起来了。
二、gin是如何解析URL查询参数的?
仍然是从官网给出的示例程序代码开始看起:
go
func main() {
router := gin.Default()
// 使用现有的基础请求对象解析查询字符串参数。
// 示例 URL: /welcome?firstname=Jane&lastname=Doe
router.GET("/welcome", func(c *gin.Context) {
firstname := c.DefaultQuery("firstname", "Guest")
// ref-6
lastname := c.Query("lastname") // c.Request.URL.Query().Get("lastname") 的一种快捷方式
c.String(http.StatusOK, "Hello %s %s", firstname, lastname)
})
router.Run(":8080")
}ref-6处代码调用了Query的代码,如下所示:
go
func (c *Context) Query(key string) (value string) {
value, _ = c.GetQuery(key)
return
}
func (c *Context) GetQuery(key string) (string, bool) {
if values, ok := c.GetQueryArray(key); ok {
return values[0], ok
}
return "", false
}
func (c *Context) GetQueryArray(key string) (values []string, ok bool) {
c.initQueryCache()
values, ok = c.queryCache[key] // 从这儿可以看到是从queryCache中获取的查询参数
return
}上述代码的关键就在于c.initQueryCache()了,我们接着往下看:
go
func (c *Context) initQueryCache() {
if c.queryCache == nil {
if c.Request != nil {
c.queryCache = c.Request.URL.Query() // ref-7
} else {
c.queryCache = url.Values{}
}
}
}ref-7的代码展示了queryCache的来源,细节如下所示:
go
func (u *URL) Query() Values {
v, _ := ParseQuery(u.RawQuery)
return v
}注意,从这儿开始已经进入到了go的net包下的url包了。我们继续看ParseQuery函数:
go
func ParseQuery(query string) (Values, error) {
m := make(Values)
err := parseQuery(m, query)
return m, err
}
func parseQuery(m Values, query string) (err error) {
for query != "" {
var key string
key, query, _ = strings.Cut(query, "&") // 把query用&符号切开
if strings.Contains(key, ";") {
err = fmt.Errorf("invalid semicolon separator in query")
continue
}
if key == "" {
continue
}
key, value, _ := strings.Cut(key, "=") // 把key用=切开
key, err1 := QueryUnescape(key)
if err1 != nil {
if err == nil {
err = err1
}
continue
}
value, err1 = QueryUnescape(value)
if err1 != nil {
if err == nil {
err = err1
}
continue
}
m[key] = append(m[key], value) // 组装key和value数据
}
return err
}其实上面这段代码比较的简单,使用本地断点调试就可以看出来运行过程了,主要是注释strings.Cut(...)函数的使用了。
三、总结
对于URL路径参数,gin会使用为路由构建的trie树来进行匹配,匹配到具体的节点后就会将实际http请求路径中的参数提取出来,并组装为key-value对,赋值给域对象的Params中。
对于URL查询参数,则是直接调用go自带库中的net包进行解析,具体解析过程就是使用strings.Cut(...)函数进行切割,最后组装好键值对放在缓存中。
参考资料: