当调用方调用服务提供方,由于网络抖动导致的请求失败,这个请求调用方希望执行成功。
调用方应该如何操作?catch异常再发起一次调用?显然不够优雅。这时可以考虑使用RPC框架的重试机制。
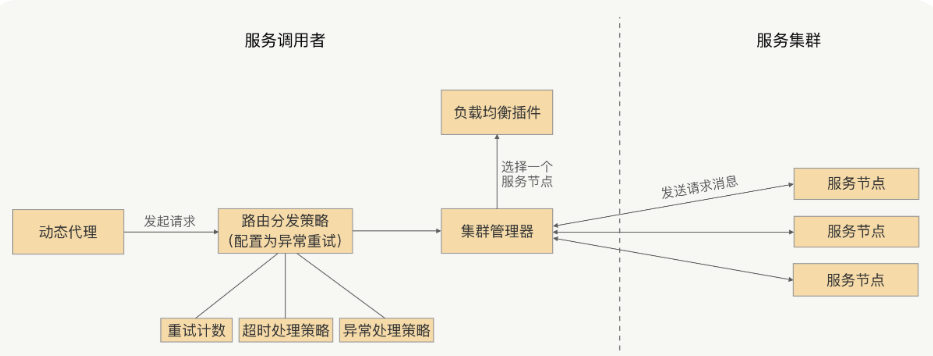
RPC框架的重试机制
RPC重试机制:当调用端发起的请求失败时,RPC框架自身可以进行重试,再重新发送请求,用户可以自行设置是否开启重试以及重试的次数。

RPC框架的重试机制就是调用端发现请求失败时捕获异常,之后触发重试,不是所有异常都触发重试,因为这个异常可能是服务提供方抛回来的业务异常,应该正常返回给动态代理。
在触发重试之前对捕获的异常进行判定,只有符合重试条件的异常才能触发重试,比如网络超时异常、网络连接异常等等。
在使用RPC框架的时候,确保被调用的服务的业务逻辑是幂等的,才能考虑根据事件情况开启RPC框架的异常重试功能。
如何在约定时间内安全可靠地重试?
连续的异常重试可能会出现一种不可靠的情况,那就是连续的异常重试并且每次处理的请求时间比较长,最终会导致请求处理的时间过长,超出用户设置的超时时间。
调用端的请求超时时间设置为5s,结果连续重试3次,每次都耗时2s,那最终这个请求的耗时是6s,那这样的话,调用端设置的超时时间就不准确了。
最直接的解决方式:在每次重试后都重置一下请求的超时时间。当调用端发起RPC请求时,如果发送请求发生异常并触发了异常重试,先判定下这个请求是否已经超时,如果已经超时了就直接返回超时异常,否则就先重置下这个请求的超时时间,之后再发起重试。
发起重试、负载均衡选择节点的时候,去掉重试之前出现过问题的那个节点,以保证重试的成功率。
有些服务端抛出的业务异常,调用端也可能发起重试。 可以加个重试异常白名单,用户可以将允许重试的异常加入到这个白名单中。
当调用端发起调用,并且配置了异常重试策略,RPC框架捕获到异常之后。如果这个异常是RPC框架允许重试的异常 ,或者这个异常类型存在于可重试异常的白名单中,就允许对这个请求进行重试。