我自己的原文哦~https://blog.51cto.com/whaosoft/11989373
#无图NOA
一场对高精地图的祛魅!2024在线高精地图方案的回顾与展望~
自VectorMapNet以来,无图/轻图的智能驾驶方案开始出现在自动驾驶量产的牌桌上,到如今也有两年多的时间。而『无图NOA』真正开始爆火的节点当属MapTR算法的提出,原来矢量化地图还能这么学习,以前分割的方案开始退出自动驾驶舞台,各家开始真正投入主力量产无图/轻图方案。
首先需要明确一点,无图方案不是完全摒弃高精地图,下游轨迹预测/规控仍然依赖高精地图的输入。『无图』实际指的是不再依赖厂商提供的高精地图,转而使用车载算法实时感知的『局部在线高精地图』。
因此无图方案的核心在于实时在线地图构建的准确性,从技术层面来讲,正常情况下无图的上限就是有图;而在传统高精地图更新不及时的区域(比如施工路段、道路重构路段等),无图方案是更有优势的。在线高精地图的发展也有两年多了,无图一直致力于从『能用』走向『好用』。今天自动驾驶之心就带大家盘点一下2024年在线高精地图的主流前沿算法,一探研究趋势,并在文末进行总结。
相关工作
Driving with Prior Maps: Unified Vector Prior Encoding for Autonomous Vehicle Mapping
论文链接:https://arxiv.org/abs/2409.05352v1
阿里巴巴和西交团队的工作:高精地图(HD地图)对于自动驾驶汽车的精确导航和决策至关重要,但其创建和维护带来了巨大的成本和及时性挑战。使用车载传感器在线构建高精地图已成为一种有前景的解决方案;然而,由于遮挡和恶劣天气,这些方法可能会受到不完整数据的阻碍。本文提出了PriorDrive框架,通过利用先验地图的力量来解决这些局限性,显著提高了在线高精地图构建的鲁棒性和准确性。我们的方法整合了各种先前的地图,如OpenStreetMap的标准定义地图(SD地图)、供应商过时的高精地图以及来自历史车辆数据的本地构建地图。为了将这些先验信息有效地编码到在线见图模型中,PriorDrive提出了一种混合先验表示(HPQuery),该表示对不同地图元素的表示进行了标准化。PriorDrive的核心是统一矢量编码器(UVE),它采用双编码机制来处理矢量数据。矢量内编码器捕获细粒度的局部特征,而矢量间编码器集成全局上下文。此外提出了一种segment-level和point-level的预训练策略,使UVE能够学习矢量数据的先验分布,从而提高编码器的泛化能力和性能。通过对nuScenes数据集的广泛测试,PriorDrive与各种在线地图模型高度兼容,并大大提高了地图预测能力。通过PriorDrive框架整合先前的地图,为单一感知数据的挑战提供了一个强大的解决方案,为更可靠的自动驾驶汽车导航铺平了道路。
Neural HD Map Generation from Multiple Vectorized Tiles Locally Produced by Autonomous Vehicles
高精地图厂商四维图新的工作:高精地图是自动驾驶系统的基本组成部分,因为它可以提供有关驾驶场景的精确环境信息。最近关于矢量化地图生成的工作,车辆运行一次只能在自车周围生成65%的局部地图元素,这就留下了一个难题,即如何在高质量标准下构建投影在世界坐标系中的全局高精地图。为了解决这个问题,我们将GNMap作为一个端到端的生成神经网络来自动构建具有多个矢量化图块的高精地图,这些图块是由自动驾驶汽车通过多次旅行在本地生成的。它利用多层和基于注意力的自动编码器作为共享网络,其中的参数是从两个不同的任务(即分别进行预训练和微调)中学习的,以确保生成的映射的完整性和元素类别的正确性。对真实世界的数据集进行了大量的定性评估,实验结果表明,GNMap可以超过SOTA方法5%以上的F1分数,只需少量手动修改即可达到工业使用水平。我们已经在有限公司Navinfo公司部署了它,作为自动构建自动驾驶系统高精地图的不可或缺的软件。
Enhancing Vectorized Map Perception with Historical Rasterized Maps(ECCV2024)
无图NOA以来,研究人员focus在端到端的在线矢量地图构建上,该技术在鸟瞰图(BEV)空间中实现,希望能够替代传统成本较高的离线高精(HD)地图。但是当前方法在恶劣环境下的准确性和鲁棒性很容易受限。为此本文提出了HRMapNet,其利用低成本的历史光栅化地图来增强在线矢量化地图的感知能力。历史光栅化地图来源于先前预测的结果,因此可以提供当前帧一定的先验信息。为了充分利用历史地图,作者设计了两个模块来增强BEV特征和地图元素的查询。对于BEV特征,本文设计了特征聚合模块,以编码图像和历史地图的特征。对于地图元素的查询,则设计了一个查询初始化模块,以赋予查询从历史地图中得到的先验信息。这两个模块对于在在线感知中利用地图信息至关重要。HRMapNet能够与大多数现有的在线矢量化地图感知方法集成。问鼎nuScenes和Argoverse 2 SOTA。
Online Temporal Fusion for Vectorized Map Construction in Mapless Autonomous Driving
为了减少对高精(HD)地图的依赖,自动驾驶的一个日益增长的趋势是利用车载传感器在线生成矢量化地图。然而目前的方法大多受到仅处理单帧输入的限制,这阻碍了它们在复杂场景中的鲁棒性和有效性。为了克服这个问题,我们提出了一种在线地图构建系统,该系统利用长期的时间信息来构建一致的矢量化地图。首先,该系统有效地将来自现成网络的所有历史道路标记检测融合到语义体素图中,该图使用基于哈希的策略来实现,以利用道路元素的稀疏性。然后通过检查融合信息找到可靠的体素,并逐步聚类到道路标记的实例级表示中。最后,该系统结合领域知识来估计道路的几何和拓扑结构,这些结构可以直接由规划和控制(PnC)模块使用。通过在复杂的城市环境中进行的实验,我们证明了我们系统的输出比网络输出更一致、更准确,并且可以有效地用于闭环自动驾驶系统。
PriorMapNet: Enhancing Online Vectorized HD Map Construction with Priors
北理工和元戎启行团队的工作:在线矢量化高精地图构建对于自动驾驶中的后续预测和规划任务至关重要。遵循MapTR范式,最近的工作取得了值得注意的成就。然而在主流方法中,参考点是随机初始化的,导致预测和GT之间的匹配不稳定。为了解决这个问题,我们引入了PriorMapNet来增强在线矢量化高精地图的构建。我们提出了PPS解码器,它为参考点提供了位置和结构先验。根据数据集中的地图元素进行拟合,先验参考点降低了学习难度,实现了稳定的匹配。此外,我们提出了PF编码器,利用BEV特征先验来增强图像到BEV的转换。此外,我们提出了DMD交叉注意,它分别沿多尺度和多样本解耦交叉注意,以实现效率。我们提出的PriorMapNet在nuScenes和Argoverse2数据集上的在线矢量化高精地图构建任务中实现了最先进的性能。
Enhancing Online Road Network Perception and Reasoning with Standard Definition Maps
用于城市和高速公路驾驶应用的自动驾驶通常需要高精(HD)地图来生成导航。然而在按比例生成和维护高精地图时,会出现各种挑战。虽然最近的在线建图方法已经开始出现,但其在于大范围感知时的性能受到动态环境中严重遮挡的限制。考虑到这些因素,本文旨在在开发在线矢量化高精地图表示时利用轻量级和可扩展的先验标准清晰度(SD)地图。我们首先研究了将原型光栅化SD地图表示集成到各种在线地图架构中。此外,为了确定轻量级策略,我们使用OpenStreetMaps扩展了OpenLane-V2数据集,并评估了图形SD地图表示的好处。设计SD地图集成组件的一个关键发现是,SD地图编码器与模型无关,可以快速适应利用鸟瞰图(BEV)编码器的新架构。我们的结果表明,使用SD图作为在线映射任务的先验可以显著加快收敛速度,并将在线中心线感知任务的性能提高30%(mAP)。此外,我们表明,引入SD图可以通过利用SD图来减少感知和推理任务中的参数数量,同时提高整体性能。
PrevPredMap: Exploring Temporal Modeling with Previous Predictions for Online Vectorized HD Map Construction
时间信息对于检测被遮挡的实例至关重要。现有的时间表示已经从BEV或PV特征发展到更紧凑的查询特征。与上述特征相比,预测提供了最高级别的抽象,提供了明确的信息。在在线矢量化高精地图构建的背景下,这种独特的预测特性可能有利于长时间建模和地图先验的整合。本文介绍了PrevPredMap,这是一个开创性的时间建模框架,利用之前的预测构建在线矢量化高精地图。我们为PrevPredMap精心设计了两个基本模块:之前的基于预测的查询生成器和动态位置查询解码器。具体而言,基于先前预测的查询生成器被设计为对来自先前预测的不同类型的信息进行单独编码,然后由动态位置查询解码器有效地利用这些信息来生成当前预测。此外,我们还开发了一种双模策略,以确保PrevPredMap在单帧和时间模式下的稳健性能。大量实验表明,PrevPredMap在nuScenes和Argoverse2数据集上实现了最先进的性能。
Mask2Map: Vectorized HD Map Construction Using Bird's Eye View Segmentation Masks
汉阳大学的工作:本文介绍了Mask2Map,这是一种专为自动驾驶应用设计的端到端在线高精地图构建方法。我们的方法侧重于预测场景中以鸟瞰图(BEV)表示的地图实例的类和有序点集。Mask2Map由两个主要组件组成:实例级掩码预测网络(IMPNet)和掩码驱动映射预测网络(MMPNet)。IMPNet生成掩码感知查询和BEV分割掩码,以在全局范围内捕获全面的语义信息。随后,MMPNet通过两个子模块使用本地上下文信息增强了这些查询功能:位置查询生成器(PQG)和几何特征提取器(GFE)。PQG通过将边界元位置信息嵌入到掩码感知查询中来提取实例级位置查询,而GFE则利用边界元分割掩码来生成点级几何特征。然而,我们观察到Mask2Map的性能有限,这是由于IMPNet和MMPNet之间对GT匹配的不同预测导致的网络间不一致。为了应对这一挑战,我们提出了网络间去噪训练方法,该方法指导模型对受噪声GT查询和扰动GT分割掩码影响的输出进行去噪。我们对nuScenes和Argoverse2基准进行的评估表明,Mask2Map比以前最先进的方法实现了显著的性能改进,分别提高了10.1%mAP和4.1 mAP。
MapDistill: Boosting Efficient Camera-based HD Map Construction via Camera-LiDAR Fusion Model Distillation(ECCV 2024)
三星研究院的工作:在线高精地图构建是自动驾驶领域一项重要而具有挑战性的任务。最近研究人员对基于成本效益高的环视相机的方法越来越感兴趣,而不依赖于激光雷达等其他传感器。然而,这些方法缺乏明确的深度信息,需要使用大型模型来实现令人满意的性能。为了解决这个问题,我们首次采用知识蒸馏(KD)思想进行高效的高精地图构建,并引入了一种名为MapDistill的基于知识蒸馏的新方法,将知识从高性能相机LiDAR融合模型转移到仅使用相机的轻量模型。具体而言,我们采用师生架构,即以摄像头LiDAR融合模型为教师,以轻量级摄像头模型为学生,并设计了一个双BEV转换模块,以促进跨模式知识提取,同时保持仅使用摄像头的成本效益部署。此外,我们提出了一种全面的蒸馏方案,包括跨模态关系蒸馏、双层特征蒸馏和映射头蒸馏。这种方法缓解了模式之间的知识转移挑战,使学生模型能够学习改进的特征表示,用于HD地图构建。在具有挑战性的nuScenes数据集上的实验结果证明了MapDistill的有效性,性能提升7.7 mAP或速度提升4.5倍。
Accelerating Online Mapping and Behavior Prediction via Direct BEV Feature Attention(ECCV 2024)
多伦多大学&英伟达等团队的工作:了解道路几何形状是自动驾驶汽车(AV)堆栈的关键组成部分。虽然高精(HD)地图可以很容易地提供此类信息,但它们的标签和维护成本很高。因此,许多最近的工作提出了从传感器数据在线估计HD地图的方法。最近的绝大多数方法将多相机观测值编码为中间表示,例如鸟瞰图(BEV)网格,并通过解码器生成矢量地图元素。虽然这种架构是高性能的,但它会大量抽取中间表示中编码的信息,从而阻止下游任务(例如行为预测)利用它们。在这项工作中,我们建议揭示在线地图估计方法的丰富内部特征,并展示它们如何将在线地图与轨迹预测更紧密地结合起来。通过这样做,我们发现直接访问内部BEV特征可以使推理速度提高73%,对真实世界nuScenes数据集的预测准确率提高29%。
Is Your HD Map Constructor Reliable under Sensor Corruptions?
三星研究院&悉尼大学等团队的工作:驾驶系统通常依赖高精(HD)地图获取精确的环境信息,这对规划和导航至关重要。虽然目前的高精地图构建器在理想条件下表现良好,但它们对现实世界挑战的弹性,例如恶劣天气和传感器故障,还没有得到很好的理解,这引发了安全问题。这项工作介绍了MapBench,这是第一个旨在评估HD地图构建方法对各种传感器损坏的鲁棒性的综合基准。我们的基准测试共包括29种由摄像头和激光雷达传感器引起的损坏。对31个HD地图构建器的广泛评估显示,在恶劣天气条件和传感器故障下,现有方法的性能显著下降,突显了关键的安全问题。我们确定了增强鲁棒性的有效策略,包括利用多模态融合、先进数据增强和架构技术的创新方法。这些见解为开发更可靠的高精地图构建方法提供了途径,这对自动驾驶技术的进步至关重要。
MapVision: CVPR 2024 Autonomous Grand Challenge Mapless Driving Tech Report
滴滴&北邮团队在CVPR 2024挑战赛上的工作:没有高精(HD)地图的自动驾驶需要更高水平的主动场景理解。在本次比赛中,组织者提供了多视角相机图像和标清(SD)地图,以探索场景推理能力的边界。我们发现,大多数现有的算法都是从这些多视角图像中构建鸟瞰图(BEV)特征,并使用多任务头来描绘道路中心线、边界线、人行横道和其他区域。然而,这些算法在道路的远端表现不佳,当图像中的主要对象被遮挡时,它们会遇到困难。因此,在这场比赛中,我们不仅使用多视角图像作为输入,还结合了SD地图来解决这个问题。我们采用地图编码器预训练来增强网络的几何编码能力,并利用YOLOX来提高交通要素检测精度。此外,对于区域检测,我们创新性地引入了LDTR和辅助任务,以实现更高的精度。因此,我们的OLUS最终得分为0.58。
DTCLMapper: Dual Temporal Consistent Learning for Vectorized HD Map Construction
时间信息在鸟瞰图(BEV)感知场景理解中起着关键作用,可以缓解视觉信息的稀疏性。然而,在构建矢量化高精晰度(HD)地图时,不加选择的时间融合方法会导致特征冗余的障碍。本文重新审视了矢量化HD地图的时间融合,重点研究了时间实例一致性和时间地图一致性学习。为了改进单帧映射中实例的表示,我们引入了一种新方法DTCLMapper。该方法使用双流时间一致性学习模块,该模块将实例嵌入与几何图相结合。在实例嵌入组件中,我们的方法集成了时态实例一致性学习(ICL),确保向量点和从点聚合的实例特征的一致性。采用矢量化点预选模块来提高每个实例中矢量点的回归效率。然后,从矢量化点预选模块获得的聚合实例特征基于对比学习来实现时间一致性,其中基于位置和语义信息选择正样本和负样本。几何映射组件引入了使用自监督学习设计的映射一致性学习(MCL)。MCL通过关注实例的全局位置和分布约束来增强我们一致学习方法的泛化能力。在公认的基准上进行的广泛实验表明,所提出的DTCLMapper在矢量化映射任务中达到了最先进的性能,在nuScenes和Argoverse数据集上分别达到了61.9%和65.1%的mAP得分。
HybriMap: Hybrid Clues Utilization for Effective Vectorized HD Map Construction
港中文团队的工作:近年来,利用全景相机构建矢量化高精地图引起了人们的广泛关注。然而,主流方法中常用的多阶段顺序工作流往往会导致早期信息的丢失,特别是在透视图特征中。通常,在最终的鸟瞰预测中,这种损失被视为实例缺失或形状不匹配。为了解决这个问题,我们提出了一种新的方法,即HybriMap,它有效地利用混合特征的线索来确保有价值的信息的传递。具体来说,我们设计了双增强模块,以便在混合特征的指导下实现显式集成和隐式修改。此外,透视关键点被用作监督,进一步指导特征增强过程。在现有基准上进行的广泛实验证明了我们提出的方法的最先进性能。
MGMap: Mask-Guided Learning for Online Vectorized HD Map Construction(CVPR 2024)
浙大和有鹿的工作:目前高精晰度(HD)地图构建倾向于轻量级的在线生成趋势,旨在保存及时可靠的道路场景信息。然而地图元素包含强大的形状先验。一些奇形怪状的标注使当前基于检测的框架在定位相关特征范围方面模糊不清,并导致预测中详细结构的丢失。为了缓解这些问题,我们提出了MGMap,这是一种掩模引导的方法,可以有效地突出信息区域,并通过引入学习到的掩模来实现精确的地图元素定位。具体来说,MGMap从两个角度采用了基于增强的多尺度边界元法特征的学习掩模。在实例级别,我们提出了掩码激活实例(MAI)解码器,该解码器通过激活实例掩码将全局实例和结构信息合并到实例查询中。在点级别,设计了一种新的位置引导掩模补丁细化(PG-MPR)模块,从更细粒度的角度细化点位置,从而能够提取特定于点的补丁信息。与基线相比,我们提出的MGMap在不同输入模式下实现了约10mAP的显著改善。大量实验还表明,我们的方法具有很强的鲁棒性和泛化能力。
MapTracker: Tracking with Strided Memory Fusion for Consistent Vector HD Mapping
Wayve等团队的工作:本文提出了一种矢量HD建图算法,该算法将地图表示为跟踪任务,并使用内存延迟历史来确保随时间推移的一致重建。我们的方法MapTracker将传感器流累积到两个潜在表示的存储缓冲区中:1)鸟瞰(BEV)空间中的光栅延迟,2)道路元素(即人行横道、车道分隔线和道路边界)上的矢量延迟。该方法借鉴了跟踪文献中的查询传播范式,该范式明确地将前一帧中的跟踪道路元素与当前帧相关联,同时融合了用距离步长选择的记忆延迟子集,以进一步增强时间一致性。对向量潜势进行解码以重建道路元素的几何形状。该论文还通过以下方式做出了基准贡献:1)改进现有数据集的处理代码,以通过时间对齐产生一致的地面实况,2)通过一致性检查增强现有的mAP度量。MapTracker在nuScenes和Agroverse2数据集上的表现明显优于现有方法,在传统和新的一致性感知指标上分别超过8%和19%。
HIMap: HybrId Representation Learning for End-to-end Vectorized HD Map Construction
三星团队的工作:矢量化高精(HD)地图构建需要预测地图元素(如道路边界、车道分隔线、人行横道等)的类别和点坐标。最先进的方法主要基于点级表示学习,用于回归精确的点坐标。然而该范式在获取元素级信息和处理元素级故障方面存在局限性,例如错误的元素形状或元素之间的纠缠。为了解决上述问题,我们提出了一个简单而有效的名为HIMap的HybrId框架,以充分学习和交互点级和元素级信息。具体来说,我们引入了一种名为HIQuery的混合表示来表示所有地图元素,并提出了一个点元素交互器来交互式地提取元素的混合信息,例如点位置和元素形状,并将其编码到HIQuery中。此外,我们提出了一个点元素一致性约束,以增强点级和元素级信息之间的一致性。最后,集成HIQuery的输出点元素可以直接转换为地图元素的类、点坐标和掩码。我们进行了广泛的实验,并在nuScenes和Argoverse2数据集上始终优于以前的方法。值得注意的是,我们的方法在nuScenes数据集上实现了77.8 mAP,至少比之前的SOTA高出8.3 mAP。
EAN-MapNet: Efficient Vectorized HD Map Construction with Anchor Neighborhoods
中山大学等团队的工作:高精(HD)地图对于自动驾驶系统至关重要。现有的大多数工作设计了基于DETR解码器的地图元素检测头。然而,初始查询缺乏对物理位置信息的明确结合,而普通的自注意力需要很高的计算复杂性。因此我们提出了EAN MapNet,用于使用锚点邻域高效构建高精地图。首先,我们基于锚点邻域设计查询单元,允许非邻域中心锚点有效地帮助将邻域中心锚点拟合到表示地图元素的目标点。然后利用查询之间的相对实例关系,提出了分组局部self-att(GL-SA)。这有助于同一实例的查询之间的直接特征交互,同时创新性地将本地查询用作不同实例查询之间交互的中介。因此,GL-SA显著降低了自注意力的计算复杂度,同时确保了查询之间有足够的特征交互。在nuScenes数据集上,EAN MapNet经过24个epoch的训练,达到了63.0 mAP的最新性能,比MapTR高出12.7 mAP。此外,与MapTRv2相比,它大大减少了8198M的内存消耗。
ADMap: Anti-disturbance framework for reconstructing online vectorized HD map(ECCV2024)
零跑&浙大等团队的工作:在自动驾驶领域,在线高精(HD)地图重建对于规划任务至关重要。最近的研究开发了几种高性能的高精地图重建模型来满足这一需求。然而,由于预测偏差,实例向量内的点序列可能会抖动或锯齿状,这可能会影响后续任务。因此,本文提出了抗干扰图重建框架(ADMap)。为了减轻点序抖动,该框架由三个模块组成:多尺度感知neck、实例交互注意力(IIA)和矢量方向差损失(VDDL)。通过以级联方式探索实例之间和实例内部的点序关系,该模型可以更有效地监控点序预测过程。ADMap在nuScenes和Argoverse2数据集上实现了最先进的性能。广泛的结果表明,它能够在复杂和不断变化的驾驶场景中生成稳定可靠的地图元素。
Stream Query Denoising for Vectorized HD Map Construction
中科大&旷视团队的工作:为了提高自动驾驶领域复杂和广泛场景中的感知性能,人们对时间建模给予了特别关注,特别强调了流式方法。流模型的主流趋势涉及利用流查询来传播时间信息。尽管这种方法很流行,但将流式范式直接应用于构建矢量化高精地图(HD地图)并不能充分利用时间信息的内在潜力。本文介绍了流查询去噪(SQD)策略,这是一种在高精地图(HD map)构建中进行时间建模的新方法。SQD旨在促进流模型中映射元素之间时间一致性的学习。该方法涉及对因在前一帧的GT中添加噪声而受到干扰的查询进行去噪。该去噪过程旨在重建当前帧的地面真实信息,从而模拟流查询中固有的预测过程。SQD策略可以应用于这些流式方法(例如StreamMapNet),以增强时间建模。拟议的SQD MapNet是配备SQD的StreamMapNet。在nuScenes和Argoverse2上的大量实验表明,我们的方法在近距离和远距离的所有设置中都明显优于其他现有方法。
MapNeXt: Revisiting Training and Scaling Practices for Online Vectorized HD Map Construction
独立研究作者:高精(HD)地图是自动驾驶导航的关键。将运行时轻量级高精地图构建的能力集成到自动驾驶系统中最近成为一个有前景的方向。在这种激增中,视觉感知脱颖而出,因为相机设备仍然可以感知立体信息,更不用说其便携性和经济性的吸引人的特征了。最新的MapTR架构以端到端的方式解决了在线高精地图构建任务,但其潜力仍有待探索。在这项工作中,我们提出了MapTR的全面升级,并提出了下一代高精地图学习架构MapNeXt,从模型训练和缩放的角度做出了重大贡献。在深入了解MapTR的训练动态并充分利用地图元素的监督后,MapNeXt Tiny在不进行任何架构修改的情况下,将MapTR Tiny的map从49.0%提高到54.8%。MapNeXt Base享受着地图分割预训练的成果,将map进一步提高到63.9%,已经比现有技术多模态MapTR提高了1.4%,同时速度提高了1.8倍。为了将性能边界推向下一个水平,我们在实际模型缩放方面得出了两个结论:增加的查询有利于更大的解码器网络进行充分的消化;一个大的主干稳定地提高了最终的准确性,没有花哨的东西。基于这两条经验法则,MapNeXt Huge在具有挑战性的nuScenes基准测试中取得了最先进的性能。具体来说,我们首次将无地图视觉单模型性能提高到78%以上,比现有方法中的最佳模型高出16%。
总结与展望
从今年文章的情况来看,可以总结以下几点趋势:
- 前期工作主要是模型层面的改动:比如模型训练的优化方法、损失、新型注意力机制、Query、Encoder-Decoder的改进等等方式;
- 下半年的文章则聚焦在如何使用额外的信息提升模型性能:比如SD Map、历史地图等等,额外信息的引入能大幅提升模型性能,这块也是业内实际量产的前沿方向,值得更进一步挖局;
- 此外也有一些工作尝试进行蒸馏、研究模型的鲁棒性等,这块对量产的指导意义更强,期待后续有业务数据的反馈。
总结来说,目前在线高精地图是工业界和学术界主流的研究方向,从CVPR/ECCV等顶会也可以反应出这一趋势。模块化方法离不开在线高精地图,端到端更离不开在线地图。但反过来说,在线地图依赖传统高精地图的标注训练。可谓从群众中来,到群众中去。传统高精地图不会湮灭,仍然会在技术发展的洪流中发光发热。
#Robo-GS
开源最Solid的赛博机械臂!机械臂与环境无缝交互
🚨🤖 警报!机器人界的"血案":特斯拉工厂惊现机械臂"暴走"事件 🚨
去年年末,一则"特斯拉机器人伤人事件"的微博引发了网友的广泛关注和热烈讨论。
📅 时间倒回2023年12月26日,英国小报《每日邮报》爆出猛料,标题惊悚:"特斯拉机器人在得克萨斯州工厂发生严重故障,一名工程师惨遭'毒手'------现场留下'血迹',紧急关闭按钮被工人们火速按下!"😱
📜 但别急,这起事故实际上记录在2021年的特斯拉报告中,并非近期发生。文章中描述了两名目击者惊恐地目睹他们的同事被一台本应用于抓取和移动新铝制汽车零件的机器"袭击"。🏭
根据澎湃新闻2024.1.10 https://www.thepaper.cn/newsDetail_forward_25951876
🤖 机器臂安全,警钟长鸣! 虽说这则网络新闻并非近期发生,但机器臂安全不容小觑。有了具身智能的加持后,或许能一定程度上防止工业机器人伤人事件。然而由于感知判断错误,以及机器臂网络重建误差依然有可能引起的工业事故。为了彻底规避"机械臂搬运零件时发生严重偏移,从而撞到检查设备的工人"这类事故,学者们对于机械臂控制以及机械臂网络重建精度的研究仍在努力探索中。
Real2Sim技术能刚好地帮助机械臂在工作时更好地控制"自己"。近期公开的Robo-GS采用混合表示模型,集成了网格几何、3D高斯核和物理属性,以增强机械臂的数字资产表示。这种混合表示通过高斯-网格-像素绑定技术实现,该技术在网格顶点和高斯模型之间建立了同构映射。这能够实现一个完全可微的渲染管道,该管道可以通过数值求解器进行优化,通过高斯展开实现高保真渲染,并使用基于网格的方法促进机械臂与其环境交互的物理合理模拟。该流程标准化了坐标系统和比例尺,确保了多个组件的无缝集成。除了重建机械臂外,还可以整体重建周围的静态背景和物体,从而实现机械臂与其环境之间的无缝交互。
该项成果还提供了涵盖各种机器人操作任务和机械臂网格重建的数据集,由网格、高斯溅射和真实世界运动的组合表示。这些数据集包括以数字资产形式捕获的现实世界运动,确保了质量和摩擦力的精确表示,这对于机器人操作至关重要。Real2Sim在机器人应用的真实渲染和网格重建质量方面达到了最先进的水平。
Robo-GS: A Physics Consistent Spatial-Temporal Model for Robotic Arm with Hybrid Representation https://arxiv.org/abs/2408.14873
背景知识
看到这里想必大家有几个问题:什么是渲染?什么是高斯溅射?下面在开始正文之前,文章先来了解一些背景知识。
什么是渲染?
渲染是指将三维场景(或模型)转换成二维图像的过程。这包括光照、阴影、纹理等效果的计算,以生成逼真的视觉效果。高保真渲染是指尽可能接近真实世界效果的渲染技术,包括光照、反射、折射等复杂物理现象的模拟。最常用的渲染方法之一就是利用三维场景重建技术,如高斯飞溅和神经辐射场(NeRF)。
- 高斯飞溅技术如何进行三维场景重建?
首先,从多个视角获取场景的图像或深度数据,以及相应的相机参数。在图像中提取特征点(如SIFT、SURF等),并在不同视角间进行匹配,以建立空间中的对应关系。然后利用多视角几何原理(如三角测量)计算匹配特征点的三维坐标,形成初始的三维点云。对于点云中的每个点,根据其位置精度和可能的误差来源(如相机校准误差、匹配误差等),分配一个高斯分布。这个高斯分布的均值即为该点的三维坐标,协方差矩阵反映了该点位置的不确定性。最后,将所有点的高斯分布组合起来,形成一个连续的、概率性的三维场景表示。这个表示可以进一步用于各种应用,如场景可视化、路径规划、碰撞检测等。
- 神经辐射场(NeRF)如何进行三维场景重建?
与传统的三维重建方法(如体素网格、点云等)不同,NeRF采用了一种连续的体积表示方式。这意味着它并不直接存储三维空间中每个点的颜色或密度,而是通过一个神经网络来"学习"这些属性的函数关系。NeRF的神经网络接收两个主要的输入:一是三维空间中的坐标点(x, y, z),它代表了场景中的位置;二是观察方向(θ, φ),它表示从哪个角度观察该点。网络的输出则是该点在给定观察方向下的颜色和体积密度(即该点被占据的可能性)。为了从神经辐射场中生成可视化的图像,NeRF采用了体积渲染技术。这一过程模拟了光线在三维场景中传播并与物质交互的过程。具体来说,它沿着从相机出发到图像平面上每个像素的光线进行采样,对于光线上的每个采样点,使用NeRF网络查询其颜色和密度。然后,根据这些颜色和密度值,以及光线在场景中的传播路径,计算出该像素的最终颜色。
NeRF的训练目标是最小化重建图像与真实图像之间的差异。这通常通过定义一个损失函数来实现,该损失函数计算了重建图像中每个像素的颜色与真实图像中对应像素颜色之间的误差。在训练过程中,通过反向传播算法来优化神经网络的参数,以最小化损失函数。这一过程通常涉及到大量的迭代计算,直到模型达到收敛状态。
特别之处
在了解了以上背景知识后,文章可以进一步看看这篇文章相对于先前的研究有什么特别的贡献了。
- 提出"同构网格-高斯绑定",实现了机械臂各部分的联动建模
在传统的或经典的机械臂控制方法中,机械臂的每个连杆都是通过预定义的关节连接起来的。控制机械臂沿特定路径运动的主要方式是通过调整各个关节的角度,这种连接方式允许机械臂按照预设的路径运动。但在高斯设置(机械臂的运动或某些特性被建模为高斯分布或高斯过程)中,各个元素(机械臂的连杆、关节或运动参数)之间没有明确的联动定义。即,这些元素被视为彼此独立的,而不是像经典控制方法中那样通过关节相互连接。由于在高斯设置中各个元素之间的独立性,当尝试模拟或控制机械臂的运动时,可能会出现运动不一致的情况,机械臂的运动可能不符合实际的物理规律或预期的运动轨迹。
为此,文章引入了"同构网格-高斯绑定"的概念。同构网格提供了一个统一的框架,用于描述机械臂的整体形状和结构。而高斯绑定则允许文章在这个框架内为每个元素分配一个高斯分布或高斯过程,以模拟其运动特性或不确定性。通过这种方式,文章能够在保持各个元素独立性的同时,实现它们之间的协调和联动,从而解决运动不一致的问题。
- 对机械臂更有效的姿态学习与控制
在Real2Sim2Real范例中,通过基于姿态的控制策略,利用逆运动学和基于扩散的生成模型,将现实世界中的机械臂操作转化为仿真环境中的控制指令,以实现更有效的机器人学习与控制。这种方法的核心在于将机械臂末端执行器在现实世界中的姿态轨迹转换到仿真环境中,以实现从现实到仿真的有效策略迁移。这种控制方法侧重于机械臂末端执行器(如夹爪、工具等)的姿态(位置和方向),通过测量或预设末端执行器在现实世界中的姿态轨迹,可以生成相应的控制指令。在仿真环境中重现末端执行器姿态的轨迹,可以帮助确保仿真训练的有效性和现实世界的一致性。
- 实现更逼真的渲染
以往的研究通常使用NeRF和高斯飞溅来重建机器人操作场景并实现模拟,探索基于高斯的、高度可变形的物体重建,进行机器人仿真和抓取任务。然而,这些方法往往无法实现高保真渲染。因此,为了实现逼真的渲染,文章将传统的基于MLP的变形场替换为数值ODE求解器,以提高四维高斯溅射的质量。
模型架构解析
接下来一起看看文章的模型具体是如何搭建的吧。
文章的数字资产由网格、高斯飞溅和真实世界的运动来表示。在传统的数字资产制作中,主要关注的是纹理网格和材料属性。然而,文章意识到物体的物理参数,如质量和摩擦,在机器人操作中更为重要。每个高斯绑定到一组网格顶点和面,创建高斯-网格-像素绑定,如图3所示。
文章定义投影映射(Projection Mapping)、网格映射(Mesh Mapping)、重投影映射(Re-projection Mapping)来连接高斯飞溅,网格和真实世界运动的表示。其中,投影映射将任何已知的3D点位置使用透视投影模型重新投影到2D图像平面上;网格映射将高斯中心(A)与顶点集合(V)中的每一个顶点关联;重投影映射定义了高斯中心(A)与图像像素位置(P)和顶点集合(V)相关联的同构关系φ,记录真实场景的图像平面、基于网格的模拟引擎的模拟结果和渲染的4D高斯飞溅场景之间转移轨迹。从真实世界的视频到高斯到网格的渐变(向后优化)、从网格到高斯到渲染视频的渐变(前向渲染)遵循以上映射关系。
接下来,文章从单目视频数据中提取机器人臂的链接、对象和背景网格,并将其与物理参数和控制方程相结合,以生成用于仿真的统一机器人描述格式(URDF)模型。具体来说分为以下几步:(1)从视频数据中提取三维网格模型,这些模型能够精确地表示机器人臂的各个部分、操作对象以及背景环境。(2)LLM(Large Language Models)在这里用于推断物理参数,如质量、摩擦系数等,这些参数对于机器人操作和仿真至关重要。(3)控制方程(用于描述和控制机器人运动的数学方程)被嵌入到URDF资产中,有助于在仿真环境中准确地模拟机器人的行为。(4)Panoptic图像分割技术更精确地从视频中提取和重建三维网格,并将它们整合到URDF模型中。(5)采用2DGS(2D Gaussian Splatting)从二维图像中提取三维几何信息,将图像中的像素映射到三维空间中的高斯分布。此外,文章采用场景重新定向技术将重建的场景与仿真引擎的坐标系对齐,并建立了一个统一的坐标系统OpenGL,无缝连接现实世界和模拟场景。
- 在运动控制方程的选择上,将原来的四维重建问题分解为静态和动态两个阶段,使用欧拉表示法处理静态场景,使用拉格朗日表示法处理动态场景。文章采用基于姿态的机械臂控制策略,重点控制末端执行器的姿态,并使用逆运动学来生成现实世界中每个关节的控制信号。在这种方法中,网格充当互连映射。每个网格的运动通过变换矩阵传递到每个绑定到该网格上的高斯,从而引导高斯的运动。
- 动力学控制方程选择牛顿-欧拉方程,生成一个具有机械臂力控制和刚体运动的变换矩阵。
- 最后,为了渲染视图,高斯飞溅将这些3D高斯投影到图像平面上,并计算每个像素的颜色,及每个高斯中心在t时刻的位置更新,从而提取一组轨迹,应用于渲染场景。
实验结果
文章比较了当前最先进的四维高斯喷溅,包括SC-GS和K-Planes,与本文的方法,发现K-Planes和SC-GS都不能优化机械臂和物体运动的转换。图5显示了执行一组轨迹以识别其拐角情况的机器人手臂的重建。本文的方法展示了处理复杂轨迹和运动的能力。
图6显示了推箱子的机械臂的重构。显然,KPlanes和SC-GS无法准确地重建机械臂和刚体的动态运动,这与Robo360的结果一致。相比之下,本文的方法在机器人操作任务中成功地保持了运动和几何一致性。
文章将文章的方法与2DGS Original, Gaustudio, SUGAR和商业3D扫描仪扫描的地面真相进行比较。与SUGAR和Gaustudio相比,文章的方法产生了更好的网格质量,并实现了接触丰富的策略执行。图7显示了与地面真值网格和其他方法相比,文章的网格结果的质量更好。可以看到,在URDF方法中,文章的模型成功地重构了机械臂不同小模块的相接的部位。
表1给出了Gaustudio、Sugar、Robostudio (v1)和Robostudio (Full)的定量比较结果。Robostudio (v1)和Robostudio (Full)之间的区别在于Robostudio (Full)包括二维高斯溅射(2DGS)中的重新定向和网格清洗技术,从而改善了对齐和采样。
总结
文章针对机械手臂操作场景的整体重建,这需要一个可操作的机器人模型,背景和对象的重建,质量和摩擦等物理参数的结合,以及逼真的渲染器。该方法的核心是高斯-网格-像素绑定,它在网格顶点、高斯核和图像像素之间建立了同构关系。每个高斯被分配一个语义标签和相应的ID,从而能够精确地应用由URDF控制的转换矩阵。这确保了真实世界视频、模拟结果和渲染图像之间轨迹的无缝传输。这种绑定的优点包括在每个表示之间传递端到端的可微分梯度,通过文章最先进的网格重建进行卓越的碰撞检测,以及高渲染质量。系统确保了模拟和现实之间的一致渲染,允许学习策略有效地部署在现实场景中。此外,它还支持在Isaac Sim (Gym)模拟中进行编辑后端,启用新姿态和新策略调整。此外,文章还提出了一种新的数字资产格式,由网格、高斯飞溅和真实世界运动的组合表示。该方法通过整合从真实世界的运动视频中提取的关键物理参数,如质量和摩擦,超越了传统的纹理网格和材料属性。
#ADS断代领先
华为发布首款轿跑SUV
26.8万,打破BBA崇拜的华为,接下来要挑战Model Y了。
刚刚,华为首款轿跑SUV智界R7开订,车长近5米,尺寸介于Model X和Model Y之间。
800V高压平台,最高续航超800km,预售价26.8万元。
同时,年度科技车皇问界M9,新增了五座版车型,46.98万起售。
26.8万起,华为首款轿跑SUV开订
智界R7车长/宽/高分别为4956/1981/1634(mm),比Model Y大得多,外观和智界S7相似,形成了鸿蒙智行家族设计语言。
前排内饰风格也和智界S7相似,椭圆的方向盘,以及超大的中控平台。
前舱部分首发了一项很有趣的功能。
华为将手机上双击截屏的思路,迁移至前备箱,可以敲击开启。
后备箱空间837L,三层分区,可以放下3个28寸大行李箱和1个20寸登机箱。
副驾有零重力座椅,余承东介绍,即便是前排如图中躺下一个女生,后排仍然可以坐人。
展车不久后会到门店,大家可以线下体验体验,验证一下嘴总有没有"以行践言"。
三电方面,搭载800V高压平台,最高续航802km,在纯电的SUV中实现了罕见的"双800"。
长续航主要得益于超低的风阻系数,余承东再次强调,智界R7的风阻系数全球最低。
操控上,前双叉臂后五连杆悬挂,全系标配CDC连续可变阻尼减震器和空气悬架。
以上就是智界R7目前公开的主要信息,预售价格为26.8万元,也就是13台华为三折叠的价格。
比智界S7的预售价格贵了1万元,比Model Y也贵了1.6万元,预计正式上市还会有惊喜。
压轴登场的智界R7,有很多惊喜,但并非是唯一主角。
与华为三折叠同台发布的,还有问界M9五座版。
46.98万起,问界M9五座版上市
问界M9交付以来,在50万元以上SUV市场势如破竹,连续5个月蝉联,累计大定突破13万台。
不过,三排座椅也劝退了一部分潜在用户,比如一孩家庭,日常用不上这么多座位。
所以说此次新增五座版,可以覆盖更大的用户群体。
五座也能变四座,中台配有杯架、储物盒和无线快充:
头枕音响拔掉后,支持"双人沙滩椅模式":
少了一排座位,后备箱空间自然更富裕了。
五座版后备箱空间达1043L,可以放下4个28英寸的大行李箱以及1个高尔夫球包。
空间更大之外,华为还进行了很多新的设计:
比如类似劳斯莱斯的"揽景座椅",非常适合钓鱼佬。
配备了储物箱:
装配了麂皮包裹的硬质遮物板以及阻隔器:
底部托盘可以拉出,野外露营时当个餐桌很方便:
除了车座数量变化,还有以下多项升级:
首先是最让人惊讶的是,问界M9可以圆规掉头了。
然后是余承东确认,ADS 3.0明日起鸿蒙智行全系升级,余承东认为ADS 3.0是"断代式领先",强调车位到车位的体验,"环岛都能开",这也是此前2.0版本的弱势场景。
其他方面,主要是车内外的一些功能小升级。
车外新增了全新的迎宾灯语。
支持语音控制打开车门:
打开车门来到车内,先来看中控位置,此前曾有人吐槽水晶旋钮功能太少,这次新增悬架高度调节功能和路面辅助模式。
然后是后排,改善了投影幕布体验,防止调节座椅挡住幕布下降:
新车投影幕布还配备了遥控器,老车主后续也会陆续免费送。
最后来看下售价,与六座版相同,有Max和Ultra两个版本。其中只有Ultra版有纯电车型。
Ultra版比Max版多了电动门、华为投影大灯、投影幕布。
Ultra增程版的电池包更大。
有没有很心动?
赛力斯总裁何利扬透露,M9五座版6-8周可交付。
毫无疑问,五座版的上市,会让问界M9在50万元以上SUV市场的统治地位,更加稳固。
问界M9终结了BBA神话,新的问题来了:
智界R7,能不能延续辉煌,把Model Y拉下神坛呢?
#MiniDrive
单卡就能训的VLM来了!中科院提出, 各项指标完爆当前SOTA~
视觉语言模型(VLM)是自动驾驶中的通用端到端模型,通过问答交互实现预测、规划和感知等子任务。然而大多数现有方法依赖于计算成本高昂的视觉编码器和大型语言模型(LLM),这使得它们难以在现实世界场景和实时应用中部署。同时大多数现有的VLM缺乏处理多幅图像的能力,因此难以适应自动驾驶中的环视感知。为了解决这些问题,我们提出了一个名为MiniDrive的新框架,该框架结合了我们提出的特征工程混合专家(FE-MoE)模块和动态指令适配器(DI-Adapter)。FE MoE在输入到语言模型之前,有效地将2D特征映射到视觉标记嵌入中。DI适配器使可视令牌嵌入能够随着指令文本嵌入而动态变化,解决了以前方法中同一图像的静态可视令牌嵌入问题。与之前的工作相比,MiniDrive在参数大小、浮点运算和响应效率方面实现了最先进的性能,轻量版本仅包含83M个参数。
开源链接:https://github.com/EMZucas/minidrive

总结来说,本文的主要贡献如下:
- 本文开发了自动驾驶VLMs MiniDrive,它解决了自动驾驶系统VLMs中高效部署和实时响应的挑战,同时保持了出色的性能。该模型的训练成本降低,多个MiniDrive模型可以在具有24GB内存的RTX 4090 GPU上同时进行完全训练;
- MinDrive首次尝试利用大型卷积核架构作为自动驾驶视觉语言模型的视觉编码器骨干,并能够更高效、更快地提取不同图像级别的2D特征。我们提出了特征工程混合专家(FE-MoE),它解决了从多个角度将2D特征高效编码到文本标记嵌入中的挑战,有效地减少了视觉特征标记的数量,并最大限度地减少了特征冗余;
- 本文通过残差结构引入了动态指令适配器,解决了同一图像在输入到语言模型之前的固定视觉标记问题。DI适配器使视觉特征能够动态适应不同的文本指令,从而增强跨模态理解;
- 我们在MiniDrive上进行了广泛的实验,与Drive LM上具有多视图图像输入的自动驾驶VLM相比,实现了最先进的性能。此外,我们在CODA-LM上使用单幅图像输入的性能比普通开源VLM(>7B)平均高出13.2分。
相关工作回顾Vision-Language Models
Transformer架构的成功推动了LLM的发展。在计算机视觉领域,Dosovitskiy等人提出了ViT,它将图像划分为补丁,并根据transformer架构对其进行处理,成功地将其应用于计算机视觉任务。Transformer架构可以有效地学习和表示图像和自然语言。一项开创性的工作是CLIP,它将对比学习用于图像-文本对齐训练,展示了在图像分类任务中优越的零样本能力。Llava冻结了CLIP的视觉编码器(ViT),并在视觉编码器和LLM之间添加了一个线性投影层,旨在将视觉输出表示映射到文本空间中。同样BLIP-2通过更复杂的Q-Former对齐视觉和文本表示。InstructBLIP以BLIP-2为基础,对公共视觉问答数据集进行指令微调。MiniGPT-4将冻结的视觉编码器和Q-Former与类似冻结的LLM Vicuna相结合,将它们与单个投影层对齐。Llava-1.5v通过使用带有多层感知器(MLP)投影层的CLIP-ViT-L-336px,并添加针对学术任务量身定制的VQA数据,通过简单的响应格式化提示,在11个基准测试中实现了最先进的性能,显著提高了数据效率。Phi-3-mini具有默认的4K上下文长度,并引入了使用LongRope技术扩展到128K上下文长度的版本,同时采用了类似于Llama-2的块结构和相同的标记器,实现了轻量级的多模式模型。尽管这些多模态大型模型具有强大的功能,并且有轻量化设计的趋势,但它们的参数数量超过10亿,这使得在许多硬件平台上的部署和实时使用具有挑战性。因此,有必要研究和开发具有较小参数大小和较低计算成本的高效视觉语言模型。
Autonomous Driving Based on LLMs
LLM有效地增强了自动驾驶系统的可解释性及其与人类的互动。这些优势促使研究人员将自动驾驶的多模态数据纳入LLM的训练中,旨在为自动驾驶构建多模态大型模型。Chen等人将矢量化模态信息与LLaMA-7B对齐,以训练自动驾驶的问答模型。训练过程遵循两阶段方法:在第一阶段,向量表示与冻结的LLaMA对齐,而在第二阶段,LoRA用于微调语言模型。DriveGPT4也使用LLaMA作为其大型语言模型,使用CLIP作为视觉编码器。它通过输入视觉和文本信息来生成相应的答案。DriveGPT4操纵ChatGPT/GPT-4生成指令数据集,并在此数据集上进行训练。然而DriveGPT4仅使用单视角图像,限制了其在自动驾驶场景中处理更全面理解的能力。Wang等人开发了DriveMLM,该模型使用LLaMA-7B作为基础语言模型,ViT-g/14作为图像编码器。该模型处理多视图图像、激光雷达点云、交通规则和用户命令,以实现闭环驾驶。受大型语言模型中的思维链方法的启发,Sha等人提出了一种用于驾驶场景的思维链框架,使用ChatGPT-3.5为自动驾驶提供可解释的逻辑推理。Mao等人介绍了GPT Driver,它使用ChatGPT-3.5为自动驾驶汽车创建运动规划器,GPT Driver通过将规划器的输入和输出表示为语言令牌,将运动规划作为语言建模任务进行刷新。Sima等人发布了DriveLM数据集,这是一个图形化的视觉问答数据集,其中包含与感知、行为和自我车辆规划相关的问答对,基于NuScenes数据集的多视图图像数据。为了建立基线,Li等人在这个新数据集上对BLIP-2进行了微调。EM-VLM4AD引入了门控池注意力(GPA),它将多个图像聚合到一个统一的嵌入中,并将其与文本嵌入连接作为LLM的输入,在DriveLM数据集上取得了有前景的结果。
虽然现有的工作提供了巨大的价值,并展示了强大的自动驾驶能力,但大多数模型都有超过10亿个参数。它们主要基于GPT-3.5和LLaMA等大规模语言模型,并依赖于基于ViT架构构建的视觉编码器,如CLIP、ViT-g/14和ViT-B/32。这导致了高昂的计算成本,使这些模型不适合在线场景。尽管有开发轻型自动驾驶车型的趋势,但与大型车型相比,它们的性能仍然不足。
MinDrive方法详解
MiniDrive是自动驾驶领域的一种视觉语言模型,旨在执行视觉问答任务。它通过接收图像和用户指令文本作为输入来生成文本响应。在本节中,我们首先详细介绍MiniDrive的整体框架,然后具体解释每个模块的技术细节和原理,包括视觉编码器、特征工程混合专家(FE-MoE)和动态指令适配器(DI适配器)。
Model Architecture

图2(a)展示了MiniDrive的整体结构。在MiniDrive中,主要有两个分支:视觉和文本。在视觉方面,给定来自车辆的n幅图像作为视觉编码器的输入,每幅图像都接收一组深度2D特征表示。然后,这些特征被输入到FE-MoE中,在那里,多个专家沿着通道维度c压缩信息,并沿着高度h和宽度w维度扩展信息,以生成新的2D特征表示。在FE MoE中,Gate网络确定哪些专家更适合处理每个图像,为每个专家分配不同的权重值。最后,通过加权和来组合新的2D特征表示,以产生新的特征集Vmoe。压扁Vmoe得到V。
在文本侧,通过Tokenizer和Em垫层处理用户在构造中的自然语言,以获得文本T的令牌嵌入。文本T的嵌入序列用作键(k)和值(v),而现阶段的视觉嵌入序列v用作查询(q)。这些被馈送到DI适配器中以计算新的视觉嵌入序列V1,该序列现在结合了来自文本嵌入T的上下文信息,从而能够更好地进行跨模态理解或决策。然后,V1通过残差连接与V组合以形成序列。然后,连接,被用作语言模型的输入。语言模型解码以生成具有最高预测概率的单词序列。整个框架高效地处理多图像输入信息,动态响应用户查询。
Vision Encoder
如图2(b)所示,视觉编码器的骨干网络基于大核神经网络UniRepLKNet(Ding等人,2024),该网络在多种模态上表现出色。它有效地利用了大型内核卷积的特性,无需深入网络层即可实现广泛的接受域。在保持高效计算的同时,它在各种任务中也达到或超过了当前最先进技术的性能。这种通用性和效率使其成为一个强大的模型,在广泛的感知任务中具有潜力。如图3所示,对UniRepLKNet的整体架构进行简要回顾后发现,它主要由多个顺序连接的Stage层组成。每个阶段主要由一系列Lark Block和Smak Block组成。在MiniDrive中,我们使用UniRepLKNet作为视觉网络的骨干,其中输入图像并从最后阶段n获得输出特征图F1。
Feature Engineering Mixture of Experts
在图2(b)中,我们展示了FE-MoE的具体结构,该结构旨在处理来自多幅图像的二维输入特征。每个输入图像对应于视觉编码器输出的特征图F1。为了进一步有效地处理每个图像的2D特征表示,它们被输入到FE-MoE中。首先,门网络使用F1来获得与样本对应的专家选择权重。Gate网络主要由卷积层、最大池化层和线性层组成,如下式所示:
每个专家网络主要由解卷积层、ReLU层和卷积层组成。解卷积层首先执行初始上采样映射,增加特征图宽度和高度的维度以扩展信息量,从而促进后续的映射学习。同时,它减少了原始特征图中的通道数量,以最小化数据冗余并选择最重要的二维特征表示信息,从而显著简化了后续视觉标记的数量。卷积层进一步变换特征,以提高专家的学习能力。公式如下:
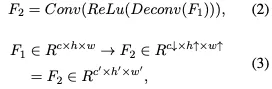
在这种情况下,F2表示单个专家的输出。假设图像的第i个专家的权重为Wi,该专家的输出为Fi,专家总数为N,则FE-MoE模型处理后的图像特征Vmoe由以下公式表示:
Dynamic Instruction Adapter
在之前的视觉语言模型中,图像表示在输入语言模型之前是固定的,在进入语言模型进行计算之前,它们对应于各种文本表示。为了使图像表示在输入到语言模型之前能够根据不同的文本表示进行动态转换,从而提高跨模态理解,我们引入了动态指令机制并设计了动态指令适配器。我们使用文本输入序列T作为键(k)和值(v),使用图像输入序列v作为查询(q)。通过交叉注意,我们计算了融合了文本上下文信息的融合序列V。公式如下:
残差通道中的序列通过残差连接与投影层的输出序列连接,作为输入到语言模型之前的视觉表示。附加语言模型输出的培训见附录。
实验结果定量结果
在表1中,我们将MiniDrive的评估结果与之前在测试集上的工作进行了比较,包括EM-VLM4AD和Drive Agent。就指标的整体性能而言,MiniDrive224和MiniDrive384都优于以前的方法,尽管DriveLM Agent在BLEU-4中覆盖了我们,但它的参数计数明显大于我们的,达到3.96B。
计算分析
本节主要比较MiniDrive和一系列现有视觉语言模型在参数计数、浮点运算(FLOP)和内存使用(GB)方面的差异。结果如表2所示。以224的输入图像分辨率为例,MiniDrive在所有三个方面都表现出了卓越的性能。
定性示例
在图4中,我们展示了MiniDrive在三个不同任务中对看不见的样本的实际响应。为了对MiniDrive对多视图图像输入的感知进行可解释性分析,我们分析了MiniDrive在各种场景下的激活图。在图4(a)中,MiniDrive演示了对多个图像输入的感知问答,蓝色框表示用户指令中"左后"位置引用的图像。红色框对应于MiniDrive的响应,主要关注该图像,在指定位置识别"许多汽车、一辆卡车和一名行人"。在图4(b)中,MiniDrive演示了如何为多个图像输入规划问答。根据用户的指令和空间术语"CAM_FRONT",MiniDrive会聚焦在相应正面图像左侧的红色框上。这种关注与人们在做出规划决策时考虑的因素相一致,包括行车道标记和自我汽车左侧的车辆。在图4(c)中,MiniDrive演示了多个图像输入的预测性问答。根据用户预测"左前"位置行人运动的指令,MiniDrive会关注相应位置图像中的行人,并用红色框突出显示。综上所述,MiniDrive在激活图中关注的对象与人类驾驶员在驾驶过程中遵循的推理一致,表明MiniDrive具有一定程度的可靠性和可解释性。
消融实验
为了验证每个模块的有效性,我们设计了一系列消融实验。在表3中,我们研究了FE-MoE和动态指令适配器(DI适配器)对MiniDrive的影响。当FE-MoE和动态指令适配器分别引入时,各种指标的结果都有所改善,当两个模块同时引入时,效果更好。这表明了模块之间机制的有效性。其他消融实验的详细信息见附录。
进一步分析
尽管MiniDrive被设计为用于接收多图像输入的自动驾驶问答模型,但它从多个图像中提取、压缩和重新学习信息,作为语言模型的文本令牌。然而它仍然可以用于单个图像输入任务。我们将其与CODA-LM上现有的主流开源和闭源通用模型进行了比较,如表4所示。很明显,尽管MiniDrive只有83M个参数,但它表现出了卓越的性能,优于开源模型,接近闭源模型的性能。由于训练数据的分布问题,我们认为这是MiniDrive识别"圆锥体"能力强的主要因素。
结论
本文介绍了MiniDrive,这是一种最先进的自动驾驶轻量级视觉语言模型。我们介绍了FE-MoE和DI-Adapter机制,提出了一种将2D卷积特征映射到语言模型的文本标记中的新方法。我们的模型在DriveLM和CODA-LM两个数据集上取得了出色的结果。未来,我们的目标是开发一个具有视频输入的实时响应模型,以进一步推进自动驾驶技术。
限制
MiniDrive构建了专用于自动驾驶领域的VLM,并在当前的主流基准测试中取得了优异的成绩。然而它仍然缺乏一定程度的泛化能力,我们认为这是由于训练样本的局限性造成的。现有的自动驾驶领域需要更多的公共数据集和开发工作。此外,MiniDrive的培训主要集中在基于指令的数据集上,它仍然会遇到幻觉问题。
#GraspSplats
具身智能再发力!高效抓取,准确性和效率都提升
机器人对物体部分进行高效且零样本抓取的能力对于实际应用至关重要,并且随着视觉语言模型(VLMs)的最新进展而变得越来越普遍。为了弥补支持这种能力的表示中的二维到三维差距,现有方法依赖于通过可微渲染或基于点的投影方法的神经场(NeRFs)。然而,我们证明NeRFs由于其隐式性而不适用于场景变化,而基于点的方法在没有基于渲染的优化的情况下,对于部件定位不准确。为了解决这些问题,我们提出了GraspSplats。通过使用深度监督和一种新颖的参考特征计算方法,GraspSplats在不到60秒的时间内生成高质量的场景表示。我们进一步通过展示GraspSplats中明确且优化的几何形状足以自然支持(1)实时抓取采样和(2)使用点跟踪器的动态和关节物体操作,来验证基于高斯表示的优势。我们在Franka机器人上进行了大量实验,证明GraspSplats在各种任务设置下显著优于现有方法。特别是,GraspSplats优于基于NeRF的方法(如F3RM和LERF-TOGO)以及二维检测方法。
原文链接:https://arxiv.org/pdf/2409.02084
领域背景介绍
基于部件级理解的零样本高效操作对于下游机器人应用至关重要。设想一个被部署到新家庭的厨房机器人:在给定包含语言指令的食谱后,机器人通过把手拉开抽屉,通过手柄抓住工具,然后推回抽屉。为了执行这些任务,机器人必须动态理解部件级的抓取功能,以便与物体进行有效交互。最近的研究工作,通过将大规模预训练视觉模型(如CLIP)的参考特征嵌入到神经辐射场(Neural Radiance Fields, NeRFs)中来探索这种理解。然而,这些方法仅提供目标级别的场景静态理解,并且需要数分钟的时间来训练场景,这导致在场景发生任何变化后都需要进行昂贵的重新训练。这一局限性极大地阻碍了涉及物体位移或需要部件级理解的实际应用。另一方面,基于点的方法,通过对二维特征进行反投影,在特征构建方面效率很高,但在处理视觉遮挡时遇到困难,并且往往无法在没有进一步优化的情况下推断出细粒度的空间关系。
除了动态和部件级的场景理解外,实现精细操作还要求机器人对场景的几何和语义都有深入的理解。为了从粗略的二维视觉特征中获得这种能力,需要进一步的优化来弥合二维到三维的差距。基于NeRF的方法通过可微渲染促进了这种理解。然而,NeRFs从根本上来说是隐式表示,这使得它们难以编辑以适应场景变化,从而导致静态假设。为了解决动态问题,一些工作通常使用三维密集对应关系来预测抓取姿态,其中基于参考状态中的关键点识别出可靠的抓取点,然后将其应用于不同的视角或物体位置。然而,这些方法在跟踪物体状态随时间的变化和处理相同物体方面面临挑战。
为此,本文提出了GraspSplats。给定来自校准相机的带姿态的RGBD帧,GraspSplats通过3DGS(3D Gaussian Splatting,3DGS)构建了一个高保真表示,该表示作为显式高斯椭球体的集合。GraspSplats在不到30秒的时间内重建场景,并支持静态和刚性变换的高效部件级抓取,从而实现了如跟踪部件物体等现有方法无法实现的操作。GraspSplats从深度帧的粗略几何形状初始化高斯分布;同时,使用MobileSAM和MaskCLIP实时计算每个输入视图的参考特征。这些高斯分布通过可微光栅化进一步优化几何、纹理和语义。用户可以提供一个目标名称查询(例如,"杯子")和部件查询(例如,"手柄"),以便GraspSplats能够高效地预测部件级可抓取性并生成抓取建议。GraspSplats直接使用显式高斯原语在毫秒级内生成抓取建议,为此扩展了现有的抓取生成器。此外,还进一步利用显式表示来在物体位移下保持高质量表示。使用点跟踪器,GraspSplats粗略地编辑场景以捕捉刚性变换,并通过部分场景重建进一步优化它。
本文在一台台式计算机上实现了GraspSplats,并搭配真实的Franka Research (FR3)机器人来评估其在桌面操作中的有效性。GraspSplats中的每个组件都非常高效,并且在经验上比现有工作快一个数量级(10倍)------包括计算二维参考特征、优化三维表示和生成二指抓取建议。这使得在手臂扫描的同时并行生成GraspSplats表示成为可能。在实验中,GraspSplats的性能优于基于NeRF的方法(如F3RM和LERF-TOGO)以及其他基于点的方法。
本文贡献主要有三个方面:
提出了一个使用三维高斯溅射(3DGS)进行抓取表示的框架。GraspSplats高效地重建了具有几何、纹理和语义监督的场景,在准确性和效率方面都优于基线方法,实现了零样本部件级抓取。
开发了一种可编辑的高保真表示技术,该技术超越了静态场景中的零样本操作,进入了动态和关节物体操作领域。
进行了广泛的真实机器人实验,验证了GraspSplats在静态和动态场景中零样本抓取的有效性,展示了方法相对于基于NeRF或基于点的方法的优越性。
相关工作一览
语言引导的操作。为了支持零样本操作,机器人必须利用从互联网规模数据中学习到的先验知识。最近有一些工作使用二维基础视觉模型(如CLIP、SAM或GroundingDINO)来构建开放词汇量的三维表示。然而,这些方法大多依赖于简单的二维反投影。没有进一步的基于渲染的优化,它们通常无法提供精确的部件级信息。最近,基于DFF和LERF的研究工作,研究人员发现将特征蒸馏与神经渲染相结合,可以为机器人操作提供有前景的表示,因为它同时提供了高质量的语义和几何信息。值得注意的是,LERF-TOGO提出了条件CLIP查询和DINO正则化,以实现基于部件的零样本操作。F3RM从少量演示中学习抓取。Evo-NeRF专注于针对堆叠透明物体的NeRF,这在概念上与我们的方法正交。然而,这些方法都是基于NeRF的,而NeRF本质上是隐式的。尽管某些NeRF表示可以适应于动态运动的建模,如基于网格的方法,但显式方法更适合于动态场景的建模。
抓取姿态检测。在机器人操作中,抓取姿态检测一直是一个长期的研究课题。现有方法大致可分为两类:端到端方法和基于采样的方法。端到端方法为抓取姿态提供了简化的流程,并融入了学习的语义先验(例如,通过手柄抓取的杯子)。然而,这些方法通常要求测试数据模式(如视角、目标类别和变换)与训练分布完全匹配。例如,LERF-TOGO通过为输入生成数百个使用不同变换的点云来解决GraspNet的视角变化问题,这需要大量的计算时间。另一方面,基于采样的方法不学习语义先验,但当存在显式表示时,它们能提供可靠且快速的结果。在本研究中,发现显式的高斯基元自然地与基于采样的方法相结合,而GraspSplats中嵌入的特征则通过语言指导来补充语义先验。这种直观的组合使得在动态和杂乱环境中高效地、准确地采样抓取姿态成为可能。
并行工作。同时,多种方法开始将3DGS与二维特征相结合。这些工作中的大多数仅关注外观编辑。我们基于特征溅射构建了GraspSplats,因为其在工程上进行了优化,并进一步将整体重建时间缩短到十分之一。在准备本工作过程中,出现了一项并行工作。与我们的工作类似,Zheng等人40也将高斯溅射与特征蒸馏相结合用于抓取。然而没有处理面向任务的操作中的部件级查询,并且仍然主要关注静态场景。尽管他们简要展示了高斯基元在处理移动物体方面的潜力,但他们仍然做出了一个强烈的假设------只有当物体被机械臂移动时,物体表示才会发生位移。这样的假设在涉及外部力量(例如,被其他机器或人类移动)的更一般场景中是不充分的。此外,他们仍然需要昂贵的参考特征生成。最新的并行工作41使用高斯溅射进行机器人操作,但它仅融合了来自几个固定camera的数据,因此没有解决部件级操作问题。GraspSplats扩展了高斯溅射,作为解决这些问题的一个有前途的替代方案。
使用3D特征溅射进行高效操作
问题定义。我们假设有一个带有平行夹爪的机器人、一个经过校准的手腕内置RGBD相机以及一个经过校准的第三人称视角相机。给定一个包含一组物体的场景,目标是让机器人通过语言查询(例如,"厨房刀")来抓取并提起物体。可选地,还可以进一步提供部分查询以指定要抓取的部分(例如,"手柄"),以实现面向任务的操控。值得注意的是,与以往的工作不同,我们不假设场景是静态的。相反,我们的目标是设计一种更通用的算法,即使物体在移动,也可以连续进行部分级别的抓取可负担性和采样。
背景。原始的Gaussian Splatting专注于新视角合成,并且仅限于仅使用纹理信息作为监督。最近的一些工作试图将GS扩展到重建密集的2D特征。更具体地说,GraspSplats使用溅射算法来渲染深度、颜色以及密集的视觉特征。
其中,、和分别是每个高斯项相对于相机原点的距离、潜在特征向量和颜色,α是每个高斯项的透明度,且索引i∈N按的升序排列。遵循惯例,我们进一步假设每个高斯项的特征向量是各向同性的。然后,使用L2损失对渲染的深度、图像和特征进行监督。请注意,所有近期的工作都遵循与等式1类似的范式。
概述。为了支持开放式抓取,GraspSplats提出了三个关键组件。概述如图2和图3所示。首先,一种使用新颖参考特征和几何正则化来有效构建场景表示的方法。其次,一种使用3D条件语言查询和扩展的对极抓取proposal直接在3D高斯上生成抓取建议的方法。最后,一种在目标位移下编辑高斯的方法,该方法可实现动态和关节式目标操作。
1.构建特征增强的3D高斯体
使用可微分的栅格化将2D特征提升到3D表示。尽管现有的特征增强的GS(Gaussian Splatting)工作提供了部分级别的理解,但一个常被忽视的弱点是场景优化开始之前的高昂开销。这个开销可以进一步分解为(1)昂贵的参考特征计算或(2)源自SfM(Structure from Motion,运动恢复结构)预处理的稀疏高斯体的密集化。
高效的层次化参考特征计算。现有方法在将粗糙的CLIP特征正则化方面花费了大部分计算资源------无论是通过数千个多尺度查询,还是通过基于掩码的正则化和昂贵的网格采样。
这里提出了一种使用MobileSAMV2来高效地正则化CLIP的方法。我们生成了层次化的特征,包括目标级和部件级,这些特征专为抓取而设计。给定一张输入图像,MobileSAMV2会预测出与类别无关的边界框集合和一组目标掩码{M}。对于目标级特征,首先使用MaskCLIP来计算整个图像的粗略CLIP特征。然后遵循Qiu等人的方法,并使用带掩码的平均池化来根据{M}对目标级CLIP特征进行正则化。
对于部件级特征,从中提取图像块,以便在MaskCLIP上进行批量推理。由于融入了从SA-1B数据集中学到的目标先验知识,因此N远小于通过均匀查询进行高效推理所需的图像块数量。然后,我们对特征进行插值,以将它们重新映射回原始图像的形状,并对多个实例取平均值,以形成用于部件级监督的。
在可微分栅格化过程中,我们引入了一个具有两个输出分支的浅层MLP(多层感知机),该MLP将等式1中的渲染特征作为中间特征输入。第一个分支渲染目标级特征,第二个分支渲染部件级特征和,即, = ,其中和分别使用和通过余弦损失进行监督。在联合损失Lobj + λ · Lpart中将部件级项的权重λ设置为2.0,以强调部件级分割。
通过深度进行几何正则化。现有的特征增强的GS方法没有对几何进行监督。在GraspSplats中,将来自深度图像的点投影为初始高斯体的中心。此外,在训练过程中使用深度作为监督。经验上,这种额外的几何正则化显著减少了训练时间,并获得了更好的表面几何形状。
2.静态场景:部件级目标定位和抓取采样
为了支持高效的零样本部件级抓取,GraspSplats执行目标级查询、条件部件级查询和抓取采样。与基于NeRF的方法不同,后者需要从隐式MLP中提取与语言对齐的特征和几何形状,这需要昂贵的渲染过程,而GraspSplats则直接在高斯原语上操作,以实现高效的定位和抓取查询。开放词汇目标查询。我们首先执行目标级开放词汇查询(例如,"杯子"),其中我们使用语言查询来选择要抓取的目标,并可选择使用否定查询来过滤掉其他目标。我们通过直接识别那些各向同性CLIP特征与正查询比负查询更紧密对齐的3D高斯体来实现这一点。特征-文本比较过程遵循标准的CLIP实践。
开放词汇条件部件级查询。正如Rashid等人所讨论的,CLIP表现出类似词袋的行为(例如,"杯子手柄"的激活往往同时包含杯子和手柄)。因此,有必要执行条件查询。虽然LERF-TOGO需要两步(渲染-体素化)过程,但GraspSplats原生支持基于高斯原语的CLIP条件查询。特别是,在给定从上一操作分割出的目标后,我们只需用新的部件级查询重复该过程,并将高斯体集合限制在分割出的目标上。图3给出了这种部件级条件的定性示例。
使用高斯Primitives进行抓取采样。直接在高斯Primitives上进行抓取采样,以实现流畅的抓取。为此,将GraspSplats与GPG(一种基于采样的抓取proposal)相结合。首先定义一个工作空间,它是从分割出的目标部件扩展而来的三维空间。扩展半径是高斯Primitives尺度最长轴之和与夹持器碰撞半径之和。然后从中采样N个点。在这些采样点的邻域内(其中表示从选定点开始指定距离内的区域),我们聚合具有渲染法线的高斯Primitives,并使用平均法线方向计算抓取采样的参考坐标系。
其中,(g)表示高斯Primitives g的单位表面法线。在每个采样点p的参考坐标系中,执行局部网格搜索以找到候选抓取位置,其中夹持器的手指在终端候选抓取位置与分割部件的几何形状接触。
3.动态场景:实时跟踪与优化
使用针对语义和几何优化的表示,将GraspSplats扩展到跟踪目标位移并实时编辑高斯Primitives是很自然的。值得注意的是,这种操作对于现有的基于NeRF的方法来说是一个挑战。多视图目标跟踪与关键点。假设有一个或多个已校准的摄像头,且没有以ego为中心的运动。给定一个目标语言查询,我们分割其3D高斯Primitives并将2D掩码渲染到摄像头上。然后,我们将渲染的掩码离散化为一系列点,作为点跟踪器的输入,该跟踪器连续跟踪给定点的2D坐标。使用深度将这些2D对应关系转换为3D,为了过滤掉噪声对应关系,使用简单的DBSCAN聚类算法来过滤掉3D离群点。最后,对于剩余的对应点,使用Kabsch算法求解SE(3)变换,并将其应用于分割后的3D高斯Primitives。对于多个摄像头,将所有摄像头估计的3D对应关系附加到Kabsch算法的方程组中。请注意,位移可以由机械臂或其他外力产生。部分微调,编辑后的场景可能在初始重建过程中未观察到的区域(例如,位移物体下方的表面)出现不希望的伪影。可选地,GraspSplats支持使用位移前后渲染的目标掩码进行部分场景再训练,这比完全重建要高效得多。
实验对比
#PPAD
用于端到端自动驾驶的预测与规划迭代交互
原标题:PPAD: Iterative Interactions of Prediction and Planning for End-to-end Autonomous Driving
论文链接:https://arxiv.org/pdf/2311.08100
代码链接:https://github.com/zlichen/PPAD
作者单位:HKUST DeepRoute.AI
论文思路:
本文提出了一种用于端到端自动驾驶的新型预测与规划的交互机制,称为PPAD(预测与规划迭代交互自动驾驶)。该机制通过逐时间步的交互更好地整合了预测与规划。自车在每个时间步都基于周围代理(如车辆和行人)的轨迹预测及其局部道路状况进行运动规划。与现有的端到端自动驾驶框架不同,PPAD以自回归方式在每个时间步交错进行预测和规划过程,从而建模自车、代理和动态环境之间的交互,而不是简单地依次进行预测和规划的单一顺序过程。具体而言,本文设计了自车与代理、自车与地图、自车与鸟瞰图(BEV)的交互机制,通过层次化动态关键目标注意力来更好地建模这些交互。在nuScenes基准测试上的实验表明,本文的方法优于当前的先进方法。
主要贡献:
本文提出了PPAD,通过迭代的预测与规划方式优化自车、代理和环境之间的交互。迭代优化能够在规划任务中更好、更自然地建模交互和博弈。预测过程处理更细粒度和复杂的未来不确定性,以进行多代理环境的学习,而规划过程则为自车规划一步的未来轨迹。
本文通过层次化动态关键目标注意力,逐步建模自车、代理、环境和BEV特征图之间的细粒度交互,强调空间局部性。
在nuScenes和Argoverse数据集上进行的实验表明,本文的方法在效果上优于当前的先进方法。
论文设计:
深度学习技术的蓬勃发展为自动驾驶提供了强大的支持,得益于便捷且可解释的离散模块设计,自动驾驶领域已经取得了许多令人振奋的重要里程碑。最近,规划导向的理念在追求更高效的端到端驾驶系统方面引起了业界的共鸣,这也是本研究的重点。
传统的自动驾驶系统方法通常将系统分解为模块化组件,包括定位、感知、跟踪、预测、规划和控制,以实现可解释性和可视性。然而,这种方法存在几个缺点:1)随着系统复杂性的增加,模块之间的误差积累变得更加显著。2)下游任务的性能高度依赖于上游模块,这使得构建统一的数据驱动基础设施非常困难。
最近,端到端自动驾驶由于其简洁性而受到广泛关注。基于学习架构,提出了两种主要的方法。第一种方法直接将原始传感器数据作为输入,不经过任何视图转换来作为场景理解的中间表示,直接输出规划轨迹或控制命令。另一种方法基于鸟瞰图(BEV)表示,充分利用查询生成中间输出,以此作为指导来产生规划结果。其最大的优势之一在于可解释性。在这项工作中,本文遵循了第二种方法的设计。
VAD 23 和 UniAD 19 是典型的单步运动规划方法,只考虑了代理、自车与周围环境(如地图元素)之间的单步交互。ThinkTwice 22 将其扩展为一个两阶段框架,以增强博弈或交互过程。QCNet 56 和 GameFormer 21 也重复地建模轨迹预测任务。运动规划作为一个计算问题,需要找到一系列有效轨迹,通常基于周围代理的预测、环境理解以及历史和未来的情境。这也可以被视为一种游戏,其中代理根据其他代理的意图和所遇环境不断规划其下一步行动,通过增量式的动作最终实现其目标。为了在端到端自动驾驶中建模这些预测与规划的动态交互,关键在于通过多步建模来考虑预测轨迹的可能变化,以规划出可行的轨迹。
受VAD 23的启发,本文旨在将逐步的预测与规划引入一个基于学习的框架。直观上,预测和规划模块可以被建模为一个运动预测任务,即通过给定的历史信息预测未来的路径点。每个时间步的预测和规划模块的结果高度依赖于彼此。因此,本文需要迭代和双向地考虑代理与代理、代理与环境之间的交互,以最大化在给定其他代理观测下代理预测的期望。本文提出了PPAD,通过逐步规划自车的未来轨迹,在一个矢量化学习框架中建模逐时间步的双向交互或博弈,如图1所示。PPAD包括预测和规划过程。对于每个运动预测步骤:
- 预测过程通过代理与环境之间的交叉注意力和自注意力生成当前步骤的运动状态,以建模细粒度的双向交互。本文考虑了自车-代理-环境-BEV的交互,以在所有交通参与者之间传播特征。
- 规划过程基于期望过程预测当前步骤的运动轨迹。
图1:本文提出的PPAD框架的高级示意图。蓝色的代理意图直行,而红色的自车计划变道。图1(a)展示了典型的单步方法,由于缺乏深入的交互,可能导致无效的运动规划并引发事故。图1(b)展示了在PPAD架构下自车与代理之间的博弈过程。在预测过程中,代理通过加速执行一个果断的计划,以阻止自车阻挡其路线。自车的规划过程基于代理之前的预测过程来规划轨迹。自车减速以避免潜在事故,然后变道以实现其驾驶目标。
图2:本文提出的自动驾驶框架PPAD的整体架构。它由感知Transformer和迭代预测-规划模块组成。感知Transformer将场景上下文编码为代理查询、地图查询和BEV查询。然后,预测-规划模块交替进行代理运动预测和自车规划的过程N次。在整个迭代的预测和规划过程中,自车、代理、地图元素和BEV特征之间进行深入交互。在预测过程中,代理最初打算直行,并未意识到自车的潜在运动。经过与自车、地图元素和BEV特征的交互后,代理计划果断加速。在随后的规划过程中,自车通过与更新后的代理查询交互,了解到代理将加速。最终,自车计划先减速,然后为安全起见进行变道。
本文在图2中展示了整体框架PPAD,该框架由感知Transformer和本文提出的迭代预测-规划模块组成。感知Transformer将场景上下文编码为BEV特征图,并进一步解码为矢量化的代理和地图表示。迭代预测-规划模块通常包括预测和规划过程,沿时间维度剖析自车与代理之间的动态交互。最终,它预测代理的运动并规划自车的未来轨迹。
图像特征模块使用共享的图像骨干网络(例如,ResNet 15)来提取不同摄像头视角的图像特征。
BEV特征模块将来自多视角摄像头的语义特征转换为统一的鸟瞰图(BEV)。具体而言,本文继承了BEVFormer 29, 47的编码器来构建BEV特征。网格状的可学习BEV查询
矢量化特征模块受到VAD 23范式的启发,本文也通过检测解码头 29, 58 和地图元素解码头 31 将场景上下文编码为矢量化表示,生成 个学习的代理查询 和 个学习的地图查询 。将附加独立的基于MLP的解码器来产生辅助输出,这些解码器以学习到的查询为输入,并预测代理属性(位置、尺寸、类别等)或地图属性(类别和由点描述的地图向量)。此外,代理查询将与可学习的运动嵌入结合,以建模代理的多样化运动。带有运动的代理表示为 。类似地,自车被建模为三种模式,代表高层次的驾驶指令:直行、左转和右转,其形式为 。
迭代预测-规划模块以交错方式预测自车和代理的未来轨迹。与传统的一次性预测所有轨迹的方法不同,本文的PPAD框架通过迭代代理运动预测和自车规划过程来详细说明每一步的运动规划。得益于PPAD框架,本文可以进行深入设计,以粗到细的方式在场景上下文中强化关键目标的交互(见第3.3节)。本文通过将噪声轨迹作为每一步的预测,并训练PPAD框架在下一个时间步重建其原始位置(见第3.4节),进一步提高自车的驾驶性能。
实验结果:
图3:PPAD的定性结果。图中的绿色框表示自车,红色框表示其他代理。
总结:
本文提出了一种新颖的自动驾驶框架PPAD。不同于以往缺乏深入交互建模的方法,本文将规划问题视为自车与代理之间的多步预测与规划博弈过程。通过PPAD架构,本文提出的层次化动态关键目标注意力被纳入其中,以在每一步学习局部和全局场景上下文,最终规划出更精确的轨迹。在训练过程中,采用了置信度感知的碰撞约束和噪声轨迹,以进一步提高驾驶安全性。总体而言,本文提出的新颖PPAD在现有的先进方法上实现了出色的性能,本文希望PPAD框架能激励业界进行更多探索。
#可提示的闭环交通仿真
英伟达新作
摘要
本文介绍了可提示的闭环交通仿真。仿真是安全且高效的自动驾驶开发的基石。仿真系统的核心应该是生成逼真、反应灵敏且可控的交通模式。本文提出了ProSim,这是一种多模态可提示的闭环交通仿真框架。ProSim允许用户给出一组复杂的数值提示、分类提示或者文本提示,以引导每个智能体的行为和意图。然后,ProSim以闭环方式生成交通场景,并且建模每个智能体与其他交通参与者的交互。本文实验表明,ProSim在不同用户提示下实现了较高的提示可控性,同时在Waymo Sim Agents挑战赛(没有给定提示)中达到了具有竞争力的性能。为了支持对可提示交通仿真的研究,本文创建了ProSim-Instruct-520k,这是一种多模态提示-场景配对的驾驶数据集,包含超过520k个现实世界驾驶场景的10M多条文本提示。
主要贡献
本文的贡献为如下三方面:
1)本文引入了ProSim,这是首创的闭环交通仿真框架;
2)本文创建了ProSim-Instruct-520k,这是一种大规模的多模态提示-场景驾驶数据集,它是首个包含丰富语义智能体运动标签和文本说明的驾驶数据集;
3)本文将发布ProSim的代码和检查点以及ProSim-Instruct-520k的数据、基准和标注工具,以促进智能体运动仿真研究。
论文图片和表格
总结
本文提出了ProSim,这是一种多模态可提示的闭环交通仿真框架。在用户给定一组复杂的多模态提示的情况下,ProSim以闭环方式模拟交通场景,同时引导智能体遵循提示。ProSim在不同的复杂用户提示下展现出高度的真实感和可控性。本文还开发了ProSim-Instruct-520k,这是首个多模态提示-场景配对的驾驶数据集,其包含超过520K个场景和10M+条提示。本文相信,ProSim模型和数据集套件将为未来对驾驶场景以内和以外的可提示人类行为仿真进行研究。
局限性:ProSim尚不支持任意的提示。复杂的智能体交互(例如,"<A0>从左车道超车<A1>")或者更为复杂的模态(例如,提示<A0>使用其前视图像)将作为今后的工作。
#自动驾驶3D占用预测(Occupancy Prediction)算法调研
在自动驾驶感知任务中,传统的3D场景理解方法大多数都集中在3D目标检测上,难以描述任意形状和无限类别的真实世界物体。3D占用网络(Occupancy Network)是特斯拉在2022年提出的一种新型感知网络,这种感知网络借鉴了机器人领域中的占用网格建图的思想,将感知环境以一种简单的形式进行在线3D重建。简单来说,就是将机器人周围的空间划分为一系列网格单元,然后定义哪个单元被占用,哪个单元是空闲的,通过预测3D空间中的占用概率来获得一种简单的3D空间表示,这样就可以更全面地实现3D场景感知。
近期对最近几年自动驾驶领域中的3D占用网络算法(主要是基于纯视觉)和数据集做了一些调研,本文将做一个简单的汇总。
- 论文和算法
综述论文
《A Survey on Occupancy Perception for Autonomous Driving: The Information Fusion Perspective》
MonoScene
论文:https://arxiv.org/pdf/2112.00726.pdf
代码:https://github.com/cv-rits/MonoScene
数据集:NYUv2(室内),SemanticKITTI
首个单目3D语义占用预测算法,是后续算法的baseline。
TPVFormer
论文:https://arxiv.org/pdf/2302.07817.pdf
代码:https://github.com/wzzheng/TPVFormer
数据集:SemanticKITTI,Panoptic nuScenes
该算法以环视图像为输入,训练过程中以激光雷达的语义标签为真值去学习实现3D占用预测。作者提出了一种三视角( tri-perspective view,TPV)表示法,能够有效地描述3D场景的细粒度结构。为了将图像特征转换到3D TPV空间,提出了一种基于注意力机制的TPVFormer模型。
SurroundOcc
论文:https://arxiv.org/pdf/2303.09551.pdf
代码:https://github.com/weiyithu/SurroundOcc
数据集:nuScenes,SemanticKITTI
该算法从输入的多个相机的RGB图像中去实现3D语义占用预测,训练时的语义真值是从激光点云的语义信息中产生。
算法流程如下:
根据稀疏的点云语义信息生成稠密的3D占用语义真值过程:
在RTX 3090 GPU上与其他几个算法的推理时间对比:
OccFormer
论文:https://arxiv.org/pdf/2304.05316.pdf
代码:https://github.com/zhangyp15/OccFormer
数据集:SemanticKITTI,Panoptic nuScenes
该算法提出使用一个双路transformer结构用于处理由相机数据生成的3D体素特征,它可以有效地捕获具有局部和全局路径的细粒度细节和场景级布局。
双路transformer结构:
VoxFormer
论文:https://arxiv.org/pdf/2302.12251.pdf
代码:https://github.com/NVlabs/VoxFormer
数据集:SemanticKITTI
算法框架如上图所示,模型支持输入单帧或多帧图像数据。采用MobileStereoNet(可换成其他深度估计网络)做深度估计,占用预测网络采用轻量级的2D CNN网络LMSCNet。该算法的特点是比较轻量级,对小目标的检测效果较好,模型参数较少,训练时需要的GPU显存少于16GB。缺点是远距离性能需要提升,因为远距离深度估计不准确。
OccupancyDETR
论文:https://arxiv.org/pdf/2309.08504.pdf
代码:https://github.com/jypjypjypjyp/OccupancyDETR
数据集:SemanticKITTI
算法框架如上图所示,由一个类似DETR的目标检测网络(Deformable DETR)和3D占用解码器模块组成,用目标检测模块来引导对3D语义占用网格的预测。把目标检测网络输出的bounding box作为位置先验,并利用物体的隐藏特征作为上下文,然后用一个空间transformer解码器用来提取每个目标的3D占用网格。
算法的详细流程如下:
- 对于一张输入图像,首先采用ResNet50骨干网络提取特征,然后将这些多尺度特征传入一个可变形编码器进行进一步编码。
- 通过可变形DETR解码器解码固定数量的查询,然后传递给分类、2D框和3D框这三个检测头网络。分类头和2D框头网络的结果是目标检测中的常规结果,根据分类头的输出选择高置信度的结果作为检测到的物体。
- 这些高置信度物体的3D框(相机坐标系,根据相机外参转到占用网格坐标系)作为每个物体的位置先验,用于在3D占用解码器中提供位置嵌入,并把可变形DETR解码器获得的特征作为上下文,3D占用解码器基于可变形DETR编码器编码的多尺度特征去预测每个物体的3D占用网格。
3D占用解码器的数据流程图如下:
该算法的特点是对小目标的检测性能好,速度快,计算资源消耗少,训练时只需要一个RTX 3090 GPU,缺点是对道路、人行横道这些类别的预测效果不好。
FB-OCC( CVPR 2023 3D占用预测挑战赛冠军)
论文:https://opendrivelab.com/e2ead/AD23Challenge/Track_3_NVOCC.pdf
代码:https://github.com/NVlabs/FB-BEV
数据集:nuScenes
算法框架如上图所示,该算法由FB-BEV算法衍生而来。视图变换模块是纯视觉3D感知算法的核心,作者设计了两个视图变换模型:一个前向投影模块(List-Splat-Shoot)和一个反向投影模块( BEVFormer)。在FB-OCC中,使用前向投影来生成初始的3D体素表示,然后将3D体素表示压缩成一个扁平的BEV特征图。BEV特征图被视为BEV空间内的查询,并与图像编码器特征进行关联,以获取密集的几何信息。最后,将3D体素表示和优化的BEV表示的融合特征输入到后续的任务头中。
除了模型结构,作者还重点对模型预训练技术进行了精心设计。首先在大规模2D目标检测数据集Object 365上对骨干网络进行训练,使得网络具备语义感知能力。接下来,在nuScenes数据集上再对网络进行专注于深度估计的预训练。由于深度预训练缺乏语义级别的监督,为了减轻模型过度偏向深度信息的风险,可能导致丧失语义先验知识(特别是考虑到大规模模型容易出现过拟合的情况),作者同时预测2D语义分割标签以及深度预测任务。
使用2D图像语义标签和深度图真值,作者联合深度估计任务和语义分割任务对模型进行训练。这种预训练任务与最终的占用预测任务密切相关,可以利用深度值和语义标签直接生成3D占用结果。预训练模型作为改进的起点,为后续的占用预测任务训练提供了帮助。
该算法是为参加比赛设计的,所以整体显得有点笨重,训练时设置batch size为32,需要32个A100 GPU进行训练。
BEVDet-Occ
论文:暂无,从BEVDet衍生到Occupancy Prediction任务
代码:https://github.com/HuangJunJie2017/BEVDet
SimpleOccupancy
论文:https://arxiv.org/pdf/2303.10076.pdf
代码:https://github.com/GANWANSHUI/SimpleOccupancy
数据集:DDAD,Nuscenes
该算法采用自监督的方式实现3D占用预测。
SparseOcc
论文:https://arxiv.org/pdf/2312.17118.pdf
代码:https://github.com/MCG-NJU/SparseOcc
数据集:Occ3D-nuScenes
下面两篇文章是对该算法的解读:
https://zhuanlan.zhihu.com/p/709576252
https://zhuanlan.zhihu.com/p/691549750
SelfOcc
论文:https://arxiv.org/pdf/2311.12754.pdf
代码:https://github.com/huang-yh/SelfOcc
项目主页:https://huang-yh.github.io/SelfOcc/
数据集:Occ3D-nuScenes,SemanticKITTI
鉴于之前的方法都需要可靠的3D语义信息来监督学习,但是3D语义真值又很难获取,因此SelfOcc希望仅使用视频序列采用自监督学习的方式来实现3D语义占用预测,以降低模型训练难度。
算法框架如下:
OccNeRF
论文:https://arxiv.org/pdf/2312.09243.pdf
代码:https://github.com/LinShan-Bin/OccNeRF
数据集:Occ3D-nuScenes
该算法采用自监督学习的方式去实现基于多相机数据输入的3D语义占用预测。为了解决无界场景的问题,作者提出参数化占用场,将无限空间缩小到有界体素内;为了利用时间光度损失,作者对参数化坐标进行体素渲染,得到多帧多摄像头深度图。对于语义占用预测,作者采用Grounded-SAM、Grounding DINO来生成2D语义伪标签。
RenderOcc
论文:https://arxiv.org/pdf/2309.09502.pdf
代码:https://github.com/pmj110119/RenderOcc
数据集:nuScenes,SemanticKITTI
该算法从多视图图像中提取NeRF风格的3D体积表示,并使用体积渲染技术来建立2D重建,从而实现从2D语义和深度标签的直接3D监督,减少了对昂贵的3D占用标注的依赖。实验表明,RenderOcc的性能与使用3D标签完全监督的模型相当,突显了这种方法在现实世界应用中的重要性。
算法框架如下图所示:
SGN
论文:https://arxiv.org/pdf/2312.05752.pdf
代码:https://github.com/Jieqianyu/SGN
数据集:SemanticKITTI,SSCBench-KITTI-360
论文提出了一种新型的端到端基于纯视觉的3D占用预测框架,称为Sparse Guidance Network(SGN)。SGN的核心思想是利用几何先验和占用信息,从具有语义和占用意识的种子体素向整个场景扩散语义。与传统方法不同,SGN采用了一种密集-稀疏-密集的设计,并引入了混合引导和有效的体素聚合来加强类内特征的分离和加速语义扩散的收敛。此外,SGN还利用了各向异性卷积来实现灵活的接收场,同时减少计算资源的需求。
FlashOcc
论文:https://arxiv.org/pdf/2311.12058.pdf
代码:https://github.com/Yzichen/FlashOCC
数据集:Occ3D-nuScenes
FlashOcc通过下面两种方法对现有基于体素级3D特征的占用预测任务进行提升:(1) 用2D卷积替换3D卷积; (2) 用通道-高度变换替换从3D卷积得到的占用预测。
FlashOcc专注于以即插即用的方式增强现有模型,它可以分为五个基本模块: (1) 用于提取图像特征的2D图像编码器。(2) 将2D图像特征映射到BEV表征的视图转换模块。(3) 用于提取BEV特征的BEV编码器。(4) 预测每个体素分割标签的占用预测头。(5) 集成历史信息以提高性能的时序融合模块(可选)。
FlashOcc的特点是速度快,计算资源消耗少,方便部署。
POP3D
论文:https://openreview.net/pdf?id=eBXM62SqKY
代码:https://github.com/vobecant/POP3D
FastOcc
论文:https://arxiv.org/pdf/2403.02710.pdf
代码:暂未开源(不开源就挺尴尬的)
数据集:Occ3D-nuScenes
Co-Occ
论文:https://arxiv.org/pdf/2404.04561.pdf
代码:https://github.com/Rorisis/Co-Occ
项目主页:https://rorisis.github.io/Co-Occ_project-page/
数据集:SemanticKITTI、NuScenes
该论文提出一种基于激光-相机数据的多模态3D占用预测算法,算法框架如下:
OccGen
论文:https://arxiv.org/pdf/2404.15014.pdf
代码:(coming soon)
项目主页:https://occgen-ad.github.io/
该论文提出一种noise-to-occupancy的生成式3D占用预测算法。
Cam4DOcc
论文:https://arxiv.org/pdf/2311.17663
代码:https://github.com/haomo-ai/Cam4DOcc
数据集:NuScenes、Lyft
MonoOcc
论文:https://arxiv.org/pdf/2403.08766v1
代码:https://github.com/ucaszyp/MonoOcc
数据集:SemanticKITTI
该论文提出一个单目3D占用预测算法框架,通过一个辅助语义损失作为对框架浅层的监督和一个图像条件交叉注意力模块来改进单目占用预测的效果,另外该算法训练的时候采用蒸馏模块,以低成本将时间信息和更丰富的知识从较大的图像主干网络传输到单目语义占用预测框架中。
HyDRa
论文:https://arxiv.org/pdf/2403.07746
代码:https://github.com/phi-wol/hydra
该论文提出一种基于相机和毫米波雷达的多模态3D感知框架,实现3D目标检测、语义占用预测多任务感知。
PanoOcc
论文:https://arxiv.org/pdf/2306.10013
代码:https://github.com/Robertwyq/PanoOcc
现有的自动驾驶感知任务(如目标检测、道路结构分割、深度估计等)仅关注整体3D场景理解任务的一小部分。这种分治的策略简化了算法开发过程,但却失去了问题的端到端统一解决方案。在本文中,作者通过基于纯视觉的3D全景分割来解决这一限制,旨在实现仅限摄像头的3D场景理解的统一占用表示。为了实现这一目标,作者提出一种名为PanoOcc的新方法,它利用体素查询以由粗到细的方案从多帧和多视角图像中聚合时空信息,将特征学习和场景表示集成到统一的占用表示中。PanoOcc在nuScenes数据集上实现了基于摄像头的语义分割和全景分割的全新最佳结果。此外,该方法还可以轻松扩展到密集占用预测任务中,并在Occ3D基准上表现出色。
GaussianFormer
论文:https://arxiv.org/abs/2405.17429
代码:https://github.com/huang-yh/GaussianFormer (暂时只放出demo)
ViewFormer
论文:https://arxiv.org/pdf/2405.04299
代码:https://github.com/ViewFormerOcc/ViewFormer-Occ
作者还开源了一个可视化工具,可以对点云目标检测、Occ预测结果等进行可视化:https://github.com/xiaoqiang-cheng/Oviz
HTCL
论文:https://arxiv.org/pdf/2407.02077
代码:https://github.com/Arlo0o/HTCL
Panoptic-FlashOcc
论文:https://arxiv.org/pdf/2406.10527v1
代码:https://github.com/Yzichen/FlashOCC
Panoptic-FlashOcc是目前速度和精度最优的全景占用预测网络,它在FlashOcc的基础上实现了全景占用(Panoptic occupancy)。全景占用旨在将实例占用(instance occupancy)和语义占用(semantic occupancy)整合到统一的框架中。
作者解读:https://zhuanlan.zhihu.com/p/709393871
COTR
论文:https://arxiv.org/pdf/2312.01919
代码:https://github.com/NotACracker/COTR.git
- 数据集
SemanticKITTI
论文:https://arxiv.org/pdf/1904.01416v3.pdf
下载地址:https://opendatalab.com/OpenDataLab/SemanticKITTI
Occ3D
论文:https://arxiv.org/pdf/2304.14365.pdf
下载地址:https://tsinghua-mars-lab.github.io/Occ3D/
该数据集基于Waymo和nuScenes数据集构建了用于3D占用网格预测的数据集Occ3D-Waymo和Occ3D-nuScenes。
OpenOccupancy
论文:https://arxiv.org/pdf/2303.03991.pdf
GitHub:https://github.com/JeffWang987/OpenOccupancy
该数据集基于nuScenes数据集构建。
OpenOcc
论文:https://arxiv.org/pdf/2306.02851.pdf
GitHub:https://github.com/OpenDriveLab/OccNet
该数据集基于nuScenes数据集构建。
SSCBench
论文:https://arxiv.org/pdf/2306.09001.pdf
GitHub:https://github.com/ai4ce/SSCBench
该数据集基于KITTI-360、 nuScenes、Waymo等数据集构建。
OpenScene
GitHub:https://github.com/OpenDriveLab/OpenScene
相比现有数据集,OpenScene具有Occupancy Flow标签:
LightwheelOcc
GitHub: https://github.com/OpenDriveLab/LightwheelOcc
这是一个合成数据集。
- 参考资料
- https://www.thinkautonomous.ai/blog/occupancy-networks/
- https://github.com/chaytonmin/Awesome-Occupancy-Prediction-Autonomous-Driving
- https://github.com/keithAND2020/awesome-Occupancy-research
- https://github.com/zya3d/Awesome-3D-Occupancy-Prediction
- https://bbs.xiaopeng.com/article/1777353
- https://zhuanlan.zhihu.com/p/675424447
- https://www.zhihu.com/question/629557685
- https://zhuanlan.zhihu.com/p/678276259
#奥迪再放大招
跻身智驾顶流?
在国家大力支持以旧换新、以及重磅新车的密集上市之下,今年的"金九银十",似乎比往年来得更持久一些。
即将开幕的广州车展作为国补的"末班车",吸引了不少用户的关注。上百个汽车品牌也带来了多达1171台展车,其中还有78台全球首发车型,可见车企们的重视程度。

就在这个节骨眼上,社长嗅到了一个非同寻常的信号:奥迪Q6L e-tron以及即将在广州车展首发的奥迪Q6L Sportback e-tron,很可能搭载华为深度定制的智驾解决方案!
从官方"双激光雷达+视觉融合感知,实现'无图'L2++级智能驾驶辅助能力"的表述、以及实车的传感器来看,大概率是华为的ADS方案。
那么,为什么奥迪这家百年传统品牌会找到华为合作智驾?如此有噱头的话题,双方为什么又有些"遮遮掩掩、秘而不宣"?
这件事,还要从30多年前说起。
- 奥迪的"在中国、为中国"
1986年4月份,国内开始要把汽车制造业作为支柱产业。
但在当时的时代背景下,外资品牌势必会对羸弱的本土汽车企业形成降维打击。
壮士断腕地停产中国品牌,通过合资的方式吸收国外的先进技术,成了当时的唯一解。
同年,奥迪从千里之外的德国来到长春,和一汽就奥迪100项目进行研究与谈判。
尽管在德国人眼里,80年代的长春实在有些荒凉。但时任大众汽车董事长的哈恩博士很快意识到,这里有着良好的汽车工业根基,也将会是奥迪进入中国发展的绝佳契机。
为此,奥迪不仅以1000万马克的低价转让了奥迪100生产线,如果双方后续能够继续合作生产高尔夫和捷达,还能再免除1900万元的技术转让费!
甚至奥迪还主动请缨,把一汽已经引进的克莱斯勒488发动机匹配到了奥迪100的车身上,只为了给合作伙伴再省一笔发动机的费用。
随着一系列"诚意换真心"的操作,双方正式开始了长达36年、且依然在延续的甜蜜期。
但有意思的是,和其他合资品牌不同,一汽和奥迪并不是"以市场换技术"的交易关系,而是更像一对并肩作战的朋友。
最能说明奥迪"在中国、为中国"的,是1996年1月份和中方签署的一份奥迪A6(C5)联合研发协议。
研发的核心,正是中方为了满足中国用户对后排腿部空间的需求,所提出的加长。
虽然奥迪方面认为,A6作为大众集团唯一的行政级轿车空间完全够用,但依然对中国用户的需求表达了理解和尊重。
最终历时3年,国产A6相比全球车型实打实地加长了90mm轴距,但造型和性能并没有受到太多影响。收获市场认可的同时,也开创了豪华品牌为中国用户定制车型的先河。
时至今日,加长已经不再是稀罕事。但当时第一批开上新车的车主们,或许很难想象20多年后的中国已经成为首屈一指的汽车大国,产销出口量均已位列全球第一。
这不仅要归功于外资品牌的支持和几代中国汽车人的努力,还有科技时代的悄然来临。
- 科技大佬,强强联手?
相信有不少小伙伴已经发现了,这几个月新能源渗透率正式突破50%,成了多数人的选择。
但很多人不知道的是,去年L2级智驾的渗透率就已经达到了47.3%,已经下放到了几万块钱的车上;智能互联功能,更是在某些"老旧燃油车"上成了标配!
而到了高端电动车领域,车企们为了给用户提供安全便捷的用车体验,也在高阶智驾领域展开了新一轮的军备竞赛。
这时,大家第一个想到的肯定是在技术上较为领先,表现也最突出的华为了。
在今年大火的端到端算法装车之前,车企们普遍采用的是"规则型"算法。就有点像是解方程,只需要输入数据和规则,就能得出答案。比的就是谁的规则更细致,计算过程更快。
这一阶段,华为的优势在于"让车辆具有上帝视角"的BEV鸟瞰视图,和GOD异形障碍物识别。遇到人类很难反应过来的紧急情况,依然能高效地触发AEB,避免事故发生。
但正因为算法需要完全遵守规则,当遇到不那么规则的路况、比如前方出现障碍车辆、非机动车抢道的时候,规则型算法就有些无能为力了。
端到端算法,刚好能解决这个问题。它的工作原理有些像chatGPT,通过大量的人类司机驾驶视频来训练,试图理解发生了什么、应该如何判断,又应该如何操控车辆。
所以现在华为的智驾,已经能在适应规则的基础之上,开起来和老司机一样丝滑了。
而从奥迪官方公布的信息来看,奥迪Q6L e-tron家族的自适应巡航辅助 Pro 和泊车辅助 Pro,能够拥有道路结构理解、交通规则认知、行车轨迹的精细规控和拟人的决策能力这四项能力。
并且从网上流出的素材来看,遇到障碍物和障碍车辆不会再傻乎乎地等到天荒地老,而是能够绕行;在导航的配合下,也能选择合适的车道通过交叉路口和环岛;甚至能学会在满足交通规则、不影响后车行驶的前提下,完成加速超车变道!
更简单的高速领航辅助、从停车场入口到停车位的全程自动泊入泊出、以及加减速转弯更加丝滑这些"相对基础"的功能,也同样不在话下。
(图片来源网络。但看到这里,怎么感觉这套智驾华里华气的)
不过为了实现这些,奥迪还为这台车打造了"满血版"的硬件方案------
双激光雷达+5个毫米波雷达+11个高清摄像头+12个超声波雷达的硬件,规格甚至比智界R7和问界M9还高,能带来宽阔的视角和精准的识别能力。
嵌入式激光雷达的设计,让车顶不再"长犄角",也同时满足了设计美学和功能性的统一。
或许只有奥迪+华为的组合,才能把这套顶级硬件发挥到极致,做到类人的智驾体验。
那么,到底奥迪为什么要上这么高阶的智驾?
社长倒是觉得,原因或许写在这句耳熟能详的广告语里:突破科技,启迪未来。
(奥迪德国官网上的品牌标签,翻译过来也是"领先优势源于技术")
纵观奥迪的百年发展史,无论是标志性的quattro四驱系统、LED大灯/流水式尾灯/矩阵式大灯、全铝车身乃至智能座舱,安全和舒适都是奥迪不懈的追求。
这种对新技术的渴望与驾乘体验的考虑,或许正是奥迪采用高阶智驾的根本原因。
- 奥迪的智能化时代
然而只有对技术的渴望,还远远不够。就像当年奥迪100能够兼容克莱斯勒488发动机一样,新车的电子电气架构和整车平台,在技术能力上必须能兼容高阶智驾才行。
这时,奥迪对大众集团的资源整合能力,就立了大功。
就比如奥迪Q6L e-tron家族的全新域控E³ 1.2电子电气架构,就是由Cariad负责开发的。
它的"高性能计算平台"HCP采用了5台高性能计算机,分管驱动系统和悬架、智驾系统、座舱的信息和娱乐功能、灯光/空调/座椅等舒适功能、以及联网/数据传输这5个部分,共同构成了全新域控E³ 1.2电子电气架构的中枢神经系统。
因此只需要为负责智驾的HCP2注入代码,对负责驱动的HCP1进行控制,就能无缝衔接全新的智驾功能,未来可以通过OTA进行升级,并且这个架构5年内仍将是第一梯队。
Q6L e-tron家族能够实现"类似人类老司机"的丝滑智驾体验,也离不开奥迪对驱动和电气系统的研发和标定。
举个例子,在其他车辆强行加塞的时候,有些智驾会一脚急刹闷在那,不仅体验不好,也会因为机械刹车介入无法回收能量,变相提升能耗;
但Q6L e-tron家族的全域动能回收能提供220kW的回收功率,覆盖95%的日常工况,甚至是ABS触发后都能回收。提升制动力的同时,也能带来更长的续航。
在起步和刹停的时候,它前后轴之间的动力输出、动能回收和传统机械刹车之间的切换都是由中央车辆动力学域控制器分配的,能够完美执行智驾系统的操作指令,体感上会更舒适。
再加上奥迪和保时捷联合研发的高端纯电平台-PPE平台,保时捷负责开发的车身和悬架,奥迪负责开发的驱动系统和电气系统,Cariad负责开发的整车软件和电子架构,这才有了集百家之所长、机械和智能双优的奥迪Q6L e-tron家族。
- 写在最后
在不久的将来,车企和科技公司的跨领域合作,很可能会成为新的趋势。这种各取所长的合作方案,必然会为用户带来更加出色的用车体验。
至于这次合作为什么迟迟没有官宣,社长觉得主要有三种可能性。
首先,一汽奥迪的风格更像是踏实做产品,而不是凭营销出圈。没有试驾车可以给用户深度体验之前,不会大肆进行宣传报道。
其次,双方在汽车行业中的地位和影响力并不需要谁蹭谁的流量,"低调行事"才是最优解。
最后还有一种可能,从一汽奥迪的动作来看,智驾体验有可能会带来新的惊喜,也许在等一个合适的契机引爆"王炸事件"。
就是不知道一汽奥迪会不会放下百年品牌的身段,和华为一同举办一场"遥遥领先"的发布会了
