事务槽(不同于事务表里面的槽位(这个事务槽在数据块的头部))

图解:
一个事务开始,要做的事情:
第一,事务表里面找槽位(undo段的段头块里有事务表,事务表有槽位,每一个槽位记录一个事务);
事务表里的槽位里记录的信息有:
1、xid(事务ID):(undo段的段号,段里面的第几个槽(槽号),覆盖数);
2、cflag(commit flag):提交标志;
3、SCN号(提交SCN号);
4、dba(数据块地址):指向事务使用的最后一个块;
第二,做DML操作,要修改某个数据块里面的一个数据行,在修改数据行以前,oracle会做一件事情:对于普通数据块来讲,在数据块的头部默认有两个事务槽,最多可以有255个。
事务槽里面含有的信息:
1、xid;
2、uba(undo block adress):undo块地址;
3、提交标志;
4、SCN号;
事务开始了,要修改数据块,必须先获取到数据块里面的事务槽;假设0号事务槽里面没有未提交事务(就是没有active事务槽的时候),这个事务槽就可以被覆盖;要修改多行数据的时候,用一个事务槽就可以了;然后将事务信息写入事务槽;
现在要修改数据行了,会在数据行的头部写入一个数字(比如:0(事务槽的槽号)),表示在数据行上加了一个锁(也就是说这个数据行正在被0号事务槽里面所对应的事务修改),然后指向0号事务槽,然后事务槽里面的xid指向这个事务的事务源;同一个事务可以修改数据块里面的多行数据(这里修改了3行数据),都指向了同一个事务;另外还修改了另外一个数据块,然后也指向同一个事务源(一个事务可以同时修改多个数据块);
关于事务的提交标志,在很多地方有,比如:在每一个数据块的事务槽里面有提交标志,在事务表里面的槽位里面有提交标志,并且都有SCN号;
现在描述一个场景:
假设,一个事务修改了100W个块,然后要commit提交;要提交的时候oracle会做几件事情:
1、清锁:需要把100W个块里面的每个数据行前面的锁标记清除了;
2、清理数据块的事务槽:就是把事务槽里面的信息清除了;
这两个清理的会很慢(非常消耗资源),因为涉及到100W个块;
3、清理undo段里面的事务表;
这个清理的比较快(不消耗资源);
用户提交的时候,希望马上提交成功,但是提交的时候第一和第二件事情很慢,很消耗资源,所以oracle在提交的时候,只清除事务表里面的信息(这个是必须要做的事情),记下提交时候的SCN号,然后第一和第二件事情oracle也会尽量的去做一些(比如,现在是100W个块,然后呢,只修改1000个块),意思意思;
事务表里面的清了,数据块里面的事务槽还没有清理完,然后oracle下次再访问块的时候,假设读到之前修改的一行数据时,发现上面有锁标记,表示上面有活动的事务,然后找事务槽里面的事务,显示事务没有提交,这时候再到事务表里面找对应的事务,但是已经显示提交了,oracle就知道当时提交的时候,数据块里的事务槽没清理,所以oracle下次再访问块的时候就顺便清了,把锁标记清了,事务槽里面的信息清了,清理完之后就接着访问
快速提交
所以,只要事务表里面的信息清了,数据块里面的信息有没有清没关系;oracle里,在提交的时候,把事务表里面的信息清了,其他的地方意思意思的清理一下,这种提交机制叫做:快速提交
延迟块清除
然后呢,再读到那个块的时候,顺便清了,然后修改数据块,修改数据块就要修改锁标记,也要修改事务槽里面的提交标记(修改为未提交),还有修改SCN号(改为null),修改的时候就会产生redo,这种情况叫做:延迟块清除
有这么一种情况:就是事务提交的时候,提交了以后,因为数据库的压力比较大,只清除了事务表里面的信息,其他的都没有清除;假设这时候,事务表里面的槽位是:5号段,2号槽位,第100次被覆盖,因为这个事务提交了,这时候就被覆盖了,就变成了:5号段,2号槽位,第101次被覆盖;然后数据块里面的事务槽因为没有清除,记录的还是:5号段,2号槽位,第100次被覆盖,这时候就去找,但是在undo事务表里面已经是:5号段,2号槽位,第101次被覆盖了,oracle就认为已经提交了,这时候接着就清除锁和事务槽,更改SCN号,更改提交状态,
快速提交和延迟块清除,都是为了提高提交的速度
构造CR块(consistent read)(读一致性)

图解:
一个undo段,假设里面有三个事务(T1、T2、T3),然后修改数据块里面的一行数据,修改数据之前,要把修改之前的数据放到undo里面事务T1对应的undo块里,修改前的值是1,修改后的值是2;
然后,select要访问这个数据块的这个数据行,oracle访问的时候,发现这个块上有事务槽,显示事务没有提交,然后oracle就根据xid找undue段里面的事务表对应的事务,看看这个事务是否已经提交,然后发现这个事务确实没有提交;
假设现在对于sp1来说,要读这个数据块,但是在这个数据块上sp2在修改并且还没有提交,这时候sp1是不能读未提交事务的,也就是说,对于任何的会话,任何的server process都是不能读未提交事务的;
这时候oracle会在buffer cache里面再找一个空块,把sp1正在修改的数据块里面所有行的数据取出来放到这个空块里,因为里面有一行有未提交事务,它就找事务槽的uba地址,然后找到undo数据,把修改前的数据取出来,还原事务修改前的值,再放到空块里面去,这就构造了一个块出来,这个块叫做:构造CR块
所以在oracle数据库里面,DML不阻塞select,也就是:修改不阻塞读;就是当oracle访问数据行的时候,去事务槽和undo事务表确认事务是否提交,未提交会在buffer中找到一个空块,找到undo中的源数据,构建一个CR,所以修改数据行的时候不会堵塞读。只读已提交事务,不读未提交事务。
崩溃恢复

图解:
数据库正在正常的运行着,一个undo段,里面有三两个事务(T1、T2、T3),T1对应修改三个块,T2修改了两个块;T1未提交,T2提交了;
这时候数据库突然崩了,数据库重新启动,重启以后呢,select要读T2事务对应的一个块,这个块是延迟块清除,然后显示T2这个事务没有提交,,然后去undo事务表的槽位发现事务已经提交,oracle知道该事务已经提交,马上清除锁和事务槽,更改SCN号,更改提交状态,然后直接读这个块;
读完以后,接着要读T1事务对应的一个块,发现T1事务之前没有提交,然后访问undo段的事务表里面的事务槽发现未提交,但是T1所对应的那个会话已经断开了,不存在了,因为数据库崩了,会话也都断开了,T1就不可能提交和回滚了,这时候select会帮助T1做一下回滚,强求回滚,然后T1这个事务就没了;
所以数据库突然崩了,数据库重新启动,在数据库突然崩的那一瞬间有很多的未提交事务,重启以后呢,这些事务不可能回来了,也不可能再提交,再回滚了,但是undo里面有undo数据在,这时候,select谁读到相应块的时候,就会把这个事务往前回滚一下,读的时候回滚一下,作为恢复的一个操作
访问以往事务修改过的数据块的数据

图解:
一个undo段,里面有一个事务T1,修改了一个数据块,然后T1提交了,还有一个事务T2,T2也要修改同样的数据块,因为事务槽所对应的事务T1已经提交,事务T2就可以覆盖事务T1在数据块中所对应的事务槽,要覆盖事务槽就要修改事务槽中的数据,就会产生undo,对于数据块来讲,修改任何数据都会产生undo;因为T2要覆盖事务槽就要修改数据,就要把事务槽里面的数据拿出来放到undo段的一个块里,然后新的事务槽的xid指向事务T2了,这时候T2也提交了;
我们就来找,找这个数据块数据修改的历史,对于这个数据块来说,被事务T1修改过,也被事务T2修改过,现在我们能看到事务T2修改后的数据,这时候,我们也可以看到事务T1修改过的数据,从T2往前推就可以找到T1修改前的数据;有T3,T4.....也是如此
假设数据库建立以后undo表空间足够大,没有边界的大;对于数据块来讲,数据库可以找到所有的数据块的修改信息,就是一个数据块被多个事务修改了
如果现在将undo returntion设置为:24小时,然后将表空间设置为:gurantee属性;也就是这个表空间一直存储24个小时的数据,那么可以访问24小时之内表的每个时刻的数据;
select * from t; 访问现在的数据;
select * from t as time of 13:30:01;访问13:30:01时修改过的所有数据块的数据
ORA-01555错误
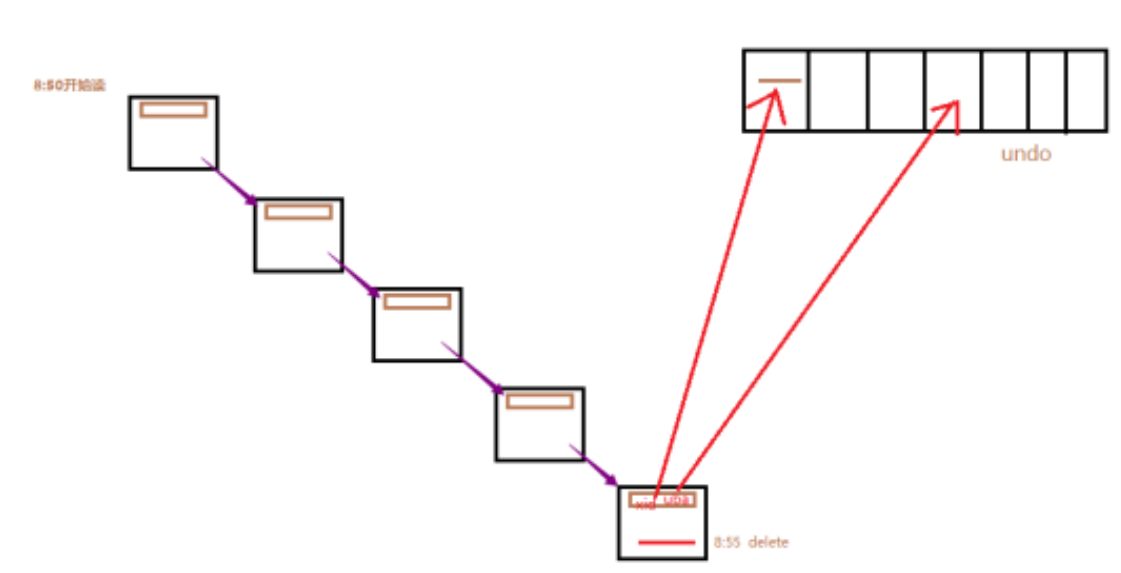
图解:
比如,现在oracle有一个t表,t表比较大,下面有很多很多块;在8:50访问t表,在8:55的时候有一个事务修改了一个数据块,数据块里面的SCN被修改为8:55,然后提交了;
假设9:00的时候读到最后一个数据块的最后一行,但是8:55删除了一行数据;假设t表有一万行,8:00的时候开始读,到9:00的时候会读到多少行数据?
读取了一万行;
因为对于select来讲,读到最后一行数据时,这行数据对应的事务已经提交了,按道理,这一行上没有未提交事务,删除数据已经提交了,不能被读,但是还是读到了10000行数据。oracle在读select开始的时候,记住当时时间点所有数据块的SCN号:850,oracle做了一个假设,并且假设成立:就是将要访问的表在8:50这个时刻,所对应的所有数据块的事务槽,它们的SCN号都应该小于等于900,突然让时间停止,将所有数据块读一遍。当读到最后一个块的时候,发现SCN号是:855,然后找最后一条数据之前的数据,通过undo构建CR块,找出该行数据SCN号为:850时的数据;
在8:57的时候,8:55的undo块被覆盖了。导致8:50的select读数据的时候,去undo块中找,发现数据没了,无法构建CR块,oracle就会报出ora-01555错误,报出ora-01555错误的因为:snapshot too old(快照太旧)或者select读取的时间过长
导致ora-01555错误的原因:
可能是snapshot too old(快照太旧)或者select的执行时间太长,还有就是undo空间压力很大,undo数据被快速覆盖;该错误,会指定哪个SQL引起的问题
select访问的是生产表,触发ora-01555这个错误,原因可能是undo空间太小;
select访问的是字典表,oracle做ddl的时候,向系统表空间的数据字典做insert操作,会将修改信息写到系统表空间的undo段中专门给字典表做回滚;
所以访问的是字典表的时候,发生01555错误是系统表空间的undo段引起的,很可能是一个bug,mos中查找。
回滚
回滚的本质:
对某个表做delete的时候,忘了加where条件,然后删;假设这个表有1000万行,删除了30分钟还没结束,这时候这个过程产生了大量的undo数据;
然后后悔了,想结束这个事务,就是将窗口叉掉,然后刚才做的这个事务需要回滚;回滚的时候,oracle会读undo,将这30分钟删除的数据找出来,然后对表进行insert操作,这时候也会产生redo,但是这个可能需要花费60分钟;当然,如果不叉掉接着执行,可能再过2分钟就执行完了,或者回滚需要90分钟,这些都是有可能的;
因为误删了,必须回滚。假设操作是正常操作,表已经删除了20分钟,还未结束。很长时间不能访问这个表,因为在表上加了很多锁。想结束这个事务,这个事务就需要回滚,回滚可能需要更长的时间。在数据库中用SQL可以查某个事务还有多少时间结束。
几个操作所占用的undo和redo的情况:
insert操作主要消耗redo资源; delete操作主要消耗undo资源; update操作消耗redo和undo操作;
注意:对于oracle来说,DML主要消耗redo和undo资源
这两个资源需要注意:
假设有一个表T,有一个id列,现在想将表中的id列删除了:
做的第一件事,将T表用排他锁锁住,任何人不能访问这个表;
第二,将表里所有的块,假设有100万个块,里面id列的数据,全部删除,所有的块都是扫描一遍,删除一遍;
第三,执行的话,T表中所有的数据都要进行操作,产生大量的redo和undo;
第四,执行的时间太长;假如执行时间很长,生产扛不住了,叉掉窗口,这个事务就需要回滚,这时候可能需要更长的时间,这个表只能废掉了;
但是在表里面加一个不加默认值的列,一下子就完成了。只会在数据字典里面添加列。但是添加一个列的时候,设置了默认值,这个操作和删除一个列数据库进行的操作一样,同样危险。