首发地址(欢迎大家访问) :如何使用AWS Lambda构建一个云端工具(超详细)
1 前言
1.1 无服务器架构
无服务器架构(Serverless Computing)是一种云计算服务模型,它允许开发者构建和运行应用程序而无需直接管理底层服务器或基础设施。开发者无需显式地管理服务器。也就是不再需要担心服务器的配置、扩展或维护。相反,云服务提供商会为替你处理这些底层基础设施,你只需专注于编写代码。
Gartner最近的一份报告表明,到2020年,全球将有20%的企业部署无服务器架构。
这说明无服务器架构不只是一个流行语,而是一种众所周知的云计算趋势,并且已经在软件世界掀起一场革命。大型厂商(如亚马逊)已经在无服务器架构领域重资投入,追赶革命的浪潮[1](#1)。
无服务器架构主要的两种类型:
FaaS(Functions as a Service):
- 将代码拆分成一个个独立的函数。
- 每个函数都是一个无状态的、短暂的执行单元。
- 函数只在有请求时才被触发执行,执行完毕后即被销毁。
- 典型应用场景: API网关后端、数据处理、事件驱动架构。
BaaS(Backend as a Service):
- 提供一组预构建的后端服务,如数据库、身份验证、推送通知等。
- 开发者可以通过 API 调用这些服务,而无需自己搭建后端。
- 典型应用场景: 移动应用后端、Web应用后端。
无服务器架构的优势:
成本效益高:
- 按需付费,只为使用的资源付费。
- 自动扩展,根据负载动态调整资源。
开发效率高:
- 无需管理服务器,专注于业务逻辑。
- 快速部署和迭代。
高可用性:
- 云服务提供商负责基础设施的可靠性。
弹性扩展:
- 自动应对流量峰值。
无服务器架构的高效、高可用特性属实很吸引我,我一直想弄一个在线的 Python 工具集;当然现在也都只是个想法,大概就是用 Python 写一些NLP工具、随机接口(随机 图片、随机一言等)或者其他任何相关的工具;
之前一直在苦恼没有硬件资源的支持,但如果用无服务器架构来实践的话,应该会有不错的效果;
1.2 本文目标
本文的目标比较简单,就是利用
无服务器架构写一个随机图片的接口以及一个jieba分词的接口;能够在客户端调用,目标效果如下:
2 关于Amazon Lambda
2.1 简介
Amazon Lambda是亚马逊云科技提供的核心服务之一,也是典型的无服务器架构服务;使用 Lambda,基本就可以只管我们的代码了;Lambda 管理提供内存、CPU、网络和其他资源均衡的计算机群,以运行代码。
而且Amazon Lambda是有免费额度的,对于我个人或者说我这小流量网站来讲,免费额度就很吸引人;
所以本文的主要目标就需要结合它来实现了;
详细的介绍及特性描述参考官方文档:什么是 Amazon Lambda?
除了Amazon Lambda,亚马逊云科技还提供了很多其他的免费云产品,了解详情可以访问:亚马逊云科技
2.2 定价
Amazon Lambda是通过运行时间和请求数量来计费的,同时亚马逊云科技提供了一定的免费使用额度;

免费额度包括:每月 1000000 次免费请求和每月 40 万 GB-秒或 320 万秒的计算时间;
这个 GB-秒 其实就是计算时间和内存结合的度量单位,假设你分配了 1 GB 内存给你的Lambda函数,然后这个函数运行了 1 秒,那么你运行一次,就花了 1 GB-秒;
那么这个 320 万秒的时间,也就是你函数最长的运行时间,假如你函数分配的内存是 100 MB ,那么你运行 320 万秒其实才花 31 万多 GB-秒;即使没超过40 万 GB-秒,也超出了免费套餐;
但是这个额度,对于个人或者小需求的用户来讲,已经非常的宽裕了;
你也可以通过Amazon Lambda 定价计算器估算你的需求:
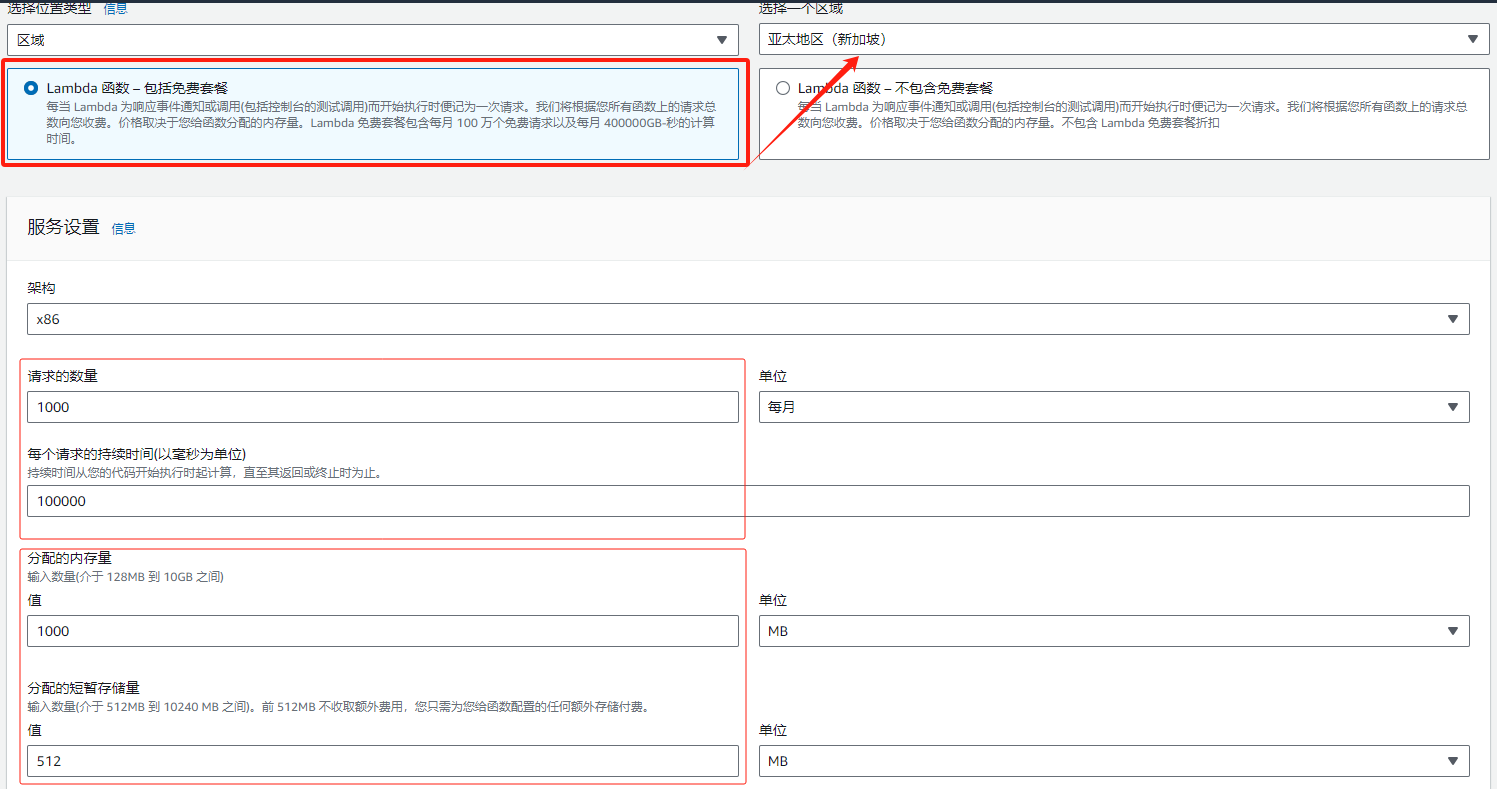
计算的项目是很详细的:

3 逻辑梳理
3.1 关键概念
在使用之前需要了解一些关键的概念,不然的话,后面的东西可能也是云里雾里的;
官方文档:了解关键的 Lambda 概念
简单总结一下:
函数(Function):Lambda 函数是用户上传的业务逻辑代码,可响应触发器执行,代码文件被称为部署程序包。
触发器(Trigger):触发器是 Lambda 执行的起点,定义 Lambda 被调用的事件源。事件源可以是 HTTP 请求(通过 API Gateway)、S3 存储事件、DynamoDB 数据变化等。
事件(Event):触发 Lambda 的具体数据。Lambda 在被调用时会获取事件数据,并将其作为输入传递给函数。
执行环境(Execution Environment):Lambda 的隔离运行环境,包含 OS、运行时、层等组件。每次触发,Lambda 会为每个函数实例创建隔离环境。
部署程序包(Deployment Package):用户上传的代码及其依赖项,以 ZIP 文件或容器镜像格式存储在 Lambda。
运行时(Runtime):Lambda 支持的编程语言环境(如 Python、Node.js),提供函数代码执行所需的语言依赖及生命周期管理。
层(Layer):用于将共享的代码库或依赖分离出来,以便不同 Lambda 函数共用。
并发(Concurrency):每个函数的并发执行次数。Lambda 自动扩展并发处理请求,但可以为函数设定最大并发数。
Qualifier:Lambda 函数的版本或别名,可在部署过程中创建,以支持不同的代码版本管理。
目标位置(Destination):Lambda 可以将执行的结果或错误消息发送到目标服务,如 SNS、SQS 或 EventBridge。
3.2 逻辑流程
以下是 Amazon Lambda 的逻辑架构图,展示了 Lambda 的执行流程,包含触发器、事件、执行环境及目标位置等关键组件:

触发阶段:
- 触发器引发事件(如 HTTP 请求、S3 文件更新),触发器向 Lambda 提供事件数据作为输入。
执行环境准备:
- Lambda 会为函数创建一个隔离的执行环境,包括初始化层、运行时及共享资源(如第三方依赖)。
代码部署和执行:
- Lambda 部署程序包进入执行环境,运行时加载程序包中的代码并开始执行。
- 函数代码通过层加载共用依赖,并通过运行时执行代码逻辑。
并发和伸缩管理:
- Lambda 会自动扩展处理多个并发请求,同时通过并发限制管理资源使用。
返回结果至目标位置:
- Lambda 执行结束后,返回结果或错误信息,并将结果发送至指定的目标位置(如 SNS、SQS)。
版本控制:
- Lambda 允许创建不同版本或别名(Qualifier),支持多版本的分发和管理,方便代码变更追踪和灰度发布。
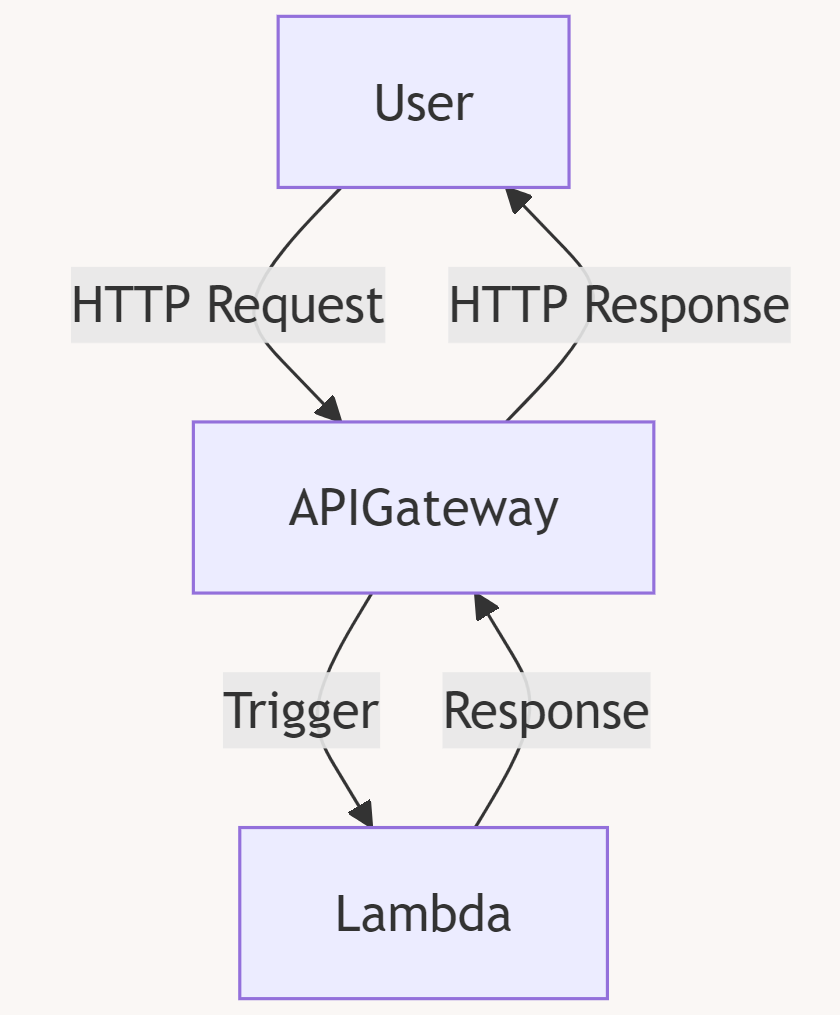
3.3 本文案例流程架构
通过上面的梳理,我们基本确定,要使用Amazon Lambda的话,一定需要一个触发器来触发对应的函数;
我们本次的目标是弄一个API的服务,所以我们需要使用亚马逊云科技的另外一个服务 Amazon API Gateway 来作为触发器;
- Amazon API Gateway 简介
Amazon API Gateway 是一项亚马逊云科技服务,用于创建、发布、维护、监控和保护任意规模的 REST、HTTP 和 WebSocket API。API 开发人员可以创建能够访问 Amazon 或其他 Web 服务以及存储在 Amazon 云中的数据的 API。
Amazon API Gateway也是可以免费试用的:
我这里不做它过多的介绍,后续有机会的话,可以再详细的研究一下,可以查看官方文档了解更多;
它在这个案例中主要的作用就是来触发函数并提供 api 接口,由 Lambda 提供主要计算逻辑;
那么我们案例的流程架构如下:
4 开始实践
4.1 前置条件
- 你需要有一个亚马逊云科技的账户,如果没有注册的话,可以进入 亚马逊云科技 官网了解更多免费服务并注册;
4.2 创建一个 Lambda 函数
进入控制台后,选择Lambda服务
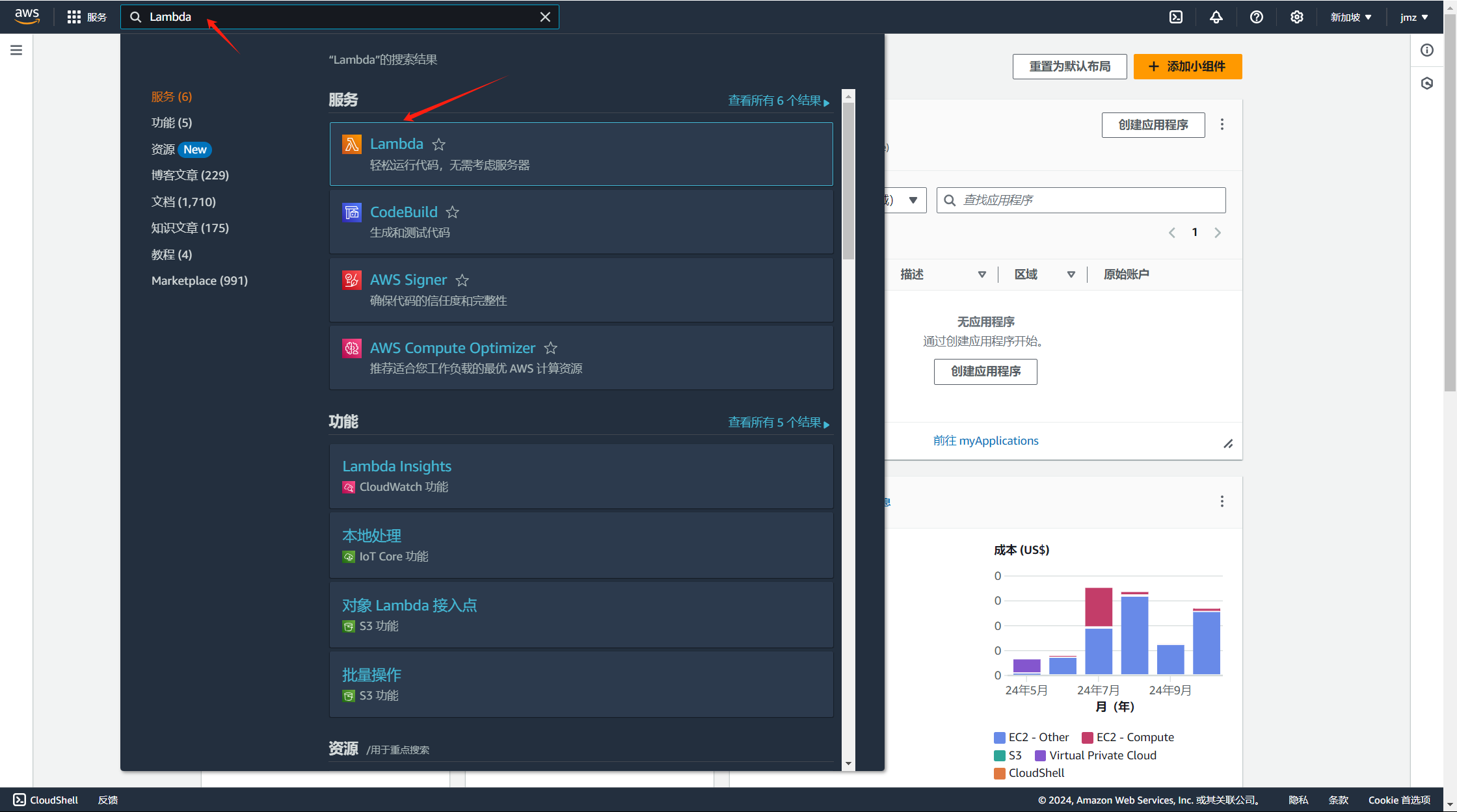
点击创建按钮
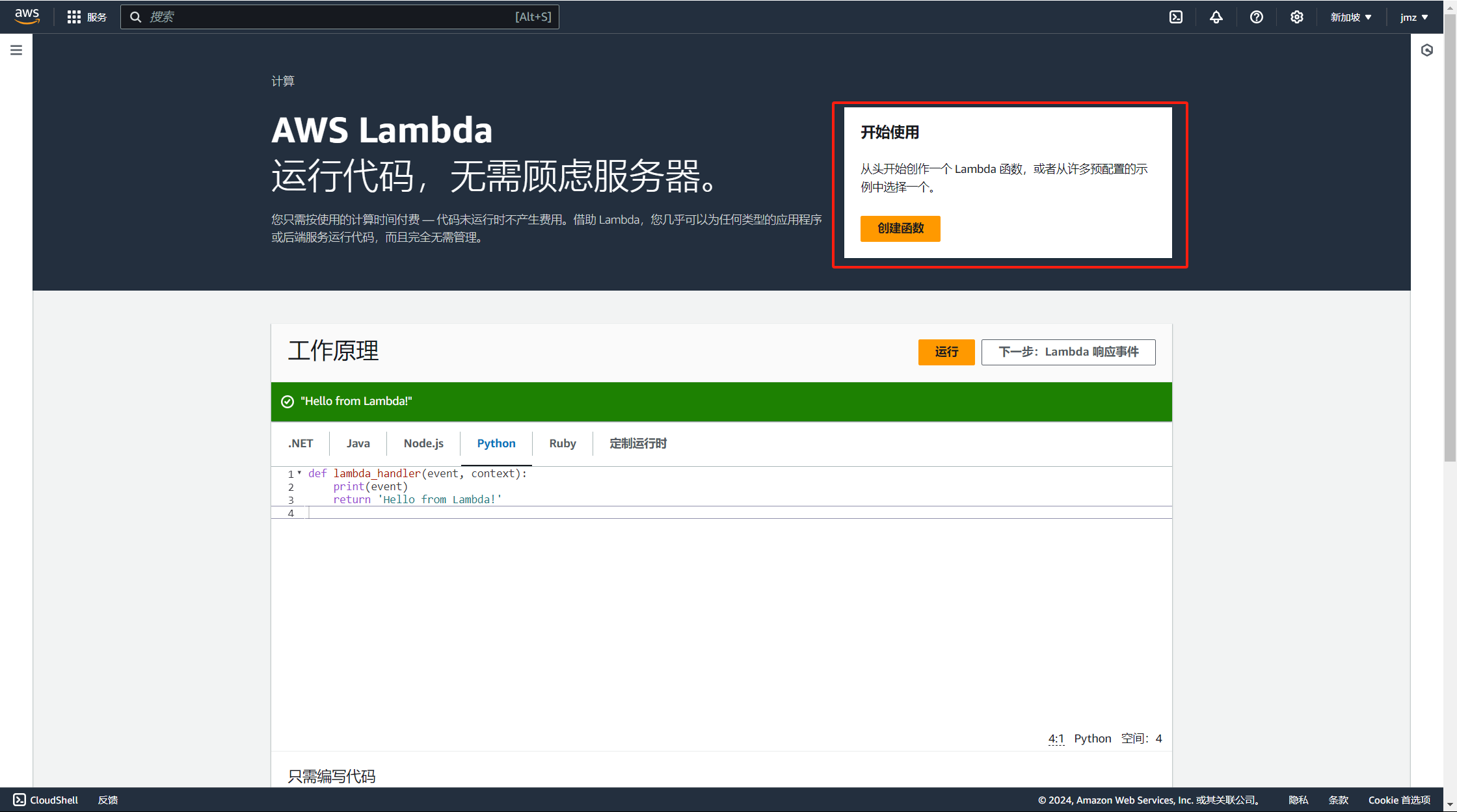
选择从头开始创作;
配置函数名称、运行时环境、主要架构;
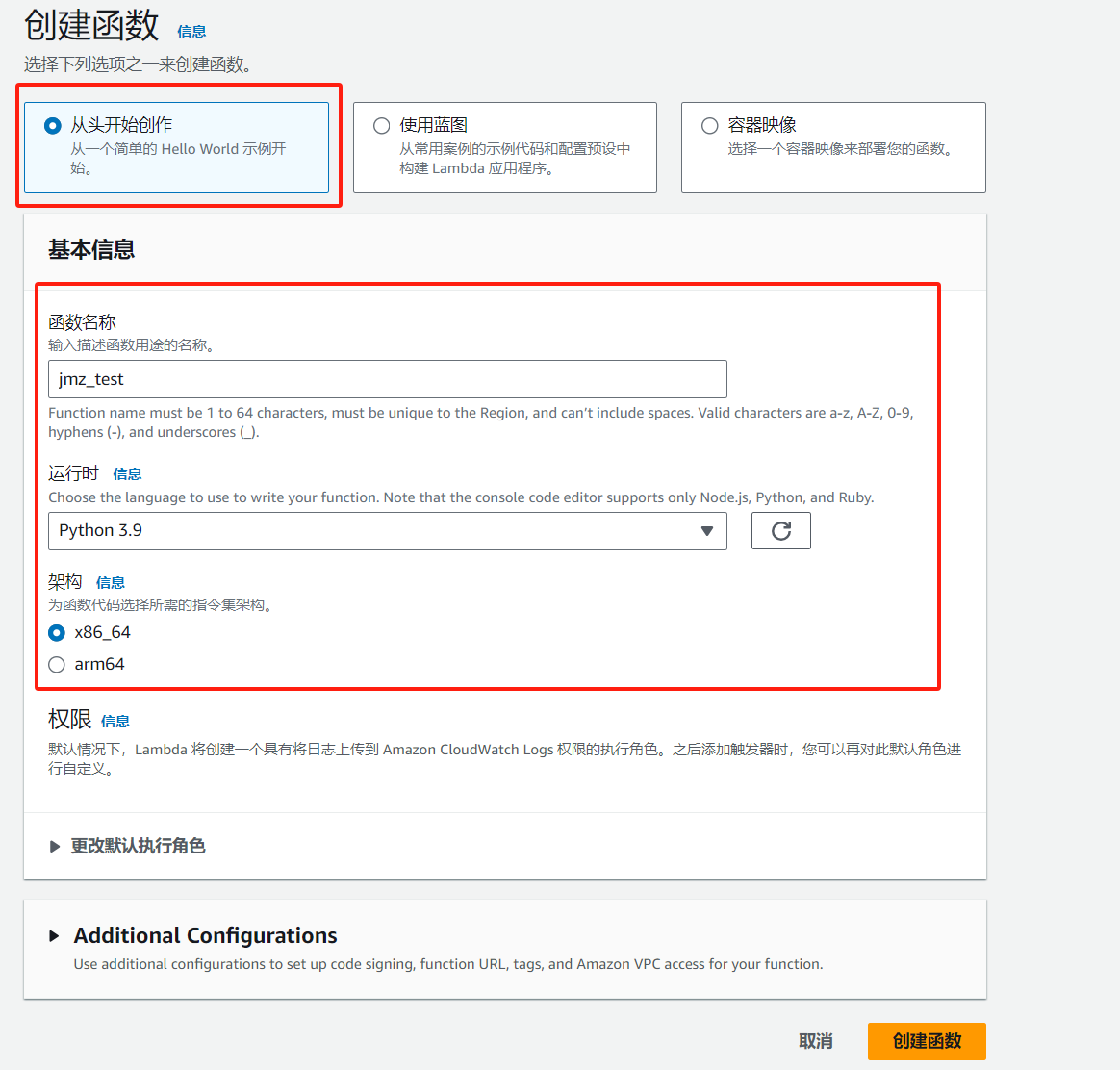
这里有个默认执行角色的配置项;
可以先不做修改,后面有机会再来琢磨这个权限的使用方法;

其他设置,这里也先不用改,默认配置就行;
这些配置项大致功能和用途介绍:
启用代码签名信息:
- 功能:启用代码签名后,Lambda 函数的代码必须通过由受信任的实体进行签名。这确保了代码的来源已被验证,并且在签名后未被篡改。
- 用途:确保安全性,防止恶意代码被部署在 Lambda 中。通过这种方式,你可以设置代码必须由可信任开发人员或构建管道进行签名,符合公司安全策略或合规要求。
启用函数 URL 信息:
- 功能:启用函数 URL 后,你将为 Lambda 函数分配一个 HTTP(S) 终端节点。这意味着你可以直接通过此 URL 发起 HTTP 请求调用 Lambda 函数。
- 用途:为 Lambda 函数创建公共或受限制的 API 接口,无需使用 API Gateway。适合轻量级的 HTTP 请求场景,如直接通过浏览器或第三方应用程序访问 Lambda。
启用标签信息:
- 功能:标签是键值对形式的标记,用于标识和组织亚马逊云科技资源。每个 Lambda 函数可以关联多个标签,帮助你管理和分类资源。
- 用途:便于成本跟踪、资源管理和权限控制。你可以通过标签筛选资源、查看某类资源的成本,以及在基于属性的访问控制策略中使用标签来定义权限。
启用 VPC 信息:
- 功能:启用后,Lambda 函数将连接到你的 VPC(Virtual Private Cloud,虚拟私有云)。这允许 Lambda 函数在调用时访问 VPC 内的私有资源,例如数据库或内部服务。
- 用途:当 Lambda 需要访问受保护的资源(例如,RDS、ElastiCache)时,通过将其连接到 VPC,可以确保这些资源不会暴露在公共互联网上,增强了安全性和网络隔离性。

配置好后点击创建,然后就进来了:
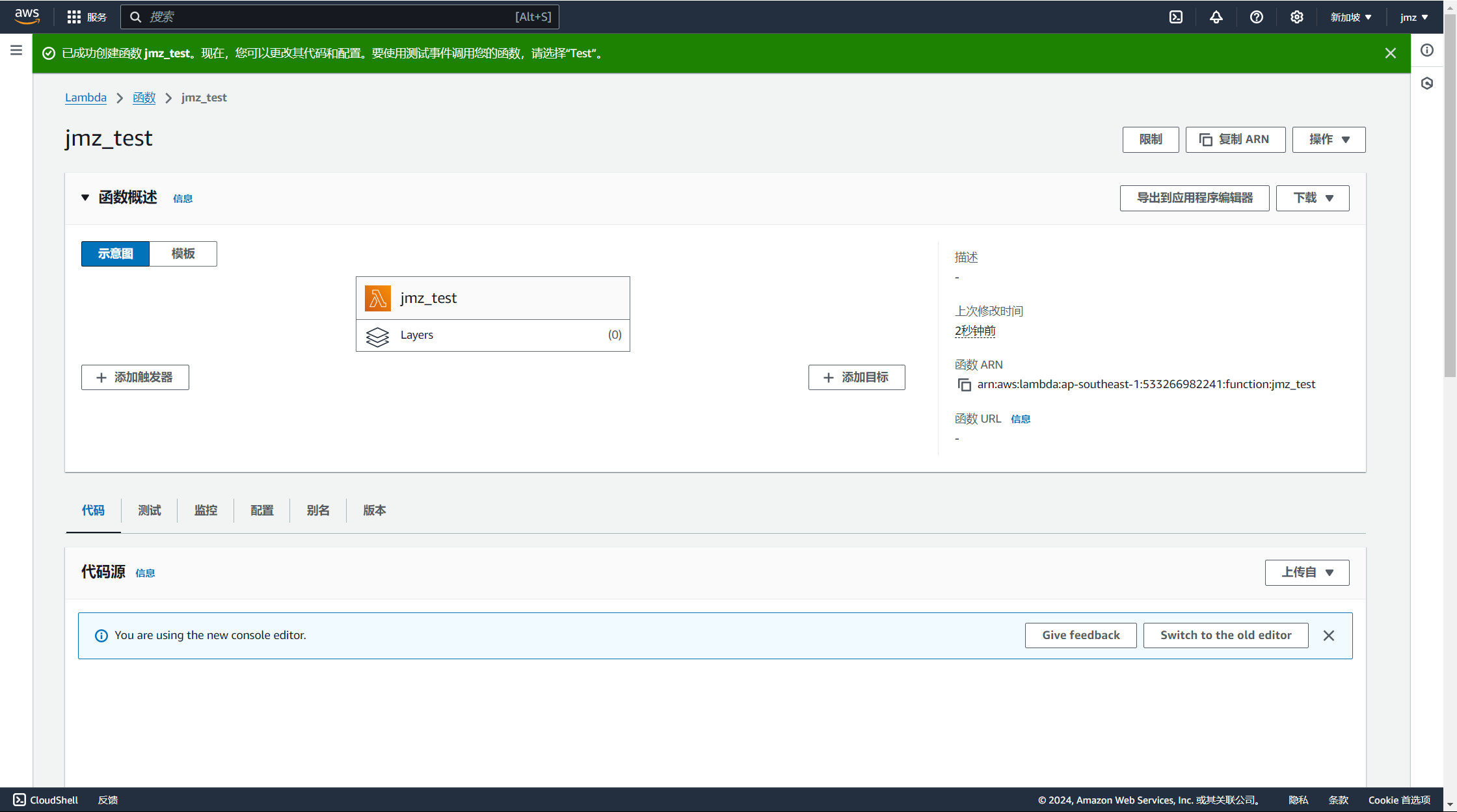
直接运行测试一下示例代码;
运行成功,说明函数没问题了;

4.3 配置API Gateway
前面流程架构里面已经说了需要配置 API Gateway 结合使用了;
所以我们先走通流程;
点击配置,选择触发器,然后添加触发器;
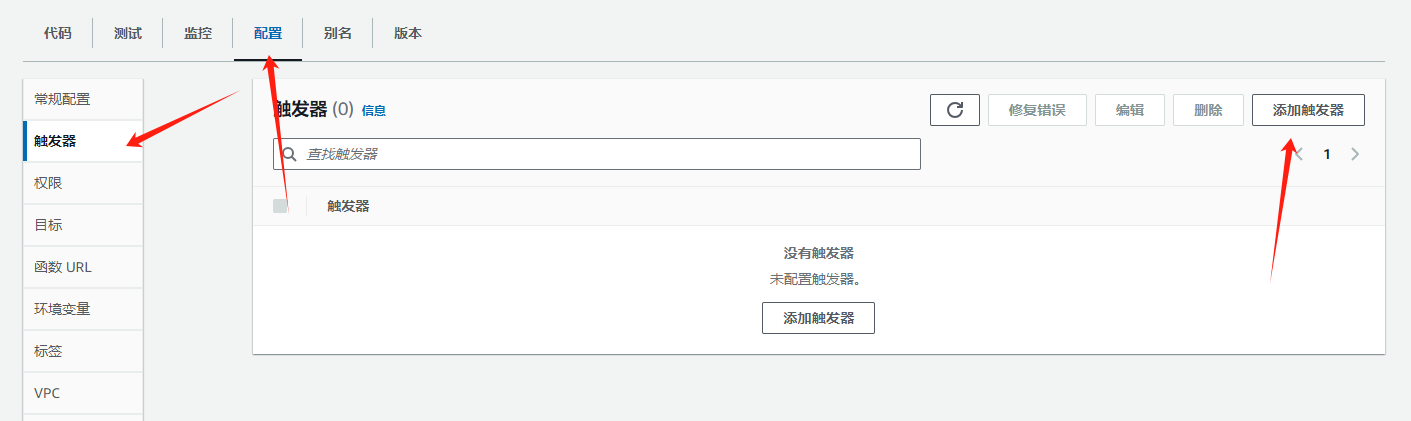
选择API Gateway
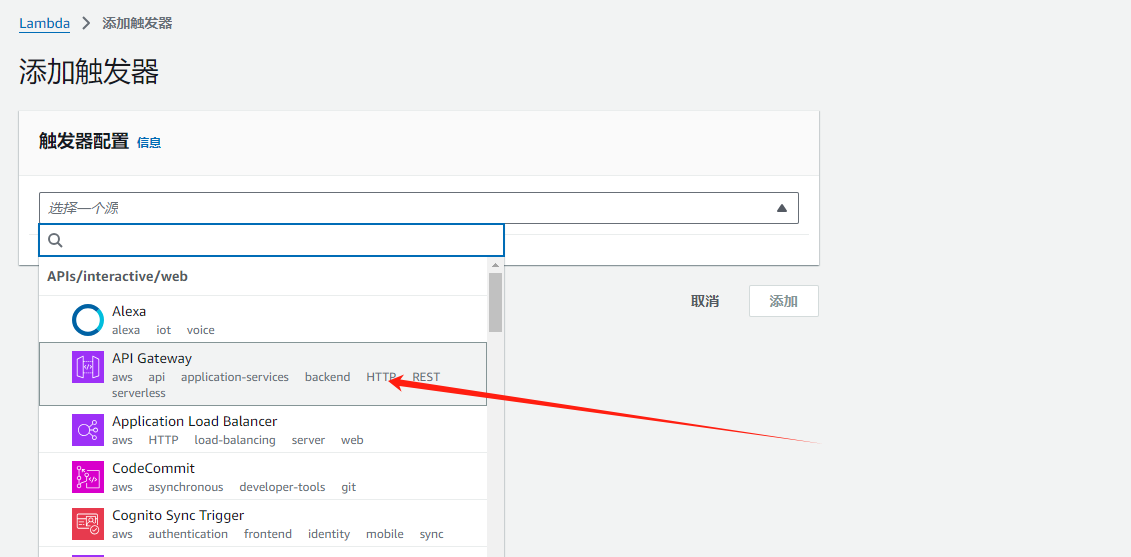
选择创建新的 API,创建一个HTTP API;配置好其他的参数;打开安全性和CORS;
然后直接点击节点 URL 测试;
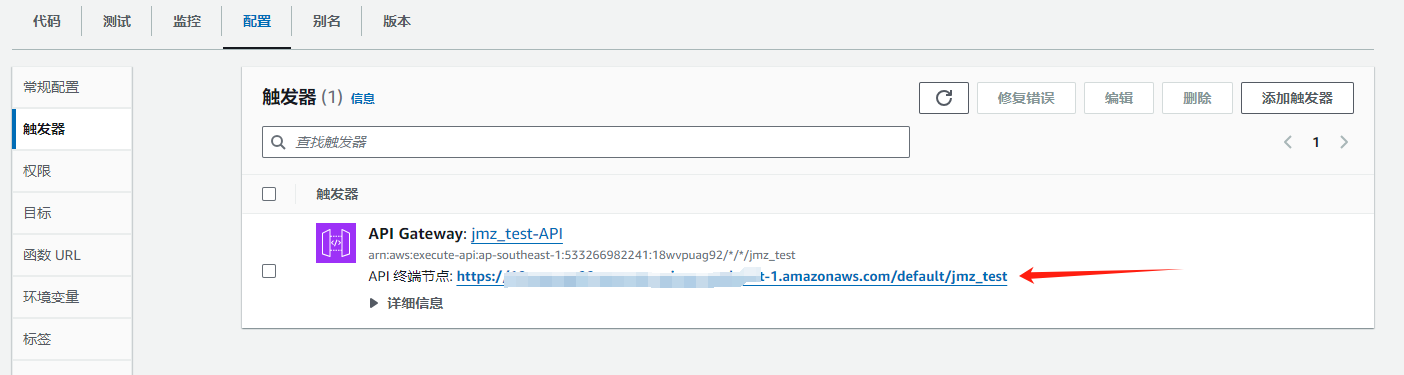
测试效果如下,现在基本流程就通了;
4.4 Lambda 获取 API Gateway传递的事件参数
Amazon API Gateway 会使用包含 HTTP 请求的 JSON 表示形式的事件同步调用函数。对于自定义集成,该事件为请求的正文。对于代理集成,该事件具有已确定的结构。
我们用的是代理集成,所以要确认一下 Amazon Lambda 获取 event的方式;
代理集成,API Gateway 传递过来的事件并不是直接由请求组成的正文,而是这样的:
json
{
"resource": "/",
"path": "/",
"httpMethod": "GET",
"requestContext": {
"resourcePath": "/",
"httpMethod": "GET",
"path": "/Prod/",
...
},
"headers": {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"Host": "70ixmpl4fl.execute-api.us-east-2.amazonaws.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-5e66d96f-7491f09xmpl79d18acf3d050",
...
},
"multiValueHeaders": {
"accept": [
"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"
],
"accept-encoding": [
"gzip, deflate, br"
],
...
},
"queryStringParameters": null,
"multiValueQueryStringParameters": null,
"pathParameters": null,
"stageVariables": null,
"body": null,
"isBase64Encoded": false
}你也可以通过下面的代码来查看返回的事件
python
import json
def lambda_handler(event, context):
# TODO implement
return {
'statusCode': 200,
'body': json.dumps(event, indent=4, default=str)
}综合来看,就是如果使用代理集成,我们的 Lambda 函数中需要通过 queryStringParameters 或其他参数来获取客户端传递过来的具体的参数值;
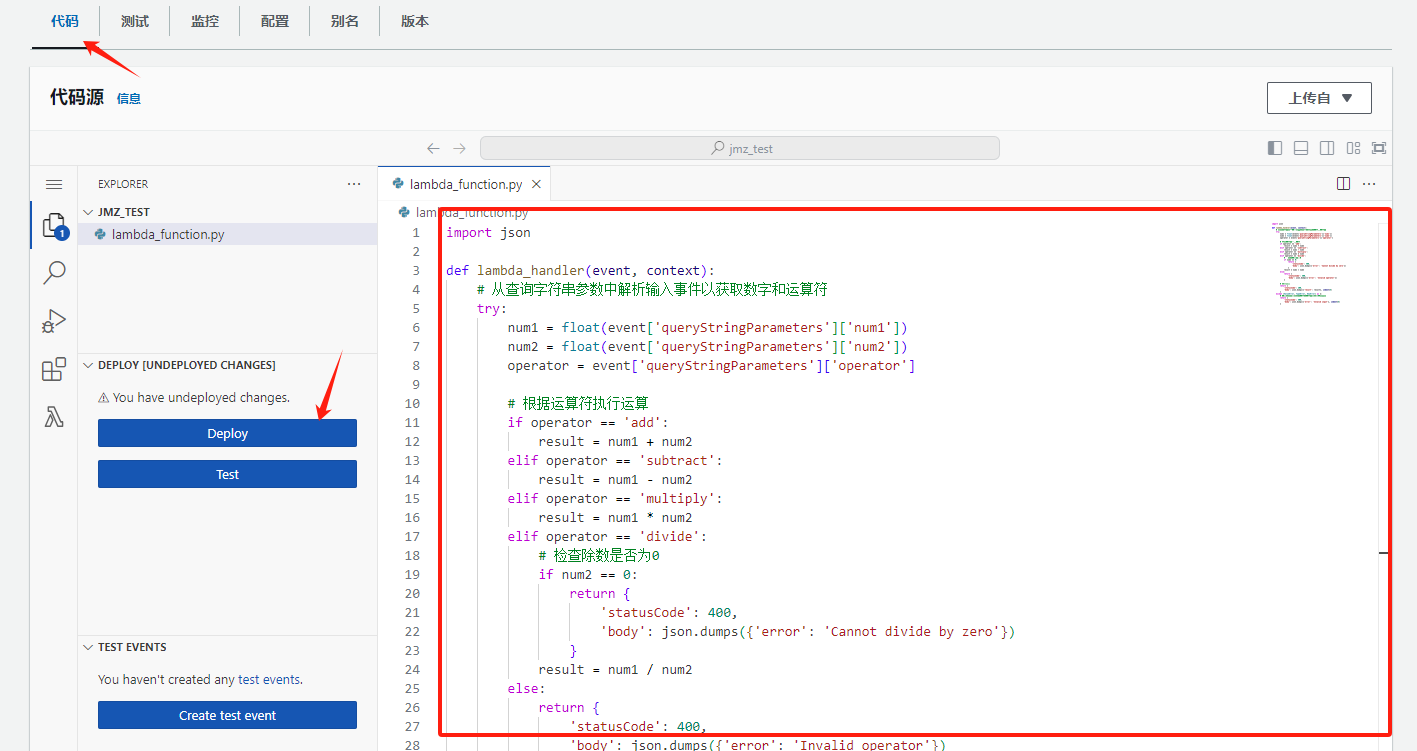
4.5 写一个简单的计算器
那我们进一步实践一下,写一个简单的计算器,代码如下:
python
import json
def lambda_handler(event, context):
# 从查询字符串参数中解析输入事件以获取数字和运算符
try:
num1 = float(event['queryStringParameters']['num1'])
num2 = float(event['queryStringParameters']['num2'])
operator = event['queryStringParameters']['operator']
# 根据运算符执行运算
if operator == 'add':
result = num1 + num2
elif operator == 'subtract':
result = num1 - num2
elif operator == 'multiply':
result = num1 * num2
elif operator == 'divide':
# 检查除数是否为0
if num2 == 0:
return {
'statusCode': 400,
'body': json.dumps({'error': 'Cannot divide by zero'})
}
result = num1 / num2
else:
return {
'statusCode': 400,
'body': json.dumps({'error': 'Invalid operator'})
}
# 返回结果
return {
'statusCode': 200,
'body': json.dumps({'result': result}, indent=4)
}
except (ValueError, TypeError, KeyError) as e:
# 如果输入不是有效的数字或运算符,返回错误信息
return {
'statusCode': 400,
'body': json.dumps({'error': 'Invalid input'}, indent=4)
}在代码中粘贴上面的代码;然后 deploy 部署一下;
等待部署完了之后,还是上面配置的 Gateway 的那个url;
进入 Postman 测试一下,测试结果如下:
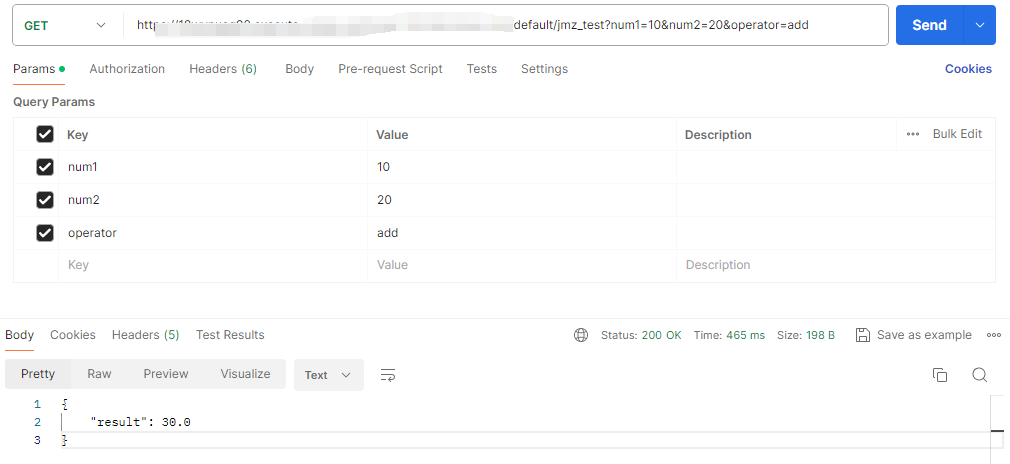
浏览器测试也可以,可以发现接口完全没问题

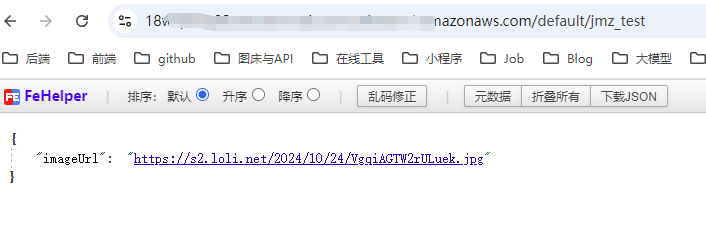
4.6 写一个随机图片接口
再简单扩展一下,这里就自定义一个列表,写入几个图片url;
进阶的可以结合Amazon S3等产品使用;
这里先简单实现:
python
import json
import random
def lambda_handler(event, context):
# 定义图片URL列表
image_urls = [
"https://s2.loli.net/2024/10/24/rQT7SwhpzM8BWiX.jpg",
"https://s2.loli.net/2024/10/24/qnzo8eZuXs73gAd.jpg",
"https://s2.loli.net/2024/10/24/TIPSGQNxv4tC6Bq.jpg",
"https://s2.loli.net/2024/10/24/VgqiAGTW2rULuek.jpg",
"https://s2.loli.net/2024/09/12/7Ev1936CLn2toRq.jpg"
]
# 从列表中随机选择一个URL
random_image_url = random.choice(image_urls)
# 返回随机选择的图片URL
return {
'statusCode': 200,
'body': json.dumps({'imageUrl': random_image_url}, indent=4)
}浏览器测试一下,完全没问题
4.7 实现一个 jieba 分词工具
来,再扩展一下,直接 jieba;
先不考虑 API Gateway 传递 event 参数,所以直接获取 text 参数:
python
import json
import jieba
def lambda_handler(event, context):
# 从事件对象中获取文本
text = event.get('text', '')
# 使用 jieba 进行分词
words = jieba.cut(text)
# 将分词结果转换为列表
words_list = list(words)
# 返回分词结果
return {
'statusCode': 200,
'body': json.dumps({'words': words_list}, indent=4, ensure_ascii=False)
}直接测试下先,然后就报错了
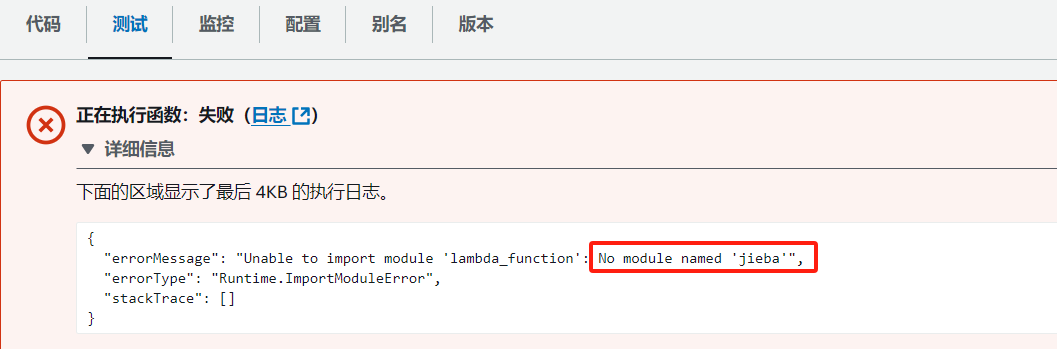
这就说明默认的运行环境中是没有第三方库的;
4.8 解决没第三方库的问题(上传本地代码)
我目前了解的有两种办法
4.8.1 将依赖的库一起打包
在本地新建一个目录,然后里面新建一个Lambda函数文件,也就是lambda_function.py;
在文件里面写上刚才的jieba分词代码;
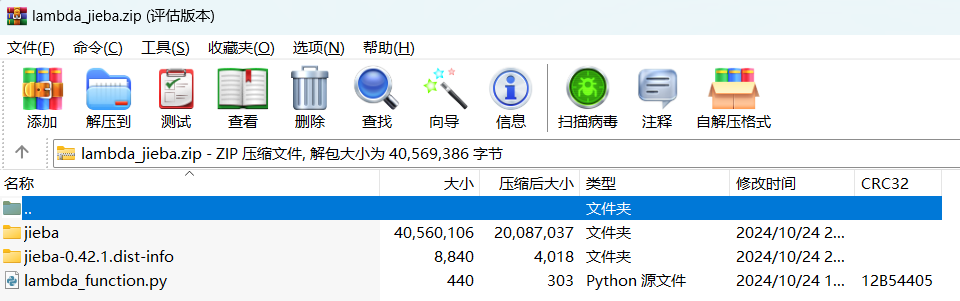
然后pip3 install --target=.\ jieba把 jieba 依赖下载到和代码同一目录下:

目录结构如下:

然后把它们一起打一个 zip 包,结构如图:
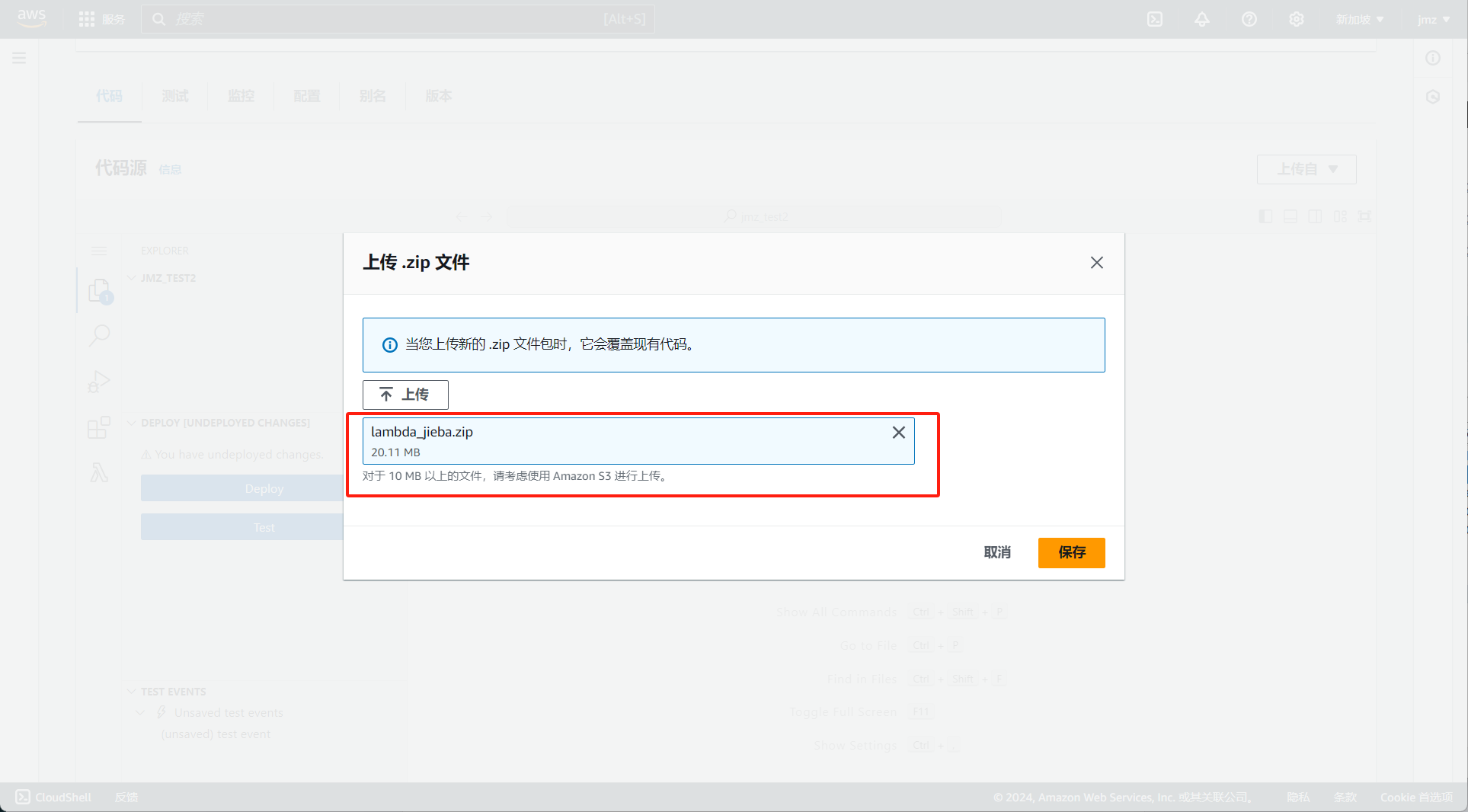
回到 Amazon 控制台,上传代码:

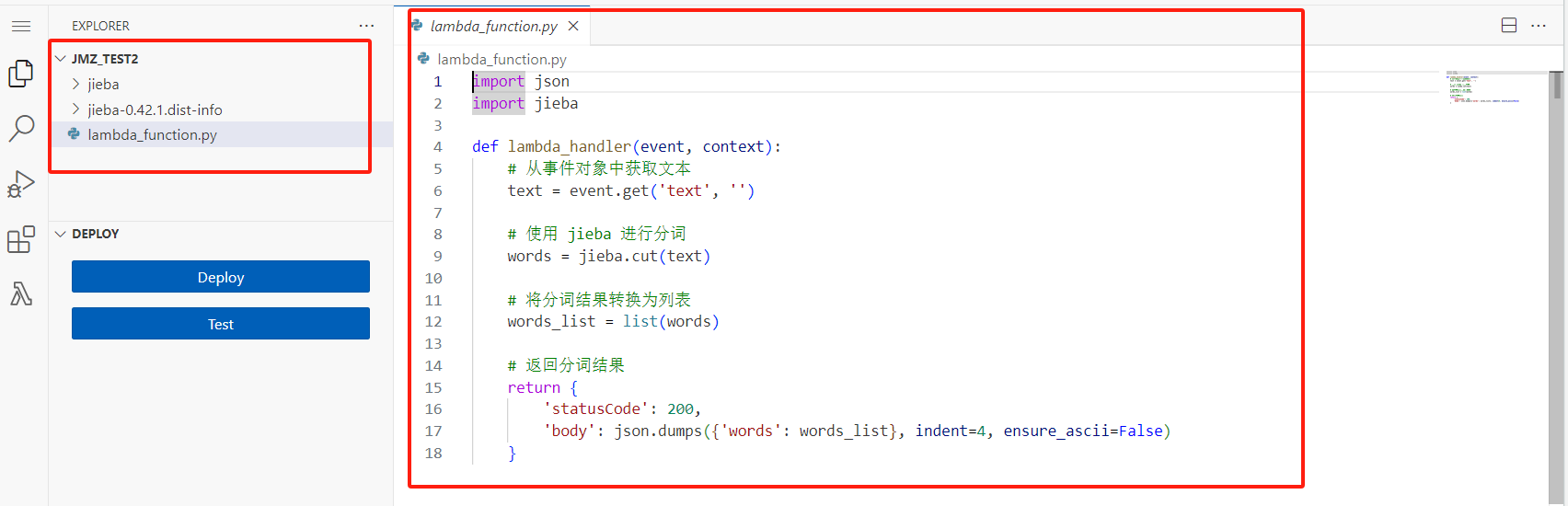
上传后的函数目录结构如下,和本地目录一致:
然后在测试中配置好事件参数后运行;

ok,失败了!
看下报错:Task timed out after 3.04 seconds
还好,问题不大,就是因为 jieba 需要的资源稍微有点大,改下资源分配就行;

进入配置菜单,在常规配置中配置;可以看到默认分配 128 MB的空间,超时是 3s ,所以错误也正常:
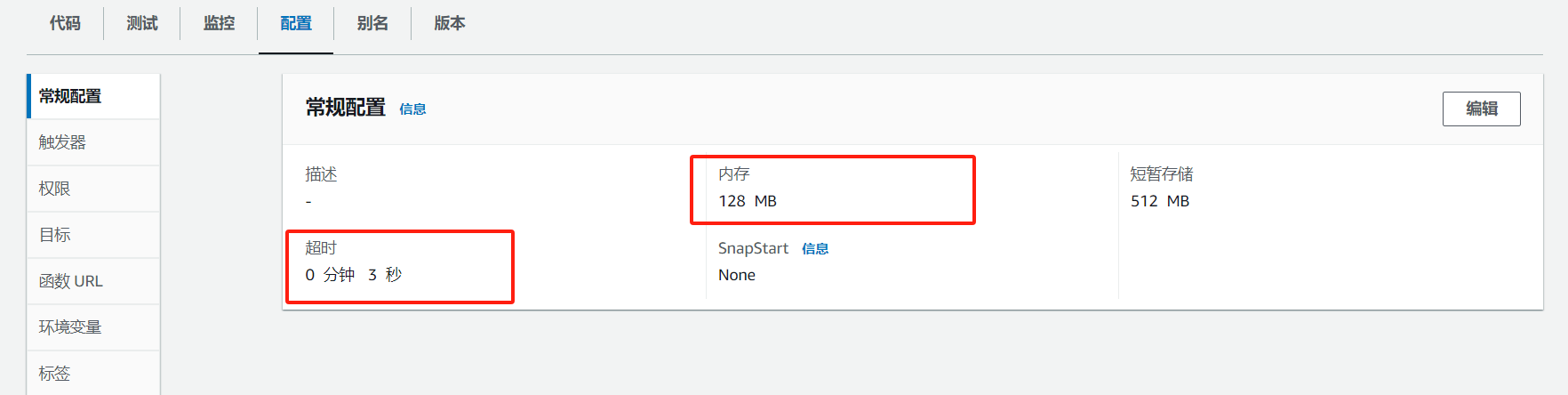
点击编辑,按照你的需求改一下:

回去再测试一下,大功告成:
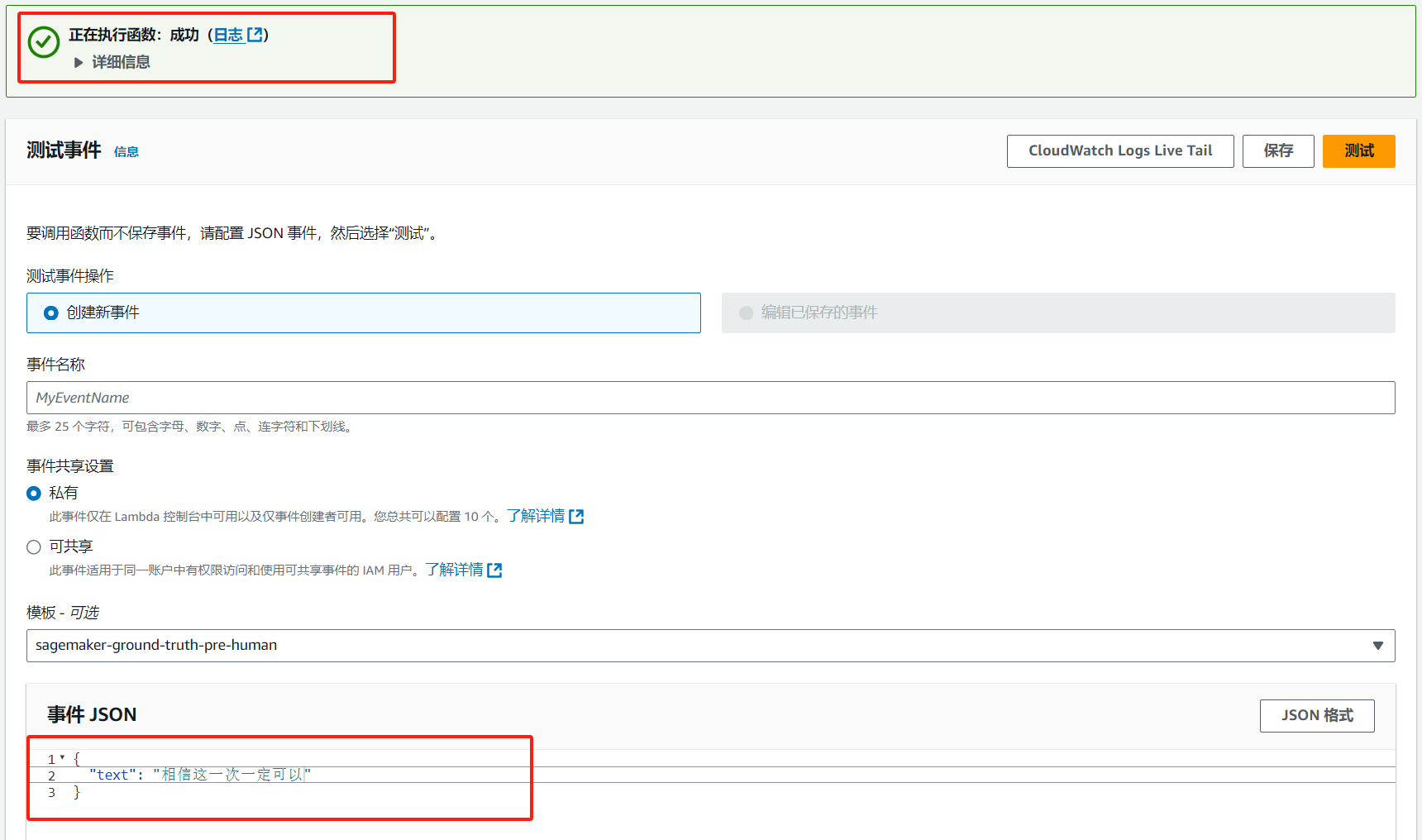
可以查看运行结果,效果不错:

4.8.2 Amazon Lambda层
这里就需要引入Lambda层的概念;
Amazon Lambda 层 是 Amazon Lambda 中的一种机制,旨在让开发者能够重用代码库、依赖项、或常用资源,以便在多个 Lambda 函数之间共享这些资源,而无需将其打包到每个函数代码中。
层的概念
层的核心思想是将某些通用的库、依赖项、配置文件等打包成一个独立的层 (Layer),然后将该层与多个 Lambda 函数关联,减少冗余,提高管理和维护的效率。层可以包含库(如第三方依赖包)、自定义运行时、共享的配置文件,甚至是自定义代码片段。
- Lambda 层的优势
- 减少代码重复:多个 Lambda 函数可以引用同一个层,因此无需在每个函数代码包中重复添加相同的依赖库或资源。
- 简化管理:通过集中管理常用的依赖库,开发者只需更新层,而不需要分别更新每个 Lambda 函数中的依赖。
- 加速部署:Lambda 函数代码包不再需要包含依赖库,从而减小代码包的体积,减少上传和部署时间。
- 版本控制:每个层都可以有多个版本,Lambda 函数可以选择使用特定版本的层,从而支持依赖库的版本管理。
Lambda 层的原理
Lambda 层的原理是通过将一些资源与 Lambda 函数的执行环境隔离开来,当 Lambda 函数执行时,Lambda 会将所需的层加载到函数的运行时环境中,从而使函数能够访问层中的资源。
运行时整合 :Lambda 函数执行时,会自动将关联的层中的文件加载到
/opt目录中,供 Lambda 函数调用。
层中的内容会根据类型放置在
/opt/下的特定路径中,例如:库文件 :Python 库或 Node.js 模块会被放置在
/opt/python或/opt/nodejs。二进制文件 :如果层中包含某些可执行文件或二进制库,这些也会被放在
/opt目录下的某些子目录中。多层支持 :一个 Lambda 函数最多可以引用 5 个层,会按顺序将这些层加载,层之间的文件可能会覆盖,后加载的层会覆盖先加载的层的文件。
跨账户共享:层可以在亚马逊云科技账户内或跨账户共享,这样一个账户的用户可以创建和维护层,其他账户的用户也能使用这些层。
使用 Lambda 层的步骤
- 创建层 :将依赖包或代码打包为
.zip文件,并将其上传作为一个 Lambda 层。- 配置函数使用层:在 Lambda 函数的设置中,选择将该层添加到函数中。可以选择层的版本。
- 在函数中引用层的资源 :例如,使用 Python 时,层中的依赖库会放在
/opt/python目录中,所以你可以像平常一样import这些库。层的使用场景
- 第三方库管理 :假如多个 Lambda 函数都需要用到同样的第三方依赖库(例如
requests或numpy),可以把这些库打包成一个层,让所有函数都可以复用它,而不必每次都在函数代码中包含这些库。- 自定义运行时:如果您想在 Amazon Lambda 中使用官方不支持的编程语言(如 Rust 或 Erlang),可以创建一个自定义运行时,并将其作为一个层进行上传,供 Lambda 函数使用。
- 共享工具集:如果多个 Lambda 函数需要使用相同的工具或二进制文件,例如加密工具、数据库连接工具等,可以将这些工具打包成层。
层的限制
- 大小限制 :每个层的最大大小为 250 MB(压缩后的大小)。
- 层的数量 :每个 Lambda 函数最多可以关联 5 个层,因此层的数量需要合理规划。
- 跨区域不可用:层是区域特定的,不能跨区域使用(但可以通过跨区域复制层来实现相同层在不同区域的使用)。
所以我们需要创建层;
首先先把依赖打包一下:pip3 install --target=.\python jieba
在本地把依赖安装到 python 目录下;
然后打个 zip 压缩包;
这里注意一下目录结构和名称(目录不规范的时候,会报错)
当向函数添加层时,
Lambda会将层内容加载到该执行环境的/opt目录中。对于每个Lambda运行时系统,PATH变量都包括/opt目录中的特定文件夹路径。为确保PATH变量能够获取层内容,层.zip文件应在以下文件夹路径中具有依赖项:构建
python层.zip存档的文件夹架构:
pythonlayer_content.zip └ python └ lib └ python3.11 └ site-packages └ requests └ <other_dependencies> (i.e. dependencies of the requests package) └ ...也就是你依赖得放到
python目录下

进入控制台,点击创建层:
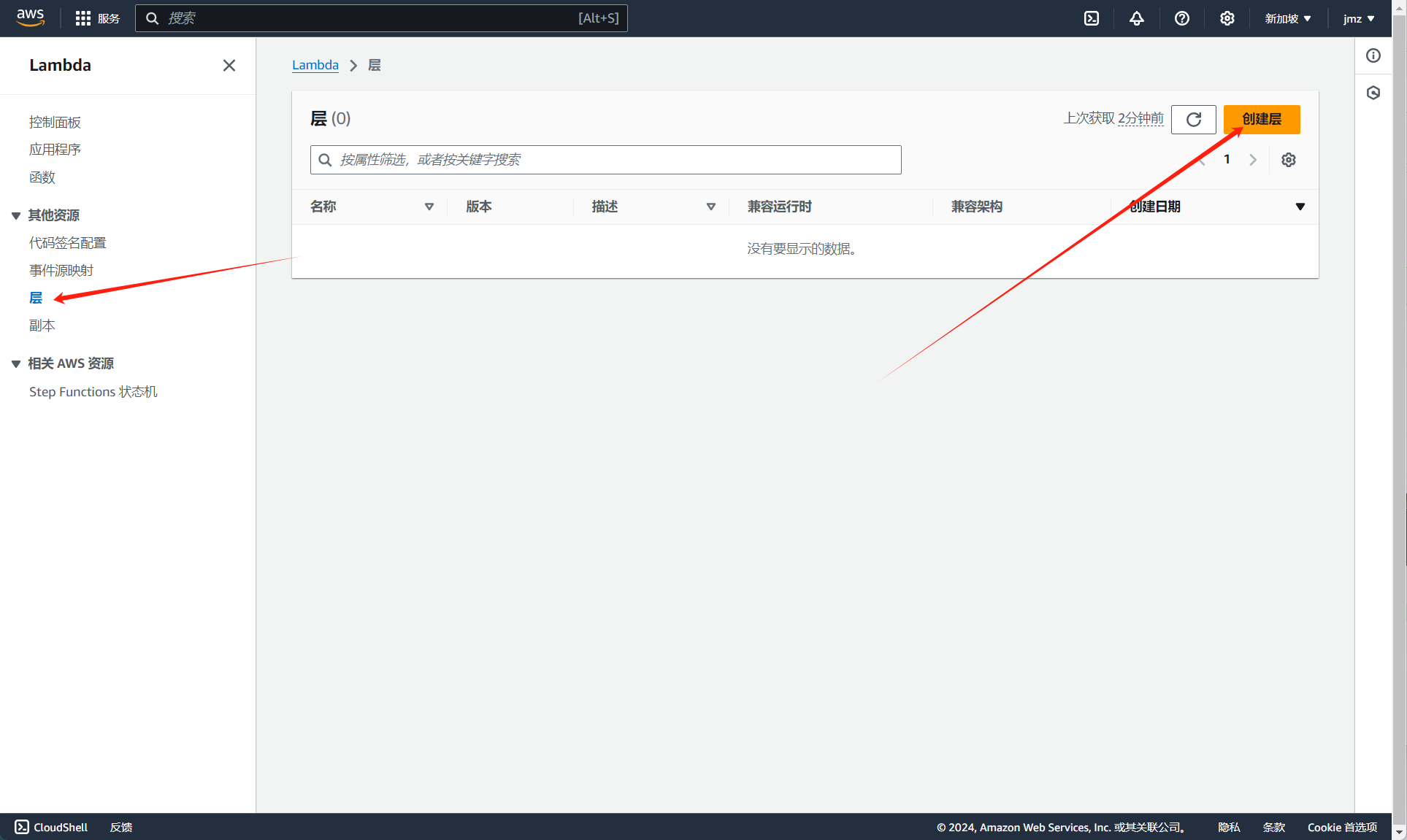
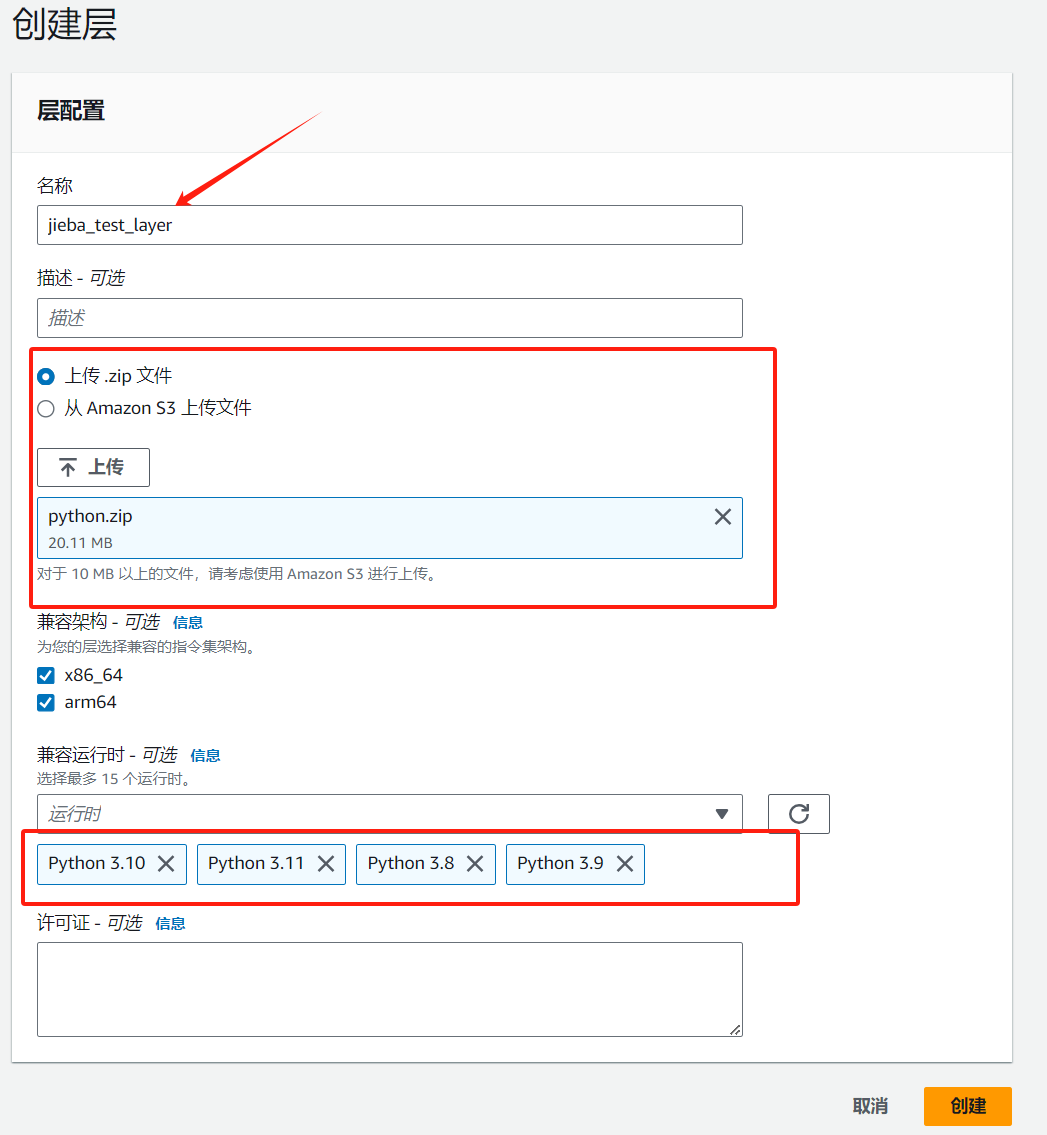
配置好层名称及其他关键参数并上传 zip 压缩包:
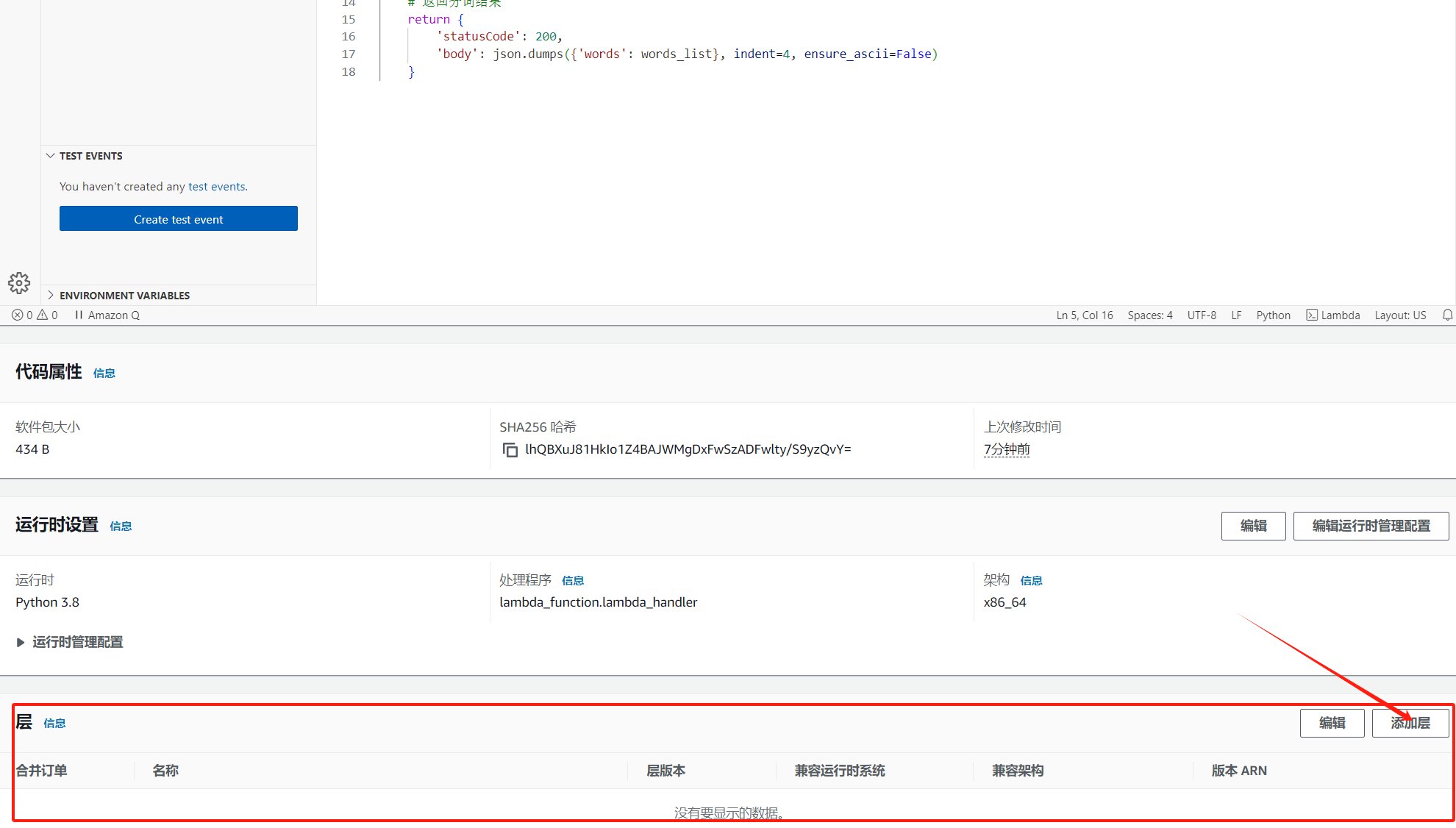
回到 Lambda 函数,划到代码最下面,点击添加层;
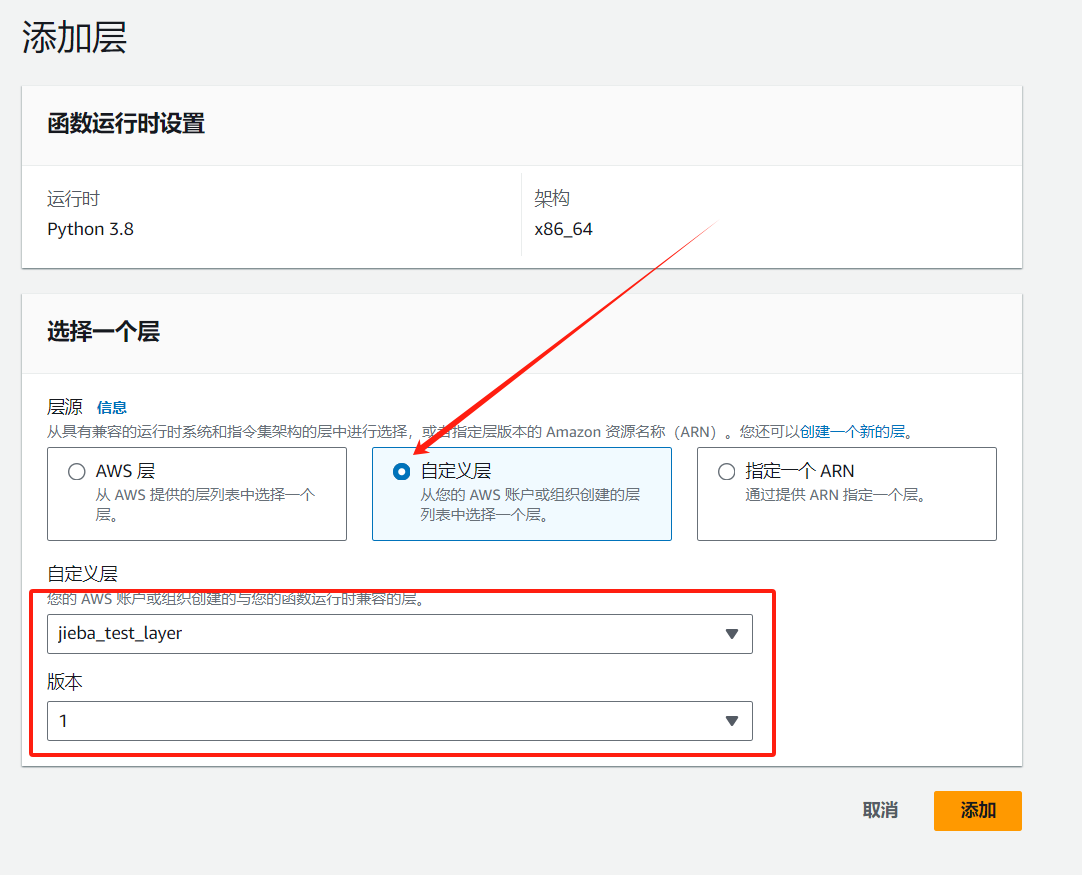
选择自定义层,然后选择创建的层和版本;
回到代码上方的示意图,可以看到函数下已经有了一个 layer 了;

此时的代码结构也只有一个主要的 python 代码文件了:
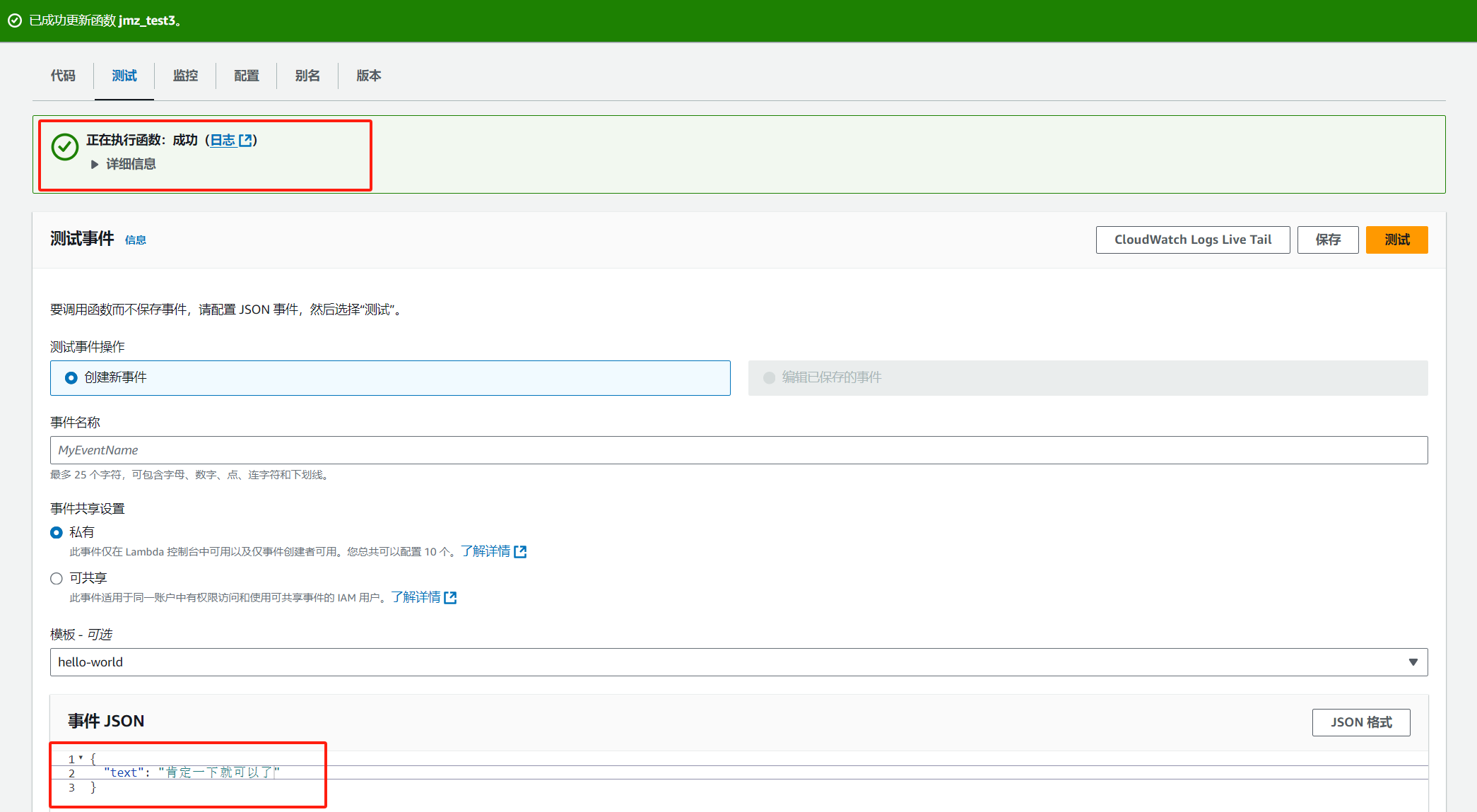
进入测试,运行成功:
4.9 制作 jieba 分词 API
上面仅仅实现了在 Lambda 中运行,但是还没做成 API;
要结合 API Gateway 就需要改一下代码,保证从 API Gateway 传递过来的 event json 中获取到参数:
python
import json
import jieba
def lambda_handler(event, context):
# 从事件对象中获取查询字符串参数
query_params = event.get('queryStringParameters', {})
# 从查询参数中获取'text'字段的值
text = query_params.get('text', '')
# 使用 jieba 进行分词
words = jieba.cut(text)
# 将分词结果转换为列表
words_list = list(words)
# 返回分词结果
return {
'statusCode': 200,
'body': json.dumps({'words': words_list}, indent=4, ensure_ascii=False)
}接着怎么结合 API Gateway 就不多说了,前面章节说了;
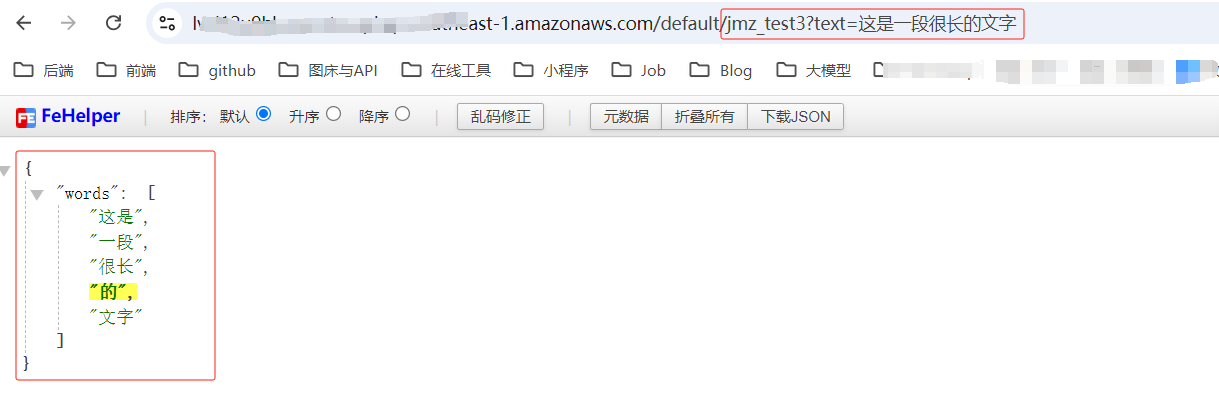
测试一下,大功告成:
5 总结与扩展
5.1 待探索
这次仅仅是打通了一下基本流程,还有很多东西都需要琢磨;
包括和其他亚马逊云科技的服务集成、Amazon API Gateway的详细使用方法、Amazon Lambda的进阶使用方法(权限、事件和触发器、函数代码和性能优化、监控和日志、自动化或半自动化部署等);
要研究的比较透彻的话,还需要投入很多,但是一边学一边实践的话,应该还是很快的;
5.2 一个无敌的 python 库
这里推荐一个开源的 python 库 python-lambda,我还没正式研究过,就大致看了一下,用了它应该是事半功倍的!
python-lambda 是一个开源库,旨在简化 AWS Lambda 函数的创建和管理。提供了一系列工具和功能,帮助开发者更轻松地构建无服务器应用程序。以下是该库的一些关键特性和功能的详细介绍:
-
主要特性
-
简化的函数定义:
python-lambda提供了一种简化的方式来定义 Lambda 函数,允许开发者用更少的代码来创建和部署函数。
-
集成的本地开发环境:
- 提供了本地开发和测试的支持,允许开发者在本地运行和调试 Lambda 函数,而无需频繁部署到 AWS。
-
自动化部署:
- 支持将 Lambda 函数及其相关资源自动部署到 AWS。开发者只需简单的命令即可完成整个部署过程。
-
支持 API Gateway:
- 可以轻松创建和管理与 AWS API Gateway 的集成,使得 Lambda 函数能够通过 HTTP 请求触发。
-
环境变量管理:
- 支持管理 Lambda 函数的环境变量,确保敏感信息和配置信息的安全存储。
-
多种事件源支持:
- 能够处理多种事件源,如 S3、DynamoDB、SNS 等,开发者可以轻松地将函数与这些服务集成。
-
灵活的依赖管理:
- 支持自定义依赖项的管理,开发者可以在项目中轻松集成第三方库。
-
5.3 总结
本文基本上完成了从理论到实践,涵盖了无服务器架构的基础知识、Amazon Lambda 和 API Gateway 的配置与使用,以及如何构建具体的无服务器应用程序。但是要正式投入相关的研发,还需要研究的东西还有很多。如果你有什么好的想法和点子,欢迎一起讨论!
最后还是得说下亚马逊云科技提供的免费云产品真的很不错,很适合开发者去学习!