本章介绍分布式数据科学工具 Xorbits 。
1 Xorbits Data
Xorbits Data 是一个面向数据科学的分布式计算框架,功能类似于 Dask 和 Modin,用于加速 Pandas DataFrame 和 NumPy。Xorbits Data 通过切分大数据集并利用 Pandas 或 NumPy 执行操作。其底层采用了自主研发的 Actor 编程框架 Xoscar,不依赖于 Ray 或 Dask。
1.1 Xorbits 集群
在进行计算之前,Xorbits 需要在多节点环境中初始化集群。在单机环境中,可以直接使用 Xorbits.init()进行初始化。在集群环境中,可以按照以下步骤进行配置:首先启动一个管理进程(Supervisor),然后在各个计算节点上启动 Worker 进程。
# 先在管理节点启动 Supervisor
xorbits-supervisor -H <supervisor_ip> -p <supervisor_port> -w <web_port>
# 在每个计算节点启动 Worker
xorbits-worker -H <worker_ip> -p <worker_port> -s
<supervisor_ip>:<supervisor_port>其中,和为管理节点的 IP 和端口号,为仪表盘端口号,客户端也通过这个端口与集群连接。和为每个计算节点的 IP和端口号。启动Supervisor和 Worker后,在代码中使用 xorbits.init(":")连接到这个集群,计算任务就可以横向扩展到集群上。
1.2 API 兼容性
在 Pandas DataFrame 的兼容性方面,排序如下:Modin>Xorbits>Dask DataFrame;在性能方面,排序如下:Xorbits> Dask DataFrame>Modin。
Xorbits 也在多维度上对数据进行切分,并在切分过程中保留行标签和列标签。它提供了广泛的 Pandas API 兼容性,包括但不限于 iloc()和 median()函数。
import os
import sys
sys.path.append("..")
from utils import nyc_flights
from utils import nyc_taxi
taxi_path = nyc_taxi()
import xorbits
import xorbits.pandas as pd
df = pd.read_parquet(taxi_path, use_arrow_dtype=False)
df.iloc[3]运行结果如图所示。

df.dtypes运行结果如图所示。

df['trip_distance'].median()运行结果如图所示。

1.3 推迟执行
Xorbits 采用类似于 Dask 的计算图模型,任何计算都会先转换为计算图再执行;但与 Dask不同,Xorbits 不需要明确调用 compute()来触发计算,这种方式称为推迟(Deferred)执行。
Xorbits 在后台构建了计算图,但只有遇到 print()等需要将数据呈现给用户的操作时,Xorbits才会执行计算图。这种方式使得 Xorbits 与 Pandas 和 NumPy 的语义更加相似。如果需要手动触发计算,也可以通过 xorbits.run(df)实现。
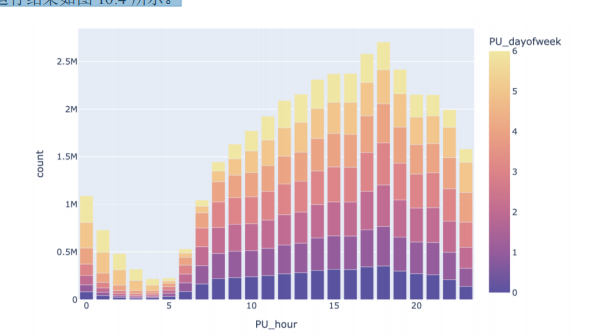
以下面的数据可视化为例,gb_time 只是一个指向计算图的指针,并不是实际数据。但当Plotly 需要 gb_time 的结果时,Xorbits 会触发计算。
df['PU_dayofweek'] = df['tpep_pickup_datetime'].dt.dayofweek
df['PU_hour'] = df['tpep_pickup_datetime'].dt.hour
gb_time = df.groupby(by=['PU_dayofweek', 'PU_hour'],
as_index=False).agg(count=('PU_dayofweek', 'count'))
import plotly.express as px
import plotly.io as pio
pio.renderers.default = "notebook"
b = px.bar(
gb_time,
x='PU_hour',
y='count',
color='PU_dayofweek',
color_continuous_scale='sunset_r',
)
b.show()运行结果如图所示。
同样使用计算图,但 Xorbits 可以避免像 Dask DataFrame 那样关注计算图的细节,也不需要使用 repartition()。Xorbits 在构建和执行计算图时进行了内部优化。例如,当数据出现倾斜时,Xorbits 会自动优化计算图,避免计算图过大。
本篇文章就先到这这结束啦,后续还有其他干货文章大家点个关注不迷路哦!

本文摘自《Python数据科学加速:Dask、Ray、Xorbits、mpi4py》,获出版社和作者授权发布。