前言
首先什么是io复用呢?
现在web框架没有不用到io复用的,这点是肯定的,不然并发真的很差。
那么io复用,复用的是什么呢?复用的真的不是io管道啥的,也不是io连接啥的,复用的是io线程。
这其实是操作系统的设计上的io并发不足的地方,然后自己给慢慢填了。
正文
听一段历史:
当时操作系统设计的时候呢? 按道理说是要操作系统去管理io这块,也就是对我们屏蔽硬件。
然后我们就调用系统的接口,让操作系统去帮我们读取数据啥的,这似乎是非常的nice的时候。
操作系统就设计了两种读取方案:
第一种呢,比如自己调用io系统接口,然后线程陷入等待,当有数据的时候呢,操作系统唤醒我们的线程
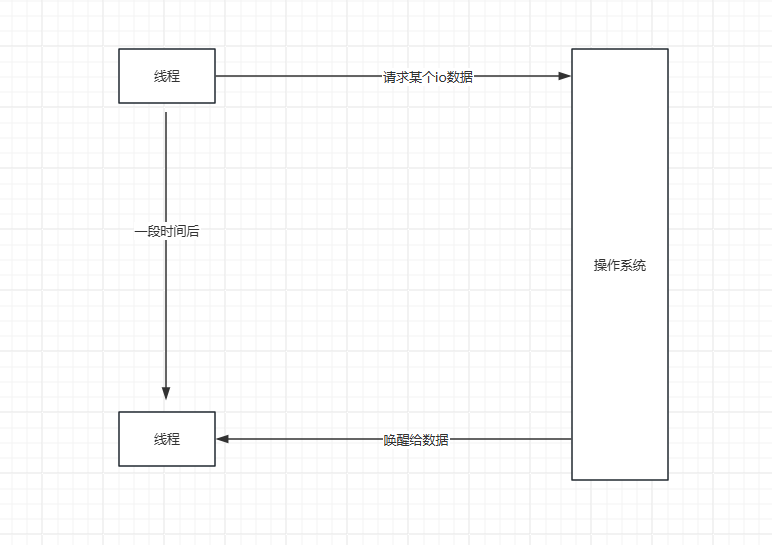
第二种,就是自己调用系统接口,然后操作系统告诉我们没有,这个时候我们可以选择做其他事情,或者等会再来问。
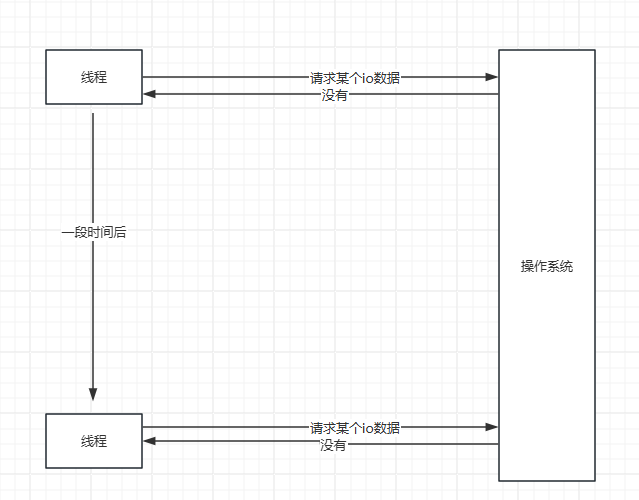
因为对io是抽象的,这个时候呢,如果是磁盘文件系统,这还是相当nice的,因为我们又不关心是网络io还是文件io,读取就完事了。
磁盘文件我们一般是对某个文件连续读对吧,这样这两种方式工作都是很好的。
可能有些人一直认为读磁盘文件就是立即返回的,其实可以调用其他方式,当磁盘有新数据的时候再返回,是可以的,在操作系统系统会补全这些机制的说明,这里不扩展。
但是网络io有个什么样的场景呢?那就是连接数可能特别多,而且是每个间断着读取。
加入我们采用第一种方式,那么每一个连接,就需要一个线程去监控,这样就会很多线程,这样的确会出现线程大爆炸,而且线程调度是需要开销的。
那么我们采用第二种方式,第二种方式好像每个都需要一个线程,其实不需要哈。
我们可以排队嘛,比如把socket放入到一个队列中,然后不断地轮训,这样其实就实现了io复用了,这个时候就有人问了,io复用这么简单吗?
是的,这就是io复用了。呀呀呀,这就实现了,是的,这就实现了io线程复用,就是一个或者多个线程实现io的数据接收嘛。
但是性能不太行,不太行的地方在于两点,就是加入有5000个连接,只有2个有信息,那么得去轮训一遍,这效率真的很感人。
还要就是不断地调用操作系统的陷入这个开销也是很大的。
那么这个时候操作系统自己就得改进了,明明就是操作系统自己知道有没有消息,为啥不主动告诉我呢?
那么操作系统自己做了一些改进。
select 函数.
#define __FD_SETSIZE 1024
typedef struct {
unsigned long fds_bits[__FD_SETSIZE / (8 * sizeof(long))];
} __kernel_fd_set;
struct timeval {
time_t tv_sec; /* seconds */
suseconds_t tv_usec; /* microseconds */
};
//函数声明
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);通过select函数可以完成多个IO事件的监听。
函数参数:
readfds:内核检测该集合中的IO是否可读。如果想让内核帮忙检测某个IO是否可读,需要手动把文件描述符加入该集合。
writefds:内核检测该集合中的IO是否可写。同readfds,需要手动加入
exceptfds:内核检测该集合中的IO是否异常。同readfds,需要手动加入
nfds:以上三个集合中最大的文件描述符数值 + 1,例如集合是{0,1,4},那么 maxfd 就是 5
timeout:用户线程调用select的超时时长。
设置成NULL,表示如果没有 I/O 事件发生,则 select 一直等待下去。
设置为非0的值,这个表示等待固定的一段时间后从 select 阻塞调用中返回。
设置成 0,表示根本不等待,检测完毕立即返回。
函数返回值:
大于0:成功,返回集合中已就绪的IO总个数
等于-1:调用失败
等于0:没有就绪的IO
// 将文件描述符fd从set集合中删除
void FD_CLR(int fd, fd_set *set);
// 判断文件描述符fd是否在set集合中
int FD_ISSET(int fd, fd_set *set);
// 将文件描述符fd添加到set集合中
void FD_SET(int fd, fd_set *set);
// 将set集合中, 所有文件描述符对应的标志位设置为0
void FD_ZERO(fd_set *set); select 缺点:
1.fd_set长度限制:由于fd_set本质是一个数组,同时操作系统限制了其长度,导致其只能接受文件描述符数值在1024以内的。
-
select函数的返回值是int,导致每次返回后,用户得手动检测集合中哪些值被改为1了(被改为1的表示产生了IO就绪事件)
-
每次调用 select,都需要把 fd 集合从用户态拷贝到内核态,当fd很多时,开销很大。
-
每次内核都是线性扫描整个 fd_set,判断是否有IO就绪事件,导致随着监控的描述符 fd 数量增长,其性能会线性下降
看到select缺点这么多,看着就不怎么好用。
这个其实就是批量检测,然后加了一个timeout,最后还得自己去轮训一遍,还是有点坑。
这时候可能我们都会想,自己设计都不会这么坑。其实这样设计也是当时的一个常规设计,因为既要保全内核的稳定,又要维护陷入函数的简单,后面就能看到数据结构之美了。
然后就到了poll了:
和 select 相比,它使用了不同的方式存储文件描述符,也解决文件描述符的个数限制。
struct pollfd {
int fd; /* file descriptor */
short events; /* events to look for */
short revents; /* events returned */
};
int poll(struct pollfd *fds, unsigned long nfds, int timeout); 函数参数:
fds:struct pollfd类型的数组, 存储了待检测的文件描述符,struct pollfd有三个成员:
fd:委托内核检测的文件描述符
events:委托内核检测的fd事件(输入、输出、错误),每一个事件有多个取值
revents:这是一个传出参数,数据由内核写入,存储内核检测之后的结果
nfds:描述的是数组 fds 的大小
timeout: 指定poll函数的阻塞时长
-1:一直阻塞,直到检测的集合中有就绪的IO事件,然后解除阻塞函数返回
0:不阻塞,不管检测集合中有没有已就绪的IO事件,函数马上返回
大于0:表示 poll 调用方等待指定的毫秒数后返回
函数返回值:
-1:失败
大于0:表示检测的集合中已就绪的文件描述符的总个数
在 select 里面,文件描述符的个数已经随着 fd_set 的实现而固定,没有办法对此进行配置;而在 poll 函数里,我们可以自由控制 pollfd 结构的数组大小,从而突破select中面临的文件描述符个数的限制。
这个pollfd就设计的人性化多了哈,有个fd然后里面是事件,看起来还是不错的,很面向对象。
poll 的实现和 select 非常相似,只是poll 使用 pollfd 结构,而 select 使用fd_set 结构,poll 解决了文件描述符数量限制的问题,但是同样需要从用户态拷贝所有的 fd 到内核态,
也需要线性遍历所有的 fd 集合,所以它和 select 并没有本质上的区别。
所以呢,有人如果系统用poll和epoll比,这两个思想就不一样,下文可见,poll只是在select上进行轻微的改进,和操作系统的沟通真的很感人,但是这个结构化,还是很舒服的,尤其是写了很多面向对象代码后epoll 是 Linux kernel 2.6 之后引入的新 I/O 事件驱动技术,它解决了select、poll在性能上的缺点,是目前IO多路复用的主流解决方案。
epoll 实现:
int epoll_create(int size);
int epoll_create1(int flags);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
struct epoll_event {
__uint32_t events;
epoll_data_t data;
};
union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
};
typedef union epoll_data epoll_data_t;1.epoll_creare、epoll_create1:这两个函数的作用是一样的,都是创建一个epoll实例。
- epoll_ctl:在创建完 epoll 实例之后,可以通过调用 epoll_ctl 往 epoll 实例增加或删除需要监控的IO事件。
epoll_ctl:在创建完 epoll 实例之后,可以通过调用 epoll_ctl 往 epoll 实例增加或删除需要监控的IO事件。
epfd:调用 epoll_create 创建的 epoll 获得的返回值,可以简单理解成是 epoll 实例的唯一标识。
op:表示是增加还是删除一个监控事件,它有三个选项可供选择:
EPOLL_CTL_ADD: 向 epoll 实例注册文件描述符对应的事件;
EPOLL_CTL_DEL:向 epoll 实例删除文件描述符对应的事件;
EPOLL_CTL_MOD: 修改文件描述符对应的事件。
fd:需要注册的事件的文件描述符。
epoll_event:表示需要注册的事件类型,并且可以在这个结构体里设置用户需要的数据。
events:表示需要注册的事件类型,可选值在下文的 Linux 常见网络IO事件定义中列出
data:可以存放用户自定义的数据。
人性化来了,可以自己删除和添加了,不用一次性给了。
3.epoll_wait:调用者进程调用该函数等待I/O 事件就绪。
epfd: epoll 实例的唯一标识。
epoll_event:相关事件
maxevents:一个大于 0 的整数,表示 epoll_wait 可以返回的最大事件值。
timeout:
-1:一直阻塞,直到检测的集合中有就绪的IO事件,然后解除阻塞函数返回
0:不阻塞,不管检测集合中有没有已就绪的IO事件,函数马上返回
大于0:表示 epoll 调用方等待指定的毫秒数后返回在内核中eventpoll结构如下:
struct eventpoll {
/* Wait queue used by sys_epoll_wait() */
wait_queue_head_t wq;
/* List of ready file descriptors */
struct list_head rdllist;
/* RB tree root used to store monitored fd structs */
struct rb_root_cached rbr;
}wq:当用户进程执行了epoll_wait导致了阻塞后,用户进程就会存储到这,等待后续数据准备完成后唤醒。
rdllist:当某个文件描述符就绪了后,就会从rbr移动到这。其本质是一个链表。
rbr:用户调用epoll_ctl增加的文件描述都存储在这,其本质是一颗红黑树。
先不介绍红黑树,到了红黑树介绍的时候再画图,不然这个过程可能比较难理解为啥epoll这么高效,除非利用了红黑树,那么看下这个改变的地方。
- 我们多个进程可以监控利用epoll_ctl进行监控,其实一般就一个,根据业务也可以多个
- 当触发事件的时候呢,就触发的事件再rbr中移除,然后加入到了rdllist中(之所以要移除就说明触发了,就不需要再继续监控该事件了呗)
- 当rdllist里面有事件后,那么就会获取到wq等待的进程,进行通知,也就是说epoll_wait就已经返回了相关的epoll_event,不需要再轮训一遍了
相当人性化哈,这是我们理解了我们作为用户和操作系统直接的沟通桥梁塑造好了,所以效率也就高了。
那么问题来了,为啥epoll的效率这么高呢,除了解决和操作系统的沟通问题,还要什么经过优化呢,后续关于红黑树的介绍,黑红树之所以再这里能发挥作用就是因为其频繁的加入和删除,以及遍历。
那么请问epoll是阻塞io,还是非阻塞io呢?
那肯定是阻塞io嘛,有个timeout当事件到了就返回了,但是也属于阻塞。
然后呢,我们如果用c语言的时候,发现网络io和磁盘io其实是用不同的库,但是他们也的确可以用的底层函数read读取,都抽象成文件了嘛,之所以用不同的库是因为这两个方向针对的场景的确不同,库嘛,肯定是帮忙封装好了的,用好库比啥都重要。
结
后续操作系统系列慢慢整理,红黑树也得整理下,以上个人简单整理和理解,如有错误忘请指正。