1. 视觉多模态简介
视觉多模态一般涵盖2个要点:视觉表征 以及 视觉与自然语言的对齐(Visual Language Alignment)或融合。
1.1. 视觉表征
视觉表征是指:将图像信息转化为深度学习模型可以处理的特征向量或向量序列的过程。具体来说,它包含以下2点:
- 合理建模视觉输入特征:这是指通过卷积神经网络(CNN)或Vision Transformer(VIT)等方法来提取图像中的关键特征
- 通过预训练手段进行充分学习表征:这意味着利用大规模数据集进行无监督或弱监督的训练,使模型能够学习到通用的视觉特征。预训练阶段通常使用大量的标注或未标注图像,让模型学习到广泛适用的特征表示。
这两点是完成基于视觉的任务的基础。从视觉表展的技术发展来说,有两个主要阶段:卷积神经网络和Vision Transformer(ViT)。两者都有各自的视觉表征方式、与训练以及多模态对齐过程。目前CNN已不再是主流,所以下面也不再介绍CNN,而是会介绍ViT。
1.2. Visual Language Alignment
视觉与自然语言的对齐(Visual Language Alignment,VLA)在多模态学习中,指的是将视觉信息(例如图像)和语言信息(例如文本)进行有效结合的过程。这种对齐的目标是希望让模型能够理解和生成与图像内容相关的文本描述,或者根据文本描述检索和识别图像中的内容。
更具体的来说,就是希望将视觉表征和自然语言表征建模到同一个表征空间,使得它们相互理解并融合,实现两者的互通。这个过程也称模态对齐,通过模型训练完成。
模态对齐是处理多模态问题的基础,也是目前流行的多模态大模型基础。在下文中,我们统一使用"多模态对齐"来表示VLA。
2. Vision Transformer
Vision Transformer(ViT)模型于2021年在《An Image is Worth 16*16 Words: Transformers for Image Recognition at Scale》中首次提出。ViT的微调代码和预训练模型可在Google Research的GitHub上获取。这些ViT模型在ImageNet和ImageNet-21k数据集上进行预训练。
ViT广泛应用于流行的图像识别任务,如目标检测、图像分割、图像分类和动作识别。此外,ViT还被应用于生成式建模和多模态任务,包括视觉定位、视觉问答以及视觉推理。
在ViT中,图像被表示为序列,模型通过预测图像的类别标签来学习图像的结构特征。输入图像被视为一组小块(patches),每个小块(patch)通过将其像素的通道扁平化为一个向量,然后线性映射到所需的输入维度。
下面逐步解析Vision Transformer的架构:
- 将图像分割为小块(分割成小块的原因是减少attention的计算量,如果使用原始像素点作为基本单元,则计算量太大)
- 扁平化(Flatten)这些小块
- 对扁平化的小块生成低维线性嵌入
- 添加位置嵌入
- 将序列输入到标准Transformer Encoder
- 使用图像标签在大规模数据集上对模型进行预训练(完全监督学习)
- 在下游数据集上进行微调以完成图像分类任
过程如下图所示:

图像块在ViT中相当于序列中的标记(类似于单词)。编码器块的结构与Vaswani等人(2017年)提出的原始Transformer完全相同。
在ViT Encoder中包含多个block,每个block由以下三个主要处理单元组成:
- 层归一化(Layer Norm)
- 多头注意力网络(Multi-head Attention Network, MSP)
- 多层感知机(Multi-Layer Perceptrons, MLP)
这几个组件其实和原始Transformer Encoder中的结构基本一致。最后CLS token对应的输出表征,再输入到MLP+softmax即可用于生成分类标签(以图像分类任务为例)。之前若是有对Transformer的结构有过了解,是可以非常容易理解ViT的架构。本质上是图片切割成小块后,充当了文本token的角色,其中位置编码的概念也和原始Encoder一致。
ViT 在计算机视觉(CV)任务中的有效性得到了验证,削弱了卷积神经网络(CNN)在 CV 领域的主导地位。同时,ViT的出现也为开发视觉模型提供了重要基础。在后续由 Google 在2021年推出的视觉模型的 ViT-MoE,拥有 150 亿个参数,在当时的 ImageNet分类中也是创下了新纪录。ViT这种Transformer 的架构需要大量的数据才能实现高准确率,这也是它成功的秘诀。如果在数据较少的情况下,CNN 通常比 Transformer 表现更好。因此,后续的一大研究方向就是如何更加有效的对ViT结构的网络进行预训练,例如MAE(Masked AutoEncoder)和BEIT(BERT Pre-Training of Image Transformers)。
3. 多模态对齐
在了解了视觉表征以及代表模型后,我们再看看多模态对齐方法。多模态对齐涉及将不同来源和类型的数据(例如图像、文本、音频等)结合起来,以便模型可以从多个角度理解数据。下面我们以CLIP为例,介绍如何做图片和文本模态的对齐。
4. CLIP
在多模态对齐中,CLIP(Contrastive Language-Image Pre-training)是OpenAI推出的一种多模态对齐方法。它是一种结合了图像和文本的嵌入式模型,使用4亿张图像和文本对,以自监督的方式进行训练的来。也就是说,它可以将文本和图像映射到同一个嵌入空间。举个例子来说,对于一张包含小狗的图片,以及文本"一张狗的图片",这两个对象在投射到同一个向量空间后,它们俩的距离时非常相近的。在这个基础之上,便可以衍生出各种多模态的应用,例如使用自然语言描述搜索图片。
除了本身训练的任务之外,CLIP 可以用于许多它未经过训练的任务。例如,在 ImageNet 等基准测试数据集上,它展示了非常好的zero-shot learning能力。CLIP 并未显式地在ImageNet其中 128 万个训练样本上进行训练。但是,CLIP 的准确率与原始的 ResNet-50(在该数据上训练的模型)基本一致。
那如何用 CLIP 进行图像分类?以 ImageNet 为例,假设它有 1000 个可能的类别或对象。可以通过 CLIP 使用提示语 "a photo of a {object}"(例如 "a photo of a dog" 或 "a photo of a cat")对每个类别进行嵌入,得到这个类别的embedding。而后我们就得到了 1000 个对应于所有可能类别的embedding。接着,取你想要分类的图像,例如一张狗的照片,并用 CLIP 对该图像进行嵌入得到图片的embedding。最后,将图像嵌入与所有文本嵌入计算点积。由于 CLIP 的训练方式是使图像和文本共享相同的嵌入空间,而点积计算嵌入之间的相似性,因此"a photo of a dog"的点积结果很可能是最高的。因此可以预测这张图像是狗。
需要注意的是,如果希望将 CLIP 转变为一个真正的分类器,则可以将点积结果通过 softmax 函数,从而得到每个类别的预测概率。
上述过程可以在下图的第 2 和第 3 步中看到:

4.1. CLIP模型结构
CLIP模型有2个主要模块,text encoder和image encoder,Text encoder部分使用的是transformer。对于image encoder,作者尝试了2个不同的模型,ResNet-50和ViT,发现使用ViT训练速度更快(text encoder和image encoder均未复用预训练过的参数):
"最大的 ResNet 模型 RN50x64 使用 592 个 V100 GPU 训练了 18 天,而最大的 Vision Transformer 使用 256 个 V100 GPU 训练了 12 天"
4.2. 训练
作者最初是尝试训练一个生成图片描述的模型,给定一张图片,预测它的准确的标题或描述。初始方法类似于 VirTex,从零开始联合训练一个图像 CNN 和一个文本 Transformer 来预测图像的标题。但是随后发现这种方法在扩展到大规模数据时遇到了效率问题。他们发现这种方法无法有效地扩展到训练 4 亿对(图像-文本)数据集,因此他们选择了一种对比表示学习(contrastive representation learning)方法。
4.2.1. 对比表示学习
对比表示学习(Contrastive Representation Learning)是一种自监督学习方法,其核心思想是通过比较数据样本之间的相似性或差异性来驱动模型学习良好的特征或表征。这种方法的目标是确保相似的数据样本在特征空间中彼此接近,而不相似的数据样本彼此远离。当模型在这种任务上表现良好时,它已经学会了区分数据的关键特征,这种特征表征为后续的监督学习任务(如分类、回归等)可以提供有利的起点。
对比表示学习的基本框架一般包括以下几个关键组件:
- 数据增强:通过对原始数据样本进行变换,生成正样本对。
- 正负样本构建:正样本通常通过对原数据样本进行数据增强得到,而负样本通常是从数据集中随机选取的,它们不与当前的正样本对有直接关联。
- 网络结构:设计神经网络以学习区分正负样本的特征表示。
- 损失函数(Loss Function):使用特定的损失函数来优化模型,使得正样本的表示更接近,负样本的表示更远离。
在标准的对比表示学习方法中,模型接受的样本形式为(anchor,positive,negative)。anchor表示来自某一个类别的图片(例如一只狗的图片),positive是同一个类别的另一张图片(例如也是狗),negative表示来自其他类别的图片(例如一只鸟的图片)。随后对这些图片进行嵌入,并训练模型达成以下目标:最小化同一个类别embedding之间的距离,即minimize distance(anchor, positive);同时最大化不同类别embedding之间的距离,即maximize distance(anchor, negative)。这种方法鼓励模型对相同类别的对象输出非常相似的嵌入,而对不同类别的对象输出差异较大的嵌入。
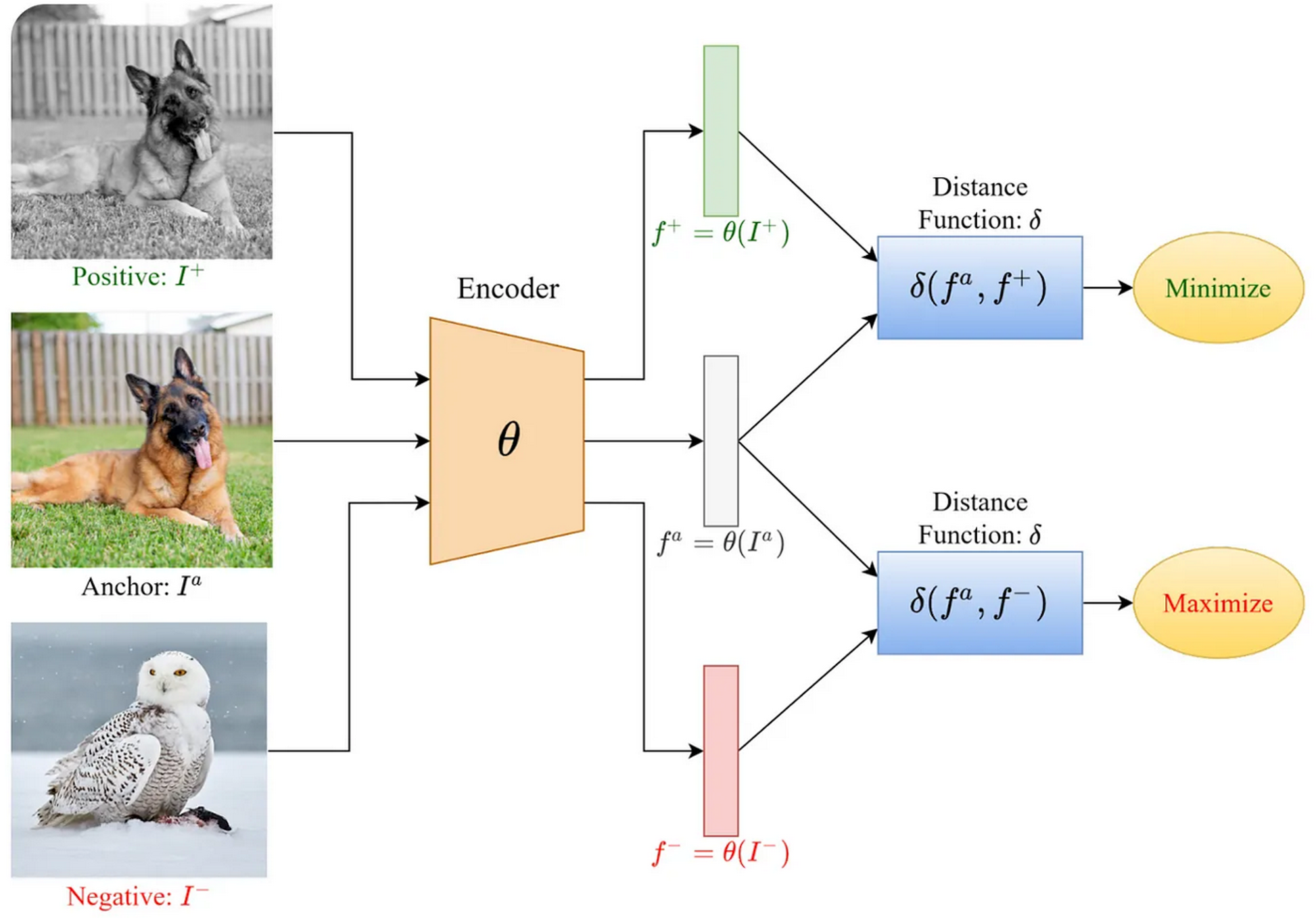
Fig. A visualization of contrastive learning[4]
同样的方法可以应用于文本以及图像和文本的组合。例如,在 CLIP 的单个训练样本中,anchor 可以是狗的图像,positive可以是文本标题"狗的图像",而 negative 可以是文本标题"鸟的图像"。
CLIP 更进一步地推广了这一方法,使用了一种多类别 N 对损失函数(multi-class N-pair loss),这是上述方法的扩展,适用于每个 anchor 有多个 positive 和 negative 的情况。具体地说:
给定一个包含 N 对(图像,文本)样本的批次,CLIP 在训练时预测批次中 N × N 个可能的(图像,文本)配对中哪些是真实的。为此,CLIP 联合训练image encoder和text encoder,学习出一个多模态嵌入空间,以最大化批次中 N 对真实配对的image embedding和text embedding的余弦相似度,同时最小化 N² − N 个错误配对的embedding余弦相似度。然后通过这些相似度分数优化对称交叉熵损失。
论文中提供的伪代码很好地总结了这一核心细节:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2步骤包括:
- 使用image encoder对图像进行嵌入,并使用text encoder对文本进行嵌入。
- 由于图像和文本的嵌入来自不同的模型,维度可能不同,需要通过一个可学习的投影矩阵将它们投影到相同的联合多模态嵌入空间。例如,np.dot(I_f, W_i)将大小为 n, d_i 的矩阵与大小为 d_i, d_e 的矩阵相乘,结果是一个大小为 n, d_e 的投影矩阵。
- 对新的嵌入向量进行归一化,将它们转化为单位向量。
- 计算点积矩阵。
- 对每一行和每一列计算交叉熵损失,并除以 2,因为每对样本会被计算两次
4.3. Prompt Engineer
由于 CLIP 的文本编码器是一个 Transformer 模型,作者发现Prompt Engineer(PE)对获得良好的Zero-shot性能也非常关键。在其预训练数据集中,文本与图像配对的情况中,单个词语(例如,"dog" 作为类别标签)相对较少见,更常见的是文本为完整的句子,例如图像的标题或描述。因此,作者发现使用提示语 "a photo of a {object}" 是一个不错的默认选择,但在某些特定情况下,更专门化的提示语效果更佳。例如,对于卫星图像,作者发现使用 "a satellite photo of a {object}" 效果更好。
4.4. Limitation
尽管论文中进行了许多实验并展示了相应结果,但也需要指出,CLIP 并非完美,存在一些局限性:
- 非生成模型:CLIP从设计上来看,并不是生成模型,因此无法实现例如图像字幕生成这样的任务
- 性能与泛化能力不足: 作者指出,CLIP 仍远未达到最先进水平(仅能与在 ResNet 顶层加线性层的模型相媲美)。对于某些任务,它的泛化能力非常差。例如,在简单的 MNIST 手写数字识别数据集上,CLIP 的准确率仅为 88%。这可能是因为训练集中缺乏类似图像,但 CLIP 对此问题几乎没有改进。
- 文本长度限制: Transformer text encoder的最大序列长度(即可以传递的最大 token 数)在原始实现中被限制为 76。因为数据集主要是图像和标题,通常是较短的句子。因此,使用现成的预训练模型处理较长文本时效果不佳,超过 76 个 token 的文本会被截断,而训练时的文本也主要是短文本。
4.5. 后续相关研究
CLIP 可以应用于多种场景,尤其是在语义搜索类的应用中。例如,我们可以通过描述图像的文字在数据库中检索图像。CLIP 的想法及其替代方案也成为了自此以来许多多模态模型的构建基础。例如,在 Flamingo 这种视觉语言模型中,它可以同时处理一系列文本和图像并生成文本。
5. Flamingo视觉语言模型
前面介绍中也提到,CLIP并非是一种生成式模型,它提出了一种图片和文本模态对齐的方法,将图片与文本投射到同一个嵌入空间内,使得它们可以相互比较。这里要介绍的Flamingo模型一个视觉语言模型,是早期多模态生成式模型中一个比较有代表性的模型。
Flamingo 于 2022 年在论文《Flamingo: a Visual Language Model for Few-Shot Learning》中首次提出。这是一种多模态语言模型(实际上是不同规模模型的一个家族,其中 Flamingo 是size最大的一种)。它的多模态特性意味着它可以接收多种模态的输入,同时像语言模型一样生成文本。
如论文中所示,Flamingo 能够在给定一些示例的情况下,通过文本和图像进行生成式推理(few-shot learning),如下图所示:

上图中最后一个例子也给出了Flamingo如何和视频结合的例子。视频可以分割为帧(以1 FPS采样),然后作为序列传入给模型。
除此之外,Flamingo也能做基于多张图片的对话:

以及QA:

5.1. 模型架构
前面也提到,Flamingo是生成式模型,所以它也是一个标准的自回归模式,基于前面的输入序列,预测下一个token。
Flamingo模型的输入是交替排列的视觉/文本数据。图像会从文本中抽取出来,并用一个通用标记(例如 `<image>`)替换。随后,这些数据传递到普通的语言模型block中。同时,图像会单独通过视觉编码器模型处理,转换为固定大小的嵌入向量。然后,这些嵌入向量通过一种cross-attention机制进行"关注"。如下图所示:
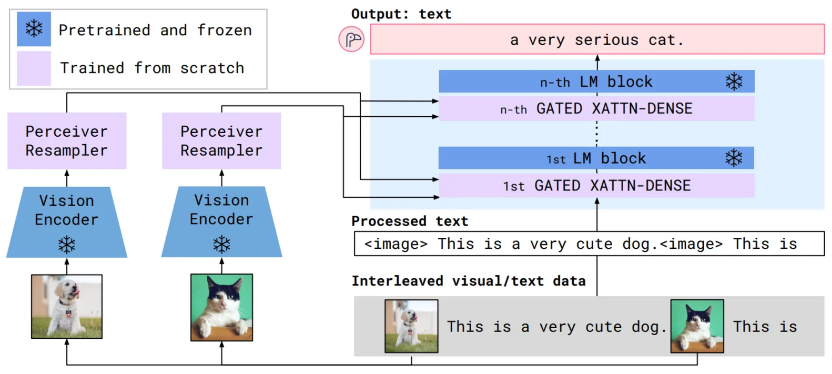
Flamingo 模型利用了两个互为补充的预训练且冻结的模型:一个能够"感知"视觉场景的视觉模型,以及一个执行基本推理的大型语言模型(LM)。在这些模型之间添加了新的架构组件进行连接它们,同时保留它们在预训练过程中积累的知识。
在Vision Encoder部分,模型使用的视觉编码器与CLIP模型非常相似。视觉编码器与文本编码器一起训练,使用这两个编码器,将图像和文本映射到同一个向量空间,并进行L2归一化处理。训练过程类似于CLIP,也采用了对比表示学习以及multi-class N-pair loss。不同的是,CLIP使用的是ViT,Flamingo使用的是Normalizer-Free Resnet。在预训练完成后,视觉编码器的模型参数便冻结,后续不再进行更新。
在Vision Encoder输出后,我们可以看到一个Perceiver Resampler组件,它是由Perceiver衍生而来。Perceiver Resampler的作用就是:接收可变数量的视觉特征,并将它们转换为固定数量的token输出。然后视觉特征会与文本特征在多个LM block中进行"融合",简单地说,"融合"的方式就是用文本特征作为Q,视觉特征作为K和V,然后通过cross attention的方式进行"融合",这种"融合"可以直观的理解为:在语言模型内关注视觉部分的输入。后续结构也和Transformer Decoder结构基本一致,在输出时通过前馈网络+softmax的方进行分类,然后采样输出下一个token。
Flamingo的文本模型使用Chinchilla,是谷歌发布的对标GPT-3的语言模型,并提供了1.4B、7B、和70B版本,分别对应Flamingo-3B、Flamingo-9B和Flamingo-80B。
5.2. Perceiver
Perceiver的推出的一个重要原因是为了解决原始transformer模型无法处理场序列的瓶颈。在transformer架构中,由于self-attention的复杂度是O(S2),所以若是序列非常长,则会产生大量的计算量,特别是在尝试将Transformer的结构用于视觉数据时。在描述一张图片所需要的像素数量是远远超过一段文本所需的token数量的。前面介绍的ViT是通过将图像分割为多个块从而减少序列的长度,这种方法虽然减少了计算量,但其缺点是对输入数据做了假设,从而会导致归纳偏差。
2021年提出的Perceiver的通用架构,便是一种替代方案,可以用来处理各种模态的数据,并能扩展至处理数十万级别的输入,是多模态处理里一个重要的里程碑。
(值得一提的事,在解决长序列的计算复杂性的问题上,目前也有一些新的方法,例如Mistral 7B里使用的滑动窗口注意力机制。滑动窗口注意力机制的核心思想是将输入特征(如图像或文本)划分为多个局部窗口,每个窗口内的特征计算注意力权重,并在这些窗口间进行滑动,逐步覆盖整个输入的所有特征。这种方法可以减少计算量,并保持局部依赖性,同时避免了全局注意力机制中的高计算复杂度问题。)
下图是Perceiver的架构:

在Perceiver模型中,K和V是从输入序列(称为byte array,例如一幅图像)的投影得到的(Q、K以及后面的V本质上都是参数矩阵,概念来源于Attention机制)。这个输入序列的长度M非常大(例如对于224x224大小的ImageNet图像来说已超过50,000),直接将它输入到Transformer中会带来巨大的计算开销。因此,他们使用了一个固定大小的latent array(潜数组),其大小为N(N远小于M,比如512)。查询矩阵Q则是从这个latent array进行投影得到的。Perceiver采用了一种交叉注意力机制,利用这个latent array来关注byte array中的token。这种机制与原始Transformer Decoder类似,其复杂度随byte array大小线性增长,即O(NM)。接下来,可以对latent array应用标准的Transformer流程,包括对latent array执行自注意力操作,其复杂度为O(N²)。这样整体的复杂度就变成了O(NM) + O(N²),其中N远小于M。重要的是,由于N较小,这使得可以在大规模数据上构建包含许多Transformer层的大规模网络成为可能,如果复杂度为O(M²)的话这是不可行的。这种使用潜在空间的方法是在其他模型如Stable Diffusion中常见的计算技巧。
5.3. Limitation
Flamingo作为一个语言类生成式模型,也具有语言类生成式模型中常见的问题,如幻觉、输出攻击性语言、传播社会偏见和刻板印象,以及泄露私人信息。它能够处理视觉输入的能力也带来了特定的风险,例如与输入图像内容相关的性别和种族歧视。下图是原文中展示的一个例子:
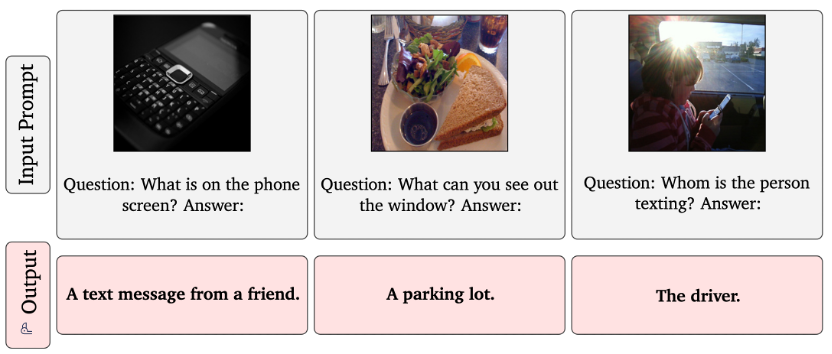
6. 总结
本文介绍了视觉多模态的基本概念,例如视觉表征 以及 视觉与自然语言对齐(VLA)两个主要要素。视觉表征涉及通过卷积神经网络(CNN)或Vision Transformer(ViT)等方法提取图像特征,并通过预训练使模型学习通用视觉特征。
在视觉与自然语言对齐方面,以CLIP为例,介绍了如何利用对比表示学习方法将图像和文本映射到同一嵌入空间中,实现跨模态的相似性匹配。CLIP展示了良好的zero shot learning能力,但存在一些局限性,如非生成模型、性能限制以及文本长度限制。
在视觉多模态理解以及文本生成方面,介绍的Flamingo是一个早期非常有代表性的视觉语言模型,它结合了视觉编码器和语言模型,能够处理多种模态输入并生成文本。不过,Flamingo同样面临生成式模型常见的挑战,如幻觉、偏见等问题。
References
1 一文看完多模态,从视觉表征到多模态大模型:https://zhuanlan.zhihu.com/p/684472814
2 Vision Transformer: What It Is & How It Works:https://www.v7labs.com/blog/vision-transformer-guide
3 Understanding OpenAI's CLIP model: https://medium.com/@paluchasz/understanding-openais-clip-model-6b52bade3fa3
4 The Beginner's Guide to Contrastive Learning: https://www.v7labs.com/blog/contrastive-learning-guide
5 Understanding DeepMind's Flamingo Visual Language Models: https://medium.com/@paluchasz/understanding-flamingo-visual-language-models-bea5eeb05268
6 Flamingo: a Visual Language Model for Few-Shot Learning: https://arxiv.org/abs/2204.14198