

01.
背景
AI业务快速增长下传统关系型数据库无法满足需求。
2024年恰逢OPPO品牌20周年,OPPO也宣布正式进入AI手机的时代。超千万用户开始通过例如通话摘要、新小布助手、小布照相馆等搭载在OPPO手机上的应用体验AI能力。
与传统的应用不同的是,在AI驱动的应用中,数据库面临的数据处理需求已经发生了根本性的变化。高维数据(如图像、文本和音频)的快速积累和使用场景的多样性,要求数据库不仅需要存储海量数据,还需要可以高效地进行复杂的数据检索。然而,传统关系型数据库由于其设计初衷是为结构化数据服务,因此在处理非结构化和高维数据时,逐渐暴露出其局限性。这直接导致它们在应对现代AI业务需求方面显得捉襟见肘,难以满足实时数据写入、大规模并发查询以及快速相似性搜索等要求。
02.
万物皆可Embedding
非结构化数据的种类和使用场景复杂,几乎无法定义,让计算机程序理解都非常困难,更不用说数据库了。为了能够统一处理和表达非结构化数据,业界通用的方法是使用Embedding。Embedding 是一种将高维稀疏数据转换为低维稠密向量的技术,广泛应用于自然语言处理(NLP)、图像处理、推荐系统等领域。通过 Embedding,复杂的输入数据可以被编码成固定长度的向量,使得这些数据可以在向量空间中进行高效计算和处理。
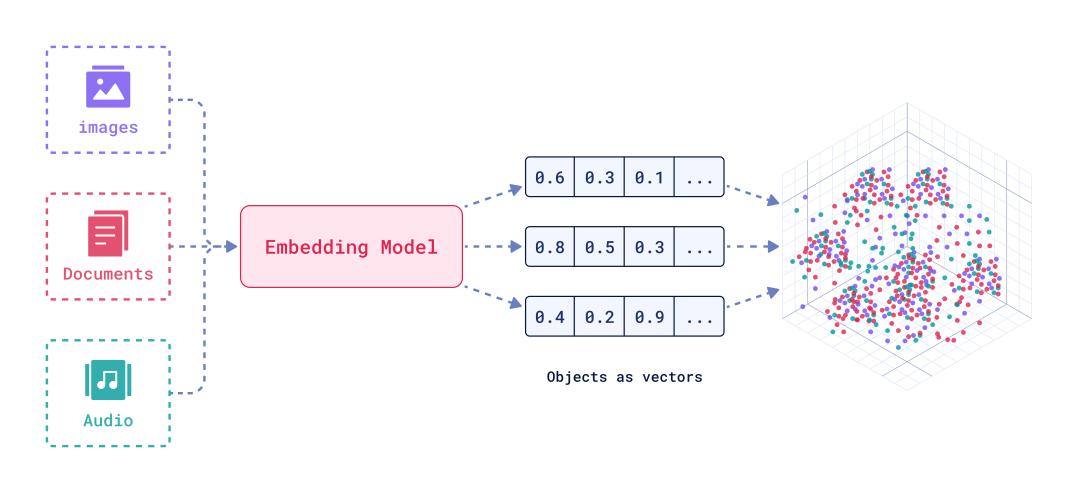
在Embedding的基础上,由非结构化数据引入的挑战演变为了如何对向量数据进行存储和检索的问题。
03.
OPPO对向量检索的探索
在业务初期,由于数据量较小、使用场景较为简单,数据存储使用本地文件,数据检索就是把全量数据加载在内存中完成。配合上HNSW, Faiss等开源库,可以很好解决问题。
但是当业务开始快速增长,上面这一条玩法很快就出现了问题:
-
数据容量:单个服务节点的内存无法承载全量向量数据;
-
查询性能:单机性能无法满足查询需求;
-
数据持久化:数据从加载到内存,直到生命周期结束后释放,没有被很好的持久化;
-
文件管理:数据、索引等文件难以被统一管理。
很自然的,向量检索开始从单机向分布式的方向进行演进,根据上面的问题提出的解决方法就是:
-
数据分片:对向量数据根据某一规则切分后加载在不同的节点上;
-
服务发现:能够对整个集群内的节点、数据进行统一管理。
基于上述思想,OPPO提出并实践了一套分布式向量检索服务:
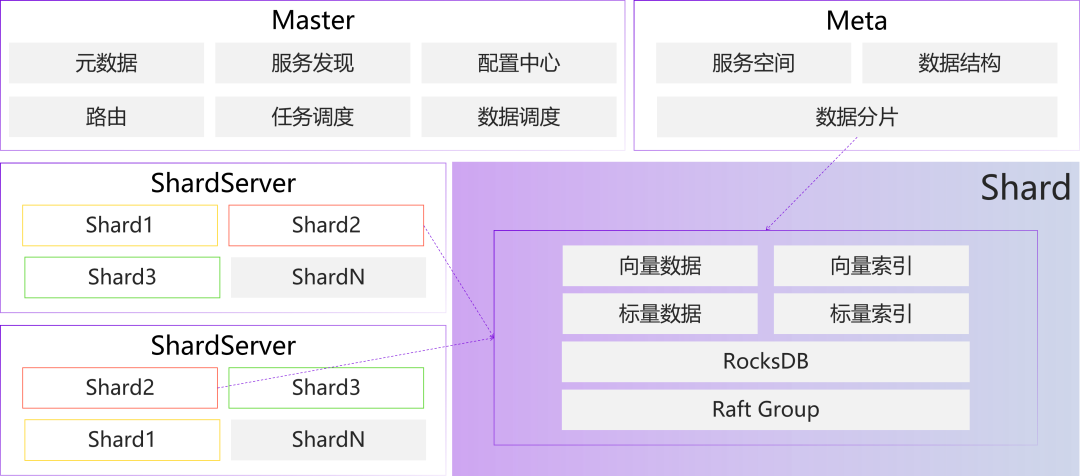
整个系统在简化后可以被分为Master和ShardServer两个部分:其中Master负责整个集群的元数据管理和调度管理,存放集群的数据分布信息和整体的路由结构信息等;ShardServer负责具体的向量数据存储和检索服务。
-
节点管理:Master本身是一个至少3节点的高可用组件,集群中的其他节点会向Master进行服务注册,由Master进行节点的管理;
-
数据分片:数据分片在系统中是一个Shard的逻辑概念,其中每个Shard中会包含该数据分片的向量数据、标量数据等,其底层使用RocksDB进行数据持久化,并且通过Raft Group实现每个Shard的高可用。ShardServer是物理上承载Shard的角色,每个ShardServer会保存若干个Shard,不同的ShardServer之间完成Raft Group的数据交换。
04.
Why Milvus?
上述的分布式向量检索实际上已经把向量检索这一功能服务化了,但是这个系统中还是存在一些不足,例如数据和节点绑定在了一起,虽然对数据做了分片但是对集群的扩展不是那么丝滑。另外,对于向量检索结果的合并、检索过程中的失败处理等都是非常棘手的问题,所以,OPPO决定引入更加稳定的开源解决方案 --- Milvus。
在对向量数据库做选型的时候,我们考虑的主要的点是:
-
性能:Embedding在调用链中的耗时要求很高,业务对性能十分敏感;
-
容量:业务增长快速,需要对未来很长一段时间的数据容量有保障;
-
扩展性:支持的索引类型、是否支持标量过滤等,是否可以覆盖大部分业务场景;
-
运维难度:作为一个较新的技术领域,我们需要考虑运维成本,以及关注弹性与故障自愈等特性;
-
成本:向量数据常驻内存的特性会导致其成本相较于传统数据库更高,因此也需要考虑。
最后选择Milvus也是基于以上的考虑:
-
性能优越:根据VectorBench的测试,Milvus的性能优于同类型向量数据库,尤其是大幅领先于插件式引擎;
-
容量支持与水平扩容:Milvus支持水平扩容,能够处理十亿级别的数据量;
-
扩展性:Milvus相比同类产品支持更多的向量索引类型,并且支持标量过滤,能够覆盖更多的业务场景;
-
运维成本低:Milvus的云原生特性和存算分离的架构设计,大大减轻了运维成本;
-
成本控制:通过DiskANN技术,对于一些非重点业务(如内部审计系统),可以大幅降低存储成本。
05.
Milvus实践 --- 小布助手
OPPO的小布助手是一个非常典型的使用Milvus的应用。
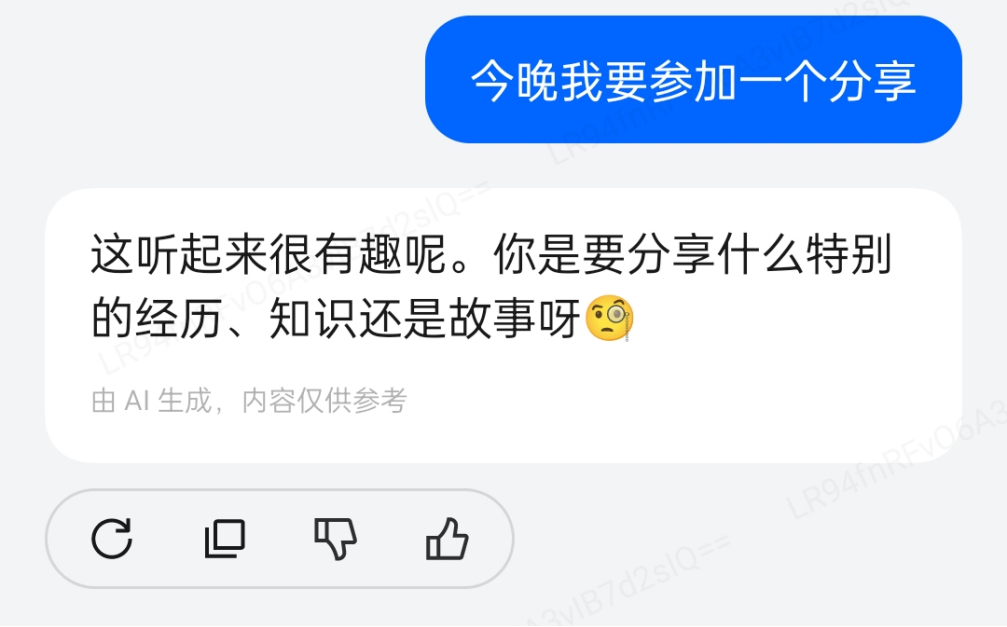
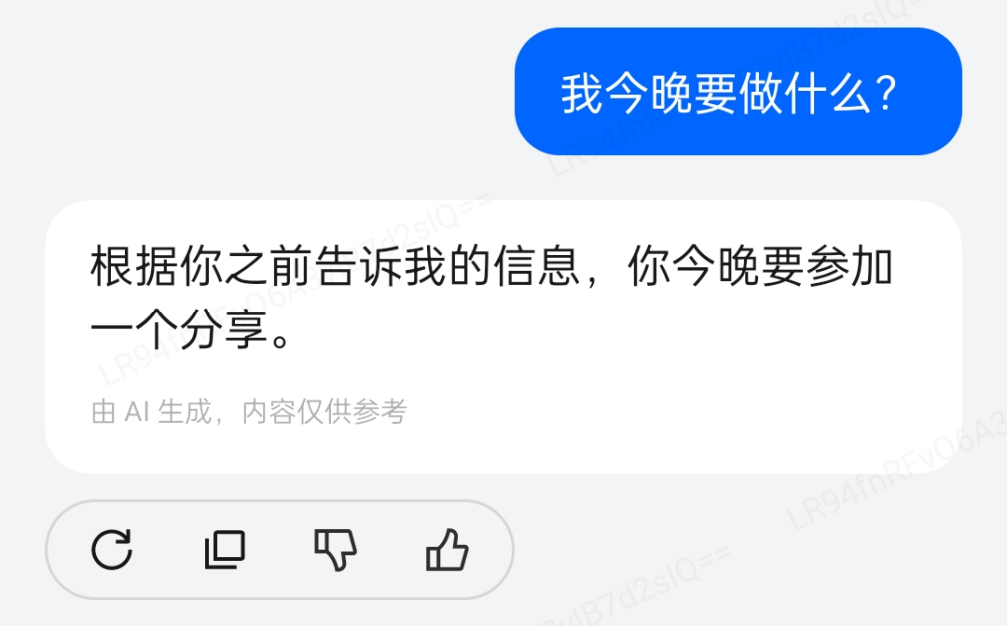
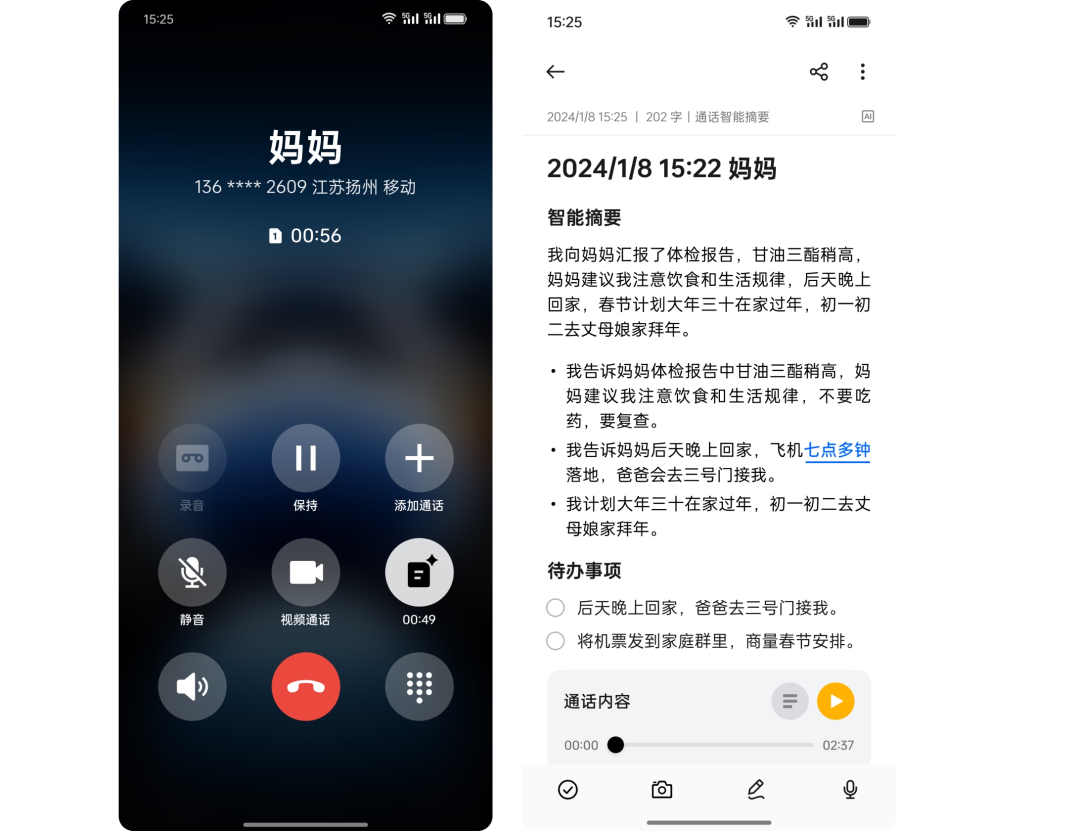
如图所示,小布助手会记录多轮对话中的信息,并且在后续的聊天中使用。这就是小布助手的「基础记忆」能力。为了实现以上能力,小布助手需要存储海量的向量数据,而且为了保证小布助手的反馈效率,还需要保证向量检索的效率。
为了服务小布助手,我们搭建了一个包含上百个QueryNode节点的集群,通过划分资源组的方式,实现对不同优先级的表隔离管理。另外,在基础记忆的业务场景中数据都是和用户相关联的,根据用户ID进行分表,再根据数据写入时间区分Partition,来减少单次数据检索的范围。
截止目前,基础记忆相关业务已经在Milvus中存储了上亿条向量数据,内存空间到达TB级别。
06.
写在最后
向量数据库是一个DB For AI的场景,传统的数据库无法满足AI业务的需求从而诞生了向量数据库。但是我们在这个过程中也越来越看到AI For DB的可能性。
-
传统的数据库开始推出例如PgVector, MySQL Vector Type来适应新的变化;
-
Milvus的云原生架构给我们对数据库未来演进的方向提供了参考;
-
AI开始在数据库的故障排查、数据治理中起到越来越重要的角色;
...
从RDBMS, NoSQL, NewSQL到现在的Unstructured Data,我们看到数据库在AI浪潮下扮演的重要角色,也看到了数据库更多的可能性。最后我想起参加完Zilliz的Meetup后的感想:从向量数据库到AI的每次接触都能感受到其潜力和魅力。谢谢!
作者介绍


推荐阅读



