简介:本文围绕 Xpath 路径表达式展开讲解,先是介绍了网页相关基础如 html、css、vue 以及前后端分离的概念与示例,包括各部分的结构、作用及简单代码展示,随后详细阐述了 xml 的节点关系、选取节点、谓语等理论知识,最后通过百度贴吧图片下载这一实战应用,分步骤详细展示了利用 Xpath 进行图片爬取及保存的完整流程,帮助读者理解并掌握 Xpath 在实际爬虫中的运用。
本文肯定会让你有所收获,请你点赞收藏关注。十分抱歉我将会把本爬虫专栏的文章转为付费专栏。您也别用开源这种道德绑架我,我没道德,是人就要恰饭的。我花费了这么多时间,精力,挣点钱不过分。仓廪实而知礼节,我又不富裕,花这么多时间精力难不成就应该饿死?
Xpath 路径表达式全解析:从网页基础到实战应用
Xpath路径表达式
Xpath是一种在网页中筛选出所需要信息的一种方式,爬虫对于网页我们需要对html 、css、vue、前后端分离有一些基础的了解,我将从 多个方面讲解,在最后列举Xpath的实战应用。请大家耐心阅读。虽然看起来挺多,可是不是很难,而且我会用最通俗的语言给大家讲解清楚。
html是什么?
是一种用于创建网页的标准标记语言。它通过一系列的标签(tag)来描述网页的结构和内容。
html的结构
HTML 文件,标签,它是整个 HTML 文档的根标签,所有其他标签都嵌套在其中。标签包含了文档标题、样式表引用、脚本引用等。标签包含了网页中实际显示的内容,如文本、图片、按钮等。
下面是一段小例子:
xml
<!DOCTYPE html>
<html>
<head>
<title>我的第一个网页</title>
</head>
<body>
<h1>欢迎来到我的网页</h1>
<p>这是一个简单的网页示例。在这里,你可以了解一些基本的HTML知识。</p>
<a href="https://www.example.com">点击这里访问其他网站</a>
</body>
</html>这个例子中:h1是一级标题,p是段落 ,a是超链接,body是展示在页面的所有内容。xpath起到了一个在这些标签中提取我们需要的信息的作用。但是在网页的源代码中我们还能看到css,比如下图,打开百度首页,开发者模式,画圈的部分class是用来设置属性的,比如某一段占多大的高度 宽度 颜色什么字体等等,这部分属于css,所以要对css有个了解:

css
下面这个例子中直接对标签进行了属颜色字体背景等等属性设置:
xml
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>CSS与HTML结合示例(内联样式)</title>
<style>
h1 {
color: blue;
font-size: 30px;
}
p {
color: green;
background-color: lightyellow;
}
button {
background-color: orange;
color: white;
padding: 10px 20px;
border: none;
border-radius: 5px;
}
</style>
</head>
<body>
<h1>这是一个标题</h1>
<p>这是一段正文内容,用来展示样式效果。</p>
<button>点击我呀</button>
</body>
</html>当然了用可以设置属性 然后给class赋值属性名来设置,因为在百度首页见过了,就不在列举了。后来随着技术进步,vue已经成为了使用量越来越高的新技术,他比css有一定的优势,当然我们学习爬虫的时候不需要会用,但是你不能没见过。vue看不懂无所谓的,重要的是你得见过。
vue
Vue 是一个用于构建用户界面的渐进式 JavaScript 框架。它采用了组件化的方式来构建 UI,使得开发者可以将一个复杂的用户界面拆分成多个独立的、可复用的组件。例如,一个电商网站的商品列表、购物车、商品详情页等都可以作为独立的组件来开发。这些组件可以包含自己的 HTML 模板、JavaScript 逻辑和 CSS 样式。
xml
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Vue Counter Example</title>
<!-- 引入Vue.js脚本 -->
<script src="https://unpkg.com/vue@3/dist/vue.global.js"></script>
</head>
<body>
<div id="app">
<p>计数器: {{ count }}</p>
<button @click="increment">加一</button>
<button @click="decrement">减一</button>
</div>
<script>
const { createApp } = Vue;
const app = createApp({
data() {
return {
count: 0
};
},
methods: {
increment() {
this.count++;
},
decrement() {
this.count--;
}
}
});
app.mount('#app');
</script>
</body>
</html>前后端分离
- 前端可以笼统的说(或者是不百分之百准确的说)他主要是浏览器的页面,跟用户交互。
- 后端呢是负责计算,比如验证用户名和密码需要前端接受,然后发送到后端数据库进行比对。
- 前后端分离的项目一般具有更好的应对问题的能力
- 我们爬虫要抓的包就是后端返还给前端的内容。
- 讲这个不是说他有多大的意义,而是你得知道你在做什么,心里踏实,脚踏实地。我们马上开始对Xpath的内容进行讲解。
xml的节点关系
父、子、同胞、先辈节点关系
下面这个案例:
xml
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>XML 父节点关系展示(静态示例)</title>
</head>
<body>
<h1>XML 父节点关系示例<a href="#">我是h1内部的超链接</a></h1>
<h2>h1的同胞节点</h2>
</body>
</html>- h1的父节点就是 body
- body的子节点就是 h1 和 h2
- 元素节点可以有0,1,多个子节点
- h1与h2是同胞节点
- a的先辈是 h1和body
选取节点
- nodename(节点名):选取此节点的所有子节点
- / :从根节点选取
- //:从匹配选择的当前节点选择文档中的节点,不考虑位置
- . :选取当前节点
- ...:先去当前节点的父节点
- @:选取属性
看不懂不会用没关系,等我们在讲案例的时候,我会逐渐分析问题,再回来查表,肯定能讲明白,记不住无所谓,用的时候回来查表就行。
谓语
有 【】的就是谓语:
- /bookstore/book1:选取属于bookstore子元素的第一个book元素
- /bookstore/booklast():选取属于bookstore子元素的最后一个book元素
- /bookstore/booklast()-1:选取倒数第二个book元素
- /bookstore/bookposition()❤️:选取最前面的两个book元素
- //title@lang:选取所有名为lang属性的title元素
- //title@lang='eng':选取所有名为lang属性且属性值为eng的title元素
- /bookstore/bookprice\>35:选取所有bookstore中的book元素且这些元素的price属性必须大于35
- /bookstore/bookprice\>35/title:选取所有bookstore中的book元素的title元素且这些title元素的父元素的price属性必须大于35
百度贴吧图片下载(验证xpath)
(第一步)打开这个页面,并复制URL
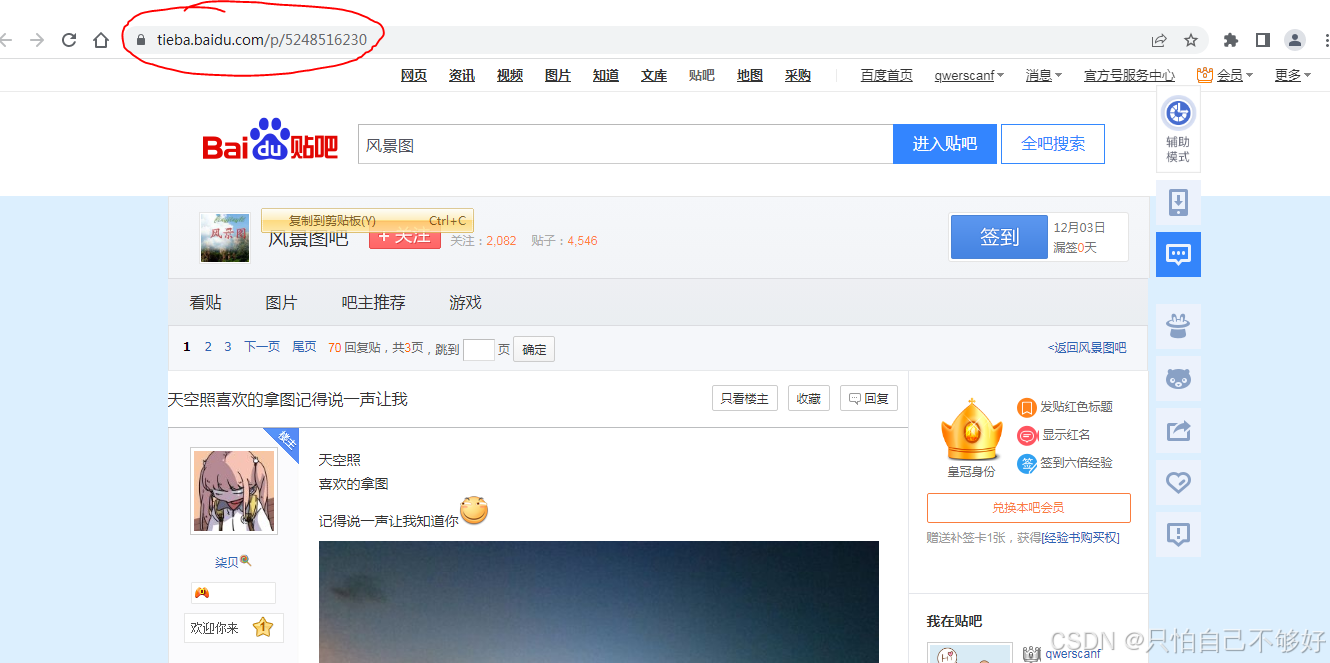
导入requests包,强调一点:一定要使用'''三引号存储URL字符串,避免可能出现的错误
python
import requests
URL = '''https://tieba.baidu.com/p/5248516230'''(第二步)右键图片检查查看他的html标签
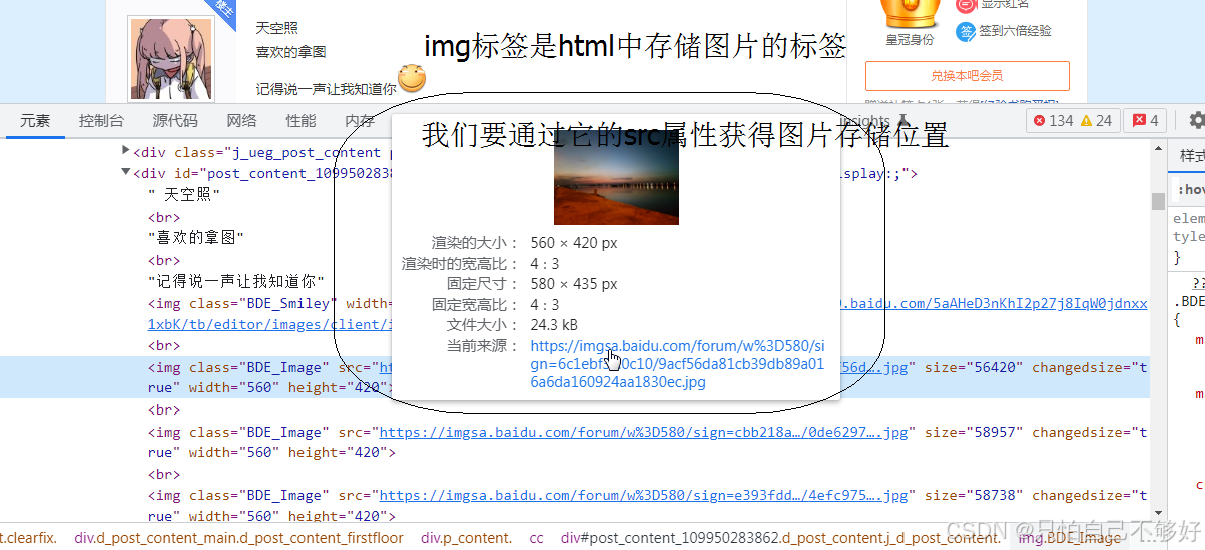
图中画圈的部分是img标签html中负责存储图片的标签,他的src属性是图片存储位置。发现这些图片标签都有着BDE_image属性,就可以通过这个属性爬取。
(第三步)定义headers请求头
任意找一个抓包 ,查看user-agent复制,并创建为字典的格式

python
headers = {'user-agent':'''Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'''}(第四步)使用requests.get并返回状态码
python
import requests
URL = '''https://tieba.baidu.com/p/5248516230'''
headers = {'user-agent':'''Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'''}
response = requests.get(URL,headers = headers)
print(response.status_code)
(第五步)使用lxml获取html中img的src并输出
我还是要反复强调在使用字符串的时候需要三引号,这段代码中的selector.xpath中的参数一定要使用三引号,养成一个好习惯,不然有的时候错了都找不到错在哪里
python
import requests
from lxml import etree
URL = '''https://tieba.baidu.com/p/5248516230'''
headers = {'user-agent':'''Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'''}
response = requests.get(URL,headers = headers)
response = response.text
selector = etree.HTML(response)
img_srcs = selector.xpath('''//img[@class = "BDE_Image"]/@src''')
for img_src in img_srcs:
print(img_src)
(第六步)把src爬取成图片并在本地创立图片文件
python
import requests
from lxml import etree
URL = '''https://tieba.baidu.com/p/5248516230'''
headers = {'user-agent':'''Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'''}
response = requests.get(URL,headers = headers)
response = response.text
selector = etree.HTML(response)
img_srcs = selector.xpath('''//img[@class = "BDE_Image"]/@src''')
position = 0
for img_src in img_srcs:
image_content = requests.get(img_src).content
with open (f'{position}.jpg','wb') as f:
f.write(image_content)
position+=1