Tesseract介绍
Tesseract 是一个开源的光学字符识别(OCR)引擎,最初由 HP 在 1985 年至 1995 年间开发,后来被 Google 收购并开源。Tesseract 支持多种语言的文本识别,能够识别图片中的文字,并将其转换为可编辑和可搜索的数据格式。它适用于多种应用场景,包括文档扫描、图像处理、数字存档等。
Tesseract 的最新版本显著提高了识别准确率,支持的文件格式包括 TIFF、JPEG、PNG 等常见图片格式。此外,Tesseract 还提供了一个命令行工具,允许用户通过简单的命令行输入来执行 OCR 任务。对于开发者而言,Tesseract 提供了多种编程语言的 API 接口,如 C++、Python、Java 等,使得集成 OCR 功能到各种应用程序中变得更为容易。
除了基本的 OCR 功能外,Tesseract 还支持语言模型和训练工具,允许用户根据特定需求训练自定义模型,以提高某些特定类型或格式文本的识别准确率。这些特性使得 Tesseract 成为了一个强大而灵活的 OCR 工具,广泛应用于个人和企业的文本数字化处理中。
GitHub地址:https://github.com/tesseract-ocr/tesseract
官方文档地址:https://tesseract-ocr.github.io

下载安装Tesseract
下载Tesseract
Home · UB-Mannheim/tesseract Wiki

安装的时候,记得选上中文语言包:

输入
cmd
tesseract -v查看Tesseract是否安装成功

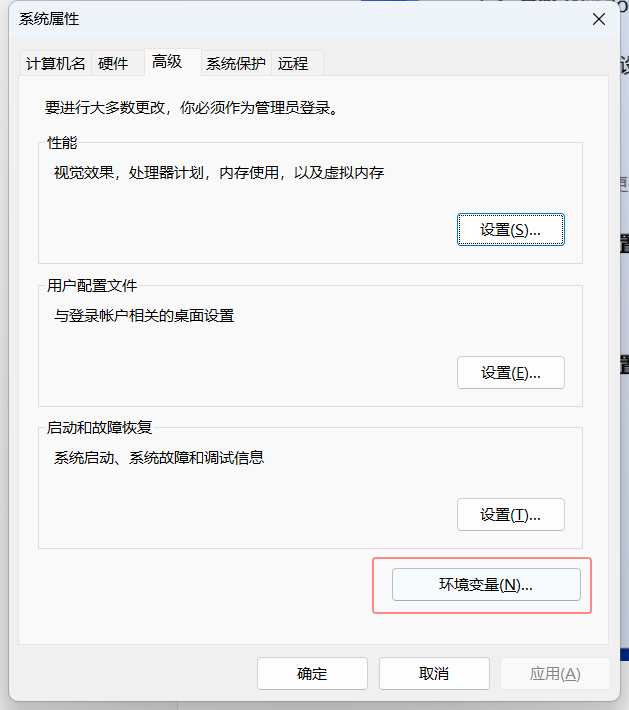
设置环境变量:
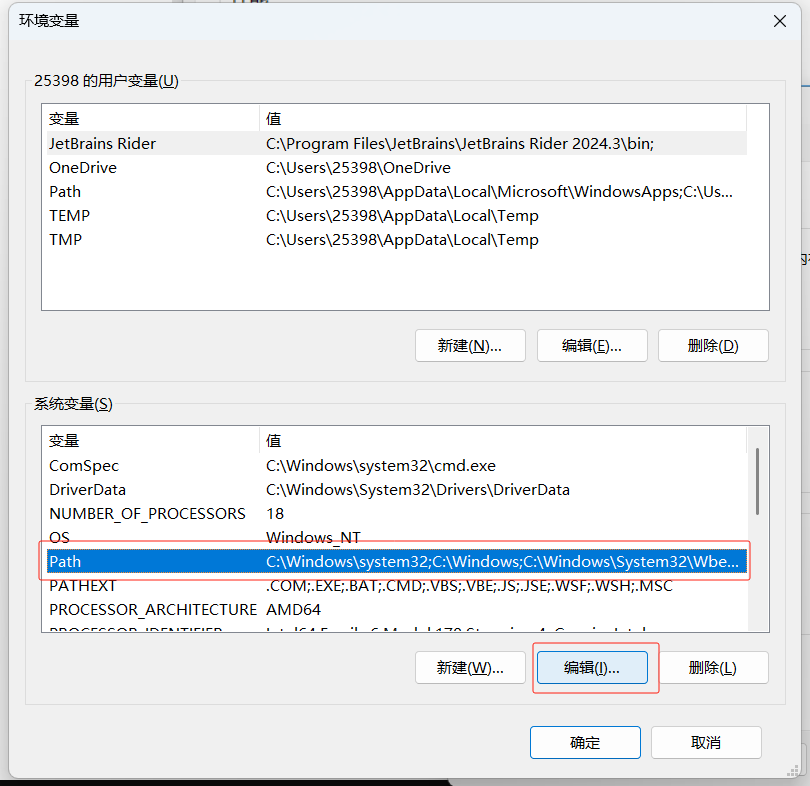
输入Tesseract的安装地址:
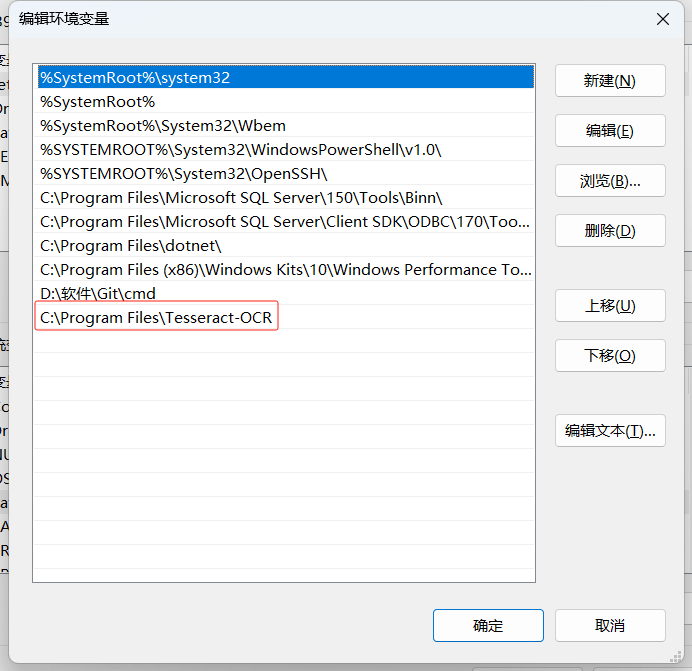
注意安装路径最好不要包含中文,由于C盘空间还比较充足,我就装在默认位置了。
再次验证安装是否完成:
cmd
tesseract -v
安装成功完成。
Tesseract的基本命令行使用
基本文本识别
最简单的命令是将图片中的文本识别并输出到标准输出(屏幕):
cmd
tesseract D:\test2.png stdout默认识别的是英文的,先拿一个英文的图片试试:

图片文字识别的效果
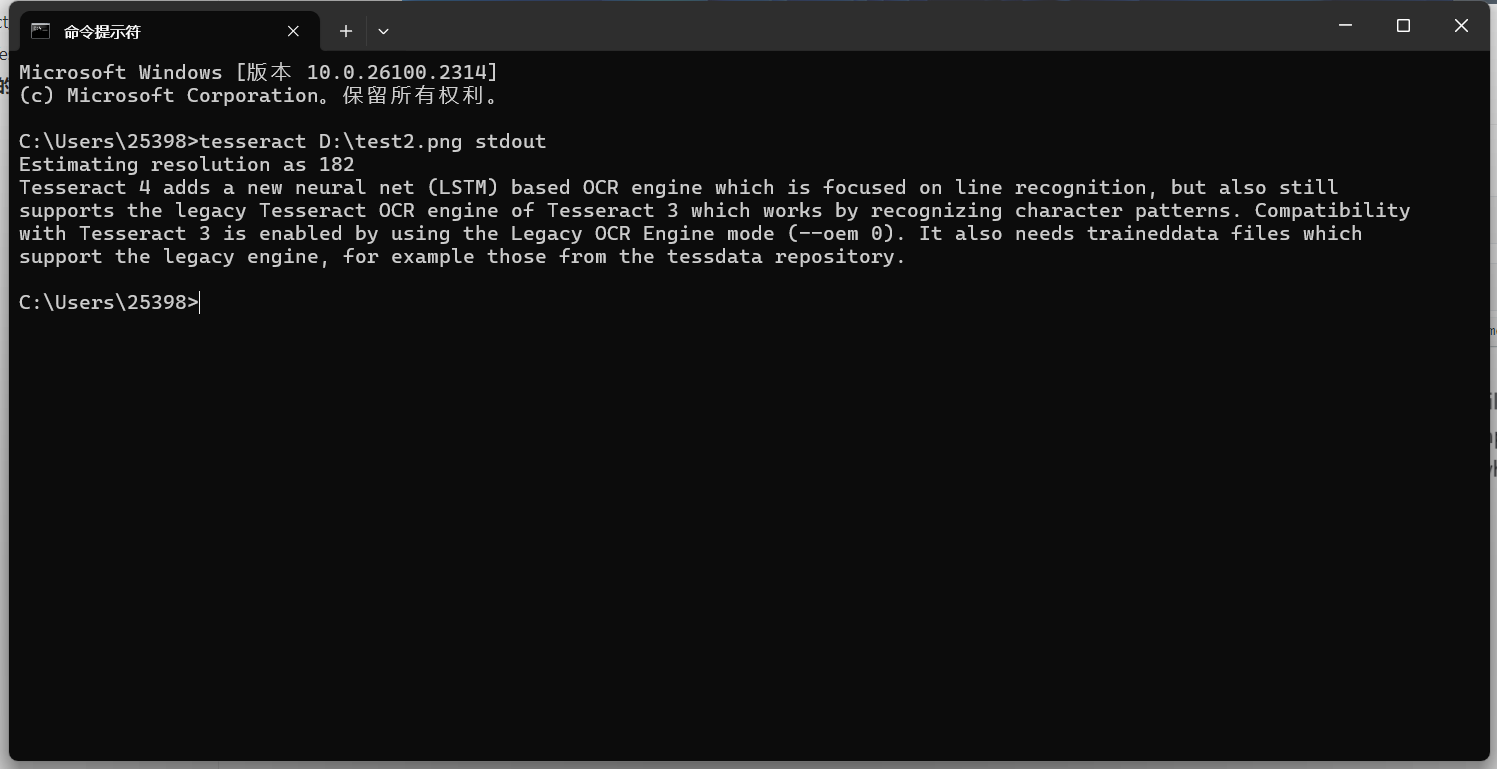
效果还是很ok的。
再试试一个中文的图片:

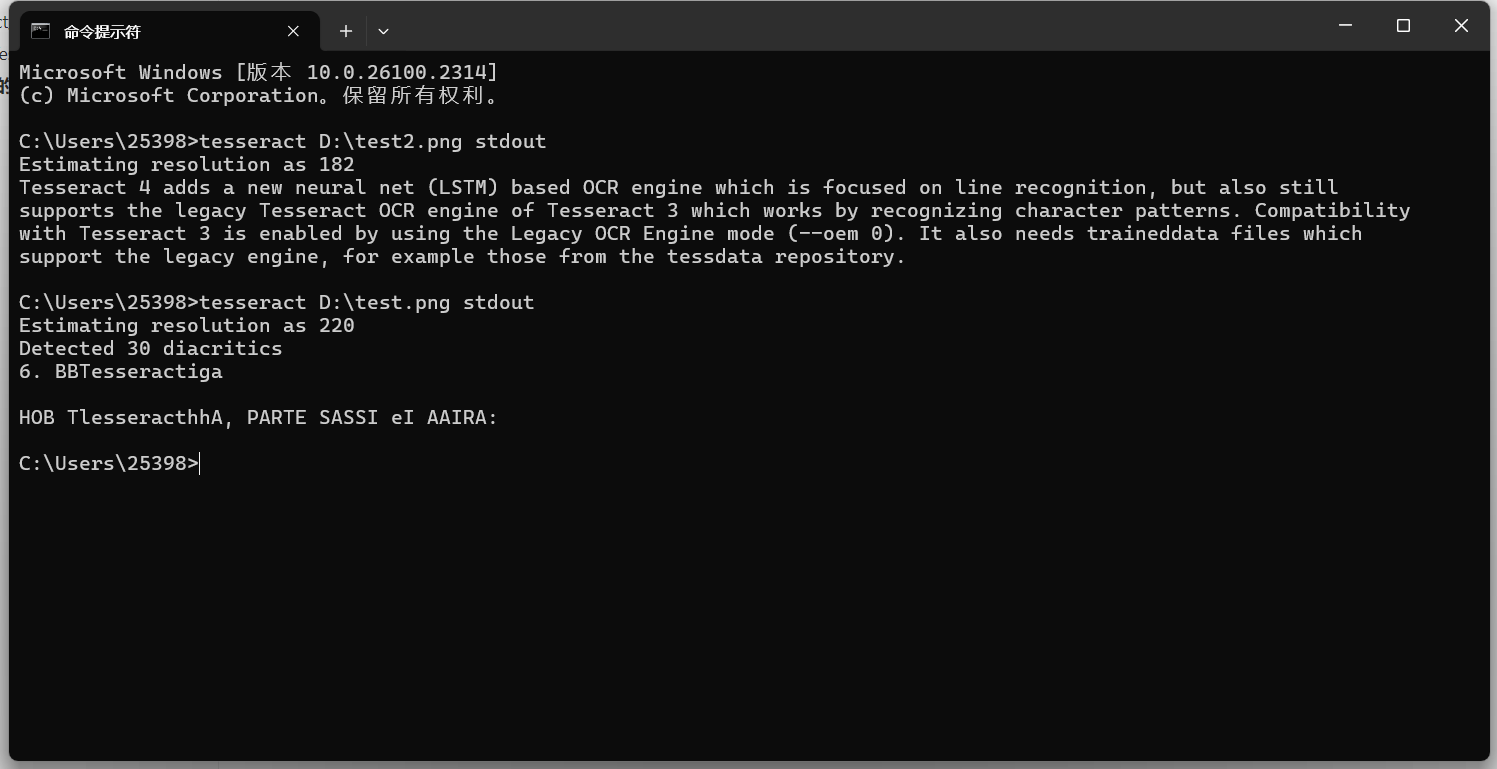
默认是无法识别中文的,这时候需要指定语言才行。
指定一种语言识别
如果图片中的文字不是英文,你需要指定相应的语言。Tesseract 支持多种语言,可以通过以下命令查看支持的语言:
cmd
tesseract --list-langs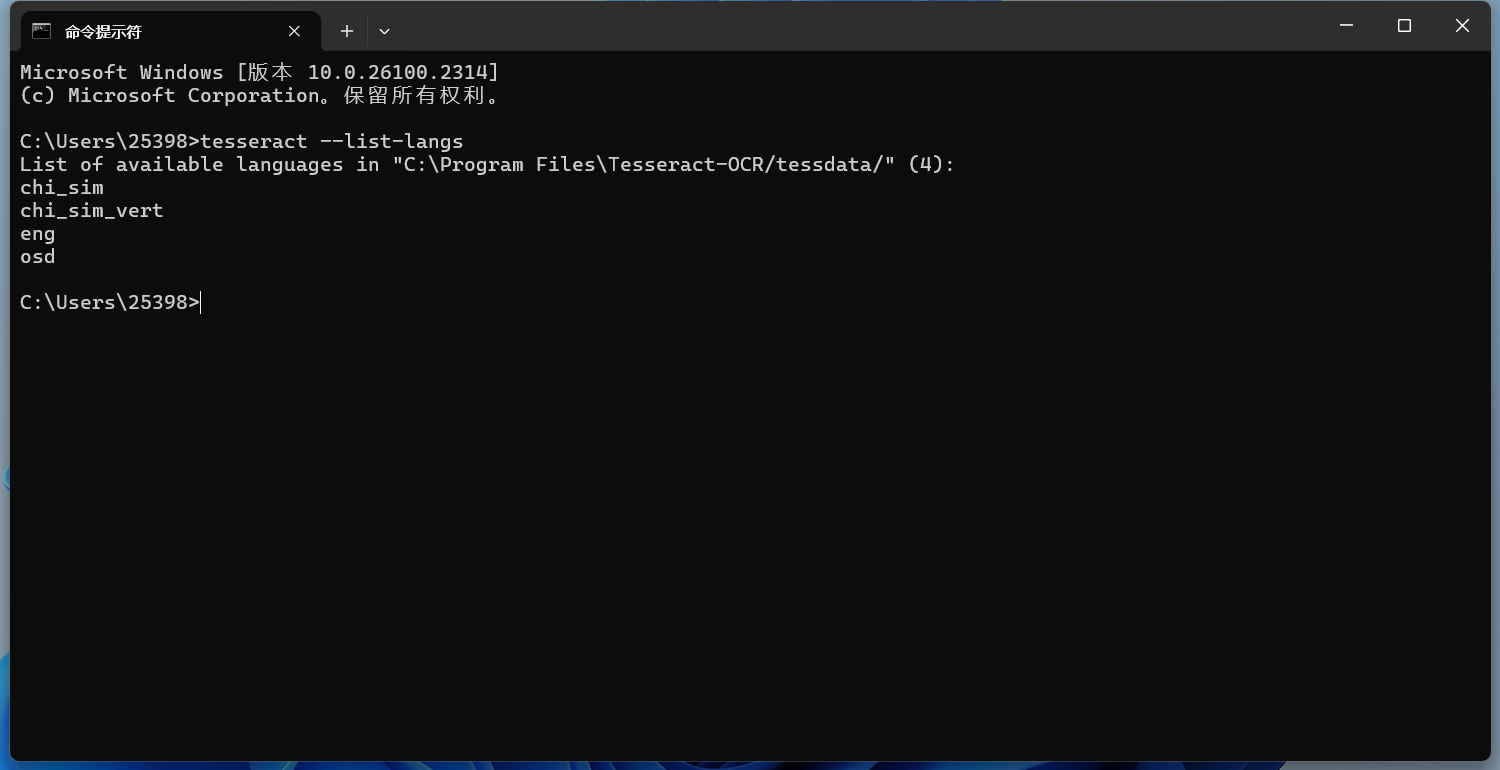
会出现你已经下载了语言包的语言。
指定语言的命令如下(例如,识别中文):
cmd
tesseract D:\test.png stdout -l chi_sim这里的 -l chi_sim 表示使用简体中文语言模型。
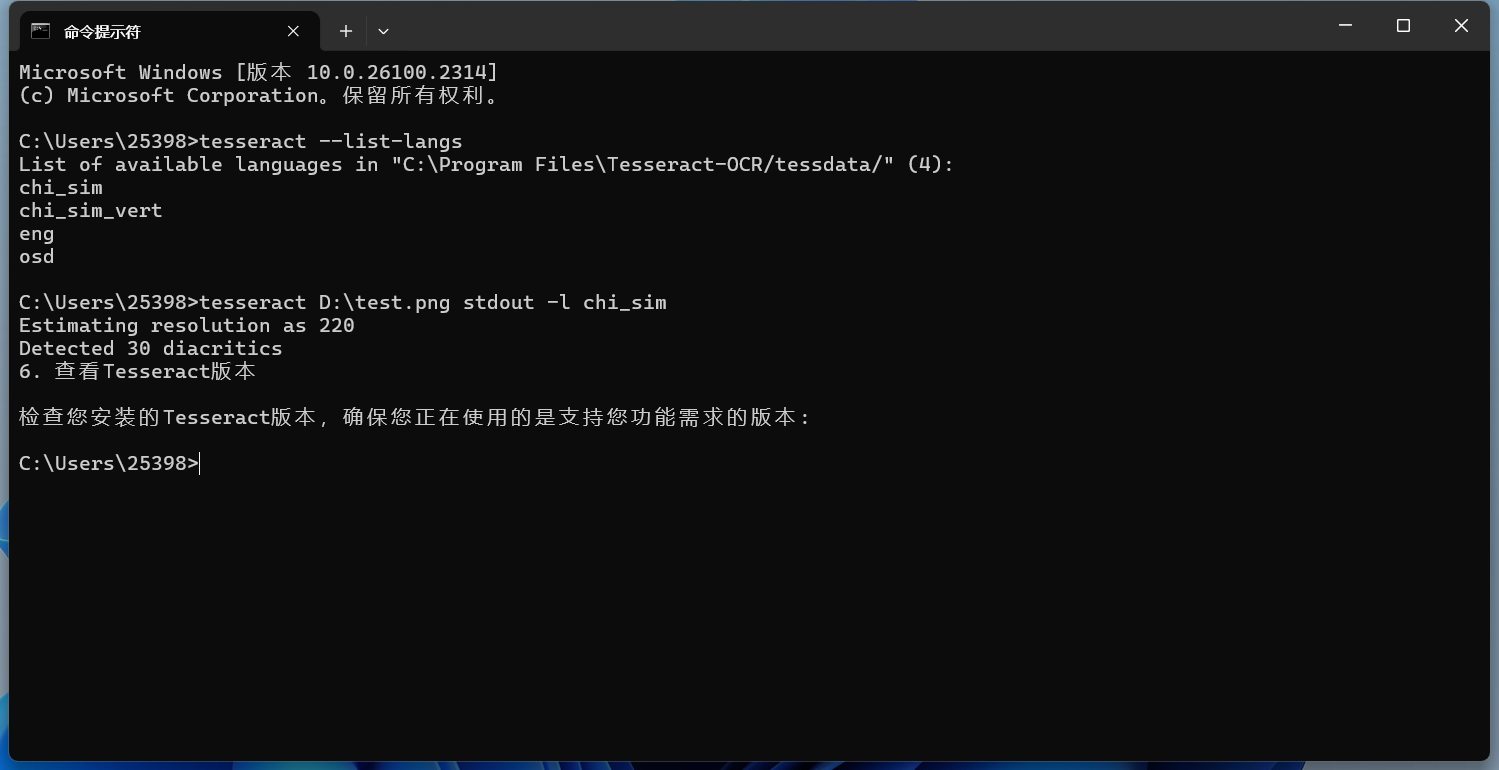
效果也很不错。
指定多种语言识别
有时候我们需要同时识别多种语言,以下面这张图片为例:

在命令行中添加-l LANG+LANG可以使用多种语言进行识别:
cmd
tesseract D:\test3.png stdout -l eng+chi_sim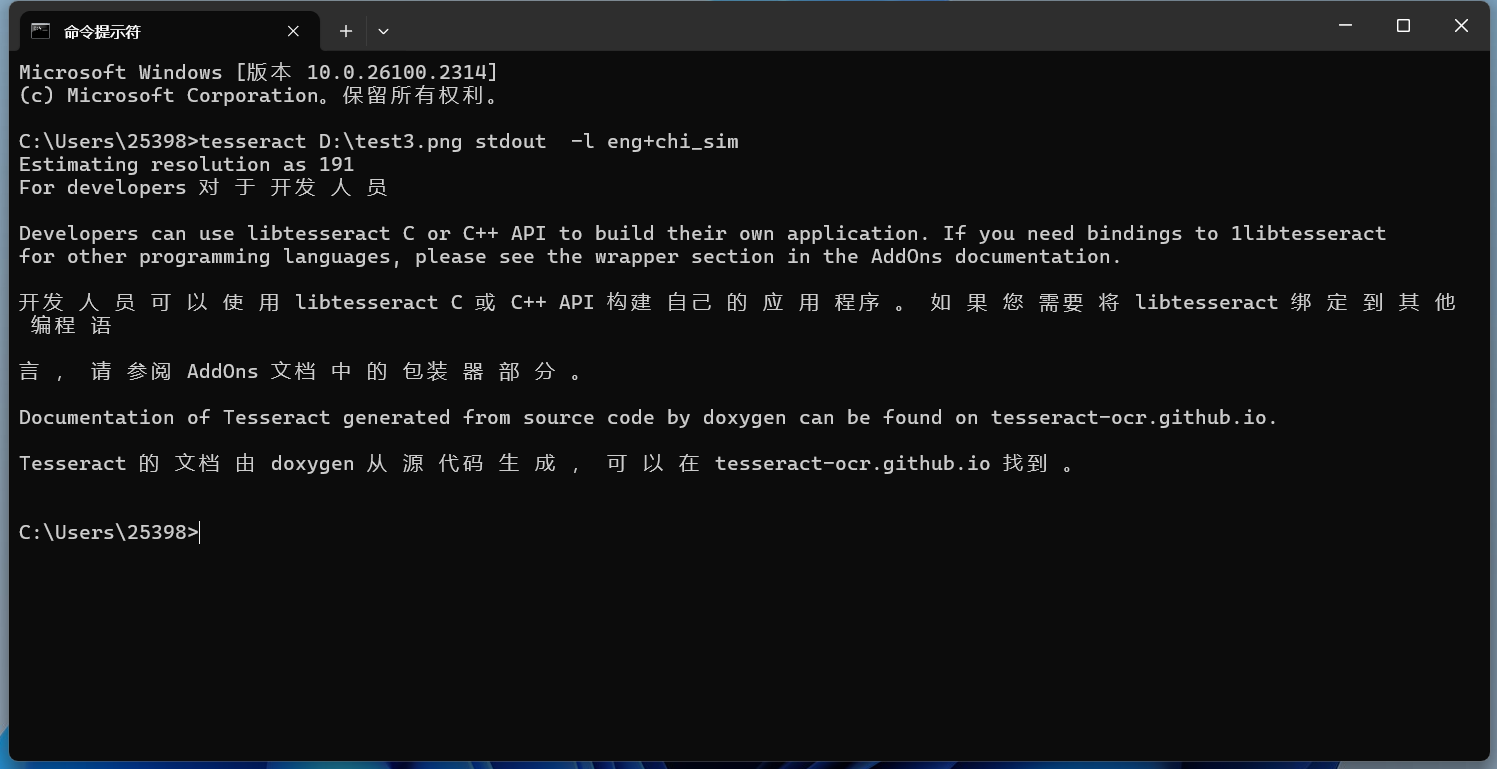
效果也还行。但是会发现识别的中文很多地方都有空格。
将中文改为主要识别语言:
cmd
tesseract D:\test3.png stdout -l chi_sim+eng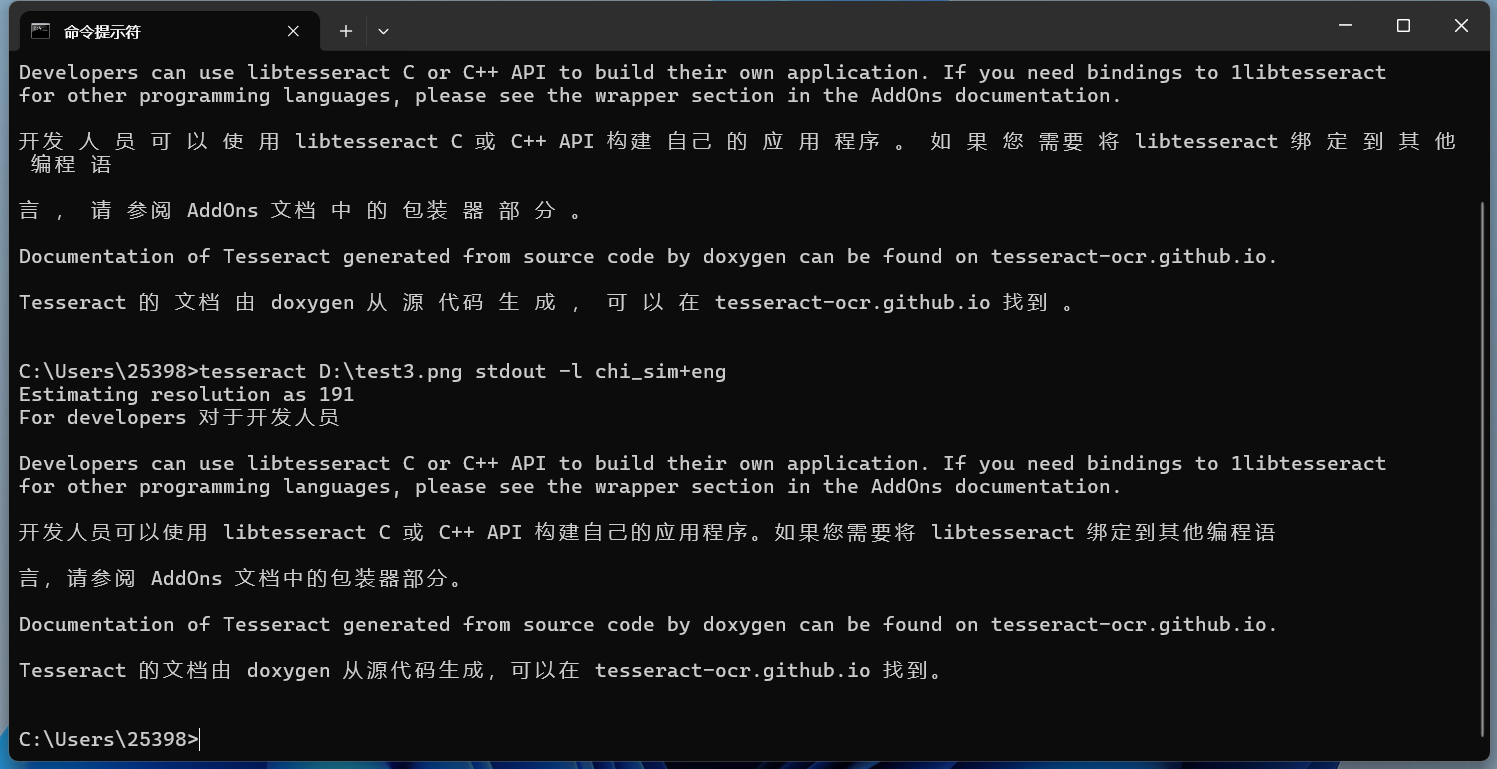
可以发现识别的空格少了很多。
保存识别文本到文件
也可以把识别的内容保存在一个txt文件中,命令如下所示:
cmd
tesseract D:\test2.png D:\output.txt 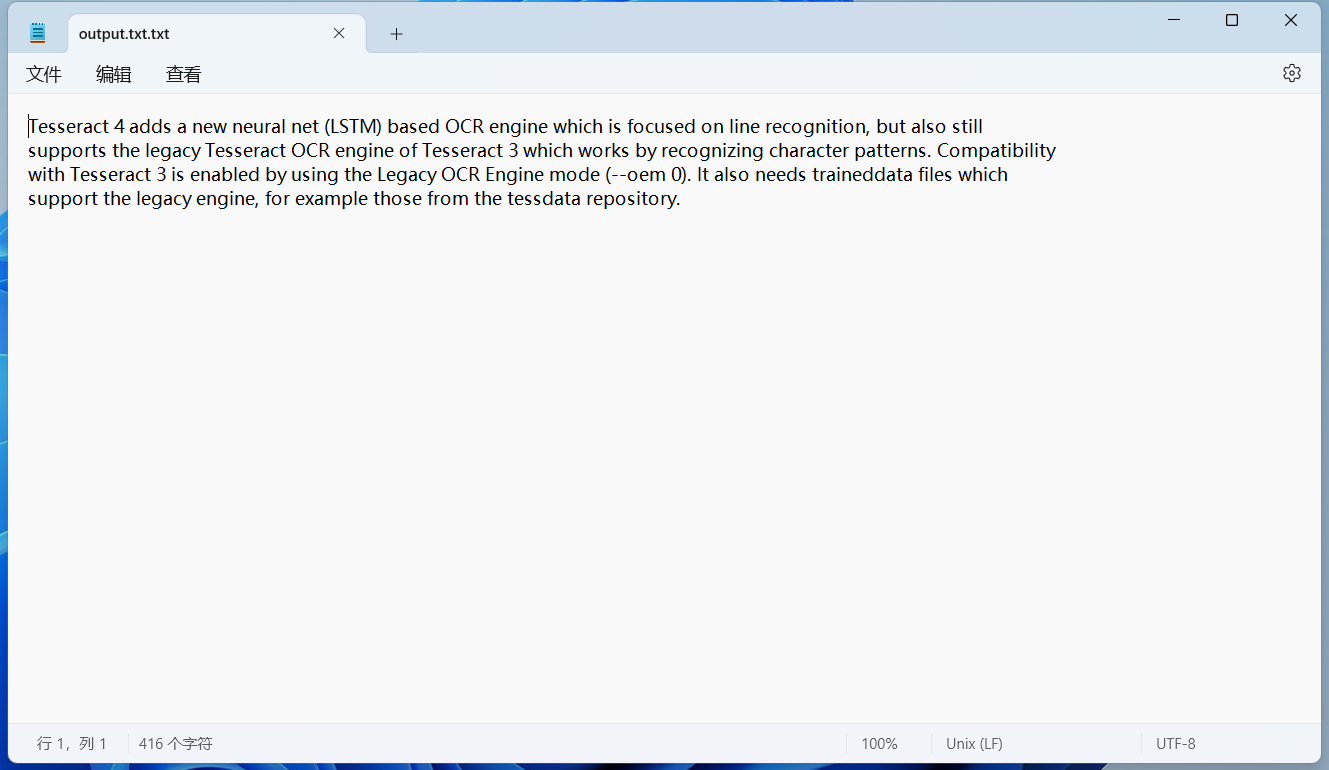
使用quiet模式抑制消息
不使用quiet模式与使用quiet模式的对比:
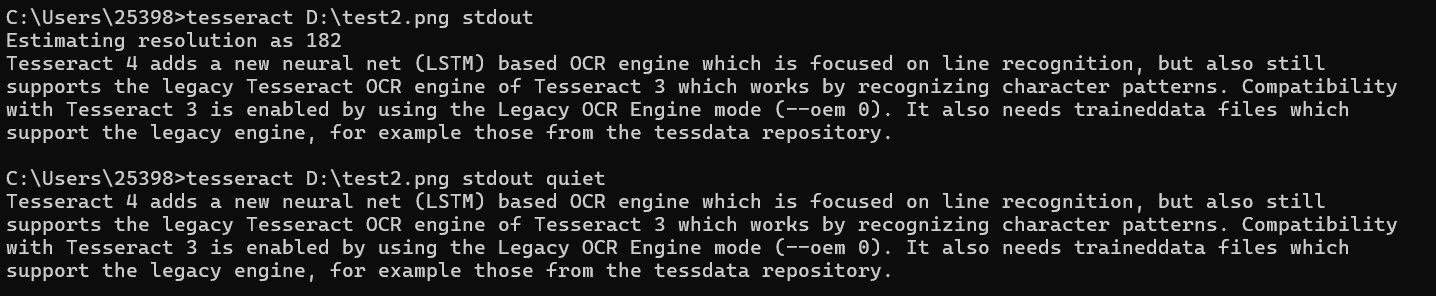
少了表示 Tesseract 正在尝试估算输入图像的分辨率的信息Estimating resolution as 182。
可搜索的pdf输出
这将创建一个包含图像和单独可搜索文本层的PDF,其中包含识别出的文本:
cmd
tesseract D:\test2.png D:\output -l eng pdf实现效果:
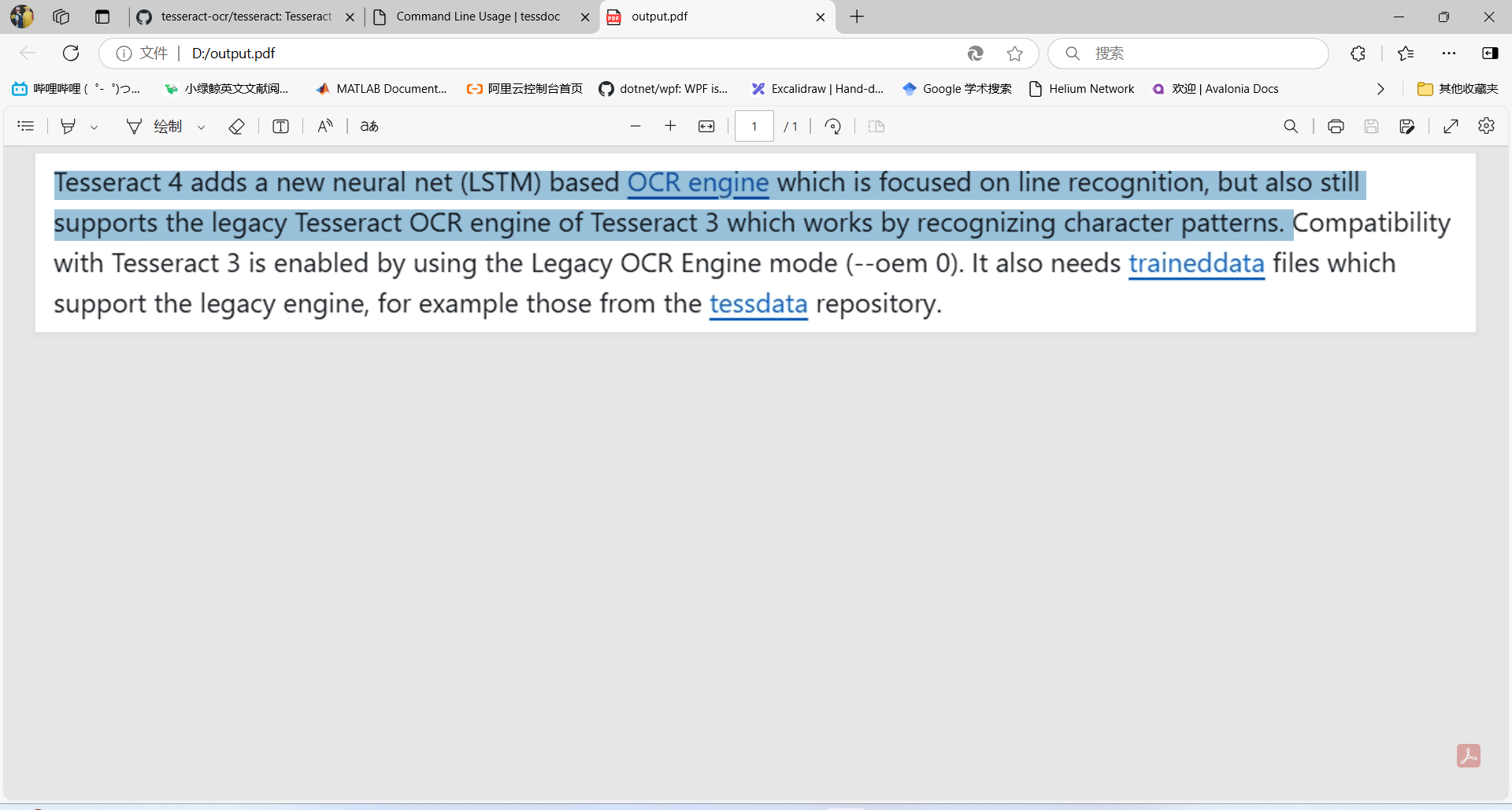
HOCR输出
在命令末尾添加hocr以使用'hocr'配置文件,获取HOCR输出:
cmd
tesseract D:\test2.png - -l eng hocr识别效果:
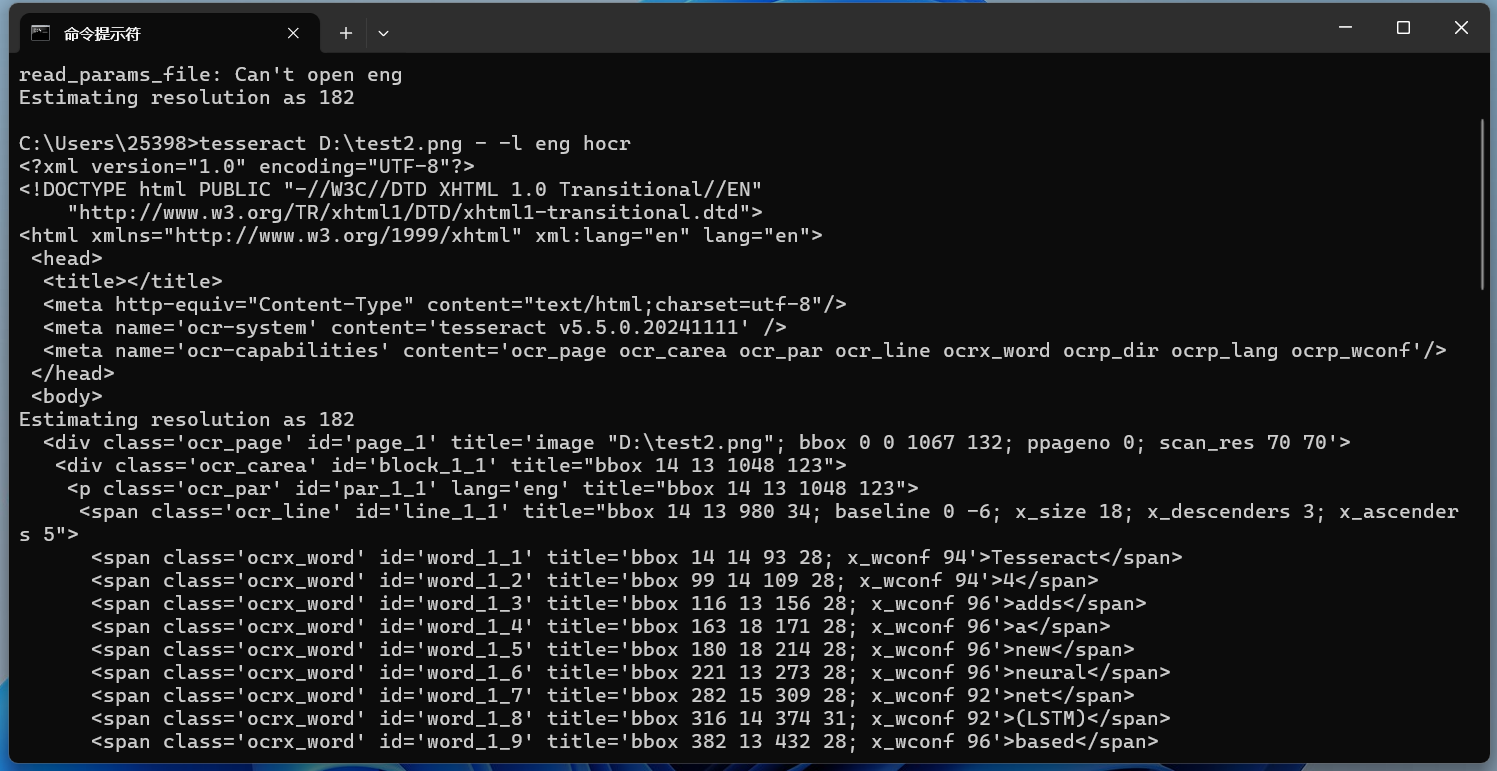
这样不够直观,保存在一个html文件中,然后再打开看看:
cmd
tesseract D:\test2.png D:\test2.html -l eng hocr把生成的文件后缀改为.html,用浏览器打开,效果如下所示:
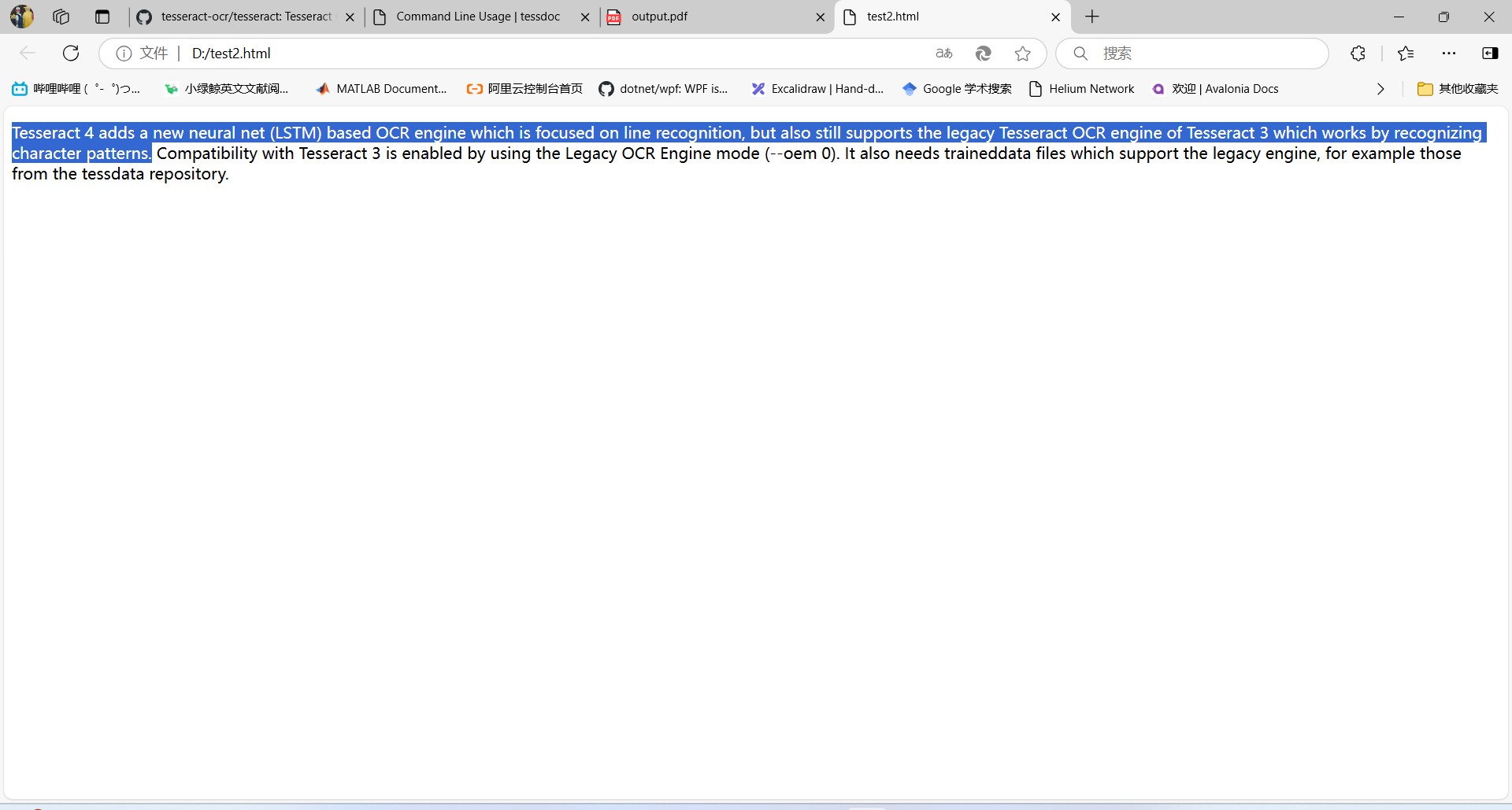
TSV输出
在命令末尾添加"tsv"配置文件以获取TSV输出:
cmd
tesseract D:\test5.jpg - -l chi_sim tsv以这张图片为例:
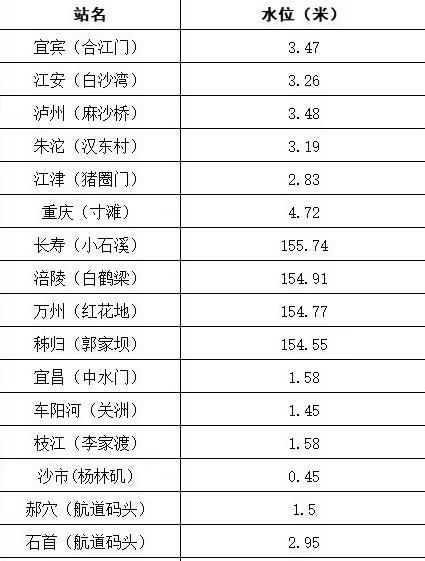
实现效果如下所示:
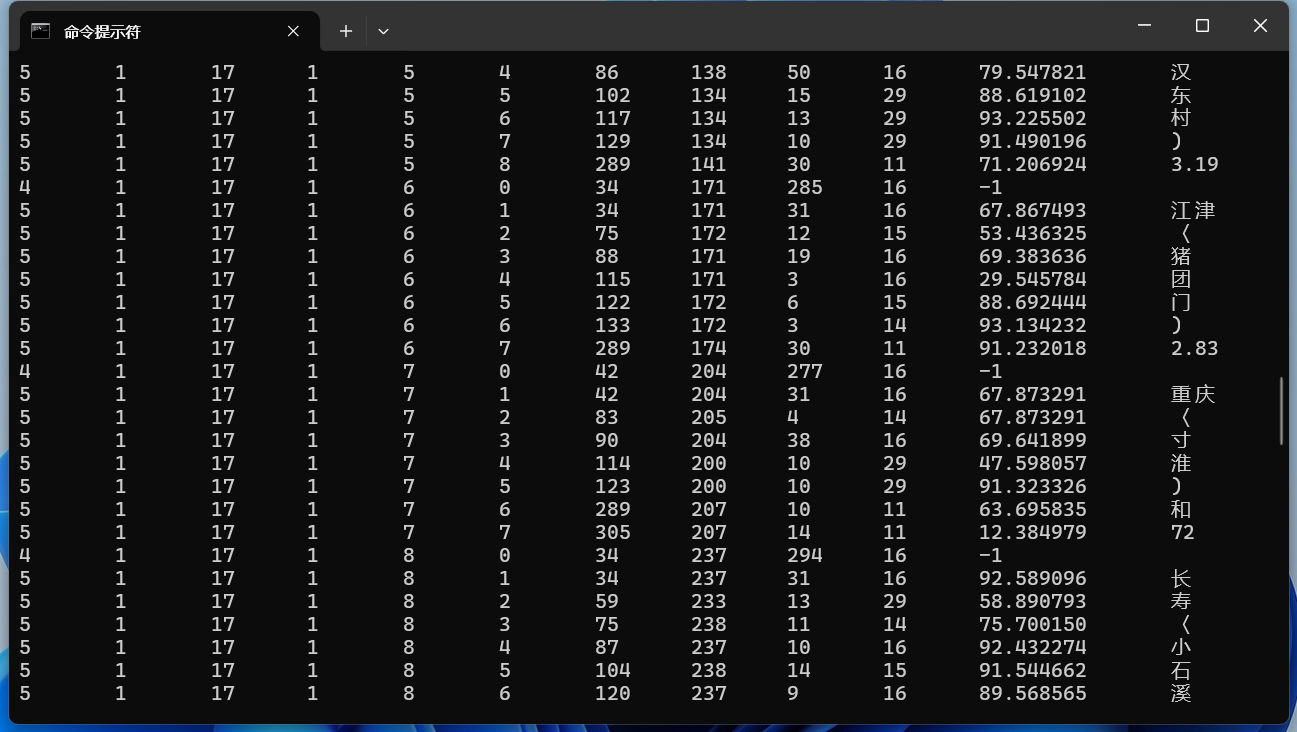
使用不同的页面分割模式
-psm 3 - 全自动页面分割,但无方向和脚本检测。(默认)
以这张图片为例:

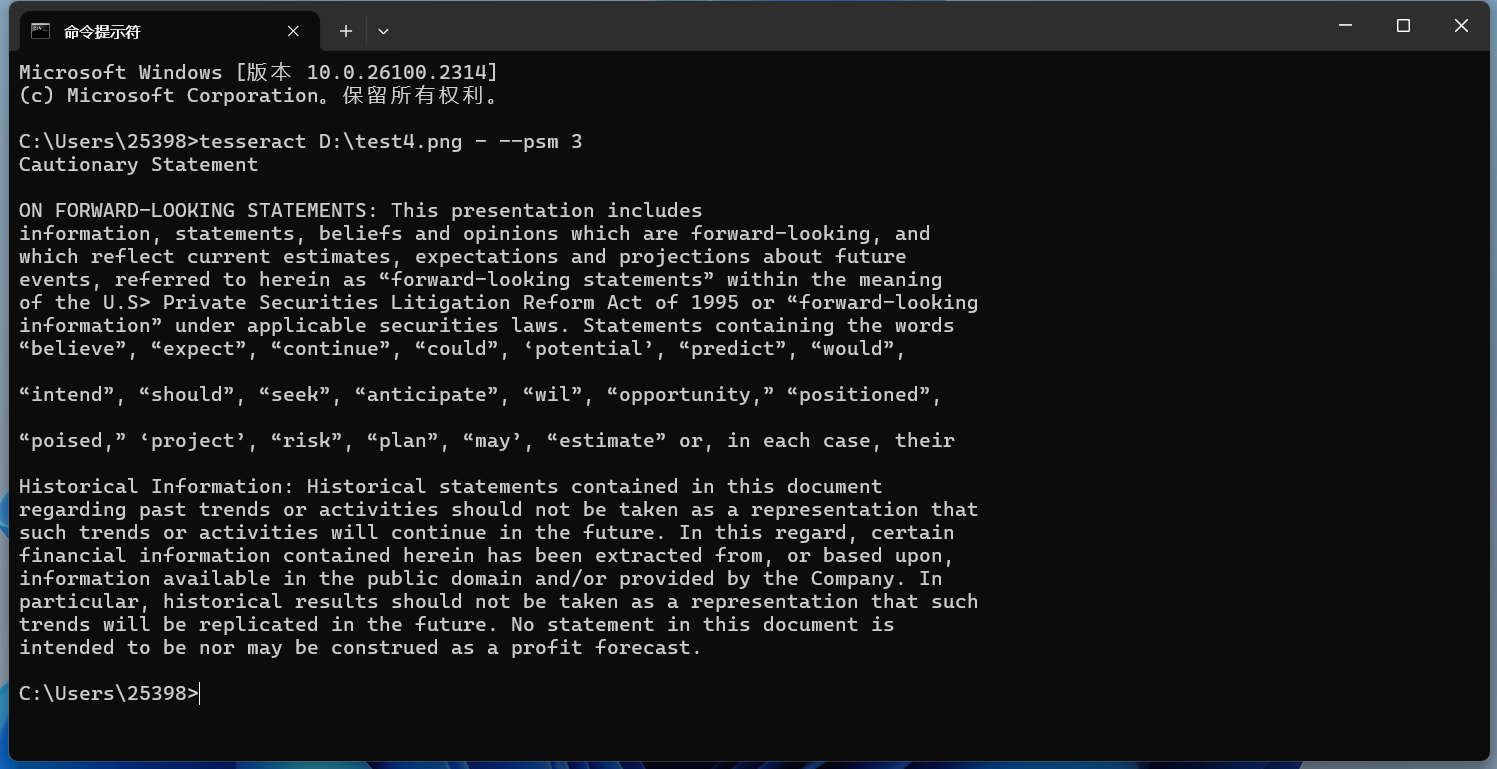
cmd
tesseract D:\test4.png - --psm 3实现的效果:
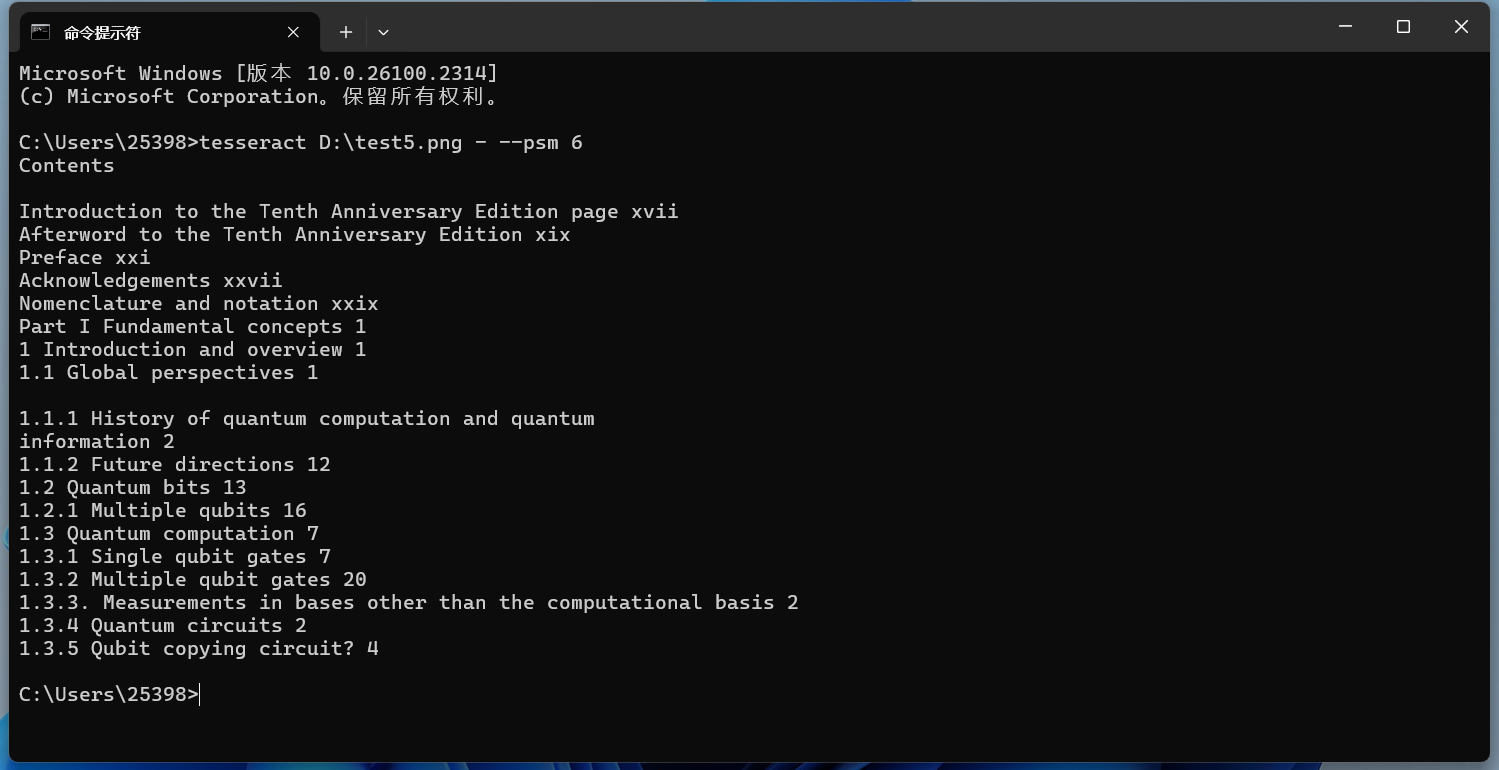
-psm 6 - 假定文本为一个整体均匀的块。
以这张图片为例:

cmd
tesseract D:\test5.png - --psm 6实现效果如下所示:
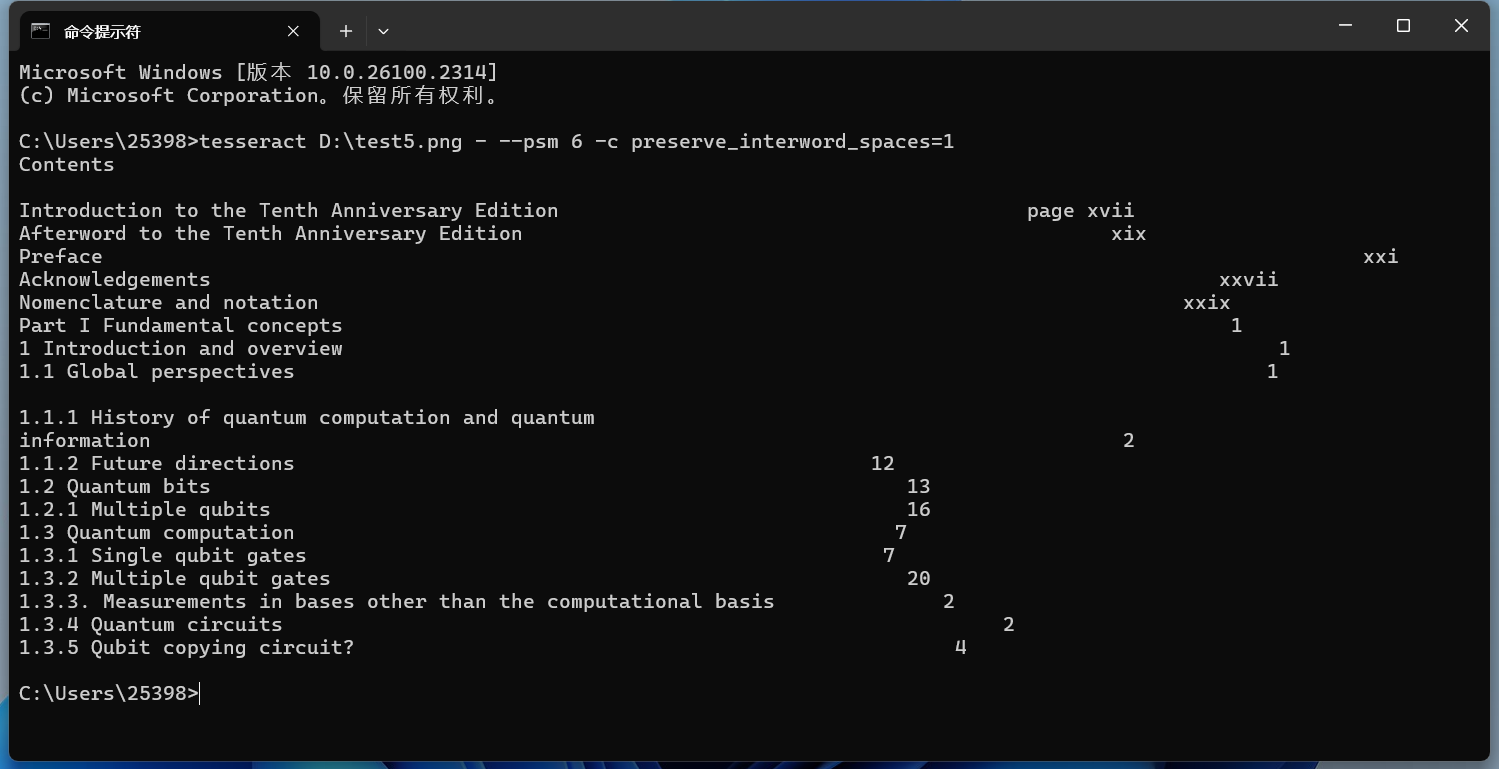
使用 -c preserve_interword_spaces=1 来保留空格
cmd
tesseract D:\test5.png - --psm 6 -c preserve_interword_spaces=1实现效果如下所示:
使用pdftotext保持文本输出的布局
cmd
tesseract D:\test5.png D:\test5 -l eng --psm 11 pdf实现的效果:
总结
现在图片文字识别已经有多种方式可以实现,也可以通过云服务商的文字识别服务,缺点就是需要网络,数量多了需要收费,优点就是识别准确率比较高。使用Tesseract与PaddleOCR这种方式的好处就是离线可用,速度也挺快的。还有一种目前还没试过的方式,就是使用多模态的大语言模型,缺点可能就是如果使用大模型服务提供商会比较耗费token,自己本地用ollama又比较吃配置相对于Tesseract与PaddleOCR而言,还有就是多模态大语言模型可能自己会出现一些别的内容。
之前写过几篇关于PaddleOCR的文章,感兴趣也可以阅读: