实现一个调度任务,可能很简单。但是如何让工作流下的任务跑得更好、更快、更稳定、更具有扩展性,同时可视化,是值得我们去思考得问题。
Apache DolphinScheduler是一个分布式和可扩展的开源工作流协调平台,具有强大的DAG可视化界面,广泛应用于数据集成、数据分析和大规模数据迁移。
Master 整体启动流程
java
@PostConstruct
public void run() throws SchedulerException {
// init rpc server
this.masterRPCServer.start();
// install task plugin
this.taskPluginManager.loadPlugin();
// self tolerant
this.masterRegistryClient.start();
this.masterRegistryClient.setRegistryStoppable(this);
this.masterSchedulerBootstrap.init();
// 处理任务的核心 重点是处理任务
this.masterSchedulerBootstrap.start();
// 事件执行启动
this.eventExecuteService.start();
this.failoverExecuteThread.start();
this.schedulerApi.start();
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
if (!ServerLifeCycleManager.isStopped()) {
close("MasterServer shutdownHook");
}
}));
}上面的代码主要做的事情:
初始化rpc的服务端,也即netty的服务端,为处理请求做好铺垫
安装Task插件,task插件主要为业务需要集成的SPI信息
master注册客户端启动
初始化master定时引导
master定时引导启动
事件执行启动
失败执行线程启动
定时任务api启动下面我们重点看这两段代码:
java
this.masterSchedulerBootstrap.start();
this.eventExecuteService.start();this.masterSchedulerBootstrap.start()
任务的来源在t_ds_command表里面,因此需要先取出指令信息,然后将指令转处理实例,遍历处理实例,创建新的工作流线程。
(1) 将处理实例id和处理线程放入到processInstanceExecCacheManager中。
(2) 添加工作流运行状态和实例id放入到workflowEventQueue队列中。
因此可以看到消费的poolEvent,可以看到workflowEventQueue.poolEvent() 本质就是workflowEventLooper.start()启动消费。
此时我们可以看到workflowEventLooper.start(),处理放入到workflowEventQueue中的事件event,也即workflowEventQueue.take(),获取工作流处理器,处理事件。
Run中的核心处理:
刘亚洲
此时先执行工作流的流程,核心方法:workflowExecuteRunnable::call。
workflowEventLooper.start()启动做的事情:

将任务放入到优先任务队列之后,就可以进行消费队列中的任务了。
ProcessInstance任务放入的核心
ProcessInstance 启动入口点为:org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteRunnable#call。
根据工作流线程状态可分为:

1)创建过程中的逻辑:
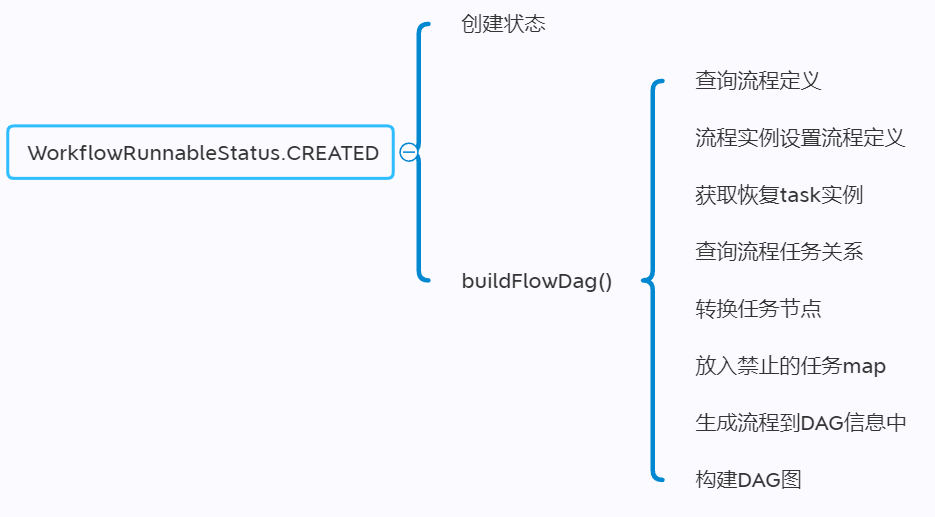
2)初始化DAG的过程:

3)初始化队列的过程:

4)工作流状态成功:

生成者消费者模型的产生是优先任务队列的放入和优先任务队列的消费。
因此可以看到两者在转换的过程之后基于Netty做了任务的转发操作,从而在Netty中做指令处理,从而完成消费,最终流转到具体的Task。
消费任务:TaskPriorityQueueConsumer
核心方法:this.batchDispatch(fetchTaskNum)

netty服务端消费任务消息
实质是放入任务线程,也即:
workerManager.offer(workerTaskExecuteRunnable)
处理消费在run方法里面:
waitSubmitQueue.take()
处理任务的核心:此时会具体流转到具体的任务,执行处理

此时完成任务的适配业务任务的处理,最终实现任务的处理。
this.eventExecuteService.start()
针对任务处理的状态进行处理。
stateEventHandler.handleStateEvent(this, stateEvent)
其主要过程是添加状态事件和消费状态事件,重点看队列的生产和消费。
分析的思路和上面的队列模式差不多,这里不展开了。
总结
从上面我们可以看到生产者消费者模型、线程模型在DS3.1.9版本中使用非常的多,也是我们去了解处理的思路的点。
同时对应任务的处理,为了保证任务的高效处理,使用了Netty来处理任务。
总体来说,代码写得还是很不错的,值得我们去学习。同时还使用了很多设计模式,比如SPI、工厂模式、状态模式等等。
参考:
dolphinscheduler文档:https://dolphinscheduler.apache.org/zh-cn github地址:https://github.com/apache/dolphinscheduler
本文由 白鲸开源科技 提供发布支持!