es实现上传文件查询
上传文件,获取文件内容base64,使用es的ingest-attachment文本抽取管道转换为文字存储
安装插件
通过命令行安装(推荐)
cmd
1.进入 Elasticsearch 安装目录
2.使用 elasticsearch-plugin 命令安装
bin/elasticsearch-plugin install ingest-attachment
3.重启elasticsearch
# 如果是系统服务
sudo systemctl restart elasticsearch
# 或者直接重启
./bin/elasticsearch
查看是否安装成功
1.查看elasticsearch-7.17.12\plugins下是否存在ingest-attachment
2.查看已安装插件列表
bin/elasticsearch-plugin list
进入kibana调试控制台,通过 API 检查
GET /_nodes/plugins可以手动加载插件再解压到plugins目录下
新增和es交互的实体FileEsDTO
尽量只留需要参与查询的字段,不经常变动的字段
java
package com.xiaofei.site.search.model.dto.file;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.io.Serializable;
import java.util.Date;
/**
* 文件 ES 包装类
**/
@Document(indexName = "file_v3")
@Data
public class FileEsDTO implements Serializable {
private static final String DATE_TIME_PATTERN = "yyyy-MM-dd'T'HH:mm:ss.SSS'Z'";
/**
* id
*/
@Id
private Long id;
/**
* 文件名
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String fileName;
/**
* 文件类型
*/
@Field(type = FieldType.Keyword)
private String fileType;
/**
* 解析后的文本内容
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String content;
/**
* 文件描述
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String description;
/**
* 上传用户ID
*/
@Field(type = FieldType.Long)
private Long userId;
/**
* 业务类型
*/
@Field(type = FieldType.Keyword)
private String biz;
/**
* 下载次数
*/
@Field(type = FieldType.Integer)
private Integer downloadCount;
/**
* 创建时间
*/
@Field(index = false, store = true, type = FieldType.Date, format = {}, pattern = DATE_TIME_PATTERN)
private Date createTime;
/**
* 更新时间
*/
@Field(index = false, store = true, type = FieldType.Date, format = {}, pattern = DATE_TIME_PATTERN)
private Date updateTime;
private Integer isDelete;
private static final long serialVersionUID = 1L;
}新增文本抽取管道
字段就是存储文本的content
json
#文本抽取管道
PUT /_ingest/pipeline/attachment
{
"description": "Extract file content",
"processors": [
{
"attachment": {
"field": "content",
"target_field": "attachment",
"indexed_chars": -1
}
},
{
"remove": {
"field": "content"
}
}
]
}新增es文档索引
json
PUT /file_v3
{
"mappings": {
"properties": {
"id": {
"type": "long"
},
"fileName": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"fileType": {
"type": "keyword"
},
"content": {
"type": "binary"
},
"attachment": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"content_type": {
"type": "keyword"
},
"language": {
"type": "keyword"
},
"title": {
"type": "text"
}
}
},
"description": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"userId": {
"type": "long"
},
"biz": {
"type": "keyword"
},
"isDelete": {
"type": "integer"
},
"createTime": {
"type": "date"
},
"updateTime": {
"type": "date"
}
}
}
}修改文件上传方法
增加文本内容同步到es
java
public interface FileService extends IService<FilePo> {
...
FilePo uploadFile(MultipartFile file, FileUploadBizEnum fileUploadBizEnum);
...
}
@Service
@Slf4j
public class FileServiceImpl extends ServiceImpl<FileMapper, FilePo> implements FileService {
@Resource
private RestHighLevelClient restHighLevelClient;
@Override
public FilePo uploadFile(MultipartFile file, FileUploadBizEnum fileUploadBizEnum) {
try {
...
int insert = fileMapper.insert(filePo);
if (insert > 0) {
//上传es
boolean esUpload = uploadFileToEs(filePo, dest);
// 4. 删除临时文件
dest.delete();
if (!esUpload) {
throw new BusinessException(ErrorCode.OPERATION_ERROR, "文件上传失败");
}
return filePo;
}
return null;
} catch (IOException e) {
log.error("文件上传失败", e);
throw new BusinessException(ErrorCode.OPERATION_ERROR, "文件上传失败");
}
}
/**
* 通过pipeline上传文件到es
* @param filePo
* @param file
* @return
*/
public boolean uploadFileToEs(FilePo filePo, File file) {
try {
// 1. 读取文件内容并转换为 Base64
byte[] fileContent = Files.readAllBytes(file.toPath());
String base64Content = Base64.getEncoder().encodeToString(fileContent);
// 2. 准备索引文档
Map<String, Object> document = new HashMap<>();
document.put("id", filePo.getId());
document.put("fileName", filePo.getFileName());
document.put("fileType", filePo.getFileType());
document.put("content", base64Content); // 使用 content 字段
document.put("description", filePo.getDescription());
document.put("userId", filePo.getUserId());
document.put("biz", filePo.getBiz());
document.put("createTime", filePo.getCreateTime());
document.put("updateTime", filePo.getUpdateTime());
// 3. 创建索引请求
IndexRequest indexRequest = new IndexRequest("file_v3")
.id(filePo.getId().toString())
.setPipeline("attachment")
.source(document);
// 4. 执行索引请求
IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
return indexResponse.status() == RestStatus.CREATED
|| indexResponse.status() == RestStatus.OK;
} catch (Exception e) {
log.error("上传文件到 ES 失败", e);
return false;
}
}
/**
* 生成文件名(防止重复)
*
* @param originalFilename
* @return
*/
private String generateFileName(String originalFilename) {
String extension = FilenameUtils.getExtension(originalFilename);
String uuid = RandomStringUtils.randomAlphanumeric(8);
return uuid + "." + extension;
}
/**
* 计算文件MD5
*
* @param file
* @return
* @throws IOException
*/
private String calculateMD5(File file) throws IOException {
return DigestUtils.md5Hex(new FileInputStream(file));
}
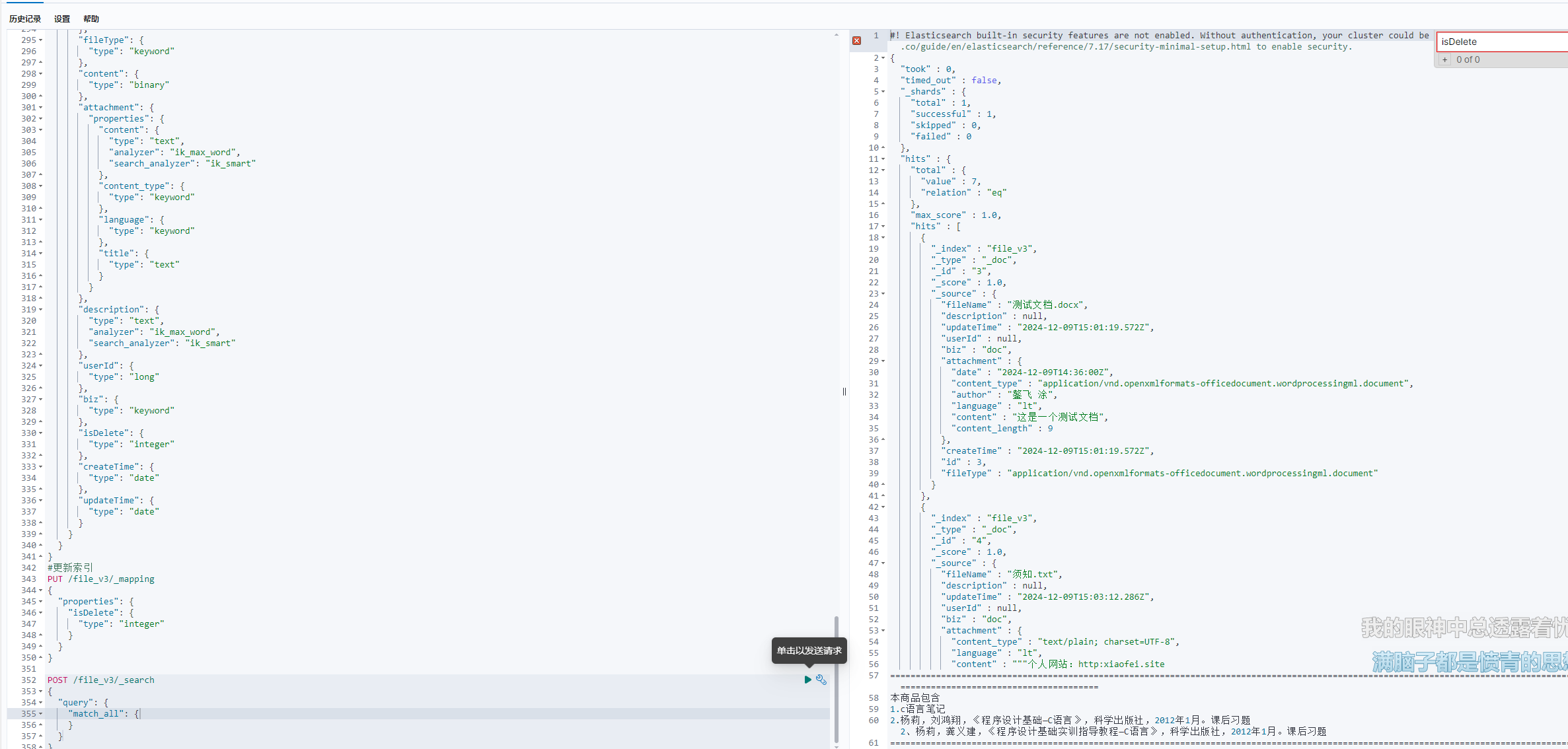
}上传一个测试文档
通过es查询,看看是否正常解析成文本
content存储着文本
新增es查询方法
java
public interface FileService extends IService<FilePo> {
Page<FileVo> searchFromEs(FileQueryRequest fileQueryRequest);
}
@Service
@Slf4j
public class FileServiceImpl extends ServiceImpl<FileMapper, FilePo> implements FileService {
@Resource
private ElasticsearchRestTemplate elasticsearchRestTemplate;
@Override
public Page<FileVo> searchFromEs(FileQueryRequest fileQueryRequest) {
String searchText = fileQueryRequest.getSearchText();
String fileName = fileQueryRequest.getFileName();
String content = fileQueryRequest.getContent();
// es 起始页为 0
long current = fileQueryRequest.getCurrent() - 1;
long pageSize = fileQueryRequest.getPageSize();
String sortField = fileQueryRequest.getSortField();
String sortOrder = fileQueryRequest.getSortOrder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//boolQueryBuilder.filter(QueryBuilders.termQuery("isDelete", 0));
// 按关键词检索
if (StringUtils.isNotBlank(searchText)) {
boolQueryBuilder.should(QueryBuilders.matchQuery("fileName", searchText));
boolQueryBuilder.should(QueryBuilders.matchQuery("description", searchText));
boolQueryBuilder.should(QueryBuilders.matchQuery("attachment.content", searchText));
boolQueryBuilder.minimumShouldMatch(1);
}
// 按标题检索
if (StringUtils.isNotBlank(fileName)) {
boolQueryBuilder.should(QueryBuilders.matchQuery("fileName", fileName));
boolQueryBuilder.minimumShouldMatch(1);
}
// 按内容检索
if (StringUtils.isNotBlank(content)) {
boolQueryBuilder.should(QueryBuilders.matchQuery("attachment.content", content));
boolQueryBuilder.minimumShouldMatch(1);
}
// 排序
SortBuilder<?> sortBuilder = SortBuilders.scoreSort();
if (StringUtils.isNotBlank(sortField)) {
sortBuilder = SortBuilders.fieldSort(sortField);
sortBuilder.order(CommonConstant.SORT_ORDER_ASC.equals(sortOrder) ? SortOrder.ASC : SortOrder.DESC);
}
// 分页
PageRequest pageRequest = PageRequest.of((int) current, (int) pageSize);
// 构造查询
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(boolQueryBuilder)
.withPageable(pageRequest).withSorts(sortBuilder).build();
SearchHits<FileEsDTO> searchHits = elasticsearchRestTemplate.search(searchQuery, FileEsDTO.class);
Page<FileVo> page = new Page<>();
page.setTotal(searchHits.getTotalHits());
List<FilePo> resourceList = new ArrayList<>();
// 查出结果后,从 db 获取最新动态数据
if (searchHits.hasSearchHits()) {
List<SearchHit<FileEsDTO>> searchHitList = searchHits.getSearchHits();
List<Long> fileIdList = searchHitList.stream().map(searchHit -> searchHit.getContent().getId())
.collect(Collectors.toList());
List<FilePo> fileList = baseMapper.selectBatchIds(fileIdList);
if (fileList != null) {
Map<Long, List<FilePo>> idPostMap = fileList.stream().collect(Collectors.groupingBy(FilePo::getId));
fileIdList.forEach(fileId -> {
if (idPostMap.containsKey(fileId)) {
resourceList.add(idPostMap.get(fileId).get(0));
} else {
// 从 es 清空 db 已物理删除的数据
String delete = elasticsearchRestTemplate.delete(String.valueOf(fileId), FileEsDTO.class);
log.info("delete post {}", delete);
}
});
}
}
List<FileVo> fileVoList = new ArrayList<>();
if (CollUtil.isNotEmpty(resourceList)) {
for (FilePo filePo : resourceList) {
FileVo fileVo = FilePoToVoUtils.poToVo(filePo);
fileVoList.add(fileVo);
}
}
page.setRecords(fileVoList);
return page;
}
}po转Vo工具
java
package com.xiaofei.site.search.utils;
import com.xiaofei.site.search.model.entity.FilePo;
import com.xiaofei.site.search.model.vo.FileVo;
import org.springframework.stereotype.Component;
/**
* @author tuaofei
* @description TODO
* @date 2024/12/6
*/
@Component
public class FilePoToVoUtils {
public static FileVo poToVo(FilePo entity) {
if (entity == null) {
return null;
}
FileVo vo = new FileVo();
vo.setId(entity.getId());
vo.setBiz(entity.getBiz());
vo.setFileName(entity.getFileName());
vo.setFileType(entity.getFileType());
vo.setFileSize(entity.getFileSize());
vo.setFileSizeFormat(formatFileSize(entity.getFileSize()));
vo.setFileExtension("");
vo.setUserId(entity.getUserId());
vo.setDownloadCount(entity.getDownloadCount());
vo.setDescription(entity.getDescription());
vo.setCreateTime(entity.getCreateTime());
vo.setUpdateTime(entity.getUpdateTime());
vo.setContent(entity.getContent());
// 设置预览和下载URL
vo.setPreviewUrl(generatePreviewUrl(entity));
vo.setDownloadUrl(generateDownloadUrl(entity));
// 设置权限
vo.setCanPreview(checkPreviewPermission(entity));
vo.setCanDownload(checkDownloadPermission(entity));
return vo;
}
/**
* 格式化文件大小
*/
private static String formatFileSize(Long size) {
if (size == null) {
return "0B";
}
if (size < 1024) {
return size + "B";
} else if (size < 1024 * 1024) {
return String.format("%.2fKB", size / 1024.0);
} else if (size < 1024 * 1024 * 1024) {
return String.format("%.2fMB", size / (1024.0 * 1024.0));
} else {
return String.format("%.2fGB", size / (1024.0 * 1024.0 * 1024.0));
}
}
/**
* 生成预览URL
*/
private static String generatePreviewUrl(FilePo entity) {
// 根据业务逻辑生成预览URL
return "/api/file/preview/" + entity.getId();
}
/**
* 生成下载URL
*/
private static String generateDownloadUrl(FilePo entity) {
// 根据业务逻辑生成下载URL
return "/api/file/download/" + entity.getId();
}
/**
* 检查预览权限
*/
private static Boolean checkPreviewPermission(FilePo entity) {
// 根据业务逻辑检查预览权限
return true;
}
/**
* 检查下载权限
*/
private static Boolean checkDownloadPermission(FilePo entity) {
// 根据业务逻辑检查下载权限
return true;
}
}测试内容分词是否正常
使用分词器分词后,拿分词后的单个分词结果搜索,应该能搜索到结果
jSO
POST /file_v3/_analyze
{
"analyzer": "ik_max_word",
"text": "xxx"
}