网上找到的一个实现:
地址:
https://gist.github.com/HenryJia/23db12d61546054aa43f8dc587d9dc2c
稍微修改后的代码:
import numpy as np
import gym
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
env = gym.make('CartPole-v1')
desired_state = np.array([0, 0, 0, 0])
desired_mask = np.array([0, 0, 1, 0])
P, I, D = 0.1, 0.01, 0.5 ###
N_episodes = 10
N_steps = 50000
for i_episode in range(N_episodes):
state, _ = env.reset()
integral = 0
derivative = 0
prev_error = 0
for t in range(N_steps):
# print(f"step: {t}")
env.render()
error = state - desired_state
integral += error
derivative = error - prev_error
prev_error = error
pid = np.dot(P * error + I * integral + D * derivative, desired_mask)
action = sigmoid(pid)
action = np.round(action).astype(np.int32)
# print(P * error + I * integral + D * derivative, pid, action)
# print(state, action, )
state, reward, done, info, _ = env.step(action)
if done or t==N_steps-1:
print("Episode finished after {} timesteps".format(t+1))
break
env.close()运行效果:
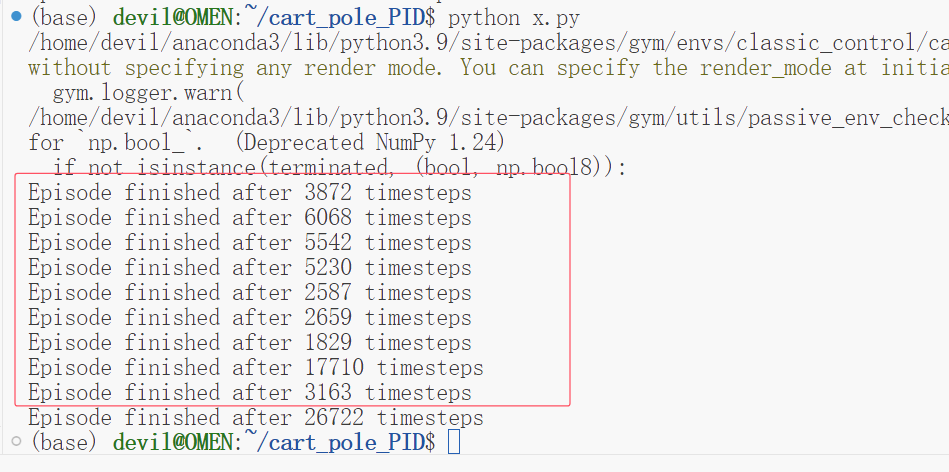
这个表现是极为神奇的,如果不考虑泛化性的话,不考虑使用AI算法和机器学习算法的话,那么不使用强化学习和遗传算法以外的算法,那么使用自动化的算法或许也是不错的选择,并且从这个表现来看这个效果远比使用AI类的算法表现好。
上面的这个代码只考虑小车平衡杆的角度与0的偏差,就可以获得如此高的表现。
根据原地址的讨论:
https://gist.github.com/HenryJia/23db12d61546054aa43f8dc587d9dc2c
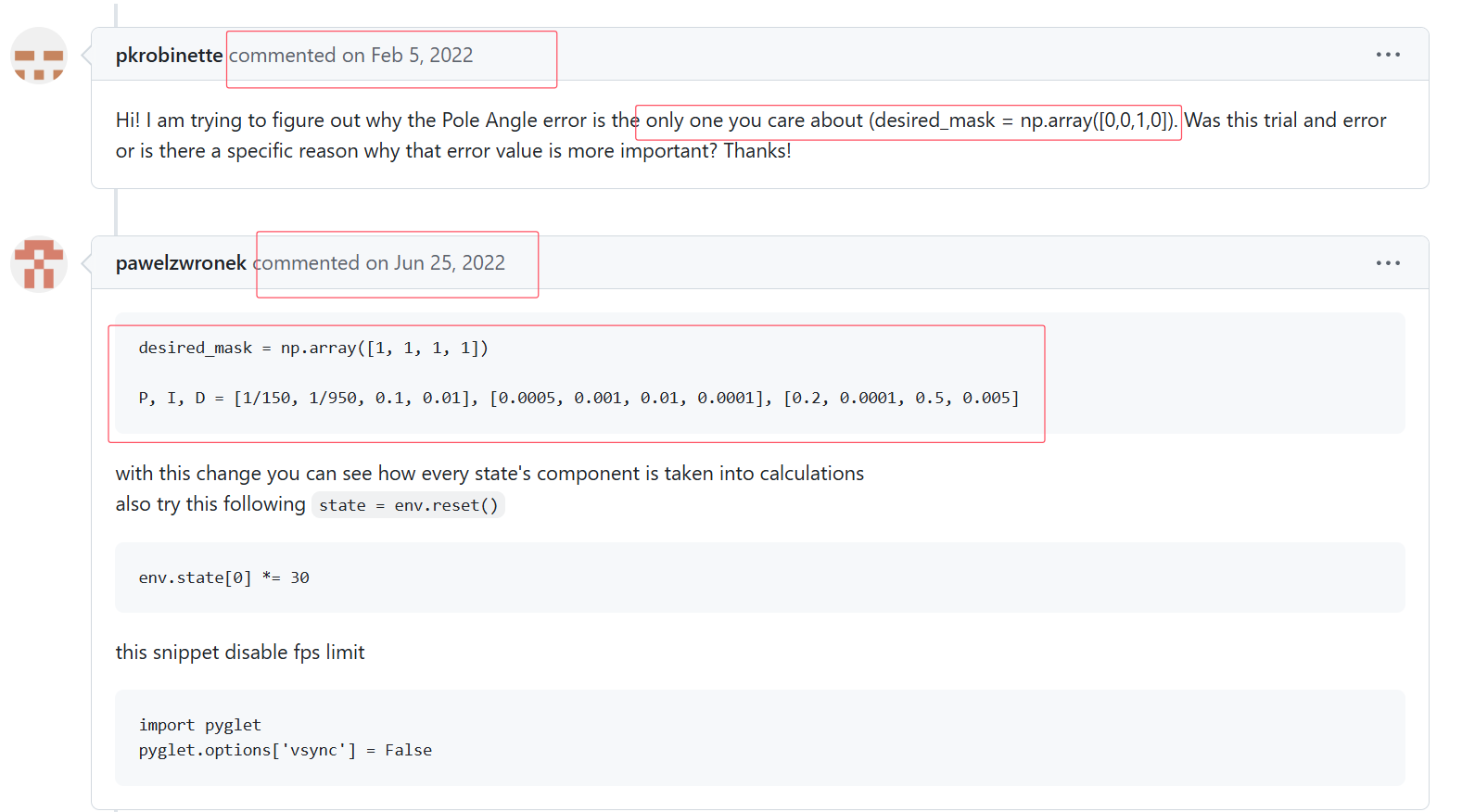
我们可以知道,如果通过调整PID算法的系数,那么可以获得更为优秀的性能表现,为此我们修改代码如下:
点击查看代码
import numpy as np
import gym
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
env = gym.make('CartPole-v1')
desired_state = np.array([0, 0, 0, 0])
# desired_mask = np.array([0, 0, 1, 0])
desired_mask = np.array([1, 1, 1, 1])
# P, I, D = 0.1, 0.01, 0.5 ###
P, I, D = [1/150, 1/950, 0.1, 0.01], [0.0005, 0.001, 0.01, 0.0001], [0.2, 0.0001, 0.5, 0.005]
N_episodes = 10
N_steps = 1000000
for i_episode in range(N_episodes):
state, _ = env.reset()
integral = 0
derivative = 0
prev_error = 0
for t in range(N_steps):
# print(f"step: {t}")
env.render()
error = state - desired_state
integral += error
derivative = error - prev_error
prev_error = error
pid = np.dot(P * error + I * integral + D * derivative, desired_mask)
action = sigmoid(pid)
action = np.round(action).astype(np.int32)
# print(P * error + I * integral + D * derivative, pid, action)
# print(state, action, )
state, reward, done, info, _ = env.step(action)
if done or t==N_steps-1:
print("Episode finished after {} timesteps".format(t+1))
break
env.close()性能表现:
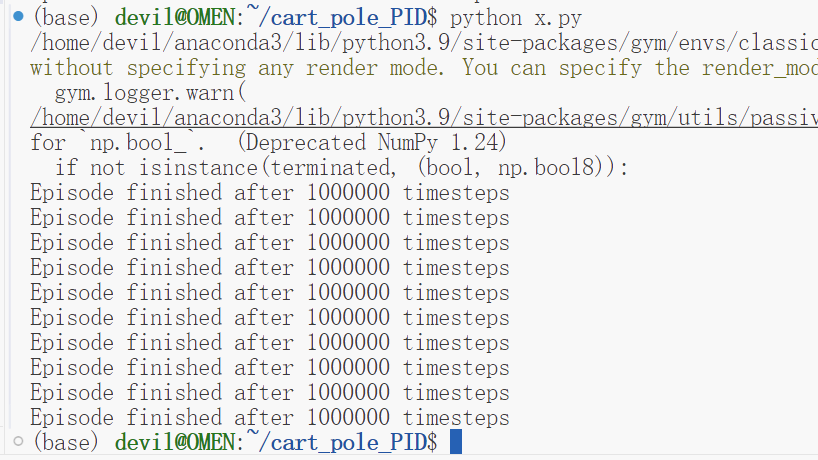
根据这个PID的系数来运行gym下的cartpole游戏,可以认为这个游泳永远不会终止,因为这里我们已经将运行长度设置为100万步。
PS:
需要注意的是PID算法的这个P,I,D系数才是影响算法的关键,而如何获得这个系数也是一个极为难的问题,很多时候是需要使用试错的方法来进行的,可以说有的P,I,D系数可以运行几十步,有的可以运行几百步或几千步,而下面的系数却可以运行上百万步,甚至是永远一直运行,可以说这种PID系数的求解才是真正的关键。
P, I, D = 1/150, 1/950, 0.1, 0.01, 0.0005, 0.001, 0.01, 0.0001, 0.2, 0.0001, 0.5, 0.005