
上一篇:《预测大师的秘籍:揭开时间序列的真相》
序言:一章介绍了序列数据以及时间序列的特性,包括季节性、趋势、自相关性和噪声。你创建了一个用于预测的合成序列,并探索了基本的统计预测方法。在接下来的章节中,你将系统地学习如何利用人工智能模型(机器学习模型)进行时间序列预测。这包括:数据集的创建、模型的构建、模型的训练与测试、架构的验证,以及通过调整超参数优化模型性能。这一篇则主要与大家共同回顾如何创建数据集。
要理解为什么需要这样做,请考虑你在第前几篇中创建的时间序列。图10-1展示了它的一个图表。

图10-1:合成时间序列
如果在某一时刻你想预测时间点 ttt 的值,你需要将其视为时间点 ttt 之前的值的函数。例如,假设你想预测时间步 1200 的时间序列值,它是之前30个值的函数。在这种情况下,从时间步 1170 到 1199 的值将决定时间步 1200 的值,如图10-2所示。
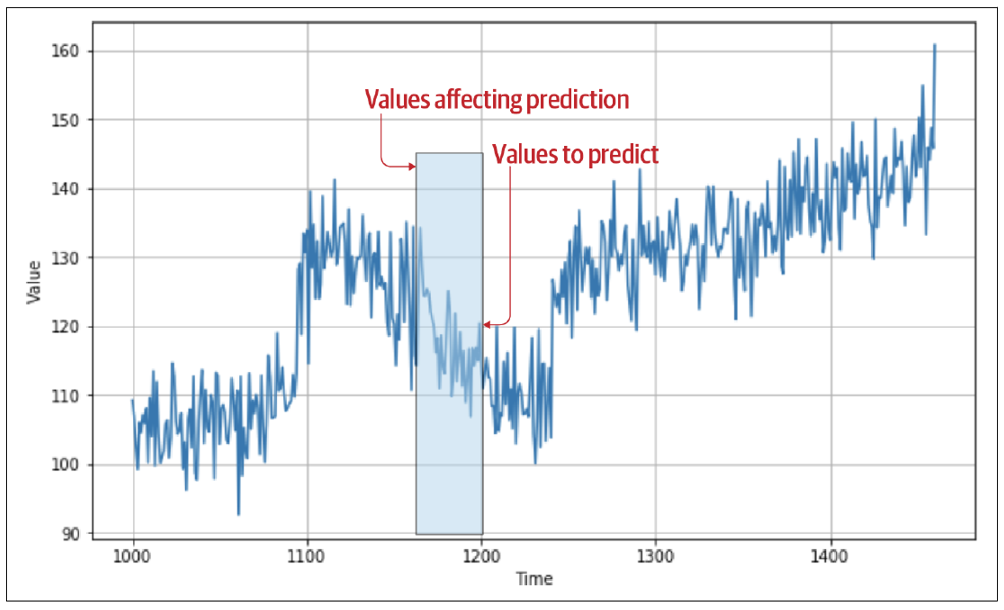
图10-2:前序值对预测的影响现在这开始变得熟悉了:你可以将1170--1199的值视为特征,而将1200的值视为标签。如果你能让你的数据集达到一种状态,使得有一定数量的值作为特征,而紧随其后的一个值作为标签,并对数据集中每个已知值执行这样的操作,你最终将得到一组相当不错的特征和标签,可用于训练模型。
在对第前几篇的时间序列数据集执行这个操作之前,让我们先创建一个非常简单的数据集,它具备相同的属性,但数据量小得多。
创建窗口化数据集
tf.data 库提供了许多对数据操作非常有用的 API。你可以使用这些 API 来创建一个包含数字 0 到 9 的基本数据集,模拟一个时间序列。然后将其转换为一个初步的窗口化数据集。代码如下:
dataset = tf.data.Dataset.range(10)
dataset = dataset.window(5, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(5))
for window in dataset:
print(window.numpy())
首先,它使用 range 创建数据集,这个方法简单地生成一个包含从 0 到 n−1n - 1n−1 的数据集,这里 n=10n = 10n=10。
接着,通过调用 dataset.window 并传入参数 5,指定将数据集分割成包含五个元素的窗口。指定 shift=1 表示每个窗口将相对于前一个窗口向后移动一个位置:第一个窗口包含从 0 开始的五个元素,第二个窗口包含从 1 开始的五个元素,依此类推。设置 drop_remainder=True 指定在数据集接近尾部时,如果窗口大小小于指定的五个元素,则这些窗口会被丢弃。
根据窗口定义,数据集的分割过程可以进行。你可以通过 flat_map 函数完成这个操作,在本例中请求一个包含五个窗口的批次。运行上述代码将得到以下结果:
0 1 2 3 4
1 2 3 4 5
2 3 4 5 6
3 4 5 6 7
4 5 6 7 8
5 6 7 8 9
但是之前提到过,我们想从中生成训练数据,其中 nnn 个值定义一个特征,而后续的一个值作为标签。你可以通过添加另一个 lambda 函数,将每个窗口分割成最后一个值之前的所有值(特征)和最后一个值(标签)。这会生成一个 xxx 和 yyy 数据集,如下所示:
dataset = tf.data.Dataset.range(10)
dataset = dataset.window(5, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(5))
dataset = dataset.map(lambda window: (window:-1, window-1:))
for x, y in dataset:
print(x.numpy(), y.numpy())
结果如下,符合你的预期:窗口中的前四个值可以被视为特征,而后续的一个值则是标签:
0 1 2 3\] \[4
1 2 3 4\] \[5
2 3 4 5\] \[6
3 4 5 6\] \[7
4 5 6 7\] \[8
5 6 7 8\] \[9
由于这是一个数据集,它还支持通过 lambda 函数进行随机打乱和批处理。下面是将数据集随机打乱,并设置批次大小为 2 的代码:
dataset = tf.data.Dataset.range(10)
dataset = dataset.window(5, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(5))
dataset = dataset.map(lambda window: (window:-1, window-1:))
dataset = dataset.shuffle(buffer_size=10)
dataset = dataset.batch(2).prefetch(1)
for x, y in dataset:
print("x = ", x.numpy())
print("y = ", y.numpy())
结果如下:第一个批次有两组 xxx(分别从 2 和 3 开始),以及它们的标签;第二个批次有两组 xxx(分别从 1 和 5 开始),以及它们的标签,依此类推:
x = \[2 3 4 5
3 4 5 6\]
y = \[6
7\]
x = \[1 2 3 4
5 6 7 8\]
y = \[5
9\]
x = \[0 1 2 3
4 5 6 7\]
y = \[4
8\]
通过这种技术,你现在可以将任何时间序列数据集转换为一个神经网络的训练数据集。在下一节中,你将学习如何从第九章的合成数据中创建一个训练集。接下来,你将构建一个简单的 DNN,使用这些数据进行训练,并用于预测未来的值。
创建时间序列数据集的窗口化版本
回顾一下,这是上一章中用来创建一个合成时间序列数据集的代码:
def trend(time, slope=0):
return slope * time
def seasonal_pattern(season_time):
return np.where(season_time < 0.4,
np.cos(season_time * 2 * np.pi),
1 / np.exp(3 * season_time))
def seasonality(time, period, amplitude=1, phase=0):
season_time = ((time + phase) % period) / period
return amplitude * seasonal_pattern(season_time)
def noise(time, noise_level=1, seed=None):
rnd = np.random.RandomState(seed)
return rnd.randn(len(time)) * noise_level
time = np.arange(4 * 365 + 1, dtype="float32")
series = trend(time, 0.1)
baseline = 10
amplitude = 20
slope = 0.09
noise_level = 5
series = baseline + trend(time, slope)
series += seasonality(time, period=365, amplitude=amplitude)
series += noise(time, noise_level, seed=42)
这段代码会生成一个类似于图 10-1 的时间序列。如果你想修改它,可以随意调整各个常量的值。
当你拥有了这个序列后,可以使用类似上一节中的代码将其转换为窗口化数据集。下面是一段独立定义的函数:
def windowed_dataset(series, window_size, batch_size, shuffle_buffer):
dataset = tf.data.Dataset.from_tensor_slices(series)
dataset = dataset.window(window_size + 1, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(window_size + 1))
dataset = dataset.shuffle(shuffle_buffer).map(
lambda window: (window:-1, window-1))
dataset = dataset.batch(batch_size).prefetch(1)
return dataset
需要注意的是,这里使用了 tf.data.Dataset 的 from_tensor_slices 方法,该方法可以将一个序列转换为 Dataset。关于这个方法的更多信息可以参考 TensorFlow 文档。
现在,要生成一个可以用于训练的数据集,你可以简单地使用以下代码。首先,将序列拆分为训练集和验证集,然后指定窗口大小、批量大小以及随机缓冲区大小:
split_time = 1000
time_train = time:split_time
x_train = series:split_time
time_valid = timesplit_time:
x_valid = seriessplit_time:
window_size = 20
batch_size = 32
shuffle_buffer_size = 1000
dataset = windowed_dataset(x_train, window_size, batch_size, shuffle_buffer_size)
现在需要记住的重要一点是,你的数据是一个 tf.data.Dataset,因此可以很方便地作为单个参数传递给 model.fit,而 tf.keras 会处理其余部分。
如果你想查看数据的具体样子,可以使用如下代码:
dataset = windowed_dataset(series, window_size, 1, shuffle_buffer_size)
for feature, label in dataset.take(1):
print(feature)
print(label)
这里的 batch_size 被设置为 1,是为了让结果更加易读。运行后,你会得到类似以下的输出,其中一组数据位于批次中:
tf.Tensor(
[[75.38214 66.902626 76.656364 71.96795 71.373764 76.881065
75.62607 71.67851 79.358665 68.235466 76.79933 76.764114
72.32991 75.58744 67.780426 78.73544 73.270195 71.66057
79.59881 70.9117 ]],
shape=(1, 20), dtype=float32)
tf.Tensor(67.47085, shape=(1,), dtype=float32)
第一批数字是特征。我们将窗口大小设置为 20,所以它是一个 1×201 \times 201×20 的张量。第二个数字是标签(在本例中为 67.47085),模型将尝试用这些特征来拟合这个标签。你将在下一节看到模型是如何工作的。
**总结:**本篇跟大家一起为模型准备了两种数据集:一种是窗口化数据集,另一种是结合时间序列特性生成的训练数据集,为完成整个模型的研发工作做足准备工作。