vmagent如何快速采集和转发Metrics
本文介绍了vmagent的设计细节,参考自:vmagent-how-it-works
VictoriaMetrics agent是一个轻量级工具,用于采集不同源的指标。vmagent可以在转发指标前(通过"relabeling")定制指标(降低基数、流聚合、去重等)。
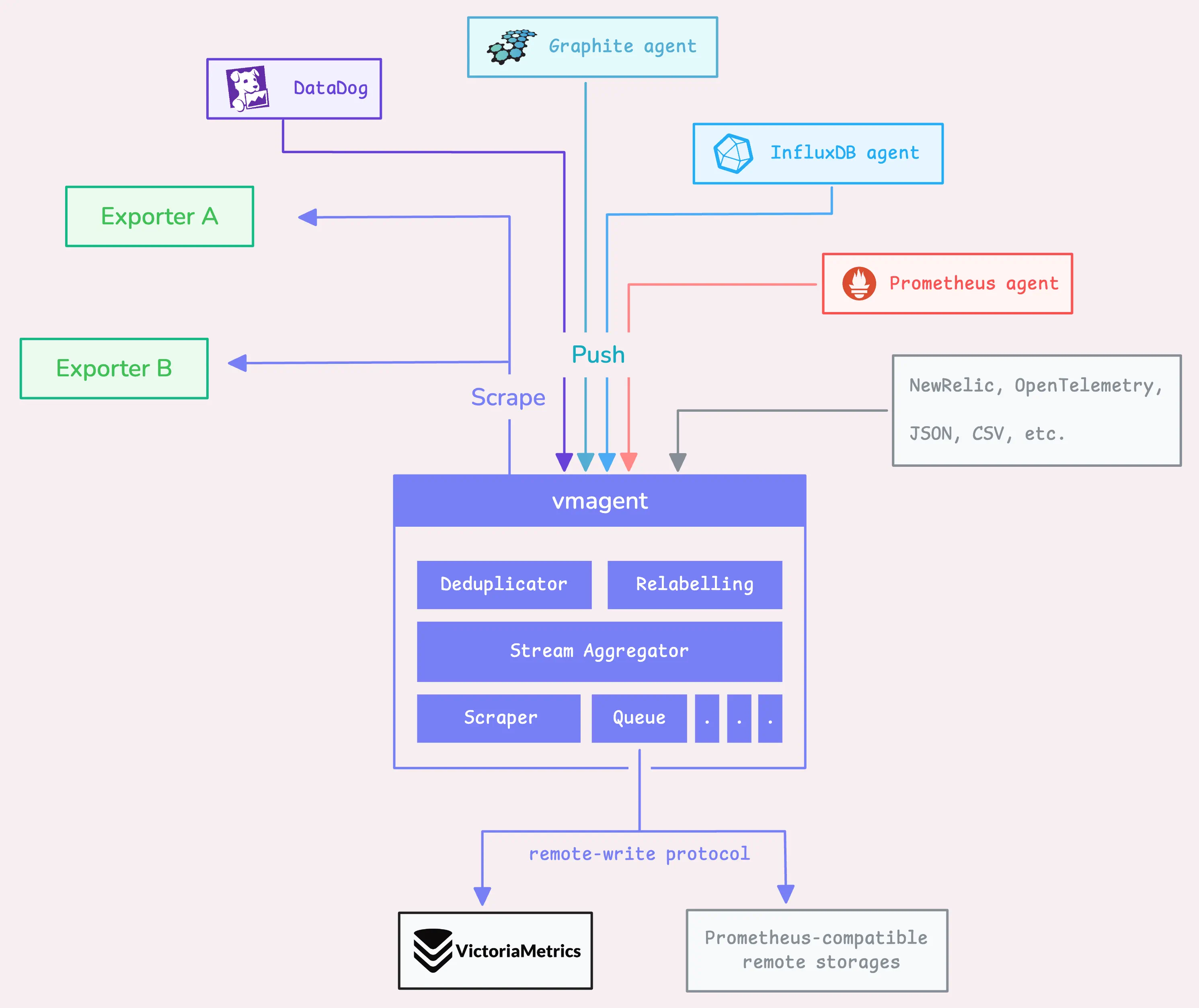
第一步:通过API或抓取方式接收数据
HTTP API方式
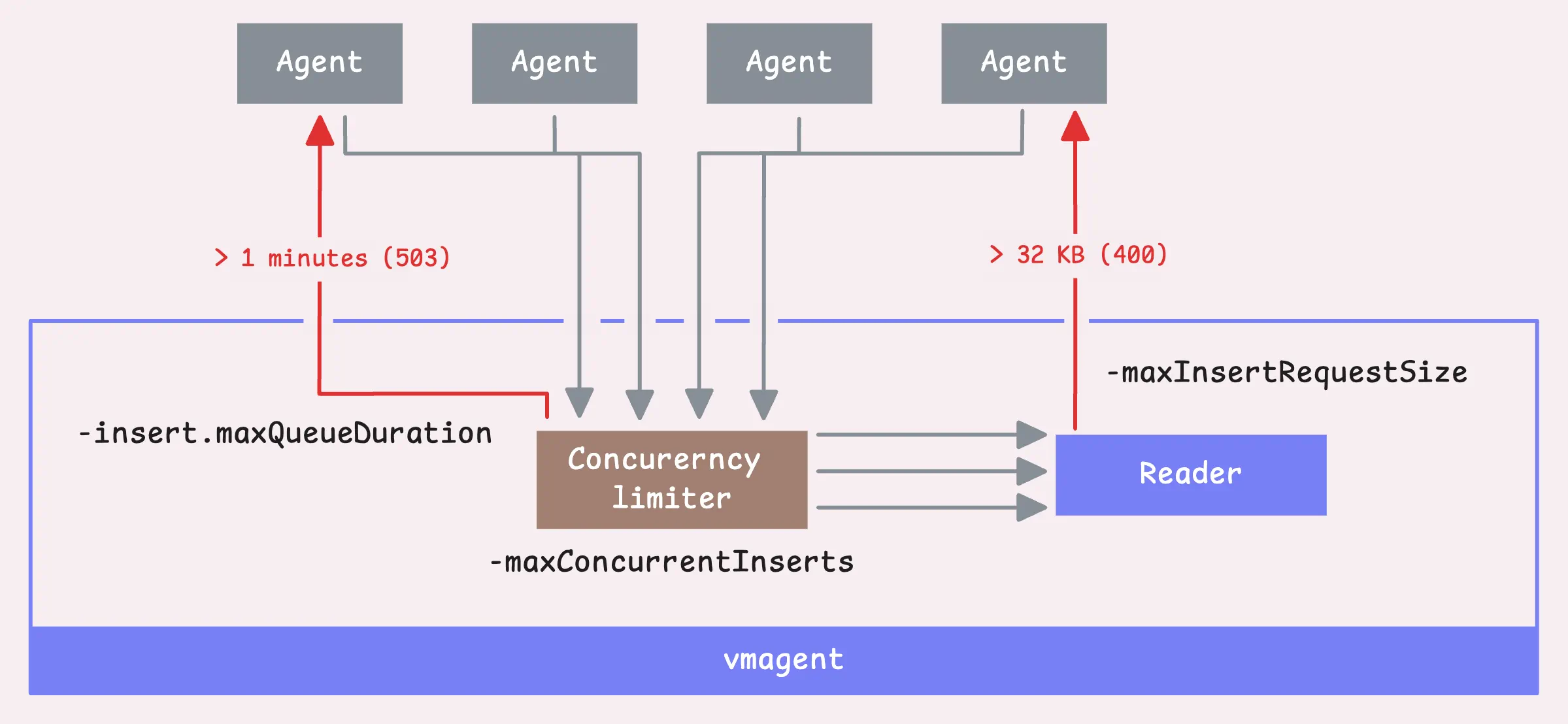
并发限速
vmagent会通过一个并发限速器来读取数据,默认情况下,允许2x CPU core数目的并发insert请求(-maxConcurrentInserts),如果所处环境的网络较慢,可以适当提高该值来优化数据传输速率。
如果一个请求阻塞超过1分钟(-insert.maxQueueDuration),vmagent会返回503。
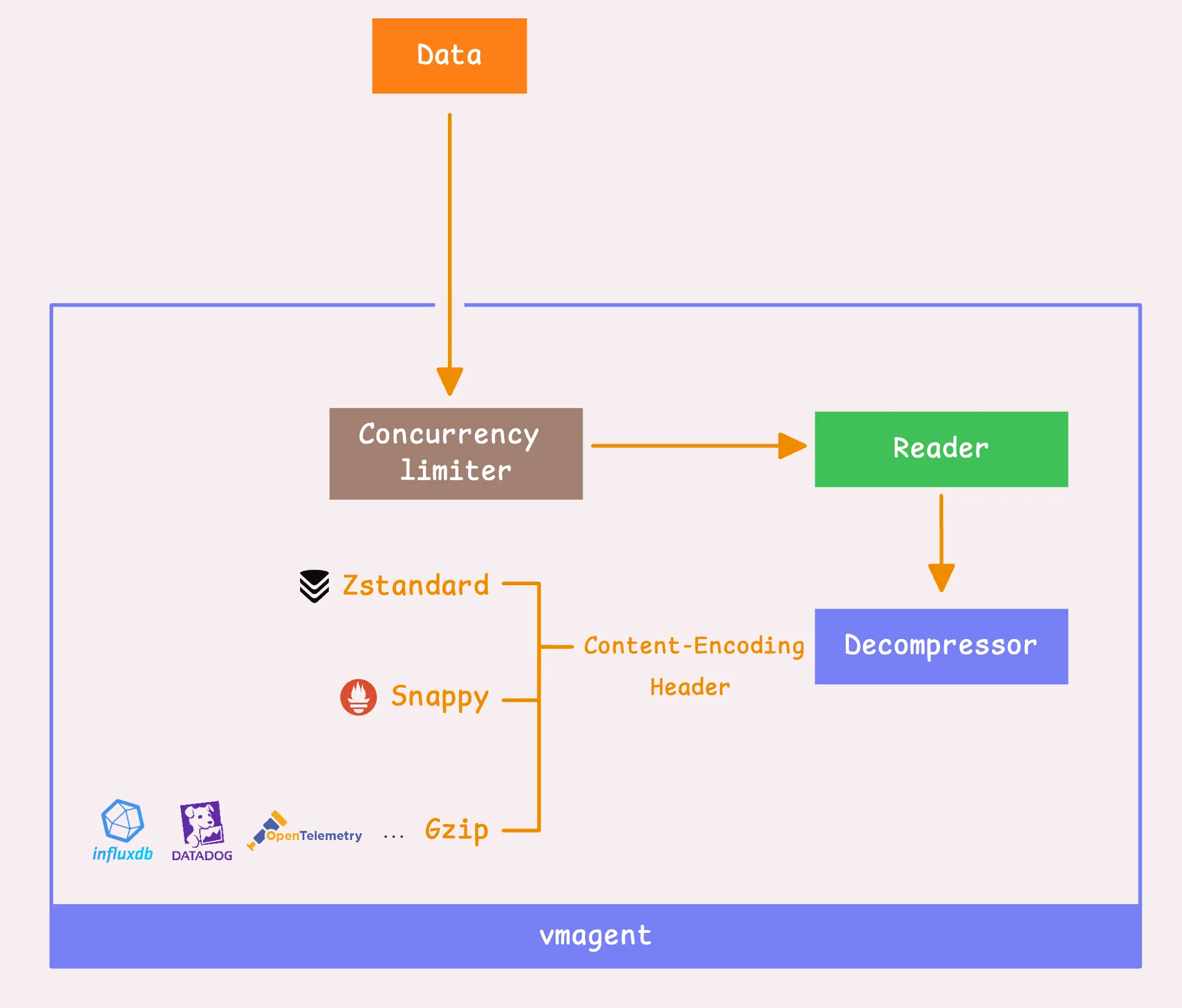
解压缩
在读取数据之后,vmagent需要根据请求头部的压缩类型来解压数据。vmagent支持3种remote write协议:Snappy、Zstandard(zstd)、Gzip。VictoriaMetrics的remote write协议采用的是zstd,相比其他方式,它可以降低2~4倍的网络流量,但需要额外约10%的CPU资源。
抓取方式
除通过HTTP API push方式获取数据外,vmagent还支持按照一定间隔从目标抓取指标。该方式与prometheus的pull方式相同:
yml
config:
global:
scrape_interval: 10s
scrape_configs:
- job_name: "kubernetes-service-endpoints-slow"
scrape_interval: 5m
scrape_timeout: 30s
...当数据加载到内存之后,有两种处理模式:流模式(以chunk为单位处理)和一次性处理模式。
流模式和一次性处理模式
这两种方式都各有优缺点。对于较小的数据,一次性处理更加高效;而对于较大的数据,使用流模式,以64 KB为单位处理数据,对资源来说更加友好。
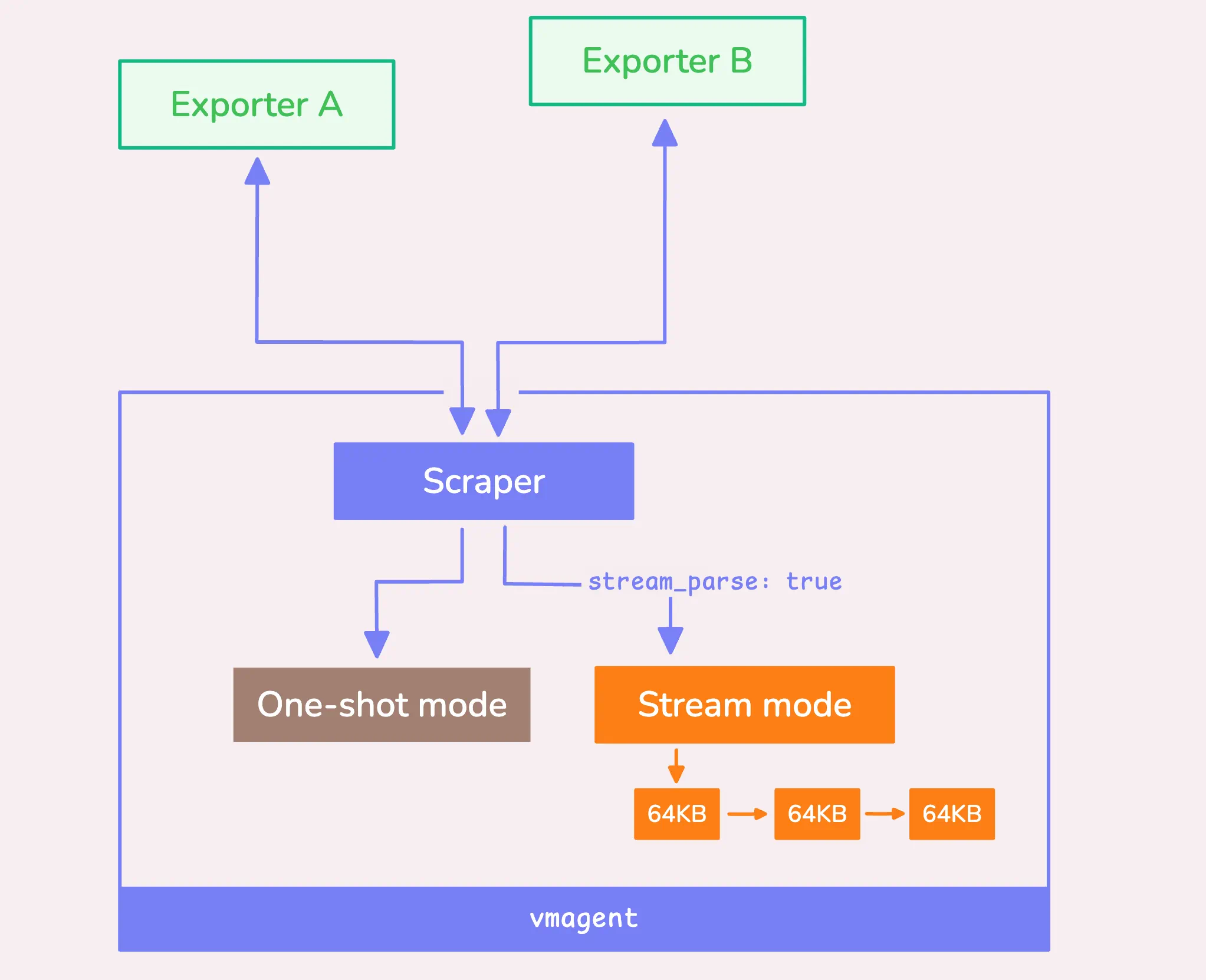
默认情况下,当数据超过1MB(-promscrape.minResponseSizeForStreamParse)时,vmagent会自动转换为流模式。
第二步:全局relabel和降低基数
现在,已经将原始数据转换为时序数据,vmagent需要将数据发送到远端存储。如果存储系统down(可能因为过载或出现故障),则vmagent会将数据发送到一个本地存储(默认启用),避免丢失该存储的数据。
如果禁用持久化队列,则直接丢弃数据。
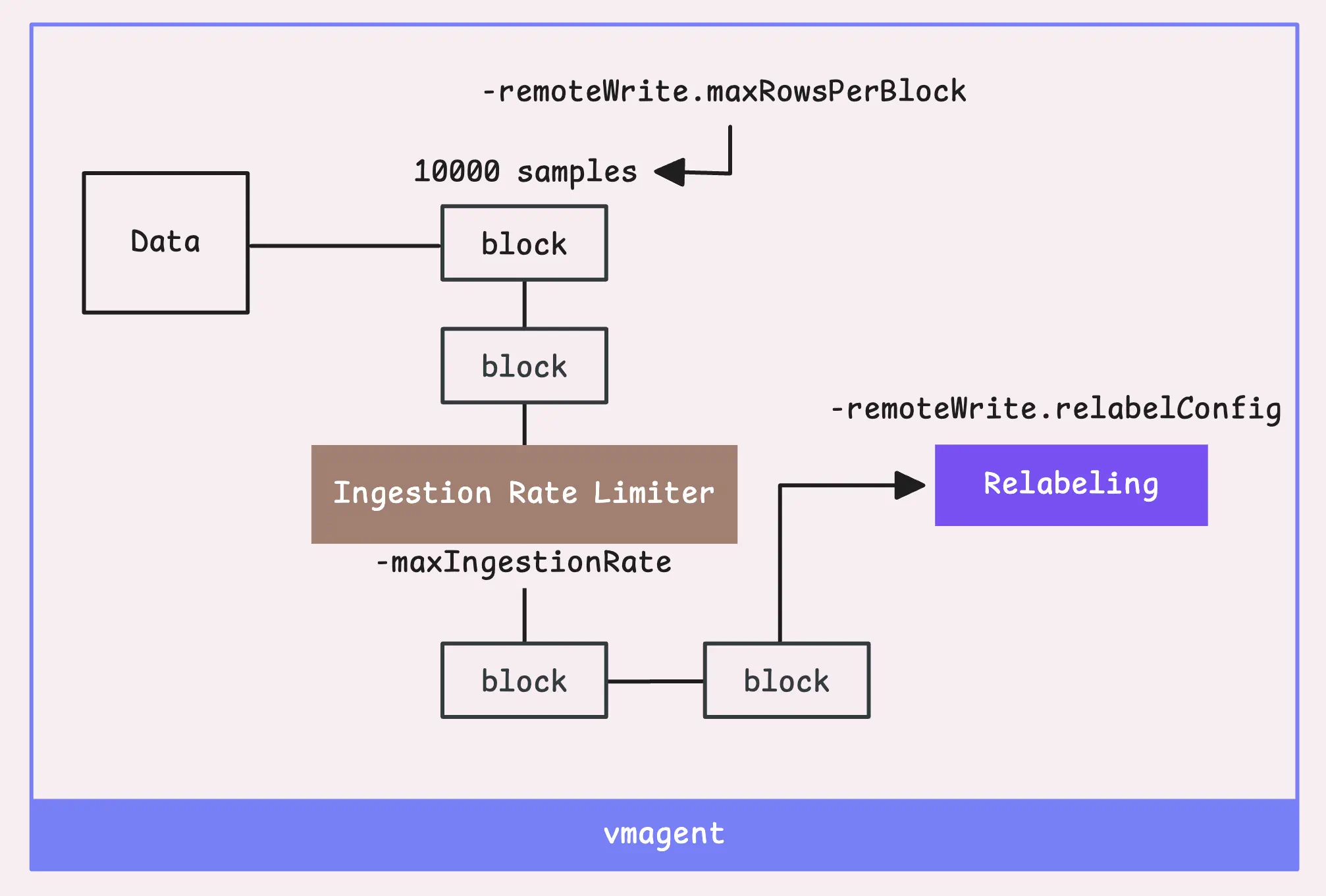
为了在内存和性能方面保持高效,vmagent将数据拆分为块(block),每个块有2个限制:10,000条样本(-remoteWrite.maxRowsPerBlock)或100,000个labels(通常是10倍的采样量)。
当一个时序块就绪后,会引入一个全局采样限速器来控制vmagent每秒可以采集的样本数(-maxIngestionRate),默认没有限制。
高基数时序数据会对远端存储造成压力。为此,可以通过-remoteWrite.maxHourlySeries 和 -remoteWrite.maxDailySeries控制一定周期内唯一时序数据的最大数目,超过限制的时序数据都将被丢弃,默认无限制。
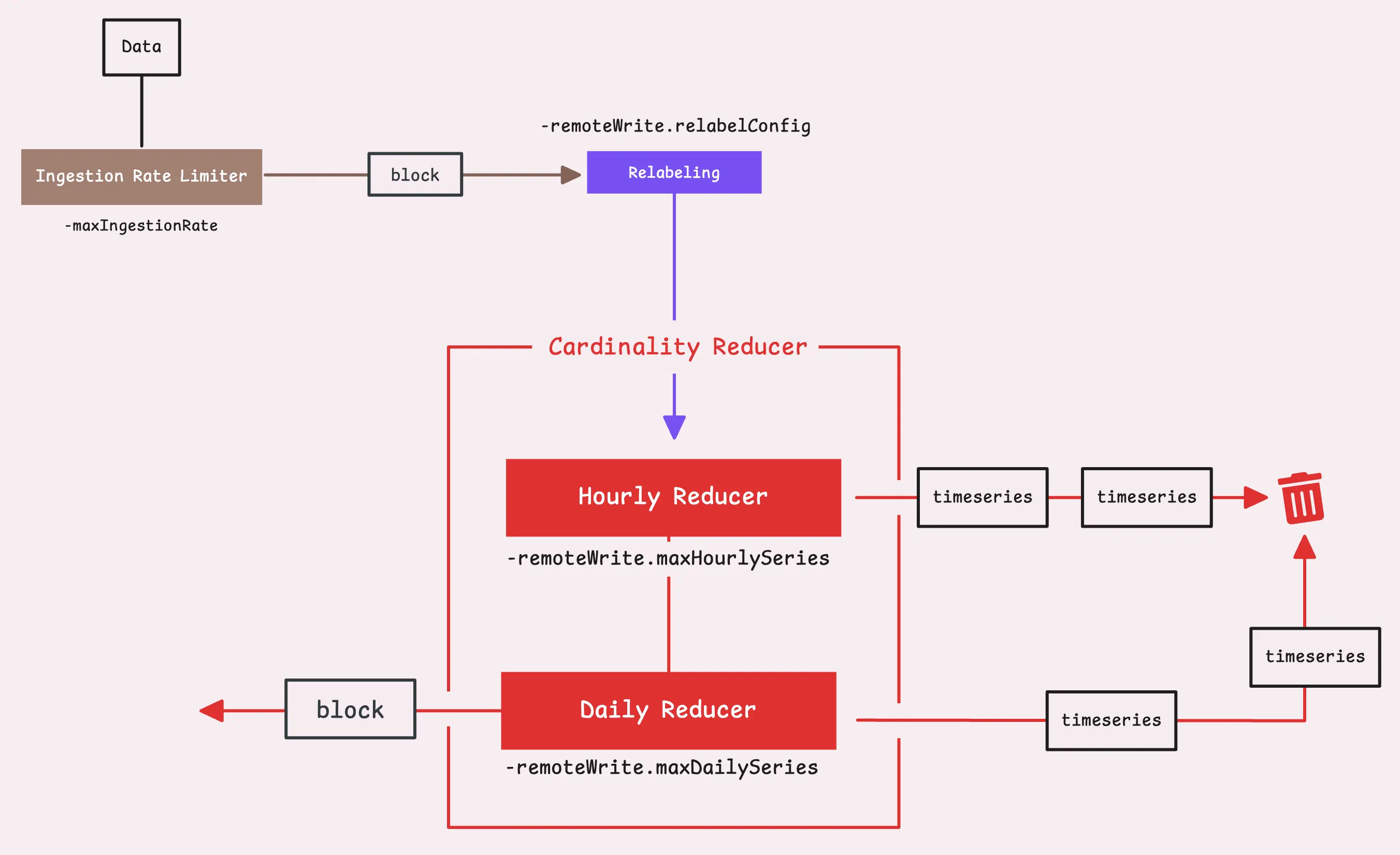
第三步:全局去重和流聚合
这两种方式都是为了降低数据量,前者会导致数据丢失,后者采用的是一种数据聚合方式。
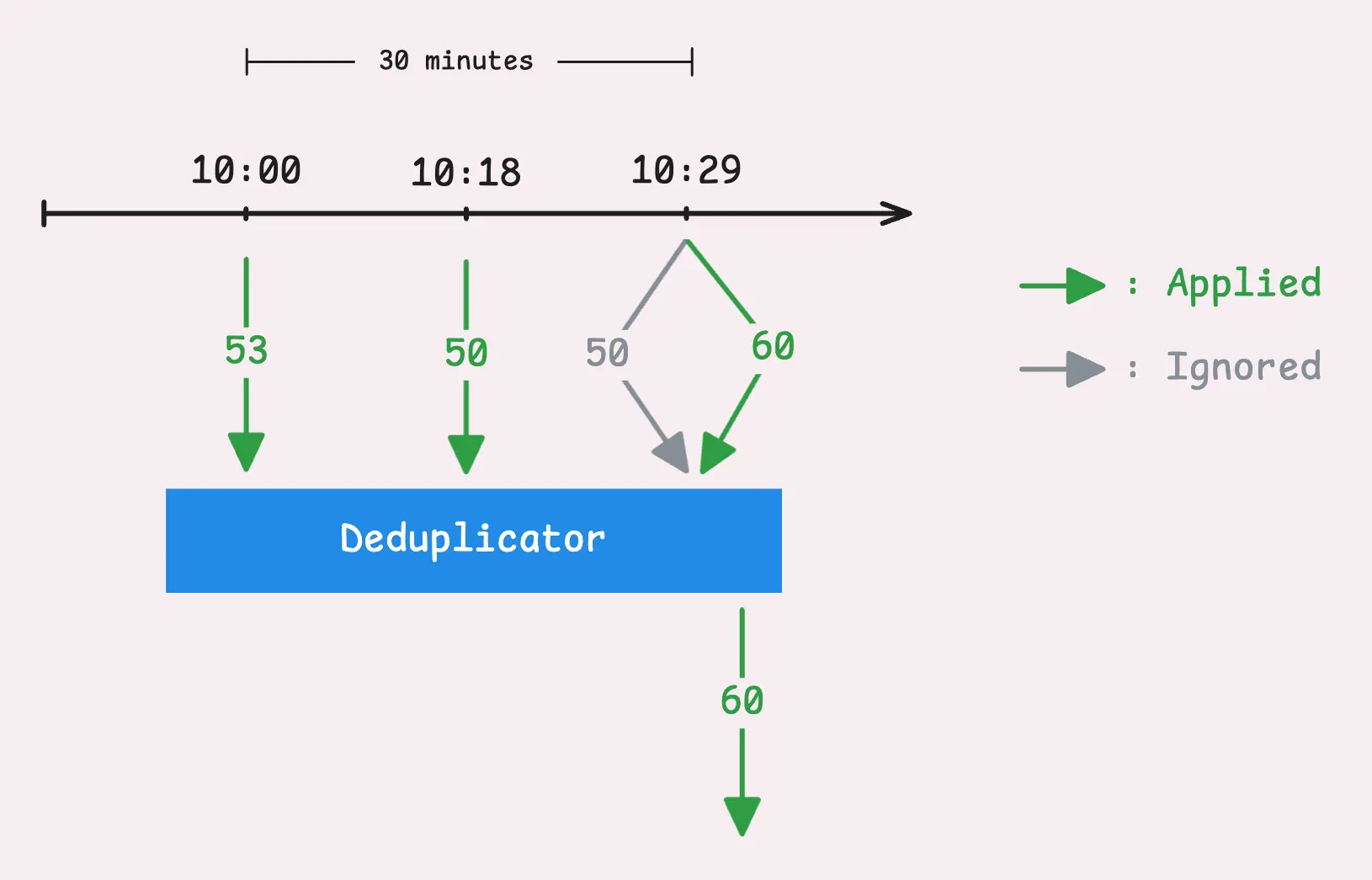
vmagent还可以去重,移除不需要的时序数据,目标是在一个特定的时间帧( -streamAggr.dedupInterval)内仅保留最重要的数据点。例如将全局去重间隔设置为30s,则vmagent会:
- 在30s的窗口内,对于同一个时间序列,vmagent会仅保留最新的一条样本,即具有最高时间戳的样本。
- 如果两条样本具有相同的时间戳,则保留具有最高值的那条。
下一步是流聚合,这是一种在将指标发送到存储(远端或本地)之前对指标进行浓缩或总结的方式。
假设每秒采集的数据量比较大,对每条数据进行保存会占用大量空间,且会放慢查询速度,同时又不希望因为使用去重而导致数据丢失,此时可以采用流聚合。
例如下面流聚合方式:
yml
- match: '{__name__=~".+_total"}'
interval: 5m
outputs: [total]这种情况下,每5分钟会保存一个以"_total"结尾的指标点。因此,如果原始指标为some_metric_total,则聚合后的指标为some_metric_total:5m_total,这样就减少了数据量,且不会丢失重要的信息。
在启用流聚合后,vmagent会将数据发送到一个聚合器,聚合器具有自己的内存缓存,最终通过后台将缓存刷新到远端存储。
默认情况下,聚合器只会"偷取"并丢弃匹配聚合规则的时序数据,作为聚合器的输入。有如下两种模式:
-streamAggr.keepInput:默认false。是否同时保存匹配和不匹配的input时间序列。如果为true,则都保存,为false,则按照-streamAggr.dropInput处理。-streamAggr.dropInput:默认false。是否丢弃所有input时间序列或仅丢弃匹配的时间序列,如果为true,则丢弃所有input 时间序列,为false,则仅丢弃匹配的input时间序列
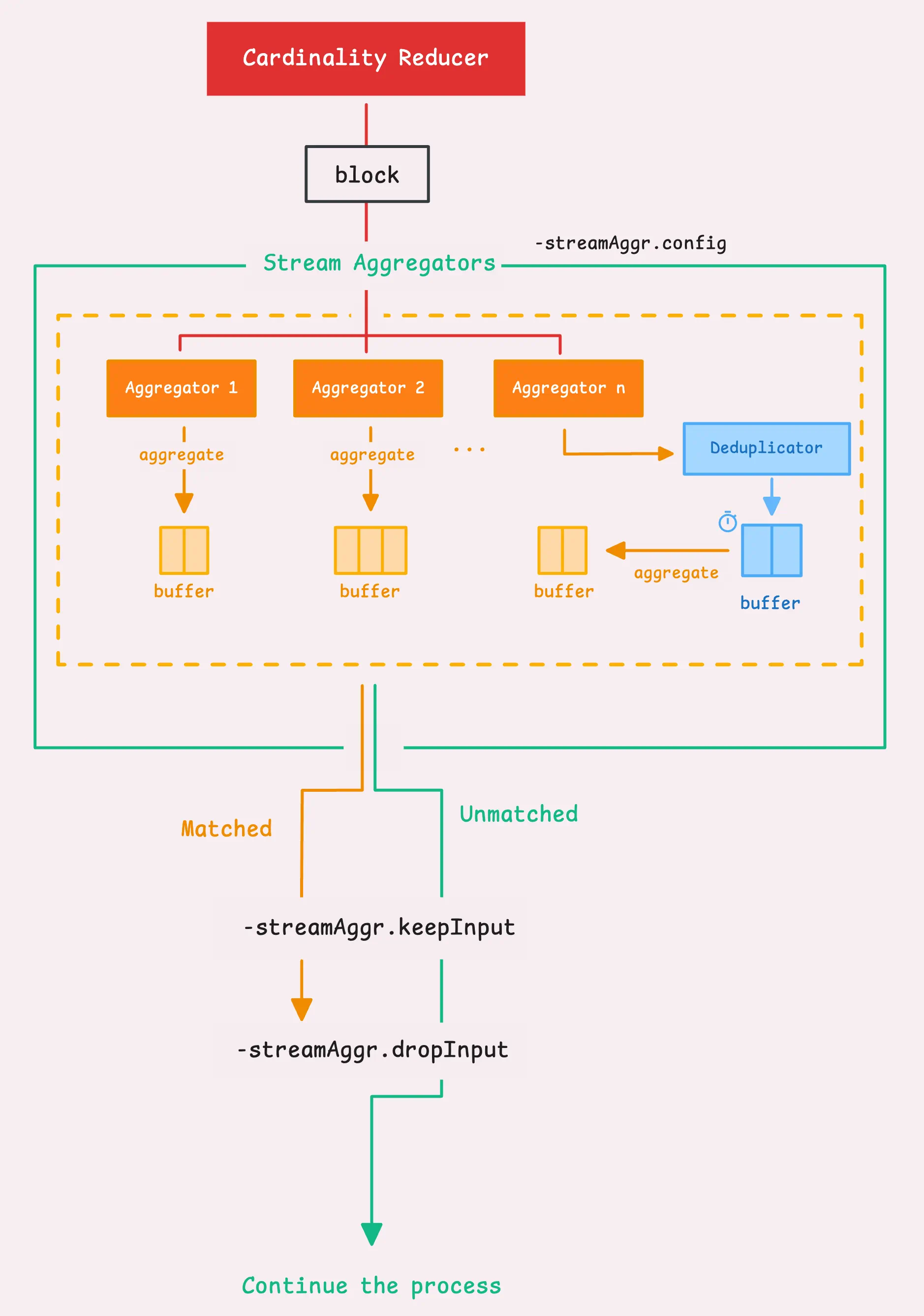
这里需要注意的是,全局去重也会被应用到流聚合中,首先会在去重间隔内过滤数据,然后再将数据刷新到聚合器中。另外,若要同时使用去重和流聚合,则需要保证流聚合间隔要大于去重间隔,且为去重间隔的倍数。
此外还可以针对单条流设置去重。下面配置中,每分钟会聚合一次数据,且每30s的窗口内会执行去重过滤。
yml
- match: '{__name__=~".+_total"}'
interval: 1m
outputs: [total]
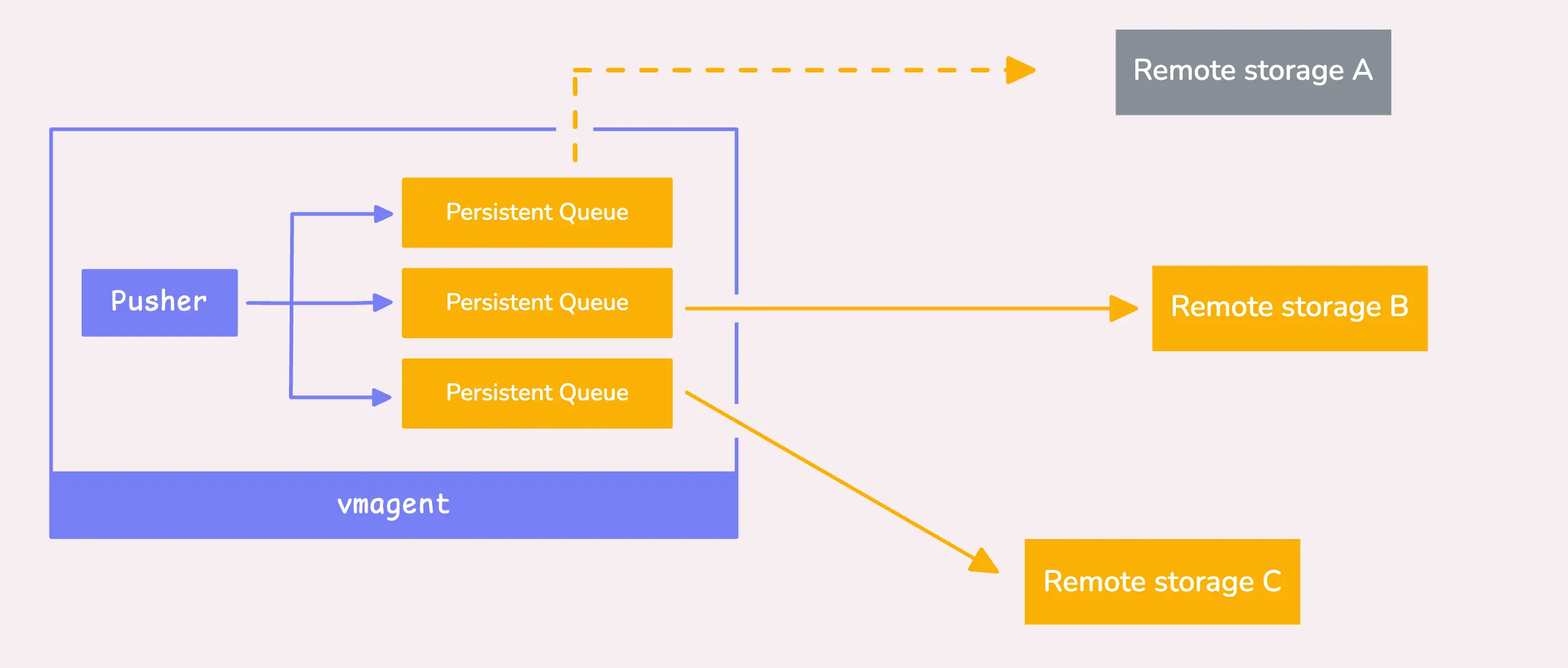
dedup_interval: 30s第四步:分片(sharding)和复制(replication)
至此处理的仍然是时序数据块(10,000条采样或100,000个labels)。下面需要考虑将数据发往远端存储,有两种策略:
- 复制:如果有多个远端存储 (
-remoteWrite.url),则vmagent会将所有时序数据发往每个远端存储。 - 分片:如果设置了分片标识 (
-remoteWrite.shardByURL),则不会将相同的数据发到每个存储系统中,而会切分这些数据,然后均匀分布到各个存储中。
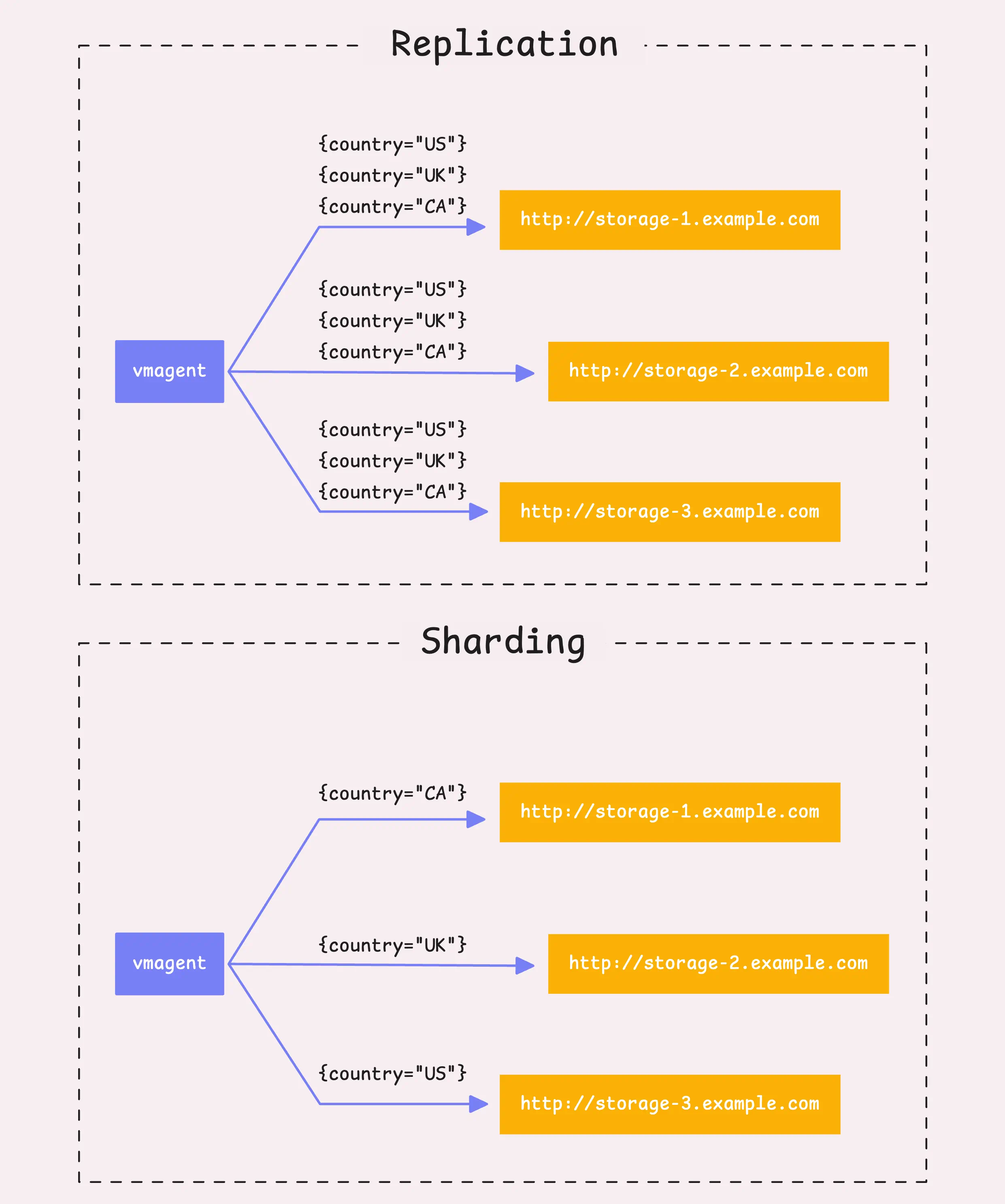
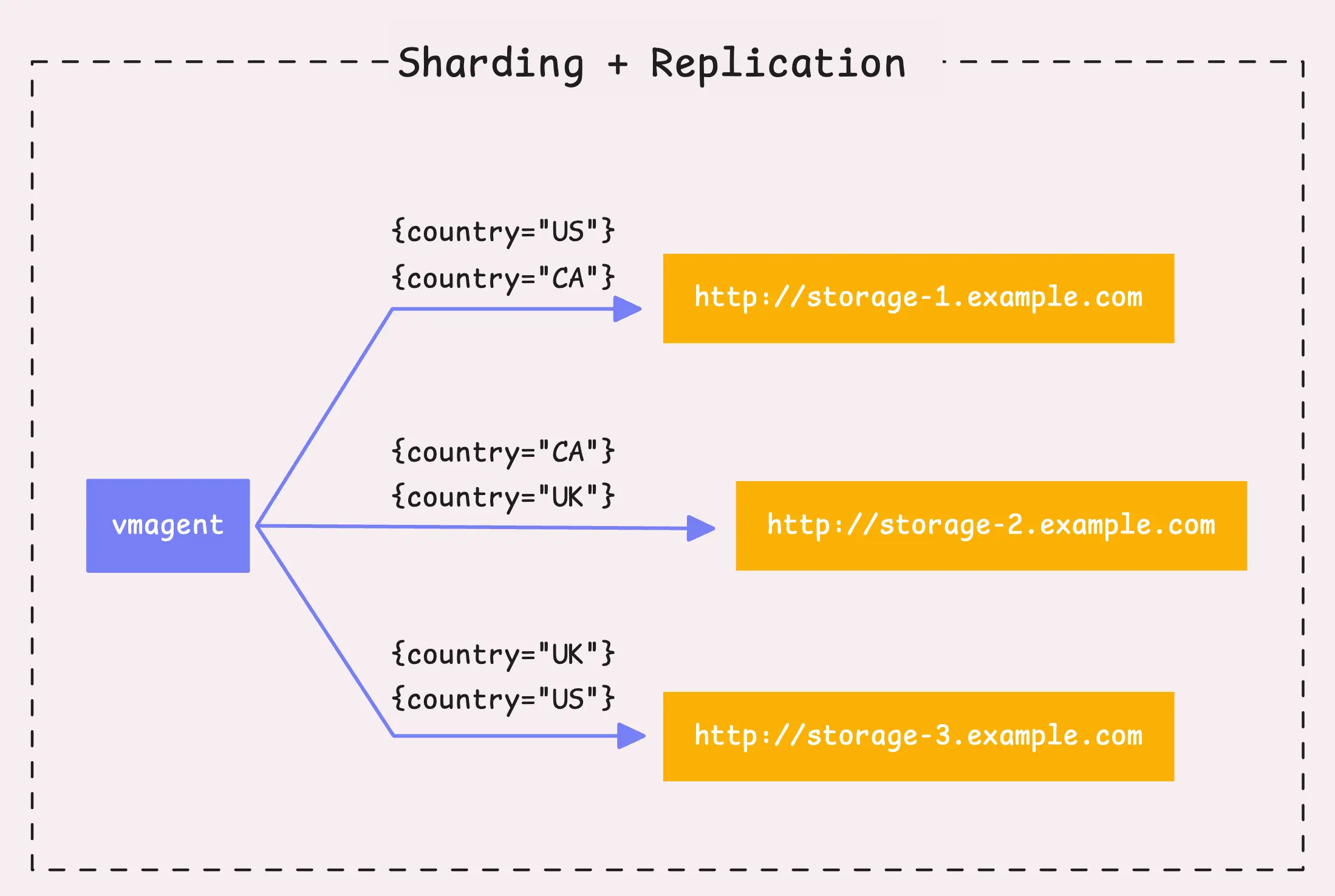
对于分片,vmagent会针对每个时间序列,使用xxHash函数对组合的labels进行哈希计算,并用生成的64-bit哈希值来决定时间序列的归属。可以通过-remoteWrite.shardByURL.labels指定用于计算分片的labels,以及使用-remoteWrite.shardByURL.ignoreLabels来忽略计算分片的labels。
为了提高数据的可用性,可以启用分片复制(-remoteWrite.shardByURLReplicas),即一个分片有多个副本。默认情况下。一个分片只有一个副本(无复制)。
第五步:对每个远端存储进行微调,四舍五入采样值
至此,可以使用分片或复制的方式将数据发往目的地。每个远端存储都对应一个管理器,称为"远端写入上下文"(remoteWriteCtx),该上下文负责处理上面提到的所有操作,但仅针对单个存储。下面看下如何针对单个存储处理流聚合和去重:
- 首先针对单个远端存储执行relabel(
-remoteWrite.urlRelabelConfig) - 执行流聚合 (
-remoteWrite.streamAggr.config)。需要注意的是,不要混用全局流聚合和单存储流聚合 - 执行去重 (
-remoteWrite.streamAggr.dedupInterval) - 最后为所有时序数据添加全局标签 (
-remoteWrite.label),这些标签不受relabel的影响
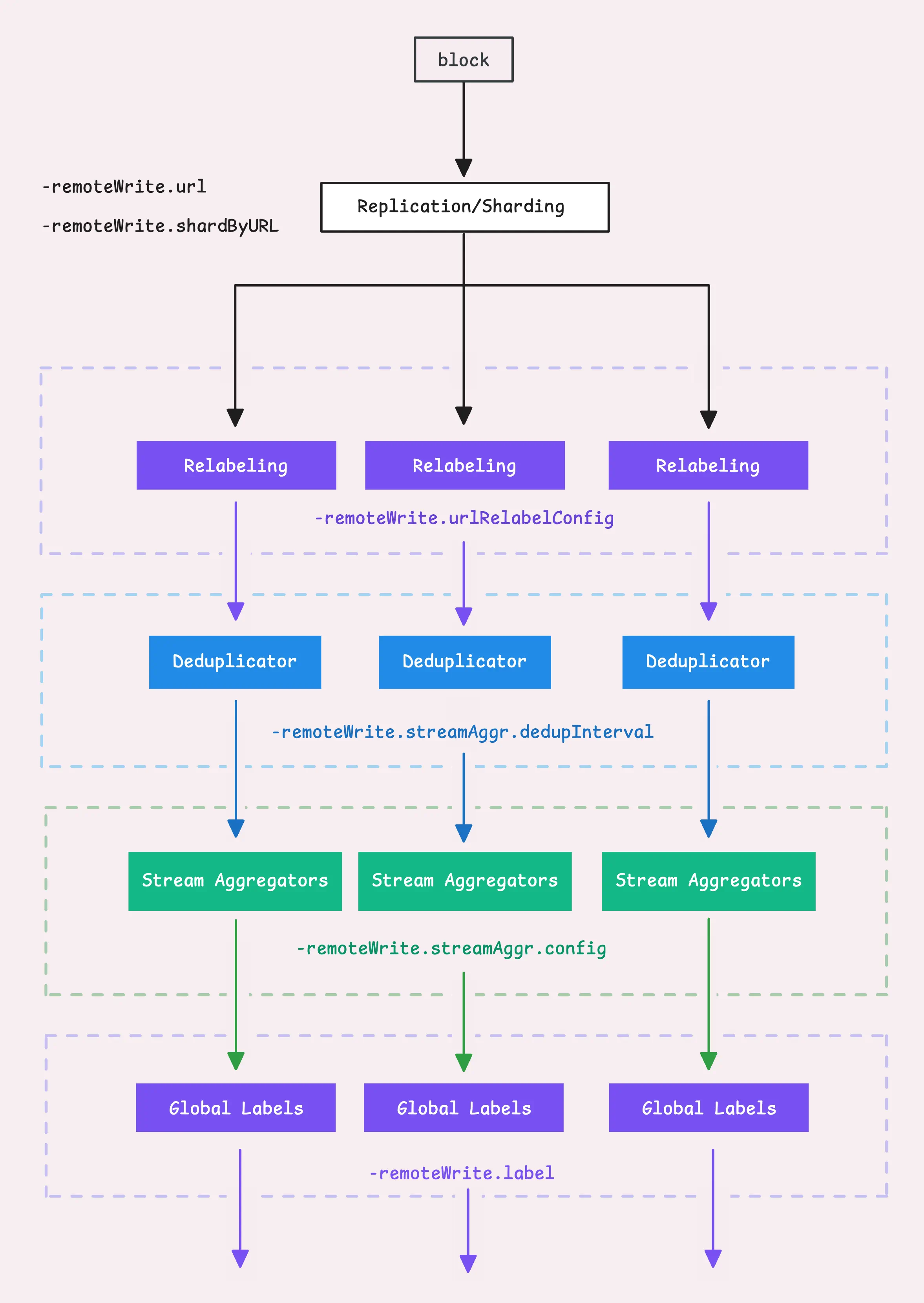
另外vmagent还可以修改时序数据的值:
- 有效数字法(
-remoteWrite.significantFigures):处理数字的精度,如12345.6789四舍五入到2位有效数字后变为12000 - 小数点位 (
-remoteWrite.roundDigits):负责处理保留多少位小数点,如12345.6789四舍五入到小数点后2位后变为12345.68
第六步:刷新:Fast Queue
下一步将数据刷新到内存队列,称为"fast queue",它是一个混合系统,包含内存队列和基于文件的队列(持久队列)。fast queue用于保存由于远端存储跟不上采样速率而累积的样本。
在前面的处理中,vmagent使用snappy或zstd解压了时序数据,这里需要在将其发送到fast queue之间再次压缩。如果压缩之后的数据块大于8MB (-remoteWrite.maxBlockSize),则vmagent会将其一切为二,如果仍然大于8MB,则继续递归拆分,直到达到8MB的限制。
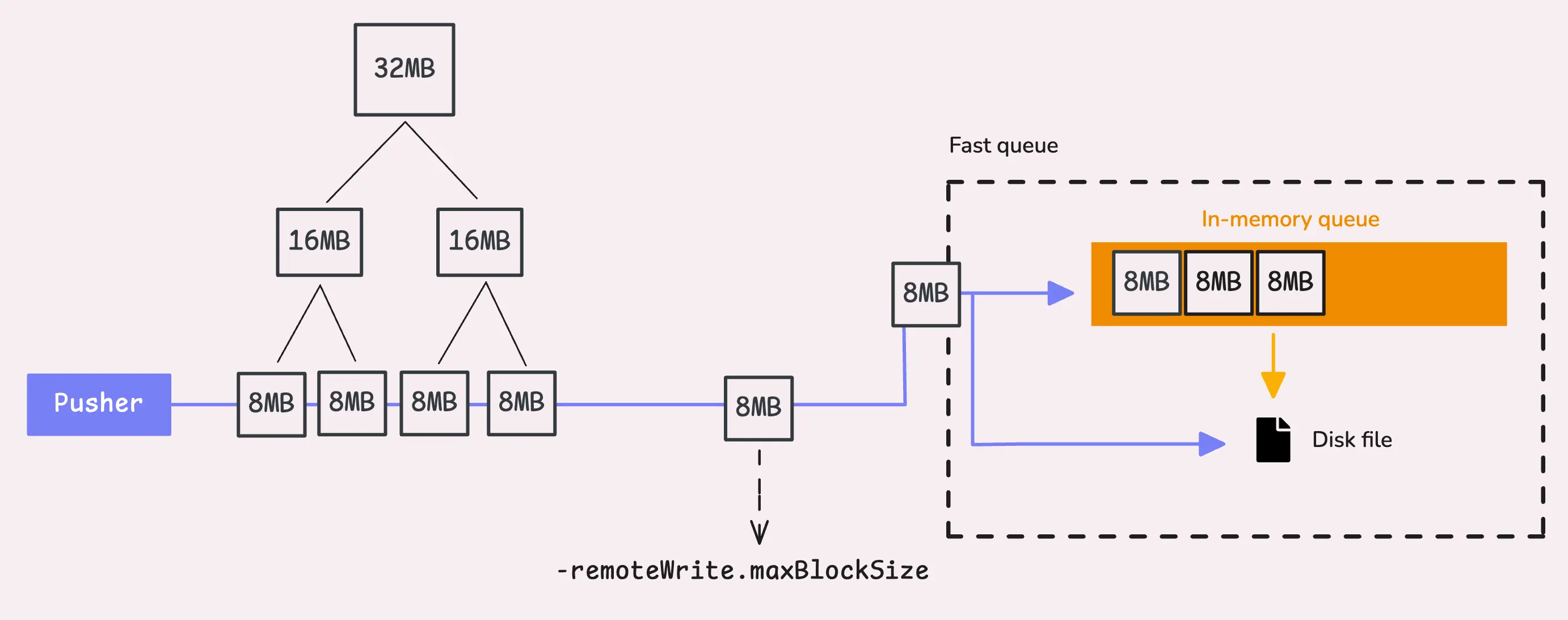
内存队列
内存队列实际上是一个简单的golang buffer channel,FIFO队列。
当vmagent启动时,默认它会启动2倍CPU core的workers(goroutines,如果需要处理更多数据,可以通过-remoteWrite.queues增加workers数目)。每个worker有5s的时间从内存队列读取数据,如果无法及时读取所有的数据,则剩余的数据会被刷新到文件队列。可以使用-memory.allowedPercent (默认 60%) 或 -memory.allowedBytes调节内存中应该保存的数据块数目。默认计算方式如下:
go
maxInmemoryBlocks := allowed memory / number of remote storage / maxRowsPerBlock / 100
// clamp(value, min, max)
clamp(maxInmemoryBlocks, 2, queue * 100)记住,每个块包含10,000条样本(-remoteWrite.maxRowsPerBlock),并确保内存中至少有2个块,且每个队列不超过100个块。
总结一下,什么时候数据会被刷新到磁盘?
- worker超时:如果一个worker无法在5s之内读取所有的内存数据,则剩余数据会被刷新到磁盘
- 积压的磁盘队列:如果磁盘队列中仍然有等待刷新到远端存储的数据,则新的块会被直接刷新到磁盘
- 内存限制:如果达到内存队列上限,则新块会被立即刷新到磁盘
基于文件的队列
刷新到磁盘的数据会被保存到-remoteWrite.tmpDataPath指定的目录中(默认 /vmagent-remotewrite-data)。
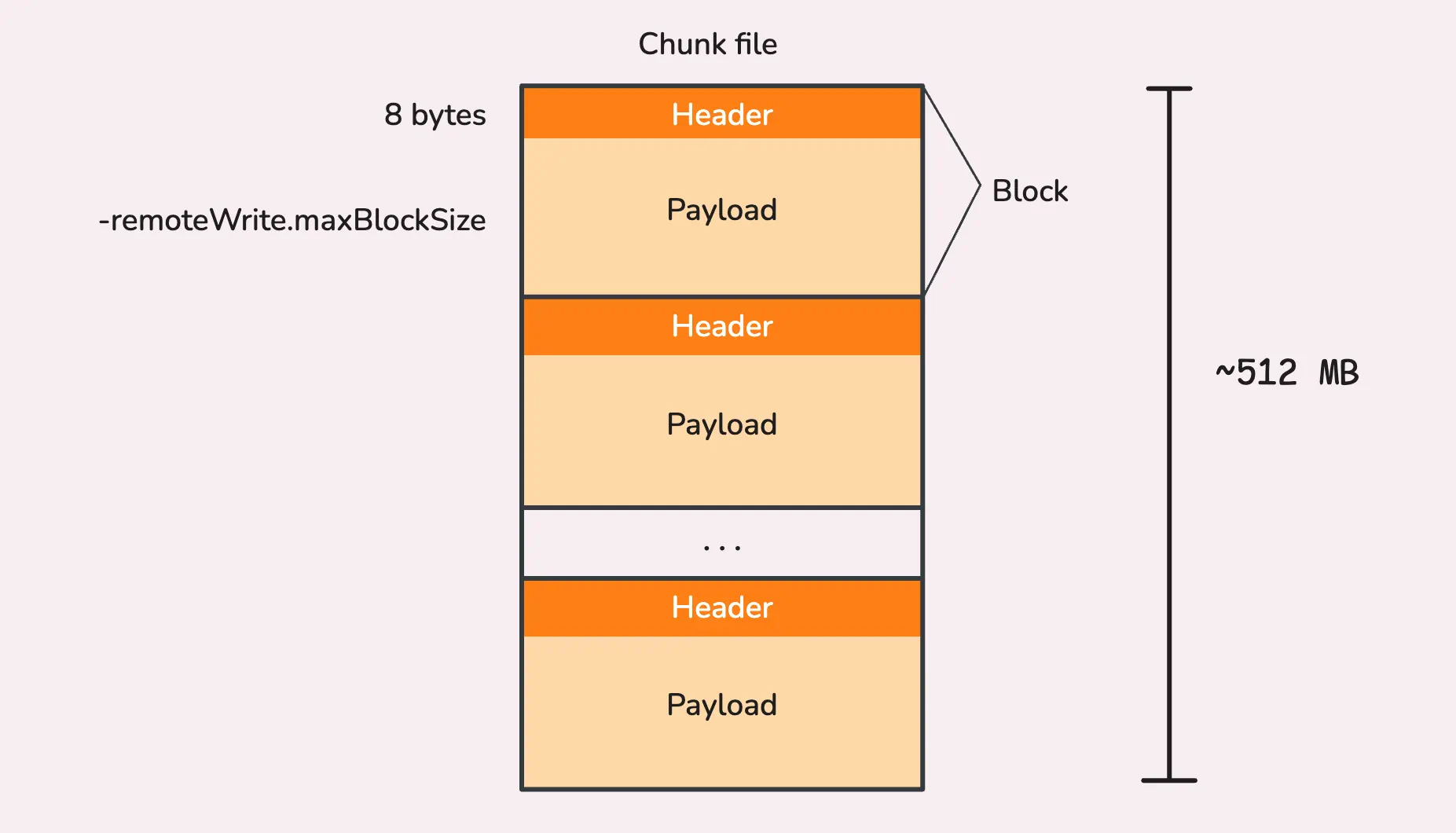
与内存队列相同,文件队列也有大小限制(-remoteWrite.maxDiskUsagePerURL,默认0,即无限制)。如果达到上限,则vmagent会通过丢弃老的块来确保数据不会溢出。刷新到磁盘的数据会被保存到chunks文件中,每个chunk大小为512MB,chunk中的block包含两部分:
- Header:8字节的首部,表示block的大小
- Payload:实际的时序数据
go
const MaxBlockSize = 32 * 1024 * 1024 // 32 MB,块压缩上限为32MB
const DefaultChunkFileSize = (MaxBlockSize + 8) * 16 // over 512 MBblock的上限约为32MB,加8字节的首部,因此每个chunk文件最多可以有16个blocks。
这些chunk文件保存在/vmagent-remotewrite-data/persistent-queue/<url_id>_<url_hash>/<byte_offset>目录中。
sh
/tmpData/persistent-queue
│
└── 1_B075D19130BC92D7
├── 0000000000000000 # 512 MB chunk file
├── 0000000002000000 # 512 MB chunk file
├── 0000000004000000 # 512 MB chunk file
├── 0000000006000000 # 512 MB chunk file
├── flock.lock
└── metainfo.jsonvmagent使用buffered writting方式写入chunk文件,buffer的大小取决于内存设定 (-memory.allowedPercent, 默认 60%, 或 -memory.allowedBytes),计算方式为:
go
// clamp(x, min, max)
bufferSize := clamp(allowed memory / 8 KB, 4 KB, 512 KB)即,如果内存为2GB,则buffer大小为250KB,适用于4KB~250KB范围。
这样去重器会按照去重间隔将数据刷新到流聚合器,然后流聚合器会周期性地将数据刷新到fast queue。
第七步:刷新到远端存储
在vmagent启动时,它会启动一些worker来从fast queue(内存以及文件队列)拉取数据块,然后处理并尝试将这些数据发往远端存储。每个远端存储都有其特定数目的workers,通常为2倍的CPU core (-remoteWrite.queues)。
每个worker会从队列拉取一个时序数据块,首先检查内存队列,如果为空,则检查文件队列,如果都为空,则等待新数据。
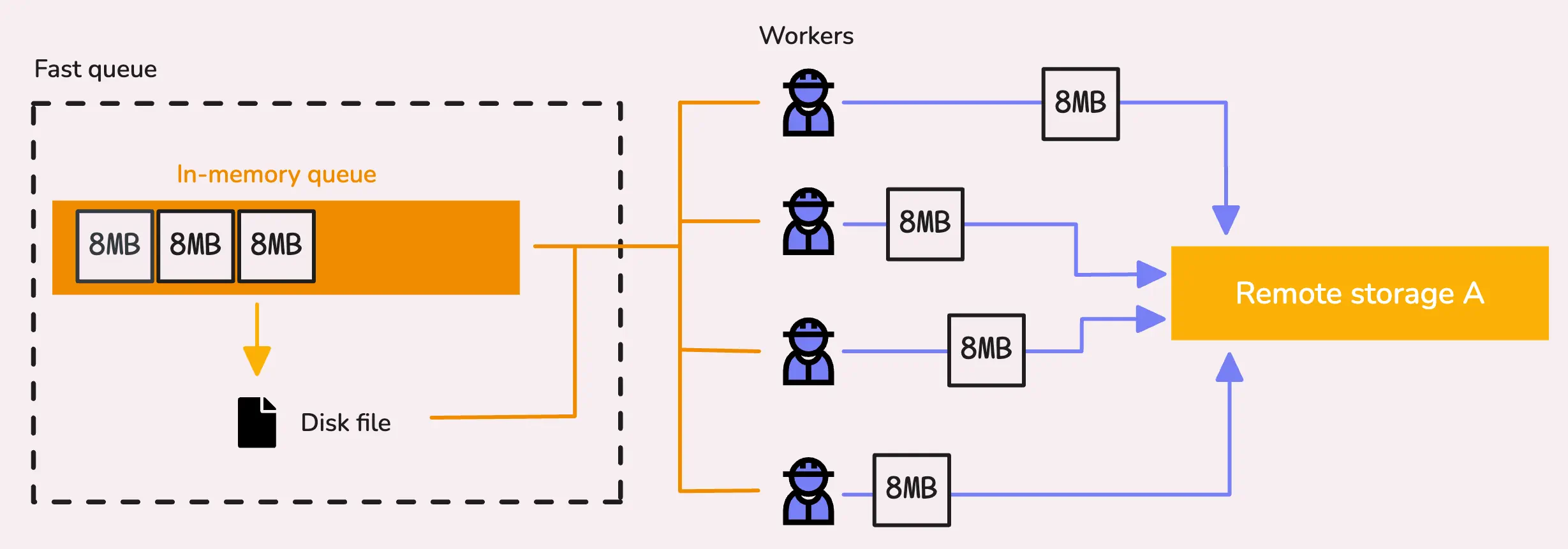
一旦获取到有效的块,worker会将它们发送到远端存储。如果vmagent需要停止(重启或重调度),则它会等待5s来结束请求发送。
vmagent使用限速器(-remoteWrite.rateLimit)来限制发送到远端存储的数据速率,默认无限制。