C#类型系统
C# 是一种强类型语言。 每个变量和常量都有一个类型,每个求值的表达式也是如此。 每个方法声明都为每个输入参数和返回值指定名称、类型和种类(值、引用或输出)。 .NET 类库定义了内置数值类型和表示各种构造的复杂类型。 其中包括文件系统、网络连接、对象的集合和数组以及日期。 典型的 C# 程序使用类库中的类型,以及对程序问题域的专属概念进行建模的用户定义类型。
简单来说就是指:类,参数,字段,属性,方法,模块,程序集等元素
眼见为实
//命名空间(模块)=>类型系统
namespace Example_4_1
{
//类属于类型系统
class UserLogin
{
//字段,属性=>类型系统
private string username;
private string password;
//构造方法=>类型系统
public UserLogin(string username, string password)
{
this.username = username;//参数=>类型系统
this.password = password;
}
//方法=>类型系统
public bool Login(string inputUsername, string inputPassword)
{
if (inputUsername == username && inputPassword == password)
{
return true;
}
else
{
return false;
}
}
}
}编译器使用类型信息来确保在代码中执行的所有操作都是类型安全的,比如
int a = 5;
int b = a + 2; //OK
bool test = true;
// Error. Operator '+' cannot be applied to operands of type 'int' and 'bool'.
int c = a + test;IL类型系统
编译器将类型信息作为元数据(metadata)嵌入到程序中。所以C#的类型系统,在IL层面叫"metadata"
眼见为实
CLR类型系统
CLR在运行时使用metadata来进一步保证类型安全,避免出现类型转换错误。
眼见为实
使用windbg来一探究竟
-
AppDomain
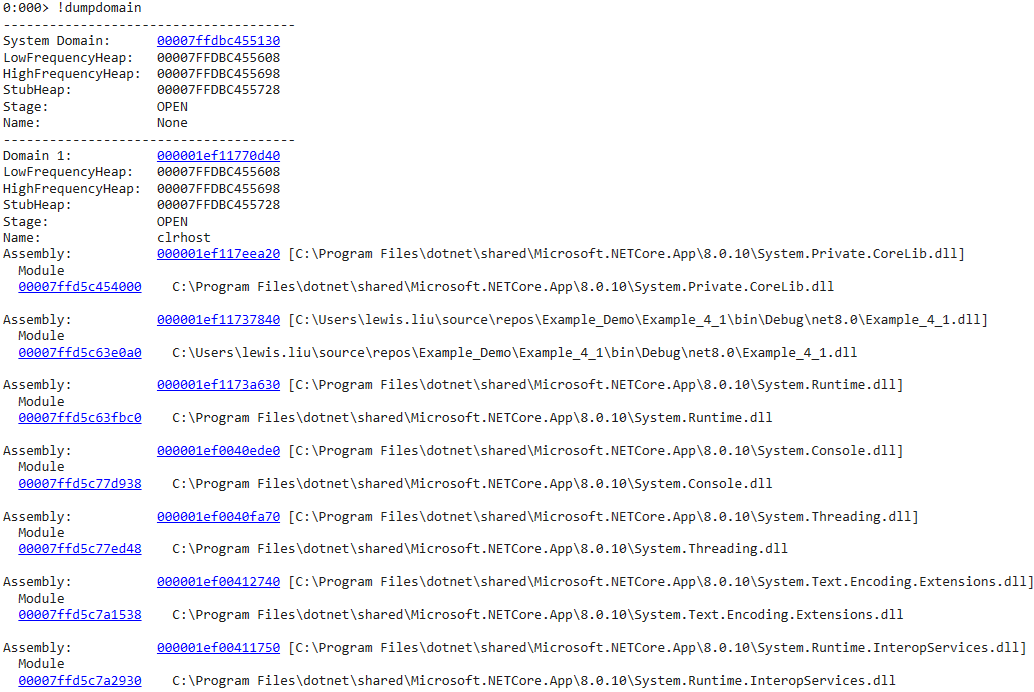
在.net core中 出于跨平台需要,相对.net framework只剩下了两个,System Domain与Domain 1
-
Assembly

-
Module
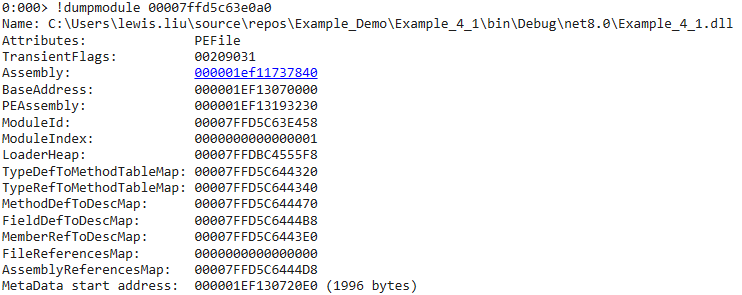
-
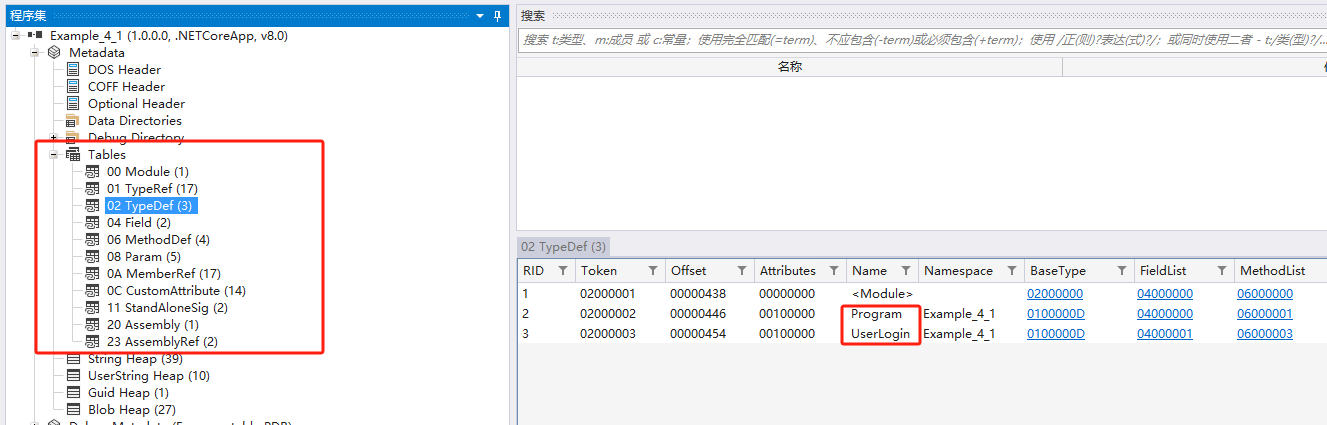
Class
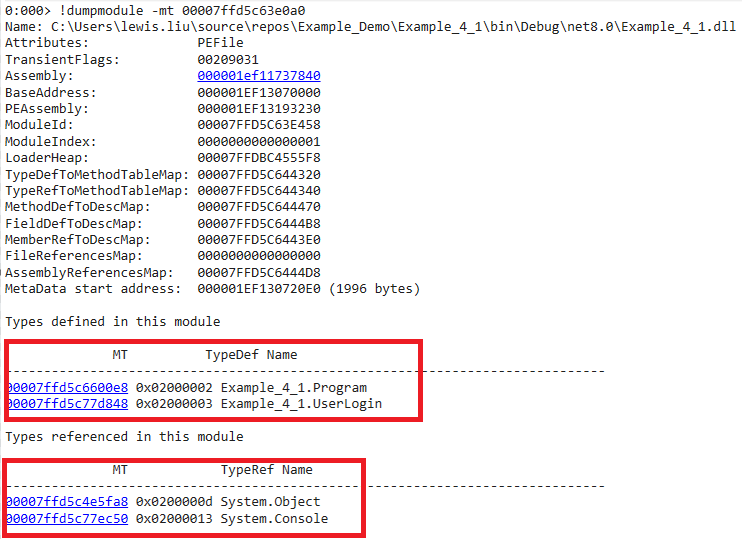
我们可以用二级命令来显示,模块中定义的类型(class),以及模块引用的类型。
-
Method
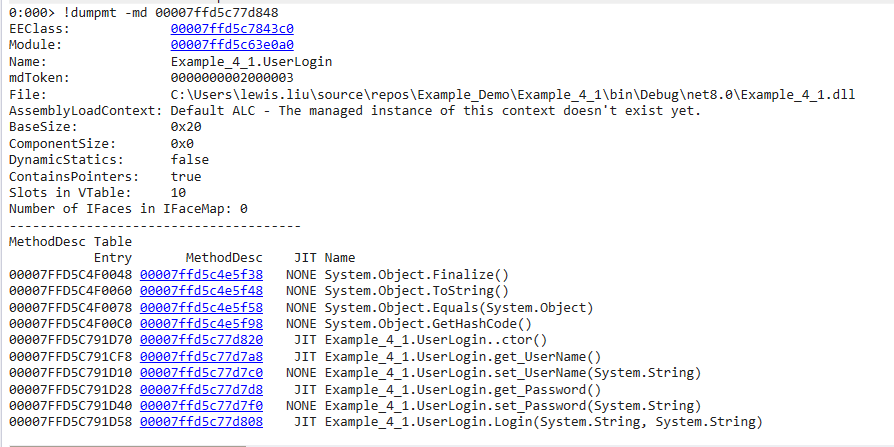
同时也显示了父类objcet的方法
-
Field
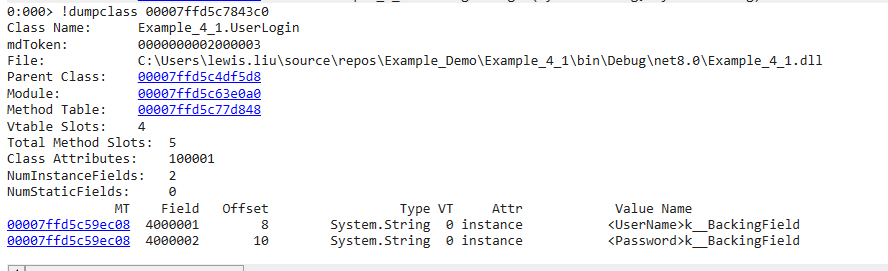
dump方法表中的EEClass,得出类的字段
CLR类型系统与C++类型系统的映射
网络上有一种说法,C#中的这个#,实际上是++++。相当于C++的超集C++++。那么为什么这么说呢?从CLR的角度出发,CLR中所有类型,在C++都有一一对应。
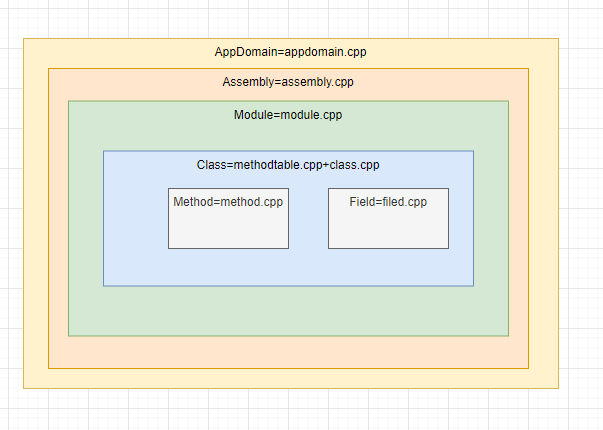
https://github.com/dotnet/runtime/blob/main/src/coreclr/vm/appdomain.cpp
https://github.com/dotnet/runtime/blob/main/src/coreclr/vm/class.cpp
https://github.com/dotnet/runtime/blob/main/src/coreclr/vm/field.cpp
值类型与引用类型
在面试八股文中,有一个经常出现的问题:值类型与引用类型的区别?
而这个问题,一个高频次的答案就是:Class是引用类型,struct是值类型。值类型分配在栈用,引用类型分配在堆中。
这个说法说并不准确,为什么呢?因为它是从实现的角度对两个概念进行描述,相当于先射箭再画靶。而不是基于两种类型内在的真正差别
ECMA335对两种类型真正的定义
值类型:这种类型的实例直接包含其所有数据。值类型的值是自包含,自解释的
引用类型:这种类型的实例包含对其数据的引用。引用类型所描述的值是指示其他值的位置
| 值类型 | 引用类型 | |
|---|---|---|
| 生存期 | 包含其所有数据,自包含,自解释。值类型包含的数据生存期与实例本身一样长 | 描述了其他值的位置,其他值的生存期并不取决于引用类型值本身 |
| 共享性 | 不可共享,如果我们想在其他地方使用它。默认使用"传值"语义,按字节复制一份,原始值不受影响。 | 可被共享,如果我们想在如果我们想在其他地方使用它。默认使用"传引用"语义。因此在传递之后,会多出一个指向同一个位置的引用类型实例。 |
| 相等性 | 仅当它们的值的二进制序列一样时才认为相同 | 当它们所指示的位置一样就认为相同 |
从定义中可以看出,没有地方说明,谁存储在栈中,谁存储在堆中。
实际上,值类型分配在栈上,引用类型分配在堆上。只是微软在设计CLI标准时根据实际情况所作出的一个设计决策。
由于它确实是一个非常好的决策,因此微软在实现不同的CLI时,沿用了这个决策。但请记住,这并不是银弹,不同的硬件平台有不同的设计
事实上类型的存储实现,主要通过JIT编译的设计来体现。JIT编译器在x86/x64的硬件平台上,由于有栈,堆,寄存器存在。JIT可以随意使用,只要它愿意,它可以把值类型分配在堆中,分配在寄存器中都是可以的。只要不违反类型的定义,又有何不可呢?
值类型内存布局
如果仅从定义出发,将所有值类型保存在堆上是完全可行的,只是使用栈或者CPU寄存器实在太香了而已。
因此主要考虑生存期与共享这两个因素,放在栈空间中更加合适。
眼见为实
internal class Program
{
static void Main(string[] args)
{
var myStruct = new MyStruct();
myStruct.x = 100;
myStruct.y = 102;
}
}
struct MyStruct
{
public int x;
public int y;
}
可以看到,值类型的内存布局没有任何额外开销,直接在线程栈中完成分配,并随线程栈释放。完美契合符合生存期/共享性的概念。
引用类型的内存布局
由于引用类型可以共享数据,因此它们的生存期并不确定。所以考虑引用类型存储到哪里要比值类型要简单得多。
通常来说,引用类型存储在栈上不符合定义 ,此时哪里能存储引用类型就很明显了。

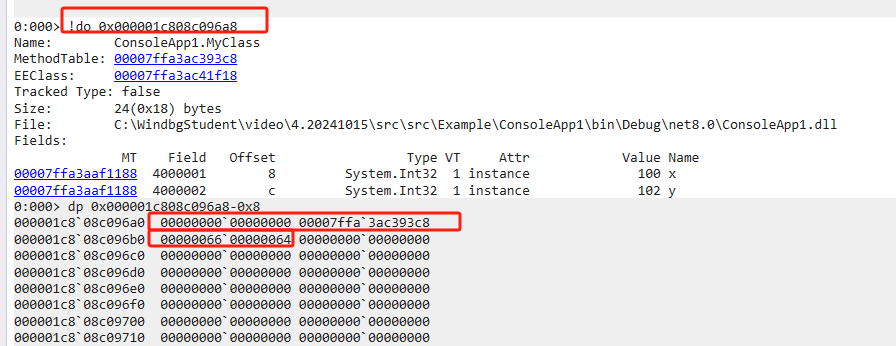
眼见为实
internal class Program
{
static void Main(string[] args)
{
var myClass = new MyClass();
myClass.x = 100;
myClass.y = 102;
Debugger.Break();
}
}
class MyClass
{
public int x;
public int y;
}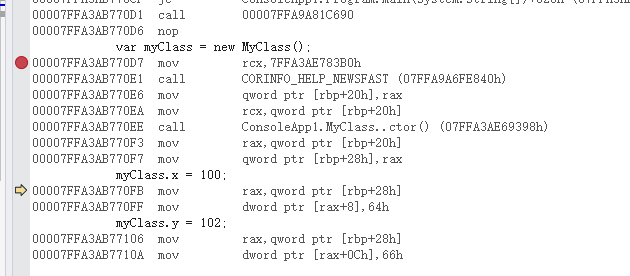
与值类型的汇编相比较,可以很明显的看出差异。
- 值类型的汇编,直接把100和102赋值给了rbp寄存器的偏移量上,从而实现跟随栈空间一起释放
- 引用类型的汇编,则是先在托管堆中创建一个内存空间,再将内存地址赋值给rax寄存器,再基于内存地址的偏移量进行赋值操作。不会随着栈空间一起释放
眼见为实
使用windbg也可以验证,MyClass对象分配在托管堆中,并结构为objHeader + methodtable + 对象本身
值类型一定存储在栈空间中吗?
值类型除了可以存储在"栈"上,也可以在"寄存器","托管堆"中
眼见为实:值类型在寄存器中
internal class ExampleStruct
{
public int Main(int i)
{
var myStruct = new MyStruct();
myStruct.vaule1 = i;
return Helper(myStruct);
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]//告诉编译器,让方法尽量内联
private int Helper(MyStruct arg)
{
return arg.vaule1;
}
}
struct MyStruct
{
public int vaule1;
public int vaule2;
public int vaule3;
public int vaule4;
}在64位release模式下,因为Helper方法被内联。所以并不会调用Helper方法,因此省略了传递Struct数据给Help方法,JIT编译器将整个操作优化成只需要对CPU寄存器进行操作。
可能是环境问题,我的release版本始终没有内联,导致无法在windbg中复现。有兴趣的小伙伴可以参考<.NET内存管理宝典> 168页内容。
眼见为实:值类型在托管堆中
internal class ExampleStruct2
{
public void Main()
{
var myStruct = new MyStruct2
{
vaule1 = 100,
vaule2 = 102
};
//因为委托是引用类型,引用类型内部引用一个值类型,也会把值类型提升至托管堆
var f = () =>
{
Console.WriteLine(t.vaule1);
Console.WriteLine(t.vaule2);
};
f();
Debugger.Break();
}
}
struct MyStruct2
{
public int vaule1;
public int vaule2;
public int vaule3;
public int vaule4;
}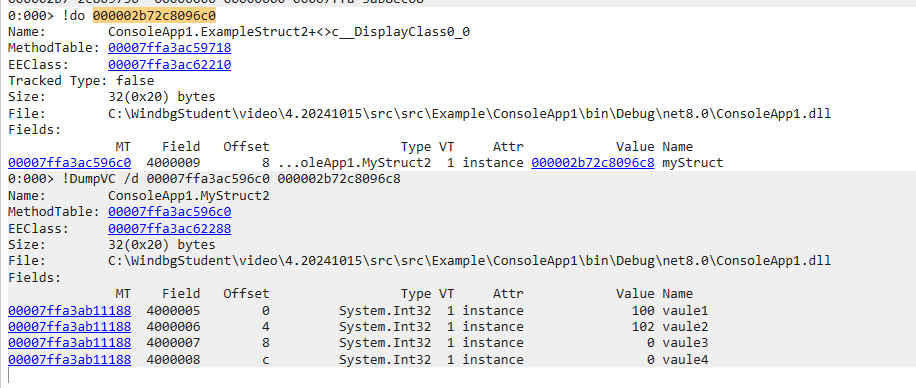
可以看到,当值类型被引用类型所持有时,同样会分配在堆空间中。
引用类型一定存储在堆空间中吗?
在.NET9 之前,这句话是成立的,因为栈空间不符合引用类型的定义。
但在.NET9之后,这个概念发生了改变。我们先来思考一段代码
public class ExampleClass
{
public void Main()
{
var myClass = new MyClass()
{
vaule1 = 100,
vaule2 = 102
};
Console.WriteLine(myClass.vaule1);
Console.WriteLine(myClass.vaule2);
}
}
public class MyClass
{
public int vaule1;
public int vaule2;
public int vaule3;
public int vaule4;
}虽然MyClass是一个引用类型,但在方法中,myClass实际上随着Main方法的执行完成而不再使用。因此把myClass放在堆空间中,会造成GC的负担以及内存浪费。能不能让JIT更智能一点?如果引用类型的生命周期与线程栈类似,是否可以放在栈空间中呢?
答案是肯定的,而且在JAVA中已经运用很多年了,这就是大名鼎鼎的逃逸分析(escape analysis)
.NET9 的逃逸分析(escape analysis)
.NET9 刚刚启用此特性,因此范围比较有限。不过在未来,相信会进一步扩大范围,实现更高性能的内存分配。
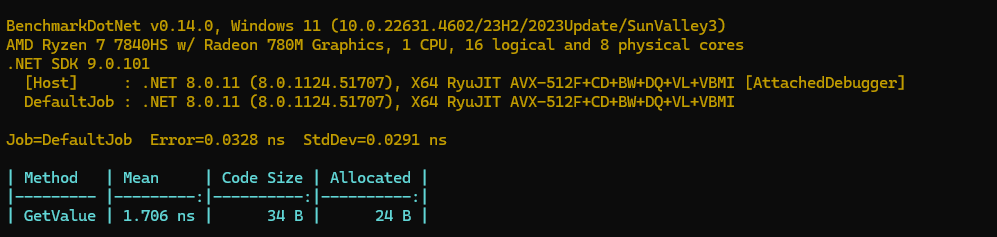
.NET 9内存分配:
.NET 8内存分配:
再引用一个官方的例子
https://devblogs.microsoft.com/dotnet/performance-improvements-in-net-9/#object-stack-allocation
// dotnet run -c Release -f net8.0 --filter "*" --runtimes net8.0 net9.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[MemoryDiagnoser(false)]
[DisassemblyDiagnoser]
[HideColumns("Job", "Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
[Benchmark]
public int GetValue() => new MyObj(42).Value;
private class MyObj
{
public MyObj(int value) => Value = value;
public int Value { get; }
}
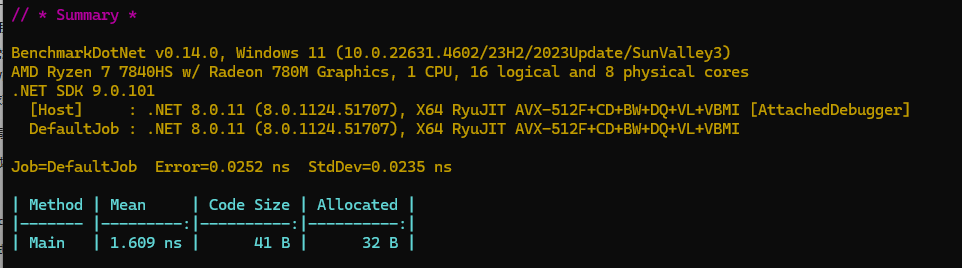
}在.net 8 中的汇编如下:
; Tests.GetValue()
push rax
mov rdi,offset MT_Tests+MyObj
call CORINFO_HELP_NEWSFAST
mov dword ptr [rax+8],2A
mov eax,[rax+8]
add rsp,8
ret
; Total bytes of code 31在.net 8中内存分配如下
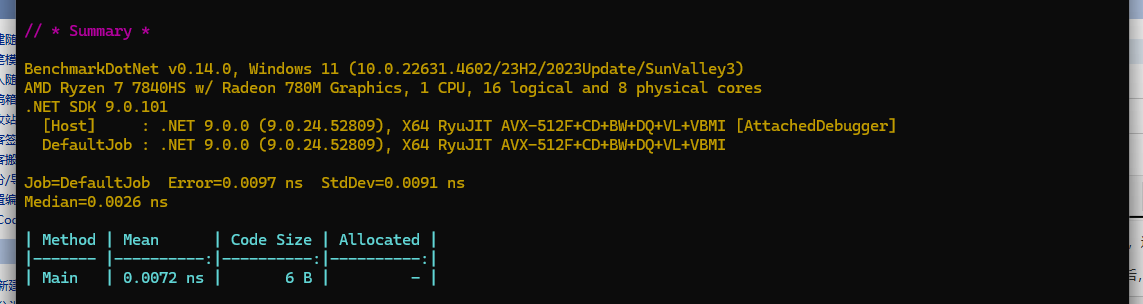
在.net 9中的汇编如下
; Tests.GetValue()
mov eax,2A
ret
; Total bytes of code 6在.net 9中内存分配如下
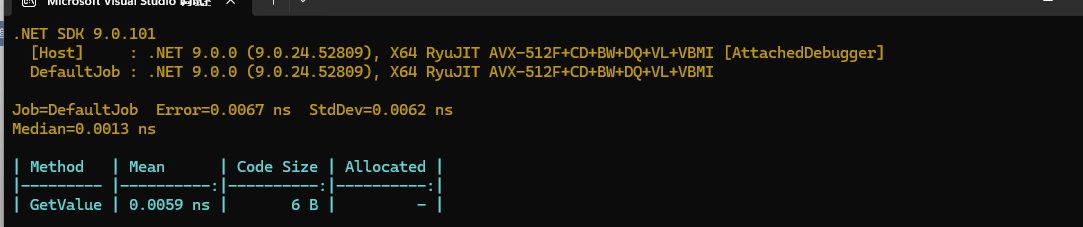
可以看到,.NET9通过方法内联,直接将new MyObj(42).Value提升为 return 42 . 不会在堆中创建MyObj对象,而是直接在栈空间赋值。
总结
以上例子可以看到,值类型与引用类型其内核就是生命周期是否可控,是否被其他线程共享?无论什么类型,只要它生存期大于线程栈或者被其他线程所共享访问。那么它就会被分配在堆上。反之,则分配在栈或者寄存器上。
更简单来说, JIT如果不知道对象什么时候被释放,那么它一定会分配到堆空间中。如果知道什么时候被释放,那么它会尽量分配到栈空间中,甚至寄存器中。