拼写纠正系列
java 实现中英文拼写检查和错误纠正?可我只会写 CRUD 啊!
单词拼写纠正-03-leetcode edit-distance 72.力扣编辑距离
NLP 开源项目
前言
大家好,我是老马。
下面学习整理一些其他优秀小伙伴的设计、论文和开源实现。
感受
这一篇和我的理念很类似,其实就是汉字的三个部分:音 形 义
字典是学习一个字符如何发音、书写和使用的参考书籍
其实本质上还是类似的。
TODO: 不过目前义(使用)这个部分我做的还比较弱,考虑添加一个关于单个字/词的解释词库。
论文+实现
论文地址: https://arxiv.org/pdf/2406.16536v2
源码地址:https://github.com/ktlktl/c-llm
摘要
中文拼写检查(CSC)旨在检测和纠正句子中的拼写错误。尽管大语言模型(LLMs)展现了强大的能力,并广泛应用于各种任务,但它们在CSC任务上的表现常常不尽如人意。我们发现,LLMs未能满足CSC任务的中文字符级约束,即字符数一致性和语音相似性,这导致了性能瓶颈。进一步分析表明,这个问题源于分词粒度的设置,因为当前的混合字符-词分词方式难以满足这些字符级约束。为了解决这个问题,我们提出了C-LLM,一种基于大语言模型的中文拼写检查方法,能够逐字符学习检查错误。字符级分词使得模型能够学习字符级对齐,有效缓解与字符级约束相关的问题。此外,CSC任务被简化为主要涉及复制和替换的任务。在两个CSC基准数据集上的实验表明,C-LLM比现有方法平均提高了10%的性能。具体来说,它在通用场景下提升了2.1%,在垂直领域场景下有显著的12%的提升,取得了当前的最佳表现。
源代码可以访问 https://github.com/ktlKTL/C-LLM。
1 引言
中文拼写检查(CSC)涉及检测和纠正中文句子中的错误字符,在各类应用中起着重要作用(Gao et al., 2010; Yu and Li, 2014)。尽管大语言模型(LLMs)展现了强大的能力,并日益应用于各种任务(Wang et al., 2023; He and Garner, 2023; Wu et al., 2023a),以往的研究(Li and Shi, 2021)表明,生成模型如LLMs在CSC任务中的表现并不理想。
CSC任务本质上涉及字符级的长度和语音约束。字符级长度约束要求预测句子的字符数与源句子一致。此外,语音约束要求预测字符在语音上与源字符高度相似,因为大约83%的拼写错误与正确字符在语音上相同或相似(Liu et al., 2010)。我们发现,LLMs往往未能满足这些字符级长度和语音相似性的要求,导致CSC任务的表现瓶颈。
以GPT-4为例(Achiam et al., 2023),我们观察到,在少样本提示下,模型生成的句子中有10%没有与源句子匹配字符数。相比之下,BERT风格的模型完全没有这个问题。此外,35%的预测字符与源字符在语音上不相似,且由于非同音字的预测错误约占70%的错误。这些字符长度和语音相似性的问题导致了生成的输出未能满足任务需求,从而导致纠错性能不佳。
我们发现,根本问题在于LLM的分词粒度。当前的混合字符-词分词方式会导致字符到词的映射,这使得LLM难以学习字符级的对齐,通常会生成不符合字符级约束的预测。如图1所示,在混合字符-词分词的情况下,LLM需要推断出多个标记对应单一字符(例如,"胆(bold)","大(large)","的(of)"->"大 量的(large amount))"),并推断出隐式的字符对齐(例如,"胆(bold)"->"大(large)")。这些推理过程使得CSC任务变得复杂,因为大多数CSC案例涉及简单的字符复制。例如,正确的字符"量(amount)"是直接从源句子复制过来的。
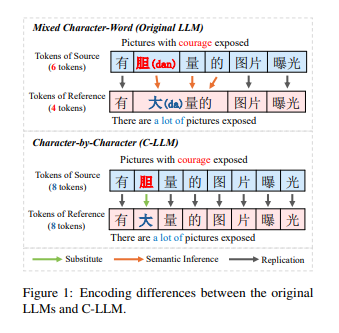
尽管LLM在各种任务中取得了语义理解的进展,但不清晰的字符对齐仍然会导致错误和过度纠正。因此,建立明确的字符级对齐至关重要。基于这一概念,我们提出了C-LLM,一种基于大语言模型的中文拼写检查方法,它逐字符学习检查错误。我们的动机是进行字符级编码,并建立字符级对齐来训练句子对,从而缓解字符级约束相关问题。如图1所示,该方法确保句子对的标记数保持一致,从而使得LLM更容易学习中文字符之间的语音映射。此外,CSC任务被简化为复制正确字符和替换错误字符的任务,而不涉及复杂的推理。
具体来说,我们构建了字符级分词,确保标记根据单个中文字符进行编码。为了适应新的词汇,我们在大型数据集上进行继续训练。此外,为了使LLM能够学习CSC任务,我们对CSC数据集进行监督微调。在通用数据集CSCD-NS(Hu et al., 2022)和多领域数据集LEMON(Wu et al., 2023b)上的实验表明,C-LLM在通用和垂直领域场景中均超越了现有方法,达到了当前的最佳表现。
本文的贡献可以总结为三个方面:
(1)我们发现混合字符-词分词妨碍了LLM有效理解CSC中的字符级约束。
(2)我们提出了C-LLM,该方法逐字符学习并能够检查错误。
(3)通过在通用和多领域数据集上的测试,我们发现C-LLM取得了当前最佳表现,为未来的错误纠正模型设计提供了见解。
2 相关工作
BERT风格的CSC模型
随着预训练语言模型的兴起,中文拼写检查(CSC)的主流方法转向了BERT风格的模型(Devlin et al., 2019),这些模型将CSC视为序列标注任务。
这些模型将句子中的每个字符映射到其正确的对应字符,并在源句子和参考句子的对上进行微调。
此外,一些研究还集成了语音学和形态学知识,以提高标注过程的效果(Cheng et al., 2020; Guo et al., 2021; Huang et al., 2021; Zhang et al., 2021)。然而,由于参数限制,这些模型在低频和复杂语义场景中的表现不如大语言模型(LLMs)。
自回归CSC模型
与BERT风格的模型可以并行推断每个标记不同,自回归CSC模型是按顺序处理标记的。
以往的研究(Li and Shi, 2021)表明,自回归模型如GPT-2(Radford et al., 2019)在CSC任务上可能表现不佳。
随着LLMs的进步,已有若干研究探讨了它们在文本修正方面的能力。
研究(Li et al., 2023b)发现,尽管ChatGPT知道中文字符的语音,但它无法理解如何发音,这使得语音错误修正变得困难。
其他研究(Fang et al., 2023; Wu et al., 2023a)指出,ChatGPT往往能够生成流畅的修正,但也会引入更多的过度修正。
这些发现与我们的观察一致,强调了提升LLMs在CSC任务中的表现的必要性。
结论
本文表明,现有的大型语言模型(LLMs)未能满足中文拼写纠错任务(CSC)的字符级约束条件,具体表现为字符长度一致性和语音相似性,这严重影响了它们的纠错性能。
我们发现,这一问题的根本原因在于标记化粒度的设置,当前模型将字符和词语混合处理,难以有效满足字符级约束。
为了解决这一问题,我们提出了 C-LLM,该模型建立了中文字符之间的映射关系,使模型能够学习字符之间的纠错关系和语音相似性。
通过这种方法,CSC 任务被简化为字符复制和替换问题。
实验结果表明,C-LLM 在通用基准和多领域基准上都优于以往的方法,并且达到了最先进的性能。