浅说c/c++ coroutine

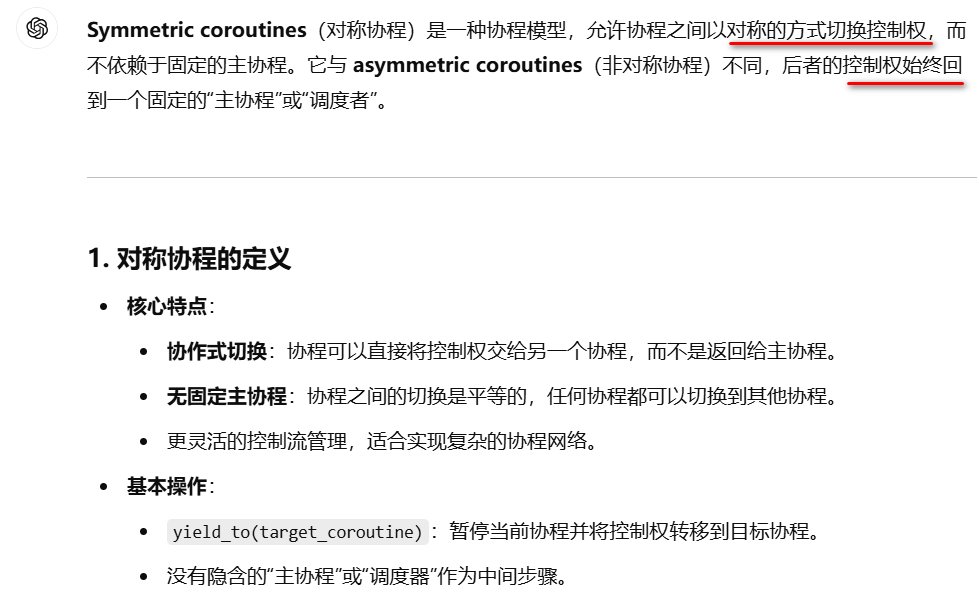
从上面我们可以得到关于协程的几个关键信息,
1.打破传统(regular)函数调用的限制。
2.stackful协程实现方式,基于独立栈,上下文切换。
3.stackless协程实现方式,状态机,闭包。
4.控制权切换的对称性。层级关系的切换为非对称。如caller跟callee
先来看传统(regular)函数调用,应该是专指我们的c/c++编译器的函数调用约定。call指令进入callee跟return指令返回caller。这到底限制了什么,它限制了必须从函数入口进入,函数结束必须回到调用处。那么打破就是算我不按这一套来做。我要从函数中间某一处进入,又从函数内某处跳到另一个函数内某处。这就是在玩脱了,放飞自我地跳转。
这么来看,协程就是一种代码跳转的技术。代码跳转,无非就是改变指令寄存器,可以修改eip的指令(在x86系处理器)只有三个,call, jmp(其它条件指令算在这里), ret。
如何安全地跳转,linux内核为我们提供了临床例子,系统调用(中断服务)。要知道我们的系统调用,并非函数调用,而是处理器的中断门进行的代码跳转。中断门将当前处理器的esp, eflags,eip入栈,用户态切换系统态,eip直接修改成中断服务程序入口,完成代码的跳转。在中断服务程序入口再入栈所有其它寄存器完成现场保护。
然后在系统调用或中断结束时,iret指令完成esp, eflags, eip出栈,并降权回到用户空间的代码。
这里就有三件事可以被协程实现借鉴,切换堆栈,切换执行地址,保护现场。
stackful协程的实现都离不开这三步。
stackful协程的代表就有win32的Fiber。c库有tencent/libco,higan-emu/libco。它们是两个不同的项目但名字一样。它们的跳转实现分别是SwitchToFiber,co_swap(coctx_swap), co_switch。
我没有windows的源代码,就用ida逆向。

ms跟tencent都使用ret修改ip寄存器,higan-emu使用jmp。ms跟higan-emu都只保护了esp,ebp,ebx,edi,esi五个寄存器。因为eax, edx, ecx都是非失寄存器,不用保护。只有tencent还去做了它们的工作。
那么跳转的地址是哪里呢,ms跟higan-emu是跳转到协程调用SwitchToFiber/co_switch函数的返回地址。而tencent的coctx_swap外还有一层co_swap,它会在co_swap内做一些事,回到协程调用co_swap的返回地址。
对于stackful协程必须要十分小心,绝对不能让协程像传统函数那样结束。这样会让一个线程在你的协程esp+eip中结束。你要退出你的协程一定要切换回常规代码,也就让esp+eip回到线程的常规代码。线程才能安全。tencent/libco的example例子,coroutine函数都是在结尾return 0; 汗。它们的coroutine都是在一个死循环while里面co_resume。不会从这个while出来,所以好像就没事,却让人容易忽略这个风险。
msFiber跟higan-emu都只提供对称协程。msFiber跟它的线程teb是有某些关联的,它会在SwitchToFiber中设置许多TEB的项。
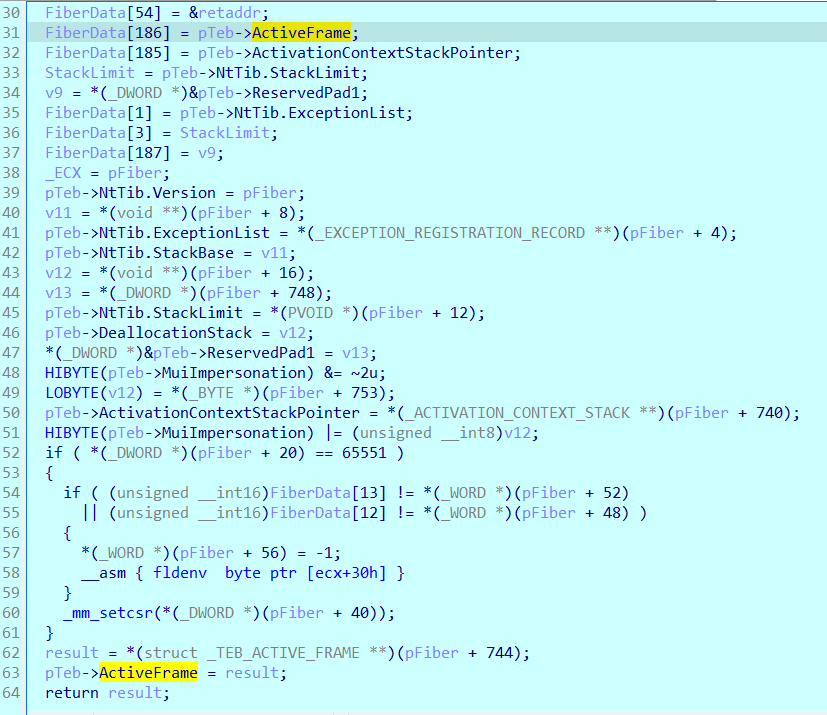
所以让Fiber在其它线程切换是有一定风险的。
下面会说tencent/libco,就它们的代码对生命周期的管理,我十分怀疑它们真的在NNN万台服务用这样的代码在做支撑。
co_release释放协程,它给的所有example统统不去调用,这是一位有大厂资历的大卡的编程习惯吗。每个线程有一个主协程环境,居然有co_init_curr_thread_env初始化环境的函数,却没有uninit的函数安全退出线程释放环境。理加扯的是,Epoll设备有两函数AllocEpoll跟FreeEpoll。查找它的代码,只有调用了AllocEpoll,却没有一处调用FreeEpoll。这是什么奇迹代码。这个Epoll是事件循环框架内部管理的,却没有一处调用FreeEpoll。从头到尾,它们的代码都没有对安全退出做任何处理,以及能确保安全退出的相关问题,还有如何通知事件循环并使其正确退出所有协程。更加离谱的是,coctx这个上下文切换器也是没有uninit()函数的。这份代码8.4k星2.1k的fork,放出9年,居然没有一个人发现这是个问题,还是说没有人以为这是一个问题(,如果作为一个应试者你漏写个释放都会被质疑)。这些人真有在用这份代码吗?
回到本篇https://www.cnblogs.com/bbqzsl/p/18639898。
这份代码是核心思想,就是用协程加上一个事件循环框架,并用它所谓的hook系统调用接口,主要是同步阻塞的read,使得阻塞的read以协程挂起结合事件循环异步回调的方式模拟。这样就可以不懂异步的同步阻塞代码,获得异步编程的性能。它吹嘘的百倍性能,不知道作为对比的样本是什么。如果你是精通异步编程的,我想不会去尝试这迷惑的吹嘘。
co_eventloop作为主协程coroutine,同时扮演调度的角色。协程通过事件循环的事件响应以及计时器,以回调的方式调度。其实跟我们写异步事件回调的事件循环一样。它的协程就只是我们回调事件的handler对应的连接对象,这样一来,说到底就只是一个异步回调的事件循环的框架的一种加入协程的实现。协程协程切换比函数回调还有更多的开销,而且事件循环的io事件复路分离器的技术细节还不能被掌控。框架就是只能按它的来。再来对比一下,它的协程绝对不是什么轻量级,先不说那个协程的私有堆栈,它的协程对象本身就有一个1024的本地存储,类比TLS,(然而win32线程才预留256个位),它就已经占用4K一个页面。你的连接对象同样可以用来作为事件循环的回调handler,你会分配一个页面而且是几乎没有的。鹅厂资源多到溢出。连代码都能够这么的洗脚不用抹嘴的,它们的WeUIEngine也是一样,一个CControlUI是2816字节的大基类,我在《逆向WeChat (二)》分析过。
对于这个read的协程版分支代码路径,是调用co_poll先挂起协程,让co_eventloop再调度回调后才读。如果read是有可读的,同样要挂起一次才能读数据。
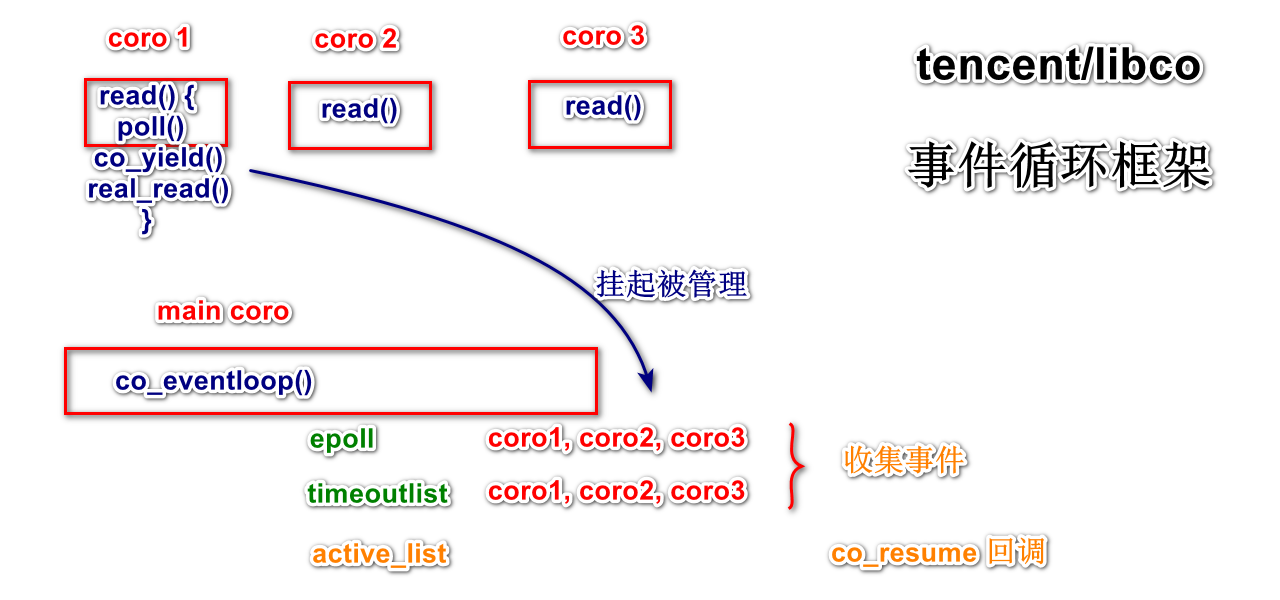

tencent则是实现成非对称协程,它使用了一个pCallStack128来支持128层的非对称协程调用。目的让对称协程有类似co_return跟co_await的能力。它让co_resume类似co_await,co_yield类似co_return。这样它co_resume就将自身coro作为一帧CallStack并push。co_yield则从pCallStack中pop一帧进行切换。这样就可以让你的coro使用co_resume好像在调用其它coro,并在其co_yiled时返回当前的coro。tencent它用了一个co_CoroutineFunc函数对coro函数进行保护,当coro函数在return返回时,会返回到co_CoroutineFunc,co_CoroutineFunc的结尾处co_yiled,确保这个coro函数的执行流最后是在co_yiled。
tencent/libco的coro生命周期管理有点怪。它的所有example代码连一个co_release都没有。可见它们不重视coro的生命周期管理。从它们的example代码可见,它们习惯将coro当作对象,一次预分配定额数量的coro放在一个全部对象池。如example_echosvr.cpp的例子,每个连接从池中取出一个coro,绑定fd后上线,连接断开后coro下线放回池中。我想这些coro也是在程序结束时清理池的时候清理coro。但是它说自己是一个coro库,普通使用者希望coro会随执行流结束自行清理。既然有一个co_CoroutineFunc函数对coro函数做了结束保护,为什么不在co_CoroutineFunc函数对coro的生命周期添加两个事件hook,init_coro跟finalize_coro。标准库就是这么设计的。另外它对coro当作一个对象,让外部绑定一个新的fd。明显coro就需要一个data成员,让外部重新绑定数据或者拿数据。
另外就是tencent/libco的co_eventloop。它是一个简化后libevent事件循环跟协程的结合体。它跟libevent的事件循环一样,用复路IO分离器epoll/kevent等待事件,用一个active队列收集事件分派handler,用一个timeoutlist实现轮盘计时器。只是这些事件handler换成了协程。
一个线程提供一个coro环境,这个环境包括一个复路IO分离器epoll/kevent。这跟libevent一样,一个线程只运行一个事件循环。tencent将所有io读写api作了一层包装。它称之为,co_hook_sys_call,一看名字就会被它吓住。其实就是包装一下,让读写操作注册到复路IO分离器,并入事件循环。以read为例,当read返回Blocking错误时,就会先poll一次。这里的poll也是被包装过的。分三步,1.当前coro执行流先注册这个fd到复路IO分离器,2.然后co_yield切换上一层coro,即挂起刚刚read的coro而回到co_eventloop执行流分派其它事件跟阻塞等待事件,3.有事件后切换回这个coro的poll函数挂起点,清理epoll的订阅,返回读数据。这个coro作为这个事件的handler。在co_eventloop就像循环poll阻塞1ms,等待io事件,等待轮盘计时器事件。co_eventloop在有事件的时候就收集事件在active队列,然后根据事件的fd去co_resume对应的coro(作为handler)。这些coro又会co_yield挂起回到co_eventloop。因此co_eventloop是一个顶端的主协程。
它将io操作,依赖co_poll_inner跟co_eventloop。它使得每次阻塞的异步io,都要用epoll_ctl订阅跟取消订阅。这里就多了两次系统调用。因为它不是一直订阅POLLIN,所以它不能很EPOLLET,会漏事件。两次系统调用,对于一个号称在NNN万台服务器上运行的网络库,支撑NNN亿的IO吞吐。像这样的巨人大厂说不重要,我也是惊了个呆。先说一下利用EPOLLET比EPOLLLT高效的原理。epoll比poll高效,是因为epoll有一个ready_list收集了事件。但是这个ready_list设计上有个问题,只有epoll_wait跟断开fd跟epoll时才会从这个ready_list上删除事件。在这样的前提下,LT不会在epoll_wait取事件的同时删除链项,就会在你下次epoll_wait时或epoll_ctl取消订阅时。例如尽管读完缓冲数据了,但是它的事件因为EPOLLLT策略仍旧留在ready_list,当下次epoll_wait时,才会对这个事件的fd进行一次状态查询,在确定没事件后才会删除。只有这么一点点不同,都可以让EPOLLET成为比EPOLLLT更加高效。那么两次系统调用是不是就有点意思了。当年的至强5也才只有3G双核四线程,今天的硬件都性能爆棚,两次系统调用不是事,但是这个库是在2013年开源的,也是奇了怪。关于epoll的详细,我以前写过《epoll的ET和LT模式比较 - 源码分析》代码https://github.com/torvalds/linux/blob/master/fs/eventpoll.c。记得那时候有些公司的文章,说是对性能榨取的程度达到了,就连时间函数都要改内核代码的地步。
扯远了,回到本篇。借助这个co_eventloop,它还提供一个同步变量co_cond。当co_cond_timedwait,会co_yield挂起回到上一层coro。co_cond_signal,就会将排队的coro收集到active队列分派。
另外它给了一个co_closure线程池例子,看一下就好了,没协程在线池程的调度的例子。这个co_closure也就是一个runnable。一个lambda的前身实现,模仿capture行为。跟chrome::base的OnceClosure是一样的东西,就一个lambda的代替。线程池example代码就只是开几条线程从一个互斥队列取workitem分派runnable,跟协程没半点关系。它给一线池的example让人错觉,它的协程支持线程池,准确来说协程是否线程安全,包括能不能够在其它线程上释放。更清楚地说,我说的支持是指像cppcoro那样可以在线程池中安全调度。如果它们真的有在支持的话,那么这个开源项目只是它们用来作为demo展示厨,没有拿出真东西。毕竟将coro迁移到其它线程上,平衡cpu负载还是需要的。
为了写本篇,对比代码,我又翻阅了一下久违的libevent,发现了一个wepoll的选项。原来windows下还可以用AFD设备+IOCP来实现epoll。libevent已经在2.2版新添加进去。
wepoll的github在https://github.com/piscisaureus/wepoll。如何实现的技术文章https://lenholgate.com/blog/2023/04/adventures-with-afd.html
如果需要在windows玩玩的话,可以用wepoll进行移植,理论上没有问题。
我以经浪费了时间,作了试验,wepoll真确可以用来移植依赖epoll的项目,至少tencent/libco没有问题。因为在这过程发现tencent/libco代码有这么多的问题,有点失望,所以原有问题继续继承。我已经移植并能够运行echosvr,echocli的例子代码。这个试验版本的libco4windows放在github。
分享坑。在windows系统,是不能够像其它操作系统那样直接使用汇编切换,尽管windows的SwitchFiber那是用同样的汇编切换。因为windows系统所有用户空间的服务,包括kernel, ntdll等,都可能关联TEB,SwitchFiber在最后完成汇编切换前,TEB现场也要进行切换。除非你完全不调用windows系统任何接口,crt底层还是要调用系统服务的。只要你要调用系统服务,TEB不正确,程序就立即崩掉。在windows系统,如果想要用stackful的协程,Fiber几乎是没有的选择。要补充,当你的程序是窗口子系统的话,跳开TEB现场切换,协程一定会崩掉,但是在用调试器调试的话,却由于调试器接管了许多异常中断,程序居然是不会崩的,只要分离调试器,程序就会因为那样没正确切换TEB的协程立即崩掉。另外如果程序是控制台子系统的话,却不会崩掉。libco的例子都是基于控制台运行,所以最初移植成功,能够运行在控制台子系统的程序。
现在,基本用Fiber代替了。代码在我的github仓库https://github.com/bbqz007/libco4windows。
同时在我的KTL放上了可测试的patch.libco:https://github.com/bbqz007/KTL/releases/tag/v0.9.3
关于stackless跟标准库的coroutine留待一下篇。