原文发布日期: 2019-05-18 06:03:50 +0000
前述:能不能够仅仅依靠Power BI自身来实现一些较简单的机器学习算法呢,而不用事事都依赖于R和Python,因此,我使用DAX做了一些尝试。过去,我实现了用DAX完成了多元线性回归,但那属于回归算法。对于分类算法,至少在K近邻算法方面,Google和百度上找不到有人做过这样的尝试,这也许因为极少有人会认为机器学习算法在DAX上能行得通,但下文的实践可以证明,这是行得通的。
一、K近邻算法简介
此处如了解可直接跳过
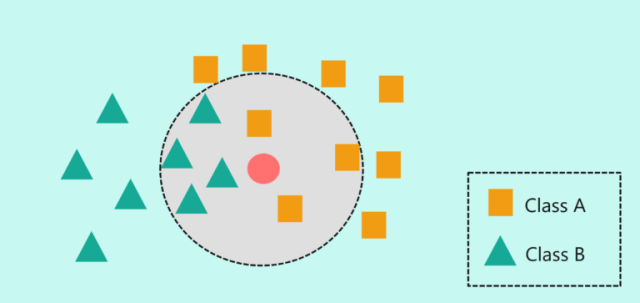
KNN全称k-nearest neighbors, 意为K近邻,是一种监督机器学习算法,新的数据点会放在现有数据集中,根据它与相邻数据点的距离来判定该数据点属于哪个类别。比如说,数据集里有一百张猫的图片和一百张狗的图片,并且记录了它们身体各个部位的特点,因此,当一张新的图片进来时,比如说图片中的动物有尖尖的耳朵,那么K近邻算法会依据它与数据集某些数据的相似性而把它归类为猫。此外,在现实应用中,我们根据不同情况来决定K的取值,比如令K等于7,那么我们分析离新的数据点最近的七个点属于什么类别,如果这些点中有3个属于A类,其余的属于B类,那么算法会依据多数表决法把它归类为B类,如下图所示:
二、利用DAX的实现过程
1.准备工作
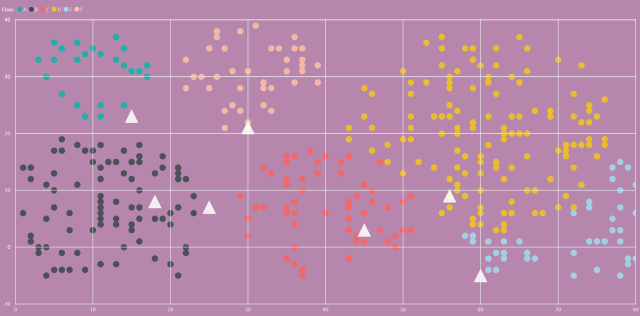
下图中的彩色散点是我随机生成的产品数据,横轴代表销量,纵轴代表利润,而其中7个白色三角形是待分类的测试数据:
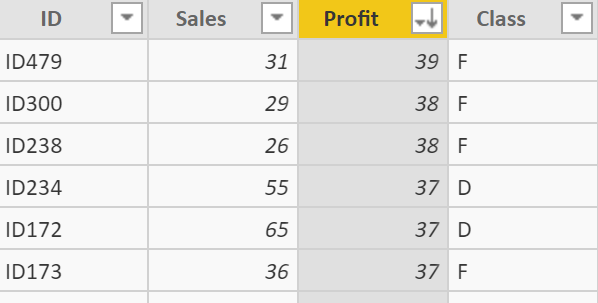
训练数据集十分简单,ID代表产品ID,Class则代表产品的分类:
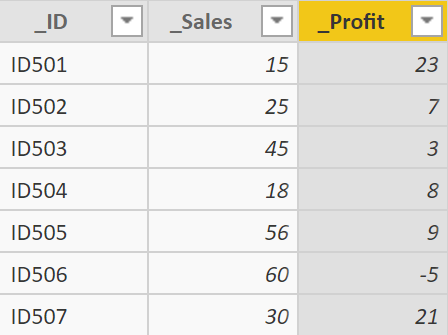
测试数据集使用如下代码生成:
Python
测试集 = DataTable("_ID", STRING,
"_Sales", INTEGER,
"_Profit",INTEGER
,{
{" ID501",15,23},
{" ID502",25,7},
{" ID503",45,3},
{" ID504",18,8},
{" ID505",56,9},
{" ID506",60,-5},
{" ID507",30,21}
}
)
结果如下:
案例目标是给这七个新的产品按照K近邻的原则自动分类。
2.实现方法
首先我们需要算出每个测试点和训练集数据点的距离,在此使用欧式距离公式计算,如下:
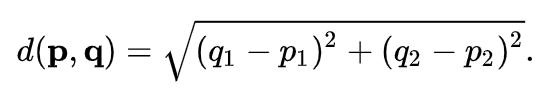
在此之前,我使用的方法是以测试集为主表,让它和训练集生成笛卡尔积,这样我们可以为每一个测试点去计算它和所有训练集数据点的距离,此外,我们需要算出所有训练数据中,有哪些数据点是被划分为测试点的邻近点的,在此处我取K等于9,在数据集中把这些距离测试点距离最小的前9名训练集数据标记出来,然后再过滤掉那些没有被标记的数据点,综上,执行如下代码以生成表"合并集":
Python
合并集 =
VAR VT_1 =
ADDCOLUMNS(
GENERATEALL('测试集','训练集'),
"DISTANCE",
CEILING(
SQRT(('测试集'_Sales-'训练集'Sales)^2+
('测试集'_Profit-'训练集'Profit)^2),
0.01))
VAR VT_2 =
ADDCOLUMNS(VT_1,
"IsKNN",
VAR K = 9
VAR v_id = '测试集'_ID
return
IF(
RANKX(
filter(VT_1,'测试集'_ID = v_id),
DISTANCE,ASC,Skip)<=K,
"T","F"))
--临近点将会被标记为"T"
VAR VT_3 =
FILTER(VT_2,IsKNN = "T")
RETURN VT_3
执行结果如下:
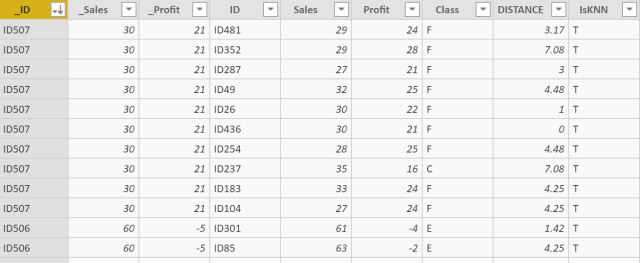
现在我们已经找出了所有临近点,现在是分析它们的时候。对每个测试点,找出其所有临近点类别的最多的那个类别,然后把这个类别赋给测试点,以完成多数表决法的分类,最终结果返回在名为"结果集"的表格中:
Python
结果集 =
VAR VT_4 =
ADDCOLUMNS('合并集',
"_Class",
VAR CLASSNUM_MAX =
CALCULATE(
MAXX('合并集',
CALCULATE(
COUNT('合并集'Class),
ALLEXCEPT('合并集','合并集'_Profit,'合并集'Class))),
ALLEXCEPT('合并集','合并集'_ID))
RETURN
IF(
CLASSNUM_MAX =
CALCULATE(
COUNT('合并集'Class),
ALLEXCEPT('合并集','合并集'_Profit,'合并集'Class)),
CALCULATE(
FIRSTNONBLANK('合并集'Class,1),
ALLEXCEPT('合并集','合并集'_ID,'合并集'Class)
)))
VAR VT_5 =
CALCULATETABLE(
GROUPBY(
FILTER(VT_4,_Class<>BLANK()),
'合并集'_ID,
'合并集'_Profit,
'合并集'_Sales,
_Class,
"Distance",
SUMX(CURRENTGROUP(),'合并集'DISTANCE)
))
RETURN VT_5
执行结果如下,"__Class"即为K近邻的分类结果:
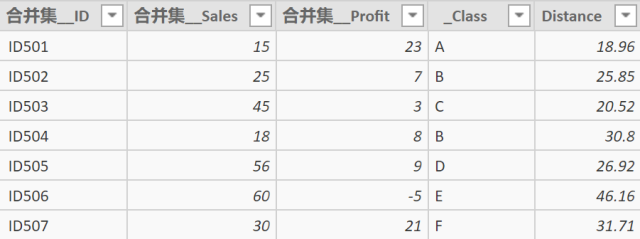
但此时,我们还需要考虑一种特殊情况(尽管在本案例未出现), 当某测试点的临近点中,有同样多的临近点属于A类,同样多的属于B类,那么该如何划分呢?在此则通过对比所有A类点和B类点距离测试点的实际距离,取距离较小者,因此,新建计算列如下:
Python
KNN_Result =
VAR Class_ =
CALCULATE(
MIN('结果集'Distance),
ALLEXCEPT('结果集','结果集'合并集__ID))
RETURN
IF(
class_ = '结果集'Distance,
'结果集'_Class,
BLANK())
此时,"KNN_Result"即为本案例的最终结果,当遇到特殊情况,过滤空值即可。至此,测试点成功完成K近邻分类,如下所示:
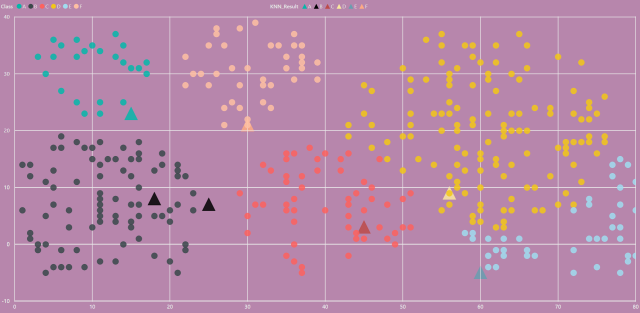
三、其他
数据集维度增加,公式以此类推即可,数据量过大会很消耗内存。如果你是一名DAX爱好者,你可以多做一些尝试。如果有关于用DAX(或M)实现K近邻更好的方法欢迎留言。