简介
C# 采用基于代的回收机制,并使用了更复杂的 链式跟踪算法 来识别对象是否为垃圾。
GC触发的原因
截至到.NET 8,GC触发的原因有18种
enum gc_reason
{
reason_alloc_soh = 0,//小对象堆,快速分配预算不足
reason_induced = 1,//主动触发GC,没有关于压缩和阻塞的选项
reason_lowmemory = 2,//操作系统发出内存不足通知信号
reason_empty = 3,//操作系统内存耗尽
reason_alloc_loh = 4,//大对象堆,快速分配预算不足
reason_oos_soh = 5,//小对象堆段,慢速分配预算不足
reason_oos_loh = 6,//大对象堆段,慢速分配预算不足
reason_induced_noforce = 7, // it's an induced GC and doesn't have to be blocking.
reason_gcstress = 8, // this turns into reason_induced & gc_mechanisms.stress_induced = true
reason_lowmemory_blocking = 9,
reason_induced_compacting = 10,
reason_lowmemory_host = 11,//主机发出内存不足通知信号
reason_pm_full_gc = 12, // provisional mode requested to trigger full GC
reason_lowmemory_host_blocking = 13,
reason_bgc_tuning_soh = 14,
reason_bgc_tuning_loh = 15,
reason_bgc_stepping = 16,
reason_induced_aggressive = 17,
reason_max
};根据命名总体分为5类
- ptr_limit预算用完
reason_alloc_soh,reason_alloc_loh 代空间不够 - 段空间预算用完
reason_oos_soh,reason_oos_loh oos是OutOfSegment的缩写, - 代码主动触发
reason_induced_xxxx,比如GC.Collect - 系统内存不足
reason_lowmemory,reason_lowmemory_blocking,reason_empty,reason_lowmemory_host - 其它
reason_bgc_tuning_soh,reason_bgc_tuning_loh
https://github.com/dotnet/runtime/blob/main/src/coreclr/gc/gc.h
GC回收流程图(节选)
以非并发工作站GC为蓝本,投石问路,先介绍最简单的一种,后面文章再展开。说人话就是挖坑待埋。
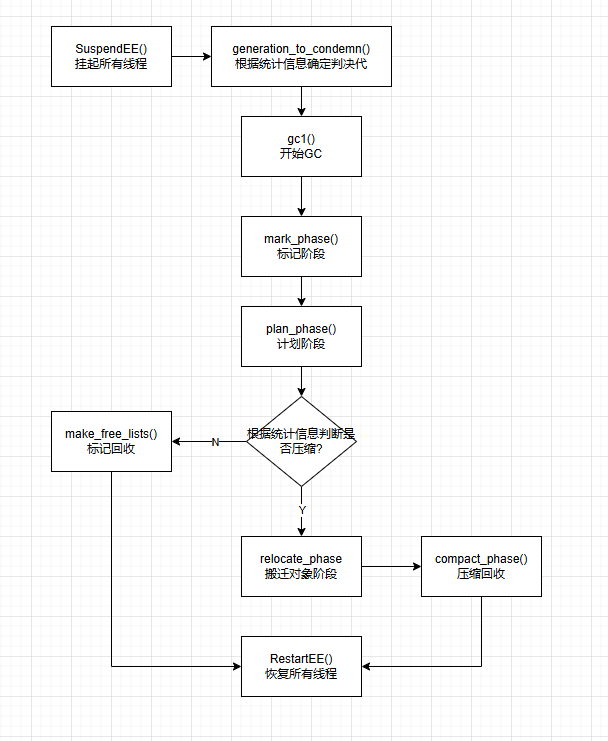
https://github.com/dotnet/runtime/blob/main/docs/design/coreclr/botr/garbage-collection.md
对象的遍历与标记
在mark_phase阶段,CLR会从根对象出发,寻找所有可到达对象,也就是依旧存在引用关系的对象。主要历经以下几个步骤
- 将根对象转换为托管对象的地址
如果根对象是非托管对象,需要在托管堆中给它占一个坑 - 设置固定标记
如果对象被固定,在ObjectHeader中,设置一个flg。 - 开始遍历对象的引用
通过MethodTable的类型信息,得出内部引用的偏移量。从而以深度优先的方式扫描。并将已经扫描的对象维护到一个集合中,这被称为"标记堆栈"
当标记堆栈中,不存在未访问的对象时。即代表遍历操作完成
注意:pinned与marked标记都是在mrak_phase阶段被设置,plan_phase阶段被清除。在正常情况下,是不会存在objectheader与methodtable中的。
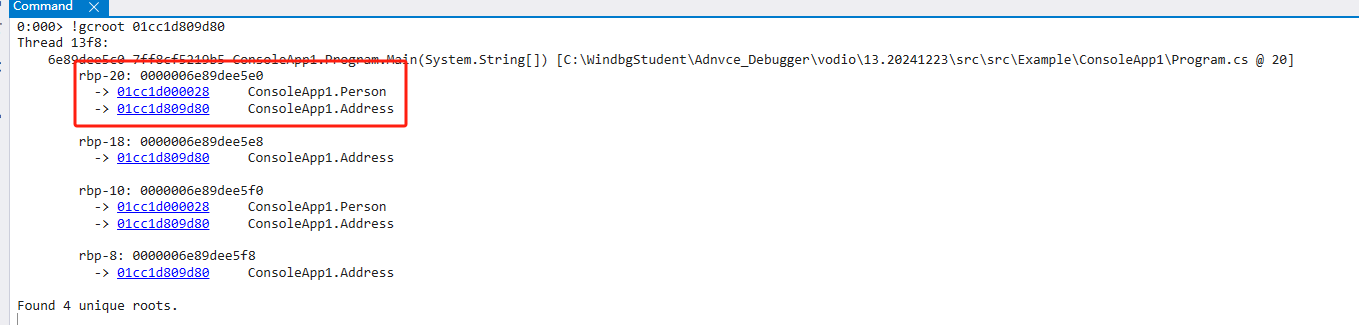
根对象
标记阶段最重要的任务,就是标记引用根(root),对于引用跟踪算法而言,这是万物的起点。
C#中,root分为四种,组成了标记阶段要扫描的所有root
线程栈(thread stack)
查找stack上的根对象,如果实时扫描stack与寄存器,在面对高频次的小对象GC中会显得力不从心,因此,CLR团队采用了更高性能的查询策略。
- 空间换时间,对引用类型缓存一个额外的gcinfo来提高查询性能
- 激进式根回收,对作用域进行判断,过滤掉出不会被线程栈引用的对象
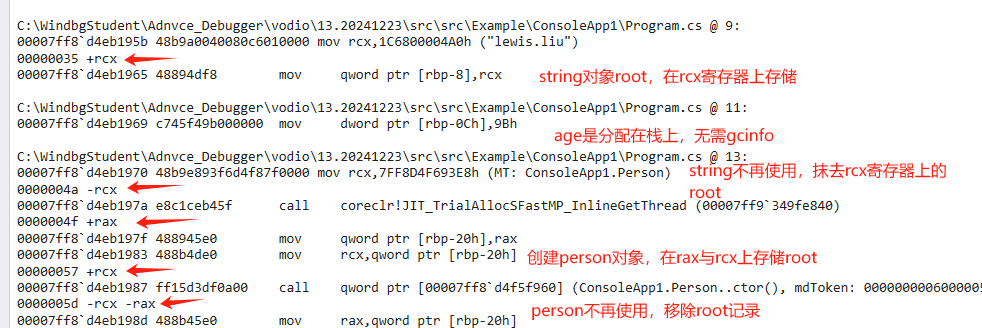
眼见为实:gcinfo
点击查看代码
static void Main(string[] args)
{
var name = "lewis.liu";
var age = 155;
var person=new Person();
Debugger.Break();
}

眼见为实:激进式根回收
点击查看代码
static void Main(string[] args)
{
Timer timer = new Timer((obj) =>
{
Console.WriteLine($"我是 Timer 线程,当前时间:{DateTime.Now}");
}, null, 0, 100);
var person = new Person();
GC.Collect();
Console.WriteLine("GC已触发。。。");
Console.ReadLine();
}使用.NET Core 2.1 分别以Debug与Release来运行。会发现惊喜!
1. Debug
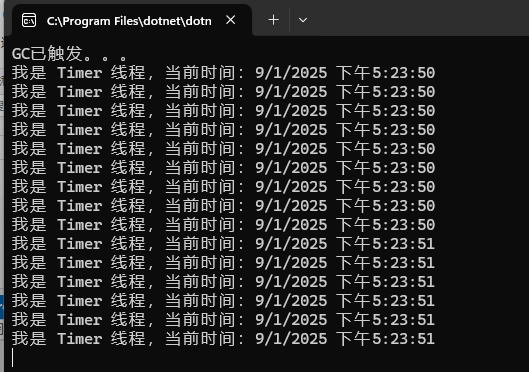
2. Release
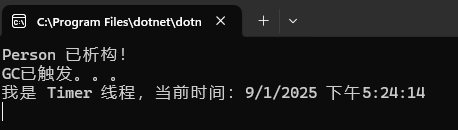
简单来说,不同版本的JIT对作用域有不同的判断策略,.NET Core 2.1中,会认为在触发GC.Collect()之前,timer与person都不再被stack所引用,因此会被GC所释放掉。这个过程叫做激进式根回收
.NET Core 3 之后已经修复此问题。
终结器队列(Finalize queue)
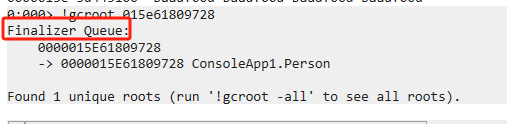
带有析构函数的对象,会单独在终结器队列中持有一份对这个对象的引用
眼见为实
点击查看代码
internal class Program
{
static void Main(string[] args)
{
Run();
Debugger.Break();
GC.Collect();
Console.WriteLine("11");
Debugger.Break();
}
static void Run()
{
var person = new Person();
}
}
class Person
{
public int Id { get; set; }
~Person()
{
Console.WriteLine("析构已执行");
}
}
GC句柄表(GCHandles)
通过GCHandle.Alloc或者fix产生的固定,以及CLR内部固定的对象
它们全部存储在CLR内部的全局句柄映射表中 ,可以使用!gchandles命令查看
GCHandleType总共有五种,GC只会对Normal,Pinned视为root,
- Weak
弱引用,弱引用允许应用程序访问对象,同时不会阻止垃圾回收器回收该对象 - WeakTrackResurrection
类似弱引用,与普通弱引用不同的是,当对象被垃圾回收时,它仍然可以跟踪对象的复活(Resurrection)情况 - Normal
强引用,只要这个GCHandle存在,垃圾回收器就不会回收它所引用的托管对象 - Pinned
强引用的更强版,当一个对象被这种方式引用时,它会在内存中被 "固定",防止垃圾回收器移动它的位置。这在与非托管代码交互时非常重要 - AsyncPinned(未开放)
固定句柄还有一个重要的变种,叫异步固定句柄,作用与类似pinned,有一个额外功能:一旦异步操作完成,它即在内部取消pinned状态。使得pinned的时间尽可能的短。目前尽在CLR内部开放。
还有一个fixed关键字,也可以固定对象。两者结果相同,但是root不同,使用GCHandle时是句柄表,使用fixed关键词是标记堆栈
眼见为实
点击查看代码
internal class Program
{
static void Main(string[] args)
{
Run();
Debugger.Break();
}
static void Run()
{
var person = new Person();
GCHandle.Alloc(person, GCHandleType.Normal);
}
}
class Person
{
}
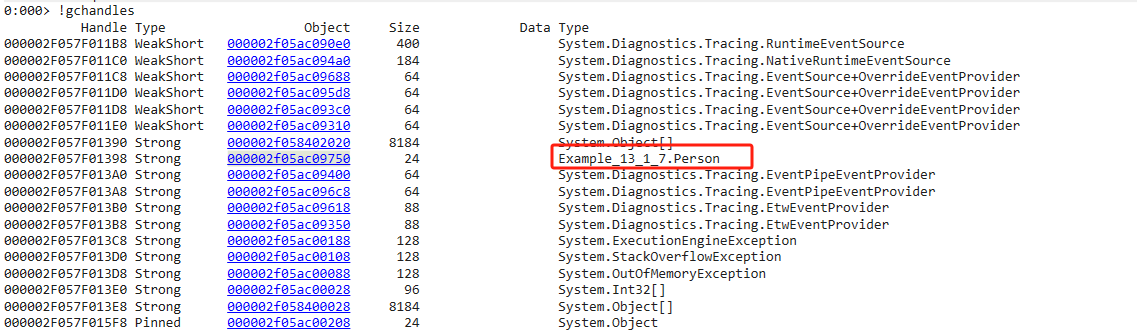
跨代引用
为了解决跨代引用问题产生的卡表,卡包
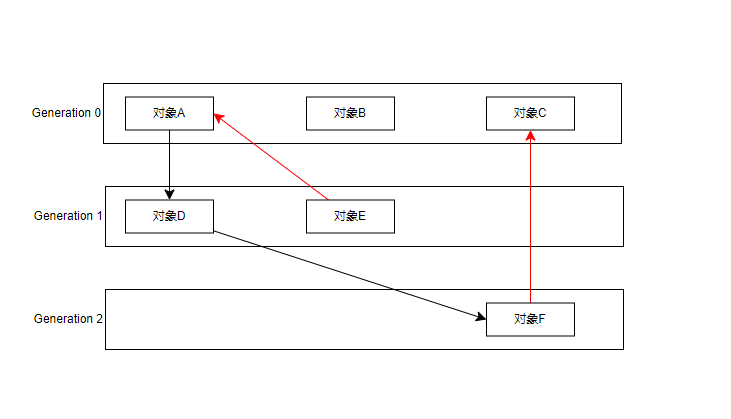
图中举例了一个常见的情况
- 年前对象引用老对象
A对象创建的时候,字段引用了对象E 。这很合理吧? - 老对象引用年前对象
在代码运行过程中,对象D的某个字段引用了对象A 。这也很合理吧?
那么问题来了,CLR将SOH分为0代,1代,2代。目的就是想根据生命周期的不同。对不同的代设置不同的GC频率。
现在好了,我回收0代内存,还因为被1代和2代引用。导致GC标记的时候,要遍历整个对象图
那内存分代图个什么?

remembered sets
为了处理跨代引用的问题,CLR团队引入了remembered sets(记忆集)。简单来说,就是记录对象被哪些对象所引用。拿空间换时间
太阳底下没有新鲜事,JVM也是使用记忆集解决跨代引用的问题

举个例子,回收1代内存。在某个时机(对象创建,指针移动),冗余了引用关系。那么只需要扫描对象的GC Root与remembered sets 便可轻松得知对象是否能被回收
思考一个问题,这里还有优化空间吗?
remembered sets存储的优化
上面可以看到,当回收1代内存时,要同时维护与0代和2代的关系。实现记忆集并不是一件容易的事
思考一下单链表与双链表的维护成本
那么如何减少维护成本呢?CLR团队做了一个决定:"回收N代意味着回收该代以及N-1代的对象"
简单来说就是:
- 仅回收0代
- 仅回收0代,1代
- 完全回收,回收0,1,2以及LOH
这样的话,记忆集只需要维护比对象代更老的关系,大大减轻了维护成本
remembered sets查询的优化
将每个对象的引用存储在记忆集中,记忆集虽然很小(只包含了更老对象的引用),但在大型系统中,几万甚至十几万个对象都是正常的现象,那么意味着也会有同等数量的记忆集。维护数量如此庞大的记忆集,将会为GC管理带来极大的开销
因此,CLR团队必须做出一些妥协,在性能与准确性之间进行权衡
- 卡表(Card Tables)
卡表的原理很简单,将老一代的内存地址。在逻辑上拆分为固定大小的区域。某个区域只要有任意对象存在跨代引用。就将对象所在的区域标记为dirty.
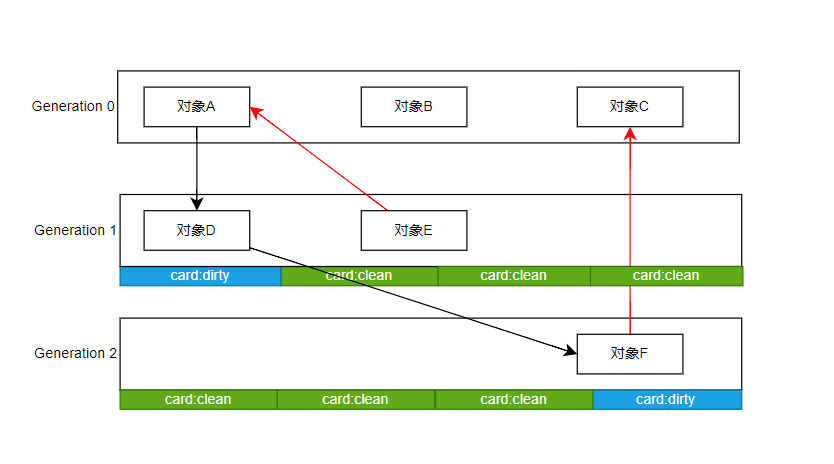
这样虽然会导致即使只有一个记忆集,也必须访问card中的所有对象。但也极大提高了GC的性能
有点类似涂抹算法
源码地址:https://github.com/dotnet/runtime/blob/main/src/coreclr/vm/amd64/JitHelpers_FastWriteBarriers.asm
在.NET Runtime中,一个bit位(clean/dirty代表0/1)对应256byte(64位)与128byte(32位) .
以64位系统为例,1byte可以表示8256=2048byte的存储区域。
一个卡表字的大小为4字节(DWORD).它所覆盖的大小为42048=8192byte
- 卡包(Card Bundles)
任意一个对象包含跨代引用,都会涂抹2048byte的空间。这就足够了吗?
假如一个Web应用程序内存使用量为1gb,那么对应多少卡表呢?10241024 1024/2024=524288. 512kb。
乍一看还算好,1mb都没有。但不要忘了,每一个对象都需要扫描一遍Card Table,以确定是否存在跨代引用。
想象一下,一个占用内存32gb的,超过5万个对象的服务器。它们的扫描量有多大。这会严重拖慢GC时间
因此,基于Card Tables的思路,CLR团队又引入了Card Bundles的概念。
以64位系统为例,每个bit位代表32个卡表字。因此一个bit覆盖范围为328192=262144,256kb
一个卡包位占用4字节空间,因此一个卡包可以覆盖256kb8*4=8192kb ,8mb空间。
这时候再算一下1gb内存使用量的web服务器,1024/8=128 .扫描量是不是就大大减少了。
其核心思路类似涂抹算法+二级缓存
眼见为实
点击查看代码
static void Main(string[] args)
{
var address = CreatedAddress();
GC.Collect();//gc后 address 升为1代
Debugger.Break();
var person = CreatedPerson();
person.Address = address;//0代的person引用1代的address
Debugger.Break();
}
static Address CreatedAddress()
{
var address = new Address()
{
City = "xxx",
County = "yyy"
};
return address;
}
static Person CreatedPerson()
{
var person = new Person()
{
Address = null,
};
return person;
}