专题目录
一文搞懂国际化(三)落地实践
一文搞懂国际化(四)总结提升
引子
第一章,我们分析了国际化项目的背景和基础知识,本章我们来分析一下要实现国际化的功能,有哪些设计点。本章只讲设计,不讲落地实践(见第三章)。
一、需求分析
回顾笔者主导的这一年的国际化改造项目过程,可归纳出三大块设计难点:
- 1)多语言改造 :系统支持用户设置自己的语言,支持语言切换,即【语言切换】功能。
- 2)多时区改造 :系统支持多时区客户端时间。客户看到的是自己本地时区时间,但后端服务、数据库一般只部署在一套环境中。如何设计解决【前端多时区,后端统一时区】的业务场景。
- 3)翻译运营 工具 :上线生产后,为了快速实现,持续可拓展的新增语言功能,急需一个翻译运营工具,即如何设计实现一个新增/维护语言的【翻译运营工具】。
相信大部分做国际化改造的项目都会遇到上面所说的设计场景,下面我们针对这三大块进行初步分析。
二、多语言设计
要实现用户多语言切换,可拆解成2部分:
- 第一步,设置用户想要的语言:具体在APP上还是WEB端上搞个入口支持设置用户的语言即可。
- 第二步,使用设置的语言,加载对应的语言翻译资源了。这里分两大块,前端的工程内的静态资源包、后端的接口动态翻译。
不管是前端静态资源包还是后端的动态翻译,都有3种实现逻辑,即设备跟随、账号跟随、系统跟随。
- 系统跟随 :未设置语言,直接跟随系统(比如APP端就是手机android/ios系统语言,WEB端就是客户浏览器运营设备的系统语言)。
- 设备跟随 :即语言跟随客户端设备走,换设备后得重新设置语言,否则默认系统跟随。
- 账号跟随 :即语言跟随账号走,不管换了什么客户端设备都是账号设置的语言,否则默认系统跟随。
纯系统跟随策略的产品很少(不够灵活),使用另外两种策略的产品市面上很多,看哪种适合你。(一般来说,账号跟随适合强B端的重企业偏向的产品,设备跟随适合强C端的重个人体验的产品。)
2.1 前端静态翻译
前端逻辑很简单:就是根据当前语言,获取静态资源包中的翻译。
1.语言包
现代前端工程框架 react、vaue等都是有自己支持一套国际化方案的,在前端工程中的保存有i18n翻译资源包(例如VUE的i18n框架),随着项目打包发布。例如zh_CN.json 这样的json格式。
2.登录态持有语言
前端的语言,生命周期应该是登录态持有的(不管用的是设备跟随还是账号跟随策略)。即如果语言被改了,不会立即生效,登出后再登入,刷新登录态,此时获取到最新语言,才会生效。
2.2 后端动态翻译
后端的翻译跟前端最大的不同是复用。比如某个微服务中的一个字典翻译,可能会被上层多个不同业务层服务接口用到。如何设计一个可复用,高性能,易维护的后端翻译架构,还是有点难度的。下买呢我们从业务模型、具体设计两个步骤来进行设计拆解。
2.2.1****翻译依赖梳理
思考到大部分翻译是通过接口定义的返回字段上做的翻译,比如某个resultDTO。这个DTO(或者是其中某些字段)又会被多个上层应用引用。当某个底层服务的接口resultDTO中的翻译字段更新时,上层引用的缓存需要同步更新。这种缓存依赖关系,需要配置在各自的apollo中。这样当依赖的缓存更新时,上层引用方也会刷新缓存。

2.2.2 流程设计

1.前置操作
**1)设置好用户的语言:**不管是客户端跟随,还是账户跟随。
**2)后端服务:**用到翻译的后端服务启动时,根据配置的服务依赖关系,读取翻译库,生成内存缓存。
2.请求流程
1)前端请求:前端请求头header传过来。前端登录态持有语言的生命周期(不管语言策略是客户端跟随还是账户跟随)。
2)后端框架:读取请求头中的语言+服务名+翻译key,从缓存中获取翻译值。
2.2.3 重点设计
1)能力封装
后端翻译,统一存储在配置中心(微服务)的翻译表中。配置中心对外提供翻译的增删改查接口,作为一种翻译能力提供。根据第一节业务分析得知,翻译拆解为服务级维护 ,翻译表设计核心业务模型:服务名-翻译key-语言类型-翻译值value.
2)翻译性能
- 增加缓存:由于翻译是高频请求且不会经常变动,我们设计在业务服务中增加内存缓存。可极大提高接口查询翻译的性能。
- 热刷新:同时,当翻译资源有新增/更新时,需要支持热刷新。避免重启生产服务带来的风险。翻译资源增加版本号概念,版本变化,监听缓存自动刷新。
3)框架升级
后端的底层框架包(一般叫base/core包)升级:要能够解析请求头中的语言+接口返回序列化时增强做翻译。接口返回DTO上加注解,注解分两类:整个类上,字段上。字段上的注解需要填写key。框架层在返回DTO序列化时,读取翻译注解:根据key+语言从缓存中读取对应的翻译值,塞入序列化返回值。
三、多时区设计
多时区改造是国际化改造中的重头戏,如非必须改造,不建议轻易动。特别是业务链路长、微服务特别多、软硬件一体化的系统。笔者项目设计了2个月,改造花了3个月最后才上线。
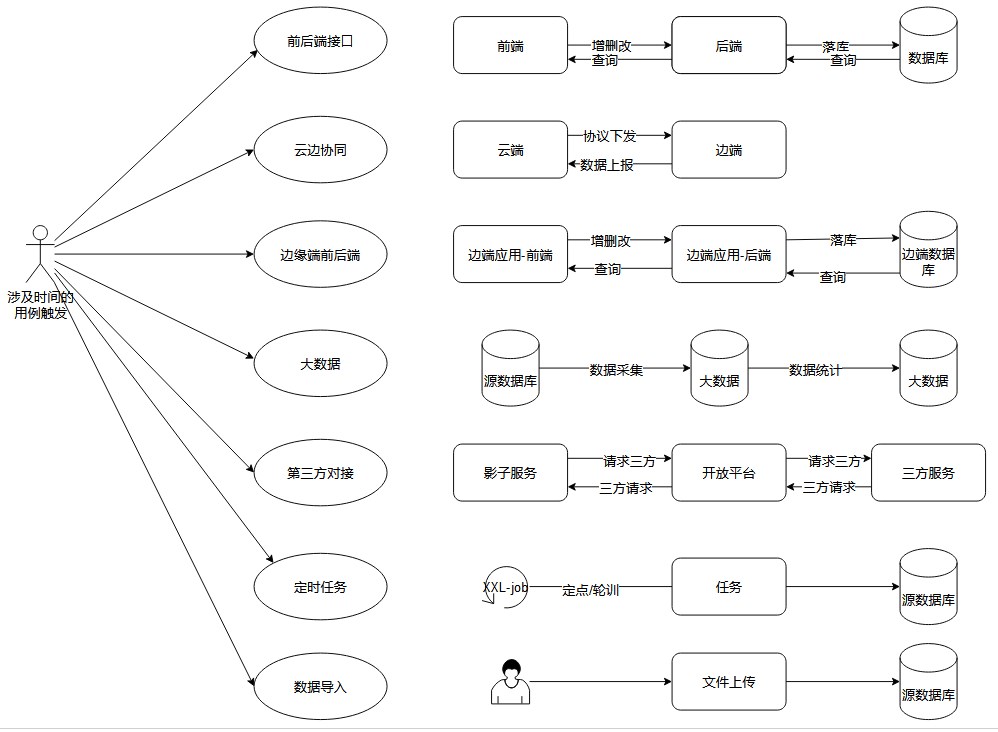
我们以最简单的前后端接口通信为例,讲解多时区的问题以及改造方案。
一般我们未支持过国际化的系统特性:
- 1.前后端通信丢失时区:前后端数据通信,接口只会传一个时间字符串 "yyyy-mm-dd HH:mm:ss"。此时并不知道这个时间,对应的时区是什么,也就没法精确定位到一个时间点。
- 2.数据存储丢失时区:数据库的时间字段是不带时区的timeStamp类型。光看数据库这个字段数据,也没法精确定位到一个时间点。
一开始业务在国内跑,一般系统的运行环境都是UTC8时区的,所以不会出现上述的2点时区偏移问题。但在国际化多时区场景下,同一个时间字符串 "yyyy-mm-dd HH:mm:ss",在美国和在韩国,代表的肯定不是一个时间点。第二点,当一般业务量不是特别巨大时,业务发展初期,也不会根据地域时区去拆库。所以数据库一般就一个时区,即国内的UTC8。有点设计经验的小伙肯定想到了,时区转换的方案:即前端数据到后端后开始,统一使用一种时区,包括存储。最后接口返回给前端时,再转换前端不同的时区时间即可。问题来了,我们是继续使用UTC8做后端底座,还是全部改造成UTC0呢?两种方案的对比如下:
3.1 时区改造方案

方案一:使用UTC8环境(后端服务、组件、数据库) 不变。步骤如下:
- 前端:请求在header中传本地时区timezone.
- 后端:请求到后端时,在入参解析时,框架根据header中的timezone(缓存本地),转换成UTC8时区时间 。(图中UTC9→UTC8)
- 后端:执行业务逻辑,数据落库(UTC8)。
- 后端:请求返回JSON格式数据时,框架统一在序列化时根据缓存中的timezone转换为客户端本地时区时间 (图中UTC9)。
- 前端:拿到后端返回的数据,时间格式化展示。

方案二:重新部署一套UTC0环境(后端服务、组件、 数据库 、洗数据)。
- 前端:发起请求,传值ISO格式 时间,例如:韩国东九区时间"2024-01-12T09:00:00+09:00"。ISO8601格式的时间(上跳第一章第三节),是为了有更好的可读性,且能表示唯一时间。
- 后端:请求到后端时,在入参接收时,框架把本地时区时间转换为系统默认时区(UTC0)的时间 。(图中UTC9→UTC0)
- 后端:执行业务逻辑,数据落库(UTC0)。
- 后端:请求返回在序列化时,框架统一在序列化时返回 ISO零时区时间。
- 前端:拿到后端返回的数据,接收ISO时间自动转成客户端本地时区时间 ,格式化后展示。
建议:
笔者的团队在纠结了多轮博弈后,最终还是选择了UTC0时区,一步到位,耗时三个月呕心沥血才改造完毕。这两种方案都可行。看哪种适合你的团队即可!!!。如果系统链路长,涉及各种云、边、端服务,保守起见可以使用UTC8方案一。
四、翻译运营工具设计
4.1 翻译工具设计
分析了国际化翻译业务场景中,在运营平台中新增多语言管理菜单,进行可视化运维。可拆分为3步骤:
- 1.字典库维护:导出翻译表,人工识别专业词汇,线下翻译后导入字典库,可视化维护。
- 2.智能翻译:拆解出一个步骤,专门用来做翻译。调用Dify的大模型翻译API即可,这是一个批量离线翻译的过程。
- 3.翻译管理:把智能翻译的结果下载,完事人工检查一下本次翻译的变化列,校验无误后导入翻译管理,即可被业务使用,支持可视化维护。流程如下图:

4.2 开放问题
关于如何提高翻译精准度问题,这里提供一些思路,大家可选择适合自己项目的:
1.人工校对
由于翻译场景不同,翻译值可能变化较大,如需要极度精准翻译,一定是找专业翻译人员,一个一个页面去校对。
2.AI翻译
1)由于中文的复杂度可能导致翻译的不精准。可以先中文->英文,再用英文做key,调用AI去翻译 韩语、俄语等外语。精准度会有较大提升。
2)如有专业领域的大模型直接选择更佳。
3.打标收敛
打标已矫正过的翻译,逐步收敛不精准翻译。