软件测试 ------ 自动化测试(Selenium)
- 什么是Selenium
- Python安装Selenium
- 写一个简单用例
- CSS_SELECTOR和XPATH
- 浏览器快速定位页面元素
- 浏览器的前进(forward),后退(back),刷新(refresh)
- 浏览器参数设置
- 页面加载策略
在测试过程当中,尤其是对web页面的测试中,有很多的步骤是重复且繁琐的,这些步骤耗时耗力,效率还非常低下。所以就有了自动化测试 把人们从繁琐复杂的步骤中解放出来,把这些工作交给代码。这里我们要介绍的Selenium就是用于web自动化测试:
什么是Selenium
Selenium 是一个用于自动化Web浏览器操作的工具,它允许你通过编写代码来控制浏览器执行一系列动作,比如点击按钮、填写表单、导航页面等。Selenium 主要用于网页测试,但它也可以被用来进行其他类型的网络爬虫或者自动化任务。
Selenium 支持多种编程语言,包括 Java、C#、Python、Ruby、JavaScript (Node.js) 和 PHP。你可以使用这些语言中的任意一种来编写 Selenium 测试脚本或程序。
以下是 Selenium 的几个关键组件:
- Selenium WebDriver: 这是 Selenium 项目的核心部分,提供了面向对象的 API 来控制不同的浏览器(如 Chrome、Firefox、Edge 等)。WebDriver 与浏览器直接交互,可以模拟真实用户的操作。
- Selenium IDE: 这是一个记录和回放工具,主要用于快速创建简单的测试用例。它作为一个浏览器插件提供,支持 Firefox 和 Chrome。
- Selenium Grid: 它允许你在多个机器上并行运行测试,从而大大缩短了测试时间。Grid 特别适合需要在不同环境(操作系统和浏览器组合)下测试的应用。
使用 Selenium 自动化 Web 应用时,通常需要做以下几件事:
- 安装相应的浏览器驱动,例如 ChromeDriver 对于 Google Chrome。
- 编写测试脚本,选择你喜欢的编程语言,并利用 WebDriver API 编写代码。
- 执行测试,这可以通过命令行、集成开发环境(IDE),或者是持续集成系统来完成。
Python安装Selenium
1.安装webdirver-manager
首先,我们的浏览器有很多种,像IE,谷歌,火狐等等,如果我们想操作不同的浏览器,就要安装不同的驱动 ,而且还要驱动还要符合相应的版本,这是一个很麻烦的工作,所以我们可以下载一个webdriver-manager,这样无论我们是什么类型或者什么版本的浏览器,他都会帮我们管理好,省去了我们下驱动的时间。
Python安装webdriver-manager,直接pip安装就行:
python
pip install webdriver-manager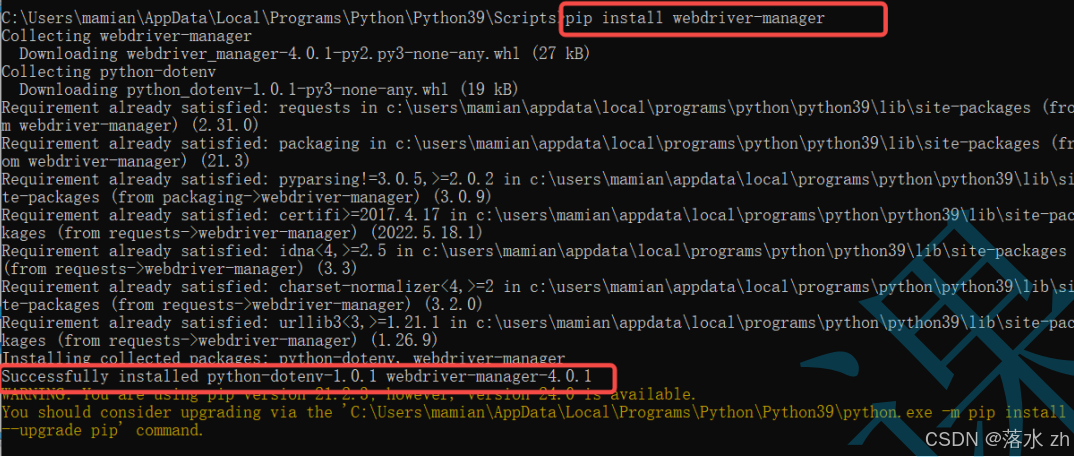
2.安装Selenium
接下来就是pip安装selenium了,这里我们安装4.0版本的库:
python
pip install selenium==4.0.0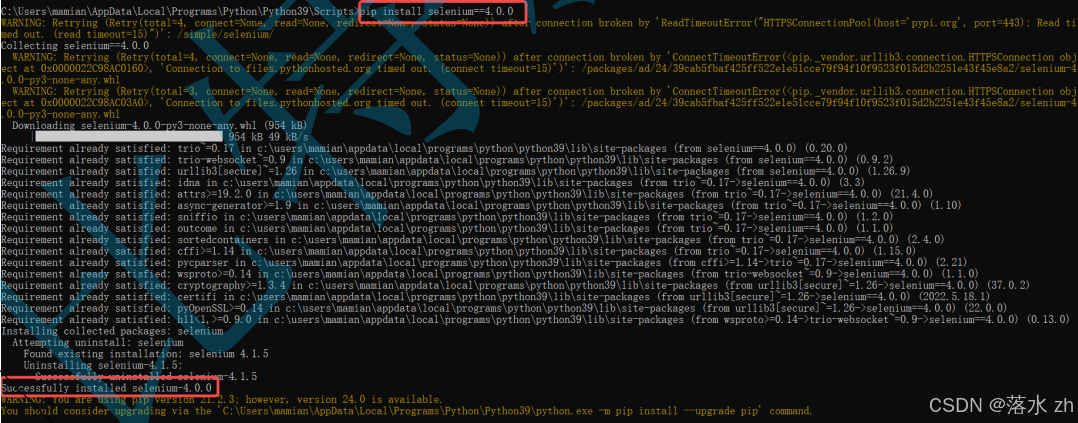
这样我们就安装好了selenium
写一个简单用例
打开Pychram,创建一个新项目,写下这几段代码
python
import time
# 导入所需的 Selenium 模块
from selenium import webdriver
from selenium.webdriver.firefox.service import Service as FirefoxService # 创建Firefox WebDriver服务
from selenium.webdriver.common.by import By # 用于选择元素的定位策略
from webdriver_manager.firefox import GeckoDriverManager # 管理并自动下载适合的 GeckoDriver
# 创建驱动对象(即启动浏览器)
# 使用 GeckoDriverManager 自动安装或更新与当前系统匹配的 GeckoDriver,并获取其路径。
firefox_driver_path = GeckoDriverManager().install()
# 创建一个 FirefoxService 对象,指定使用的 GeckoDriver 路径。
service = FirefoxService(firefox_driver_path)
# 使用创建的服务对象实例化一个 Firefox WebDriver 实例,从而打开一个新的 Firefox 浏览器窗口。
driver = webdriver.Firefox(service=service)
# 发送URL(即导航到目标网页)
# 访问 bilibili 网站。
driver.get("https://www.bilibili.com/")
# 找到搜索框,输入关键词 "小潮院长"
# 使用 CSS_SELECTOR 定位页面上的搜索输入框,并向其中发送字符串 "小潮院长"。
search_input = driver.find_element(By.CSS_SELECTOR, ".nav-search-input")
search_input.send_keys("小潮院长") # 输入搜索关键字
time.sleep(3) # 等待几秒以确保页面和元素加载完成
# 点击搜索按钮
# 使用 CSS_SELECTOR 定位搜索按钮,并模拟点击操作。
search_button = driver.find_element(By.CSS_SELECTOR, ".nav-search-btn > svg:nth-child(1)")
search_button.click() # 执行点击动作
time.sleep(3) # 等待几秒以确保搜索结果加载
# 关闭浏览器
# 结束会话,关闭所有由 WebDriver 打开的浏览器窗口。
driver.quit()
# 注意:在实际使用中,应该考虑添加异常处理机制,例如 try-except 块来捕获可能出现的错误,
# 并且可能需要更智能的方法来等待元素加载,比如使用显式等待(WebDriverWait)而不是简单的 sleep。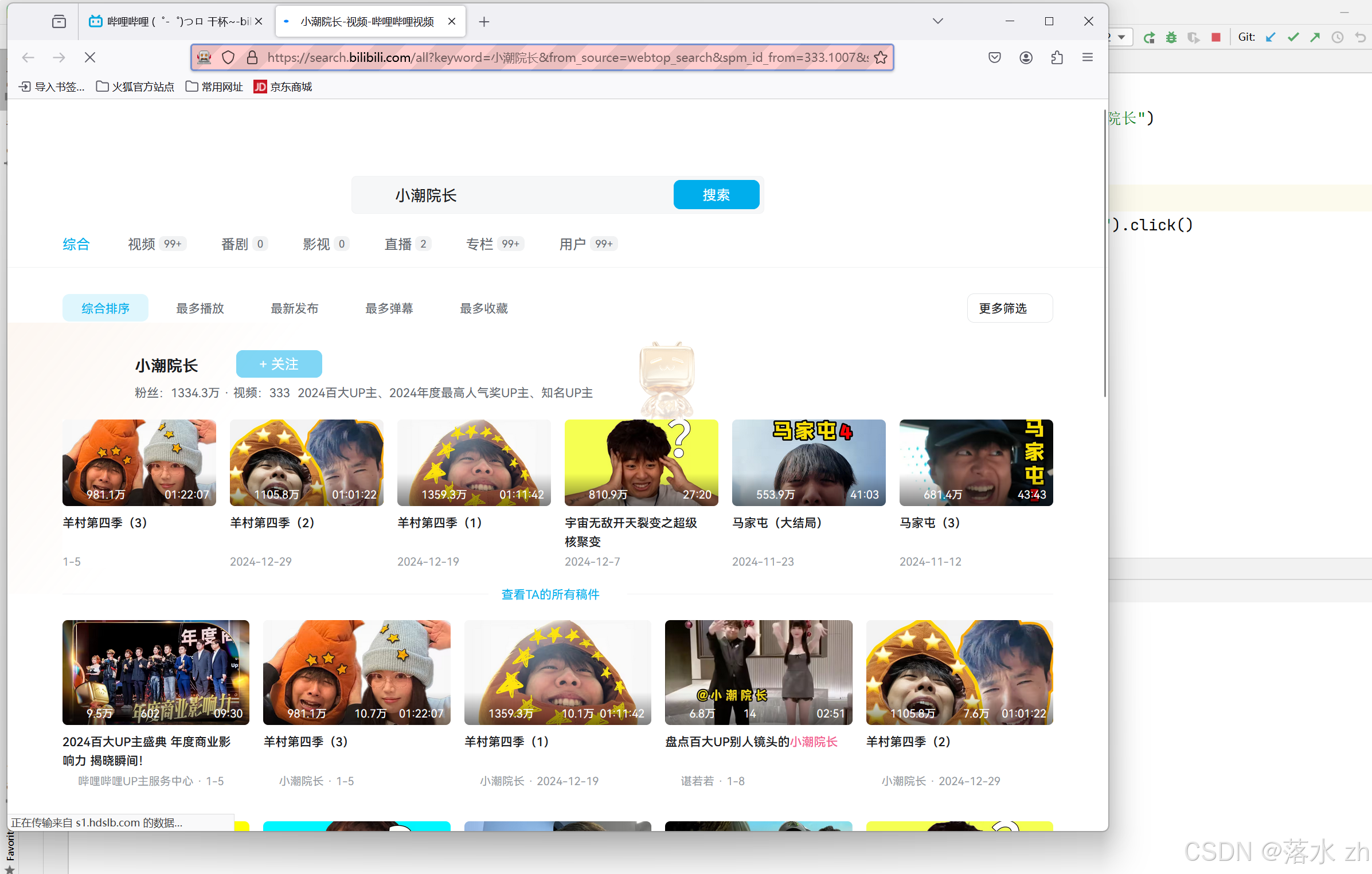
这里我用的是火狐,大家可以试试其他的浏览器。
CSS_SELECTOR和XPATH
在我们定位页面元素的时候,我们可以用两种方式CSS_SELECTOR和XPATH
python
import time
from selenium import webdriver
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.firefox import GeckoDriverManager
# 创建驱动对象
FirefoxIns = GeckoDriverManager().install()
driver = webdriver.Firefox(service=Service(FirefoxIns))
# 发送url
driver.get("https://www.bilibili.com/")
# 找到搜索框,输入小潮院长
driver.find_element(By.CSS_SELECTOR,".nav-search-input").send_keys("小潮院长")
time.sleep(3)
# 点击搜索键
driver.find_element(By.CSS_SELECTOR,".nav-search-btn > svg:nth-child(1)").click()
driver.find_element(By.XPATH,"/html//body/div[2]/div[2]/div[1]/div[1]/div/div/form/div[2]/svg").click()
time.sleep(3)
# 关闭浏览器
driver.quit()这里的话,XPATH大家了解一下,我测试了一下,用XPATH可能会找不到页面元素。
浏览器快速定位页面元素
现在我们知道了代码咋写,但是我们怎么样知道元素在页面中的位置呢?这里要用到浏览器的开发者工具,快键键一般是F12。
假设我现在在b站的页面要定位搜索键的位置:
 点击F12,进入开发者界面:
点击F12,进入开发者界面:
 点击左上角的小框:
点击左上角的小框:
 点完之后,把鼠标挪到搜索图标就会自动定位这个图标的代码:
点完之后,把鼠标挪到搜索图标就会自动定位这个图标的代码:


右击,点击复制,选择CSS选择器:
 这样我们就可以得到在CSS选择器下,图标的代码是多少。
这样我们就可以得到在CSS选择器下,图标的代码是多少。
浏览器的前进(forward),后退(back),刷新(refresh)
python
import time # 导入time模块用于使用sleep函数
# 导入Selenium WebDriver相关的类和方法
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.firefox import GeckoDriverManager
# 使用webdriver_manager自动管理Firefox的驱动程序(GeckoDriver),并安装适合的版本
FireFoxIns = GeckoDriverManager().install()
# 创建一个Firefox浏览器实例,并指定服务为之前安装的GeckoDriver
driver = webdriver.Firefox(service=Service(FireFoxIns))
# 打开百度首页
driver.get("https://www.baidu.com/")
# 定位搜索框元素,使用CSS选择器匹配ID为'kw'的元素
serach_box = driver.find_element(By.CSS_SELECTOR, "#kw")
# 在搜索框中输入搜索关键词
serach_box.send_keys("阮阮是个天才7")
# 定位搜索按钮元素,使用CSS选择器匹配ID为'su'的元素
click_button = driver.find_element(By.CSS_SELECTOR, "#su")
# 点击搜索按钮执行搜索
click_button.click()
# 暂停脚本3秒,等待搜索结果页面加载
time.sleep(3)
# 浏览器后退到上一页面
driver.back()
# 暂停脚本3秒,观看后退效果
time.sleep(3)
# 浏览器前进到下一页面
driver.forward()
# 暂停脚本2秒,观看前进效果
time.sleep(2)
# 刷新当前页面
driver.refresh()
# 暂停脚本2秒,观看刷新效果
time.sleep(2)
# 关闭浏览器并结束会话
driver.quit()浏览器参数设置
无头模式
无头模式(Headless Mode)是指浏览器在没有图形用户界面(GUI)的情况下运行。这种模式非常适合用于服务器端环境或不需要可视化输出的自动化测试场景,因为它可以节省资源并加快执行速度。
在创建driver时带上-headless
python
options = webdriver.ChromeOptions()
options.add_argument("-headless")
driver =
webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()),options
=options)
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.firefox import GeckoDriverManager
# 使用webdriver_manager自动管理Firefox的驱动程序(GeckoDriver),并安装适合的版本
FireFoxIns = GeckoDriverManager().install()
# 创建一个 FirefoxOptions 对象用于存储选项,并设置为无头模式(即不显示浏览器窗口运行)
options = webdriver.FirefoxOptions()
options.add_argument("-headless")
# 创建一个新的 Firefox 浏览器实例,并传入配置好的 options 参数
driver = webdriver.Firefox(service=Service(FireFoxIns), options=options)
# 设置全局隐式等待时间为10秒。这意味着在查找元素时,如果没找到,WebDriver会继续尝试最多10秒
driver.implicitly_wait(10)
# 打开百度首页
driver.get("https://www.baidu.com/")
# 定位搜索框元素,使用CSS选择器匹配ID为'kw'的元素
serach_box = driver.find_element(By.CSS_SELECTOR, "#kw")
# 在搜索框中输入搜索关键词
serach_box.send_keys("阮阮是个天才7")
# 定位搜索按钮元素,使用CSS选择器匹配ID为'su'的元素
click_button = driver.find_element(By.CSS_SELECTOR, "#su")
# 点击搜索按钮执行搜索
click_button.click()
# 暂停脚本3秒,等待搜索结果页面加载
time.sleep(3)
# 浏览器后退到上一页面
driver.back()
# 暂停脚本3秒,观看后退效果
time.sleep(3)
# 浏览器前进到下一页面
driver.forward()
# 暂停脚本2秒,观看前进效果
time.sleep(2)
# 刷新当前页面
driver.refresh()
# 暂停脚本2秒,观看刷新效果
time.sleep(2)
# 关闭浏览器并结束会话
driver.quit()页面加载策略
页面加载策略(Page Load Strategy)是 Selenium WebDriver 中用于控制浏览器如何加载网页的一种设置。它决定了 WebDriver 在执行脚本时等待页面加载完成的程度。不同的加载策略可以影响到测试的速度和稳定性。以下是三种可能的页面加载策略:
normal(默认):
- 这是最完整的加载策略,WebDriver 会等待整个页面完全加载完毕,包括所有的子资源(如图片、样式表等),然后才继续执行下一步操作。
- 这种方式确保了所有内容都已准备好,但可能会导致较长的等待时间,特别是对于那些有大量外部资源的页面。
eager或者称为interactive:
- 当文档的内容已经加载完毕,并且DOM树已经构建好,但是像图片、样式表等其他资源还在加载中时,WebDriver 就认为页面已经加载完成并开始执行下一步操作。
- 使用这种方式可以在保证基本功能可用的同时减少等待时间,提高测试效率。
none:
- WebDriver 不会等待页面加载结束,而是立即返回控制权给测试脚本。这意味着只要初始 HTML 文档被解析,WebDriver 就不再关心后续资源是否加载完成。
- 这种策略非常适合需要快速启动的场景,但在这种情况下,你必须自己处理任何与未加载资源相关的潜在问题。
python
options.page_load_strategy = '加载⽅式'
python
options = webdriver.ChromeOptions()
options.page_load_strategy = 'eager'
driver =
webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()),options=options)
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.firefox import GeckoDriverManager
# 使用webdriver_manager自动管理Firefox的驱动程序(GeckoDriver),并安装适合的版本
FireFoxIns = GeckoDriverManager().install()
# 创建一个 FirefoxOptions 对象用于存储选项
options = webdriver.FirefoxOptions()
# 设置页面加载策略为 'eager',即交互式加载,这样可以减少等待时间,提高测试效率
# 页面内容加载完毕后,不等待图片和样式表等资源加载完成就继续执行下一步操作
options.page_load_strategy = "eager"
# 创建一个新的 Firefox 浏览器实例,并传入配置好的 options 参数
driver = webdriver.Firefox(service=Service(FireFoxIns), options=options)
# 打开百度首页
driver.get("https://www.baidu.com/")
# 定位搜索框元素,使用CSS选择器匹配ID为'kw'的元素
serach_box = driver.find_element(By.CSS_SELECTOR, "#kw")
# 在搜索框中输入搜索关键词
serach_box.send_keys("阮阮是个天才7")
# 定位搜索按钮元素,使用CSS选择器匹配ID为'su'的元素
click_button = driver.find_element(By.CSS_SELECTOR, "#su")
# 点击搜索按钮执行搜索
click_button.click()
# 暂停脚本3秒,等待搜索结果页面加载
time.sleep(3)
# 浏览器后退到上一页面
driver.back()
# 暂停脚本3秒,观看后退效果
time.sleep(3)
# 浏览器前进到下一页面
driver.forward()
# 暂停脚本2秒,观看前进效果
time.sleep(2)
# 刷新当前页面
driver.refresh()
# 暂停脚本2秒,观看刷新效果
time.sleep(2)
# 关闭浏览器并结束会话
driver.quit()