软件测试 ------ Selenium(窗口)
- 多个窗口打开情况
- 窗口大小的设置
-
- [窗口最大化 maximize_window()](#窗口最大化 maximize_window())
- [窗口最小化 minimize_window()](#窗口最小化 minimize_window())
- [指定窗口全屏 fullscreen_window()](#指定窗口全屏 fullscreen_window())
- [手动设置窗口大小 set_window_size()](#手动设置窗口大小 set_window_size())
- 屏幕截图
我们之前的测试都只是简单打开了一个页面,如果有多个页面,我们的程序还是要进行一些相应的修改:
多个窗口打开情况
我们以b站为例,我们首先先打开首页,然后点击热门:

 我们可以看到两个页面的url是不一样的,如果我们按照以前的方法来写,返回值就有问题:
我们可以看到两个页面的url是不一样的,如果我们按照以前的方法来写,返回值就有问题:
python
import time
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from webdriver_manager.firefox import GeckoDriverManager
# 创建驱动对象
FirefoxIns = GeckoDriverManager().install()
driver = webdriver.Firefox(service=Service(FirefoxIns))
# 发送url
driver.get("https://www.bilibili.com/")
#driver.get("https://www.baidu.com/")
# 获取当前页面的url
url1 = driver.current_url
print(url1)
# 点击热门
hot_box = driver.find_element(By.CSS_SELECTOR,"#i_cecream > div.bili-feed4 > div.bili-header.large-header > div.bili-header__channel > div.channel-icons > a:nth-child(2) > div > svg")
hot_box.click()
time.sleep(3)
# 再次获取url
url2 = driver.current_url
print(url2)
time.sleep(3)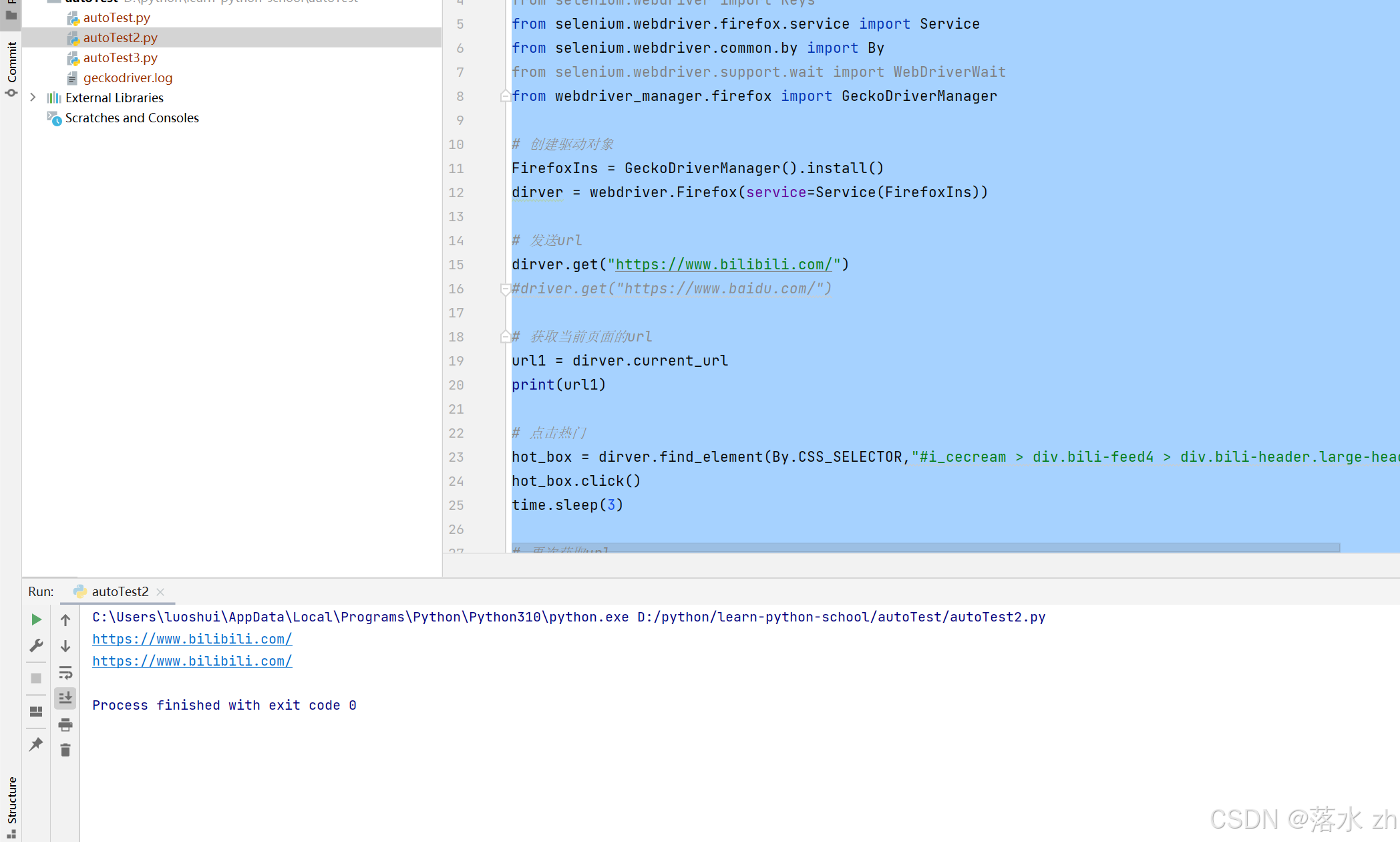
我们发现返回的两个结果都是一样的,好像返回的url是第一个页面上的。并没有发生变化,那是因为在使用 Selenium 进行网页自动化测试时,如果你打开了新的浏览器标签页或窗口,你可能需要切换到新的页面句柄来与新打开的页面进行交互。每个标签页或窗口都有一个唯一的句柄(handle),你可以通过这些句柄来切换当前操作的上下文。
python
import time
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from webdriver_manager.firefox import GeckoDriverManager
# 创建驱动对象
FirefoxIns = GeckoDriverManager().install()
driver = webdriver.Firefox(service=Service(FirefoxIns))
# 发送url
driver.get("https://www.bilibili.com/")
#driver.get("https://www.baidu.com/")
# 获取当前页面的url
# 获取当前窗口句柄(通常是第一个打开的页面)
main_window = driver.current_window_handle
url1 = driver.current_url
print(url1)
# 点击热门
hot_box = driver.find_element(By.CSS_SELECTOR,"#i_cecream > div.bili-feed4 > div.bili-header.large-header > div.bili-header__channel > div.channel-icons > a:nth-child(2) > div > svg")
hot_box.click()
time.sleep(3)
# 获取所有窗口句柄
all_windows = driver.window_handles
# 切换到最新的窗口(假设它是新打开的那个)
for window in all_windows:
if window != main_window:
driver.switch_to.window(window)
break
# 再次获取url
url2 = driver.current_url
print(url2)
time.sleep(3)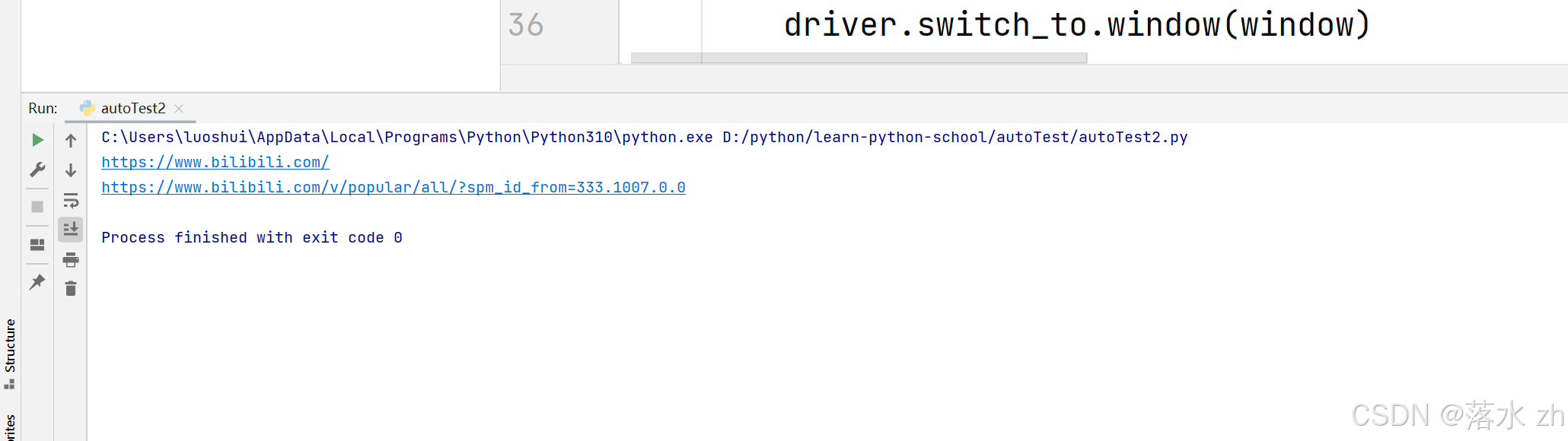
current_window_handle、window_handles和switch_to.window
在 Selenium WebDriver 中,current_window_handle、window_handles 和 switch_to.window() 是用于管理和切换浏览器窗口或标签页的关键方法。下面分别解释这三个概念:
current_window_handle:
- 这个属性返回当前活动窗口的句柄(handle)。每个浏览器窗口或标签页都有一个唯一的句柄字符串来标识它。当你启动 WebDriver 并加载初始页面时,这个句柄代表的是最开始的那个窗口或标签页。
window_handles:
- 这个属性返回一个列表,包含所有已打开窗口或标签页的句柄。每次你打开一个新的标签页或窗口,Selenium 都会自动将新的句柄添加到这个列表中。你可以使用此列表来确定哪些窗口是可用的,并选择要切换到哪个窗口。
switch_to.window(window_handle):
- 这个方法用于将 WebDriver 的焦点从当前窗口切换到指定的窗口或标签页。你需要传递你想要切换到的窗口的句柄作为参数。一旦切换成功,WebDriver 将与新窗口中的元素进行交互。
示例代码
这里有一个简单的例子,展示了如何使用这些方法来处理多个窗口:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
# 初始化 WebDriver (例如 Chrome)
driver = webdriver.Chrome()
# 打开初始页面
driver.get('http://example.com')
# 获取当前窗口句柄
main_window = driver.current_window_handle
# 假设我们点击了一个链接,这会在新标签页中打开另一个页面
# link_element.click() # 假设这是导致新标签页打开的操作
# 等待新窗口被打开
# 在实际应用中,应该使用显式等待,如 WebDriverWait 配合 expected_conditions
# 获取所有窗口句柄
all_windows = driver.window_handles
# 如果我们知道新窗口是最后一个打开的,我们可以直接访问列表的最后一个元素
if len(all_windows) > 1:
new_window = all_windows[-1]
driver.switch_to.window(new_window)
# 现在可以与新窗口进行交互了
# ...
# 切换回主窗口
driver.switch_to.window(main_window)
# 记得最后关闭浏览器
driver.quit()注意事项
- 使用
window_handles返回的列表时,请注意窗口打开和关闭的顺序,因为列表中的句柄是按照它们被创建的时间顺序排列的。- 当你关闭一个窗口后,确保再次获取
window_handles列表,以确保你操作的是最新的窗口信息。- 对于现代浏览器,打开新标签页通常不会立即出现在
window_handles列表中;因此,你可能需要使用适当的等待机制来确保新窗口已经准备好。
这里会有一个情况,我们打开了多个页面,万一我不想转到最新的页面,而是我想跳到第二个页面,或者第三个页面怎么办。这个放心,自动化测试一般不太会出现这样的情况。但是可以让大家了解一下:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 初始化 WebDriver (例如 Chrome)
driver = webdriver.Chrome()
# 打开初始页面
driver.get('http://example.com')
# 获取当前窗口句柄,这是最开始的那个窗口
main_window = driver.current_window_handle
# 假设我们点击了两个不同的链接,这会在新标签页中打开另外两个页面
# link_element_1.click() # 导致第一个新标签页打开的操作
# link_element_2.click() # 导致第二个新标签页打开的操作
# 等待新窗口被打开。这里应该使用显式等待以确保新窗口已经准备好。
WebDriverWait(driver, 10).until(EC.number_of_windows_to_be(3))
# 获取所有窗口句柄
all_windows = driver.window_handles
# 如果我们知道新的窗口是按照打开顺序排列的,我们可以直接访问列表中的相应元素
# 注意:列表索引是从0开始的,所以第二个打开的页面应该是 all_windows[1]
if len(all_windows) >= 3:
second_new_window = all_windows[1] # 第二个新打开的窗口
driver.switch_to.window(second_new_window)
# 现在可以与第二个新窗口进行交互了
print("Now operating on the second new window.")
# 切换回主窗口或其他窗口可以根据需要进行
# driver.switch_to.window(main_window)
# 记得最后关闭浏览器
# driver.quit()这里注意一下,如果点击了新链接,并没有打开新的标签页,就不需要进行句柄的切换
比如说我现在在百度搜索手抄报:
 现在我点击旁边的资讯:
现在我点击旁边的资讯:


你会发现并没有打开新的标签页,这样的话我们可以直接用原来的句柄,因为没有新的标签页就不会有新的句柄。
窗口大小的设置
窗口最大化 maximize_window()
python
import time
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from webdriver_manager.firefox import GeckoDriverManager
# 创建驱动对象
FirefoxIns = GeckoDriverManager().install()
driver = webdriver.Firefox(service=Service(FirefoxIns))
# 发送url
driver.get("https://www.bilibili.com/")
#driver.get("https://www.baidu.com/")
# 获取当前页面的url
# 获取当前窗口句柄(通常是第一个打开的页面)
main_window = driver.current_window_handle
url1 = driver.current_url
print(url1)
# 点击热门
hot_box = driver.find_element(By.CSS_SELECTOR,"#i_cecream > div.bili-feed4 > div.bili-header.large-header > div.bili-header__channel > div.channel-icons > a:nth-child(2) > div > svg")
hot_box.click()
time.sleep(3)
# 获取所有窗口句柄
all_windows = driver.window_handles
# 切换到最新的窗口(假设它是新打开的那个)
for window in all_windows:
if window != main_window:
driver.switch_to.window(window)
break
#窗口最大化
driver.maximize_window()
# 再次获取url
url2 = driver.current_url
print(url2)
time.sleep(3)窗口最小化 minimize_window()
python
import time
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from webdriver_manager.firefox import GeckoDriverManager
# 创建驱动对象
FirefoxIns = GeckoDriverManager().install()
driver = webdriver.Firefox(service=Service(FirefoxIns))
# 发送url
driver.get("https://www.bilibili.com/")
#driver.get("https://www.baidu.com/")
# 获取当前页面的url
# 获取当前窗口句柄(通常是第一个打开的页面)
main_window = driver.current_window_handle
url1 = driver.current_url
print(url1)
# 点击热门
hot_box = driver.find_element(By.CSS_SELECTOR,"#i_cecream > div.bili-feed4 > div.bili-header.large-header > div.bili-header__channel > div.channel-icons > a:nth-child(2) > div > svg")
hot_box.click()
time.sleep(3)
# 获取所有窗口句柄
all_windows = driver.window_handles
# 切换到最新的窗口(假设它是新打开的那个)
for window in all_windows:
if window != main_window:
driver.switch_to.window(window)
break
#窗口最大化
driver.maximize_window()
#窗口最小化
driver.minimize_window()指定窗口全屏 fullscreen_window()
python
import time
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from webdriver_manager.firefox import GeckoDriverManager
# 创建驱动对象
FirefoxIns = GeckoDriverManager().install()
driver = webdriver.Firefox(service=Service(FirefoxIns))
# 发送url
driver.get("https://www.bilibili.com/")
#driver.get("https://www.baidu.com/")
# 获取当前页面的url
# 获取当前窗口句柄(通常是第一个打开的页面)
main_window = driver.current_window_handle
url1 = driver.current_url
print(url1)
# 点击热门
hot_box = driver.find_element(By.CSS_SELECTOR,"#i_cecream > div.bili-feed4 > div.bili-header.large-header > div.bili-header__channel > div.channel-icons > a:nth-child(2) > div > svg")
hot_box.click()
time.sleep(3)
# 获取所有窗口句柄
all_windows = driver.window_handles
# 切换到最新的窗口(假设它是新打开的那个)
for window in all_windows:
if window != main_window:
driver.switch_to.window(window)
break
#窗口最大化
driver.maximize_window()
#窗口最小化
driver.minimize_window()
#窗口全屏
driver.fullscreen_window()
# 再次获取url
url2 = driver.current_url
print(url2)
time.sleep(3)手动设置窗口大小 set_window_size()
python
import time
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from webdriver_manager.firefox import GeckoDriverManager
# 创建驱动对象
FirefoxIns = GeckoDriverManager().install()
driver = webdriver.Firefox(service=Service(FirefoxIns))
# 发送url
driver.get("https://www.bilibili.com/")
#driver.get("https://www.baidu.com/")
# 获取当前页面的url
# 获取当前窗口句柄(通常是第一个打开的页面)
main_window = driver.current_window_handle
url1 = driver.current_url
print(url1)
# 点击热门
hot_box = driver.find_element(By.CSS_SELECTOR,"#i_cecream > div.bili-feed4 > div.bili-header.large-header > div.bili-header__channel > div.channel-icons > a:nth-child(2) > div > svg")
hot_box.click()
time.sleep(3)
# 获取所有窗口句柄
all_windows = driver.window_handles
# 切换到最新的窗口(假设它是新打开的那个)
for window in all_windows:
if window != main_window:
driver.switch_to.window(window)
break
#窗口最大化
driver.maximize_window()屏幕截图
python
python
深色版本
import os
import time
from selenium import webdriver
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from webdriver_manager.firefox import GeckoDriverManager
# 创建驱动对象
# 使用 webdriver_manager 自动管理 Firefox 的 WebDriver (GeckoDriver),确保使用的是与浏览器版本匹配的驱动。
FirefoxIns = GeckoDriverManager().install()
driver = webdriver.Firefox(service=Service(FirefoxIns))
# 发送URL请求到指定网页
# 这里我们访问哔哩哔哩网站作为示例。你可以根据需要更改为其他网址。
driver.get("https://www.bilibili.com/")
# driver.get("https://www.baidu.com/") # 如果需要访问百度,取消此行注释并注释掉上面一行
# 创建保存截图的目录(如果不存在)
# 确保目标目录存在,以便可以将截图保存到该位置。
# 如果目录不存在,则创建它;如果已经存在,则不会有任何操作。
screenshot_dir = '../images'
if not os.path.exists(screenshot_dir):
os.makedirs(screenshot_dir)
# 捕捉屏幕截图并保存到指定路径
# 将当前页面的截图保存为文件,文件名为 'image.png',位于 '../images/' 目录下。
# 注意:确保 '../images/' 目录存在,否则会抛出异常。
driver.save_screenshot('../images/image.png')
我们可以以时间作为文件名,这样可以保证每次我们创建的文件名不会重复:
python
import datetime
import os
import time
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from webdriver_manager.firefox import GeckoDriverManager
# 创建驱动对象
FirefoxIns = GeckoDriverManager().install()
driver = webdriver.Firefox(service=Service(FirefoxIns))
# 发送url
driver.get("https://www.bilibili.com/")
#driver.get("https://www.baidu.com/")
screenshot_dir = '../images'
if not os.path.exists(screenshot_dir):
os.makedirs(screenshot_dir)
filename = "auto"+datetime.datetime.now().strftime('%Y-%m-%d-%H%M%S')+'.png'
driver.save_screenshot('../images/'+filename)