背景
突然就想起了一句话,"有的路,必须得自己走",就是说,父母或者长辈有时候苦口婆心地劝说年轻一辈走自己认为对的路,但是呢,年轻人经常很叛逆,不愿意走别人指的路,虽然,若干年后,他发现父母长辈指的路是对的。
我今天这个bug吧,说起来,好早我就知道了,比如做一个后台系统,分页查询,很常见吧。
shell
select * from xxx where condition1 = '1' limit ?,?其中的limit部分,就是分页参数,咱们这里先不管深分页的性能问题,你就说,功能有没有实现吧?
结果,提测后,测试妹子就来找你了:怎么一条数据,在第二页出现了,翻到下一页,又出现了啊?
这时候你就开始去到处查,网上告诉你,要加order by,才能保证分页查询出来的数据是稳定的,不会到处乱跳,一会出现在第一页,一会第二页。
于是改成这样:
shell
// 假设要排序的列名为x
select * from xxx where condition1 = '1' order by x limit ?,?这样一改,果然就好了。
这么基础的问题,我n年前遇到了,稍微像上面改了下就好了。没想到,这次又遇到了。
问题描述
数仓同步
我们有个系统,刚上线,业务同事直接在线上测试(测试环境呢,他们觉得不是里面数据不够真实,感觉就没咋仔细测)。测着测着,跟我说,有个地方的数据好像不对。
这个系统,简单介绍下,极度依赖上游系统的数据,上游系统每天产生些什么数据呢,主要是各种各样的指标,就像各个公司的财报那样。这些公司的指标数据,存储在他们上游系统的数据库里。
数据怎么给我们呢?接口?那是不可能,因为系统很老,是采购的,以前的系统根本就没有开放数据的意识(现在很多采购的新系统也提供open-api了)。所以,这种系统的数据一般是通过数仓同步过来。数仓就是数据仓库,我理解就是可以对接各种数据库,mysql、oracle、sql server、pg,想要啥数据,就给数仓同事提需求:我要1.1.1.1:3306中test这个db中xxx表的数据(或者提供源数据查询的sql也行),每天定时给我同步到2.2.2.2:5432的xxx这个数据库中的xxx表。
像这种大量的数据交换,感觉用数仓也还是不错,反正不用我维护,对吧。个人来说,其实还是喜欢接口,接口可以记日志,数仓这种,经常就是先把你表里数据truncate,然后批量写入。这样经常就是,你程序出错了,开始查,查到最后发现数据有问题,然后在那想,数据怎么就错了呢,最后就发现是数仓出错了:没同步,或者同步出错,或是上游数据出错。
不像通过接口拿数据,我拿到数据后可以检查数据有没有异常,有异常可以报错,可以告警,记日志。
反正吧,我不是很喜欢数仓同步,但我这边没办法,人家没接口。
问题表
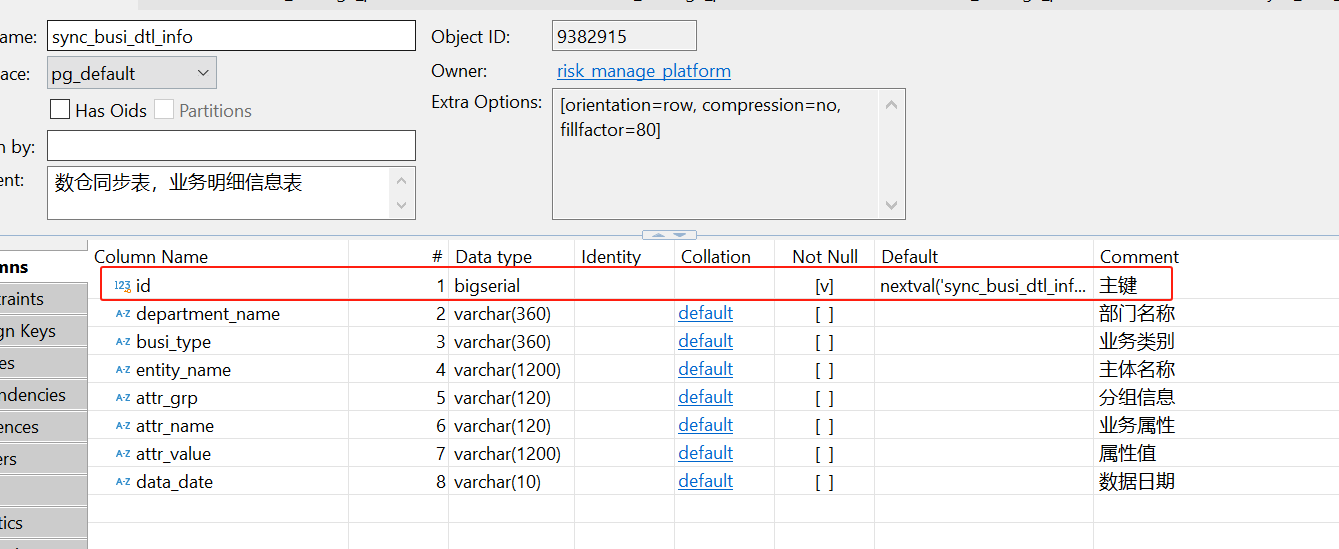
我们用来接收数仓数据的表,一开始长这样(表名:sync_busi_dtl_info,业务明细表):
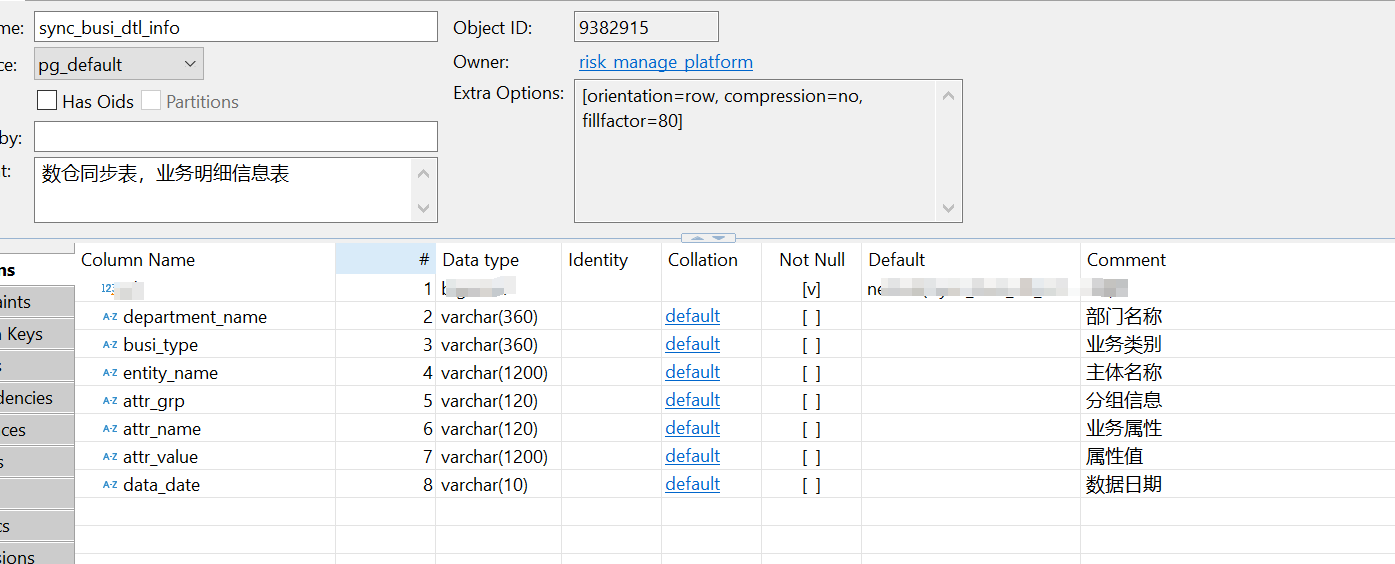
你仔细看,这个表其实是没有主键的,全是业务列,每次数仓会先把这个表truncate,然后把数据批量写进来,其中,data_date就是数据的日期。
写完后,会再写一个标记表t_etl_status,主要就是告诉我,比如下面这条,20241115这一天的数据写好了(状态0表示成功),完成写入的时间是2024-11-15 07:00:20.868。

我们程序这边呢,会每天去定时做一次数据转移。主要目的就是,把上面那个sync_busi_dtl_info表的数据,转移到另一个表,这里暂且叫target表。
为啥要转移呢,因为这个sync_busi_dtl_info表,就是个临时中转站,像个队列一样,数仓这个生产者,每天写数据到这里,然后写标记表(注意,这里只会有一天的数据);我们程序,就是个消费者,读标记表,把中转站里的数据,转移到target表(target表,随着时间推移,里面就会有每一天的数据)。
我们程序的业务逻辑,只会去操作target表,在target表上做curd。
这边可以看下target表的字段,基本差不多,主要增加的字段是自增主键和etl_time(为了标识数据的时间):

现象
今天呢,都快下班了,业务同事说,感觉某某地方数据不对。然后我就去查,找运维看日志、看数据库数据(运维那有台堡垒机,windows,装了数据库图形客户端,真的感恩)。
然后就查得很奇怪,有几条数据,在数仓原始表sync_busi_dtl_info中是存在的,但是,在target表中,就是不存在。
我以为是这个从原始表转移到target表的job(用的xxljob)出现了问题,但是仔细看,感觉没问题。
我查看xxljob的执行日志,日志里清清楚楚记录,说转移了282602条数据。
我又查了原始表中的数据条数:
shell
select count(*) from sync_busi_dtl_info查出来就是282602条。
我又查了target表中的数据条数:
shell
select count(*) from target where data_date = 20240910查出来也是282602条。
但是,里面就是有几条数据不对。
下面这条sql能查到(数仓原始表):
shell
select * from sync_busi_dtl_info where condition = 'xxx'下面这条sql就查不到:
shell
select * from target where condition = 'xxx'排查
我们代码大概长这样:
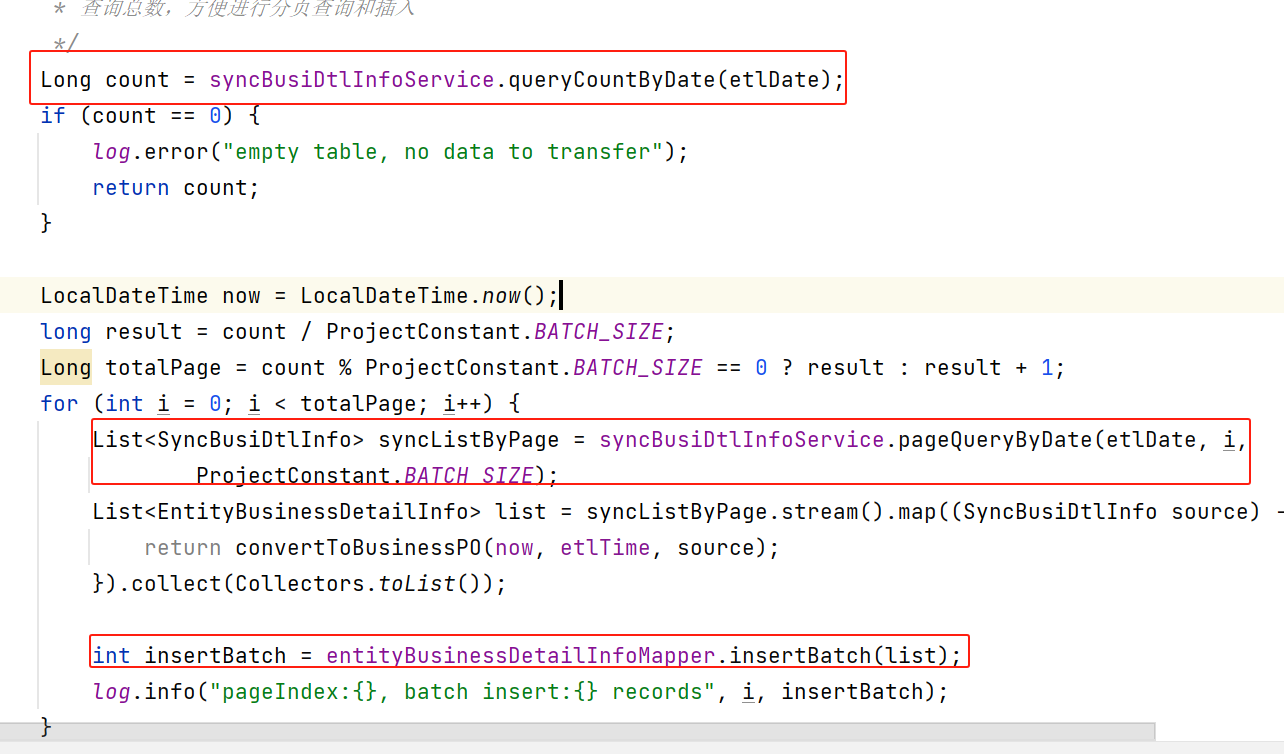
主要就是先查询下原始表的总数,比如这里是28w条左右,我是按1000条进行批量插入,所以分页会有280页。
每一页的查询逻辑如下:
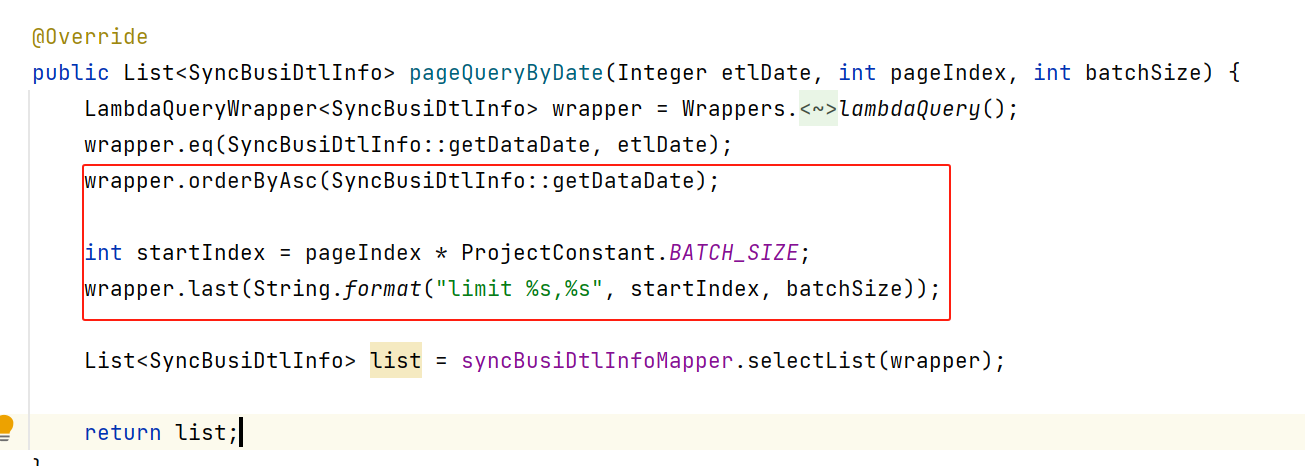
就是普通的limit offset,size。没考虑深分页的性能问题,毕竟这个表数据量也不是很大。
这里面也加了个order by,只是order by的列是data_date,为啥当初用这个列,实在是不知道用哪个列了,可以再看看下面的表结构。
下面说说排查过程。
当我确认是数据有问题,两边不一致的时候,也很困惑,先是查了服务的日志,我是打印了sql的,真的就没发现有insert那几条记录。
所以我就感觉,那难道是查询原始表的时候,没查询到这个数据吗?
我就在运维那个堡垒机的数据库客户端中,试了试,看看这个数据到底分布在哪一页。
我先搞了个limit 0,100000,发现,查到了,意思是,这个数据就分布在第0条和第10w条之间。
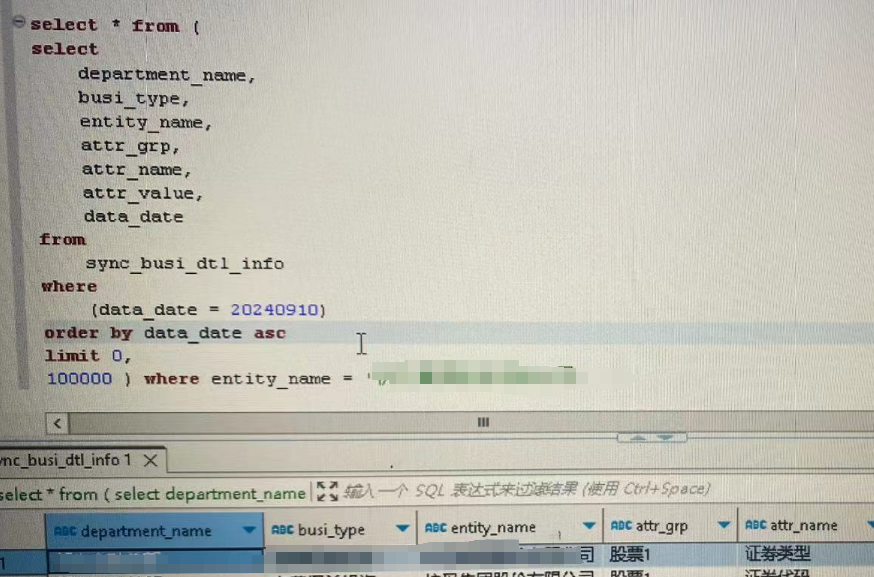
下面开始用上了我的二分法:
下图说明不在5w到10w之间,那就在0-5w。
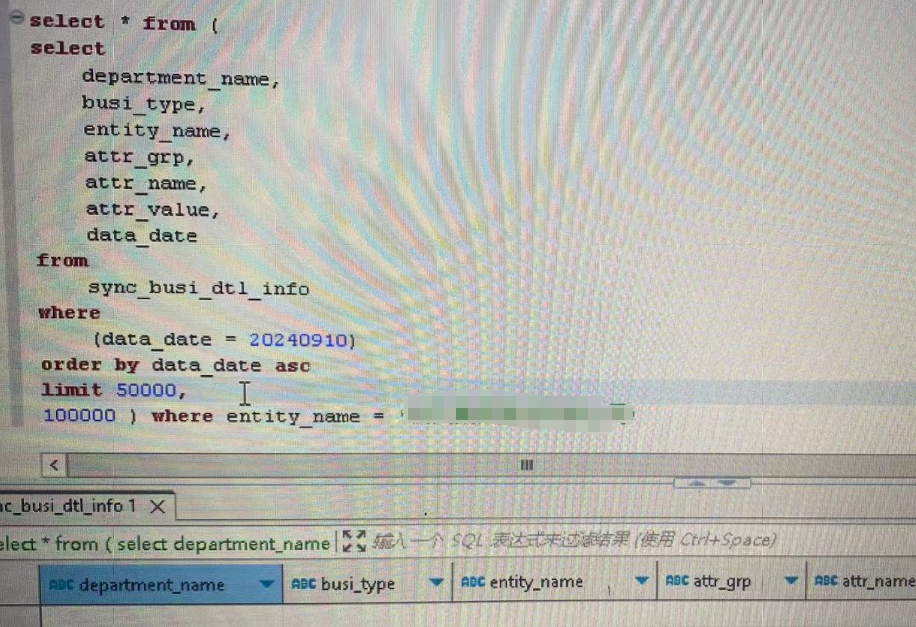
确认在0-5w:
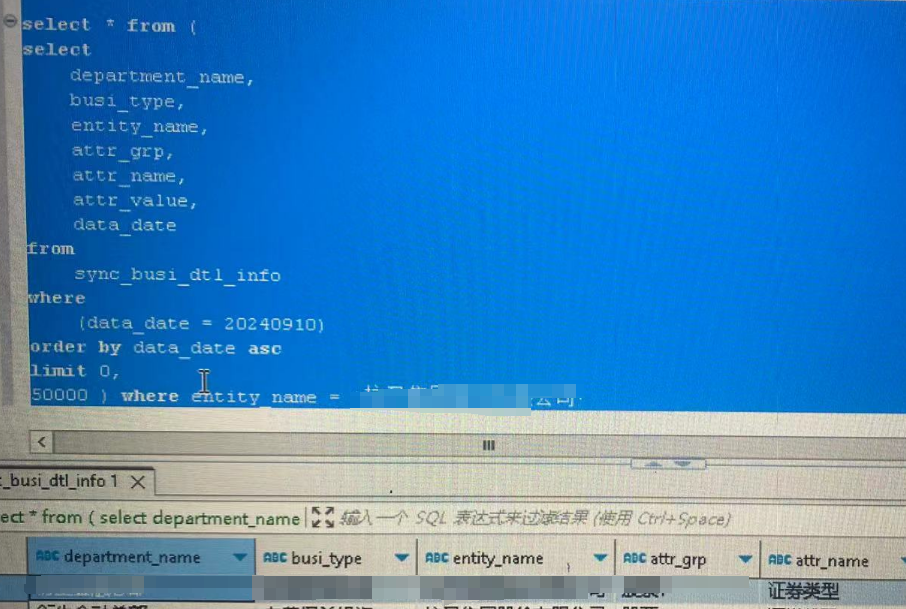
确认在0-2w5:
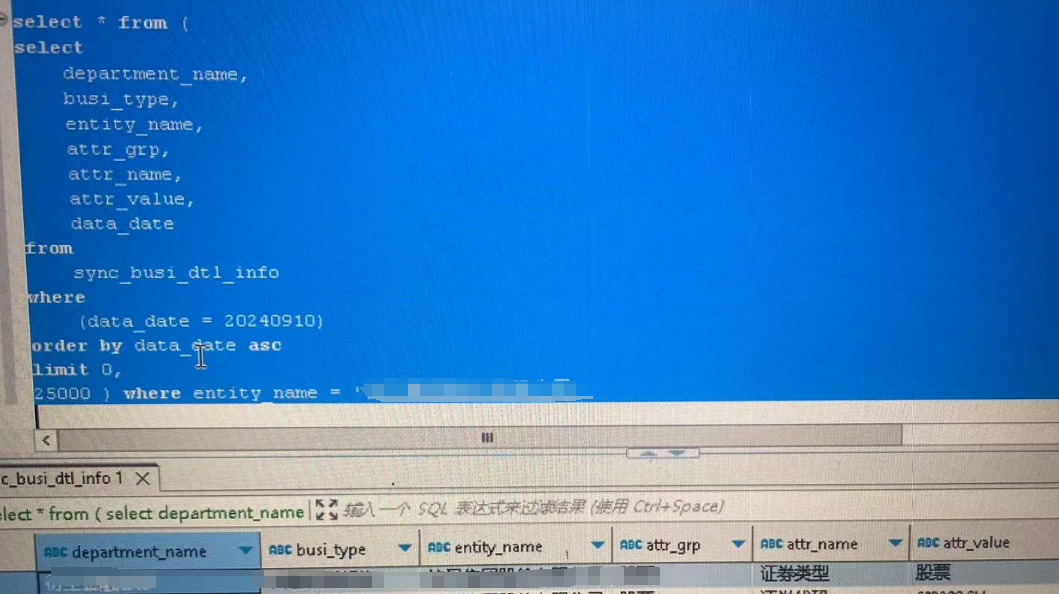
下图确认不在0-1.25w:
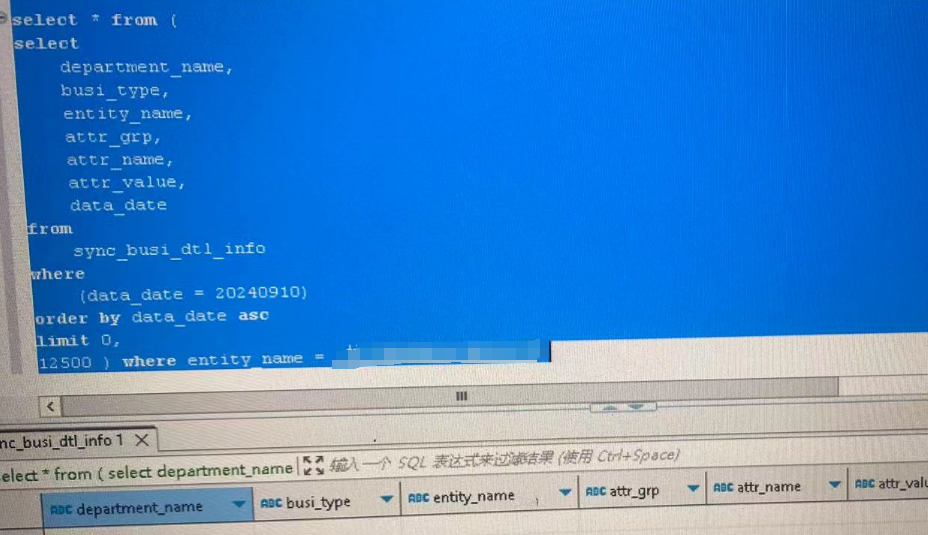
行,那肯定在1.25w到2.5w吧,结果,下图真是见鬼了,这个区间竟然没查到:

尝试id排序
到这里,基本可以认为是排序的列有问题了,虽然我排了序,但是表里所有行的这一列都一样,难道是这样,导致了排序就和没排序一样?这个我就没法验证了。
不知不觉就查了一个多小时,运维同事都吃完外卖了,我也有点饿了。
试试id排序吧。
你可能要问,id哪里来的?
最开始的时候,确实是没有id列,后来我在开发环境就感觉没有主键,导致我数据库导入导出数据的时候,出现各种问题,后来就在数仓表加了一个id,自增的,数仓每次批量写入的时候,会默认生成自增id。
但是,这个id,我并没有想着要拿来做什么具体作用,也就没想着,要拿它来做分页查询时候的排序字段,直到遇到了今天这个问题。
看下图,改成根据id排序后,我又用我的二分法,定位这几条记录,可以看到,定位到了286950到287000这个区间(中间仅间隔50条记录)
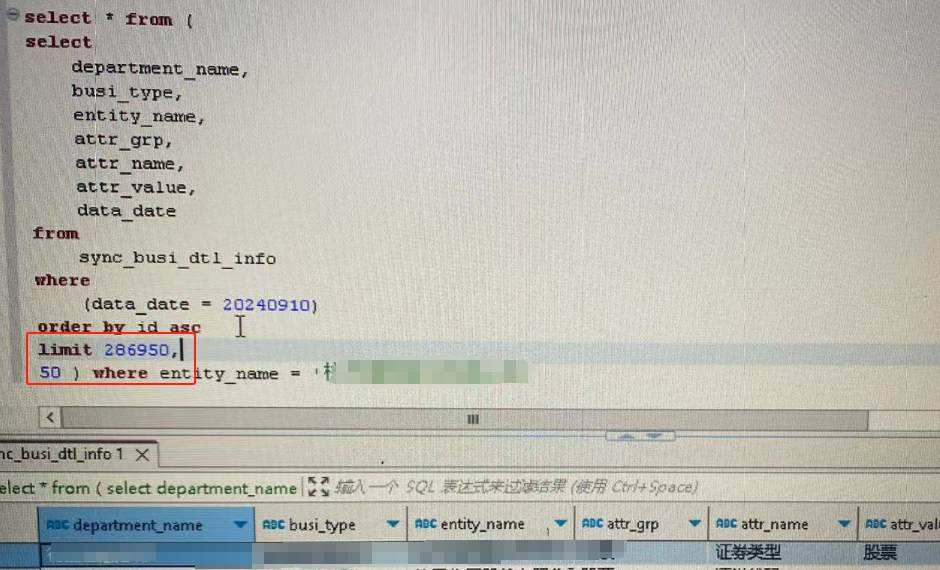
可以看出来,没有再出现上面有data_date那个字段排序时,出现的尴尬境地了。
由于data_date的值都一样,在数据库术语中,这一列被认为是基数低。
我简单问了下ai:

总的来说,我感觉按主键排序还是挺合适的,毕竟,主键不会重复。
总结
有的坑,一定得自己踩,人教人,教不会,事教人,真管用。