
背景
网关服务已成功发布,然而新创建的Pod却始终未能成功启动。在Pod的事件(Event)中,明确显示健康检查失败。但令人困惑的是,仔细查看启动日志,却未发现任何异常情况,具体情况如下图所示。 
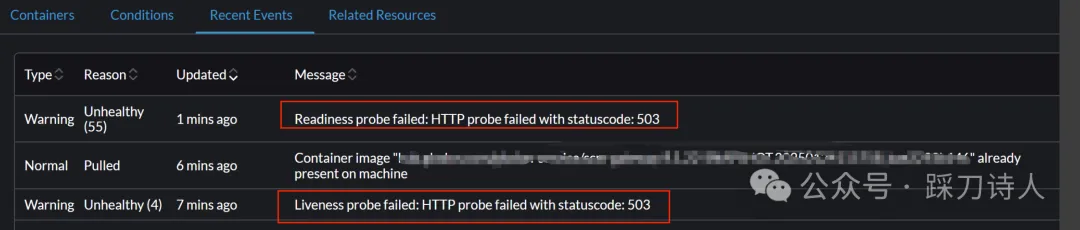
排查
既然当前问题表现为健康检查失败,那就有必要深入排查究竟是哪些关键部分不可用,进而导致了这一结果。在开展排查工作前,我们先来全面了解下健康检查的相关概念,为后续分析打下基础。
服务部署在k8s中,k8s可以对容器执行定期的诊断,要执行诊断,kubelet 调用由容器实现的 Handler (处理程序)。有三种类型的处理程序:
-
ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
-
TCPSocketAction:对容器的 IP 地址上的指定端口执行 TCP 检查。如果端口打开,则诊断被认为是成功的。
-
HTTPGetAction:对容器的 IP 地址上指定端口和路径执行 HTTP Get 请求。如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的。
每次探测都将获得以下三种结果之一:
-
Success(成功):容器通过了诊断。
-
Failure(失败):容器未通过诊断。
-
Unknown(未知):诊断失败,因此不会采取任何行动。
针对运行中的容器,kubelet 可以选择是否执行以下三种探针,以及如何针对探测结果作出反应:
-
livenessProbe:指示容器是否正在运行。如果存活态探测失败,则 kubelet 会杀死容器, 并且容器将根据其重启策略决定未来。如果容器不提供存活探针, 则默认状态为 Success。
-
readinessProbe:指示容器是否准备好为请求提供服务。如果就绪态探测失败, 端点控制器将从与 Pod 匹配的所有服务的端点列表中删除该 Pod 的 IP 地址。初始延迟之前的就绪态的状态值默认为 Failure。如果容器不提供就绪态探针,则默认状态为 Success。
-
startupProbe: 指示容器中的应用是否已经启动。如果提供了启动探针,则所有其他探针都会被 禁用,直到此探针成功为止。如果启动探测失败,kubelet 将杀死容器,而容器依其 重启策略进行重启。如果容器没有提供启动探测,则默认状态为 Success。
以上探针介绍内容来源于https://kubernetes.io/zh/docs/concepts/workloads/pods/pod-lifecycle/#container-probes
从K8s的Event中,仅能获取到健康检查的HTTP状态码为503,并没有输出更详细的内容。那么,手动访问这个地址,是否能够获取到更多关键信息呢?

趁着Pod 刚起来(Running) 还没有**被重启(Termiting)**的时候快速进入shell执行curl -i http://127.0.0.1:8080/actuator/health,看能否捕捉到一些有价值信息。

尝试手动访问后,问题并未得到解决。查看gateway的日志,竟无任何输出。期间,我将spring的日志级别调至debug,满心期待能挖掘出有价值的线索,可依旧一无所获。或许是我技术水平有限,未能从这些信息中提炼出关键内容。
难道这就是springboot的设计?健康检查失败了也不明示,让我意会?我xxxxxxxxxxx,骂完还得继续解决问题啊,去看看官网的使用文档吧,看能不能行大运,最终还真在官网找到一个相关配置
management.endpoint.health.show-details: always可以展示健康检查的详细信息,现在curl -i http://127.0.0.1:8080/actuator/health的结果明显就丰富多了

{
"status": "DOWN",
"components": {
"clientConfigServer": {
"status": "UP",
"details": {
"propertySources": ["bootstrapProperties-configClient", "bootstrapProperties-classpath:/repo/scm-gateway/scm-gateway-common.yml"]
}
},
"diskSpace": {
"status": "UP",
"details": {
"total": 598725427200,
"free": 199748194304,
"threshold": 10485760,
"path": "/usr/app/bin/.",
"exists": true
}
},
"livenessState": {
"status": "UP"
},
"ping": {
"status": "UP"
},
"rabbit": {
"status": "DOWN",
"details": {
"error": "org.springframework.amqp.AmqpConnectException: java.net.ConnectException: Connection refused"
}
},
"readinessState": {
"status": "UP"
},
"redis": {
"status": "UP",
"details": {
"version": "6.0.9"
}
},
"refreshScope": {
"status": "UP"
}
},
"groups": ["liveness", "readiness"]
}可以看到rabbit的status是DOWN,rabbitmq挂了?
实在蹊跷!网关按常理根本无需RabbitMQ ,我们也从未维护过任何RabbitMQ的配置信息,怎么会突然开始针对它进行健康检查呢?肯定是有谁引入了RabbitMQ的相关依赖,却又没做好配置工作。
查看提交历史后,并没有发现直接引入RabbitMQ相关依赖的记录,不过新增了一个xxx-interface依赖。难不成是这个新引入的依赖,在传递过程中把RabbitMQ相关依赖也带进来了?
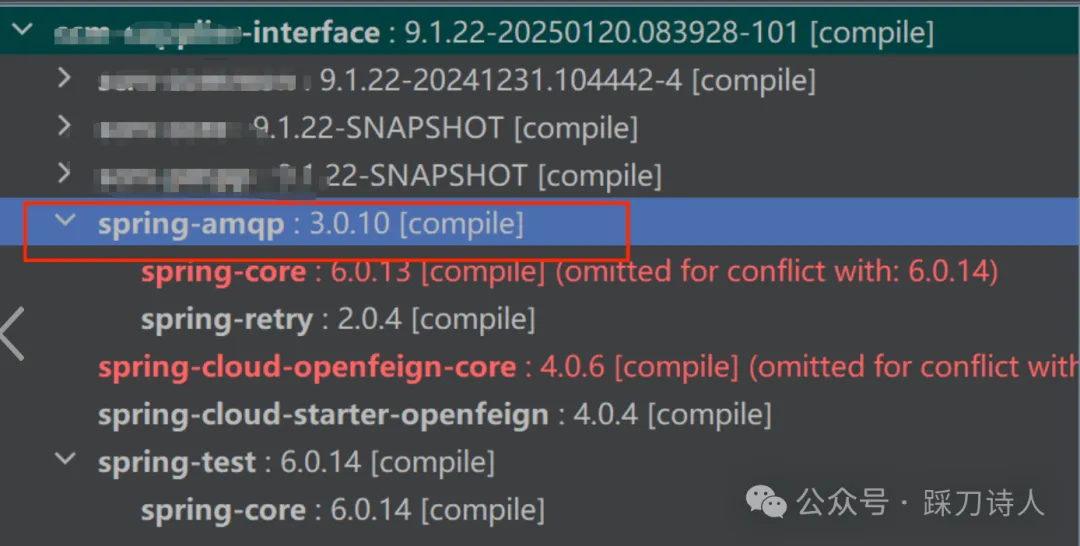
果然是xxx-interface传递依赖了spring-amqp,从而触发了RabbitHealthContributorAutoConfiguration的自动装配。
最终解决
1.重新审视网关依赖xxx-interface的合理性,本次的解决方案是直接去除xxx-interface的依赖;
2.使用maven的依赖排除能力去除spring-amqp:
3.禁用rabbitmq的健康检查
management:
health:
rabbit:
enabled: false推荐阅读
