数据集
TweepFake
摘要:深度伪造(deepfakes)、合成或篡改媒体的威胁正变得越来越令人担忧,尤其是对于那些已经被指控操纵公众舆论的社交媒体平台而言。即使是最简单的文本生成技术(例如查找和替换方法)也能欺骗人类,正如2017年的"网络中立性"丑闻所证明的那样。与此同时,从基于RNN的方法到GPT-2语言模型,更强大的生成模型已经发布。最先进的语言模型,特别是基于Transformer的模型,可以在接收到任意输入后生成合成文本。因此,开发能够帮助检测媒体真实性的工具至关重要。为了支持这一领域的研究,我们收集了一个真实的深度伪造推文数据集。这里的"真实"指的是每条深度伪造推文都确实发布在Twitter上。我们总共收集了23个机器人账号的推文,这些机器人模仿了17个人类账号。 这些机器人基于各种生成技术,包括马尔可夫链、RNN、RNN+马尔可夫、LSTM和GPT-2。**我们还从被机器人模仿的人类账号中随机选取了推文,以确保数据集的整体平衡性,最终数据集包含25,836条推文(一半是人类发布的,一半是机器人生成的)。**该数据集已在Kaggle上公开。为了在提出的数据集上为检测技术建立坚实的基线,我们测试了13种基于各种最先进方法的检测方法。使用这13种检测方法报告的基线检测结果证实,基于Transformer架构(如GPT-2)的最新、更复杂的生成方法能够生成高质量的短文本,难以被检测出来。
MAGE
摘要:大型语言模型(LLMs)已经实现了人类水平的文本生成能力,这凸显了有效检测深度伪造文本的重要性,以减轻诸如虚假新闻传播和抄袭等风险。现有的研究往往局限于在特定领域或特定语言模型上评估检测方法。然而,在实际场景中,检测器需要面对来自不同领域或不同LLMs生成的文本,而无需知道它们的来源。为此,我们通过收集来自多样化人类写作的文本以及由不同LLMs生成的深度伪造文本,构建了一个全面的测试平台。在主流检测方法上的实证结果表明,在一个广泛覆盖的测试平台中检测深度伪造文本存在困难,特别是在分布外(out-of-distribution)场景下。这些困难与两种文本来源之间逐渐缩小的语言差异相吻合。尽管面临挑战,表现最佳的检测器能够识别出由新LLM生成的84.12%的域外文本,这表明了在实际应用场景中的可行性。
HC3
摘要:ChatGPT的推出在学术界和工业界引起了广泛关注。ChatGPT能够有效地回应各种人类问题,提供流畅且全面的答案,在安全性和实用性方面显著超越了以往的公开聊天机器人。一方面,人们好奇ChatGPT如何能够实现如此强大的能力,以及它与人类专家之间的差距有多大。另一方面,人们开始担心像ChatGPT这样的大型语言模型(LLMs)可能对社会产生的潜在负面影响,例如虚假新闻、抄袭以及社会安全问题。在本研究中,**我们收集了来自人类专家和ChatGPT的数万条对比回答,问题涵盖开放领域、金融、医疗、法律和心理等领域。**我们将收集到的数据集称为"人类与ChatGPT对比语料库"(HC3)。基于HC3数据集,我们研究了ChatGPT回答的特点、与人类专家的差异和差距,以及LLMs未来的发展方向。我们对ChatGPT生成的内容与人类生成的内容进行了全面的人工评估和语言学分析,揭示了许多有趣的结果。随后,我们进行了广泛的实验,探讨如何有效检测某段文本是由ChatGPT还是人类生成的。我们构建了三种不同的检测系统,探索了影响其有效性的几个关键因素,并在不同场景下对其进行了评估。
RAID
摘要:最近,有许多共享任务专注于检测来自大型语言模型(LLMs)生成的文本。然而,这些共享任务往往要么局限于单一领域的文本,要么涉及多个领域的文本,其中一些领域可能在测试时并未出现。在此次共享任务中,**我们利用新发布的RAID基准,旨在探讨模型是否能够检测来自大量但固定的领域和LLMs生成的文本,所有这些领域和模型在训练期间都已见过。**在三个月的任务期间,共有9个团队尝试了该任务,提交了23个检测器。我们发现,多个参与者能够在RAID基准上对机器生成的文本获得超过99%的准确率,同时保持5%的误报率------这表明检测器能够同时稳健地检测来自多个领域和模型的文本。我们讨论了这一结果的潜在解释,并为未来的研究提供了方向。

RAID榜单效果最好的两个模型:
【1】Leidos
-
利用Transformer架构(特别是DistilRoBERTa-Base)来构建检测模型。
-
在训练过程中,作者引入了四种模型变体(二分类和多分类,带权重和不带权重)。二分类模型(Binary Classifiers)任务目标判断文本是人类撰写的还是机器生成的;多分类模型(Multi-class Classifiers)不仅判断文本是人类撰写还是机器生成,还能进一步区分机器生成文本的具体生成器模型(例如,GPT-3、Cohere等);权重平衡策略处理数据集中的类别不平衡问题。这种策略通过调整不同类别的权重,使得模型在训练过程中更加关注少数类,从而提高检测性能,权重平衡策略公式如下:
\(w_i = \frac{N}{C \times n_i}\)
其中,N 是数据集中的总样本数,C 是总类别数,\(n_i\)是第 i 个类别的样本数。
【2】Pangram
- 使用mirror prompt生成 "机器生成文本" 的训练数据。
- 在合成数据生成过程中,论文使用了多种现代 LLM(如 GPT-3.5、GPT-4、Claude、LLaMA、Mistral 等)来生成合成样本。此外,对于非英语数据,使用 DeepL 翻译 API 将提示翻译为目标语言,从而支持多语言的合成数据生成。
- 数据预处理和数据增强。包括去除零宽空格、转换为小写、合并连续空格、移除 LLM 特定的"头部"(如"Sure! Here is a...")等。随机将部分英语训练集翻译为其他语言,以及随机掩盖部分输入标记(类似于计算机视觉中的 CutOut 技术)。
- 论文使用了 Mistral NeMo 架构(约 120 亿参数),并结合了可训练的 LoRA 适配器和未训练的线性分类头。此外,论文还提出了权重交叉熵损失函数,通过为假阳性赋予更高权重来优化模型的检测性能。
- 主动学习策略。通过主动挖掘高错误率的样本,并将其与对应的人类样本一起重新训练模型。
ps:利用transformers怎么进行分类任务?
【1】AutoModelForSequenceClassification
-
有prompt
-
无prompt
【2】AutoModelForCausalLM
- base
- instr
GenImage
摘要:生成模型在生成逼真图像方面的非凡能力加剧了人们对虚假信息传播的担忧,从而催生了对能够区分AI生成的假图像和真实图像的检测器的需求。然而,缺乏包含最先进图像生成器生成图像的大型数据集,成为开发此类检测器的一大障碍。在本文中,我们介绍了GenImage数据集,该数据集具有以下优势:1)海量图像,包含超过一百万对AI生成的假图像和收集的真实图像。2)丰富的图像内容,涵盖广泛的图像类别。3)采用最先进的生成器,利用先进的扩散模型和生成对抗网络(GANs)合成图像。上述优势使得在GenImage上训练的检测器能够接受全面评估,并展现出对多样化图像的强大适用性。我们对数据集进行了全面分析,并提出了两项任务来评估检测方法在模拟现实场景中的表现。跨生成器图像分类任务衡量了在一个生成器上训练的检测器在其他生成器上的测试性能。退化图像分类任务评估了检测器在处理低分辨率、模糊和压缩等退化图像时的能力。借助GenImage数据集,研究人员可以有效地加速开发并评估优于现有方法的AI生成图像检测器。
ArtworksImage
期刊会议:CCS 2024
摘要:生成式AI图像的出现彻底颠覆了艺术界。将AI生成的图像与人类艺术区分开来是一个具有挑战性的问题,其影响随着时间的推移而日益增长。未能解决这一问题会让不良行为者有机可乘,欺骗那些为人类艺术支付高额费用的个人,以及那些明确禁止使用AI图像的公司。对于内容所有者确立版权,以及对于希望筛选训练数据以避免潜在模型崩溃的模型训练者来说,这也是至关重要的。
区分人类艺术与AI图像有几种不同的方法,包括通过监督学习训练的分类器、针对扩散模型的研究工具,以及专业艺术家利用他们对艺术技巧的知识进行识别。在本文中,我们试图了解这些方法在面对当今现代生成模型时,在良性和对抗性环境下的表现如何。我们收集了跨越7种风格的真实人类艺术作品,从5种生成模型中生成匹配的图像,并应用了8种检测器(5种自动化检测器和3种不同的人类群体,包括180名众包工作者、3800多名专业艺术家和13名在检测AI方面经验丰富的专家艺术家)。Hive和专家艺术家都表现得非常出色,但会以不同的方式犯错(Hive在对抗性扰动面前较弱,而专家艺术家则会产生较高的误报率)。我们认为这些弱点将持续存在,并认为人类和自动化检测器的结合能够提供最佳准确性和鲁棒性的组合。
Fake2M
摘要:照片是人类记录日常生活经历的一种方式,通常被视为可信的信息来源。然而,随着人工智能(AI)技术的进步,人们越来越担心可能会产生虚假照片,这些照片可能会造成混淆并削弱对照片的信任。本研究旨在全面评估用于区分最先进的AI生成视觉内容的代理。我们的研究使用新收集的大规模假图像数据集Fake2M,对人类能力和尖端的假图像检测AI算法进行了基准测试。在我们的人类感知评估(称为HPBench)中,我们发现人类在区分真实照片和AI生成的照片方面存在显著困难,误分类率达到38.7%。与此同时,我们进行了AI生成图像检测的模型能力评估(称为MPBench),在人类评估相同的设置下,MPBench中表现最佳的模型的失败率为13%。我们希望我们的研究能够提高人们对AI生成图像潜在风险的认识,并促进进一步的研究,以防止虚假信息的传播。
WildFake
摘要:生成模型的非凡能力使得生成的图像质量如此之高,以至于人类无法区分人工智能(AI)生成的图像与现实生活中的照片。生成技术的发展开辟了新的机遇,但同时也对隐私、真实性和安全带来了潜在风险。因此,检测AI生成图像的任务对于防止非法活动至关重要。为了评估AI生成图像检测的泛化能力和鲁棒性,我们提出了一个大规模的数据集,称为WildFake,该数据集包含最先进的生成器、多样化的对象类别和现实世界的应用。WildFake数据集具有以下优势:1)丰富的野生收集内容:WildFake从开源社区收集假图像,通过广泛的图像类别和图像风格丰富了其多样性。2)层次结构:WildFake包含由不同类型的生成器合成的假图像,从生成对抗网络(GANs)、扩散模型到其他生成模型。这些关键优势增强了在WildFake上训练的检测器的泛化能力和鲁棒性,从而证明了WildFake在现实场景中对AI生成检测器的显著相关性和有效性。此外,我们广泛的评估实验旨在深入洞察不同级别生成模型的能力,这是WildFake独特层次结构所带来的独特优势。
项目
WRITER
BrandWell
GPTZero
困惑度(perplexity)反映模型预测下一个词时的平均不确定性。数值越低,表示模型预测越准确,其基本思想是:给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好。PPL计算公式如下:
\(\text{Perplexity} = \exp\left(-\frac{1}{N} \sum_{i=1}^{N} \log P(w_i | w_1, w_2, \dots, w_{i-1})\right)\)
由公式可知,句子概率越大,语言模型越好,迷惑度越小。
但是,有研究发现,用预训练的语言模型计算文本PPL的话,人类的文本PPL很多时候反而挺高的,模型生成的文本比较低。由此诞生了一些其他基于PPL的想法,就比如用不同级别的PPL构建了一组特征,比如整条文本的PPL,所有句子PPL的最大/小值、均值、标准差等等,也同样训练一个逻辑回归模型。
pangram
faceswap
人脸交换。
论文
GLTR: Statistical Detection and Visualization of Generated Text
- 发表时间:2019
- 期刊会议:ACL
- 论文单位:Harvard SEAS, IBM Research, MIT-IBM Watson AI lab
- 论文作者:Sebastian Gehrmann, Hendrik Strobelt, Alexander M. Rush
- 论文链接
- 开源代码
- 线上demo
GLTR的核心思想是,给定一段话,按照从左到右的文本生成顺序,用GPT-2 117M模型或BERT(用这个位置的左边和右边各30个单词作为输入来预测)依次在每个词的位置上预测整个词表的生成概率分布 (一个长度为词表大小的数组,每个元素是预测概率/分数)。然后找到这个词的概率在整个分布中的排名。

在最有可能的单词中排名的单词以绿色(top 10)、黄色(top 100)、红色(top 1000)突出显示,其余单词以紫色突出显示。因此,我们可以直接直观地了解每个单词在模型下的可能性。论文指出,在人类写的真实文本中,红色和紫色单词(即不太可能的预测)的比例会显著增加。

a、b和c图使用GPT-2 1.5B生成的文本检测结果,d和e图是两个人类书写的样本。其中,c图中的第一个直方图显示了文本中每个类别的单词数量。第二个直方图说明了文本中每个单词对应的预测概率的分布数量。最后一个直方图显示了预测的熵分布,熵的计算公式如下:
\(H = -\sum_{w} p(X_i = w | X_{1:i-1}) \log p(X_i = w | X_{1:i-1})\)
在文本生成任务中,熵可以用来评估模型对生成文本的置信度。如果熵值较高,表示概率分布较为均匀,模型对下一个词的预测不确定性较大,这意味着模型认为多个词都有可能成为下一个词,没有明显的偏好。如果熵值较低,表示概率分布较为集中,模型对下一个词的预测较为确定,这意味着模型对某个或某几个词有较高的置信度。
上面的分析表明,GPT-2 1.5B生成的文本中,没有紫色(a图是人造的文本生成用的prompt,所以存在紫色),很少有标记以红色突出显示,大多数单词是绿色或黄色的。此外,第二个直方图显示了高概率选择的高比例。最后一个指标是第三个直方图中的规律性,其中低熵预测的比例很高,而高熵词的频率几乎呈线性增加。
最后,拿到文本中top k单词数量分布(即颜色的数量分布)的特征,训练一个逻辑回归模型,就完成了一个检测器。
思考:
是否可以在颜色数量分布的特征中考虑各个单词的位置因素?
RADAR: Robust AI-Text Detection via Adversarial Learning
- 发表时间:2023
- 期刊会议:NeurIPS
- 论文单位:The Chinese University of Hong Kong
- 论文作者:Xiaomeng Hu, Pin-Yu Chen, Tsung-Yi Ho
- 论文链接
- 开源代码
- 线上demo
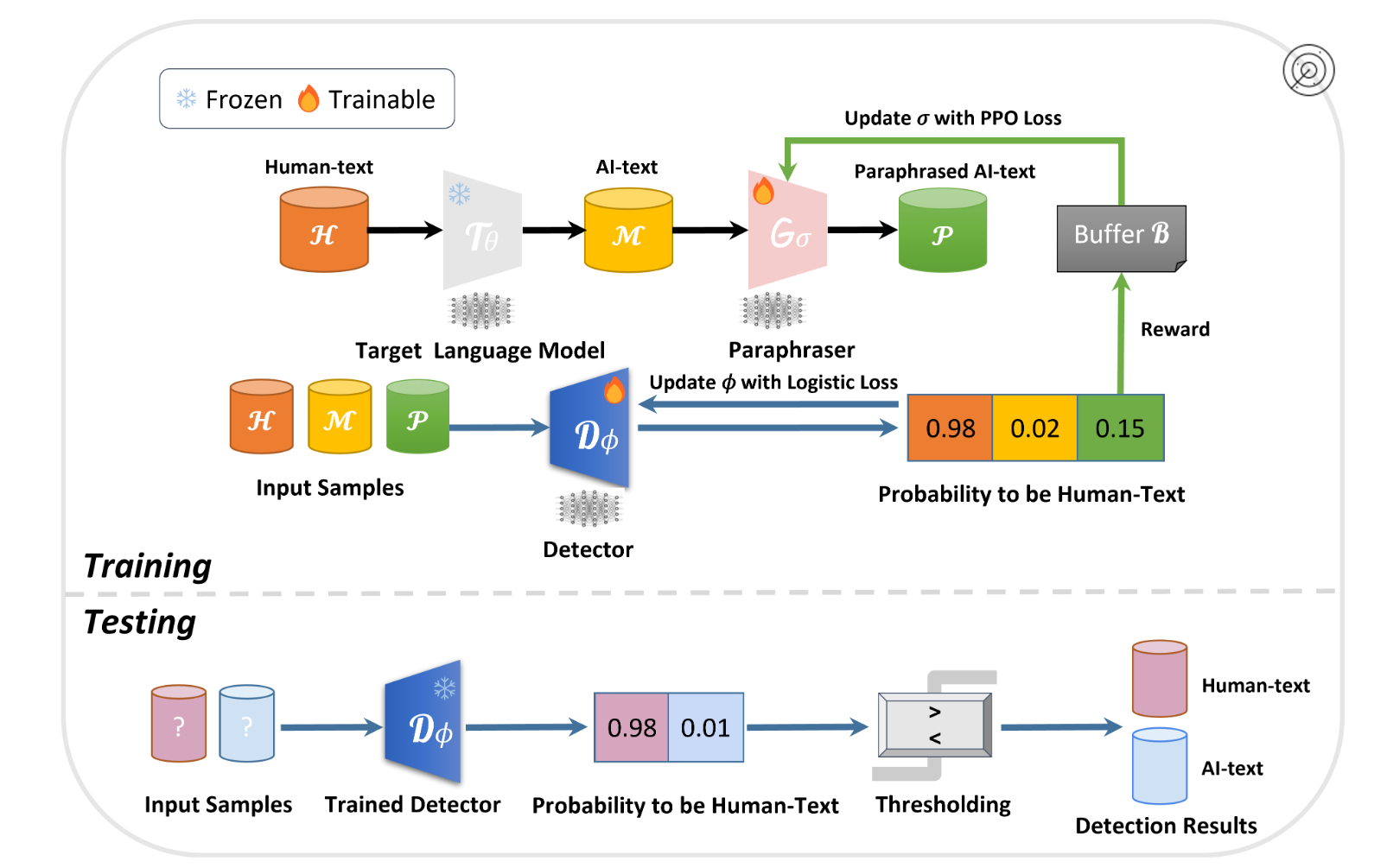
如上图所示,首先,从目标(冻结的)语言模型中生成一个AI文本语料库,该语料库源自人类文本语料库。在RADAR中,我们引入了一个paraphraser(可调的语言模型)和一个detector(另一个可调的语言模型)。在训练阶段,detector的目标是区分人类文本与AI文本,而paraphraser的目标是重写AI文本以逃避检测。paraphraser和detector的模型参数以对抗学习的方式进行更新。在评估阶段,训练好的检测器被部署用于预测任何输入实例中AI生成内容的可能性。
但是该论文并没有开源完全的训练代码,只公布了trained checkpoints,以及说明了训练框架是参考了TextGAIL。
TextGAIL:......我们提出了一个用于文本生成的生成对抗模仿学习框架,该框架使用大型预训练语言模型来提供更可靠的奖励指导。我们的方法使用对比鉴别器和近端策略优化 (PPO) 来稳定和提高文本生成性能......
Towards Possibilities & Impossibilities of AI-generated Text Detection: A Survey
- 发表时间:2023
- 期刊会议:arxiv
- 论文单位:University of Maryland, College Park, MD, USA
- 论文作者:Soumya Suvra Ghosal, Souradip Chakraborty, Jonas Geiping, Furong Huang, Dinesh Manocha, Amrit Singh Bedi
- 论文链接
- 解说链接
摘要:大型语言模型(LLMs)凭借其生成类人文本响应的卓越能力,彻底改变了自然语言处理(NLP)领域。然而,尽管取得了这些进展,现有文献中的多项研究对LLMs的潜在滥用提出了严重关切,例如传播错误信息、生成虚假新闻、学术界的抄袭行为以及污染网络。为了解决这些问题,研究界的共识是开发算法解决方案来检测AI生成的文本。其基本思路是,只要我们能够判断给定文本是由人类还是AI撰写的,就可以利用这一信息来解决上述问题。为此,已经提出了大量的检测框架,突显了AI生成文本检测的可能性。然而,在检测框架发展的同时,研究人员也专注于设计规避检测的策略,即关注AI生成文本检测的不可行性。这是确保检测框架足够稳健且不容易被欺骗的关键一步。尽管该领域引起了极大的兴趣并涌现了大量研究,但目前社区仍缺乏对最新发展的全面分析。**在本综述中,我们旨在对当前工作进行简明分类和概述,涵盖AI生成文本检测的前景和局限性。**为了丰富集体知识,我们对与AI生成文本检测相关的重要且具有挑战性的开放性问题进行了详尽讨论。

prepared detector
(1)基于水印的方法:输入带水印的文本,根据输出是否包含水印有关信息判断该输出是人写的还是机器写的
(2)基于检索的方法:用户先跟AI交互,得到一批AI输出。对于待检测的文本,比较它们和AI输出的相似度,相似度高则认为是AI输出。这种方法可能会有隐私问题,因为需要存储一批用户数据
post-hoc detecto
(1)zero-shot:无需训练专用分类器,直接利用生成模型与人类写作的统计差异进行检测
- 离群点检测:语言模型通过概率采样生成文本,倾向于选择高概率词(如常见词汇),而人类写作会更多使用低频但语义精准的词汇
- 机器回答的特性,不擅长逻辑推断,而擅长背诵记忆:基于大型语言模型(LLM)的对话机器人在涉及操作、噪声过滤和随机性 的任务上表现显著较差。例如,一个涉及替换的问题是:"用 m 替换 p,用 a 替换 e,用 n 替换 a,用 g 替换 c,用 o 替换 h,按照这个规则如何拼写 peach?"。作者指出,面对这个问题,ChatGPT 的回答是"enmog",而正确答案应为"mango"。另一方面,与人类相比,这些机器人在记忆和计算方面表现得更出色。一些利用这种差异的示例问题包括:"列出美国所有州的州府"和"π 的前 50 位数字是什么?"
(2)training/fine-tuning
- n-gram:同一个LLM更可能输出类似的句子。那就给他一个前缀,让他多输出几遍,比较输出的相似度
- RADAR:利用对抗学习来增强LLM应对文本改写模型(Paraphraser)的能力。在训练检测模型时,同步使用Paraphraser模型生成对抗样本,迫使检测器学习改写不变的深层特征。通过对比学习区分改写文本的"表面特征"(如词汇替换)和"本质特征"(如句法结构)。训练过程中迭代更新Paraphraser模型,形成检测器与攻击者的博弈
MULTISCALE POSITIVE-UNLABELED DETECTION OF AI-GENERATED TEXTS
- 发表时间:2023
- 期刊会议:ICLR'24 Spotlight
- 论文单位:1 National Key Lab of General AI, School of Intelligence Science and Technology, Peking University 2 Huawei Noah's Ark Lab
- 论文作者:Yuchuan Tian, Hanting Chen, Xutao Wang, Zheyuan Bai, Qinghua Zhang, Ruifeng Li, Chao Xu, Yunhe Wang
- 论文链接
- 开源代码
- 解说链接
主流的文本分类器没有考虑文本长度对分类难度的影响。短文本往往难以区分,而长文本则更容易分类。在一些短文本情况下,生成式语言模型甚至可以直接"复制"人类语料库作为输出,使得所有机器生成的特征都消失。
为了克服这个问题,本文将多尺度文本检测任务建模为部分正未标记问题(PU)。在这个问题中,来自人类的语料库被认为是"Positive"的,但是来自机器的短文本被给予一个额外的"Unlabeled"标记,用于PU损失计算。然后我们的检测器模型在这个部分PU上下文中被优化。
本文提出了两个创新点。(1)在PU上下文中,提出了长度敏感的多尺度PU损失,其中递归模型用于估计尺度变化语料库的positive priors(2)引入了文本多尺度模块来丰富训练语料库。
MPU: A LENGTH-SENSITIVE PU APPROACH
先引入一下PU loss(Positive-Unlabeled Loss)的概念,PU loss是一种用于处理正例-未标记样本(Positive-Unlabeled Learning, PU Learning)问题的损失函数。在PU Learning中,训练数据仅包含正例(Positive)和未标记样本(Unlabeled),未标记样本可能包含正例或负例(Negative)。PU Loss的目标是从未标记样本中区分出潜在的负例,从而训练分类器。
PU Loss设计基于以下假设:
-
未标记样本是正例和负例的混合。
-
正例的分布是已知的。
-
负例的分布需要通过模型从未标记样本中推断。
PU Loss公式如下:
\(\mathcal{L}{\text{PU}} = \pi_p \cdot \mathbb{E}{x \sim P}\\log p(y=1\|x) + \mathbb{E}{x \sim U}\\log (1 - p(y=1\|x)) - \pi_p \cdot \mathbb{E}{x \sim P}\\log (1 - p(y=1\|x))\)
其中,\(\pi_p\)(先验概率)的计算公式为:(已标注正样本数 + 未标注样本数未标注中正样本的比例) / 样本总数,\(P\) 是正例样本的分布,\(U\) 是未标记样本的分布,\(p(y=1∣x)\) 是模型预测样本 x 为正例的概率。
在PU loss中先验概率\(\pi_p\) 的值是确定的,它反映了在一些文本中,属于人类创造文本的比例,然而对于不同长度的文本,人类创造文本的比例其实是不均匀的,直观感受是文本越短,这个比例越大。
本文提出使用一个general recurrent language model来根据检测文本的长度来动态改变先验概率\(\pi_p\) ,相关代码如下:
python
def expectation_matrix(length, pi, device='cpu'):
if length < 3:
return torch.tensor(pi).float().to(device)
state = torch.zeros((1, length+1)).float().to(device)
state[0, 0] += 1.
trans = torch.zeros((length+1,length+1)).float().to(device) # state transition matrix
trans[1:, :-1] += torch.eye(length).to(device)*pi
trans[:-1, 1:] += torch.eye(length).to(device)*(1-pi)
trans[0,0] += pi
trans[length, length] += (1-pi)
total_trans = torch.zeros_like(trans) + torch.eye(length+1).to(device) # id mat
for _ in range(length):
total_trans @= trans
distribution = (state @ total_trans).squeeze(0)
expectation = 1. - ((distribution * torch.arange(0, length+1).to(device)).sum()/length)
return expectation.to(device)最后的损失函数公式如下:
\(\hat{R}(g) = \hat{R}{PN}(g) + \gamma \hat{R}{MPU}(g)\)
其中,\(\hat{R}{PN}(g)\)表示canonical PN classification loss,\(\gamma\)是一个权重系数,\(\hat{R}{MPU}(g)\)具体公式如下:
\(\text{objective} = \begin{cases} \text{positive_loss} + \text{negative_loss}, & \text{if } \text{negative_loss} \geq -\text{beta} \\ \text{positive_loss} - \text{beta}, & \text{otherwise} \end{cases}\)
\(\text{positive_loss} = \sum \left( \text{prior} \times \frac{\text{positive_x}}{\text{positive_num}} \times \sigma(-\text{input}) \right)\)
\(\text{negative_loss} = \sum \left( \left( \frac{\text{unlabeled_x}}{\text{unlabeled_num}} - \text{prior} \times \frac{\text{positive_x}}{\text{positive_num}} \right) \times \sigma(\text{input}) \right)\)
\(\text{prior} = \text{prior}\\text{sentence_length}\)
TEXT MULTISCALING
所提出的多尺度PU损失期望训练文本的长度具有高度变化性,但训练集可能仅包含冗长的段落。因此,我们引入了文本多尺度化模块,该模块生成多种短文本,以充分发挥对长度敏感的多尺度PU损失的潜力。我们提出了在句子尺度上进行随机删除的解决方案。文本多尺度化模块包含三个步骤:首先,将完整的训练文本分词成n个句子,表示为句子数组C;然后,根据句子级别的掩码概率psent,对句子进行独立且随机的掩码处理。在概率论的角度,每个句子由样本空间{0, 1}中的独立伯努利试验决定。在样本空间中,0表示句子被舍弃,1表示句子被保留。最后,所有句子再次合并,形成多尺度化的训练文本cmul。
Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
- 发表时间:2024
- 期刊会议:ICML
- 论文单位:1 University of Maryland 2 Carnegie Mellon University
- 论文作者:Abhimanyu Hans, Avi Schwarzschild, Valeriia Cherepanova, Hamid Kazemi, Aniruddha Saha, Micah Goldblum, Jonas Geiping, Tom Goldstein
- 论文链接
- 开源代码
- 线上demo
- 论文解说
常规的基于PPL的方法存在诸如对提示词的敏感性(Capybara 问题)、对新模型适应能力差(大模型种类很多,生成的待检测文本风格多样)、跨领域(待检测文本的领域多样,比如日记、新闻......)和多语言鲁棒性不足(存在一些Adversarial Attacks)等问题。
Capybara 问题:当语言模型生成的文本依赖于特定的提示词(Prompt)时,这些提示词会显著影响生成文本的困惑度。复杂提示词可能导致生成文本的困惑度表现得像人类生成文本,从而造成误判。所以先前的基于普通困惑度的判断方案难以应对这一场景。例如简单提示词"1, 2, 3," 会生成困惑度极低的文本 "4, 5, 6";复杂提示词 "写一个关于天文学家的水豚的故事" 可能生成内容"奇特"的文本,对模型来说困惑度较高。
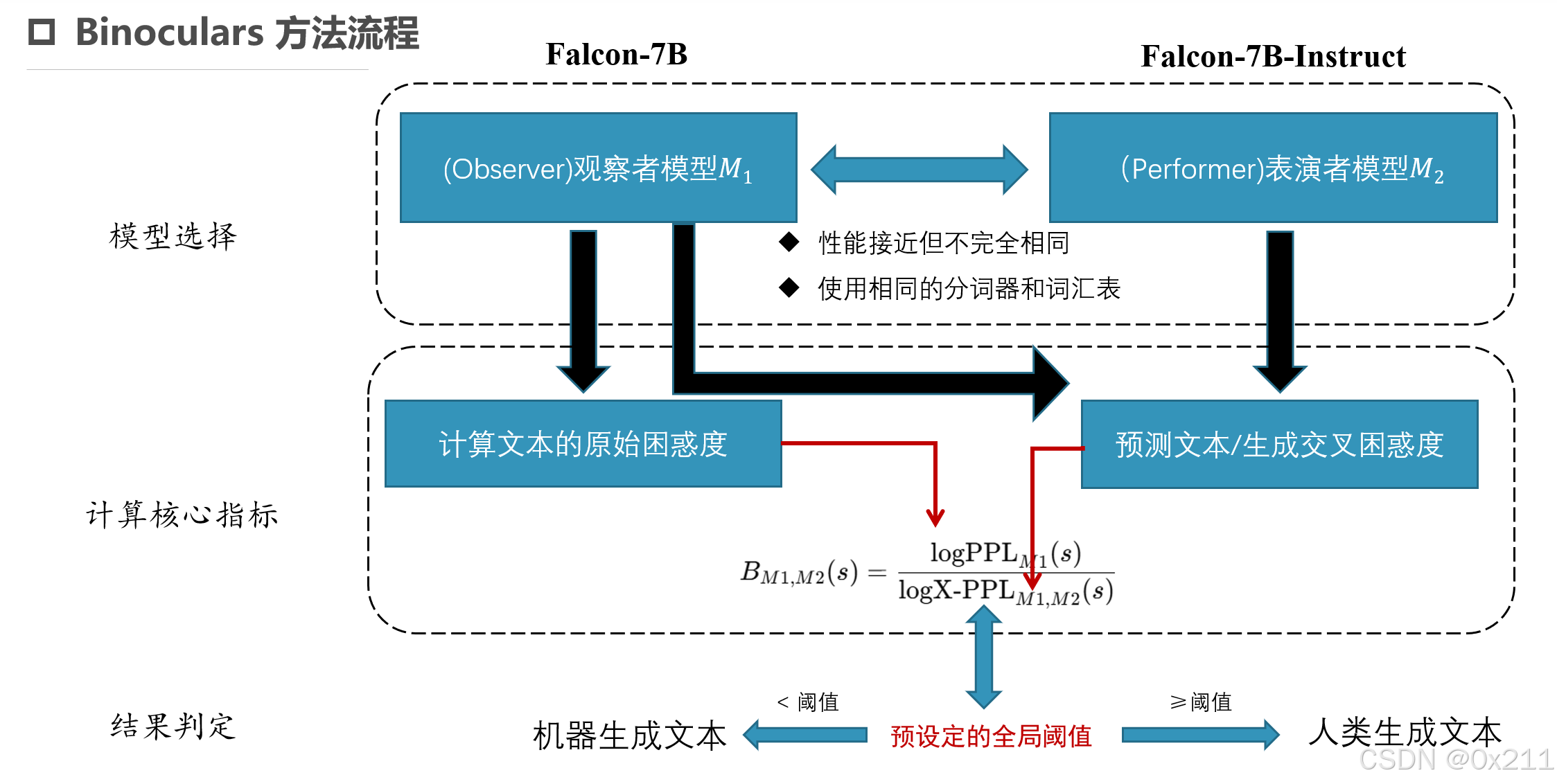
本文提出的研究动机是开发一种通用、零样本且高鲁棒的生成文本检测方法,能够适应不同的生成模型和多语言、多领域的环境。本文的核心贡献是提出了 Binoculars 方法,通过结合原始困惑度和交叉困惑度的比值,消除了提示词对困惑度的干扰,并提高了检测的准确性和鲁棒性。
交叉困惑度(Cross-Perplexity, X-PPL):通过比较两个语言模型对文本的预测差异,计算交叉困惑度。人类文本通常在两个模型的预测上表现出更大的分歧,而机器文本的预测更为一致。公式如下:
\( \log X \cdot PPL_{M_1, M_2}(s) = -\frac{1}{L} \sum_{i=1}^{L} M_1(s)_i \cdot \log (M_2(s)_i). \)
Binoculars 方法结合了两个预训练语言模型的困惑度计算:
(1)使用模型M1计算的原始困惑度。
(2)使用 M1和M2两个模型(论文中提到M1和M2性能越接近越好)计算的交叉困惑度,公式如下:
\(B_{\mathcal{M}_1, \mathcal{M}2}(s) = \frac{\log \text{PPL}{\mathcal{M}1}(s)}{\log \text{X-PPL}{\mathcal{M}_1, \mathcal{M}_2}(s)}\)
(3)最终计算的 Binoculars 分数为原始困惑度与交叉困惑度的比值
(4)根据计算结果,分数低于设定阈值则判定为机器生成,高于阈值则判定为人类生成。
CNN-Generated Images Are Surprisingly Easy to Spot... for Now
- 发表时间:2020
- 期刊会议:CVPR
- 论文单位:UC Berkeley
- 论文作者:Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, Alexei A. Efros
- 论文链接
- 开源代码
背景:训练的二分类器泛化性弱,创建一个"通用"检测器,用于区分真实图像和CNN生成的图像,而不考虑生成模型的架构或数据集。这篇文章是通过一些实验研究检测器的泛化性。证明在CNN生成的图像上训练的取证模型比其他CNN合成方法表现出惊人的泛化程度。
通过使用单个CNN模型(ProGAN,一种高性能的无条件GAN模型)生成大量伪造图像,构建数据集ForenSynths(收集了一个由11个不同的基于cnn的图像生成器模型生成的假图像组成的数据集),并将模型的真实训练样本作为负样本,用 ResNet - 50 预训练模型进行二分类训练。训练时采用多种数据增强方法(如随机左右翻转、裁剪、高斯模糊、JPEG 压缩等)。
Learning on Gradients: Generalized Artifacts Representation for GAN-Generated Images Detection
- 发表时间:2023
- 期刊会议:CVPR
- 论文单位:1 Institute of Information Science, Beijing Jiaotong University 2 Beijing Key Laboratory of Advanced Information Science and Network Technology
- 论文作者:Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Yunchao Wei
- 论文链接
- 开源代码

背景:大多数图像检测器在未知领域的性能会急剧下降,因此开发一种通用的表示方法来描述生成模型产生的伪影对于假图像检测至关重要。
引入梯度学习检测框架(LGrad):使用预训练的 CNN 模型作为转换模型,将图像转换为梯度图。利用这些梯度图来呈现通用伪影,并将其输入到分类器中以确定图像的真实性。该框架将数据依赖问题转化为转换模型依赖问题。整体流程图如下:
- 选择一个在大规模图像数据集上预训练过的CNN模型(resnet50,VGG16等)
- 将图像输入到CNN模型中,得到中间层的特征图,计算特征图梯度,得到梯度图。
- 使用带有标签的真实图像和 GAN 生成图像的梯度图特征向量作为训练数据,训练一个二分类器。
- 将生成的梯度图输入到二分类器中,进行分类
DIRE for Diffusion-Generated Image Detection
- 发表时间:2023
- 期刊会议:CVPR
- 论文单位: CAS Key Laboratory of GIPAS, EEIS Department, University of Science and Technology of China
- 论文作者:Zhendong Wang, Jianmin Bao, Wengang Zhou, Weilun Wang, Hezhen Hu, Hong Chen, Houqiang Li
- 论文链接
- 开源代码
背景:现有的图像检测方法在检测由扩散模型生成的图像时存在局限性,难以准确识别。需要一种有效的方法来检测扩散生成的图像。
构建数据集DiffusionForensics:建立了一个综合的扩散生成基准,包括8种扩散模型生成的图像。提出扩散重建误差(DIRE):通过预训练的扩散模型来测量输入图像与重建图像之间的误差。(扩散生成的图像可以使用扩散模型近似重建,而真是图像难以重建)。详细流程如下:
- 向扩散模型编码器输入图像x,将其映射到噪声空间N(0,I)中,得到噪声向量XT
- 将噪声向量XT输入解码器对图像进行重建,重建图像X'
- 求x与x'之间的DIRE值
- 将DIRE输入到一个二元分类器中,使用交叉熵损失函数训练分类器
DIRE公式如下:
\(\text{DIRE}(\mathbf{x}_0) = |\mathbf{x}_0 - \mathbf{R}(\mathbf{I}(\mathbf{x}_0))|\)
其中\(|*|\)是计算absolute value,\(\mathbf{I}(*)\)是加噪过程,\(\mathbf{R}(*)\)是去噪重建过程。
LaRE2: Latent Reconstruction Error Based Method for Diffusion-Generated Image Detection
- 发表时间:2024
- 期刊会议:CVPR
- 论文单位:Tencent YouTu Lab
- 论文作者:Yunpeng Luo, Junlong Du, Ke Yan, Shouhong Ding
- 论文链接
- 开源代码
背景:扩散模型的发展极大地提高了图像生成的质量,使得区分真实图像和生成图像变得越来越困难。在特征提取阶段,DIRE和SeDID都需要多步DDIM采样过程,这导致实际应用效率较低。此外,DIRE和SeDID将重建误差作为唯一特征,忽略了误差与原始图像之间的对应关系。
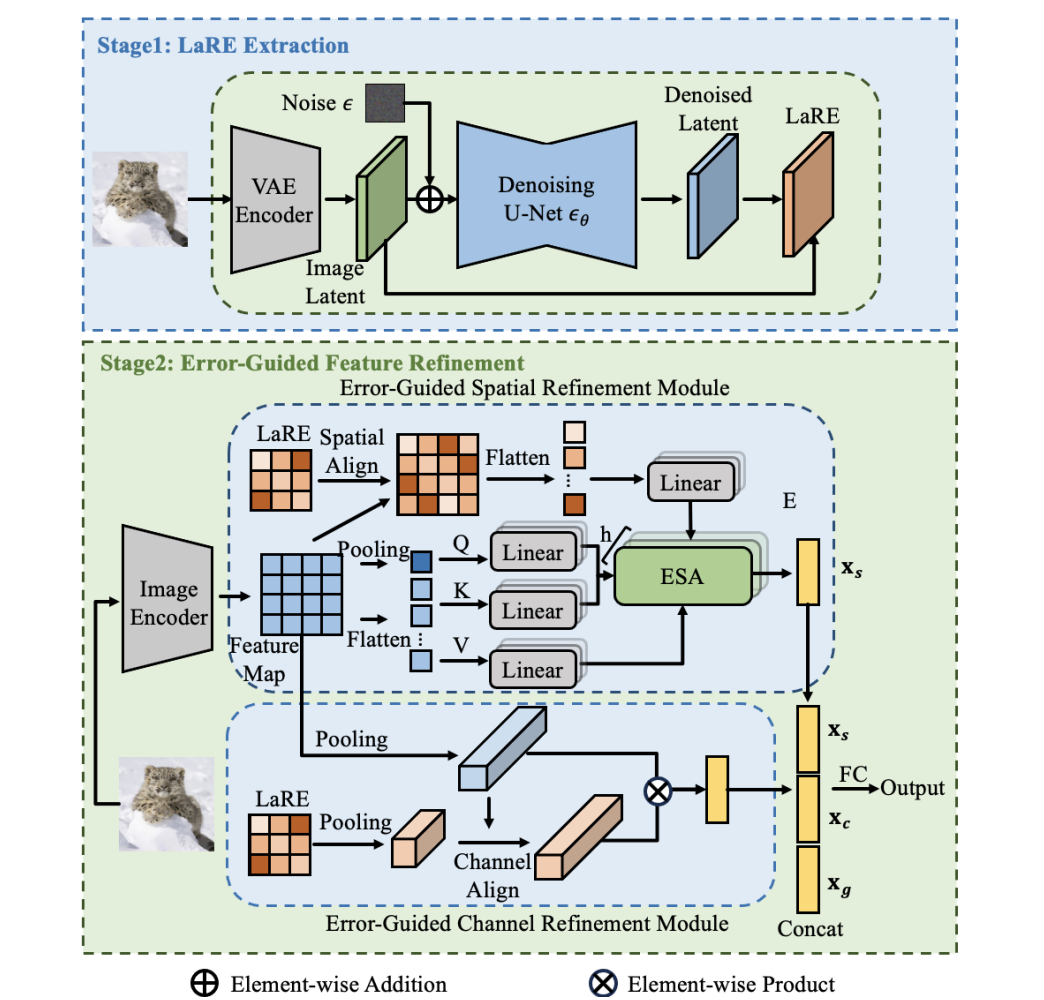
提出了LARE2来检测图像,其中包含LARE和EGRE两部分。
将图像通过VAE转化为潜在向量,向潜在向量中加入步长为t的噪声,然后使用扩散模型预测噪声。使用预测噪声和加入的噪声计算误差LARE。潜在重建误差LARE:LaRE是在扩散反求过程中一步提取出来的,这比经过几十步去噪完全重建图像的效率要高得多。 此外,发现重建的损失与原始图像的局部信息频率呈正相关,高频区域的重建损失比较大。
提出EGRE:EGRE 的核心目标是利用 LaRE 中包含的与原始图像相关的信息,对图像特征进行优化,使得特征能够更好地揭示生成图像与真实图像之间的差异,从而提高检测的准确性。它通过两个子模块,即空间细化模块(ESR)和通道细化模块(ECR),分别从空间和通道的角度对特征进行处理,最后将处理后的特征进行整合,以获得更具判别性的最终特征表示。空间细化模块(ESR):使用自适应平均池化层将LARE和图像拥有相同的空间大小,使用多头注意力机制和LARE值增强图像中一些区域的权值,比如(一些高频区域权值比较大)。通道细化模块(ECR):将图像特征和LARE都转化为一维的,根据 LaRE 在通道维度上的信息,调整特征图在不同通道上的权重。
将空间细化后的特征和通道细化后的特征进行连接操作,将连接后的特征经过一个全连接层(FC layer)进行进一步的特征变换和映射,最终输出用于生成图像检测的特征表示。
Attack-Resilient Image Watermarking Using Stable Diffusion
- 发表时间:2024
- 期刊会议:arxiv
- 论文单位:University of Massachusetts Amherst
- 论文作者:Lijun Zhang, Xiao Liu, Antoni Viros Martin, Cindy Xiong Bearfield, Yuriy Brun, Hui Guan
- 论文链接
- 开源代码
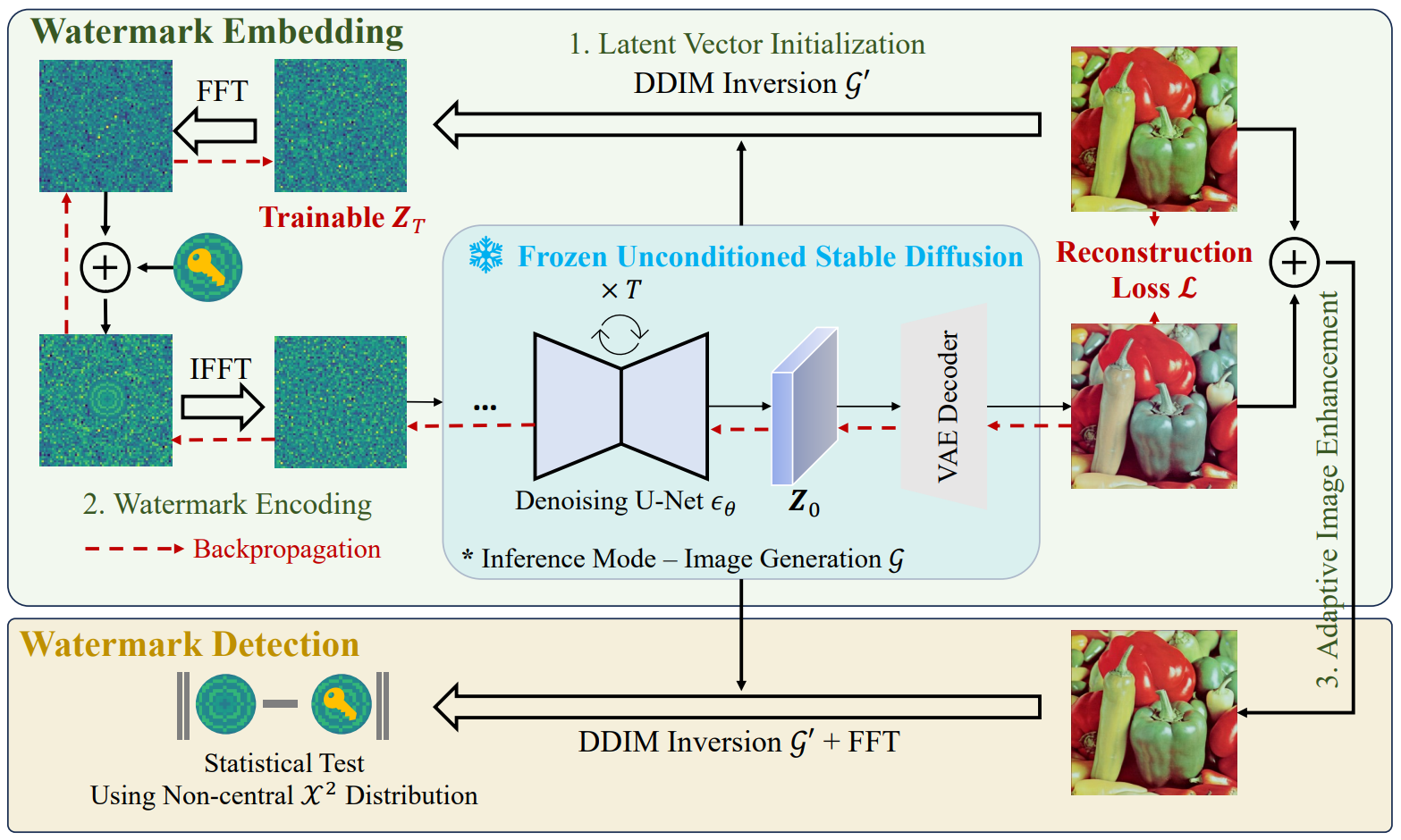
背景:在使用数字水印进行AI生成图像检测的方法中,stable difusion可以用于水印去除攻击,现有的水印无法抵抗这种攻击。
提出了一种新的基于稳定扩散的水印框架ZoDiac:将水印注入到可训练的潜在空间中,从而即使受到攻击也可以在潜在向量中可靠地检测到水印。整体框架如下:
嵌入水印:(1)首先输入图像经过DDIM反演过程生成潜在向量(2)将潜在向量转换到傅里叶空间,然后嵌入水印,然后再转换回潜在向量空间(3)将潜在向量输入扩散模型生成带有水印的图像(4)图像增强:将带水印的图像和原始图像融合
检测水印:(1)将待检测图像通过DDIM反演生成潜在向量(2)将潜在向量变换到傅里叶空间,然后进行水印检测
A SANITY CHECK FOR AI-GENERATED IMAGE DETECTION
- 发表时间:2025
- 期刊会议:ICLR
- 论文单位:1 Xiaohongshu Inc 2 University of Science and Technology of China 3 Shanghai Jiao Tong University
- 论文作者:Shilin Yan, Ouxiang Li, Jiayin Cai, Yanbin Hao, Xiaolong Jiang, Yao Hu, Weidi Xie
- 论文链接
- 开源代码
- 论文解说
摘要:随着生成模型的快速发展,识别人工智能生成的内容已引起工业界和学术界的日益关注。在本文中,我们对人工智能生成图像检测任务是否已得到解决进行了合理性检查。首先,我们提出了Chameleon数据集,其中包含对人类感知极具挑战性的人工智能生成图像。 为了量化现有方法的泛化能力,我们在Chameleon数据集上评估了9种现成的人工智能生成图像检测器。分析发现,几乎所有模型都将人工智能生成的图像误分类为真实图像。随后,**我们提出了AIDE(基于混合特征的人工智能生成图像检测器),它利用多个专家同时提取视觉伪影和噪声模式。**具体来说,为了捕捉高层语义,我们使用CLIP计算视觉嵌入,这有效地使模型能够基于语义和上下文信息识别人工智能生成的图像。其次,我们选择图像中最高和最低频率的局部区域,并计算低层次的局部特征,旨在通过低层次伪影(例如噪声模式、抗锯齿效应)检测人工智能生成的图像。在现有基准测试(例如AIGCDetectBenchmark和GenImage)上进行评估时,AIDE相比最先进的方法分别提升了+3.5%和+4.6%,并且在我们提出的具有挑战性的Chameleon基准测试中也取得了显著成果,尽管检测人工智能生成图像的问题远未解决。
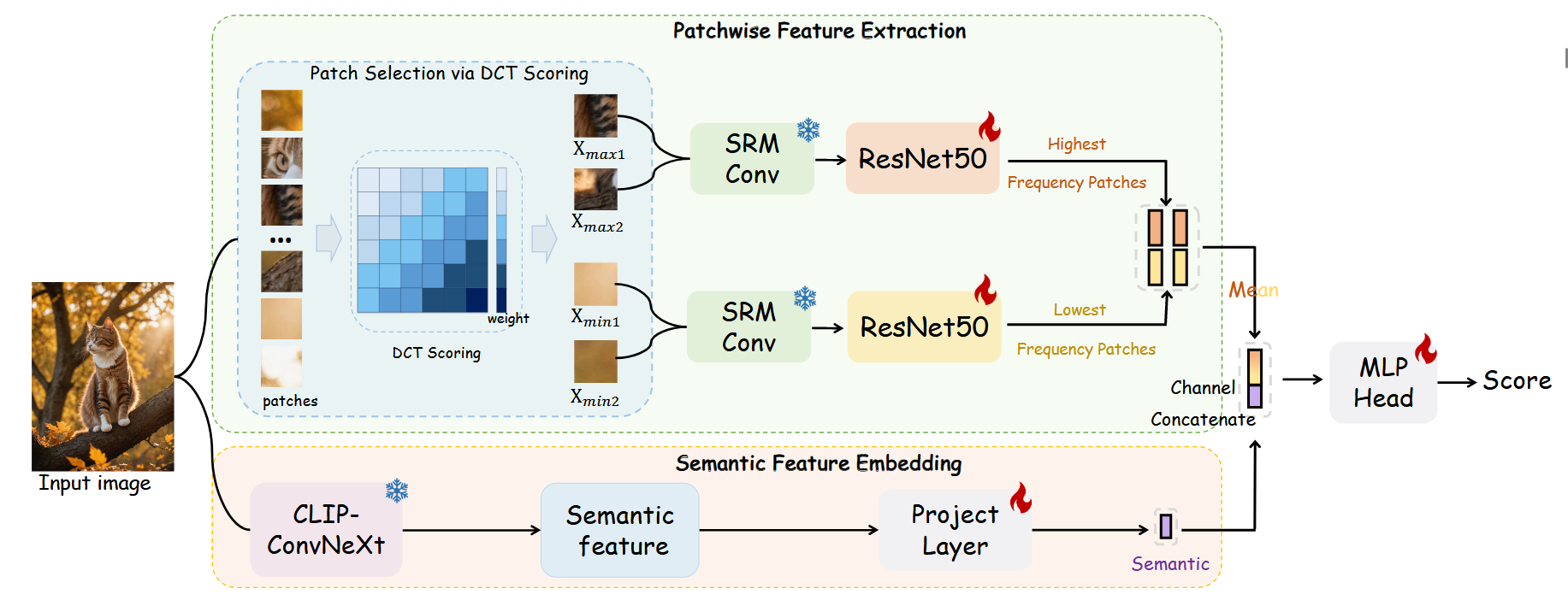
像生成对抗网络或扩散模型这样的模型通常会产生具有某些伪像的图像,例如过度平滑或抗锯齿效果。为了捕捉这种差异,论文采用Discrete Cosine Transform(DCT)score model来识别具有最高和最低频率的patche (高频成分通常对应于图像中的细节、边缘、纹理和快速变化的部分 ,对于检测AI生成图像中的伪影非常有用;低频成分通常对应于图像中的平滑区域、背景和整体结构,有助于分析图像的整体一致性) ,进而关注这些极端patche。
首先把图像分割成若干个patche,然后计算每个patche的DCT score,计算公式如下:
\(F(u, v) = C(u)C(v) \sum_{x=0}^{M-1} \sum_{y=0}^{N-1} f(x, y) \cos \left( \frac{(2x+1)u\pi}{2M} \right) \cos \left( \frac{(2y+1)v\pi}{2N} \right)\)
\(C(u) = \begin{cases} \sqrt{\frac{1}{M}}, & u = 0 \\ \sqrt{\frac{2}{M}}, & u > 0 \end{cases}\)
为了获取最高和最低的图像patche,论文使用complexity of the frequency components作为指标。由此,论文设计了一个简单而有效的评分机制,使用K个不同的带通滤波器:
\(F_{k,ij} = \begin{cases} 1, & \frac{2N}{K} \cdot k \leq i + j < \frac{2N}{K} \cdot (k + 1) \\ 0, & \text{otherwise} \end{cases}\)
其中,N 是图像块的大小(如32×32像素);K 是滤波器的数量,表示将频率范围划分为 K 个区间;i ,j 是频率域中的坐标;k 是滤波器的索引,表示第 k 个频率区间。
接下来,对于第m个补丁\(x^{\text{dct}}{m}∈R^{N × N × 3}\),应用滤波器\(F{k,ij}∈R^{N × N × 3}\)来乘以绝对DCT系数\(x^{\text{dct}}_{m}∈R^{N × N × 3}\)的对数,并对所有位置求和以获得patche\(G^m\)的等级,论文把它表述为:
\(G_m = \sum_{k=0}^{K-1} 2^k \times \sum_{c=0}^{2} \sum_{i=0}^{N-1} \sum_{j=0}^{N-1} F_{k,ij} \cdot \log(|x^{\text{dct}}_{m}| + 1)\)
为了捕捉图像中丰富的语义特征,如object co-occurrence和contextual relationships,论文用现成的视觉语言基础模型计算输入图像的视觉嵌入。具体来说,采用基于ConvNeXt的OpenCLIP模型来获得最终的特征图\(v∈R^{h × w × c}\)。
最后把DCT和CLIP的结果concatenate一起,输入mlp head进行预测。
参考链接
- https://blog.csdn.net/qq_36332660/article/details/144105316
- https://blog.csdn.net/weixin_62277441/article/details/143368070
胡思乱想
- 用大模型对一个人类写的文本进行拓展,或者喂一些prompt生成一些新的数据集,作为补充数据集
- 影子模型
- RLHF手段,lora、prompt-tuning等peft微调手段
- 搞一个统一的文本图像检测模型
- 对新模型适应能力差(大模型种类很多,生成的待检测文本风格多样)、跨领域(待检测文本的领域多样,比如日记、新闻......)和多语言鲁棒性不足(存在一些Adversarial Attacks)等问题
- 检测视频是不是ai生成的
- 应用场景创新,(1)人脸识别(2)小红书抖音等媒体平台...
- 推理模型,cot?