最新的英特尔® 酷睿™ Ultra 处理器(第二代)让我们能够在台式机、移动设备和边缘中实现大多数 AI 体验,将 AI 加速提升到新水平,在 AI 时代为边缘计算提供动力。英特尔® 酷睿™ Ultra 处理器提供了一套全面的专为 AI 定制的集成计算引擎,包括 CPU、GPU 和 NPU,提供高达 99 总平台 TOPS。近期,YOLO系列模型发布了YOLOv12, 对 YOLO 框架进行了全面增强,特别注重集成注意力机制,同时又不牺牲 YOLO 模型所期望的实时处理能力,是 YOLO 系列的一次进化,突破了人工视觉的极限。本文中,我们将使用英特尔® 酷睿™ Ultra 处理器AI PC设备,结合OpenVINO™ C# API 使用最新发布的OpenVINO™ 2025.0 部署YOLOv11 和 YOLOv12 目标检测模型,并在AIPC设备上,进行速度测试:
OpenVINO™ C# API项目链接:
https://github.com/guojin-yan/OpenVINO-CSharp-API.git本文使用的项目源码链接为:
https://github.com/guojin-yan/YoloDeployCsharp/blob/yolov1/demo/yolo_openvino_demo/1. 前言
1.1 英特尔® 酷睿™ Ultra 处理器(第二代)
全新英特尔酷睿Ultra 200V系列处理器对比上代Meteor Lake,升级了模块化结构、封装工艺,采用全新性能核与能效核、英特尔硬件线程调度器、Xe2微架构锐炫GPU、第四代NPU...由此也带来了CPU性能提升18%,GPU性能提升30%,整体功耗降低50%,以及120TOPS平台AI算力。
酷睿Ultra 200V系列处理器共有9款SKU,包括1款酷睿Ultra 9、4款酷睿Ultra 7以及4款酷睿Ultra 5,全系8核心8线程(4个性能核与4个能效核),具体规格如下。
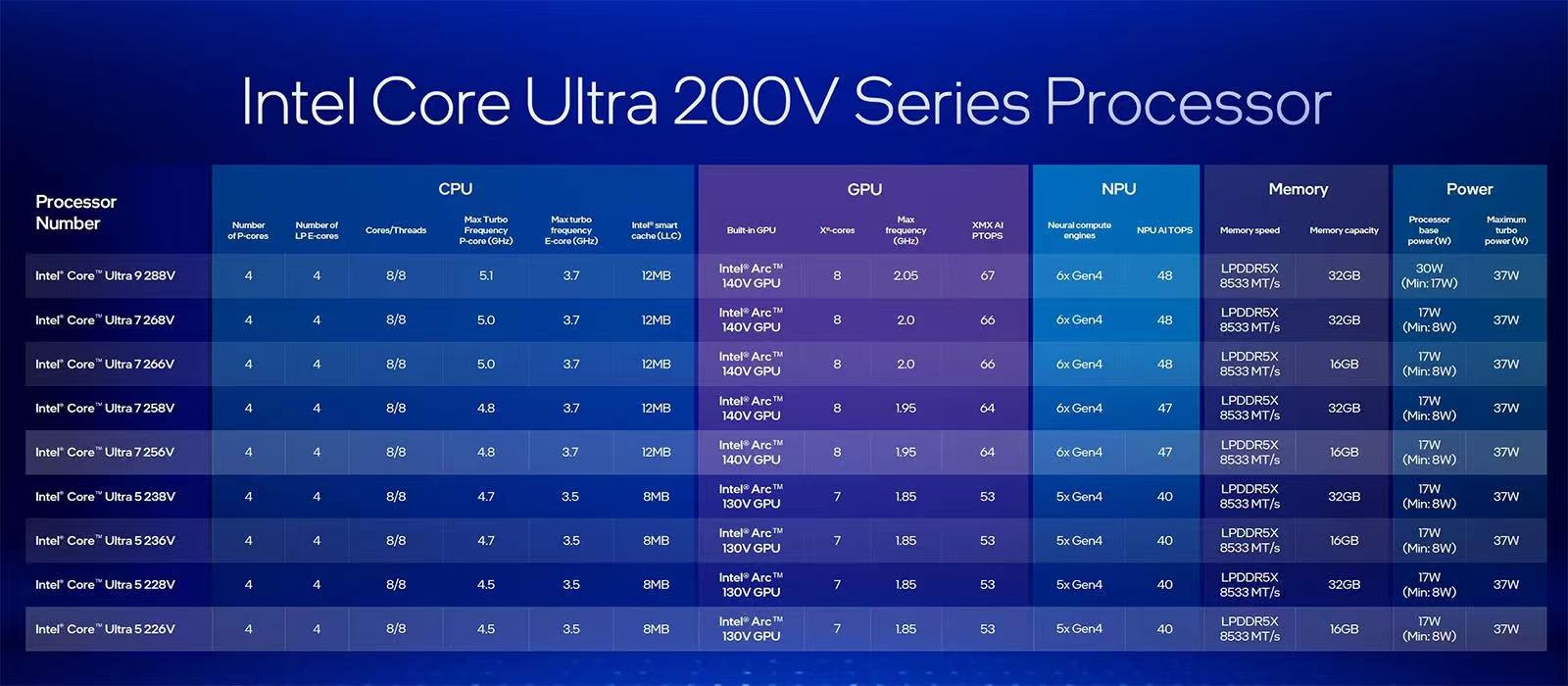
作为新一代旗舰,酷睿Ultra 9 288V性能核频率最高5.1GHz、能效核频率最高3.7GHz,拥有12MB三级缓存。GPU方面,集成锐炫140V显卡,拥有8个全新Xe2核心、8个光线追踪单元,频率最高2.05GHz,可以实现67TOPSAI算力。而NPU集成6个第四代神经计算引擎,AI算力提升至48TOPS。

在当前项目测试,使用的是Intel® Core™ Ultra 9 288V设备,处理器信息如下表所示:
| 设备 | 规格 | 参数 |
|---|---|---|
| CPU | 名称 | Intel® Core™ Ultra 9 288V |
| 内核数 | 8(4个性能核+4个低功耗高效内核) | |
| 总线程数 | 8 | |
| 最大睿频频率 | 5.1 GHz | |
| 缓存 | 12 MB Intel® Smart Cache | |
| 支持的人工智能软件框 | OpenVINO™, WindowsML, DirectML, ONNX RT, WebNN | |
| GPU | 名称 | Intel® Arc™ Graphics 140V |
| 显卡最大动态频率 | 2.05 GHz | |
| GPU 峰值 TOPS(Int8) | 67 TOPS | |
| 支持的人工智能软件框架 | OpenVINO™, WindowsML, DirectML, ONNX RT, WebGPU, WebNN | |
| NPU | 名称 | Intel® AI Boost |
| NPU 峰值 TOPS(Int8) | 48 TOPS | |
| 支持的人工智能软件框架 | OpenVINO™, WindowsML, DirectML, ONNX RT, WebNN |
1.2 OpenVINO™ C# API
英特尔发行版 OpenVINO™ 工具套件基于 oneAPI 而开发,可以加快高性能计算机视觉和深度学习视觉应用开发速度工具套件,适用于从边缘到云的各种英特尔平台上,帮助用户更快地将更准确的真实世界结果部署到生产系统中。通过简化的开发工作流程,OpenVINO™ 可赋能开发者在现实世界中部署高性能应用程序和算法。

OpenVINO™ 2025.0版本在生成式AI和硬件支持方面实现了多项重大突破。生成式AI推理速度大幅提升,特别是Whisper语音模型和图像修复技术的加速,让AI应用的实时性和效率得到显著改善。同时,新增支持Qwen 2.5和DeepSeek-R1等中文大模型,优化了长文本处理和7B模型的推理吞吐量。在硬件方面,新一代Intel Core Ultra和Xeon处理器带来了更强的FP16推理能力,同时OpenVINO还推出了全球首个支持torch.compile的NPU后端,提升了异构计算能力。GPU优化和Windows Server原生支持也让硬件性能得到更大释放,边缘计算领域的优化使IoT设备能效大幅提高。
OpenVINO™ C# API 是一个 OpenVINO™ 的 .Net wrapper,应用最新的 OpenVINO™ 库开发,通过 OpenVINO™ C API 实现 .Net 对 OpenVINO™ Runtime 调用,使用习惯与 OpenVINO™ C++ API 一致。OpenVINO™ C# API 由于是基于 OpenVINO™ 开发,所支持的平台与 OpenVINO™ 完全一致,具体信息可以参考 OpenVINO™。通过使用 OpenVINO™ C# API,可以在 .NET、.NET Framework等框架下使用 C# 语言实现深度学习模型在指定平台推理加速。
下表为当前发布的 OpenVINO™ C# API NuGet Package,支持多个目标平台,可以通过NuGet一键安装所有依赖。
Core Managed Libraries
| Package | Description | Link |
|---|---|---|
| OpenVINO.CSharp.API | OpenVINO C# API core libraries |  |
| OpenVINO.CSharp.API.Extensions | OpenVINO C# API core extensions libraries |  |
| OpenVINO.CSharp.API.Extensions.OpenCvSharp | OpenVINO C# API core extensions libraries use OpenCvSharp |  |
| OpenVINO.CSharp.API.Extensions.EmguCV | OpenVINO C# API core extensions libraries use EmguCV |  |
Native Runtime Libraries
| Package | Description | Link |
|---|---|---|
| OpenVINO.runtime.win | Native bindings for Windows |  |
| OpenVINO.runtime.ubuntu.22-x86_64 | Native bindings for ubuntu.22-x86_64 |  |
| OpenVINO.runtime.ubuntu.20-x86_64 | Native bindings for ubuntu.20-x86_64 |  |
| OpenVINO.runtime.ubuntu.18-x86_64 | Native bindings for ubuntu.18-x86_64 |  |
| OpenVINO.runtime.debian9-arm64 | Native bindings for debian9-arm64 | |
| OpenVINO.runtime.debian9-armhf | Native bindings for debian9-armhf |  |
| OpenVINO.runtime.centos7-x86_64 | Native bindings for centos7-x86_64 |  |
| OpenVINO.runtime.rhel8-x86_64 | Native bindings for rhel8-x86_64 |  |
| OpenVINO.runtime.macos-x86_64 | Native bindings for macos-x86_64 |  |
| OpenVINO.runtime.macos-arm64 | Native bindings for macos-arm64 |  |
1.3 YOLOv11与YOLOv12
YOLO系列目标检测模型自2016年提出以来,始终以"实时检测"为核心优势,通过端到端架构和网格化预测思想,在目标检测领域持续引领技术革新。从YOLOv1的7x7网格基础框架,到YOLOv8的骨干网络优化,再到YOLOv10的C3K2模块创新,该系列通过特征提取增强、后处理优化和计算效率提升,不断突破速度与精度的平衡极限 。
YOLOv11特色由Ultralytics公司开发,通过改进CSPNet主干网络和颈部架构,实现参数精简与精度提升的双重突破。其核心创新在于:
-
增强型特征提取:采用跨阶段特征融合技术,在复杂场景中捕捉细微目标特征
-
动态计算优化:通过自适应计算分配策略,在保持45ms推理速度的同时,mAP提升3.2%
-
轻量化设计:相比YOLOv8减少18%参数量,更适合边缘设备部署
YOLOv12的开发人员通过其最新模型在开创性版本中树立了计算机视觉领域的新标准。YOLOv12 以其无与伦比的速度、准确性和多功能性而闻名,是 YOLO 系列的一次进化,突破了人工视觉的极限。YOLOv12 对 YOLO 框架进行了全面增强,特别注重集成注意力机制,同时又不牺牲 YOLO 模型所期望的实时处理能力。
-
以注意力为中心的设计: YOLOv12 具有区域注意力模块,该模块通过分割特征图来保持效率,将计算复杂度降低一半,同时使用 FlashAttention 来缓解实时检测的内存带宽限制。
-
分层结构:该模型采用残差高效层聚合网络(R-ELAN)来优化特征集成并减少梯度阻塞,并简化了最后阶段以实现更轻、更快的架构。
-
架构增强:通过用 7x7 可分离卷积取代传统位置编码,YOLOv12 有效地保留了位置信息。自适应 MLP 比率可以更好地分配计算资源,在实时约束下支持多样化数据集。
-
训练和优化:该模型使用 SGD 和自定义学习计划训练了 600 多个时期,实现了高精度。它采用 Mosaic 和 Mixup 等数据增强技术来提高泛化能力,从而提升了 YOLOv12 快速、准确检测物体的能力。
两代模型分别代表了YOLO系列在传统架构优化与新型注意力机制融合两个方向的最新突破,其中YOLOv12更开创性地将Transformer优势融入实时检测框架,标志着该系列进入"注意力增强"新阶段。
2. 模型获取
2.1 配置环境
安装模型下载以及转换环境,此处使用Anaconda进行程序集管理,输入以下指令创建一个yolo环境:
shell
conda create -n yolo python=3.10
conda activate yolo
pip install ultralytics
2.2 下载并转换ONNX模型
首先导出目标识别模型,此处以官方预训练模型为例,目前ultralytics已经集成了,依次输入以下指令即可:
shell
yolo export model=yolo11s.pt format=onnx
目前OpenVINO™支持直接调用ONNX模型,因此此处只导出ONNX模型即可,如需要导出OpenVINO™格式的模型,可以参考OpenVINO™官方文档。
3. Yolo 项目配置
3.1 项目创建与环境配置
在Windows平台开发者可以使用Visual Studio平台开发程序,但无法跨平台实现,为了实现跨平台,此处采用dotnet指令进行项目的创建和配置。
首先使用dotnet创建一个测试项目,在终端中输入一下指令:
shell
dotnet new console --framework net8.0 --use-program-main -o yolo_sample此处以Windows平台为例安装项目依赖,首先是安装OpenVINO™ C# API项目依赖,在命令行中输入以下指令即可:
shell
dotnet add package OpenVINO.CSharp.API
dotnet add package OpenVINO.runtime.win
dotnet add package OpenVINO.CSharp.API.Extensions
dotnet add package OpenVINO.CSharp.API.Extensions.OpenCvSharp关于在不同平台上搭建 OpenVINO™ C# API 开发环境请参考以下文章: 《在Windows上搭建OpenVINO™C#开发环境》 、《在Linux上搭建OpenVINO™C#开发环境》、《在MacOS上搭建OpenVINO™C#开发环境》
接下来安装使用到的图像处理库 OpenCvSharp,在命令行中输入以下指令即可:
shell
dotnet add package OpenCvSharp4
dotnet add package OpenCvSharp4.Extensions
dotnet add package OpenCvSharp4.runtime.win关于在其他平台上搭建 OpenCvSharp 开发环境请参考以下文章:《【OpenCV】在Linux上使用OpenCvSharp》 、《【OpenCV】在MacOS上使用OpenCvSharp》
添加完成项目依赖后,项目的配置文件如下所示:
xml
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net8.0</TargetFramework>
<ImplicitUsings>enable</ImplicitUsings>
<Nullable>enable</Nullable>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="OpenCvSharp4" Version="4.10.0.20241108" />
<PackageReference Include="OpenCvSharp4.Extensions" Version="4.10.0.20241108" />
<PackageReference Include="OpenCvSharp4.runtime.win" Version="4.10.0.20241108" />
<PackageReference Include="OpenVINO.CSharp.API" Version="2025.0.0.1" />
<PackageReference Include="OpenVINO.runtime.win" Version="2025.0.0.1" />
</ItemGroup>
</Project>3.2 定义模型预测方法
使用 OpenVINO™ C# API 部署模型主要包括以下几个步骤:
- 初始化 OpenVINO Runtime Core
- 读取本地模型(将图片数据预处理方式编译到模型)
- 将模型编译到指定设备
- 创建推理通道
- 处理图像输入数据
- 设置推理输入数据
- 模型推理
- 获取推理结果
- 处理结果数据
按照 OpenVINO™ C# API 部署深度学习模型的步骤,编写YOLOv10模型部署流程,在之前的项目里,我们已经部署了YOLOv5~9等一系列模型,其部署流程是基本一致的,YOLOv10模型部署代码如下所示:
csharp
internal class YoloDet
{
public static void predict(string model_path, string image_path, string device)
{
DateTime start = DateTime.Now;
// -------- Step 1. Initialize OpenVINO Runtime Core --------
Core core = new Core();
DateTime end = DateTime.Now;
Console.WriteLine("1. Initialize OpenVINO Runtime Core success, time spend: " + (end - start).TotalMilliseconds + "ms.");
// -------- Step 2. Read inference model --------
start = DateTime.Now;
Model model = core.read_model(model_path);
end = DateTime.Now;
Console.WriteLine("2. Read inference model success, time spend: " + (end - start).TotalMilliseconds + "ms.");
// -------- Step 3. Loading a model to the device --------
start = DateTime.Now;
CompiledModel compiled_model = core.compile_model(model, device);
end = DateTime.Now;
Console.WriteLine("3. Loading a model to the device success, time spend:" + (end - start).TotalMilliseconds + "ms.");
// -------- Step 4. Create an infer request --------
start = DateTime.Now;
InferRequest infer_request = compiled_model.create_infer_request();
end = DateTime.Now;
Console.WriteLine("4. Create an infer request success, time spend:" + (end - start).TotalMilliseconds + "ms.");
// -------- Step 5. Process input images --------
start = DateTime.Now;
Mat image = new Mat(image_path); // Read image by opencvsharp
int max_image_length = image.Cols > image.Rows ? image.Cols : image.Rows;
Mat max_image = Mat.Zeros(new OpenCvSharp.Size(max_image_length, max_image_length), MatType.CV_8UC3);
Rect roi = new Rect(0, 0, image.Cols, image.Rows);
image.CopyTo(new Mat(max_image, roi));
float factor = (float)(max_image_length / 640.0);
end = DateTime.Now;
Console.WriteLine("5. Process input images success, time spend:" + (end - start).TotalMilliseconds + "ms.");
// -------- Step 6. Set up input data --------
start = DateTime.Now;
Tensor input_tensor = infer_request.get_input_tensor();
Shape input_shape = input_tensor.get_shape();
Mat input_mat = CvDnn.BlobFromImage(max_image, 1.0 / 255.0, new OpenCvSharp.Size(input_shape[2], input_shape[3]), new Scalar(), true, false);
float[] input_data = new float[input_shape[1] * input_shape[2] * input_shape[3]];
Marshal.Copy(input_mat.Ptr(0), input_data, 0, input_data.Length);
input_tensor.set_data<float>(input_data);
end = DateTime.Now;
Console.WriteLine("6. Set up input data success, time spend:" + (end - start).TotalMilliseconds + "ms.");
// -------- Step 7. Do inference synchronously --------
infer_request.infer();
start = DateTime.Now;
infer_request.infer();
end = DateTime.Now;
Console.WriteLine("7. Do inference synchronously success, time spend:" + (end - start).TotalMilliseconds + "ms.");
// -------- Step 8. Get infer result data --------
start = DateTime.Now;
Tensor output_tensor = infer_request.get_output_tensor();
int output_length = (int)output_tensor.get_size();
float[] output_data = output_tensor.get_data<float>(output_length);
end = DateTime.Now;
Console.WriteLine("8. Get infer result data success, time spend:" + (end - start).TotalMilliseconds + "ms.");
// -------- Step 9. Process reault --------
start = DateTime.Now;
// Storage results list
List<Rect> position_boxes = new List<Rect>();
List<int> class_ids = new List<int>();
List<float> confidences = new List<float>();
// Preprocessing output results
for (int i = 0; i < 8400; i++)
{
for (int j = 4; j < 84; j++)
{
float conf = output_data[8400 * j + i];
int label = j - 4;
if (conf > 0.2)
{
float cx = output_data[8400 * 0 + i];
float cy = output_data[8400 * 1 + i];
float ow = output_data[8400 * 2 + i];
float oh = output_data[8400 * 3 + i];
int x = (int)((cx - 0.5 * ow) * factor);
int y = (int)((cy - 0.5 * oh) * factor);
int width = (int)(ow * factor);
int height = (int)(oh * factor);
Rect box = new Rect(x, y, width, height);
position_boxes.Add(box);
class_ids.Add(label);
confidences.Add(conf);
}
}
}
// NMS non maximum suppression
int[] indexes = new int[position_boxes.Count];
CvDnn.NMSBoxes(position_boxes, confidences, 0.5f, 0.5f, out indexes);
end = DateTime.Now;
Console.WriteLine("9. Process reault success, time spend:" + (end - start).TotalMilliseconds + "ms.");
for (int i = 0; i < indexes.Length; i++)
{
int index = indexes[i];
Cv2.Rectangle(image, position_boxes[index], new Scalar(0, 0, 255), 2, LineTypes.Link8);
Cv2.Rectangle(image, new OpenCvSharp.Point(position_boxes[index].TopLeft.X, position_boxes[index].TopLeft.Y + 30),
new OpenCvSharp.Point(position_boxes[index].BottomRight.X, position_boxes[index].TopLeft.Y), new Scalar(0, 255, 255), -1);
Cv2.PutText(image, class_ids[index] + "-" + confidences[index].ToString("0.00"),
new OpenCvSharp.Point(position_boxes[index].X, position_boxes[index].Y + 25),
HersheyFonts.HersheySimplex, 0.8, new Scalar(0, 0, 0), 2);
}
string output_path = Path.Combine(Path.GetDirectoryName(Path.GetFullPath(image_path)),
Path.GetFileNameWithoutExtension(image_path) + "_result.jpg");
Cv2.ImWrite(output_path, image);
Console.WriteLine("The result save to " + output_path);
Cv2.ImShow("Result", image);
Cv2.WaitKey(0);
}
}接下来就是在C#static void Main(string[] args)方法里调用该方法,调用代码如下所示:
c#
YoloDet.predict("E:/Model/Yolo/yolo11x.onnx", "./demo_2.jpg", "NPU");
YoloDet.predict("E:/Model/Yolo/yolo12x.onnx", "./demo_2.jpg", "CPU");4. 项目运行与演示
4.1 项目编译和运行
接下来输入项目编译指令进行项目编译,输入以下指令即可:
dotnet build接下来运行编译后的程序文件,在CMD中输入以下指令,运行编译后的项目文件:
dotnet run --no-build4.2 模型推理效果
下面分别使用x格式的模型演示YOLOv11和YOLOv12模型运行结果:
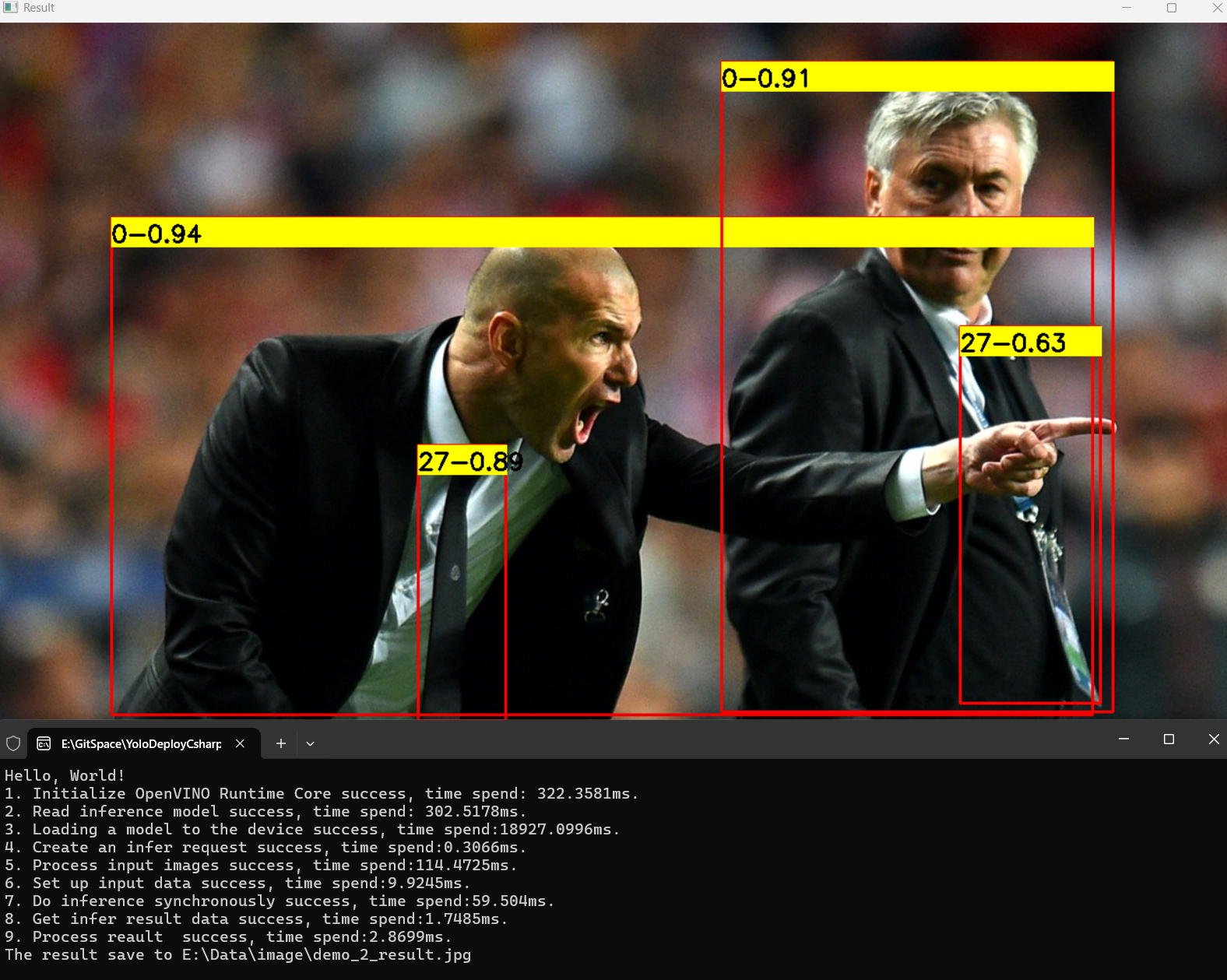
首先是YOLOv11x模型推理效果,如下图所示
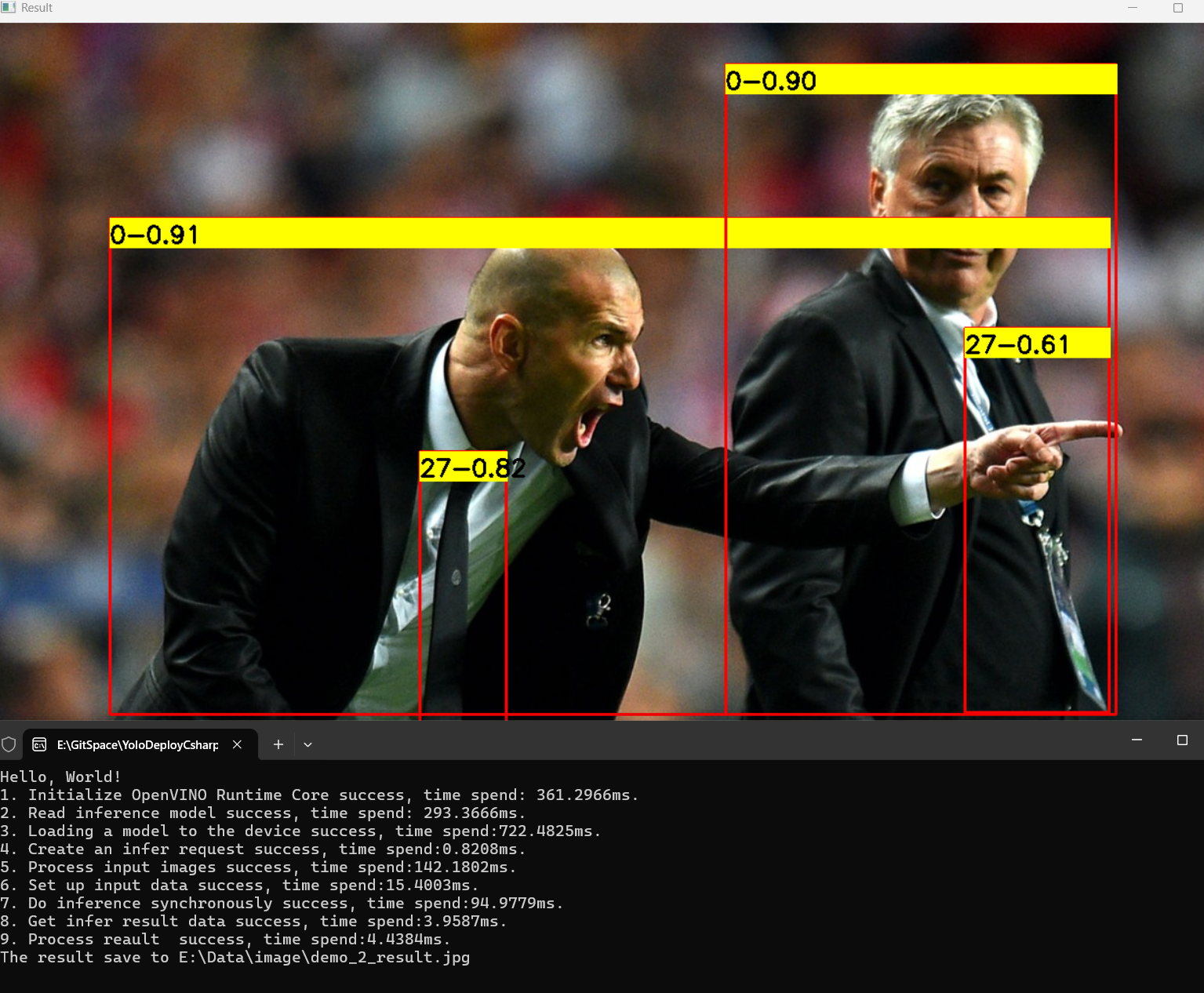
下面是YOLOv12x模型推理效果,如下图所示:
5. YOLO系列模型推理性能表现
下面四个表格通过对YOLOv8、YOLOv11和YOLOv12系列模型在Intel® Core™ Ultra 9 288V处理器上推理速度的对比分析,我们可以看到它们在CPU、NPU和GPU平台上的表现差异。下面将详细描述每个系列在不同硬件平台上的推理速度,并对比其性能。
表 1 YOLOv8全系模型在 Intel® Core™ Ultra 9 288V 处理器上推理速度
| 模型类型 | CPU | NPU | GPU |
|---|---|---|---|
| YOLOv8n | 24.78 ms | 3.60 ms | 2.64 ms |
| YOLOv8s | 72.04 ms | 6.37 ms | 4.62 ms |
| YOLOv8m | 200.34 ms | 12.23 ms | 9.13 ms |
| YOLOv8l | 410.67 ms | 22.89 ms | 16.72 ms |
| YOLOv8x | 629.35 ms | 33.72 ms | 23.86 ms |
表1列出了YOLOv8全系模型的推理时间,在YOLOv8系列中,随着模型复杂度的增加,推理时间也随之增长。在CPU 上,YOLOv8n(最小模型)需要24.78ms,YOLOv8x(最大模型)则达到629.35ms,推理时间大幅增加。在NPU 上,YOLOv8n的推理时间为3.60ms,YOLOv8x则为33.72ms。GPU上,YOLOv8n的推理时间最短,仅为2.64ms,而YOLOv8x则为23.86ms。可以看出,YOLOv8系列在NPU和GPU加速下的表现非常优越,特别是YOLOv8n和YOLOv8s,它们在GPU上的推理时间仅为2.64ms和4.62ms,显示了YOLOv8系列在加速硬件上的高效性。
表 2 YOLOv11全系模型在 Intel® Core™ Ultra 9 288V 处理器上推理速度
| 模型类型 | CPU | NPU | GPU |
|---|---|---|---|
| YOLOv11n | 19.90 ms | 3.97 ms | 2.55 ms |
| YOLOv11s | 56.56 ms | 6.15 ms | 4.53 ms |
| YOLOv11m | 184.46 ms | 15.20 ms | 8.87 ms |
| YOLOv11l | 228.37 ms | 18.20 ms | 11.62 ms |
| YOLOv11x | 499.18 ms | 38.50 ms | 20.40 ms |
表2介绍了YOLOv11系列,YOLOv11系列的推理时间相较于YOLOv8系列较长,尤其是在CPU 上。YOLOv11n在CPU上的推理时间为19.90ms,相比YOLOv8n的24.78ms稍快;但随着模型复杂度增加,YOLOv11x的CPU推理时间为499.18ms,依然长于YOLOv8x的629.35ms。NPU 加速方面,YOLOv11n的推理时间为3.97ms,YOLOv11x为38.50ms,虽然NPU加速显著提升了推理速度,但整体表现逊色于YOLOv8系列。GPU方面,YOLOv11n在GPU上为2.55ms,YOLOv11x为20.40ms,也表现得相对较慢。
表 3 YOLOv12全系模型在 Intel® Core™ Ultra 9 288V 处理器上推理速度
| 模型类型 | CPU | NPU | GPU |
|---|---|---|---|
| YOLOv12n | 23.31 ms | 6.55 ms | - |
| YOLOv12s | 64.50 ms | 13.39 ms | - |
| YOLOv12m | 185.73 ms | 29.39 ms | - |
| YOLOv12l | 253.26 ms | 49.43 ms | - |
| YOLOv12x | 559.51 ms | 82.29 ms | - |
YOLOv12系列的推理时间在所有系列中表现较慢,尤其是在CPU 上。YOLOv12n的推理时间为23.31ms,相比YOLOv8n和YOLOv11n都略长,而YOLOv12x的推理时间为559.51ms,明显比其他系列的最大模型更慢。在NPU上,YOLOv12n的推理时间为6.55ms,YOLOv12x为82.29ms,虽然在NPU加速下,推理速度有所提升,但相对其他系列仍然较慢。YOLOv12系列在推理速度方面的表现整体较为逊色,特别是在没有GPU加速的情况下。
从推理速度的整体表现来看,YOLOv8系列 无疑是表现最好的。YOLOv8在NPU和GPU加速下的推理速度非常高效,尤其是在YOLOv8n和YOLOv8s这两个小型模型上,其推理时间明显优于YOLOv11和YOLOv12系列,且在GPU和NPU加速下依然保持较短的推理时间。相比之下,YOLOv11系列 的表现略逊,虽然NPU加速有助于提升推理速度,但整体推理时间仍然较长。YOLOv12系列则在推理时间上表现最差,尤其是在没有GPU加速的情况下,其推理时间远高于YOLOv8和YOLOv11系列。
6. 总结
英特尔® 酷睿™ Ultra 处理器凭借其出色的性能和高效的能耗管理,成为深度学习和计算机视觉应用的理想选择。通过结合OpenVINO™工具套件和YOLOv11、YOLOv12等先进模型,我们可以显著提升推理性能,并确保在不同平台上高效运行。本文介绍了如何配置开发环境、使用C# API进行模型部署,以及如何利用处理器的优势优化应用程序性能。随着AI技术的不断发展,英特尔的硬件和软件工具将继续为开发者提供更强大的支持,推动人工智能在各个领域的应用与创新。希望通过本文的学习,读者能够在实际项目中灵活运用这些技术,实现更高效、更智能的解决方案。
最后如果各位开发者在使用中有任何问题,欢迎大家与我联系。
