一、准备工作
1、Python
下载Win平台的Python安装包,添加环境变量,测试:
bash
python --version在VSCode里( Ctrl+Shift+P 打开命令面板),指定Python解释器为上面安装路径。写一个python脚本运行测试。
2、虚拟环境
在 Windows 系统下使用 Python 虚拟环境(Virtual Environment)可以有效隔离不同项目的依赖,避免版本冲突。
在项目文件夹中新建虚拟环境venv,随后会在当前目录生成venv文件夹:
bash
python -m venv venv激活虚拟环境:
bash
.\venv\Scripts\activate后续的代码流程均是在venv虚拟环境中运行。
可以通过Ctrl+Shift+P,选择python解释器,选择虚拟环境venv。
3、添加国内镜像源
设置全局镜像源(清华源):
bash
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip config set global.trusted-host pypi.tuna.tsinghua.edu.cn4、安装pytorch环境
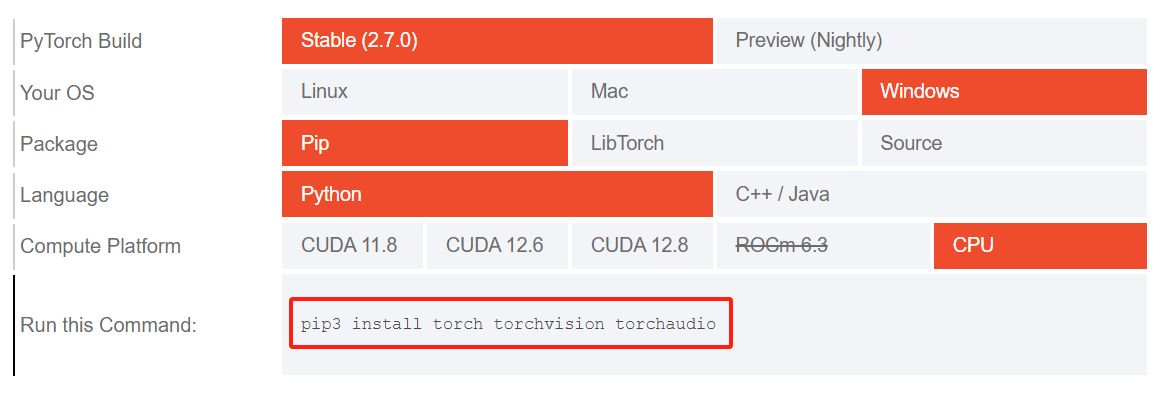
在官网选择对应版本的安装命令:Get Started
例如在win上通过cpu运行模型,安装对应的pytorch版本命令为:
pip3 install torch torchvision torchaudio
验证安装成功:
bash
python -c "import torch; print(torch.__version__)"二、部署OpenVINO
1、安装OpenVINO核心库
bash
pip install openvino
# 如果需使用 Open Model Zoo 的预训练模型,还需安装额外工具:
pip install openvino-dev[onnx] # 支持ONNX模型
pip install "openvino-dev[extras]" # OpenVINO 完整工具包2、官方教程 快速部署一个示例
GitHub - openvinotoolkit/openvino:OpenVINO™ 是一个用于优化和部署 AI 推理的开源工具包
基于pytorch进行部署,可以运行成功。
对于给定的示例,可以看到会先自动下载模型保存到本地,然后调用运行。
3、手动实现图像分类
使用预训练的resnet18模型,进行图像分类。
python
import openvino as ov
import torch
import torchvision
from PIL import Image
import numpy as np
# 加载PyTorch模型
# model = torch.hub.load("pytorch/vision", "resnet18", weights="DEFAULT")
model = torchvision.models.resnet18(weights="IMAGENET1K_V1")
model.eval() # 设置为测试模式
# 转换为OpenVINO模型
example = torch.randn(1, 3, 224, 224)
ov_model = ov.convert_model(model, example_input=(example,))
# 编译模型
core = ov.Core()
compiled_model = core.compile_model(ov_model, 'CPU')
# 图像预处理
preprocess = torchvision.transforms.Compose([
torchvision.transforms.Lambda(lambda x: x.convert("RGB")), # 强制转换为RGB
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
# 加载本地图片
image_path = "pic.jpg" # 修改本地图片路径
image = Image.open(image_path)
# 预处理并转换为模型输入格式
input_tensor = preprocess(image).unsqueeze(0) # 添加batch维度
input_numpy = input_tensor.numpy()
# 执行推理
output = compiled_model([input_numpy])[0] # 注意输入格式可能因版本不同需要调整
# 解析推理结果
probabilities = torch.nn.functional.softmax(torch.tensor(output), dim=1)
top5_prob, top5_catid = torch.topk(probabilities, 5)
# 加载类别标签(需要下载ImageNet 1000分类标签)
with open("imagenet_classes.txt") as f: # 确保该文件存在
categories = [line.strip() for line in f.readlines()]
# 输出预测的前5个结果和概率
print("\nTop 5 predictions:")
for i in range(top5_prob.size(1)):
print(f"{categories[top5_catid[0][i]]}: {top5_prob[0][i].item()*100:.2f}%")ImageNet的类别标签:imagenet_classes.txt
https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt