作者:来自 vivo 互联网服务器团队- Zhou Qi 、Kong Manyu
容器平台已经成为支持应用运维和部署的重要基础设施,当前 vivo 内部容器平台共有20+生产集群,管理数万物理机节点,运维管理难度不断增大。为提升运维效率和稳定性,容器团队开发了北斗运维管理平台用于解决大规模集群运维问题。北斗容器运维管理平台包含资源管理,集群扩缩容,巡检,事件中心,监控中心等功能。通过这些能力的构建,提升了集群的稳定性,从而提升了运维效率,节省了人力投入。
一、容器建设初期面临的挑战
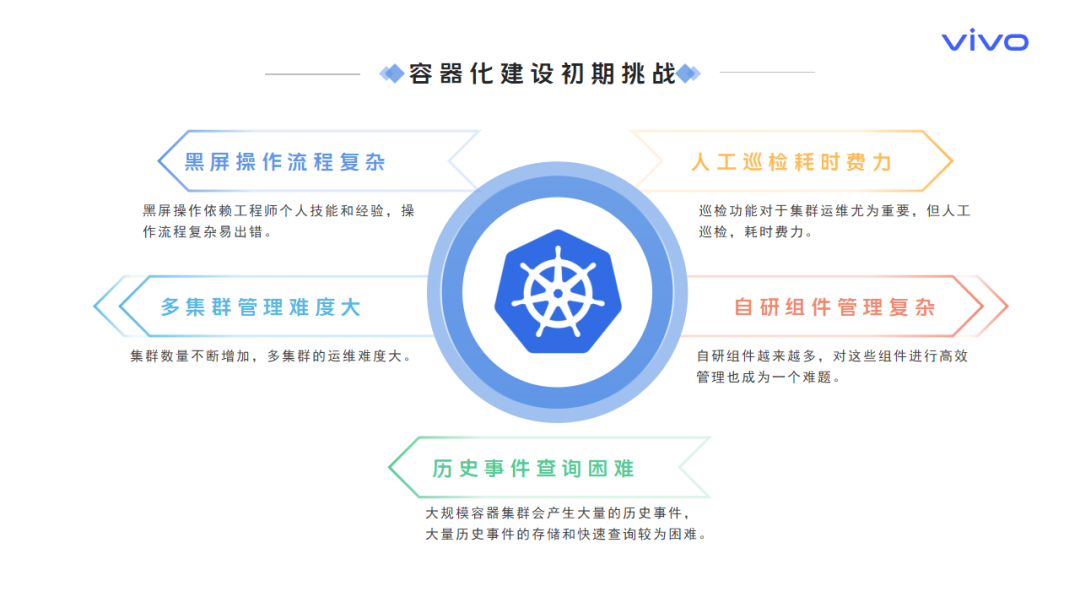
vivo 容器平台已经成为支撑应用运维和部署的重要基础设施,当前vivo内部容器化平台共有20+生产集群,管理数万物理机节点,运维管理难度不断增大,容器集群运维问题主要集中在以下几个方面:
-
黑屏操作流程复杂:黑屏操作依赖工程师个人技能和经验,容器运维操作流程复杂易出错。
-
人工巡检耗时费力:巡检功能对于集群运维尤为重要,但人工巡检,耗时费力。
-
多集群管理难度大:随着业务的不断接入,集群数量不断增加,多集群的运维难度大。
-
自研组件管理复杂:为扩展平台能力,自研组件越来越多,对这些组件进行高效管理也成为一个难题。
-
历史事件查询困难:大规模容器集群会产生大量的历史事件,大量历史事件的存储和快速查询较为困难。
仅靠人工很难运维大规模的容器化平台,解决当前面临的问题需从白屏化 和自动化入手,将黑屏操作转为白屏操作,将复杂的运维操作通过程序实现自动化,进而实现运维操作的标准化,提升整体的运维效率。
二、北斗平台解决方案
2.1 北斗平台构建目标
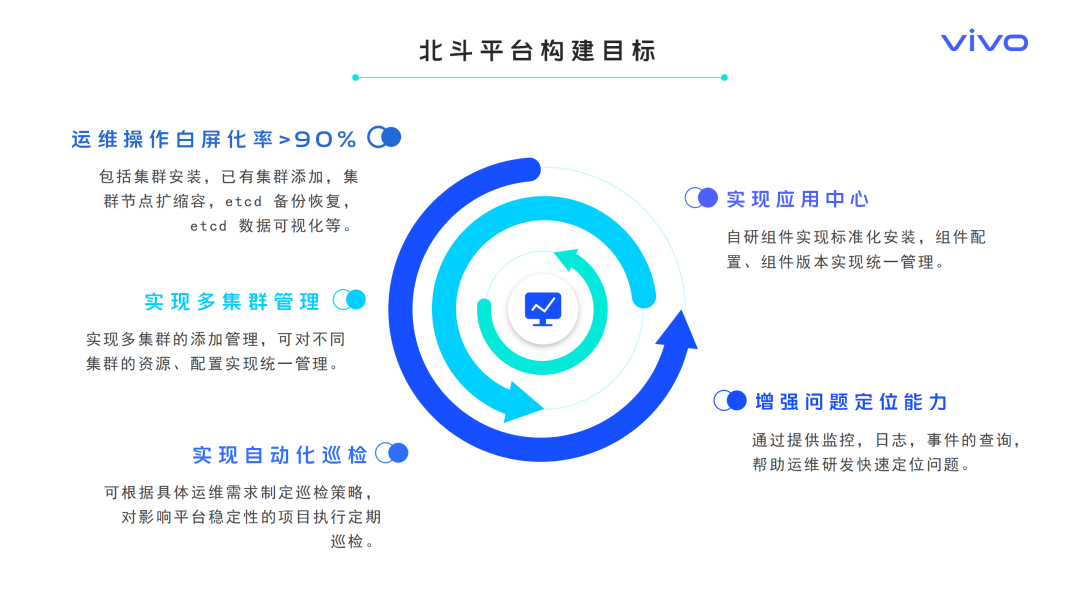
针对大规模容器集群运维面临的挑战,我们开始构建统一的容器集群运维管理平台,平台构建目标如下:
-
提升运维操作白屏化率: 实现运维操作白屏化率大于90%,实现高频运维操作白屏化。
-
实现多集群管理: 实现对不同集群的资源、配置的统一管理。
-
实现自动化巡检: 可根据具体运维需求制定巡检策略,执行定期巡检。
-
实现应用中心:实现自研组件的标准化安装,实现组件配置、组件版本的统一管理。
-
增强问题定位能力:提供事件查询,日志查询,监控查询能力,帮助运维研发快速定位问题。
基于以上的目标和需求,vivo 容器团队进行了相关能力和工具的开发,构建了北斗运维管理平台。
2.2 北斗平台能力矩阵
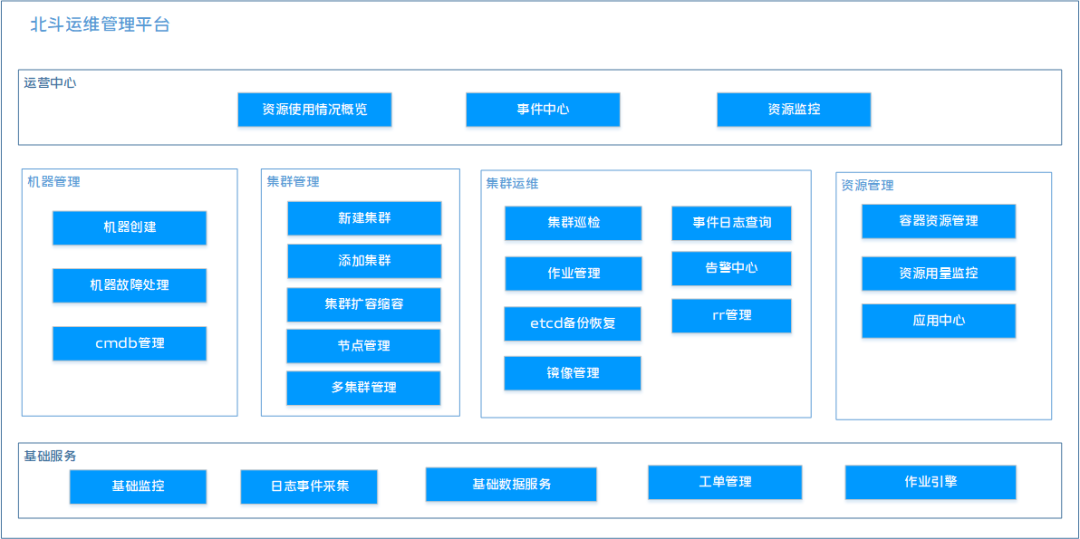
以上为北斗运维平台的能力矩阵,北斗运维平台包括运营中心、机器管理、集群管理、集群运维、资源管理、基础服务几大核心模块覆盖了运维管理的各个维度。
-
运营中心:提供关键运营数据的展示,嵌入了 Grafana 的监控面板,为用户提供全方位立体化的数据监控。
-
机器管理:支持对集群节点的统一管理和白屏操作,支持机器的添加,机器变更记录的查询,从而便于把控机器的全生命周期。
-
集群管理:支持对集群的基础资源、服务组件和应用资源的统一管理,提供创建集群,纳管已有集群,节点自动化扩缩容等能力。
-
集群运维:支持集群巡检,Etcd 的可视化管理,Etcd 数据备份恢复,ip地址池管理,镜像管理,变更管理等能力。
-
资源管理:支持对集群资源和业务应用的全方位管理。
三、平台核心能力构建
3.1 节点扩缩容工具建设
3.1.1 问题背景
集群节点的扩容和缩容是频率较高的运维操作,人工按照文档进行黑屏操作步骤繁琐,流程复杂,易出现误操作,影响集群稳定性。因此,实现集群节点扩缩容自动化成为首要解决的问题。
3.1.2 解决方案
3.1.2.1 集群扩缩容白屏化
为了解决集群扩缩容问题,我们借助了 Kubernetes 控制器模型设计了 kubeops-controller 模块,用于实现节点的自动扩缩容和集群安装。我们将所有的操作抽象为 Kubernetes 的 crd 资源 operation,operation 资源定义如下:
apiVersion: vcluster.caas.xxxx.com/v1alpha1
kind: Operation
name: scaleup-2024
namespace: beidou-system
spec:
clusterName: product-cluster
operationType: ScaleUp
operationFlow:
- preCheck
- scaleUp
- postCheck
operationMachines:
- ip: 127.0.0.1
role: Compute
user: admin下图为扩缩容模块的架构设计图。
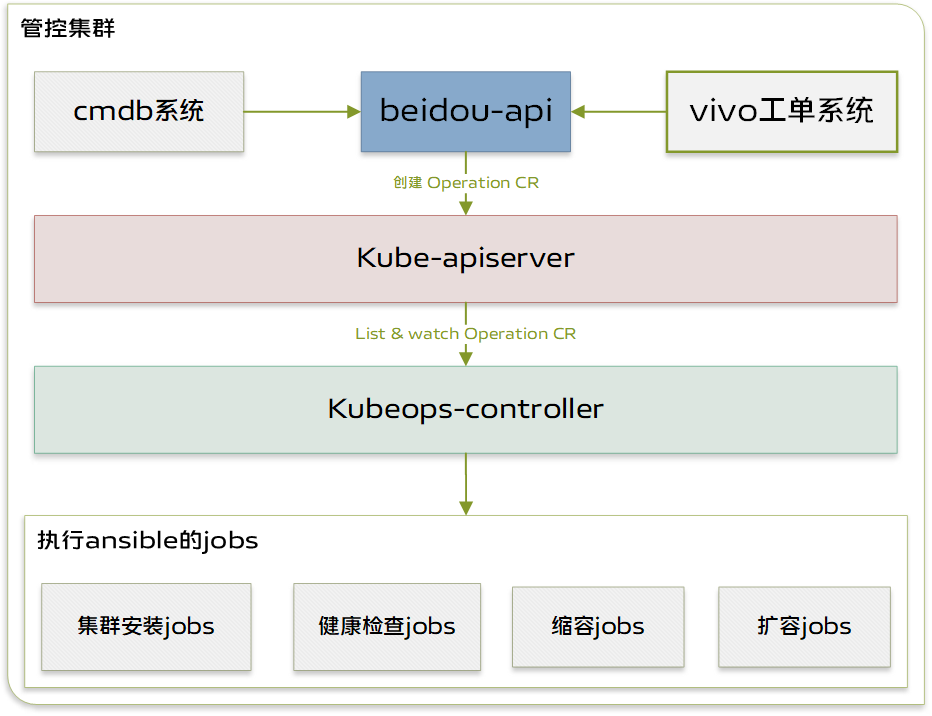
如架构设计图所示扩缩容组件包含以下主要模块:
-
beidou-api: 北斗平台的 API 层,用于接收和响应外部请求。
-
kube-apiserver: Kubernetes API 层,负责处理和响应来自集群内部和外部的所有API请求。
-
kubeops-controller: 用于处理 operation 扩缩容操作的控制器。
-
Job: Job 用于创建和管理一次性任务或定时任务,确保任务能够成功完成并且不会重复运行,这里主要用于执行 Ansible 脚本。
用户在控制台创建扩容任务后,beidou-api 会捕捉其中的参数并调用 Kubernetes 接口创建 operation,operation 中包含了集群标识,待扩缩容节点,操作类型等信息。kubeops-controller 控制器会监听 operation 的创建,并根据 operation 参数来执行相应的流程任务。kubeops-controller 会依据扩容或缩容参数来创建 Job,Job 则会执行 Ansible 脚本来自动完成集群安装和节点扩缩容任务,其中的 Ansible 脚本是基于 Kubespray 项目进行定制化改造而成。
1)扩容操作
扩容分为三个小步:扩容前检查,扩容,扩容后检查。通过三个步骤确保能够成功扩容集群节点,每个步骤都会启动一个 Job 来执行 Ansible 脚本完成任务。
-
扩容前检查:通过 Ansible 脚本来检查磁盘空间是否够用,内核版本是否符合需求,是否残留 kubelet 和 Docker 等进程。通过扩容前检查来确保节点能够顺利安装。
-
扩容:扩容节点则会执行 Ansible 脚本将节点添加到集群。
-
扩容后检查:节点是否处于就绪状态,网络是否连通,确保节点就绪后,会放开调度投入生产。
2)缩容操作
缩容操作主要分为两个步骤:缩容前检查,缩容。
-
缩容前检查:需要先检查节点是否存在业务 Pod。如果存在业务 Pod,平台会提供一键迁移业务功能,避免对业务造成影响。
-
缩容:执行 Ansible 脚本删除节点的 kubelet,Docker 等服务,并清理残留数据,确保不影响下次的节点安装。
3)节点健康检查
在进行运维操作时,需随时检查集群节点的健康状态,检查流程包括网络侦测、pod 是否可正常创建等,通过这个步骤可进行问题排查。节点健康检查是通过执行 Ansible 脚本来检查 kubelet、Docker、kube-proxy 服务的运行状态,检测节点的网络连通性。
3.1.2.2 扩缩容全流程自动化
扩缩容白屏化功能的构建解决了黑屏操作存在的问题,但节点的扩容操作依然涉及多个步骤,即使白屏操作,也无法避免繁琐的流程。为了进一步节约人力,提升效率,实现一键扩缩容节点迫在眉睫,我们设计实现了全流程自动化功能。为了实现全流程自动化扩缩容功能,我们在 operation 的上层设计了 autooperationtask crd,autooperationtask 的定义如下:
apiVersion: vcluster.caas.xxxx.com/v1alpha1
kind: AutoOperationTask
metadata:
name: scaleup-xxxxxx
namespace: beidou-system
spec:
cluster:cluster-example
clusterType: native
operationIds:
- scale-up
operationTaskMachines:
- name: xx.xx.xx.xx
- name: xx.xx.xx.xx
operationTaskStep:
- step: ScaleUpPreCheck
- step: ScaleUpWorkprocess
- step: ScaleUp
- step: UncordonNodes
- step: ScaleUpSubWorkprocess
operationTaskType: ScaleUp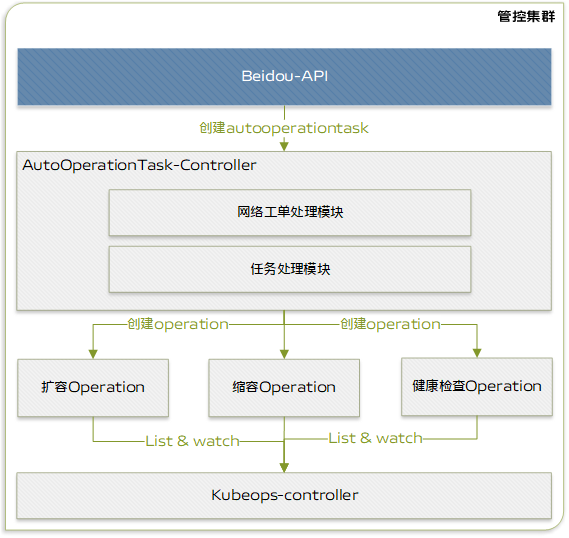
如上架构图所示,全流程自动化主要包含如下模块:
-
AutoOperationTask-controller:全流程自动化控制器,会对 autooperationtask 进行处理。
-
网络模块: 网络模块的作用是处理网络相关的任务,如调用网络接口配置节点网络
-
任务处理模块:此模块的主要作用是根据需求按顺序创建operation。
-
kubeops-controller: 任务处理控制器,会对 operation进行处理。
AutoOperationTask-controller会持续监听autooperationtask crd 的创建事件,任务处理模块会根据 autotask 定义的流程和步骤,创建 operation(上文提到的对扩缩容等任务的抽象)。kubeops-controller 会监听 operation 的创建,并创建 Job 执行脚本。

上图是可视化的扩缩容流程,通过这种设计,我们将所有能够顺序执行的任务简化成一个自动化任务,全流程自动化将所有的操作串联起来,不仅可以节省人工操作的时间,而且支持实时追踪任务进程,观测任务状态。
3.1.3 达成效果
通过扩缩容全流程自动化的建设,我们将扩容20台机器的时间从60分钟缩短到10分钟,从原本的人工十几个步骤才能完成的流程变为一键部署,且没有出现过由于人工操作失误而引入的问题。目前,通过北斗系统执行了5000+ 的扩缩容任务,交付了上万台机器。未来团队将持续优化扩容效率,缩短健康检测时间。
3.2 集群巡检工具建设
3.2.1 问题背景
集群常会出现一些不可预料的问题,这些问题都严重影响集群的稳定性。
-
集群节点问题:cpu, 内存使用率过高,磁盘占满,内核死锁,文件系统崩溃等。这些都会导致节点 Pod 不可用,影响用户的业务。及时发现节点问题对于运维来说至关重要,尽早介入处理才可以避免更为严重的问题发生。
-
资源配置问题:除了节点问题外,集群配置问题,证书过期和资源定义不规范,都可能导致集群不可用,带来严重隐患,为避免这些潜在问题影响到生产环境,巡检能力的构建变得尤为重要。
集群巡检需要具备如下能力:
-
Kubernetes资源巡检:巡检 Kubernetes 集群的Deployment、StatefulSet 等资源配置是否符合要求。
-
集群节点巡检:巡检节点磁盘、内存、cpu 使用率、内核日志是否存在问题。
-
自定义脚本巡检:支持自定义脚本巡检。
3.2.2 解决方案
为解决如上问题,实现巡检目标,我们开发了 kube-doctor 组件来对集群进行巡检。
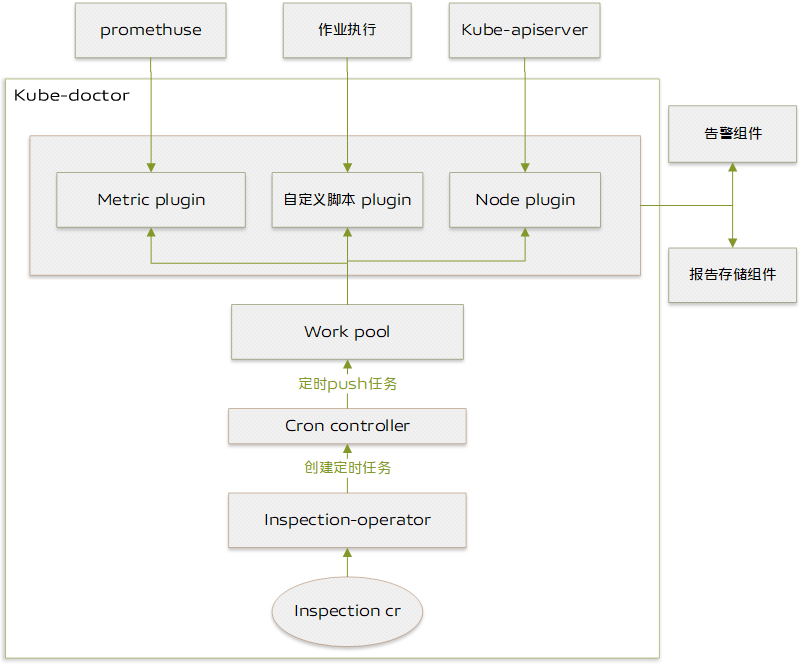
上图为 kube-doctor 的架构设计:
-
inspection crd:用于记录巡检的基本信息,包括巡检名称、巡检脚本、巡检集群、巡检时间、巡检策略等
-
inspection-operator:inspection-operator 控制器会监听 inspection 的创建,并对其进行处理,inspection 会根据 inspection 定义的巡检时间和巡检内容,交给 cron-controller 模块处理。
-
cron-controller: cron-controller 负责按照巡检任务 inspection 定义的巡检周期驱动 worker 定时执行任务,worker则负责具体巡检任务的执行。
-
work-pool: worker 资源池,当有新的巡检任务需执行时,cron-controlle 会从 worker 池中获取 worker,驱动 worker 执行定时任务。
-
巡检驱动:为了支持不同类型和不同场景的巡检,我们设计了巡检驱动功能。巡检驱动需要实现两个标准的巡检接口 RunInspectionTask 和 StoreReport。
如下为 go 语言实现的 driver 接口:
type InspectionInterface interface {
RunInspectionTask(ctx context.Context, cluster []ScheduledCluster) (error, []string, *AlertInfo)
StoreReport(result interface{}, cluster ScheduledClusteralertMessages *SyncMessages) error
}RunInspectionTask 执行具体巡检任务,例如到指定节点执行脚本,并获取结果。StoreReport 的作用则是存储巡检报告,存储巡检报告支持将数据存储到 MySQL 或者 Elasticsearch。目前定义了自定义脚本,数据指标和节点指标三种 driver。
-
自定义脚本: 用户可以自定义的脚本,到指定的集群节点执行,并获取到执行结果。
-
数据指标:数据指标来自于监控模块 promethuse。
-
节点指标:获取 node-problem-detector(用于发现节点问题的开源组件) 的执行数据。
3.2.3 达成效果
目前 kube-doctor 已经执行了数千次的巡检任务,生成数千份巡检报告,帮助运维及时发现容器集群问题。
3.3 应用中心建设
3.3.1 问题背景
随着业务的发展,集群内自研组件的增多使得对组件的管理变得复杂,基于此问题我们需着手构建应用中心能力,对组件进行统一管理。应用中心需要具备如下能力:
-
应用模版管理:支持上传 Chart 包到 vivo 对象存储,可发布到应用中心,发布成功后支持对 Chart 模版进行更新,按照版本管理。
-
应用部署管理:支持将应用直接部署到不同的集群和 Namespace,部署过程中可监听修改参数。常用参数支持配置在 values.yml 文件中直接编辑修改,无需重新打 Chart 包,使部署流程更方便高效。
-
应用实例管理:支持查看应用在哪些集群部署了哪些实例,点击应用实例可以跳转到实例详情,查看实例的配置等相关信息,进行相应的配置修改和升级。
3.3.2 解决方案
为解决如上问题,我们开发了应用中心功能,将集群中各类组件和服务托管到北斗平台进行统一管理。通过 Kubernetes 提供的应用安装管理组件 Helm 执行应用的安装、部署、升级及配置修改等,方便在不同集群中分发和部署应用,支持服务的全生命周期管理。下图为应用中心的架构设计:
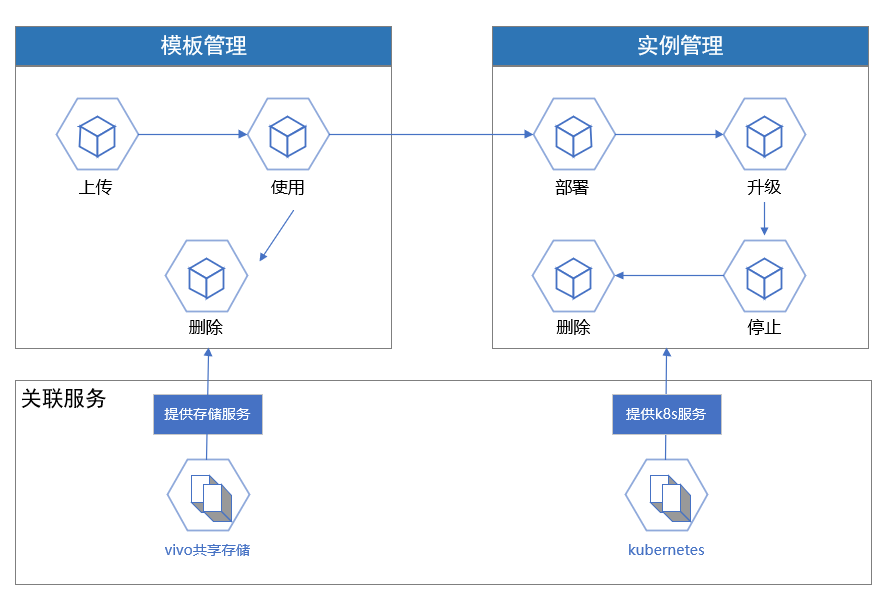
3.3.2.1 模板管理
为管理应用模板,我们定义了 helmapp CRD和helmappversion CRD。用户可以上传 chart 包,前端将解析其内容并传递给 beidou-api,以创建 helmapp CRD 并存储到 vivo 对象存储系统,同时会创建一个 helmappversion CRD,用于记录版本和存储地址,以便进行安装操作。
-
helmapp crd: 用于记录 chart 包的基本信息,如应用名称、应用描述、应用 log 等信息。
-
helmappversion crd: 用于记录 chart 包的版本信息和存储地址,便于安装包的获取。
3.3.2.2 实例管理
应用安装包安装到集群后会生成一个运行中的应用,也就是一个应用实例,对此我们设计了 release crd 用于表示一个应用实例,通过调用 beidou-api 接口创建 release(实例),控制器监听到创建事件后从 crd 中获取需要安装的chart包名称和版本,并从 vivo 对象存储系统中获取 chart 包,从 values 中读取相关参数,最后获取 cluster crd 中的 kubeconfig 数据,通过这种方式就能够将应用安装到不同集群中。
-
release crd:存储应用实例信息,包括 chart 包名称、版本等信息
-
beidou-release-controller:监听 release 创建事件,并对 release 进行处理。
-
values: release spec 中定义的应用配置参数。
3.3.3 达成效果
目前通过应用中心管理的应用达到了50+,管理的应用实例达到200+,实现了降低组件管理复杂度,提升管理效率,且与AI和数据部门合作用于复杂应用的部署和管理。
3.4 事件采集和监控体系构建
3.4.1 问题背景
在 Kubernetes 中,事件(Events)是集群在特定对象上发生的特定时间点上的状态变化记录。事件涵盖有关 Pod 的调度决策、Container 的状态变化、节点的压力情况等重要信息。事件可帮助开发工程师和集群运维工程师理解集群内部发生的事件。通过 Kubernetes 中的事件,可快速发现和定位问题。但当前集群的事件都存储于 Etcd,事件查看较为麻烦,由于 Etcd 空间限制,无法长期存储事件,这些问题为追溯历史问题造成困难。
3.4.2 解决方案
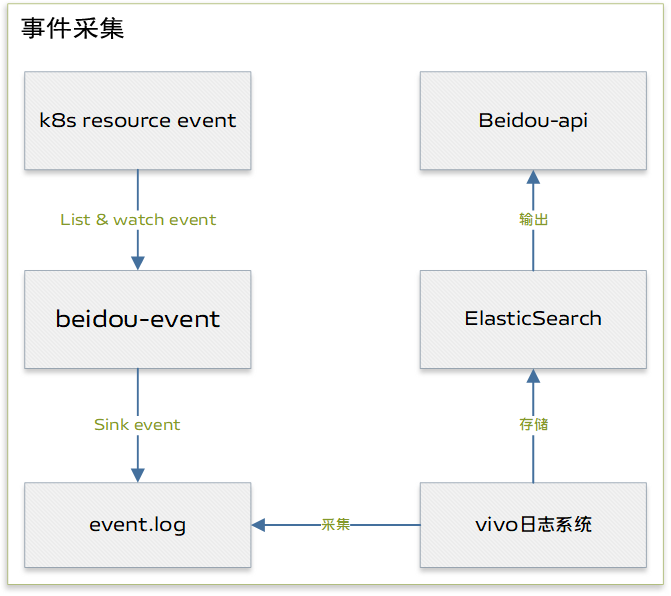
针对此问题,平台开发了事件采集存储组件 beidou-event,上图 beidou-event 架构图。
-
beidou-event: beidou-event模块会实时监听kube-apiserver 的事件,并将事件按照一定的格式输出到主机的某一个目录。
-
vivo 日志系统:vivo 日志系统由 vivo 开发用于专门的日志采集和存储的系统,这里也可以使用ELK等日志采集方案。
-
Elasticsearch: vivo 日志系统采集完数据后会将数据存储到Elasticsearch。
-
Beidou-api: beidou-api 会调用 Elasticsearch 获取事件数据并在前端作展示。
3.4.3 达成效果
当前 Elasticsearch 保持在30亿+的事件数量,历史事件的查询帮助运维和研发快速定位历史问题,在问题追溯上发挥了重要作用。
四、总结与展望
经过几年的能力建设,我们基本实现了北斗平台构建目标。
-
90%以上高频操作实现白屏化:北斗运维平台已经将90%的黑屏运维操作实现白屏化。各种高频率文件配置,资源配置,资源调整,问题定位都可以通过北斗运维管理平台进行。操作人,操作内容皆可通过审计功能进行追溯。
-
集群安装和扩缩容工具大幅提效:通过北斗平台安装数个k8s集群,扩容了上万台机器。标准化的程序执行规避了由于人为操作导致的失误,保证了集群的稳定性和可靠性。通过白屏化简化了操作流程,扩容由原本的人工执行十几个步骤,实现了一键扩缩容,缩减了扩缩容时间,提升了运维的效率。
-
运营中心实现全方位运营监控:通过运营中心的资源概览和监控功能可帮助及时掌握集群数量,集群规模,资源填充率,集群资源使用情况等关键指标,便于对资源进行治理,避免由于资源问题影响业务。
-
巡检能力助力问题及时发现解决:集群巡检功能自投入使用已经生成了3000+份的巡检报告,详细记录了巡检过程中发现的不符合规范和巡检规则的风险项。通过巡检功能及时发现集群存在的不稳定因素,帮助运维同事及时排除问题。
-
事件采集助力集群问题排查:事件采集和查询功能在问题定位过程发挥重要作用,为问题的解决提供重要线索。同时,事件中心归纳了核心且关键的事件指标,便于掌控集群的运行状况。
-
应用中心标准化组件安装:应用中心功能管理所有的自研组件,组件的安装、升级和配置修改变得更加便利。同时,此功能开放给高级用户用于复杂应用的部署。
北斗容器自动化运维平台的构建进一步解放了人力,提升了运维效率,支撑了上万台机器数十个容器集群的运维。容器运维平台未来会向智能化自动化方向发展,实现平台自动侦测问题,解决问题,结合人工智能技术,提供更加智能的运维平台,进一步提升运维效率和集群稳定性。