链表的觉醒:当线性结构长出翅膀
想象一串珍珠项链------每个节点优雅地牵着下一个节点的手。这种单向的、线性的、链表最本真的特性:插入与删除的瞬时性 \(O(1)\)。但当需要寻找特定节点时,我们不得不 \(O(n)\)遍历。
为链表赋予有序性,我们就可以维护一个有序的结合。使用有序数组维护有序集合,插入删除将移动大量元素;使用链表可快速插入删除,但当我们试图用二分查找加速时,却发现致命缺陷:数组可以通过下标瞬间跃迁,而链表只能沿着指针蹒跚爬行。
如果让链表突破二维平面呢?其实基础深厚的你很容易想到,我们可以再建造一层间隔更大的列表,首先从大间隔的副本里加速跳跃,就可以缩短遍历时间。
想象一座立体城市:地面是原始链表,空中架设多层高架桥。高层道路跨度更大,连接远方地标;底层道路细密交织,保留完整细节。这种空间折叠的直觉,正是跳表的核心隐喻。
当然,由于链表可以再中间随时插入删除,我们不可能提前规定好每层链表副本的间隔数。跳表的神性在于:它不强制维持完美平衡,而是让每个节点以概率为尺,以一定概率在上一层中出现。
通过概率性生长 的层级结构,跳表在保持链表动态优势的同时,创造出类似二分查找的快速通道。每一层都是下层链表的"快照缩影",高层指针如同穿越时空的虫洞,让查询操作实现对数级\(O(\log n)\) 的跳跃式演进。
跳表结构
传统链表节点只携带单一下程地址:
cpp
struct Node {
int value;
Node* next;
}; 而跳表节点则化身多维存在,每个节点代表本节点的所有层,同时携带一组指针,代表本节点在每一层指向谁:
cpp
struct Node {
int value;
vector<Node*> next;
}; 每个节点的next数组长度即其高度,动态分配。
层数的生成从底层(层0)开始抛掷一枚概率硬币,连续成功则向上跃升。设跳表的参数概率为 \(p\),则节点达到第 \(k\) 层的概率为:
\P(k) = p\^{k} \\cdot (1-p) \\
这形成几何分布,其数学期望为:
\E(\\text{层数}) = \\frac{1}{1-p} - 1 \\
当 \(p=0.5\) 时,约50%节点有第1层,25%有第2层......如同金字塔,高层节点愈发稀少却战略地位显著。
参数设计
- 概率 \(p\) :通常取 0.25~0.5。\(p\) 值越小,高层节点越稀疏,查询时跳跃幅度更大,但需要更多层数补偿
- 最大层数 \(L_{max}\) :防御极端情况,常取\(L_{max} = \log_{1/p}n + 1\)。例如 \(n=10^6\) 时,\(p=0.5\) 则 \(L_{max} \approx 20\)
空间折叠的具象化
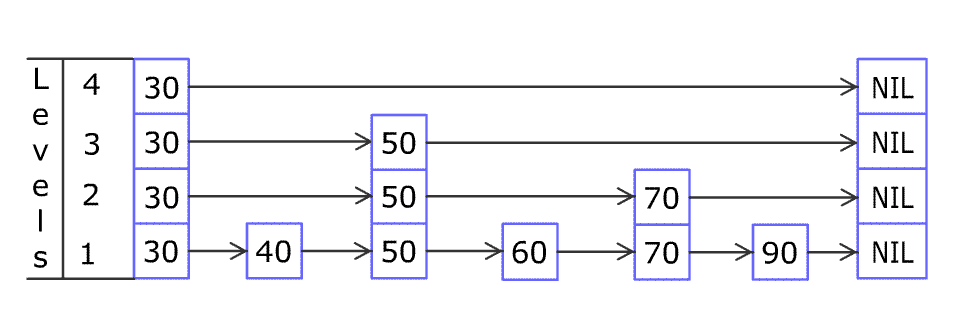
想象一个含值1,3,5,7,9的跳表( \(p=0.5\) ),其结构可能呈现:
层3:1 ----------------------------> 9
层2:1 --------5 --------> 7 -----> 9
层1:1 -> 3 -> 5 -> 7 ---> 9
层0:1 -> 3 -> 5 -> 7 -> 9 高层指针如同跃迁引擎,使查询7时路径为:层3跳1→9(超界)→降层→层2跳1→5→7,仅需3步而非底层5步。
- 时间复杂度 :每层遍历节点数期望为 \(\frac{1}{p}\),总层数约 \(\log_{1/p}n\),单次查询的整体时间复杂度 \(O(\log n)\)
- 空间复杂度 :节点平均层数\(\frac{1}{1-p}\),平均总空间消耗 \(O(n)\)。当 \(p=0.5\) 时,空间开销仅为原链表的 2 倍
核心操作
1. 查找
-
高空俯冲策略:从最高层指针出发(如 16 层)
-
层间跃迁法则 :
\\\text{while } (当前节点.next\[层 \neq null) \land (当前节点.next层.val < target) \]
-
精准着陆:当无法继续向右(右侧更大或来到链表尾)时,向下穿越维度(层数减1)
2. 插入
- 定位:和查找一样从上往下定位。不过,由于是单链表,从高层向底层逐层记录走过的最后一个点。
- 随机生长:要插入的节点依概率得到自己的层数。
- 缝合 :在每一层进行和通常链表一样的插入,将新节点的各层指针与
update数组节点链式缝合。
3. 删除
- 定位:和查找一样从上往下定位。也需要从高层向底层逐层记录走过的最后一个点。
- 缝合:在每一层和通常链表一样逐层解除链接,释放内存

cpp
// 参考题目:https://leetcode.cn/problems/design-skiplist/description/
class Skiplist {
int maxLevel;
double p;
struct Node {
int val;
vector<Node*> next;
Node(int val, int level) : val(val), next(level+1, nullptr) {}
};
Node* head;
int randomLevel() {
int level = 0;
while (rand() < p * RAND_MAX && level < maxLevel) {
level++;
}
return level;
}
public:
Skiplist(): p(0.4), maxLevel(16), head(new Node(-1, maxLevel)) {
srand(time(0));
}
bool search(int target) {
auto p = head;
for (int level = maxLevel - 1; level >= 0; level--) {
while (p->next[level] && p->next[level]->val < target) {
p = p->next[level];
}
} return p->next[0] && p->next[0]->val == target;
}
void add(int num) {
auto p = head;
vector<Node*> update(maxLevel, nullptr);
for (int level = maxLevel - 1; level >= 0; level--) {
while (p->next[level] && p->next[level]->val < num) {
p = p->next[level];
}update[level] = p;
}
Node* newNode = new Node(num, randomLevel());
for (int i = 0; i < newNode->next.size(); i++) {
newNode->next[i] = update[i]->next[i];
update[i]->next[i] = newNode;
}
}
bool erase(int num) {
auto p = head;
vector<Node*> update(maxLevel, nullptr);
for (int level = maxLevel - 1; level >= 0; level--) {
while (p->next[level] && p->next[level]->val < num) {
p = p->next[level];
}
update[level] = p;
}
Node* target = p->next[0];
if (!target || target->val != num) return false;
for (int i = 0; i < target->next.size(); i++) {
update[i]->next[i] = target->next[i];
}
delete target;
return true;
}
};复杂度
| 操作 | 平均情况 | 最坏情况 |
|---|---|---|
| 查找 / 插入 / 删除 | \(O(\log n)\) | \(O(n)\) |
虽然理论最坏情况(所有链表都没有被提升或都被顶到最高)与链表相同,但实际工程中通过:
- 合理设置 \(p=0.4\)
- 限制 \(L_{max}=16\)
使得极端情况概率低于\(10^{-9}\),实践复杂度等效 \(O(\log n)\)
假定 \(p=0.4\),节点平均层数:
\E(L) = \\frac{1}{1-p} = \\frac{1}{1-0.4} \\approx 1.67 \\
总空间消耗:
\O(n \\cdot E(L)) = O(1.67n) = O(n) \\
即增加这么多层后,平均仍是 \(O(n)\),假设最大高度设置为 \(\log n\),那么理论最坏空间是每层都顶到最高,即\(O(n\log n)\),实际上不可能发生。
相比红黑树每个节点存储颜色标记和左右子树指针,跳表通过空间换时间获得更简洁的实现
跳表与平衡树
平衡树和跳表解决了同一个问题(维护有序集合),各有优缺点。
1. 跳表的锋芒
- 实现简单性:200 行代码 vs 红黑树500+行
- 无锁并发优势:LevelDB MemTable 利用跳表的局部性实现高效写入
- 范围查询优化 :
SELECT * WHERE key BETWEEN a AND b可沿底层链表快速遍历
2. 平衡树的坚守
- 严格时间复杂度:红黑树保证最坏情况
- 内存紧凑性:B+树节点存储更多子节点,适合磁盘页存储
- 持久化优势:AVL树旋转不改变原有路径,利于实现事务回滚
| 特性 | 跳表 (Skip List) | 平衡树 (Balanced Tree) |
|---|---|---|
| 时间复杂度 | 查找、插入、删除:平均 O(log N),最坏 O(N) | 查找、插入、删除:O(log N) |
| 空间复杂度 | O(N),其中 N 是元素个数 | O(N) |
| 实现复杂度 | 相对简单,容易实现 | 较复杂,涉及树的旋转操作 |
| 平衡性 | 不需要复杂的平衡操作,随机化的跳跃机制实现平衡 | 通过旋转操作确保平衡 |
| 查询效率 | 平均 O(log N),最坏 O(N) | O(log N) |
| 插入/删除效率 | 平均 O(log N),最坏 O(N) | O(log N) |
| 内存消耗 | 由于多层链表,内存消耗较高 | 由于节点存储平衡因子(或颜色),内存消耗略高 |
| 可扩展性 | 可以适应动态扩展,但随着规模增大,跳表可能退化为链表 | 在动态环境中(如频繁插入删除)效率保持较高 |
| 应用场景 | 高度并发的场景,尤其是在网络协议、分布式系统中 | 数据库、文件系统、图形学中的空间分配等 |
3. 战场启示录
| 场景 | 胜出者 | 决胜因素 |
|---|---|---|
| 内存数据库索引 | 跳表 | 实现简单,写入速度快 |
| 磁盘数据库索引 | B+树 | 页对齐优化 |
| 实时游戏排行榜 | 跳表 | 范围查询高效 |
| 金融交易系统 | 红黑树 | 稳定延迟保证 |